
Data Placement Using a Classifier for SLC/QLC Hybrid SSDs


1
Department of Computer Engineering, Kwangwoon University, Seoul 01897, Republic of Korea
2
School of Computer and Information Engineering, Kwangwoon University, Seoul 01897, Republic of Korea
*
Author to whom correspondence should be addressed.
Appl. Sci. 2024, 14(4), 1648; https://doi.org/10.3390/app14041648
Submission received: 19 January 2024
/
Revised: 7 February 2024
/
Accepted: 14 February 2024
/
Published: 18 February 2024
(This article belongs to the Special Issue Resource Management for Emerging Computing Systems)
Abstract
:In hybrid SSDs (solid-state drives) consisting of SLC (single-level cell) and QLC (quad-level cell), efficiently using the limited SLC cache space is crucial. In this paper, we present a practical data placement scheme, which determines the placement location of incoming write requests using a lightweight machine-learning model. It leverages information about I/O workload characteristics and SSD status to identify cold data that does not need to be stored in the SLC cache with high accuracy. By strategically bypassing the SLC cache for cold data, our scheme significantly reduces unnecessary data movements between the SLC and QLC regions, improving the overall efficiency of the SSD. Through simulation-based studies using real-world workloads, we demonstrate that our scheme outperforms existing approaches by up to 44%.
1. Introduction
Modern Solid-State Drives (SSDs) are increasingly adopting Quad-Level Cell (QLC) flash memory, a technology that allows for the storage of four bits of data in a single cell, as their primary storage medium to significantly enhance storage capacity [1,2,3,4]. Although this advancement offers a substantial price advantage over SSDs utilizing Single-Level Cell (SLC), Multi-Level Cell (MLC), or Triple-Level Cell (TLC) technologies, QLC SSDs often face limitations in terms of I/O performance and lifespan, a comparison of which is detailed in Table 1 [5]. To mitigate these drawbacks, recent innovations in SSD technology have led to the exploration of hybrid SSD architectures. These architectures strategically program certain blocks of QLC memory to operate in SLC mode, which involves storing just one bit per cell, therefore harnessing the high-speed advantages of SLC memory [6,7,8]. In these hybrid designs, the SLC region is commonly utilized as a cache layer for the remaining QLC blocks, enhancing the overall efficiency and performance of the storage device [9,10,11].
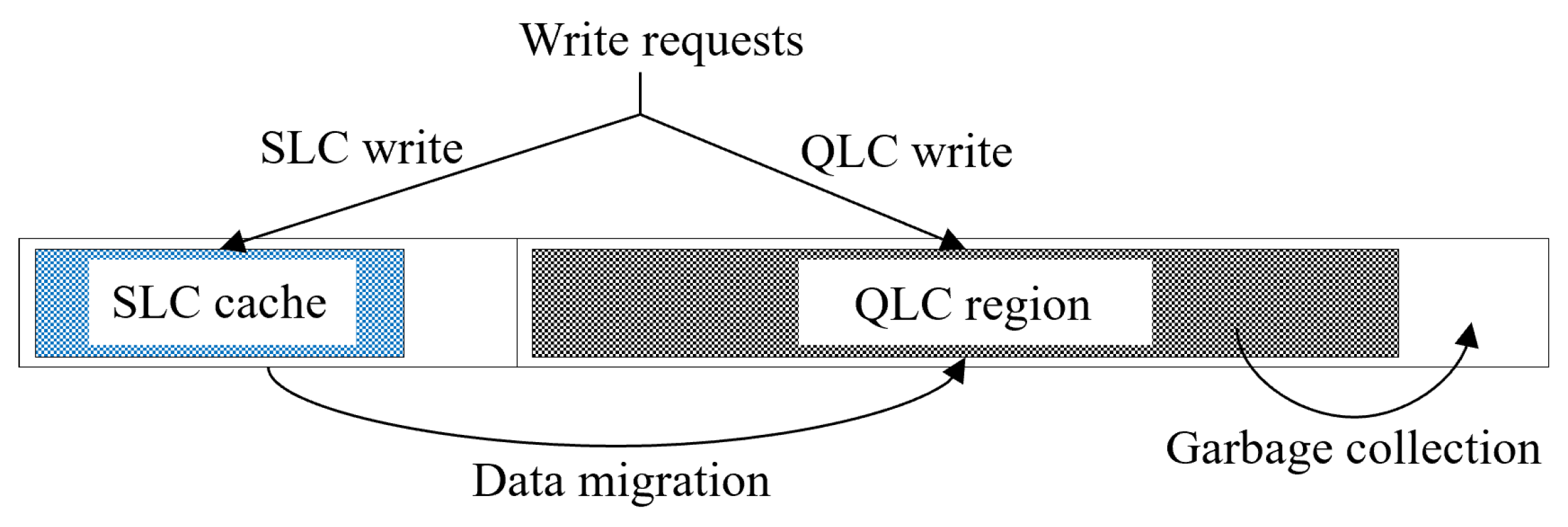
In the context of hybrid SSD architectures, a notable challenge arises due to the inverse relationship between cache size and available data storage space. As the allocated SLC cache size increases, the available space for data storage correspondingly decreases, therefore emphasizing the need for efficient and strategic management of the SLC cache [12,13]. This management becomes particularly critical when the SLC cache reaches its capacity, necessitating the initiation of processes such as garbage collection or the migration of certain data from the SLC cache to the slower QLC region (Figure 1). These processes typically involve employing sophisticated algorithms, and they often result in additional write and erase operations.
