

PCCAU-Net: A Novel Road Extraction Method Based on Coord Convolution and a DCA Module

 , ,
, ,
Abstract
:1. Introduction
1.1. Related Works
1.2. Innovation Statement
- Multi-scale feature and spatial context fusion: PCCAU-Net employs Pyramid Pathway Input and CoordConv convolution, achieving a seamless assimilation of features from across multiple scales down to fine-grain levels, along with precocious spatial context recognition. This holistic design strategy assures precise road localization and extraction, even amidst complex settings.
- At the critical encoder stage, the model incorporates a Dual-Input Cross Attention (DCA) module. This not only augments the nimble integration of feature maps across various scales but also sharpens the model’s focus on road center detection, effectively attenuating false positives induced by obstructions, entanglements, and noise.
- Across key performance metrics such as precision, recall, and Intersection-over-Union (IoU), PCCAU-Net demonstrates a clear supremacy over existing mainstream approaches, vindicating its potential applicability in the realm of remote sensing data processing.
2. Methods
2.1. Overview of PCCAU-Net
2.2. Pyramid Path Input
2.3. CoordConv Layer
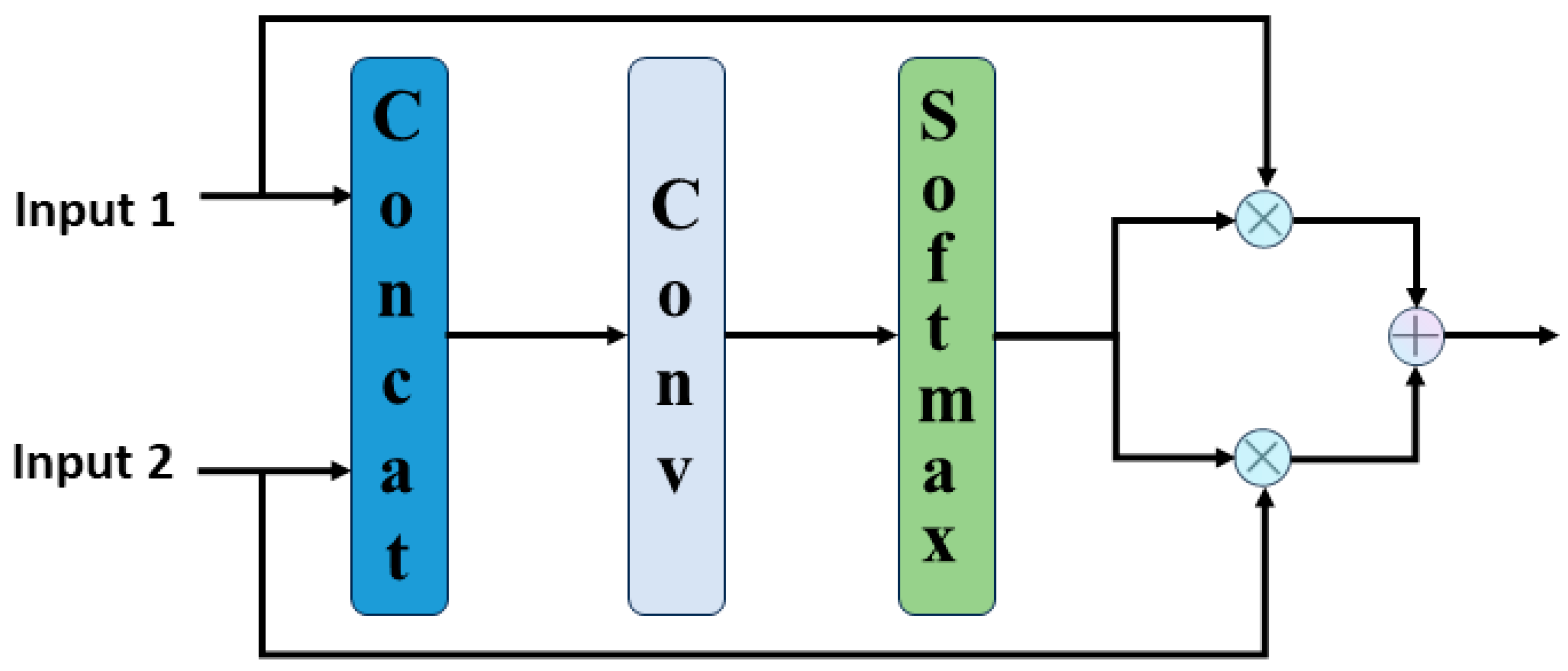
2.4. Dual-Input Cross-Attention (DCA) Module
- Feature encoding and interaction: the DCA module initially performs specialized convolution operations on both input features, generating query (Q), key (K), and value (V) representations. Ingeniously concatenated, these features complement and interact with each other in the subsequent attention stage.
