
CRAS: Curriculum Regularization and Adaptive Semi-Supervised Learning with Noisy Labels


Abstract
:1. Introduction
- Proposal of CR: A robust warm-up method for handling noisy labels, which uses only reliable targets for regularization. The proposed CR builds on ELR+ and functions as a potent warm-up technique specifically tailored to noisy labels. In comparison with ELR+, this method offers an enhanced confidence during the warm-up phase for the hard samples, which in turn improves the model’s overall performance. In CRAS, the model trained by CR is used for sample selection. This differs from existing methods, which use the model trained by cross-entropy.
- Development of adaptive SSL: AWL replaces the weights of the unsupervised loss used in existing combined sample selection and semi-supervised learning methods with the weights that we designed. This approach achieves SSL, which is highly robust to noisy labels by monitoring the bias of training data at each epoch, which has not previously been considered, and by adjusting the weights of unlabeled losses with an AWL.
2. Related Work
2.1. Learning with Noisy Labels
2.2. Robust Learning Algorithms
2.3. Noise Detection Algorithms
2.4. Semi-Supervised Learning
2.5. Semi-Supervised Learning with Noisy Labels
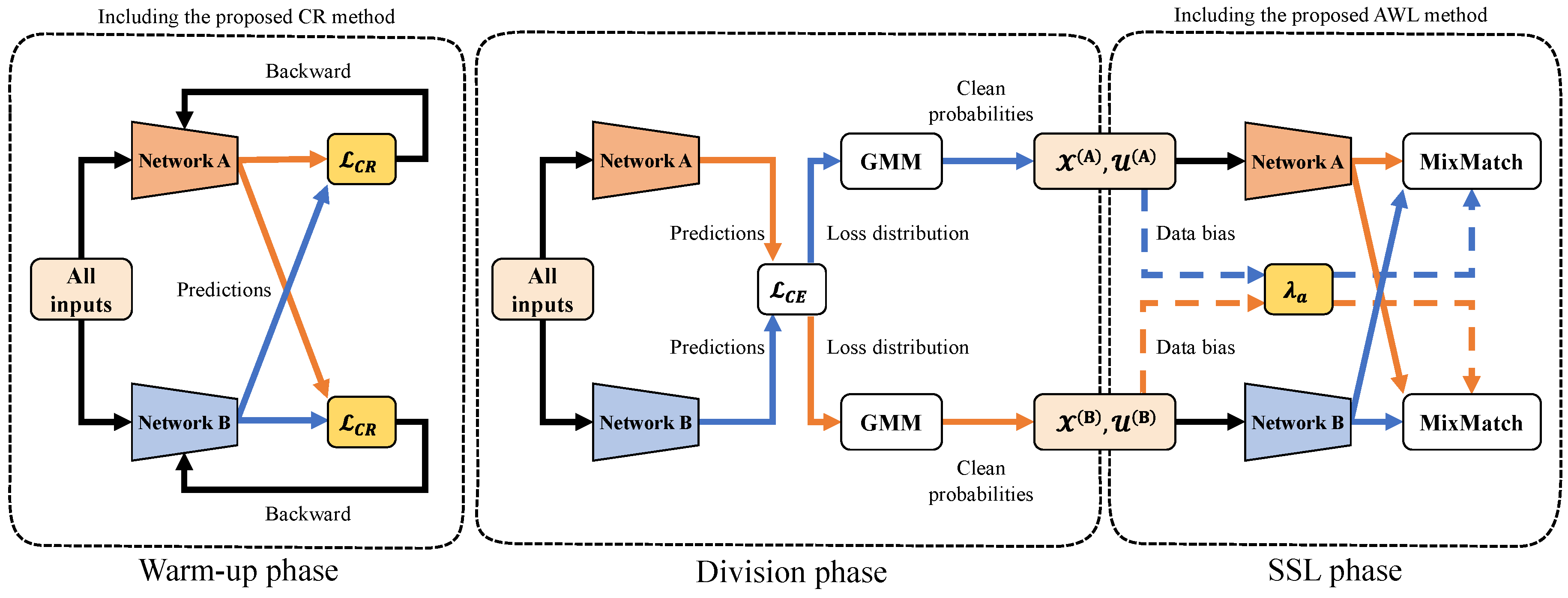
3. Proposed Method
| Algorithm 1 Curriculum Regularization |
| Require: batch size B, training data , temporal ensembling momentum , weight averaging momentum , regularization parameter , mixup hyperparameter , confidence threshold , network parameters
|
3.1. Curriculum Regularization
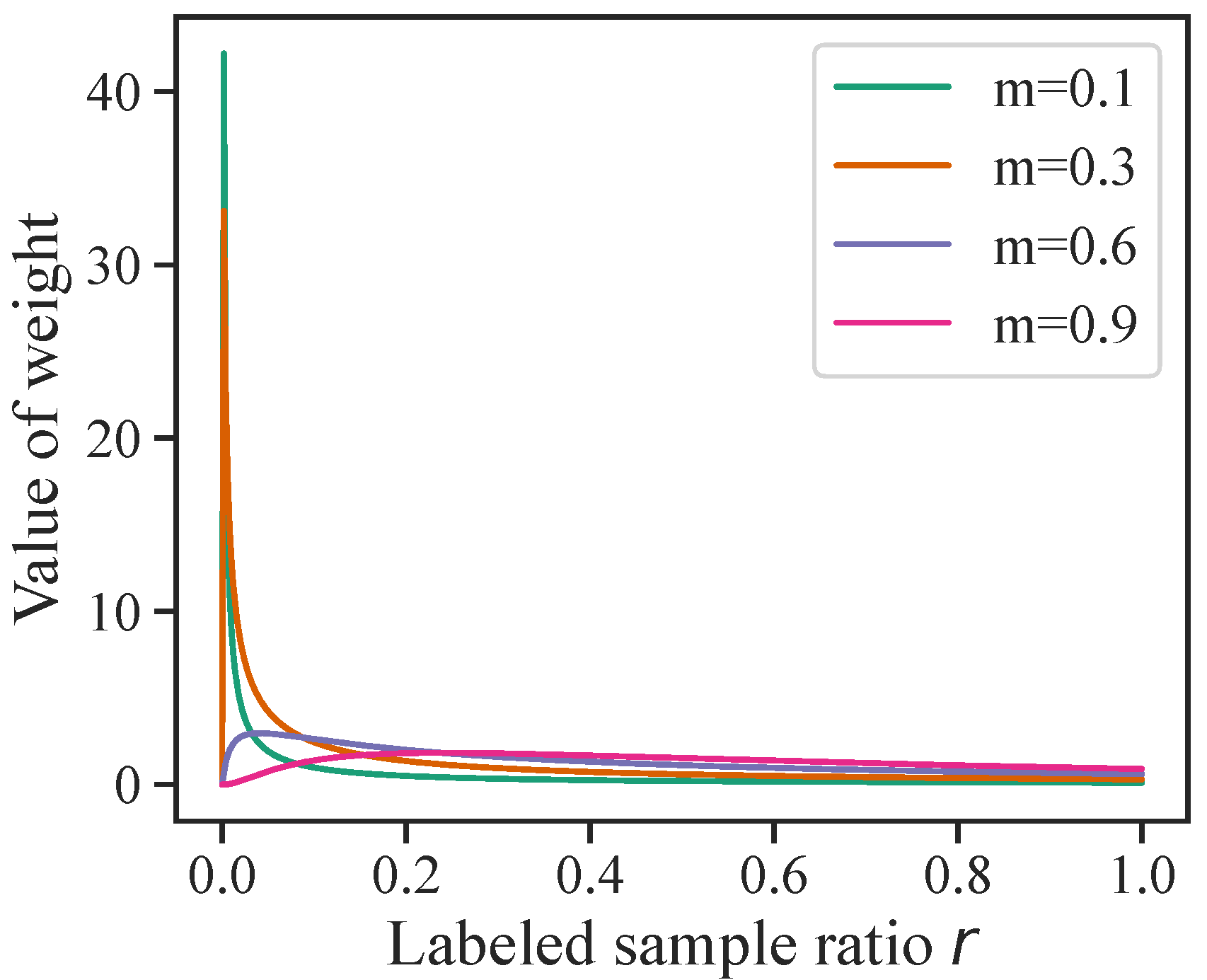
3.2. Adaptive Weighted Loss for Data Bias
4. Experiments
4.1. Datasets and Implementation Details
4.1.1. Simulated Noisy Datasets
4.1.2. Real-World Datasets
4.1.3. Comparative Methods
- PENCIL [34]: A method that iteratively updates class probabilities and refines noisy labels by minimizing the difference between the estimated class distribution and the class distribution predicted by the network.
- Joint-Optim [33]: A method that estimates true labels from network predictions and relabels samples for explicit loss correction.
- Iterative-CV [20]: A method that iteratively applies cross-validation to noisy labeled datasets to improve label quality and model performance.
- CORES [62]: A method that uses a data reweighting mechanism and an iterative learning process to identify and reweight clean and noisy samples, thereby enhancing the learning process.