A specific challenge within this management process is the handling of cold data, which is data that is not frequently accessed and, therefore, is unlikely to be reused in the short term. When such data occupies space in the SLC cache, it eventually needs to be transferred to the QLC region, an action that, in many cases, proves to be unnecessary if the data are not accessed again [14,15]. To address this inefficiency, a more effective strategy involves the accurate identification of cold data at the outset, followed by its direct storage in the QLC region, bypassing the SLC cache altogether. This approach was explored by Im et al. [7], who classified data as hot or cold based on the size of the I/O requests, with the assumption that smaller-sized I/O requests usually correspond to hot data. Building on these insights, Yoo et al. [16] furthered this field of study by implementing reinforcement learning techniques to determine various parameters in hybrid SSDs, including the optimal size for the SLC cache and the threshold for distinguishing between hot and cold data.
The task of deciding whether to allocate incoming write requests to the SLC cache or to route them directly to the QLC region in hybrid SSDs is both essential and complex. This complexity arises from the dynamic nature of workload characteristics and the fluctuating status of the SSD itself. Despite the intricate nature of this decision-making process, the fundamental goal remains clear: to optimally choose between these two storage options for each write request. Given this challenge, machine learning emerges as a particularly promising approach due to its ability to process and learn from complex and variable data.
In our method, we gather a diverse array of features that influence this decision-making process. These features include workload characteristics such as the frequency of data updates and various aspects of SSD status, like the current space utilization. By integrating these features, we train a binary classifier that is adept at determining the most suitable destination for each incoming write request—be it the SLC cache or the QLC region. To validate the efficacy of our approach, we conducted extensive simulation studies using real-world workload scenarios. These studies provided a rigorous testing ground for our machine-learning-based method, allowing us to compare its performance against other existing strategies. The results demonstrated that our method outperforms other techniques, showing improvements of up to 44% in I/O execution times.
2. Related Work
In the evolving landscape of hybrid SSD architecture, two primary configurations have emerged as dominant: hard partitioning and soft partitioning. Hard partitioning involves the use of physically distinct memory chips such as SLC, MLC, TLC, or QLC within a single hybrid SSD, as detailed by Tripathy et al. [12]. This configuration enables the effective utilization of different types of memory technologies within the same device, each serving specific storage roles based on their performance characteristics.
In the realm of hard-partitioned hybrid SSDs, Kwon et al. [8] implemented an innovative segmentation strategy within the SLC cache. They created separate areas for file system journal data and regular data, aiming to enhance sequential journal writes and, therefore, reduce the overhead associated with garbage collection. During periods of low activity, data are strategically moved from the SLC cache to TLC flash memory. In scenarios where the SLC cache reaches full capacity, normal data bypasses the cache and is written directly to the TLC flash, optimizing space utilization. Furthering this approach, Jung et al. [17] proposed a method that employs multiple SLC chips as a cache layer for MLC flash memory. In this system, a single SLC chip is designated for the storage of both random and sequential data. This chip is utilized until it runs out of free blocks. Upon reaching its maximum capacity, with no available space for additional logs or data blocks, another SLC chip is activated for continued data storage. Yao et al. [9] discussed a different system, where SLC and MLC pages are allocated using two distinct mapping caches, one for hot data and the other for normal data. This system prioritizes the use of SLC pages for hot data that register hits in its dedicated cache while defaulting to MLC pages for other data types.
Chang et al. [18] proposed a unique management technique for SLC-MLC hybrid SSDs. In their approach, hot data are preferentially stored in SLC flash, whereas cold data are directly written to MLC flash. This method employs a K-means algorithm to periodically determine and adjust the threshold for estimating the hotness of data, ensuring optimal data placement. Similarly, Hachiya et al. [19] introduced a cache management technique tailored for MLC-TLC hybrid SSDs. In their system, hot data are retained in MLC flash, and cold data, once identified, are transferred to TLC flash. This methodology reflects an ongoing trend in hybrid SSD technology, where smart data management and strategic cache utilization play crucial roles in enhancing overall storage efficiency and performance.
Soft partitioning presents a contrasting approach within hybrid SSD architecture, characterized by its flexibility in allowing various types of flash memory to emulate SLC-type flash characteristics. This versatility offers a dynamic solution to the rigid physical constraints of hard partitioning. Expanding on this concept, Im et al. [7] put forward a cache management strategy for SLC-MLC hybrid SSDs. Their approach involves classifying data as either hot or cold based on the size of the incoming requests. Hot data, typically smaller in size and more frequently accessed, is allocated to the SLC cache for fast retrieval. In contrast, cold data, which is less likely to be accessed frequently, is directly written to the MLC flash, therefore optimizing the usage of the SLC cache. Crucially, this technique incorporates a dynamic adjustment of the hotness threshold, which is calibrated based on the observed frequency of data migrations to the MLC flash, ensuring efficient cache utilization and data flow.
