
Improving Time Study Methods Using Deep Learning-Based Action Segmentation Models

Abstract
:1. Introduction
2. Related Work
3. Problem Formulation
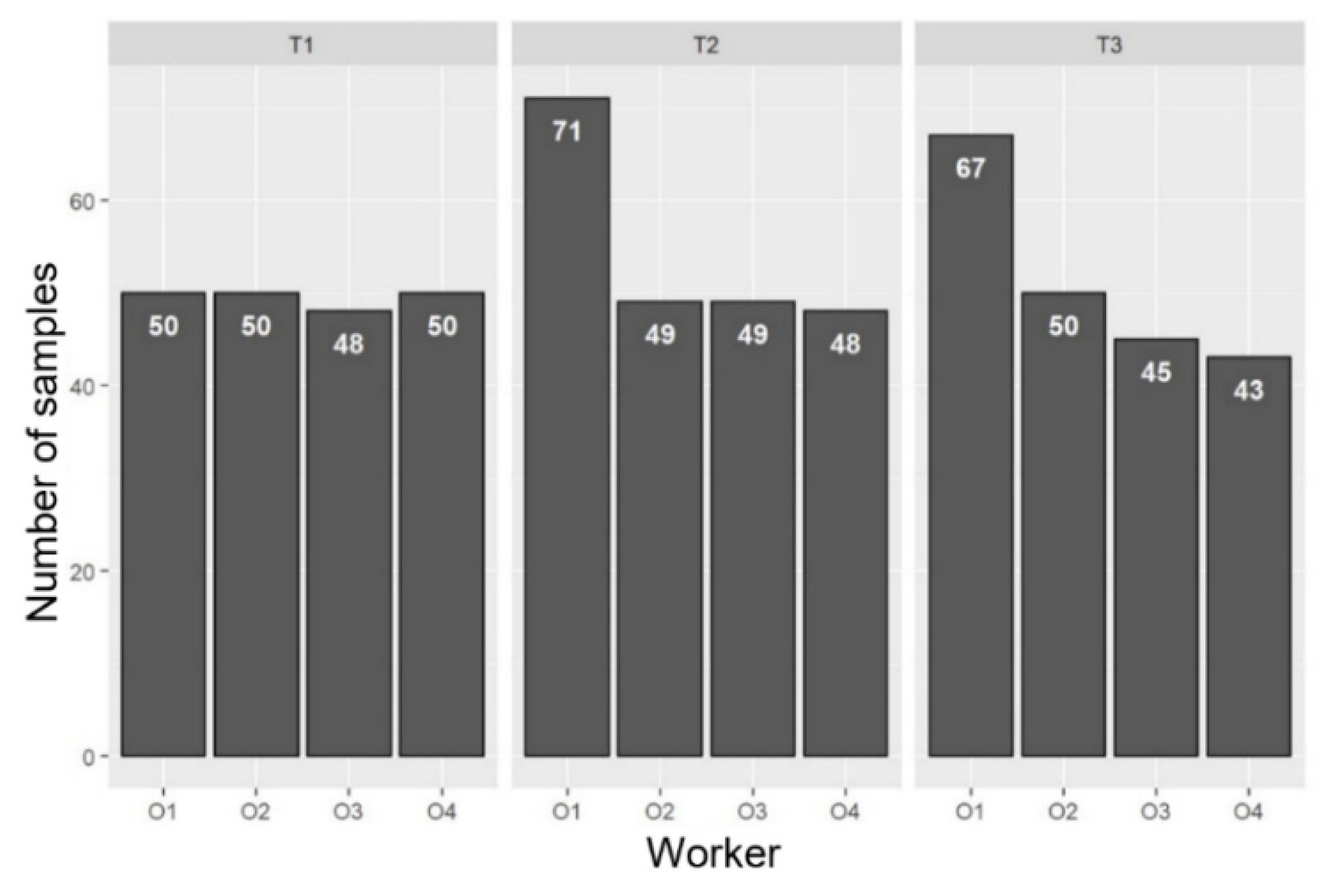
4. Dataset
5. Methodology
5.1. Feature Extraction Methods
- Feat. extraction from a pretrained model without fine-tuning (FE);
- Feat. extraction from a pretrained model with fine-tuning on our dataset (FT);
- Feat. extraction from a new 2D CNN model trained only on our dataset (TN).
