
MSIE-Net: Associative Entity-Based Multi-Stage Network for Structured Information Extraction from Reports

Abstract
:1. Introduction
- We introduce MSIE-Net for structured information extraction from MERs. Experiments have shown its superior ability to provide more complete information and more structurally organized output compared to existing methods for extracting examination report information.
- We propose an attention refinement module that augments traditional self-attention mechanisms. The module uses information from previously parsed regions to adjust the attention score of the current input, focusing on yet unparsed regions and, thus, enhancing the model’s contextual comprehension.
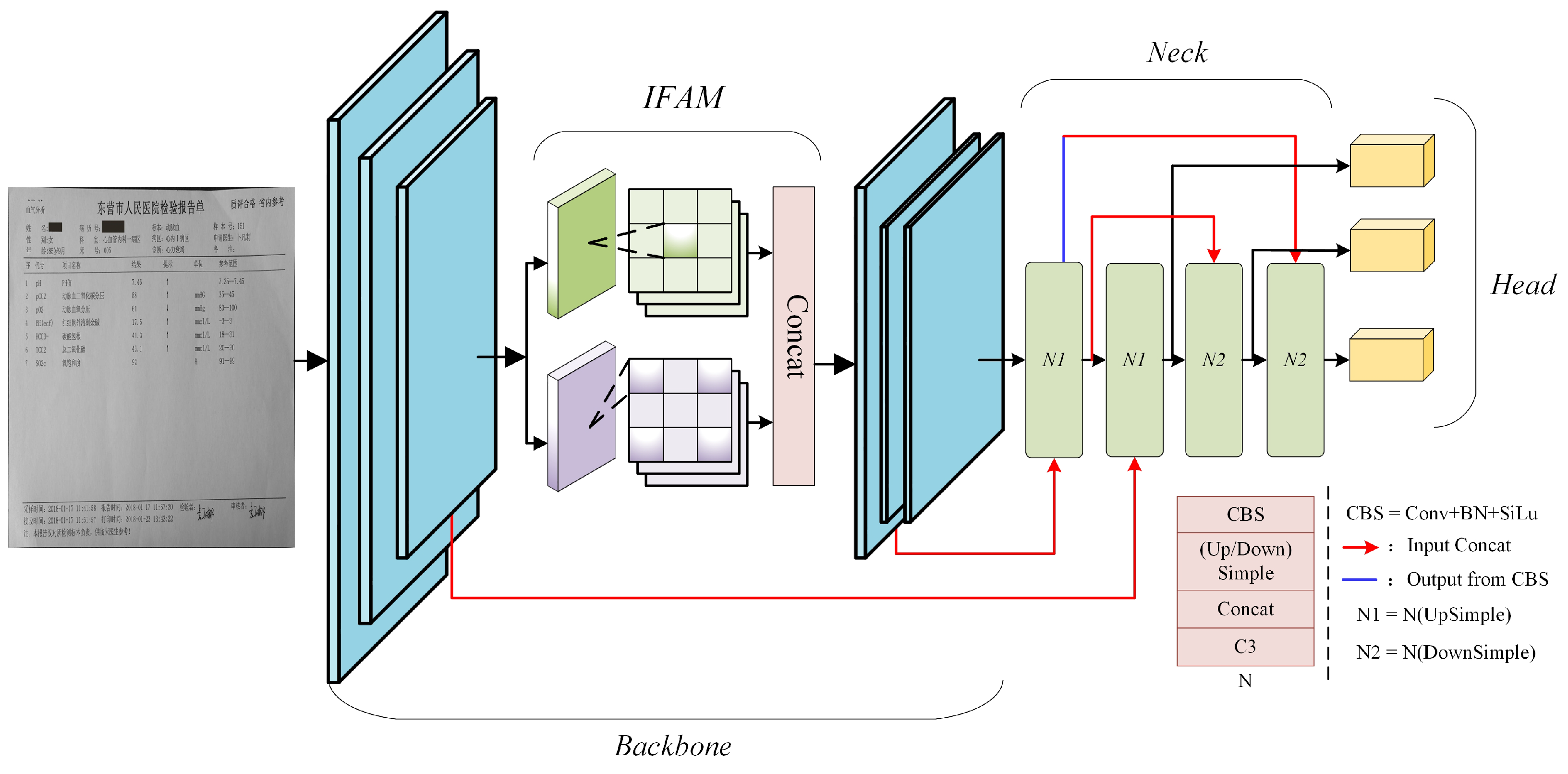
- We introduce the intra-layer feature adjustment module (IFAM), designed for detecting MER-associated entities, to fuse global and local features. This addresses prevalent issues like omitted rows and inaccurate edge demarcation.