4.2. Results on Simulated Noisy Datasets
4.3. Results on Real-World Datasets
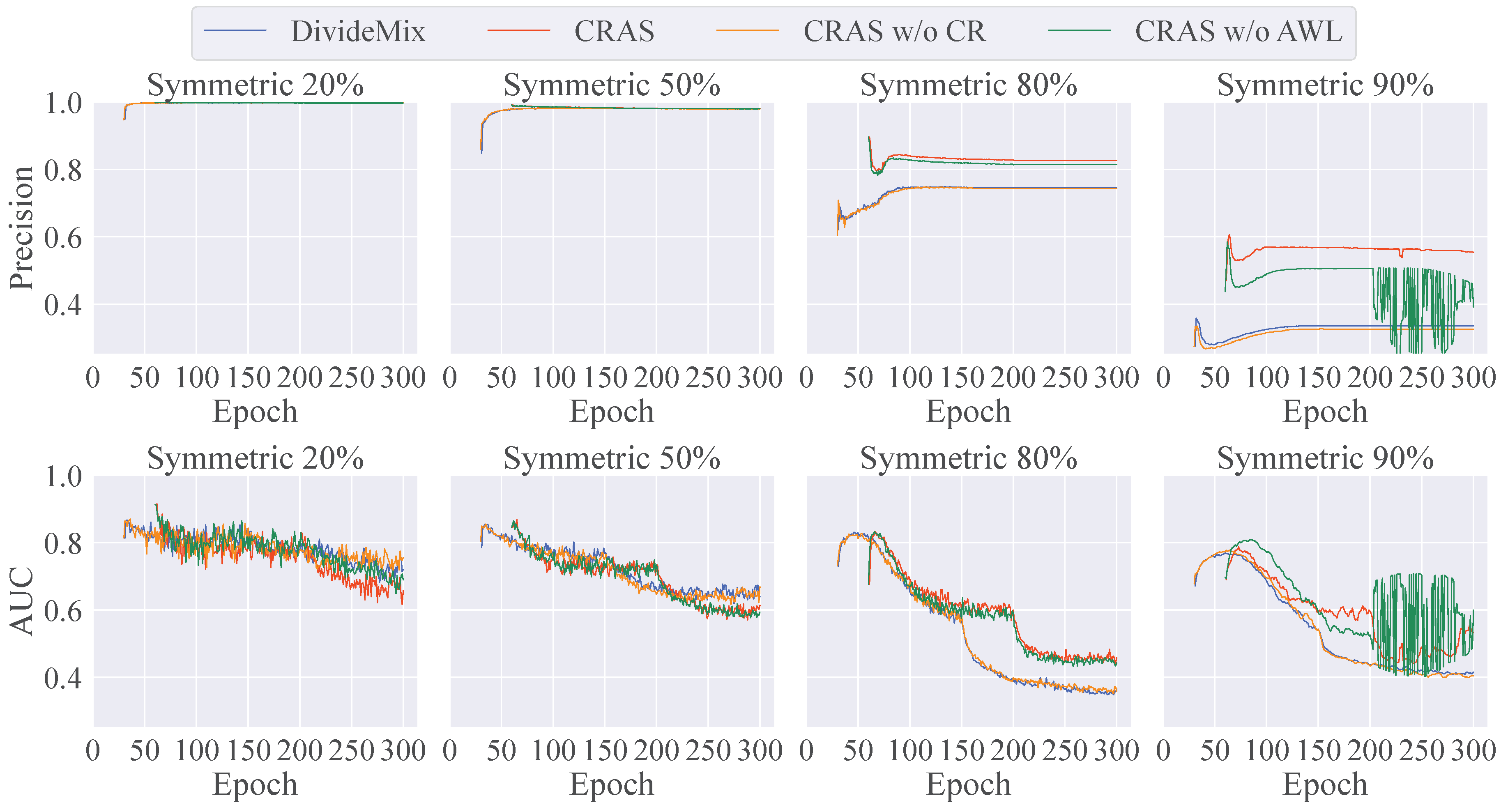
4.4. Ablation Study
4.4.1. Influence of Each Component
- To study the influence of CR, we trained two networks (with and without CR) using a standard warm-up. CRAS without CR demonstrated a degraded performance for all of the noise rates. As the noise rate increased, CRAS without CR outperformed DivideMix, suggesting that AWL helps prevent overfitting to a small number of labels. In contrast with DivideMix, CRAS without CR consistently performed better than, or as well as, DivideMix, despite using the same hyperparameters for all of the noise patterns. In real environments, it is difficult to identify the proportion of noise in datasets. Therefore, these results demonstrate that AWL is robust to unknown noise rates.
- To study the influence of AWL, we trained a network (without AWL) using CR as a warm-up for DivideMix. Although the performance degradation was relatively small, it was more pronounced for higher noise rates. These results suggest that CR has a more significant impact on performance than AWL and that the warm-up performance is crucial for the combined sample selection and SSL strategy. However, CR results in a significant decrease in accuracy without AWL for 90% label noise. These results are discussed in Section 4.4.2.
- The effectiveness of CR compared with ELR+ was evaluated by comparing the results of CRAS without AWL to those of DivideMix and ELR+ combined. For noise rates other than 50%, CR performed notably better than ELR+, thereby demonstrating its superior effectiveness.
