

Named Entity Recognition in Government Audit Texts Based on ChineseBERT and Character-Word Fusion

Abstract
:1. Introduction
2. Named Entity Recognition Model for Government Audit Text
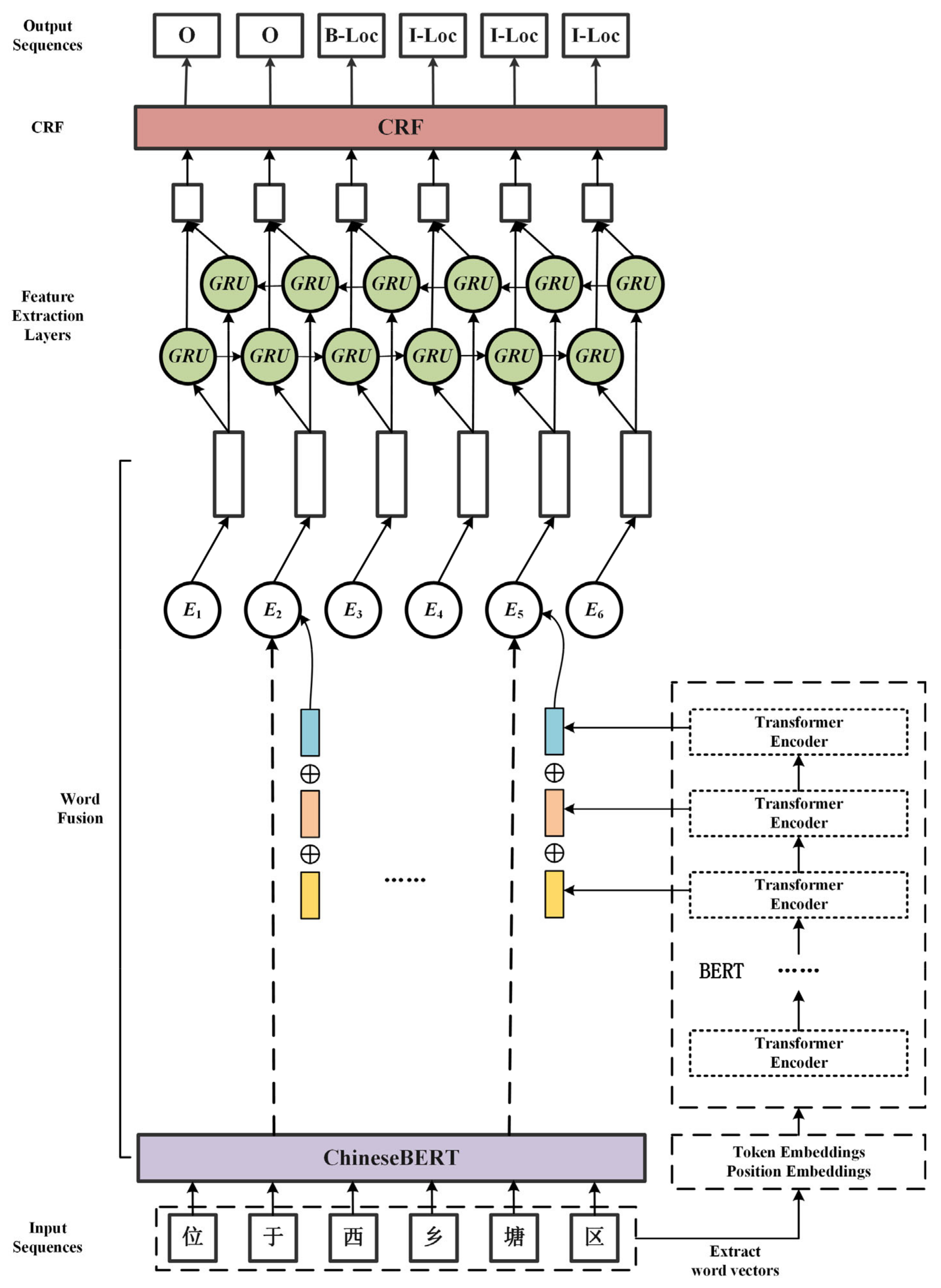
2.1. Overall Framework of Model
2.2. Embedded Layer
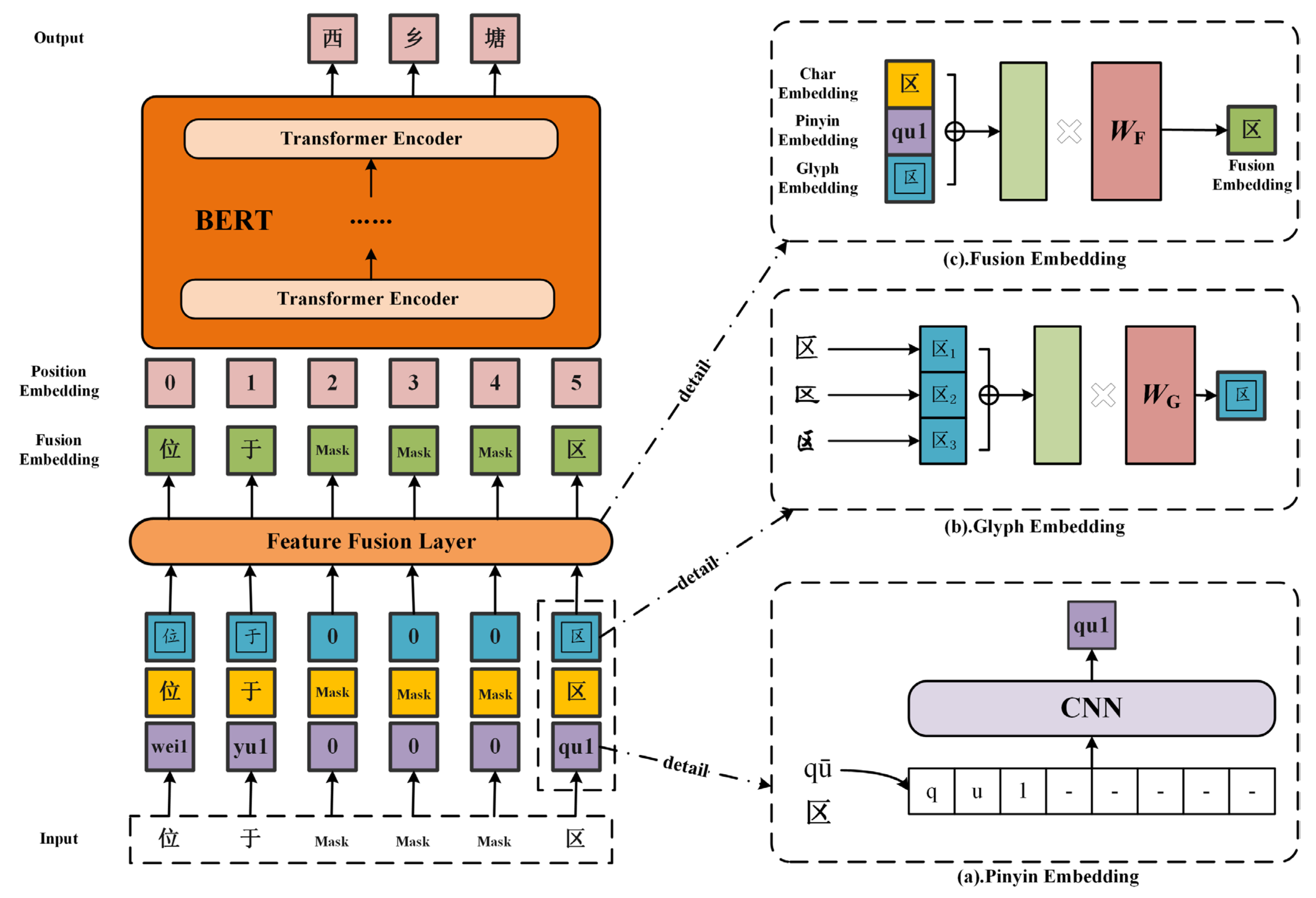
2.2.1. Character Vector Representation
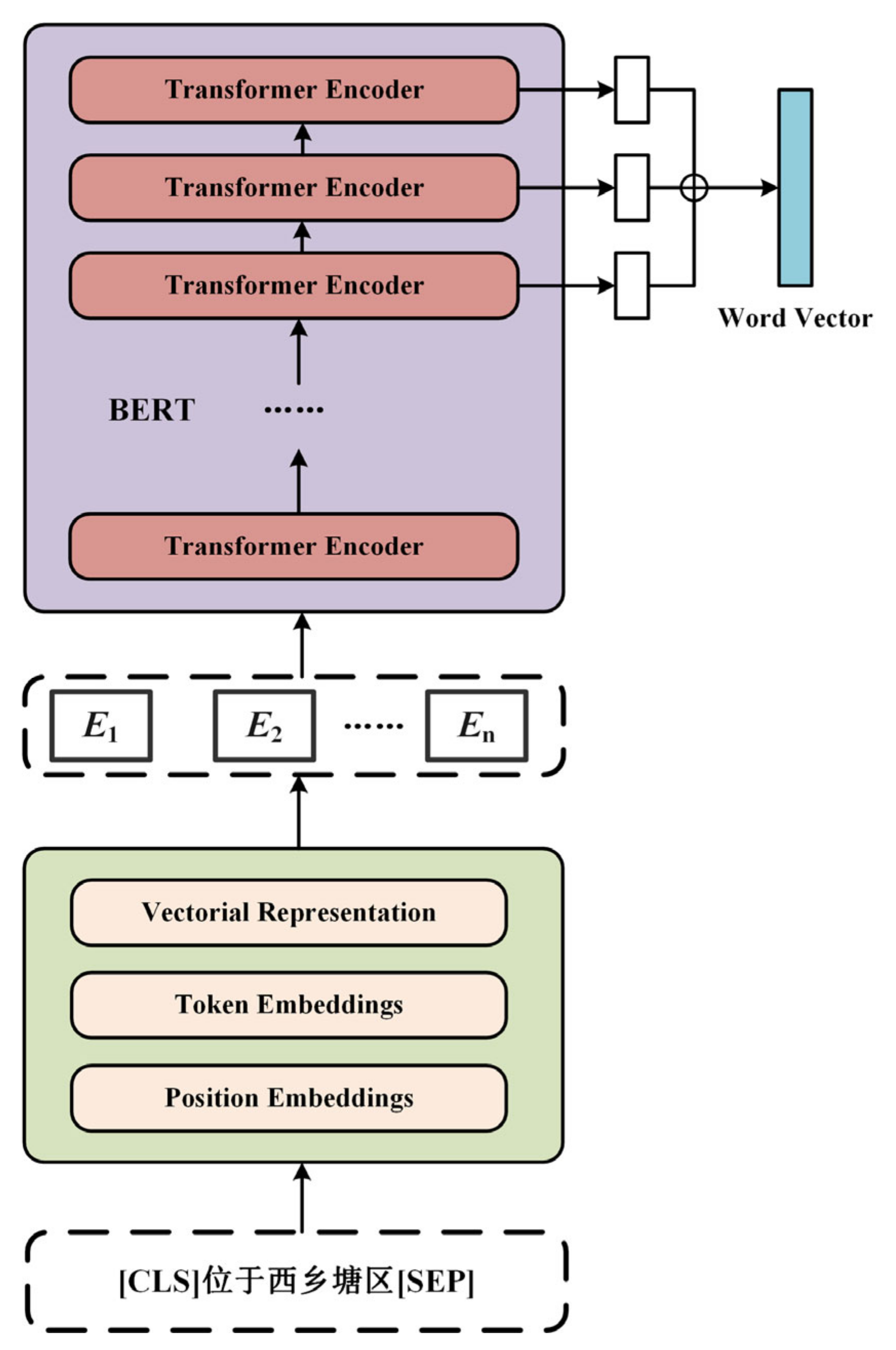
2.2.2. Word Vector Representation
2.2.3. Character-Word Vector Fusion
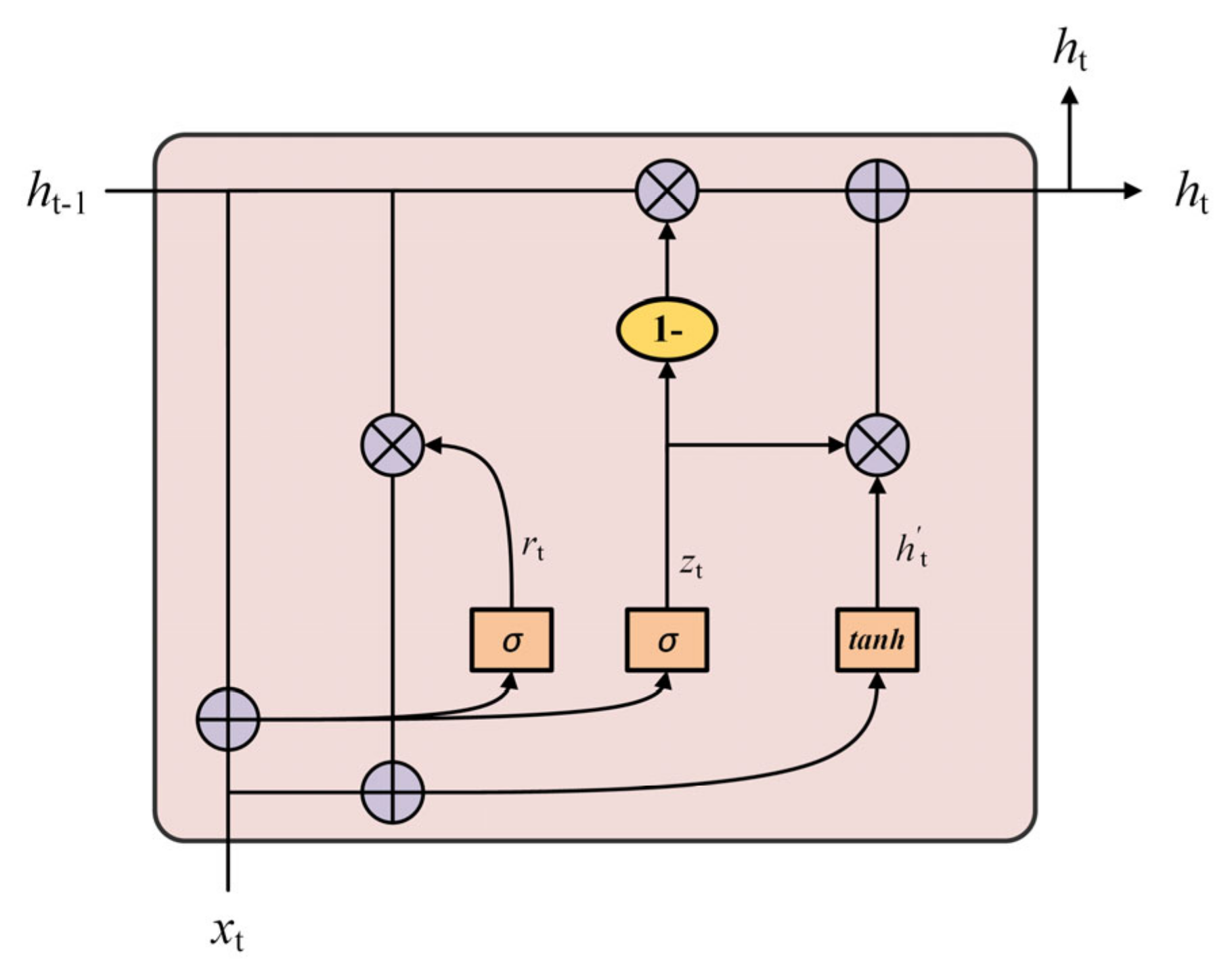
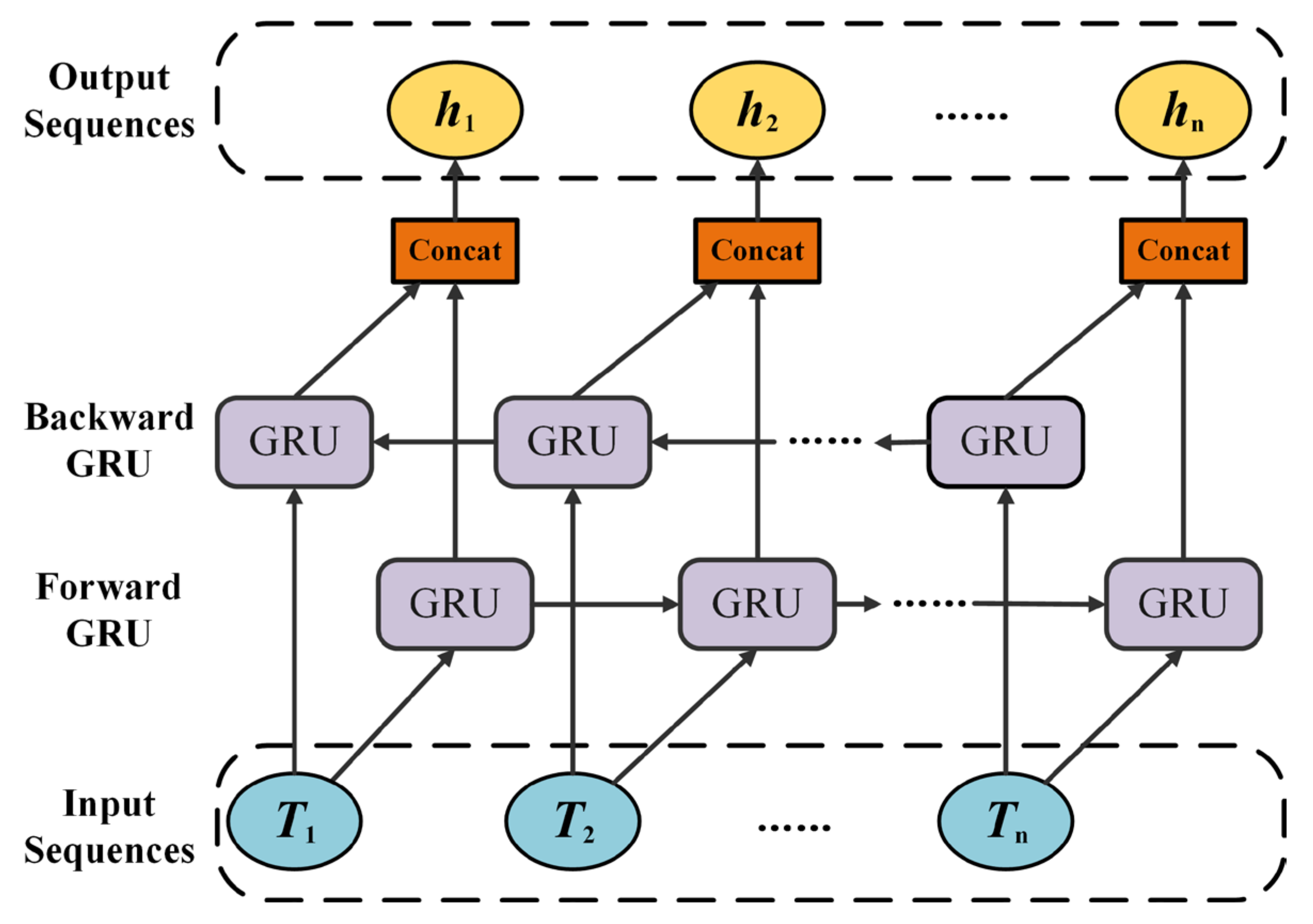
2.3. Feature Extraction Layer
2.4. CRF Layer
2.5. Loss Functions
3. Experiment and Results Analysis
3.1. Experimental Data and Pre-Processing