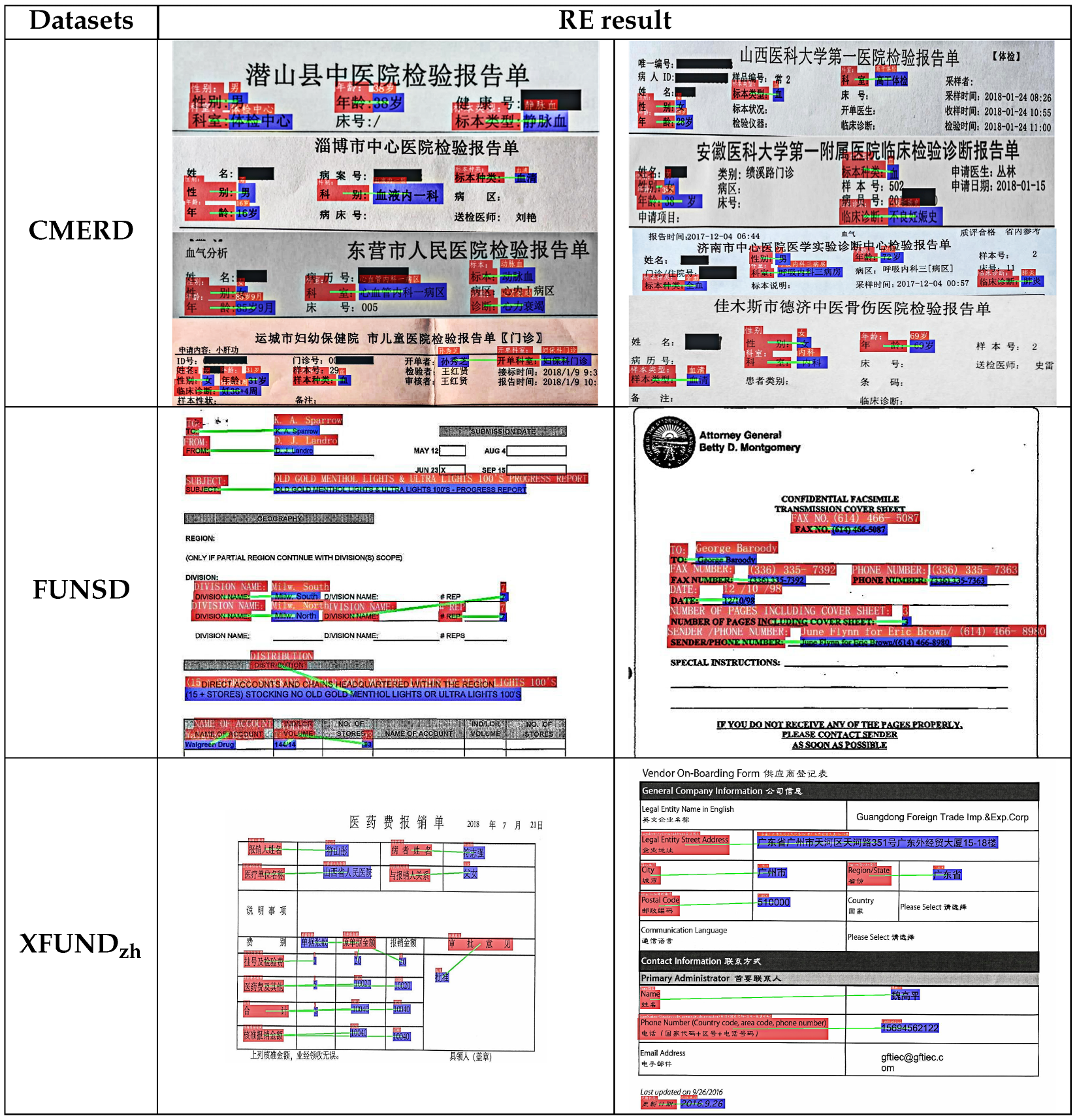
- For the CMERD images constructed in this study, we devised an exhaustive annotation scheme. Apart from the pixel location, the annotation of the dataset includes the content and entity class of the text, the entity class relationship of the “Header”, and the position of the smallest bounding rectangle of all entities in each row of the “Body”.