- Cross- Attention fusion: the module dynamically determines the importance of each feature by computing weights based on the juxtaposed Q and K. This process ensures that DCA can pinpoint and integrate salient information from varied origins.
- Feature harmonization and dynamic fusion: the resultant features are first optimized via residual connections and subsequently subjected to layer normalization to ensure the continuity and stability of the information flow. Ultimately, the fusion attention mechanism calculates fusion weights and meticulously integrates Out_Input1 and Out_Input2, guaranteeing seamless spatial and semantic alignment.
2.5. Fusion Attention Module
2.6. Loss Function
3. Experiments and Results
3.1. Data Description
3.1.1. Massachusetts Roads Dataset
3.1.2. DeepGlobe Road Dataset
3.2. Experimental Setup
3.2.1. Training Environment and Hyperparameters
3.2.2. Verification Indicator
3.3. Comparative Experiment Results and Analysis
3.3.1. Analysis of Massachusetts Roads Dataset Results
- Precision: PCCAU-Net outperforms its peers with a precision rate of 83.395%, thereby indicating fewer false positives. The closest competitor, SDUNet, registers a precision of 80.094%, underscoring the substantial advantage of PCCAU-Net in minimizing identification errors.
- Recall: While SDUNet achieves the highest recall rate at 84.856%, indicating its prowess in detecting the majority of true road segments; PCCAU-Net trails closely with a recall of 84.076%. This demonstrates a well-calibrated balance between precision and recall, offering a more nuanced view of road attributes.
- IoU: PCCAU-Net leads with an IoU of 78.783%, narrowly eclipsing SDUNet’s 78.625%. The superior IoU score for PCCAU-Net suggests its proficiency in delivering more accurate road segmentation, a critical aspect for applications demanding high precision.
3.3.2. Analysis of DeepGlobe Roads Dataset Results
3.4. Ablation Experiments Results and Analysis
3.5. Computational Efficiency
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oliveira, G.L.; Burgard, W.; Brox, T. Efficient deep models for monocular road segmentation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4885–4891. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.; Wang, R.; Yang, J. Road segmentation for remote sensing images using adversarial spatial pyramid networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4673–4688. [Google Scholar] [CrossRef]
- Huan, H.; Sheng, Y.; Zhang, Y.; Liu, Y. Strip Attention Networks for Road Extraction. Remote Sens. 2022, 14, 4516. [Google Scholar] [CrossRef]
- Lyu, Y.; Bai, L.; Huang, X. Road segmentation using cnn and distributed lstm. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Lan, M.; Zhang, Y.; Zhang, L.; Du, B. Global context based automatic road segmentation via dilated convolutional neural network. Inf. Sci. 2020, 535, 156–171. [Google Scholar] [CrossRef]
- Ajayi, O.G.; Odumosu, J.O.; Samaila-Ija, H.A.; Zitta, N.; Adesina, E.A. Dynamic Road Segmentation of Part of Bosso Local Governemt Area, Niger State; Scientific & Academic: Rosemead, CA, USA, 2015. [Google Scholar]
- Sun, Z.; Zhou, W.; Ding, C.; Xia, M. Multi-resolution transformer network for building and road segmentation of remote sensing image. ISPRS Int. J. Geo-Inf. 2022, 11, 165. [Google Scholar] [CrossRef]