Yoo et al. [16] introduced another management policy for SLC-QLC hybrid SSDs, utilizing the principles of reinforcement learning. This policy is specifically tailored to distinguish between hot and cold data, directing hot data to the SLC cache while routing cold data straight to the QLC flash. The innovative aspect of this policy lies in its dynamic nature, allowing for continuous modification of both the size of the SLC cache and the threshold that differentiates hot from cold data, adapting in real time to changing data access patterns. Furthering the advancements in soft partitioning, Zhang et al. [20] developed a method tailored for SLC-TLC hybrid SSDs. Their approach focuses on spreading SLC pages across multiple planes to significantly enhance parallelism, therefore reducing latency associated with data migration. This strategy includes a sophisticated policy for allocating these planes, which takes into account not only the availability of SLC pages but also the capabilities for parallel processing. This method represents a strategic balance between enhancing data access speed and optimizing the use of available storage resources, a key consideration in the evolving landscape of hybrid SSD technology.
Most existing research in the realm of hybrid SSDs has predominantly concentrated on the identification and management of hot data for the effective utilization of the SLC cache. In addition to this, several studies have ventured into the application of machine-learning techniques, aiming to ascertain or fine-tune the optimal size of the SLC cache and to establish precise thresholds for evaluating the hotness level of incoming data. These thresholds are crucial in determining which data benefits most from the faster SLC cache and which can be relegated to slower storage.
Our research methodology significantly deviates from traditional approaches, as it does not depend on indirect indicators such as data hotness levels, specific SLC cache sizes, or predetermined threshold values. This means that the mere classification of data as “hot” does not automatically justify its storage in the SLC cache. Our approach is more direct and focused: we aim to precisely evaluate the potential for future reuse of data currently stored in the SLC cache, moving beyond conventional metrics to a more targeted assessment of data value for cache management.
To achieve this objective, we employ machine-learning algorithms capable of analyzing and predicting data reuse patterns. Our approach takes into account the dynamic and ever-changing nature of workload characteristics, as well as the current operational state of the SSD. By doing so, we can make more informed and accurate predictions about which data will be accessed again in the near future. This allows for more efficient use of the SLC cache, as it ensures that only data with a high probability of reuse occupies this valuable space, therefore optimizing the overall performance and lifespan of the hybrid SSD.
3. A Classifier-Based Data Placement
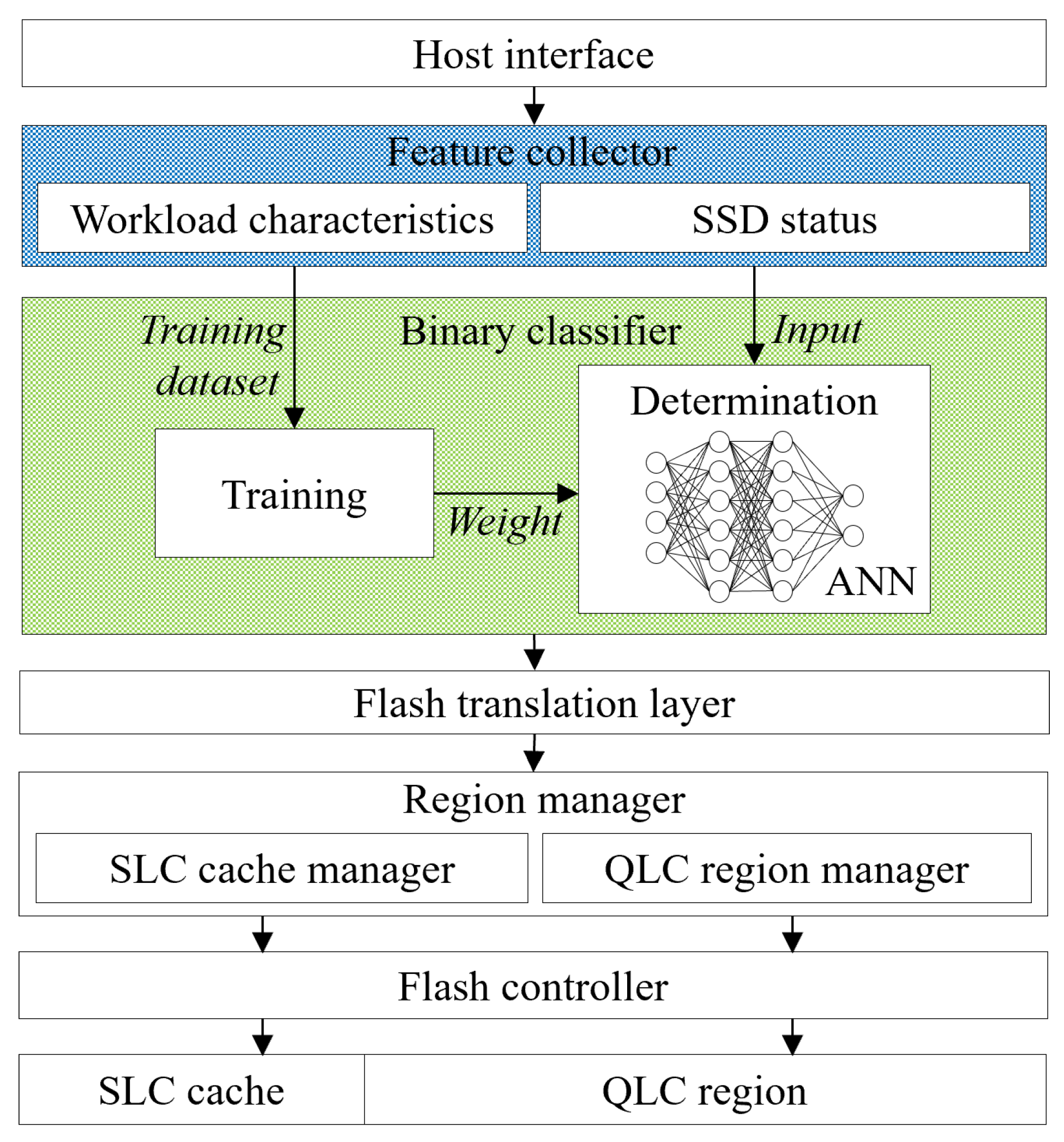
The data placement scheme we propose is illustrated in Figure 2, outlining a systematic process for handling write requests in hybrid SSDs. At the core of this scheme is a feature collector, a crucial component that initiates the process by capturing a range of basic features from each incoming write request. These basic features include essential information like the timestamp, logical block address, size, and type of the request. Going beyond these basic parameters, the feature collector also delves into more nuanced statistical or relational aspects that paint a clearer picture of the I/O workload patterns. It analyzes factors such as the frequency of requests, intervals between requests, and both the average and standard deviation of these intervals and the sizes of I/O requests. This deeper analysis allows the system to recognize and understand the nature of the workload over a given window of time.
