
FedDeep: A Federated Deep Learning Network for Edge Assisted Multi-Urban PM2.5 Forecasting
Abstract
:1. Introduction
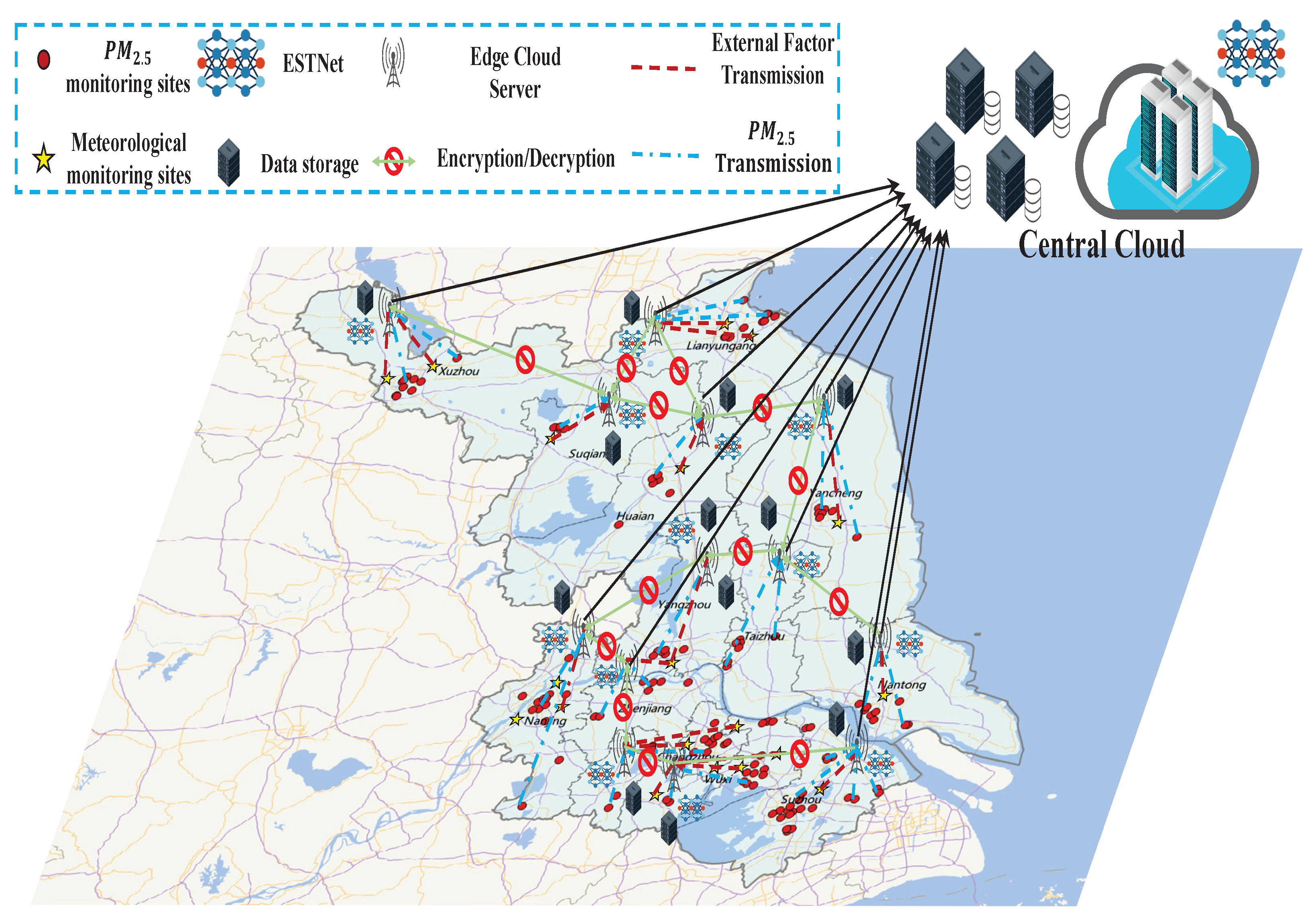
- Since multiple urban monitoring sites produce massive amounts of data, high computational pressure and data leakage levels occur when leveraging only a central cloud for all data and computing task. In light of this, we present an edge-based federated learning architecture. Specifically, we deploy a separate ECS in each urban region. The data acquired by the sensors in each urban region are uploaded to the corresponding ECS instead of the central cloud for training, which effectively mitigates the computational pressures on the central cloud and prevents security risks. Subsequently, the gradients trained on the ECS are uploaded to the central cloud for parameter updates, and then the model deployed on the central cloud predicts the in all urban regions, which creates a “distributed training, centralized prediction” mode.