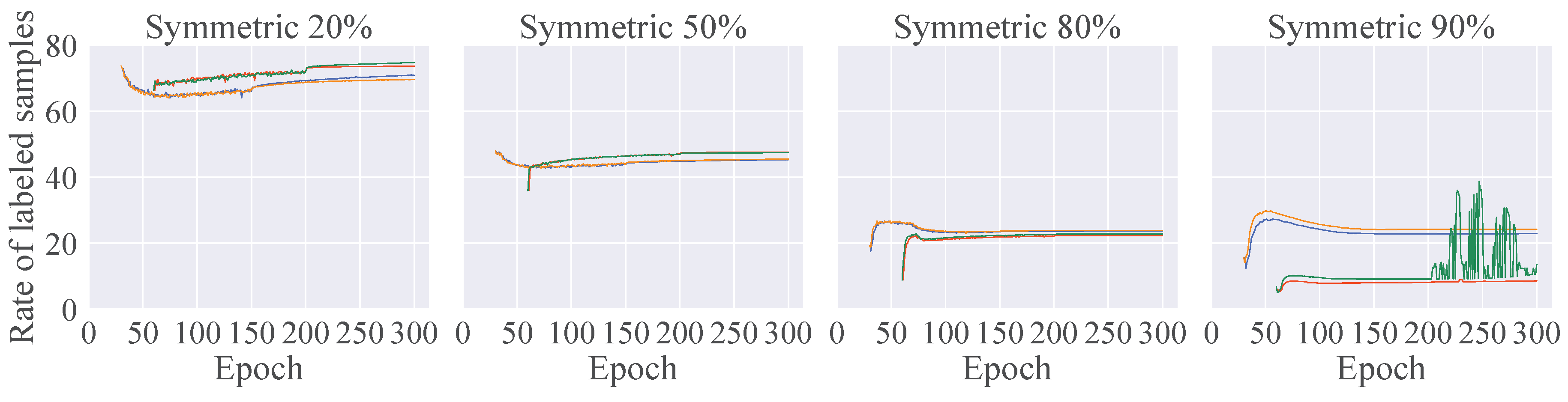
4.4.2. Analysis of the Numbers of Clean Labels and Labeled Samples
4.4.3. Comparison of Training Time
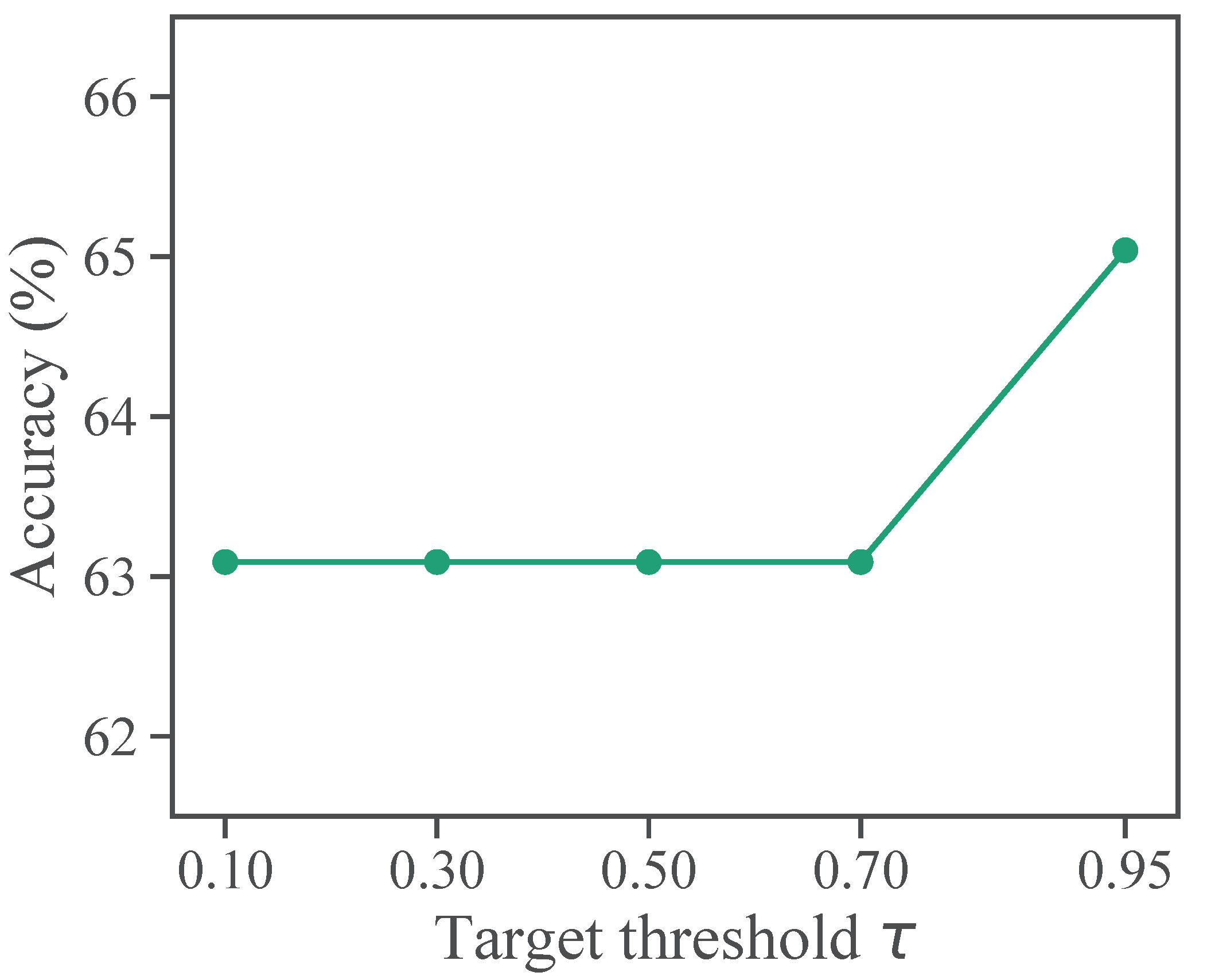
4.5. Sensitivity to Hyperparameters
4.6. Limitations
- CR is designed for cases in which memorization occurs during the warm-up phase, causing the network to fit noisy labels. However, on a dataset such as CIFAR-10, where the number of classes is small and the noise rate is as low as 20%, the network may be well-trained before memorization takes place.