Another key aspect of our approach is the tracking of the most recent placement location for each write request, either in the SLC cache or the QLC region. This tracking is based on the understanding that data requests exhibiting similar characteristics often follow comparable access patterns. Such insights are invaluable in predicting future data accesses. In addition to these external features, internal SSD characteristics are also taken into account. These include the total SSD capacity, the ratio of the SLC cache to the QLC region, and the overall space utilization of the SSD. These internal features provide a comprehensive view of the SSD’s operational state, which is critical in making informed data placement decisions.
To ensure the efficacy of our feature set, we employ information gain as a metric to evaluate the relevance and quality of each feature. Through this process, we iteratively refine our feature set, adding only the most valuable features. This iterative process continues until there is no further improvement in classification accuracy. The final, optimized set of features that we derive through this meticulous process is summarized in Table 2.
The training module of our data placement scheme plays a pivotal role in refining the decision-making process. It utilizes the eight carefully gathered features and employs a binary labeling system for the training data, where a ‘1’ represents a cache hit and a ‘0’ denotes a cache miss. These labels are crucial for guiding the training of the model to accurately predict future data access patterns.
At the heart of the training module is an Artificial Neural Network (ANN), a sophisticated machine-learning framework known for its ability to model complex patterns in data. The ANN in our scheme is composed of several layers, each housing multiple neurons. This multi-layered structure of the ANN, along with its ability to apply non-linear activation functions, grants it the capability to identify intricate patterns in data that are not readily apparent or linearly separable [21,22,23]. This feature of ANNs is particularly beneficial for our data placement scheme, as it enables the model to discern the optimal locations for data placement, therefore effectively reducing I/O latency, a critical factor in SSD performance.
Our specific ANN model includes one input layer, two hidden layers, and one output layer designed for binary classification. For the activation function in the input and hidden layers, we use the Rectified Linear Unit (ReLU). ReLU is chosen for its renowned performance benefits and its ability to facilitate fast learning in neural networks [24]. In the output layer, we employ the Sigmoid function, which is well-suited for binary classification tasks due to its ability to map inputs to a binary output effectively. To ensure that the model remains accurate and relevant to current data access patterns, we have implemented a routine for updating the model. The ANN model is refreshed daily during the early hours, a time typically characterized by lower system activity. This regular updating schedule allows the model to adapt to changes in workload characteristics and SSD status, maintaining its high predictive accuracy and ensuring that the data placement decisions it informs are as efficient and timely as possible.
The decision-making core of our data placement scheme is the determination module, which is responsible for assigning the appropriate placement locations for incoming write requests in the hybrid SSD. This module operates based on the outputs of the trained ANN model. It processes the features collected by the feature collector and employs the ANN’s forward propagation mechanism to generate a binary result, indicating whether each write request should be placed in the SLC cache or directly in the QLC region.