5.2. Action Segmentation Models
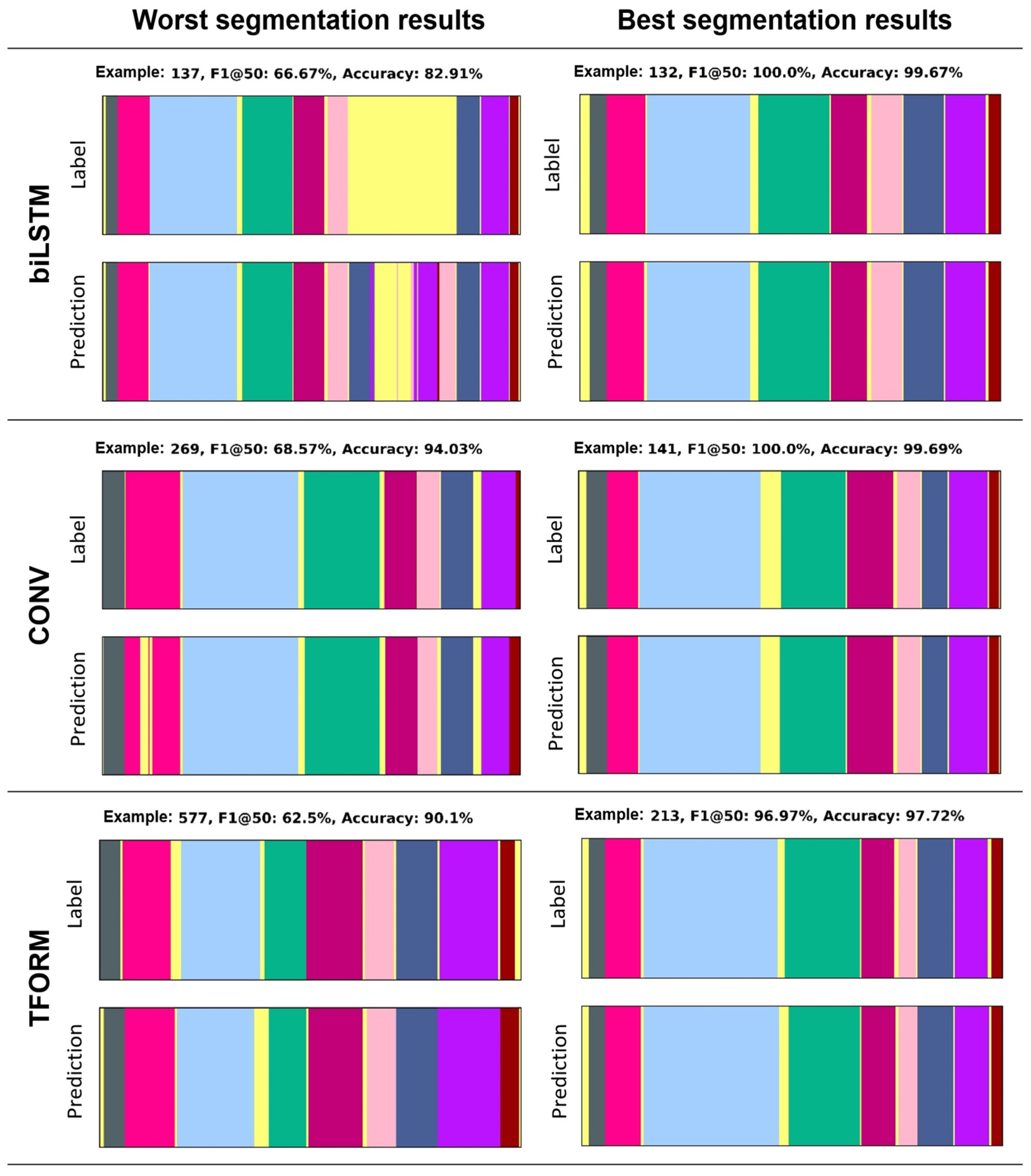
6. Evaluation
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Romero, D.; Bernus, P.; Noran, O.; Stahre, J.; Fast-Berglund, Å. The Operator 4.0: Human Cyber-Physical Systems & Adaptive Automation towards Human-Automation Symbiosis Work Systems. In Advances in Production Management Systems. Initiatives for a Sustainable World; Nääs, I., Vendrametto, O., Mendes Reis, J., Gonçalves, R.F., Silva, M.T., von Cieminski, G., Kiritsis, D., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 488, pp. 677–686. [Google Scholar] [CrossRef]
- Xu, L.D.; Duan, L. Big data for cyber physical systems in industry 4.0: A survey. Enterp. Inf. Syst. 2019, 13, 148–169. [Google Scholar] [CrossRef]
- Pfeiffer, S. Robots, Industry 4.0 and Humans, or Why Assembly Work Is More than Routine Work. Societies 2016, 6, 16. [Google Scholar] [CrossRef]
- Posada, J.; Zorrilla, M.; Dominguez, A.; Simoes, B.; Eisert, P.; Stricker, D.; Rambach, J.; Döllner, J.; Guevara, M. Graphics and Media Technologies for Operators in Industry 4.0. IEEE Comput. Graph. Appl. 2018, 38, 119–132. [Google Scholar] [CrossRef]
- Abdullah, R.; Abdul Rahman, M.d.N.; Salleh Mohd, R. A systematic approach to model human system in cellular manufacturing. J. Adv. Mech. Des. Syst. Manuf. 2019, 13, JAMDSM0001. [Google Scholar] [CrossRef]
- Rude, D.J.; Adams, S.; Beling, P.A. Task recognition from joint tracking data in an operational manufacturing cell. J. Intell. Manuf. 2018, 29, 1203–1217. [Google Scholar] [CrossRef]
- Jiang, Q.; Liu, M.; Wang, X.; Ge, M.; Lin, L. Human motion segmentation and recognition using machine vision for mechanical assembly operation. SpringerPlus 2016, 5, 1629. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A Review on Human Activity Recognition Using Vision-Based Method. J. Healthc. Eng. 2017, 2017, 3090343. [Google Scholar] [CrossRef]
- Zhu, F.; Shao, L.; Xie, J.; Fang, Y. From handcrafted to learned representations for human action recognition: A survey. Image Vis. Comput. 2016, 55, 42–52. [Google Scholar] [CrossRef]
- Ding, G.; Sener, F.; Yao, A. Temporal Action Segmentation: An Analysis of Modern Techniques. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1011–1030. [Google Scholar] [CrossRef]
- Li, S.-J.; AbuFarha, Y.; Liu, Y.; Cheng, M.-M.; Gall, J. MS-TCN++: Multi-Stage Temporal Convolutional Network for Action Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 45, 6647–6658. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1003–1012. [Google Scholar] [CrossRef]
- Singh, B.; Marks, T.K.; Jones, M.; Tuzel, O.; Shao, M. A Multi-stream Bi-directional Recurrent Neural Network for Fine-Grained Action Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1961–1970. [Google Scholar] [CrossRef]