- AWL is intended for cases in which the number of labels per class is small, leading to overfitting to a limited number of labels. On CIFAR-10 with 20% symmetric noise and 40% asymmetric noise, the number of labels per class may be sufficient, and the network’s training may be hindered by increased regularization. Under these situations, it is desired that regularization by unsupervised loss in (15) does not contribute to learning, i.e., it is set at , but in this case, AWL has no effect.
5. Conclusions
- CR:
- –
- CRAS implements a specialized warm-up phase using CR, diverging from conventional methods. This phase is carefully designed to progressively adjust to the complexity of the training data, focusing on datasets affected by noisy labels.
- –
- The critical aspect of this approach is the application of regularization at the onset of training. Regularization effectively counters the tendency of the network to fit to noisy labels prematurely; such overfitting is a prevalent challenge in standard training approaches.
- AWL:
- –
- In the SSL framework of CRAS, the AWL component improves on traditional static loss-weighting methods. It dynamically modifies the loss weights according to the detected bias in the data.
- –
- This dynamic property is vital for aligning the network’s training with the most dependable data. AWL’s adaptability to different noise levels and data distributions significantly improves the effectiveness of the learning process in a variety of scenarios.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Tahoe City, CA, USA, 3–8 December 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; Wang, X. Learning from Massive Noisy Labeled Data for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2691–2699. [Google Scholar]
- Ge, S.; Zhang, C.; Li, S.; Zeng, D.; Tao, D. Cascaded Correlation Refinement for Robust Deep Tracking. In Proceedings of the Transactions on Neural Networks and Learning Systems; IEEE: Piscataway, NJ, USA, 2020; Volume 32, pp. 1276–1288. [Google Scholar]
- Chen, H.; Han, F.X.; Niu, D.; Liu, D.; Lai, K.; Wu, C.; Xu, Y. Mix: Multi-channel Information Crossing for Text Matching. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 110–119. [Google Scholar]
- Yu, X.; Liu, T.; Gong, M.; Tao, D. Learning with Biased Complementary Labels. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; van der Maaten, L. Exploring the Limits of Weakly Supervised Pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. [Google Scholar] [CrossRef]
- Tanno, R.; Saeedi, A.; Sankaranarayanan, S.; Alexander, D.C.; Silberman, N. Learning From Noisy Labels by Regularized Estimation of Annotator Confusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yan, Y.; Rosales, R.; Fung, G.; Subramanian, R.; Dy, J. Learning from Multiple Annotators with Varying Expertise. Mach. Learn. 2014, 95, 291–327. [Google Scholar] [CrossRef]
- Song, H.; Kim, M.; Lee, J.G. Selfie: Refurbishing Unclean Samples for Robust Deep Learning. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5907–5915. [Google Scholar]
- Li, W.; Wang, L.; Li, W.; Agustsson, E.; Gool, L.V. WebVision Database: Visual Learning and Understanding from Web Data. arXiv 2017, arXiv:1708.02862. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding Deep Learning Requires Rethinking Generalization. arXiv 2017, arXiv:1611.03530. [Google Scholar] [CrossRef]
- Arpit, D.; Jastrzebski, S.K.; Ballas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.C.; Bengio, Y.; et al. A Closer Look at Memorization in Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 233–242. [Google Scholar]
- Chen, X.; Gupta, A. Webly Supervised Learning of Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Goldberger, J.; Ben-Reuven, E. Training Deep Neural-networks Using a Noise Adaptation Layer. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Ghosh, A.; Kumar, H.; Sastry, P.S. Robust Loss Functions Under Label Noise for Deep Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1919–1925. [Google Scholar]
- Lyu, Y.; Tsang, I.W. Curriculum Loss: Robust Learning and Generalization against Label Corruption. arXiv 2020, arXiv:1905.10045v3. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. In Proceedings of the Annual Conference on Neural Information Processing Systems 2018—NeurIPS 2018, Montreal, QC, Canada, 3–8 December 2018; pp. 8792–8802. [Google Scholar]