- Song, X.; Rui, T.; Zhang, S.; Fei, J.; Wang, X. A road segmentation method based on the deep auto-encoder with supervised learning. Comput. Electr. Eng. 2018, 68, 381–388. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote sensing image scene classification using bag of convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Blaschke, T.; Burnett, C.; Pekkarinen, A. Image segmentation methods for object-based analysis and classification. In Remote Sensing Image Analysis: Including the Spatial Domain; Springer: Berlin/Heidelberg, Germany, 2004; pp. 211–236. [Google Scholar]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road extraction methods in high-resolution remote sensing images: A comprehensive review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Furano, G.; Meoni, G.; Dunne, A.; Moloney, D.; Ferlet-Cavrois, V.; Tavoularis, A.; Byrne, J.; Buckley, L.; Psarakis, M.; Voss, K.-O. Towards the use of artificial intelligence on the edge in space systems: Challenges and opportunities. IEEE Aerosp. Electron. Syst. Mag. 2020, 35, 44–56. [Google Scholar] [CrossRef]
- Paisitkriangkrai, S.; Sherrah, J.; Janney, P.; Van Den Hengel, A. Semantic labeling of aerial and satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2868–2881. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18; Springer International Publishing: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceeding of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, J.; Liu, Y.; Zhang, Y.; Zhang, Y. Cascaded Attention DenseUNet (CADUNet) for Road Extraction from Very-High-Resolution Images. ISPRS Int. J. Geo-Inf. 2021, 10, 329. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Cao, X.; Zhang, K.; Jiao, L. CSANet: Cross-Scale Axial Attention Network for Road Segmentation. Remote Sens. 2023, 15, 3. [Google Scholar] [CrossRef]
- Zhang, Z.; Miao, C.; Liu, C.; Tian, Q.; Zhou, Y. HA-RoadFormer: Hybrid Attention Transformer with Multi-Branch for Large-Scale High-Resolution Dense Road Segmentation. Mathematics 2022, 10, 1915. [Google Scholar] [CrossRef]
- Tong, Z.; Li, Y.; Zhang, J.; He, L.; Gong, Y. MSFANet: Multiscale Fusion Attention Network for Road Segmentation of Multispectral Remote Sensing Data. Remote Sens. 2023, 15, 1978. [Google Scholar] [CrossRef]
- Alshaikhli, T.; Liu, W.; Maruyama, Y. Simultaneous Extraction of Road and Centerline from Aerial Images Using a Deep Convolutional Neural Network. ISPRS Int. J. Geo-Inf. 2021, 10, 147. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A Global Context-aware and Batchin dependent Network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High Resolution Images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Rong, Y.; Zhuang, Z.; He, Z.; Wang, X. A Maritime Traffic Network Mining Method Based on Massive Trajectory Data. Electronics 2022, 11, 987. [Google Scholar] [CrossRef]
- Li, Z.; Fang, C.; Xiao, R.; Wang, W.; Yan, Y. SI-Net: Multi-Scale Context-Aware Convolutional Block for Speaker Verification. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 220–227. [Google Scholar] [CrossRef]
- Kang, L.; Riba, P.; Rusiñol, M.; Fornés, A.; Villegas, M. Pay attention to what you read: Non-recurrent handwritten text-line recognition. Pattern Recognit. 2022, 129, 108766. [Google Scholar] [CrossRef]