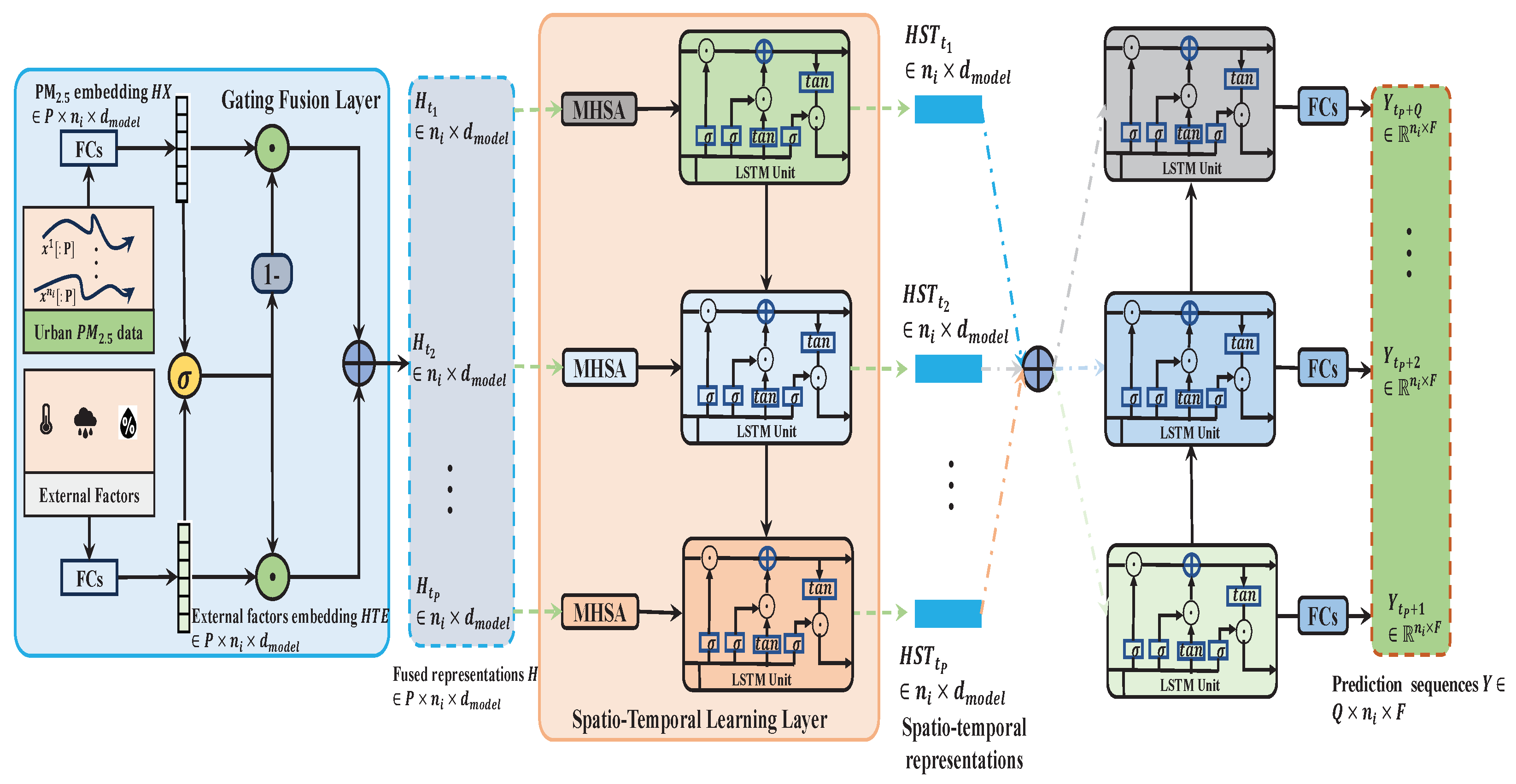
- We design a novel ESTNet model, in which a gating fusion layer is proposed to adaptively fuse external factors and urban features based on the different impacts of external features.