- Zhou, X.; Liu, X.; Jiang, J.; Gao, X.; Ji, X. Asymmetric Loss Functions for Learning with Noisy Labels. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 12846–12856. [Google Scholar]
- Chen, P.; Liao, B.B.; Chen, G.; Zhang, S. Understanding and Utilizing Deep Neural Networks Trained with Noisy Labels. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 1062–1070. [Google Scholar]
- Jiang, L.; Zhou, Z.; Leung, T.; Li, L.J.; Li, F.-F. MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2309–2318. [Google Scholar]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018; pp. 8536–8546. [Google Scholar]
- Yu, X.; Han, B.; Yao, J.; Niu, G.; Tsang, I.; Sugiyama, M. How does Disagreement Help Generalization against Label Corruption? In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7164–7173. [Google Scholar]
- Liu, S.; Niles-Weed, J.; Razavian, N.; Fernandez-Granda, C. Early-Learning Regularization Prevents Memorization of Noisy Labels. In Proceedings of the Annual Conference on Neural Information Processing Systems 2020—NeurIPS 2020, Virtual Event, 6–12 December 2020; pp. 20331–20342. [Google Scholar]
- Li, J.; Socher, R.; Hoi, S.C. DivideMix: Learning with Noisy Labels as Semi-supervised Learning. arXiv 2020, arXiv:2002.07394. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, Department of Computer Science, University of Toronto, Toronto, ON, Canada, 2009. [Google Scholar]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Xu, J.; Cheng, X. DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval. In Proceedings of the ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 257–266. [Google Scholar]
- Onal, K.D.; Zhang, Y.; Altingovde, I.S.; Rahman, M.M.; Karagoz, P.; Braylan, A.; Dang, B.; Chang, H.L.; Kim, H.; McNamara, Q.; et al. Neural information retrieval: At the end of the early years. Inf. Retr. J. 2018, 21, 111–182. [Google Scholar] [CrossRef]
- Ren, W.; Pan, J.; Zhang, H.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-scale Convolutional Neural Networks with Holistic Edges. Int. J. Comput. Vis. 2020, 128, 240–259. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Tan, J.; Li, Y. Multi-Purpose Oriented Single Nighttime Image Haze Removal Based on Unified Variational Retinex Model. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1643–1657. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Chen, S.; Ye, T.; Ren, W.; Chen, E. NightHazeFormer: Single Nighttime Haze Removal Using Prior Query Transformer. In Proceedings of the ACM International Conference on Multimedia, Otawa, ON, Canada, 29 October–3 November 2023; pp. 4119–4128. [Google Scholar]
- Menon, A.K.; Rawat, A.S.; Kumar, S.; REddi, S. Can gradient clipping mitigate label noise? In Proceedings of the ICLR 2020 Conference Blind Submission, Addis Ababa, Ethiopia, 1 August–25 September 2019. [Google Scholar]
- Tanaka, D.; Ikami, D.; Yamasaki, T.; Aizawa, K. Joint Optimization Framework for Learning with Noisy Labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yi, K.; Wu, J. Probabilistic End-To-End Noise Correction for Learning with Noisy Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Han, J.; Luo, P.; Wang, X. Deep Self-Learning From Noisy Labels. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, Y.; Zheng, S.; Wu, P.; Goswami, M.; Chen, C. Learning with Feature-Dependent Label Noise: A Progressive Approach. arXiv 2021, arXiv:2103.07756. [Google Scholar]
- Zheng, S.; Wu, P.; Goswami, A.; Goswami, M.; Metaxas, D.; Chen, C. Error-bounded Correction of Noisy Labels. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 11447–11457. [Google Scholar]
- Cordeiro, F.R.; Sachdeva, R.; Belagiannis, V.; Reid, I.; Carneiro, G. LongReMix: Robust Learning with High Confidence Samples in a Noisy Label environment. Pattern Recognit. 2023, 133, 109013. [Google Scholar] [CrossRef]
- Patrini, G.; Rozza, A.; Krishna Menon, A.; Nock, R.; Qu, L. Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.E.; McGuinness, K. Unsupervised Label Noise Modeling and Loss Correction. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 312–321. [Google Scholar]