- Ding, L.; Xu, C. TricorNet: A Hybrid Temporal Convolutional and Recurrent Network for Video Action Segmentation. arXiv 2017, arXiv:1705.07818. [Google Scholar]
- Bai, R.; Zhao, Q.; Zhou, S.; Li, Y.; Zhao, X.; Wang, J. Continuous Action Recognition and Segmentation in Untrimmed Videos. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2534–2539. [Google Scholar] [CrossRef]
- Lei, P.; Todorovic, S. Temporal Deformable Residual Networks for Action Segmentation in Videos. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6742–6751. [Google Scholar] [CrossRef]
- Ma, S.; Sigal, L.; Sclaroff, S. Learning Activity Progression in LSTMs for Activity Detection and Early Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1942–1950. [Google Scholar] [CrossRef]
- Bodenstedt, S.; Rivoir, D.; Jenke, A.; Wagner, M.; Breucha, M.; Müller-Stich, B.; Mees, S.T.; Weitz, J.; Speidel, S. Active learning using deep Bayesian networks for surgical workflow analysis. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1079–1087. [Google Scholar] [CrossRef]
- Jin, Y.; Dou, Q.; Chen, H.; Yu, L.; Qin, J.; Fu, C.W.; Heng, P.A. SV-RCNet: Workflow Recognition from Surgical Videos Using Recurrent Convolutional Network. IEEE Trans. Med. Imaging 2018, 37, 1114–1126. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Shen, X.; Qiao, P.; Li, S.; Li, D.; Dou, Y. Exploring frame segmentation networks for temporal action localization. J. Vis. Commun. Image Represent. 2019, 61, 296–302. [Google Scholar] [CrossRef]
- Yang, H.; He, X.; Porikli, F. Instance-Aware Detailed Action Labeling in Videos. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1577–1586. [Google Scholar] [CrossRef]
- Montes, A.; Salvador, A.; Giró-i-Nieto, X. Temporal Activity Detection in Untrimmed Videos with Recurrent Neural Networks. arXiv 2016, arXiv:1608.08128. [Google Scholar]
- Shou, Z.; Chan, J.; Zareian, A.; Miyazawa, K.; Chang, S.-F. CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Farha, Y.A.; Gall, J. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3575–3584. [Google Scholar]
- Ishikawa, Y.; Kasai, S.; Aoki, Y.; Kataoka, H. Alleviating Over-segmentation Errors by Detecting Action Boundaries. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2321–2330. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef]
- Ahn, H.; Lee, D. Refining Action Segmentation with Hierarchical Video Representations. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 16282–16290. [Google Scholar] [CrossRef]
- Kaku, A.; Liu, K.; Parnandi, A.; Rajamohan, H.R.; Venkataramanan, K.; Venkatesan, A.; Wirtanen, A.; Pandit, N.; Schambra, H.; Fernandez-Granda, C. Sequence-to-Sequence Modeling for Action Identification at High Temporal Resolution. arXiv 2021. [Google Scholar] [CrossRef]