- The experimental results on 13 prefecture-level cities in Jiangsu Province confirmed that FedDeep outperformed other state-of-the-art baselines. Specifically, FedDeep achieved the highest accuracy in predicting for the subsequent 12 h. Meanwhile, FedDeep had a short training time and low GPU usage, thus showing its high efficiency.
2. Related Work
2.1. Air Pollution Prediction
2.2. Federated Learning
3. Materials and Methods
3.1. Overview
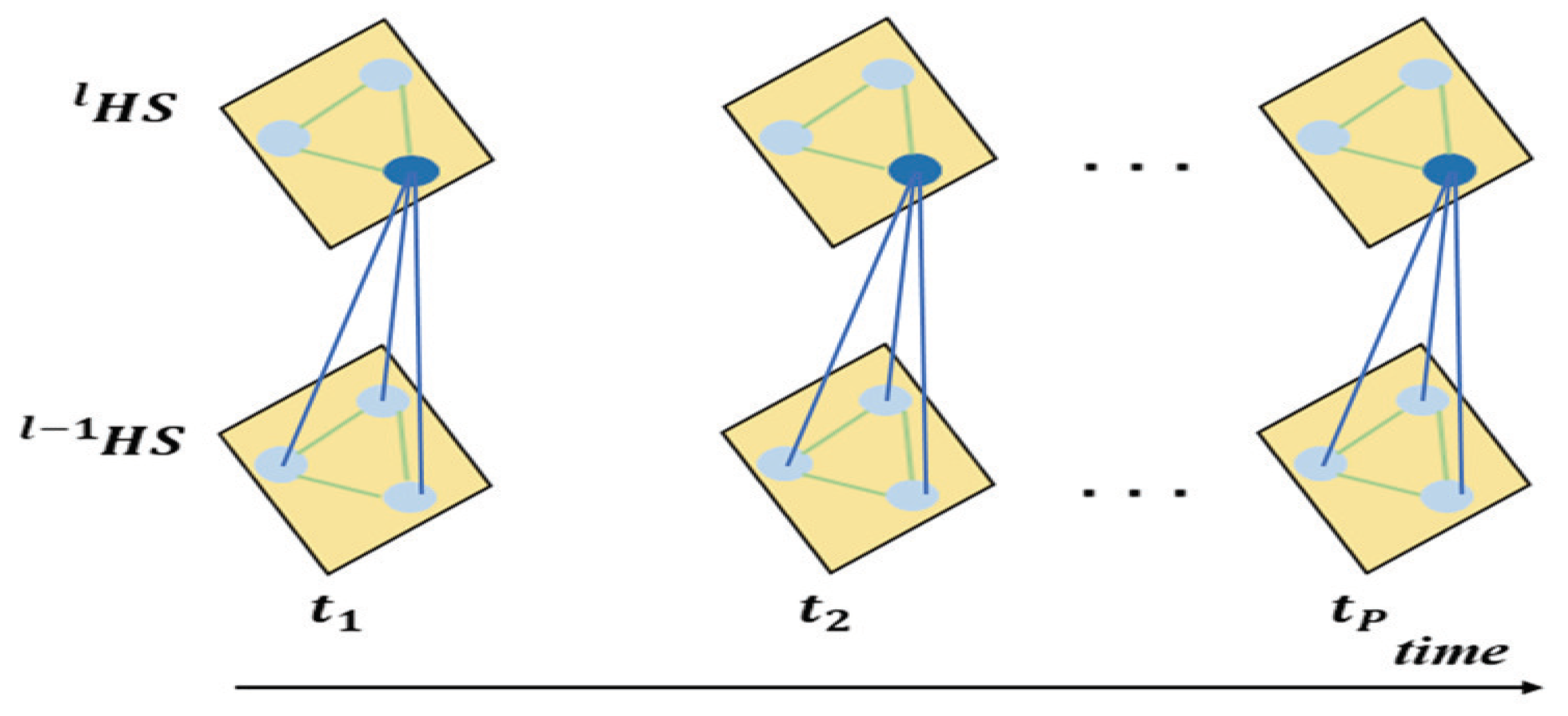
3.2. Local Estnet
3.3. Parameter Update for Global ESTNet
4. Results and Discussion
4.1. Experimental Settings
4.1.1. Study Area and Data
4.1.2. Baselines
- HA [20]: The average historical sequence was adopted to forecast future multi-urban concentrations.