3.2. Experimental Environment
3.3. Evaluation Indicators
3.4. Experimental Results and Analysis
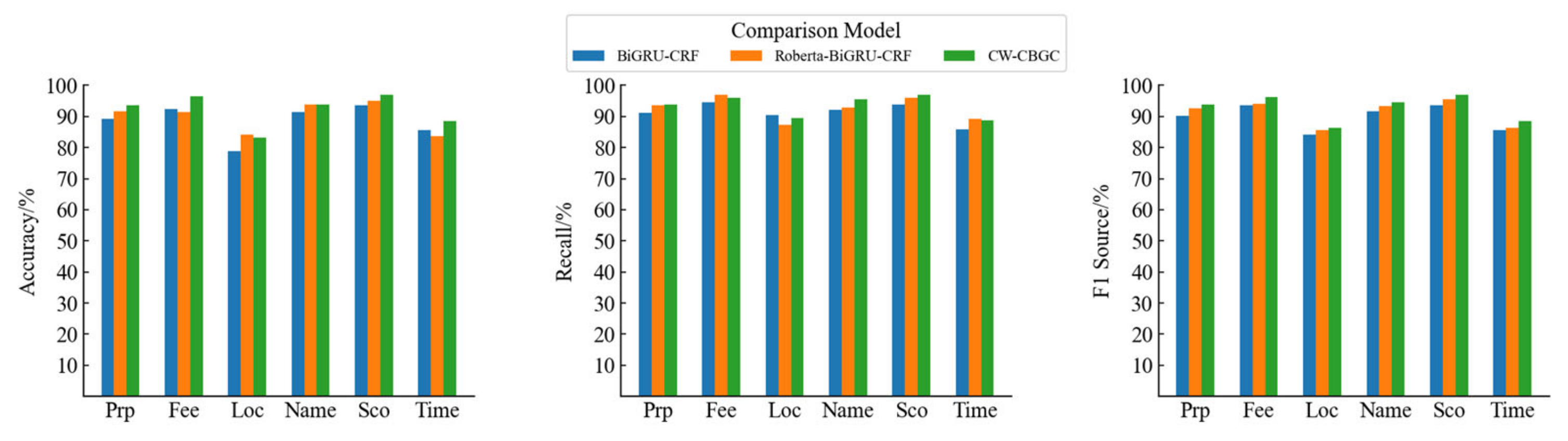
3.4.1. Results and Analysis of Experimental Comparison
3.4.2. Results and Analysis of Experimental Ablation
3.4.3. Audit Entity Identification Effectiveness and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiang, N. On State Audit Change and Development in the Age of Artificial Intelligence. Financ. Account. Mon. 2022, 11, 104–109. [Google Scholar]
- Li, D.M.; Luo, S.S.; Zhang, X.P.; Xu, F. A Review of Research on Named Entity Recognition Methods. J. Front. Comput. Sci. Technol. 2022, 16, 1954–1968. [Google Scholar]