- Yi, F.; Wen, H.; Jiang, T. ASFormer: Transformer for Action Segmentation. arXiv 2021, arXiv:2110.08568. [Google Scholar]
- Wang, J.; Wang, Z.; Zhuang, S.; Hao, Y.; Wang, H. Cross-enhancement transformer for action segmentation. Multimed Tools Appl. 2023. [Google Scholar] [CrossRef]
- Behrmann, N.; Golestaneh, S.A.; Kolter, Z.; Gall, J.; Noroozi, M. Unified Fully and Timestamp Supervised Temporal Action Segmentation via Sequence to Sequence Translation. In Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; Volume 13695, pp. 52–68. [Google Scholar] [CrossRef]
- Du, D.; Su, B.; Li, Y.; Qi, Z.; Si, L.; Shan, Y. Do We Really Need Temporal Convolutions in Action Segmentation? In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 1014–1019. [Google Scholar] [CrossRef]
- Makantasis, K.; Doulamis, A.; Doulamis, N.; Psychas, K. Deep learning based human behavior recognition in industrial workflows. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1609–1613. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Lalos, C.; Stentoumis, C. Human tracking driven activity recognition in video streams. In Proceedings of the 2016 IEEE International Conference on Imaging Systems and Techniques (IST), Chania, Greece, 4–6 October 2016; pp. 554–559. [Google Scholar] [CrossRef]
- Arbab-Zavar, B.; Carter, J.N.; Nixon, M.S. On hierarchical modelling of motion for workflow analysis from overhead view. Mach. Vis. Appl. 2014, 25, 345–359. [Google Scholar] [CrossRef]
- Zhang, M.; Hu, H.; Li, Z.; Chen, J. Attention-based encoder-decoder networks for workflow recognition. Multimed Tools Appl. 2021, 80, 34973–34995. [Google Scholar] [CrossRef]
- Kang, Z.; Cui, J.; Chu, Z. Manual assembly actions segmentation system using temporal-spatial-contact features. RIA 2023, 43, 509–522. [Google Scholar] [CrossRef]
- Voulodimos, A.; Kosmopoulos, D.; Vasileiou, G.; Sardis, E.; Anagnostopoulos, V.; Lalos, C.; Doulamis, A.; Varvarigou, T. A Threefold Dataset for Activity and Workflow Recognition in Complex Industrial Environments. IEEE Multimed. 2012, 19, 42–52. [Google Scholar] [CrossRef]
- Rude, D.J.; Adams, S.; Beling, P.A. A Benchmark Dataset for Depth Sensor Based Activity Recognition in a Manufacturing Process. IFAC-PapersOnLine 2015, 48, 668–674. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9908, pp. 630–645. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Smith, L.N. A disciplined approach to neural network hyper-parameters: Part 1–learning rate, batch size, momentum, and weight decay. arXiv 2018, arXiv:1803.09820. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label 1 | Hyperparameters | Set of Values Used |
|---|---|---|
| M | Number of biLSTM layers | |
| BiN | Number of neurons per biLSTM gate | |
| N | Number of additional fully connected layers | |