2. Related Work
2.1. Key Information Extraction
2.1.1. Traditional Key Information Extraction Methods
2.1.2. Modern Key Information Extraction Methods
2.2. Object Detection
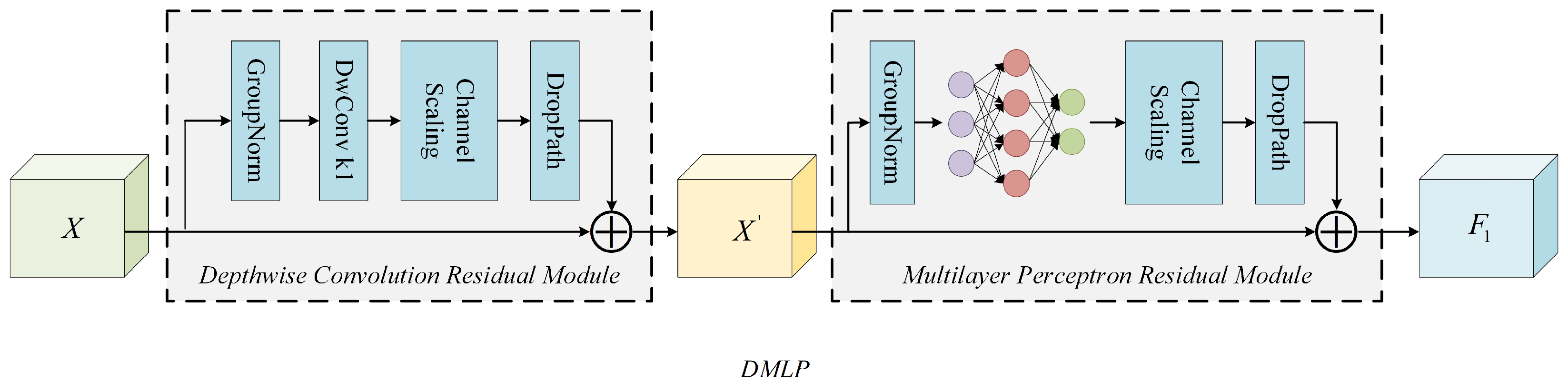
2.2.1. MLP in Object Detection
2.2.2. Learnable Residual Encoding
3. Method
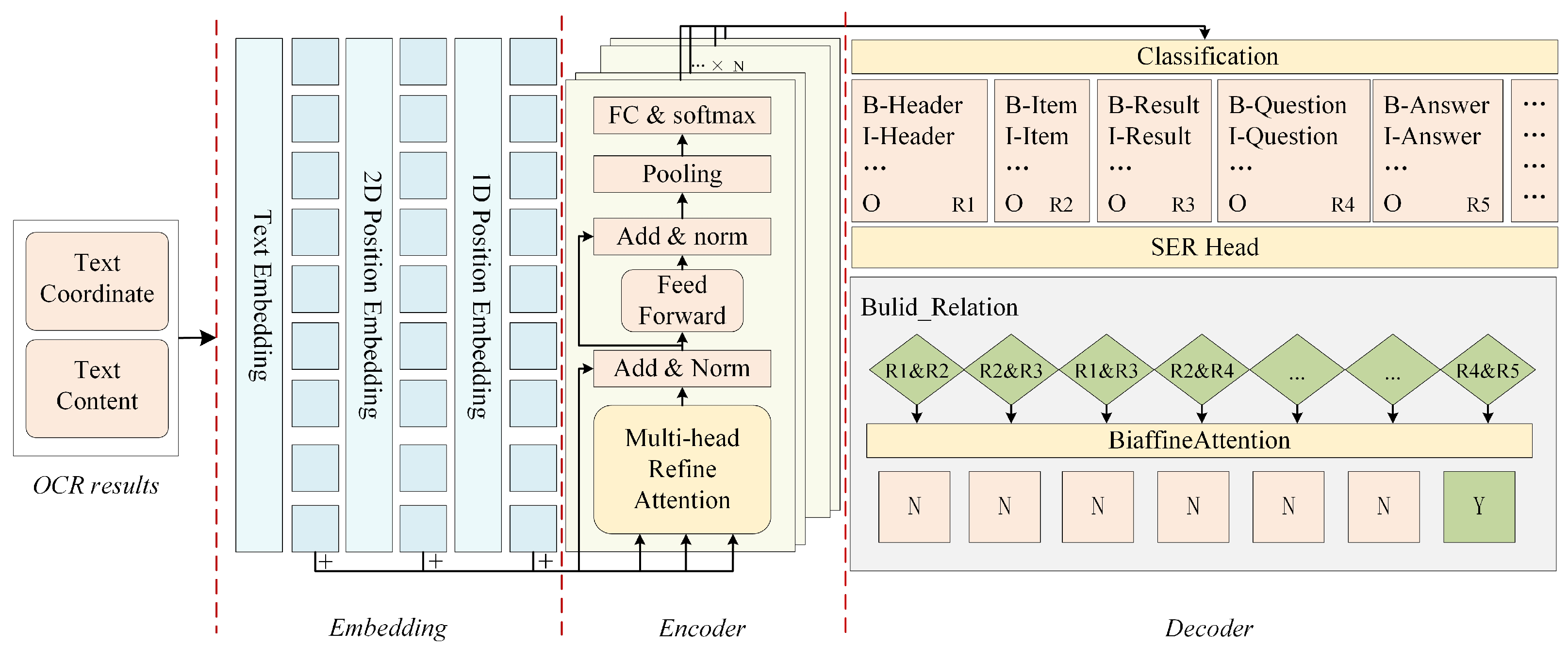
3.1. Key Information Extraction
3.1.1. Multimodal Information Embedding
3.1.2. Multimodal Encoder with Attention Refinement
3.1.3. Decoder
3.2. Associated Entity Detection
3.3. Structured Post-Processing
4. Experiments and Analyses
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Result and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hong, T.P.; Chen, W.C.; Wu, C.H.; Xiao, B.W.; Chiang, B.Y.; Shen, Z.X. Information Extraction and Analysis on Certificates and Medical Receipts. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 7–9 January 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Krieger, F.; Drews, P.; Funk, B.; Wobbe, T. Information extraction from invoices: A graph neural network approach for datasets with high layout variety. In Proceedings of the Innovation Through Information Systems: Volume II: A Collection of Latest Research on Technology Issues, Duisburg, Germany, 9–11 March 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 5–20. [Google Scholar]
- Wan, H.; Zhong, Z.; Li, T.; Zhang, H.; Sun, J. Contextual transformer sequence-based recognition network for medical examination reports. Appl. Intell. 2023, 53, 17363–17380. [Google Scholar] [CrossRef]
- Cheng, Z.; Bai, F.; Xu, Y.; Zheng, G.; Pu, S.; Zhou, S. Focusing Attention: Towards Accurate Text Recognition in Natural Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5086–5094. [Google Scholar] [CrossRef]
- Ye, J.; Qi, X.; He, Y.; Chen, Y.; Gu, D.; Gao, P.; Xiao, R. PingAn-VCGroup’s Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML. arXiv 2021, arXiv:2105.01848. [Google Scholar]
- Guarasci, R.; Damiano, E.; Minutolo, A.; Esposito, M.; Pietro, G.D. Lexicon-Grammar based open information extraction from natural language sentences in Italian. Expert Syst. Appl. 2020, 143, 112954. [Google Scholar] [CrossRef]
- Jaume, G.; Kemal Ekenel, H.; Thiran, J.P. FUNSD: A Dataset for Form Understanding in Noisy Scanned Documents. In Proceedings of the 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), Sydney, Australia, 22–25 September 2019; Volume 2, pp. 1–6. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Knight, K., Nenkova, A., Rambow, O., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 260–270. [Google Scholar] [CrossRef]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention Is All You Need In Speech Separation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 21–25. [Google Scholar] [CrossRef]