- Malach, E.; Shalev-Shwartz, S. Decoupling “when to update” from “how to update”. In Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 961–971. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Oliver, A.; Papernot, N.; Raffel, C. MixMatch: A Holistic Approach to Semi-Supervised Learning. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 5049–5059. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. ReMixMatch: Semi-Supervised Learning with Distribution Matching and Augmentation Anchoring. In Proceedings of the The 8th International Conference on Learning Representations, Virtual Event, 26 April–1 May 2020. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual Event, 6–12 December 2020; pp. 596–608. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Zhang, B.; Wang, Y.; Hou, W.; Wu, H.; Wang, J.; Okumura, M.; Shinozaki, T. FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual Event, 6–14 December 2021; pp. 18408–18419. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. arXiv 2016, arXiv:1610.02242. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean Teachers are Better Role Models: Weight-averaged Consistency Targets Improve Semi-supervised Deep Learning Results. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 1195–1204. [Google Scholar]
- Ding, Y.; Wang, L.; Fan, D.; Gong, B. A Semi-Supervised Two-Stage Approach to Learning from Noisy Labels. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Tahoe City, NV, USA, 12–15 March 2018; pp. 1215–1224. [Google Scholar]
- Kong, K.; Lee, J.; Kwak, Y.; Kang, M.; Kim, S.G.; Song, W.J. Recycling: Semi-Supervised Learning with Noisy Labels in Deep Neural Networks. IEEE Access 2019, 7, 66998–67005. [Google Scholar] [CrossRef]
- Ortego, D.; Arazo, E.; Albert, P.; O’Connor, N.E.; McGuinness, K. Multi-Objective Interpolation Training for Robustness To Label Noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6606–6615. [Google Scholar]
- van Rooyen, B.; Menon, A.; Williamson, R.C. Learning with Symmetric Label Noise: The Importance of Being Unhinged. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Scott, C.; Blanchard, G.; Handy, G. Classification with Asymmetric Label Noise: Consistency and Maximal Denoising. In Proceedings of the Annual Conference on Learning Theory, Princeton, NJ, USA, 12–14 June 2013; Volume 30, pp. 489–511. [Google Scholar]
- Menon, A.K.; van Rooyen, B.; Natarajan, N. Learning from Binary Labels with Instance-Dependent Corruption. arXiv 2016, arXiv:1605.00751. [Google Scholar]
- Garg, A.; Nguyen, C.; Felix, R.; Do, T.T.; Carneiro, G. Instance-Dependent Noisy Label Learning via Graphical Modelling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 2288–2298. [Google Scholar]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M.S. Learning to Learn From Noisy Labeled Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5051–5059. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Lee, J. Prestopping: How Does Early Stopping Help Generalization against Label Noise? arXiv 2019, arXiv:1911.08059. [Google Scholar]
- Chen, P.; Ye, J.; Chen, G.; Zhao, J.; Heng, P.A. Beyond Class-Conditional Assumption: A Primary Attempt to Combat Instance-Dependent Label Noise. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 11442–11450. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning From Noisy Labels with Deep Neural Networks: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8135–8153. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the 31st Conference on Artificial Intelligence (AAAI-17), San Francisko, CA, USA, 4–9 February 2017; Volume 31, pp. 4278–4284. [Google Scholar]
- Cheng, H.; Zhu, Z.; Li, X.; Gong, Y.; Sun, X.; Liu, Y. Learning with Instance-Dependent Label Noise: A Sample Sieve Approach. arXiv 2020, arXiv:2010.02347. [Google Scholar]
- Feng, C.; Ren, Y.; Xie, X. OT-Filter: An Optimal Transport Filter for Learning with Noisy Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 16164–16174. [Google Scholar]
- Li, Y.; Han, H.; Shan, S.; Chen, X. DISC: Learning From Noisy Labels via Dynamic Instance-Specific Selection and Correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, USA, 18–22 June 2023; pp. 24070–24079. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- Zheng, M.; You, S.; Huang, L.; Wang, F.; Qian, C.; Xu, C. SimMatch: Semi-Supervised Learning with Similarity Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14471–14481. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Val | Test | Image Size | Classes |