In terms of design, our ANN model is meticulously structured to balance efficiency with complexity. Each neuron within the network consists of a weight and a bias, and for storage purposes, each neuron is allocated 16 bytes. The total storage space required for the entire neural network is thus calculated using the formula , where is the number of neurons in the ith layer of the network. To further detail the computational aspect, the number of floating-point operations (specifically, multiplications) needed for the forward propagation process in the network is given by . Our neural network’s architecture comprises 8 input neurons in the input layer. The hidden layers are designed with 32 neurons each, while the output layer contains 2 neurons. Given this configuration, the spatial and computational overheads of implementing our neural network within the SSD’s data management system are minimal. This efficient design ensures that the neural network adds negligible additional burden to the SSD’s operational resources while still providing advanced data placement decision-making capabilities. This balance is crucial, as it allows our scheme to enhance the SSD’s performance and efficiency without compromising its existing functionality or adding significant complexity to its operation.
Based on the outcome of the binary classification from our neural network, each incoming write request in our hybrid SSD system undergoes a series of steps before its final storage destination is determined. Initially, the write request is processed by the flash translation layer that maps logical block addresses to physical flash memory locations. Once the flash translation layer has processed the request, the path of the write request diverges based on the classification result. If the request is classified for the SLC cache (indicating a high likelihood of re-access in the near future), it is then handled by the SLC cache manager. Conversely, if the request is classified for the QLC region (typically indicating less frequent access), it is directed to the QLC region manager.
The SLC cache manager plays a crucial role in optimizing the limited SLC cache space in hybrid SSDs. When the SLC cache is full, it employs a replacement algorithm to transfer data that is unlikely to be accessed again soon from the SLC cache to the QLC region, therefore making space for new requests. The SLC cache can be set up either as a write-only structure or as an integrated structure. In a write-only structure, read requests are served by the SLC cache only if the requested data are already present in the cache. If the data are not in the cache, a read-miss request is then forwarded to the QLC region. On the other hand, in an integrated structure, when there is a read-miss, the SLC cache is populated with the requested data after it has been read from the QLC region. Our work utilizes a write-only configuration for the cache.
The QLC region manager handles space limitations in the QLC region. As this region nears capacity, it initiates garbage collection, removing unused data blocks to accommodate new ones. After passing through these management stages, the write request is processed by the flash memory controller, which writes the data to the designated cells, either in the SLC cache or the QLC region. This efficient data flow ensures that the hybrid SSD system maintains optimal performance and longevity, dynamically responding to varying data access patterns.
4. Performance Evaluation
To validate the effectiveness of our proposed data placement method for hybrid SSDs, we developed a comprehensive simulator using Python. This simulator is intricately designed to mimic the real-world functioning of an SSD. It incorporates a range of critical operations such as I/O processing to both the SLC cache and QLC region, intricate address translation mechanisms, garbage collection, and data migration processes. Moreover, it is equipped with a feature for dynamically adjusting the size of the SLC cache, which is crucial for evaluating the adaptability and performance of our data placement scheme under varying conditions. In our simulator, the garbage collection process is governed by a greedy algorithm, and for data migration from the SLC cache to the QLC region, the Least Recently Used (LRU) strategy is employed.
The data preprocessing component of our simulator is handled by Pandas [25], a powerful data manipulation and analysis library in Python, which is renowned for its ease of use and versatility in handling large datasets. The training and determination tasks within the simulator are managed by a binary classification model, which is crafted using Keras [26], a high-level neural networks API capable of building and training sophisticated machine-learning models. To benchmark the performance of our algorithm, we utilized the MSR (Microsoft Research) workload [27,28]. This workload is widely recognized for its comprehensive and realistic representation of real-world SSD usage patterns. The first 60% of the dataset was used for training the ANN model, and the rest 40% was used for testing it. Additionally, we verified the adaptability of our scheme using the VDI (virtual desktop infrastructure) workload obtained from an enterprise VDI server [29], and the YCSB (Yahoo! cloud serving benchmark) workload obtained from a server running RocksDB [30].
For exact and simple analysis, we presumed the SSD in the experiment to be equipped with a single 32 GB QLC NAND flash memory chip, which roughly consists of 4000 blocks. This assumption helps streamline the complexity of the simulation while still providing a realistic scenario for testing our data placement method. Furthermore, we allocated 5% of the total SSD capacity for over-provisioning, a common practice in SSDs to enhance performance and endurance by providing additional space for operations like garbage collection and wear leveling.
To comprehensively assess the efficacy of our proposed data placement method, we conducted a comparative analysis against three alternative approaches: (1) QLC-only, where no SLC cache exists; (2) No-classifier, where classification is not applied, and consequently, all data initially passes through the SLC cache; and (3) Size-based, where classification is based solely on I/O size like ComboFTL [7]. In our experiments, as depicted in Figure 3, we dynamically allocated the SLC cache size based on the overall SSD space utilization, a strategy outlined in detail in Table 3 [16,20]. We meticulously analyzed the total execution time for each method, breaking it down into four distinct segments: the times taken to write data to the SLC cache, to write data to the QLC region, to migrate data from the SLC cache to the QLC region, and to conduct garbage collection within the QLC region.