- Katti, A.R.; Reisswig, C.; Guder, C.; Brarda, S.; Bickel, S.; Höhne, J.; Faddoul, J.B. Chargrid: Towards Understanding 2D Documents. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 4459–4469. [Google Scholar] [CrossRef]
- Liu, X.; Gao, F.; Zhang, Q.; Zhao, H. Graph Convolution for Multimodal Information Extraction from Visually Rich Documents. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Industry Papers), Minneapolis, MN, USA, 2–7 June 2019; Loukina, A., Morales, M., Kumar, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 32–39. [Google Scholar] [CrossRef]
- Xu, Y.; Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M. LayoutLM: Pre-training of Text and Layout for Document Image Understanding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Online, 6–10 July 2020. [Google Scholar]
- Zhang, P.; Xu, Y.; Cheng, Z.; Pu, S.; Lu, J.; Qiao, L.; Niu, Y.; Wu, F. TRIE: End-to-End Text Reading and Information Extraction for Document Understanding. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1413–1422. [Google Scholar] [CrossRef]
- Liao, M.; Zou, Z.; Wan, Z.; Yao, C.; Bai, X. Real-Time Scene Text Detection With Differentiable Binarization and Adaptive Scale Fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 919–931. [Google Scholar] [CrossRef] [PubMed]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Rusiñol, M.; Benkhelfallah, T.; dAndecy, V.P. Field Extraction from Administrative Documents by Incremental Structural Templates. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1100–1104. [Google Scholar] [CrossRef]
- Jiang, Z.; Huang, Z.; Lian, Y.; Guo, J.; Qiu, W. Integrating Coordinates with Context for Information Extraction in Document Images. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, Australia, 20–25 September 2019; pp. 363–368. [Google Scholar] [CrossRef]
- Hwang, W.; Kim, S.; Seo, M.; Yim, J.; Park, S.; Park, S.; Lee, J.; Lee, B.; Lee, H. Post-OCR parsing: Building simple and robust parser via BIO tagging. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Zhang, Z.; Ma, J.; Du, J.; Wang, L.; Zhang, J. Multimodal Pre-Training Based on Graph Attention Network for Document Understanding. IEEE Trans. Multimed. 2023, 25, 6743–6755. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Hong, T.; Kim, D.; Ji, M.; Hwang, W.; Nam, D.; Park, S. BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Xu, Y.; Xu, Y.; Lv, T.; Cui, L.; Wei, F.; Wang, G.; Lu, Y.; Florencio, D.; Zhang, C.; Che, W.; et al. LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 2–5 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2579–2591. [Google Scholar] [CrossRef]