- SVR [21]: A support vector with RBF Kernel was designed for multi-step forecasting.
- LSTM [23]: This is a variant recurrent neural network (RNN) used to mine dynamic temporal dependencies in data and produce predictive sequences.
- CNN-LSTM [24]: This model integrates CNN and LSTM to capture the spatio-temporal correlations in data.
- GAT-LSTM [25]: This model mines spatial dependencies from a non-Euclidean spatial perspective and then applies LSTM to model temporal dependencies.
4.1.3. Metrics
4.1.4. Parameter Settings
4.2. Experimental Results
4.2.1. Performance Comparisons
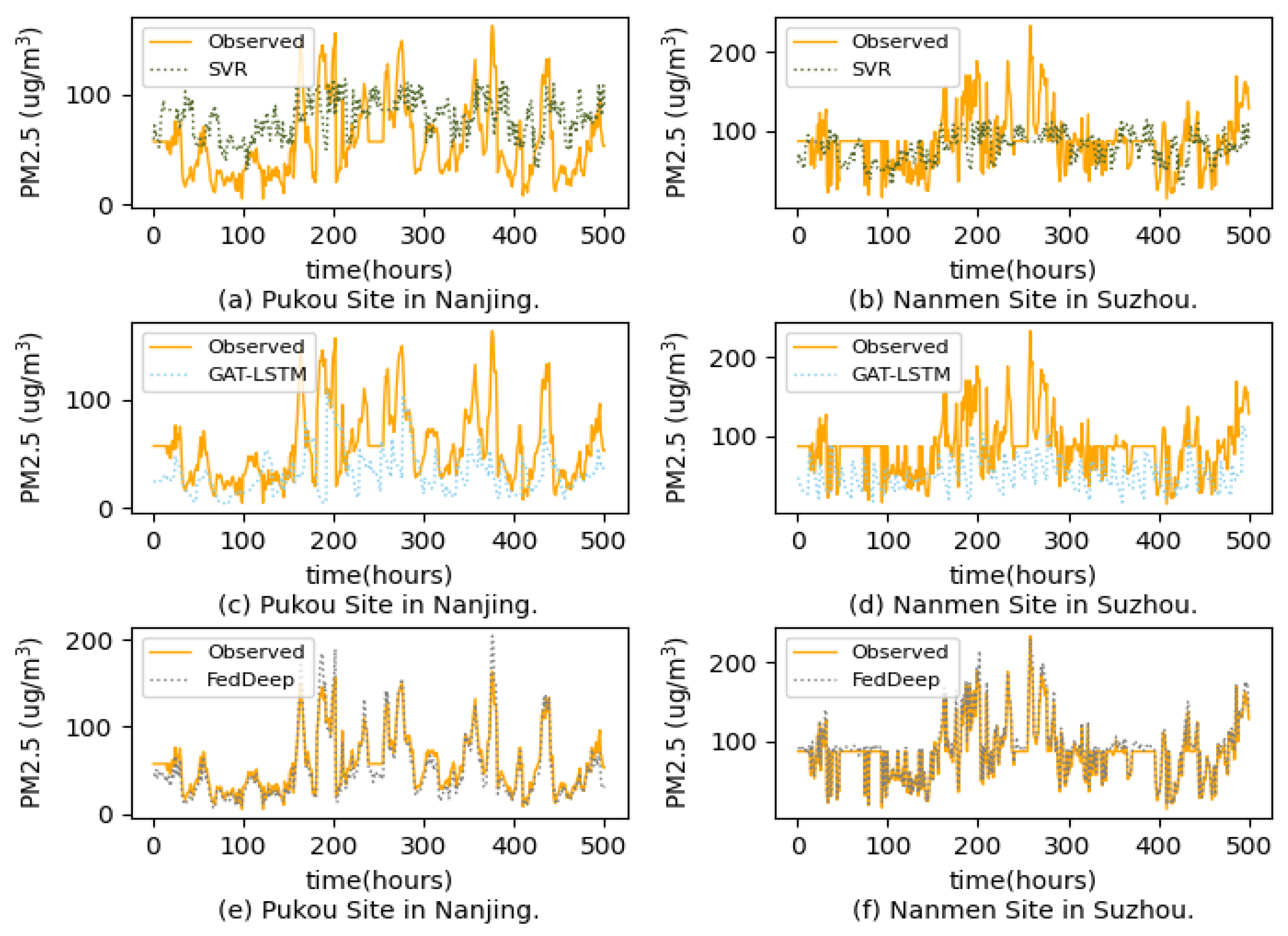
4.2.2. Case Study
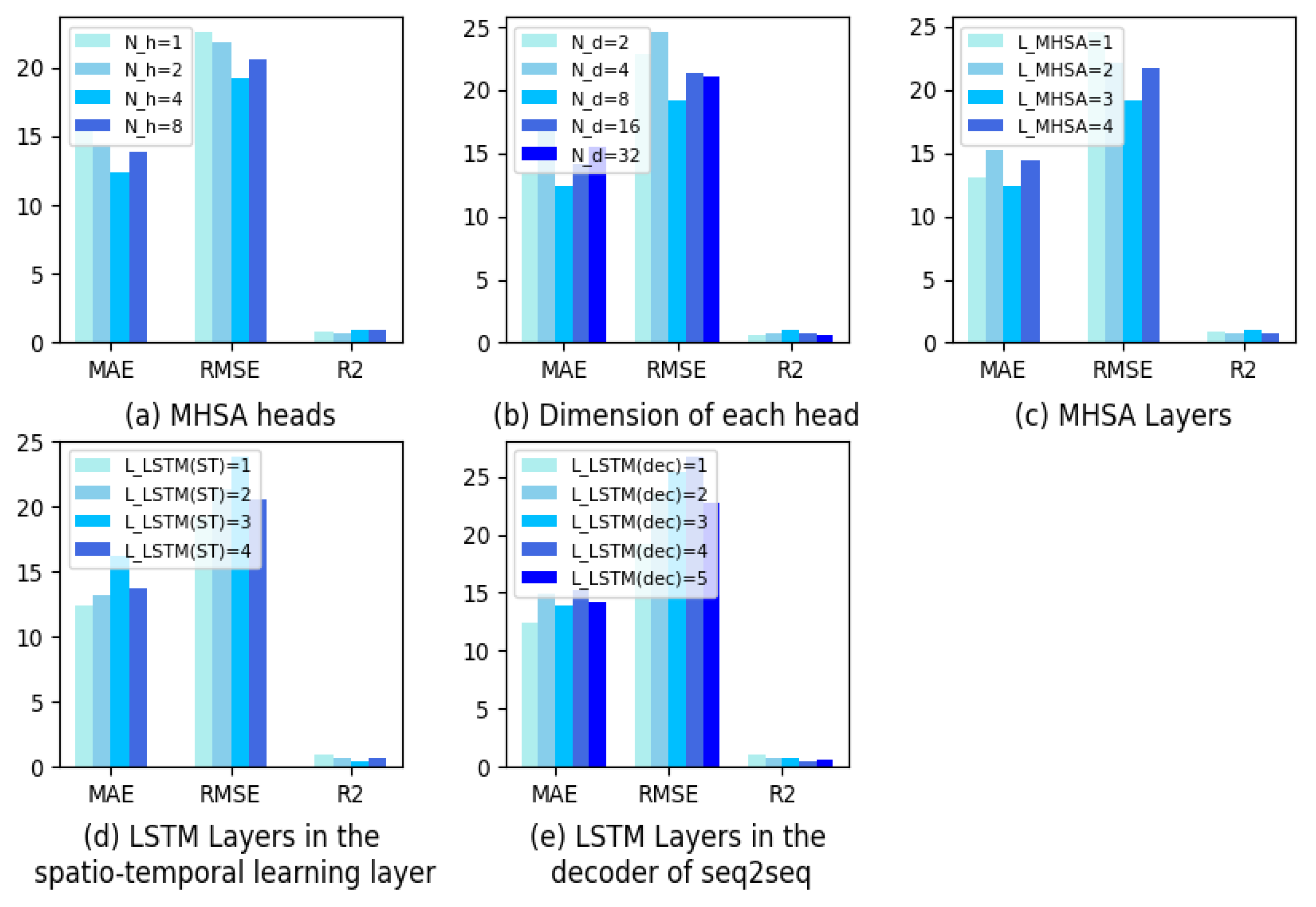
4.2.3. Effect of Hyperparameters
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN-LSTM | Convolutional Neural Network and Long Short-Term Memory |
| ECS | Edge Computing Server |
| ESTNet | External Spatio-Temporal Network |
| FedDeep | Federated Deep Learning Network |
| GAT-LSTM | Graph Attention Network and Long Short-Term Memory |
| GPUM | GPU memory |
| HA | Historical Average |
| MAE | Mean Absolute Error |
| MHSA | Multi-Head Self Attention |
| RMSE | Root Mean Squared Error |
| Coefficient of determination | |
| SVR | Support Vector Regression |
| TT | Training Time |
References
- Zhang, B.; Rong, Y.; Yong, R.; Qin, D.; Li, M.; Zou, G.; Pan, J. Deep learning for air pollutant concentration prediction: A review. Atmos. Environ. 2022, 119347. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, T.; Yang, B.; Zhang, X.S.; Qu, K. Many-objective optimal power dispatch strategy incorporating temporal and spatial distribution control of multiple air pollutants. IEEE Trans. Ind. Inform. 2019, 15, 5309–5319. [Google Scholar] [CrossRef]
- Shaban, K.B.; Kadri, A.; Rezk, E. Urban air pollution monitoring system with forecasting models. IEEE Sens. J. 2016, 16, 2598–2606. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef]