The proposed method demonstrated a remarkable performance advantage over the other approaches. It shows performance improvements of 44%, 40%, and 35% when compared to the QLC-only, No-classifier, and Size-based approaches, respectively. These significant improvements can be largely attributed to the more efficient utilization of the SLC cache, which our method achieves through its binary classification system utilizing the eight carefully selected features. By correctly identifying and categorizing cold write requests, our method not only conserves valuable SLC cache space but also minimizes the need for frequent data migration and garbage collection operations, which are both time-consuming and resource-intensive. In particular, we observed that the migration time was significantly reduced; there was an improvement of 76% and 67% compared to the No-classifier and Size-based schemes, respectively. Consequently, this efficient machine-learning-based data management leads to a reduction in overall execution time, enhancing the performance of the SSD.
In Figure 4, we present the experimental results with a focus on the erase count, a critical metric directly affecting the longevity and durability of SSDs. In our analysis, we specifically measured the erase count within the QLC region. The results of this experiment further reinforce the effectiveness of our proposed data placement method. When the SLC cache size is set to represent 5% of the total SSD capacity, our method significantly outperforms the other approaches. It achieves an impressive reduction in erase counts by 85%, 81%, and 80% compared to the QLC-only, No-classifier, and Size-based schemes, respectively. This substantial decrease in erase counts is a clear indicator of the enhanced efficiency and lifespan of SSDs using our method.
However, it is noteworthy that when the SLC cache size is increased to 20% of the SSD’s total capacity, there is a noticeable increase in erase counts across all schemes, including ours. This increase can be primarily attributed to the consequent reduction in the size of the QLC region. A smaller QLC region leads to more frequent garbage collections within this area, as the available space for storing new data diminishes more rapidly.
This observed trend particularly highlights a significant limitation of the Size-based method. It reveals that using a fixed threshold for distinguishing between hot and cold data, as done in the Size-based scheme, can lead to suboptimal performance. This approach lacks the flexibility to adapt to changes in workload patterns and variations in the SSD’s storage status. Consequently, while it might offer some benefits in specific scenarios, its overall effectiveness in enhancing the SSD’s lifespan can be limited compared to more dynamic and adaptive methods like ours. This insight underscores the importance of employing a data placement strategy that is not only efficient but also adaptable to the changing conditions and demands of SSD usage.
The efficacy of our proposed data placement method, particularly its sensitivity to varying workload characteristics, necessitates thorough validation to gauge its adaptability to diverse I/O patterns. This is crucial to ensure that the method remains effective across a wide range of real-world scenarios. In Table 4, we present experimental results that shed light on this crucial aspect of our approach. When the method is trained and tested on the same workload, it achieves an accuracy rate exceeding 90%. Conversely, testing with the VDI workload after training with the YCSB workload results in a 77.5% accuracy rate, and the reverse scenario yields a 61% accuracy rate. Although accuracy diminishes when training and testing are conducted with different workloads, our method’s overall performance remains robust and significant. This minor reduction in accuracy is mainly observed during periods of rapidly changing I/O workloads, wherein the predictive model might momentarily struggle to keep up with evolving data access patterns.
It is important to note that this minor decrease in accuracy is predominantly a transient phenomenon. We anticipate that as the I/O workload begins to stabilize and the system adapts to the new patterns of data access, there will be a corresponding improvement in the cache hit ratio and overall performance efficacy. This adaptability is a key strength of our method, as it is designed to continually learn and adjust to evolving workload characteristics. Thus, even in scenarios where the workload undergoes significant fluctuations, our method is capable of recalibrating itself to maintain high levels of efficiency and accuracy over time. This ability to dynamically adapt to changing conditions underscores the versatility and robustness of our proposed data placement scheme in managing hybrid SSD environments. In our experiments, the classifier’s training time amounts to 3.78 s, and considering that the model undergoes training just once daily, the computational overhead can be negligible.
5. Conclusions
In hybrid SSDs employing a section of QLC blocks in SLC mode, optimal use of a limited SLC cache is crucial. This paper introduces an effective data placement strategy that uses a streamlined classifier to determine the placement locations for incoming write requests based on features tied to I/O workload and SSD status. The classifier adeptly identifies data unnecessary for SLC cache storage. Supported by simulations with real-world workloads, our method consistently outperforms alternatives. It demonstrates exceptional adaptability to workload fluctuations, highlighting its significant contribution to enhancing hybrid SSDs’ efficiency.