- Xu, Y.; Lv, T.; Cui, L.; Wang, G.; Lu, Y.; Florêncio, D.A.F.; Zhang, C.; Wei, F. LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding. arXiv 2021, arXiv:2104.08836. [Google Scholar]
- Huang, Y.; Lv, T.; Cui, L.; Lu, Y.; Wei, F. LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 4083–4091. [Google Scholar] [CrossRef]
- Li, Y.; Qian, Y.; Yu, Y.; Qin, X.; Zhang, C.; Liu, Y.; Yao, K.; Han, J.; Liu, J.; Ding, E. StrucTexT: Structured Text Understanding with Multi-Modal Transformers. In Proceedings of the 29th ACM International Conference on Multimedia, Online, 20–24 October 2021; pp. 1912–1920. [Google Scholar] [CrossRef]
- Yu, Y.; Li, Y.; Zhang, C.; Zhang, X.; Guo, Z.; Qin, X.; Yao, K.; Han, J.; Ding, E.; Wang, J. StrucTexTv2: Masked Visual-Textual Prediction for Document Image Pre-training. arXiv 2023, arXiv:2303.00289. [Google Scholar]
- Chi, Z.; Dong, L.; Wei, F.; Yang, N.; Singhal, S.; Wang, W.; Song, X.; Mao, X.L.; Huang, H.; Zhou, M. InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tur, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3576–3588. [Google Scholar] [CrossRef]
- Gu, Z.; Meng, C.; Wang, K.; Lan, J.; Wang, W.; Gu, M.; Zhang, L. XYLayoutLM: Towards Layout-Aware Multimodal Networks For Visually-Rich Document Understanding. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4573–4582. [Google Scholar] [CrossRef]
- Li, C.; Guo, R.; Zhou, J.; An, M.; Du, Y.; Zhu, L.; Liu, Y.; Hu, X.; Yu, D. PP-StructureV2: A Stronger Document Analysis System. arXiv 2022, arXiv:2210.05391. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2015. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13024–13033. [Google Scholar] [CrossRef]
- Glenn Jocher. ultralytics/yolov5. 2021. Available online: https://github.com/ultralytics/yolov5/releases (accessed on 1 December 2023).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Rosenblatt, F. Principles of neurodynamics. Perceptrons and the theory of brain mechanisms. Am. J. Psychol. 1963, 76, 705. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized Feature Pyramid for Object Detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [CrossRef] [PubMed]
- Arandjelovic, R.; Zisserman, A. All About VLAD. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1578–1585. [Google Scholar] [CrossRef]
- Perronnin, F.; Dance, C. Fisher Kernels on Visual Vocabularies for Image Categorization. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, H.; Xue, J.; Dana, K. Deep TEN: Texture Encoding Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2896–2905. [Google Scholar] [CrossRef]