- Bekkar, A.; Hssina, B.; Douzi, S.; Douzi, K. Air-pollution prediction in smart city, deep learning approach. J. Big Data 2021, 8, 161. [Google Scholar] [CrossRef] [PubMed]
- Du, S.; Li, T.; Yang, Y.; Horng, S.J. Deep air quality forecasting using hybrid deep learning framework. IEEE Trans. Knowl. Data Eng. 2019, 33, 2412–2424. [Google Scholar] [CrossRef]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar]
- Puthal, D.; Sahoo, B.P.; Mishra, S.; Swain, S. Cloud computing features, issues, and challenges: A big picture. In Proceedings of the 2015 International Conference on Computational Intelligence and Networks, Odisha, India, 12–13 January 2015; pp. 116–123. [Google Scholar]
- Singh, A.; Chatterjee, K. Cloud security issues and challenges: A survey. J. Netw. Comput. Appl. 2017, 79, 88–115. [Google Scholar] [CrossRef]
- Bai, Y.; Zeng, B.; Li, C.; Zhang, J. An ensemble long short-term memory neural network for hourly PM2.5 concentration forecasting. Chemosphere 2019, 222, 286–294. [Google Scholar] [CrossRef]
- Hrdličková, Z.; Michálek, J.; Kolář, M.; Veselỳ, V. Identification of factors affecting air pollution by dust aerosol PM10 in Brno City, Czech Republic. Atmos. Environ. 2008, 42, 8661–8673. [Google Scholar] [CrossRef]
- Dickson, R. Meteorological factors affecting particulate air pollution of a city. Bull. Am. Meteorol. Soc. 1961, 42, 556–560. [Google Scholar] [CrossRef]
- Xue, T.; Zheng, Y.; Geng, G.; Zheng, B.; Jiang, X.; Zhang, Q.; He, K. Fusing observational, satellite remote sensing and air quality model simulated data to estimate spatiotemporal variations of PM2. 5 exposure in China. Remote Sens. 2017, 9, 221. [Google Scholar] [CrossRef]
- Han, J.; Liu, H.; Xiong, H.; Yang, J. Semi-supervised air quality forecasting via self-supervised hierarchical graph neural network. IEEE Trans. Knowl. Data Eng. 2022, 35, 5230–5243. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Chen, J.; Wang, Q. Air pollution concentration forecasting based on wavelet transform and combined weighting forecasting model. Atmos. Pollut. Res. 2021, 12, 101144. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Wu, R.; Cen, Y. Spatio-temporal fusion of meteorological factors for multi-site PM2. 5 prediction: A deep learning and time-variant graph approach. Environ. Res. 2023, 239, 117286. [Google Scholar] [CrossRef]
- Pan, J.; McElhannon, J. Future edge cloud and edge computing for internet of things applications. IEEE Internet Things J. 2017, 5, 439–449. [Google Scholar] [CrossRef]
- Ni, X.; Huang, H.; Du, W. Relevance analysis and short-term prediction of PM2. 5 concentrations in Beijing based on multi-source data. Atmos. Environ. 2017, 150, 146–161. [Google Scholar] [CrossRef]
- Wang, P.; Wang, P.; Chen, K.; Du, J.; Zhang, H. Ground-level ozone simulation using ensemble WRF/Chem predictions over the Southeast United States. Chemosphere 2022, 287, 132428. [Google Scholar] [CrossRef]
- Gourav.; Rekhi, J.K.; Nagrath, P.; Jain, R. Forecasting air quality of Delhi using ARIMA model. In Advances in Data Sciences, Security and Applications: Proceedings of ICDSSA 2019; Springer: Singapore, 2020; pp. 315–325. [Google Scholar]
- Liu, H.; Li, Q.; Yu, D.; Gu, Y. Air quality index and air pollutant concentration prediction based on machine learning algorithms. Appl. Sci. 2019, 9, 4069. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhao, J.; Deng, F.; Cai, Y.; Chen, J. Long short-term memory-Fully connected (LSTM-FC) neural network for PM2. 5 concentration prediction. Chemosphere 2019, 220, 486–492. [Google Scholar] [CrossRef]
- Sayeed, A.; Choi, Y.; Eslami, E.; Lops, Y.; Roy, A.; Jung, J. Using a deep convolutional neural network to predict 2017 ozone concentrations, 24 h in advance. Neural Netw. 2020, 121, 396–408. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Dong, H.; Teng, X.; Li, X.; Wang, X. Correlational graph attention-based Long Short-Term Memory network for multivariate time series prediction. Appl. Soft Comput. 2021, 106, 107377. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Nguyen, D.V.; Zettsu, K. Spatially-distributed federated learning of convolutional recurrent neural networks for air pollution prediction. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 3601–3608. [Google Scholar]
