1. Introduction
As network infrastructure continues to improve, traditional industries are moving towards networking, digitalization, and intelligence. This trend is leading to a rapid iteration in communication network technology to meet the increasing industrial capacity demands. However, behind this rapid development in network technology and infrastructure lies significant cybersecurity risks. The “2020 Annual Overview of China’s Internet Network Security Situation” [
1] focuses on describing potential network risks such as APT attacks, supply chain attacks, illegal collection of personal information, ransomware viruses, targeted delivery, and Wildcard Domain Resolution.
Meanwhile, according to the “2022 Annual Report on Network Security Vulnerability Trends”, nearly 25,000 new vulnerabilities were reported in 2022, reaching a historical high and maintaining a trend of annual growth. The overall situation has seen new changes, characterized by a surge in high-risk vulnerabilities, intensified competition in zero-day exploits, disruptions in international order due to one-sided vulnerability controls, and challenges to cyberspace rights by network hegemony. Consequently, the overall network security situation has become more complex and severe.
Cyberspace is a vast and intricate information environment. In the field of cybersecurity, conventional cybersecurity solutions often rely on predefined rules or signatures to detect and defend against known threats. However, they tend to struggle against newly emerged or unknown types of attack methods. To leverage the scattered and fragmented cybersecurity-related data more effectively within the Internet and enhance capabilities in threat intelligence analysis, risk assessment, and the formulation of protective measures, researchers and engineers are now embarking on the construction of a cybersecurity knowledge graph. A framework constructed based on graph theory and technology can integrate disparate information into a structured knowledge base that is meaningful and easily queryable and analyzable. Named Entity Recognition (NER) technology plays a crucial role in this process. Through Natural Language Processing (NLP) algorithms, NER accurately identifies various entities from unstructured text, such as names of malicious software, identifiers of hacker organizations, system vulnerability codes, and other crucial pieces of information. NER technology aids in rapidly extracting valuable information from extensive textual data, transforming it into a structured format that can be further processed and analyzed.
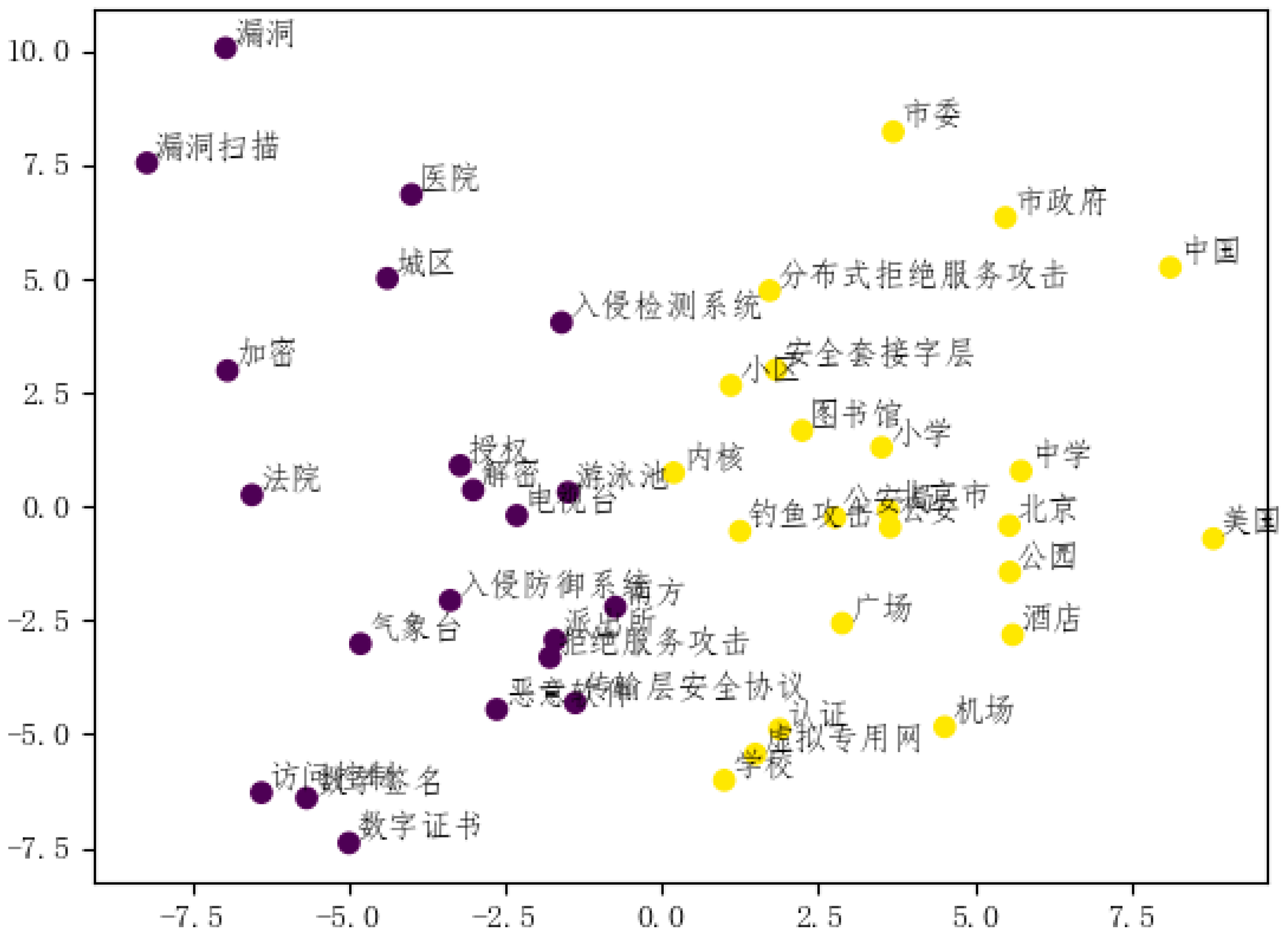
The existing research and applications of NER technology mostly concentrate on the English language context, where this field has made significant progress. In the English environment, there is a relatively well-established theoretical foundation, technical framework, and abundant data repositories. For instance, within the domain of English cybersecurity, NLP tools can effectively extract critical information such as IP addresses, names of malicious software, vulnerability identifiers, etc., and accurately map them to respective nodes in a knowledge graph.