| FN | Number of neurons in additional fully connected layers | |
| DR | Dropout rate |
| Label 1 | Hyperparameters | Set of Values Used |
|---|---|---|
| D | Number of dilated residual layers | |
| DD | Number of dual dilated layers | |
| R | Number of refinement stages | |
| CK | Number of kernels in each CNN layer | |
| DR | Dropout rate |
| Label 1 | Hyperparameters | Set of Values Used |
|---|---|---|
| T | Number of Transformer encoder layers | |
| NH | Number of heads in multihead attention | |
| TN | Number of neurons in Transformer hidden layer | |
| FN | Number of neurons in two-layer feedforward network | |
| DR | Dropout rate |
| Model Type | Feature Type | Viewpoint | Number of Parameters | Accuracy | F1@50 |
|---|---|---|---|---|---|
| CONV * | TN | OH + HF | 511,572 | 97.84 | 93.64 |
| CONV | FT | OH + HF | 511,572 | 97.74 | 93.46 |
| biLSTM * | FT | OH + HF | 262,890 | 97.78 | 93.16 |
| CONV | FT | HF | 380,500 | 97.50 | 92.63 |
| CONV | TN | OH | 380,500 | 97.60 | 92.48 |
| biLSTM | FT | HF | 131,818 | 97.52 | 92.45 |
| CONV | TN | HF | 380,500 | 97.41 | 92.33 |
| biLSTM | TN | OH | 135,018 | 97.37 | 92.10 |
| biLSTM | TN | OH + HF | 262,890 | 97.66 | 91.80 |
| CONV | FE | HF | 380,500 | 96.97 | 90.49 |
| biLSTM | TN | HF | 131,818 | 97.24 | 90.39 |
| CONV | FE | OH + HF | 511,572 | 97.00 | 90.34 |
| CONV | FT | OH | 380,500 | 96.75 | 89.85 |
| biLSTM | FE | HF | 264,650 | 96.33 | 88.30 |
| CONV | FE | OH | 627,860 | 95.66 | 86.60 |
| biLSTM | FE | OH + HF | 1,057,674 | 96.18 | 85.59 |
| biLSTM | FT | OH | 131,818 | 95.53 | 84.48 |
| TFORM * | TN | OH | 8,960,778 | 96.14 | 83.50 |
| TFORM | FT | OH + HF | 5,268,234 | 96.45 | 83.17 |
| TFORM | TN | OH + HF | 17,918,730 | 94.41 | 82.83 |
| TFORM | FT | OH | 17,394,442 | 95.95 | 82.37 |
| TFORM | TN | HF | 8,960,778 | 96.06 | 81.62 |
| TFORM | FT | HF | 4,743,946 | 95.70 | 80.47 |
| TFORM | FE | OH + HF | 2,105,610 | 95.17 | 78.03 |
| TFORM | FE | HF | 4,743,946 | 95.42 | 78.02 |
| biLSTM | FE | OH | 25,194,506 | 90.38 | 76.14 |
| TFORM | FE | OH | 4,743,946 | 94.08 | 74.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gudlin, M.; Hegedić, M.; Golec, M.; Kolar, D. Improving Time Study Methods Using Deep Learning-Based Action Segmentation Models. Appl. Sci. 2024, 14, 1185. https://doi.org/10.3390/app14031185
Gudlin M, Hegedić M, Golec M, Kolar D. Improving Time Study Methods Using Deep Learning-Based Action Segmentation Models. Applied Sciences. 2024; 14(3):1185. https://doi.org/10.3390/app14031185
Chicago/Turabian StyleGudlin, Mihael, Miro Hegedić, Matija Golec, and Davor Kolar. 2024. "Improving Time Study Methods Using Deep Learning-Based Action Segmentation Models" Applied Sciences 14, no. 3: 1185. https://doi.org/10.3390/app14031185