- Velentzas, P.; Vassilakopoulos, M.; Corral, A. GPU-aided edge computing for processing the k nearest-neighbor query on SSD-resident data. Internet Things 2021, 15, 100428. [Google Scholar] [CrossRef]
- Ghimire, B.; Rawat, D.B. Recent advances on federated learning for cybersecurity and cybersecurity for federated learning for internet of things. IEEE Internet Things J. 2022, 9, 8229–8249. [Google Scholar] [CrossRef]
- Ma, J.; Yu, Z.; Qu, Y.; Xu, J.; Cao, Y. Application of the XGBoost machine learning method in PM2. 5 prediction: A case study of Shanghai. Aerosol Air Qual. Res. 2020, 20, 128–138. [Google Scholar] [CrossRef]
- Lian, M.; Liu, J. Single Pollutant Prediction Approach by Fusing MLSTM and CNN. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Singapore, 6–8 August 2022; pp. 129–140. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Zheng, H.; Xu, Z.; Wang, Q.; Ding, Z.; Zhou, L.; Xu, Y.; Su, H.; Li, X.; Zhang, F.; Cheng, J. Long-term exposure to ambient air pollution and obesity in school-aged children and adolescents in Jiangsu province of China. Environ. Res. 2021, 195, 110804. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhao, Y.; Mao, P.; Zhang, Q.; Zhang, J.; Qiu, L.; Yang, Y. Development of a high-resolution emission inventory and its evaluation and application through air quality modeling for Jiangsu Province, China. Atmos. Chem. Phys. 2017, 17, 211–233. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Urban Region | The Number of Sites | The Variables of Air Pollution | The Variables of External Factor |
|---|---|---|---|
| Nanjing | 13 | weather conditions, temperature, and wind speed | |
| Suzhou | 24 | ||
| Wuxi | 16 | ||
| Changzhou | 13 | ||
| Zhenjiang | 8 | ||
| Nantong | 9 | ||