- Zhang, R.; Kikui, G.; Sumita, E. Subword-based Tagging by Conditional Random Fields for Chinese Word Segmentation. In Proceedings of the Human Language Technology Conference of the NAACL, Companion Volume: Short Papers, New York, NY, USA, 4–9 June 2006; Moore, R.C., Bilmes, J., Chu-Carroll, J., Sanderson, M., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 193–196. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8440–8451. [Google Scholar] [CrossRef]
- Wang, J.; Jin, L.; Ding, K. LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 7747–7757. [Google Scholar] [CrossRef]
- Zhang, Y.; Bo, Z.; Wang, R.; Cao, J.; Li, C.; Bao, Z. Entity Relation Extraction as Dependency Parsing in Visually Rich Documents. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M.F., Huang, X., Specia, L., Yih, S.W.t., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2759–2768. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language | Split | Header | Question | Answer | Other | Total |
|---|---|---|---|---|---|---|
| ZH | training set | 229 | 3692 | 4641 | 1666 | 10,228 |
| test set | 58 | 1253 | 1732 | 586 | 3629 | |
| JA | training set | 150 | 2397 | 3836 | 2640 | 9005 |
| test set | 58 | 726 | 1280 | 1332 | 3383 | |
| ES | training set | 253 | 3013 | 4254 | 3929 | 11,449 |
| test set | 90 | 909 | 1218 | 1196 | 3413 | |
| FR | training set | 183 | 2497 | 3427 | 2709 | 8816 |
| test set | 666 | 1023 | 1281 | 1131 | 3501 | |
| IT | training set | 166 | 3762 | 4932 | 3355 | 12,215 |
| test set | 65 | 1230 | 1599 | 1135 | 4029 | |
| DE | training set | 155 | 2609 | 3992 | 1876 | 8632 |
| test set | 59 | 858 | 1322 | 650 | 2889 | |
| PT | training set | 185 | 3510 | 5428 | 2531 | 11,654 |
| test set | 59 | 1288 | 1940 | 882 | 4196 |
| Task | Model | Modality | F1 (%) | P (%) | R (%) |
|---|---|---|---|---|---|
| SER | LayoutLM [12] | Text + Layout | 95.41 | 95.61 | 95.22 |
| LayoutLMv2 [22] | Text + Layout + Image | 96.73 | 96.64 | 96.84 | |
| LayoutXLM [23] | Text* + Layout + Image | 96.74 | 96.31 | 97.18 | |
| VI-LayoutXLM [29] | Text* + Layout | 97.08 | 96.75 | 97.41 | |
| RVI-LayoutXLM (Ours) | Text* + Layout | 97.38 | 97.01 | 97.76 | |
| RE | LayoutLMv2 [22] | Text + Layout + Image | 89.02 | 85.73 | 92.58 |
| LayoutXLM [23] | Text* + Layout + Image | 93.22 | 93.97 | 92.49 | |
| VI-LayoutXLM [29] | Text* + Layout | 95.22 | 95.40 | 95.04 | |
| RVI-LayoutXLM (Ours) | Text* + Layout | 95.77 | 95.75 | 95.80 |
| Task | Model | F1 (%) | P (%) | R (%) |
|---|---|---|---|---|
| SER | RVI-LayoutXLM | 97.38 | 97.01 | 97.76 |
| RVI-LayoutXLM + Image | 96.05 | 96.54 | 97.35 | |
| RVI-LayoutXLM + Image + Focal Loss | 96.64 | 97.04 | 97.56 | |