Author Contributions
Conceptualization, H.C. and T.K.; methodology, H.C.; software, H.C.; validation, H.C. and T.K.; formal analysis, T.K.; investigation, H.C.; resources, T.K.; data curation, H.C.; writing—original draft preparation, H.C. and T.K.; writing—review and editing, T.K.; visualization, T.K.; supervision, T.K.; project administration, T.K.; funding acquisition, T.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Research Grant of Kwangwoon University in 2021, and the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT), grant number 2020R1F1A1074676.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available since future studies are related to current data.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liang, S.; Qiao, Z.; Tang, S.; Hochstetler, J.; Fu, S.; Shi, W.; Chen, H.B. An empirical study of quad-level cell (QLC) nand flash ssds for big data applications. In Proceedings of the 2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 3676–3685. [Google Scholar]
- Chen, Q.; Wang, S.; Zhou, Y.; Wu, F.; Li, S.; Wang, Z.; Xie, C. PACA: A page type aware read cache scheme in QLC flash-based SSDs. In Proceedings of the 2022 IEEE 40th International Conference on Computer Design, Olympic Valley, CA, USA, 23–26 October 2022; pp. 59–66. [Google Scholar]
- Luo, L.; Li, S.; Lv, Y.; Shi, L. Performance and reliability optimization for high-density flash-based hybrid SSDs. J. Syst. Archit. 2023, 136, 102830. [Google Scholar] [CrossRef]
- Li, S.; Luo, L.; Lv, Y.; Shi, L. Latency aware page migration for read performance optimization on hybrid SSDs. In Proceedings of the 2022 IEEE 11th Non-Volatile Memory Systems and Applications Symposium (NVMSA), Taipei, Taiwan, 23–25 August 2022; pp. 33–38. [Google Scholar]
- Stoica, R.; Pletka, R.; Ioannou, N.; Papandreou, N.; Tomic, S.; Pozidis, H. Understanding the design trade-offs of hybrid flash controllers. In Proceedings of the 2019 IEEE 27th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS), Rennes, France, 21–25 October 2019; pp. 152–164. [Google Scholar]
- Liu, D.; Yao, L.; Long, L.; Shao, Z.; Guan, Y. A workload-aware flash translation layer enhancing performance and lifespan of TLC/SLC dual-mode flash memory in embedded systems. Microprocess. Microsyst. 2017, 52, 343–354. [Google Scholar] [CrossRef]
- Im, S.; Shin, D. ComboFTL: Improving performance and lifespan of MLC flash memory using SLC flash buffer. J. Syst. Archit. 2010, 56, 641–653. [Google Scholar] [CrossRef]
- Kwon, K.; Kang, D.H.; Eom, Y.I. An advanced SLC-buffering for TLC NAND flash-based storage. IEEE Trans. Consum. Electron. 2017, 63, 459–466. [Google Scholar] [CrossRef]
- Yao, Y.; Fan, J.; Zhou, J.; Kong, X.; Gu, N. Hdftl: An on-demand flash translation layer algorithm for hybrid solid state drives. IEEE Trans. Consum. Electron. 2021, 67, 50–57. [Google Scholar] [CrossRef]
- Wei, Q.; Li, Y.; Jia, Z.; Zhao, M.; Shen, Z.; Li, B. Reinforcement learning-assisted management for convertible SSDs. In Proceedings of the 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 9–13 July 2023; pp. 1–6. [Google Scholar]
- Li, J.; Li, M.; Cai, Z.; Trahay, F.; Wahib, M.; Gerofi, B.; Liao, J. Intra-page cache update in SLC-mode with partial programming in high density SSDs. In Proceedings of the 50th International Conference on Parallel Processing, Lemont, IL, USA, 9–12 August 2021; pp. 1–10. [Google Scholar]
- Tripathy, S.; Satpathy, M. SSD internal cache management policies: A survey. J. Syst. Archit. 2022, 122, 102334. [Google Scholar] [CrossRef]
- Xiao, C.; Qiu, S.; Xu, D. PASM: Parallelism aware space management strategy for hybrid SSD towards in-storage DNN training acceleration. J. Syst. Archit. 2022, 128, 102565. [Google Scholar] [CrossRef]
- Lee, J.; Kim, J.S. An empirical study of hot/cold data separation policies in solid state drives (SSDs). In Proceedings of the 6th International Systems and Storage Conference, Haifa, Israel, 30 June–2 July 2013; pp. 1–6. [Google Scholar]
- Wang, Y.L.; Kim, K.T.; Lee, B.; Youn, H.Y. A novel buffer management scheme based on particle swarm optimization for SSD. J. Supercomput. 2018, 74, 141–159. [Google Scholar] [CrossRef]
- Yoo, S.; Shin, D. Reinforcement learning-based SLC cache technique for enhancing SSD write performance. In Proceedings of the 12th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 20), Virtual Event, 13–14 July 2020. [Google Scholar]
- Jung, S.; Song, Y.H. Hierarchical use of heterogeneous flash memories for high performance and durability. IEEE IEEE Trans. Consum. Electron. 2009, 55, 1383–1391. [Google Scholar] [CrossRef]