| Taizhou | 7 | ||
| Yangzhou | 6 | ||
| Yancheng | 7 | ||
| Huaian | 6 | ||
| Suqian | 5 | ||
| Xuzhou | 10 | ||
| Lian yungang | 9 |
| Each local ESTNet | The number of heads in MHSA | |
| The dimensions of each head | ||
| The MHSA layers | ||
| LSTM layers in the spatio-temporal learning layer | ||
| LSTM layers in the decoder of seq2seq | ||
| The Global ESTNet | The number of heads in MHSA | |
| The dimensions of each head | ||
| The MHSA layers | ||
| LSTM layers in the spatio-temporal learning layer | ||
| LSTM layers in the decoder of seq2seq | ||
| 32 | ||
| Historical timesteps | ||
| Prediction timesteps | ||
| The Central Cloud | 1 A100 card | |
| ECS | 13 Nvidia 3090 Ti GPU cards | |
| Batchsize | 32 | |
| Learning rate | 0.0001 | |
| Epochs | 64 | |
| Optimizer | Stochastic Gradient Descent | |
| Model | MAE | RMSE | R2 | TT | GPUM |
|---|---|---|---|---|---|
| HA | 23.19 | 36.57 | 0.869 | 24.87 min | - |
| SVR | 22.75 | 32.36 | 0.878 | 25.76 min | - |
| LSTM | 17.66 | 26.34 | 0.904 | 43.55 min | 1.53 GB |
| CNN-LSTM | 15.64 | 24.90 | 0.913 | 54.19 min | 2.45 GB |
| GAT-LSTM | 13.13 | 21.82 | 0.945 | 67.20 min | 3.27 GB |
| FedDeep (w/o) | 12.43 | 19.32 | 0.973 | 65.28 min | 3.12 GB |
| FedDeep | 12.38 | 19.19 | 0.972 | 28.32 min | 0.87 GB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Cao, N.; Guo, W.; Chen, M.; Rong, Y.; Lu, H. FedDeep: A Federated Deep Learning Network for Edge Assisted Multi-Urban PM2.5 Forecasting. Appl. Sci. 2024, 14, 1979. https://doi.org/10.3390/app14051979
Hu Y, Cao N, Guo W, Chen M, Rong Y, Lu H. FedDeep: A Federated Deep Learning Network for Edge Assisted Multi-Urban PM2.5 Forecasting. Applied Sciences. 2024; 14(5):1979. https://doi.org/10.3390/app14051979
Chicago/Turabian StyleHu, Yue, Ning Cao, Wangyong Guo, Meng Chen, Yi Rong, and Hao Lu. 2024. "FedDeep: A Federated Deep Learning Network for Edge Assisted Multi-Urban PM2.5 Forecasting" Applied Sciences 14, no. 5: 1979. https://doi.org/10.3390/app14051979