- Grishman, R.; Sundheim, B.M. Message Understanding Conference-6: A brief history. In Proceedings of the 16th Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996. [Google Scholar]
- Zhang, J.; Shen, D.; Zhou, G.D.; Su, J.; Tan, C.L. Enhancing HMM-based biomedical named entity recognition by studying special phenomena. J. Biomed. Inform. 2004, 37, 411–422. [Google Scholar] [CrossRef] [PubMed]
- Lafferty, J.; Mccallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the 18th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Sun, C.J.; Guan, Y.; Wang, X.L.; Lin, L. Rich features based conditional random fields for biological named entities recognition. Comput. Biol. Med. 2007, 37, 1327–1333. [Google Scholar] [CrossRef] [PubMed]
- Chieu, H.L.; Ng, H.T. Named entity recognition with a maximum entropy approach. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 160–163. [Google Scholar]
- Liu, J. A Chinese Named Entity Recognition Algorithm Based on Improved Hidden Markov Models. J. Taiyuan Norm. Univ. (Nat. Sci. Ed.) 2009, 8, 80–83+90. [Google Scholar]
- Zhang, W.Q. Deep Learning-Based Recognition of Named Entities in Zhuang Language. Master’s Thesis, Guangxi Normal University, Guilin, China, 2022. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Hammerton, J. Named entity recognition with long short-term memory. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 172–175. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Lin, J.T.; Liu, E.D. Research on Named Entity Recognition Method of Metro On-Board Equipment Based on Multiheaded Self-Attention Mechanism and CNN-BiLSTM-CRF. Comput. Intell. Neurosci. 2022, 2022, 6374988. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yang, J. Chinese NER using lattice LSTM. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1554–1564. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; MIT Press: Lake Tahoe, CA, USA, 2013; pp. 3113–3119. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Xu, L.; Li, J.H. Biomedical Named Entity Recognition Based on BERT and BiLSTM-CRF. Comput. Eng. Sci. 2021, 43, 1873–1879. [Google Scholar]
- Wang, Z.H.; Huang, M.; Li, C.X.; Feng, J.L.; Liu, S.; Yang, G. Intelligent Recognition of Key Earthquake Emergency Chinese Information Based on the Optimized BERT-BiLSTM-CRF Algorithm. Appl. Sci. 2023, 13, 3024. [Google Scholar] [CrossRef]
- Yang, C.L.; Sheng, L.; Wei, Z.C.; Wang, W. Chinese Named Entity Recognition of Epidemiological Investigation of Information on COVID-19 Based on BERT. IEEE Access 2022, 10, 104156–104168. [Google Scholar] [CrossRef]
- Qian, T.Y.; Chen, Y.F.; Pang, B.W. Audit Text Named Entity Recognition Based on MacBERT and Adversarial Training. Comput. Sci. 2023, 50, 93–98. [Google Scholar]
- Sun, Z.J.; Li, X.Y.; Sun, X.F.; Meng, Y.X.; Ao, X.; He, Q.; Wu, F.; Li, J.W. ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; pp. 2065–2075. [Google Scholar]
- Li, S.T.; Zhang, M.M.; Liu, B. A Study on Named Entity Recognition in Kiwifruit Cultivation Domain by Incorporating Word Semantic Information. Trans. Chin. Soc. Agric. Mach. 2022, 53, 323–331. [Google Scholar]
- Zhao, P.F.; Zhao, C.J.; Wu, H.R.; Wang, W. BERT-based multi-feature fusion for agricultural named entity recognition. Trans. Chin. Soc. Agric. Eng. 2022, 38, 112–118. [Google Scholar]
- Ni, J.; Wang, Y.J.; Zhao, B. Named Entity Recognition for Automotive Production Equipment Failure Domain by Fusing Header Features and BERT. J. Chin. Comput. Syst. 2003, 1–7. Available online: http://kns.cnki.net/kcms/detail/21.1106.tp.20230413.1826.031.html (accessed on 11 September 2023).