- Chang, L.P. A hybrid approach to NAND-flash-based solid-state disks. IEEE Trans. Comput. 2010, 59, 1337–1349. [Google Scholar] [CrossRef]
- Hachiya, S.; Johguchi, K.; Miyaji, K.; Takeuchi, K. Hybrid triple-level-cell/multi-level-cell NAND flash storage array with chip exchangeable method. Jpn. J. Appl. Phys. 2014, 53, 04EE04. [Google Scholar] [CrossRef]
- Zhang, W.; Cao, Q.; Jiang, H.; Yao, J.; Dong, Y.; Yang, P. SPA-SSD: Exploit heterogeneity and parallelism of 3D SLC-TLC hybrid SSD to improve write performance. In Proceedings of the 2019 IEEE 37th International Conference on Computer Design (ICCD), Abu Dhabi, United Arab Emirates, 17–20 November 2019; pp. 613–621. [Google Scholar]
- Hao, M.; Toksoz, L.; Li, N.; Halim, E.E.; Hoffmann, H.; Gunawi, H.S. LinnOS: Predictability on unpredictable flash storage with a light neural network. In Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), Virtual Event, 4–6 November 2020; pp. 173–190. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Chen, X.; Tan, Y.; Zhang, R.; Liang, L.; Liu, D. SSDKeeper: Self-adapting channel allocation to improve the performance of SSD devices. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), New Orleans, LA, USA, 8–22 May 2020; pp. 966–975. [Google Scholar]
- Lee, H.; Song, J. Introduction to convolutional neural network using Keras; an understanding from a statistician. Commun. Stat. Appl. Methods 2019, 26, 591–610. [Google Scholar] [CrossRef]
- McKinney, W. Pandas: A foundational Python library for data analysis and statistics. Python High Perform. Sci. Comput. 2011, 14, 1–9. [Google Scholar]
- Joseph, F.J.J.; Nonsiri, S.; Monsakul, A. Keras and TensorFlow: A hands-on experience. Adv. Deep. Learn. Eng. Sci. Pract. Approach 2021, 85–111. [Google Scholar]
- Koller, R.; Rangaswami, R. I/O deduplication: Utilizing content similarity to improve I/O performance. ACM Trans. Storage (TOS) 2010, 6, 13. [Google Scholar] [CrossRef]
- Narayanan, D.; Donnelly, A.; Rowstron, A. Write off-loading: Practical power management for enterprise storage. ACM Trans. Storage (TOS) 2008, 4, 10. [Google Scholar] [CrossRef]
- Lee, C.; Kumano, T.; Matsuki, T.; Endo, H.; Fukumoto, N.; Sugawara, M. Understanding storage traffic characteristics on enterprise virtual desktop infrastructure. In Proceedings of the 10th ACM International Systems and Storage Conference, Haifa, Israel, 22–24 May 2017; pp. 1–11. [Google Scholar]
- Yadgar, G.; Gabel, M.; Jaffer, S.; Schroeder, B. SSD-based workload characteristics and their performance implications. ACM Trans. Storage (TOS) 2021, 17, 8. [Google Scholar] [CrossRef]
Figure 1.
Operations in the SLC/QLC hybrid SSD architecture.

Figure 2.
Data placement using a binary classifier.

Figure 3.
Performance when the SLC cache size is dynamically adjusted.

Figure 4.
Erase count as a function of SLC cache size.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Performance of SLC, MLC, TLC, and QLC flash memories.
| SLC | MLC | TLC | QLC | |
|---|---|---|---|---|
| Read time | 20–25 us | 55–110 us | 75–170 us | 120–200 us |
| Write time | 50–100 us | 0.4–1.5 ms | 0.8–2 ms | 2–3 ms |
| Erase time | 2–5 ms | 5–10 ms | 10–15 ms | 15–20 ms |
| Max. P/E | 100,000 | 15,000 | 3000–5000 | 800–1500 |
Table 2.
Features used for the classification.
| Features | Description |
|---|---|
| LBA | Logical block address of the I/O request |
| Size | Size of the I/O request in bytes |
| Type | Type of the I/O request (read/write) |
| Frequency | The number of accesses to the same I/O request within a window |
| Interval | The number of accesses since the most recent request for the same data |
| Location | Location where the same request was most recently sent to |
| Ratio | Ratio of SLC cache space to the QLC region |
| SSD utilization | SSD space utilization |
Table 3.
Dynamic allocation of the SLC cache space.
| Utilization (%) | 0–20 | 20–30 | 30–40 | 40–50 | 50–60 | 60–70 | 70–100 |
| SLC cache (%) | 56 | 50 | 40 | 30 | 25 | 20 | 10 |
Table 4.
Adaptability of the proposed method.
| Accuracy | YCSB Trace | VDI Trace |
|---|---|---|
| YCSB trace | 93.8% | 61.0% |
| VDI trace | 77.5% | 94.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Cho, H.; Kim, T. Data Placement Using a Classifier for SLC/QLC Hybrid SSDs. Appl. Sci. 2024, 14, 1648. https://doi.org/10.3390/app14041648
AMA Style
Cho H, Kim T. Data Placement Using a Classifier for SLC/QLC Hybrid SSDs. Applied Sciences. 2024; 14(4):1648. https://doi.org/10.3390/app14041648
Chicago/Turabian StyleCho, Heeseong, and Taeseok Kim. 2024. "Data Placement Using a Classifier for SLC/QLC Hybrid SSDs" Applied Sciences 14, no. 4: 1648. https://doi.org/10.3390/app14041648
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.