| RVI-LayoutXLM + Focal Loss | 97.62 | 97.03 | 98.22 | |
| RE | RVI-LayoutXLM | 95.27 | 95.75 | 95.80 |
| RVI-LayoutXLM + Image | 94.51 | 94.27 | 94.75 |
| Task | Model | Modality | FUNSD (F1%) | XFUNDzh (F1%) |
|---|---|---|---|---|
| SER | BERT [20] | Text | 60.26 | - |
| LayoutLM [12] | Text + Layout | 79.27 | - | |
| XLM-RoBERTa [49] | Text* | 66.70 | 87.74 | |
| InfoXLM [27] | Text* | 68.52 | 88.68 | |
| BROS [21] | Text + Layout | 83.05 | - | |
| LiLT [50] | Text* + Layout | 88.41 | 89.38 | |
| StrucTexT [25] | Text + Layout + Image | 83.09 | - | |
| LayoutLMv2 [22] | Text + Layout + Image | 82.76 | 85.44 | |
| LayoutXLM [23] | Text* + Layout + Image | 89.50 | 89.24 | |
| XYLayoutLM [28] | Text + Layout + Image | 83.35 | 91.76 | |
| VI-LayoutXLM [29] | Text* + Layout | 87.79 | 90.46 | |
| RVI-LayoutXLM (Ours) | Text* + Layout | 89.57 | 91.92 | |
| RE | BERT [20] | Text | 27.65 | - |
| LayoutLM [12] | Text + Layout | 45.86 | - | |
| XLM-RoBERTa [49] | Text* | 26.59 | 51.05 | |
| InfoXLM [27] | Text* | 29.20 | 52.14 | |
| SERA [51] | Text + Layout | 65.96 | - | |
| BROS [21] | Text + Layout | 71.46 | - | |
| LiLT [50] | Text* + Layout | 62.76 | 72.97 | |
| LayoutLMv2 [22] | Text + Layout + Image | 42.91 | 67.77 | |
| LayoutXLM [23] | Text* + Layout + Image | 54.83 | 70.73 | |
| XYLayoutLM [28] | Text + Layout + Image | - | 74.45 | |
| VI-LayoutXLM [29] | Text* + Layout | 74.87 | 83.92 | |
| RVI-LayoutXLM (Ours) | Text* + Layout | 76.35 | 85.01 |
| Model | Backbone | mAP@.5 | mAP@.5-.95 | mAP@.75 |
|---|---|---|---|---|
| Faster-RCNN [32] | Swim | 97.31% | 70.82% | 77.62% |
| YOLOv3 [34] | Darknet-53 | 87.30% | 60.87% | 68.43% |
| YOLOv4 [35] | CSPDarknet-53 | 87.64% | 65.19% | 70.52% |
| YOLOv5-s [36] | CSPDarknet-53 | 92.35% | 67.94% | 73.28% |
| YOLOX-s [37] | CSPDarknet | 96.21% | 72.23% | 78.94% |
| PPYOLOE-s [38] | CSPResnet | 95.21% | 63.07% | 75.93% |
| RIFD-Net (Ours) | CSPDarknet + IFAM | 98.26% | 74.00% | 81.10% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Sheng, H.; Sheng, M.; Wan, H. MSIE-Net: Associative Entity-Based Multi-Stage Network for Structured Information Extraction from Reports. Appl. Sci. 2024, 14, 1668. https://doi.org/10.3390/app14041668
Li Q, Sheng H, Sheng M, Wan H. MSIE-Net: Associative Entity-Based Multi-Stage Network for Structured Information Extraction from Reports. Applied Sciences. 2024; 14(4):1668. https://doi.org/10.3390/app14041668
Chicago/Turabian StyleLi, Qiuyue, Hao Sheng, Mingxue Sheng, and Honglin Wan. 2024. "MSIE-Net: Associative Entity-Based Multi-Stage Network for Structured Information Extraction from Reports" Applied Sciences 14, no. 4: 1668. https://doi.org/10.3390/app14041668