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On loss functions for deep neural networks in classification. arXiv 2016, arXiv:1702.05659. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Category | Entity Symbol | Entity | Entity Category |
|---|---|---|---|
| Name | Name | Specific title of audit project | 绿色智能制造环保设备生产项目 (Green intelligent manufacturing environmental protection equipment production project) |
| Address | Loc | Audit project-specific address | 西乡塘区秀厢大道36号(Xixiangtang District Xiuxiang Avenue 36) |
| Willfulness | Prp | Main Project Manager | 盛都投资集团有限责任公司(Sheng Du Investment Group limited liability company) |
| Amount | Fee | Amount to be audited for projects | 28.05 万元 (280,500 yuan) |
| Area | Sco | Audit project area | 17.04 hm2 |
| Text Data | “BIO” Labelling |
|---|---|
| 基(Ji) | O |
| 本(Ben) | O |
| 同(Tong) | O |
| 意(Yi) | O |
| 项(Xiang) | O |
| 目(Mu) | O |
| 位(Wei) | O |
| 于(Yu) | O |
| 西(Xi) | B-Loc |
| 乡(Xiang) | I-Loc |
| 塘(Tang) | I-Loc |
| 区(Qu) | I-Loc |
| Dataset | Category | Training Set | Validation Set | Test Set |
|---|---|---|---|---|
| Audit | Sentence | 5000 | 625 | 625 |
| Entity | 6807 | 753 | 843 | |
| Resume | Sentence | 3821 | 463 | 477 |
| Entity | 13,438 | 1497 | 1630 |
| Relevant Parameter | Value |
|---|---|
| LSTM hidden layer dimension | 128 |
| Learning rate | 5 × 10−5 |
| Optimizer | Adam |
| Batch_size | 32 |
| Dropout | 0.5 |
| Epochs | 50 |
| Clip | 5 |
| Experimental Model | Audit Datasets | Resume Datasets | ||||
|---|---|---|---|---|---|---|
| Accuracy | Recall | F1 | Accuracy | Recall | F1 | |
| Word2Vec-BiLSTM-CRF | 87.06 | 94.14 | 90.46 | 93.66 | 93.31 | 93.48 |
| SoftLexicon | 91.25 | 92.17 | 91.71 | 95.30 | 95.77 | 95.53 |
| BERT-BiLSTM-CRF | 91.78 | 94.52 | 93.13 | 95.75 | 95.28 | 95.51 |
| RoBERTa-BiLSTM-CRF | 94.69 | 92.52 | 93.59 | 94.96 | 95.22 | 95.09 |
| RoBERTa-BiGRU-CRF | 95.76 | 92.79 | 94.25 | 95.13 | 95.25 | 95.20 |
| RoBERTa-BiGRU-CRF-FL | 96.05 | 94.19 | 95.11 | 95.43 | 95.27 | 95.35 |
| CW-CBGC | 97.38 | 96.56 | 97.23 | 96.35 | 96.18 | 96.26 |
| Experimental Model | Accuracy | Recall | F1 |
|---|---|---|---|
| Baseline models | 95.76 | 92.79 | 94.25 |
| +CW | 97.06 | 95.20 | 96.12 |
| +GHM | 95.67 | 95.07 | 95.36 |
| CW-CBGC | 97.38 | 96.56 | 97.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, B.; Lin, Y.; Pang, S.; Fu, L. Named Entity Recognition in Government Audit Texts Based on ChineseBERT and Character-Word Fusion. Appl. Sci. 2024, 14, 1425. https://doi.org/10.3390/app14041425
Huang B, Lin Y, Pang S, Fu L. Named Entity Recognition in Government Audit Texts Based on ChineseBERT and Character-Word Fusion. Applied Sciences. 2024; 14(4):1425. https://doi.org/10.3390/app14041425
Chicago/Turabian StyleHuang, Baohua, Yunjie Lin, Si Pang, and Long Fu. 2024. "Named Entity Recognition in Government Audit Texts Based on ChineseBERT and Character-Word Fusion" Applied Sciences 14, no. 4: 1425. https://doi.org/10.3390/app14041425