|---|---|---|---|---|---|
| Simulated datasets with clean annotations | |||||
| CIFAR-10 | 50 k | - | 10 k | 32 × 32 | 10 |
| CIFAR-100 | 50 k | - | 10 k | 32 × 32 | 100 |
| Datasets with real world annotations | |||||
| Clothing1M | 1M | 14 k | 10 k | 224 × 224 | 14 |
| WebVision1.0 | 66 k | 2.5 k | - | 256 × 256 | 50 |
| ILSVRC12 | - | 2.5 k | - | 256 × 256 | 50 |
| Dataset | CIFAR-10 | CIFAR-100 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Noise Type | Sym. | Asym. | Sym. | Asym. | ||||||||
| Method/Noise Ratio | 20% | 50% | 80% | 90% | 40% | 20% | 50% | 80% | 90% | 40% | ||
| Cross-Entropy | Best | 86.8 | 79.4 | 62.9 | 42.7 | 85.0 | 62.0 | 46.7 | 19.9 | 10.1 | - | |
| Last | 82.7 | 57.9 | 26.1 | 16.8 | 72.3 | 61.8 | 37.3 | 8.8 | 3.5 | - | ||
| Mixup () [45] | Best | 95.6 | 87.1 | 71.6 | 52.2 | - | 67.8 | 57.3 | 30.8 | 14.6 | - | |
| Last | 92.3 | 77.6 | 46.7 | 43.9 | - | 66.0 | 46.6 | 17.6 | 8.1 | - | ||
| Co-teaching+() [23] | Best | 89.5 | 85.7 | 67.4 | 47.9 | - | 65.6 | 51.8 | 27.9 | 13.7 | - | |
| Last | 88.2 | 77.6 | 45.5 | 30.1 | - | 64.1 | 45.3 | 15.5 | 8.8 | - | ||
| PENCIL () [34] | Best | 92.4 | 89.1 | 77.5 | 58.9 | 88.5 | 69.4 | 57.5 | 31.1 | 15.3 | - | |
| Last | 92.0 | 88.7 | 76.5 | 58.2 | 88.1 | 68.1 | 56.4 | 20.7 | 8.8 | - | ||
| DivideMix () [25] | Best | 96.1 | 94.6 | 93.2 | 76.0 | 93.4 | 77.3 | 74.6 | 60.2 | 31.5 | 60.8 | |
| Last | 95.7 | 94.4 | 92.9 | 75.4 | 92.1 | 76.9 | 74.2 | 59.6 | 31.0 | 55.5 | ||
| MOIT () [51] | Best | - | - | - | - | - | - | - | - | - | - | |
| Last | 93.1 | 90.0 | 79.0 | 69.6 | 92.0 | 73.0 | 64.6 | 46.6 | 36.0 | 55.0 | ||
| LongReMix () [38] | Best | 96.3 ± 0.1 | 95.1 ± 0.1 | 93.8 ± 0.2 | 79.9 ± 2.7 | 94.7 ± 0.1 | 77.9 ± 0.2 | 75.5 ± 0.2 | 62.3 ± 0.5 | 34.7 ± 0.3 | 59.8 ± 0.1 | |
| Last | 96.0 ± 0.1 | 94.8 ± 0.1 | 93.3 ± 0.2 | 79.1 ± 3.1 | 94.3 ± 0.1 | 77.5 ± 0.2 | 74.9 ± 0.2 | 61.7 ± 0.5 | 30.7 ± 5.9 | 54.9 ± 0.4 | ||
| CRAS | Best | 95.7 ± 0.1 | 95.4 ± 0.0 | 93.8 ± 0.0 | 80.0 ± 0.7 | 93.1 ± 0.0 | 79.5 ± 0.0 | 77.0 ± 0.1 | 65.0 ± 0.0 | 34.5 ± 0.5 | 78.0 ± 0.1 | |
| Last | 95.5 ± 0.1 | 95.1 ± 0.1 | 93.5 ± 0.0 | 78.9 ± 0.8 | 91.9 ± 0.1 | 79.0 ± 0.0 | 76.5 ± 0.1 | 64.7 ± 0.0 | 34.1 ± 0.6 | 77.6 ± 0.2 | ||
| Method | Test Accuracy (%) |
|---|---|
| Cross-Entropy | 69.21 |
| Joint-Optim () [33] | 72.16 |
| M_correction () [40] | 71.00 |
| DivideMix * () [25] | 74.11 |
| ELR+ * () [24] | 74.45 |
| CORES () [62] | 73.24 |
| LongReMix () [38] | 74.38 |
| CRAS | 74.54 |
| WebVision | ILSVRC12 | |||
|---|---|---|---|---|
| Top1 | Top5 | Top1 | Top5 | |
| Decoupling () [41] | 62.54 | 84.74 | 58.26 | 82.26 |
| MentorNet () [21] | 63.00 | 81.40 | 57.80 | 79.92 |
| Co-teaching () [22] | 63.58 | 85.20 | 61.48 | 84.70 |
| F-correction () [34] | 61.12 | 82.68 | 57.36 | 82.36 |
| Interactive-CV () [20] | 65.24 | 85.34 | 61.60 | 84.98 |
| DivideMix () [25] | 77.32 | 91.64 | 75.20 | 90.84 |
| ELR+ () [24] | 77.78 | 91.68 | 70.29 | 89.76 |
| MOIT () [51] | 77.90 | 91.90 | 73.80 | 91.70 |
| LongReMix () [38] | 78.92 | 92.32 | - | - |
| CRAS | 78.60 | 93.00 | 76.72 | 92.88 |
| Method/Noise Ratio | 20% | 50% | 80% | 90% | |
|---|---|---|---|---|---|
| CRAS | Best | 79.5 | 76.9 | 65.0 | 33.8 |
| Last | 79.0 | 76.4 | 64.7 | 33.3 | |
| CRAS w/o CR | Best | 77.0 | 74.8 | 60.6 | 32.8 |
| Last | 76.5 | 74.3 | 60.3 | 32.1 | |
| CRAS w/o AWL | Best | 79.5 | 75.8 | 64.5 | 29.2 |
| Last | 78.9 | 75.3 | 64.2 | 28.6 | |
| DivideMix and ELR+ | Best | 78.1 | 75.8 | 60.2 | 28.0 |
| Last | 77.8 | 75.3 | 59.9 | 27.7 |
| Method | DivideMix [25] | CRAS |
|---|---|---|
| Time (hours) | 3.5 | 3.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Higashimoto, R.; Yoshida, S.; Muneyasu, M. CRAS: Curriculum Regularization and Adaptive Semi-Supervised Learning with Noisy Labels. Appl. Sci. 2024, 14, 1208. https://doi.org/10.3390/app14031208
Higashimoto R, Yoshida S, Muneyasu M. CRAS: Curriculum Regularization and Adaptive Semi-Supervised Learning with Noisy Labels. Applied Sciences. 2024; 14(3):1208. https://doi.org/10.3390/app14031208
Chicago/Turabian StyleHigashimoto, Ryota, Soh Yoshida, and Mitsuji Muneyasu. 2024. "CRAS: Curriculum Regularization and Adaptive Semi-Supervised Learning with Noisy Labels" Applied Sciences 14, no. 3: 1208. https://doi.org/10.3390/app14031208