- Qin, N.; Tan, W.; Ma, L.; Zhang, D.; Guan, H.; Li, J. Deep learning for filtering the ground from ALS point clouds: A dataset, evaluations and issues. ISPRS J. Photogramm. Remote Sens. 2023, 202, 246–261. [Google Scholar] [CrossRef]
- Liu, R.; Lehman, J.; Molino, P.; Petroski Such, F.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the coordconv solution. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Mena, J.B. State of the art on automatic road extraction for GIS update: A novel classification. Pattern Recognit. Lett. 2003, 24, 3037–3058. [Google Scholar] [CrossRef]
- Emam, Z.; Kondrich, A.; Harrison, S.; Lau, F.; Wang, Y.; Kim, A.; Branson, E. On the state of data in computer vision: Human annotations remain indispensable for developing deep learning models. arXiv 2021, arXiv:2108.00114. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 172–181. [Google Scholar]
- SDUNet: Road Extraction via Spatial Enhanced and Densely Connected UNet. Available online: https://www.sciencedirect.com/science/article/pii/S0031320322000309 (accessed on 9 March 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value | |
|---|---|---|
| Epoch | 100 | |
| Batch Size | 4 (Massachusetts Roads Dataset) | 2 (DeepGlobe Road Dataset) |
| Initial Learning Rate | 1 × 10−4 | |
| ϵ | 1 × 10−8 | |
| Weight Decay | 0 | |
| Beta 1 | 0.9 | |
| Beta 2 | 0.999 | |
| Model | Precision (%) | Recall (%) | IoU (%) |
|---|---|---|---|
| U-Net | 78.823 | 83.764 | 77.672 |
| Resunet | 79.297 | 83.253 | 77.902 |
| DeeplabV3+ | 79.567 | 83.909 | 77.457 |
| SDUNet | 80.094 | 84.856 | 78.625 |
| PCCAU-Net | 83.395 | 84.076 | 78.783 |
| Model | Precision (%) | Recall (%) | IoU (%) |
|---|---|---|---|
| U-Net | 83.436 | 84.454 | 75.365 |
| Resunet | 86.098 | 86.085 | 77.819 |
| DeeplabV3+ | 85.489 | 85.653 | 78.158 |
| SDUNet | 86.061 | 85.209 | 77.238 |
| PCCAU-Net | 87.424 | 88.293 | 80.113 |
| Scheme | Massachusetts Roads Dataset | DeepGlobe Road Dataset | ||||
|---|---|---|---|---|---|---|
| Precision (%) | ReCall (%) | IoU (%) | Precision (%) | ReCall (%) | IoU (%) | |
| a | 78.823 | 83.764 | 77.672 | 83.436 | 84.454 | 75.365 |
| b | 79.182 | 84.035 | 77.768 | 84.273 | 85.145 | 76.092 |
| c | 80.357 | 83.913 | 77.937 | 84.224 | 86.047 | 77.642 |
| d | 81.136 | 83.849 | 78.217 | 85.423 | 86.864 | 78.652 |
| e | 83.395 | 84.076 | 78.783 | 87.424 | 88.293 | 80.113 |
| Model | Parameters (M) | FLOPs (GLOPS) |
|---|---|---|
| U-Net | 29.97 | 5.63 |
| Resunet | 25.57 | 5.42 |
| DeeplabV3+ | 5.88 | 6.60 |
| SDUNet | 25.90 | 62.30 |
| PCCAU-Net | 24.35 | 60.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, X.; Ren, C.; Yin, A.; Zhou, Y.; Liu, Y.; Ding, C.; Lu, J. PCCAU-Net: A Novel Road Extraction Method Based on Coord Convolution and a DCA Module. Appl. Sci. 2024, 14, 1634. https://doi.org/10.3390/app14041634
Xue X, Ren C, Yin A, Zhou Y, Liu Y, Ding C, Lu J. PCCAU-Net: A Novel Road Extraction Method Based on Coord Convolution and a DCA Module. Applied Sciences. 2024; 14(4):1634. https://doi.org/10.3390/app14041634
Chicago/Turabian StyleXue, Xiaoqin, Chao Ren, Anchao Yin, Ying Zhou, Yuanyuan Liu, Cong Ding, and Jiakai Lu. 2024. "PCCAU-Net: A Novel Road Extraction Method Based on Coord Convolution and a DCA Module" Applied Sciences 14, no. 4: 1634. https://doi.org/10.3390/app14041634