However, when attempting to transfer these advanced techniques into the Chinese language environment, various challenges arise. Firstly, issues stem from the characteristics of Chinese characters. Unlike English words that are clearly separated by spaces, Chinese characters lack fixed delimiters when written. Secondly, many Chinese characters exhibit polysemy, where a single character can possess different pronunciations and meanings based on different contexts. This complexity makes direct segmentation using spaces or simple character matching to identify entities become intricate and error prone. Moreover, traditional entity recognition methods struggle to adapt to the iterative nature of cybersecurity entities and fail to resolve issues related to semantic overlap among cybersecurity entities. Existing research outcomes are insufficient to support the construction of a Chinese cybersecurity knowledge graph.
This paper proposes a joint model based on CSBERT-IDCNN-BiLSTM-CRT to address the current issues of lack of datasets and low accuracy in Chinese named entity recognition in the field of Chinese network security. This method utilizes the pre-trained model CSBERT to ensure high performance even with small datasets, and integrates IDCNN for extracting local features, BiLSTM for extracting contextual features, and CRF for sequence labeling to further improve the accuracy of named entity recognition in the Chinese network domain, better accomplishing the task of transforming unstructured text into structured text.
The rest of this paper is organized as follows:
Section 2 reviews recent domestic and international research achievements in NER problems and cybersecurity knowledge graphs.
Section 3 details how to establish the CSBERT-IDCNN-BiLSTM-CRT approach for entity recognition in the Chinese cyber domain.
Section 4 presents training results and comparative tests of the model, while
Section 5 provides an experimental summary, concluding with references at the end of this paper.
2. Related Work
At present, it is widely recognized in the industry that utilizing entity recognition technology to convert unstructured data into structured data and assist in building knowledge graphs is a direction with prospects and practical significance. However, currently, most named entity recognition is applied in general domains, and there are fewer named entity recognition technologies specifically designed for the field of network security. In recent years, with continuous iterations of software and hardware, deep neural network-based models for named entity recognition have replaced traditional methods based on vocabulary and rules. They have become mainstream approaches in academia and industry with good performance. With the increase in computing power, neural networks have returned to people’s attention. In 2003, Hammerton J. [
2] first applied Long Short-Term Memory (LSTM) [
3] to named entity recognition tasks. Although the performance in entity recognition was not satisfactory, it provided a new research direction. In 2015, Huang Z. et al. [
4] designed a neural network model using Bidirectional LSTM (BiLSTM) and Conditional Random Field (CRF) for entity recognition tasks. It achieved excellent results in various English NER tasks and became the state-of-the-art (SOTA) model at that time, as well as the baseline model for many English NER models.
Collobert R. et al. [
5] proposed a unified neural network architecture and learning algorithm for handling various natural language processing tasks. They trained a word embedding using a language model, and then applied the word embedding to tasks such as part-of-speech tagging, chunking, named entity recognition, etc. By combining word embeddings, convolutional neural networks (CNN), and conditional random fields (CRF), they achieved better results than previous research. However, CNN are unable to handle long text sequences. To enable the model to process long text data, Lample G. et al. [
6] replaced CNN with bidirectional long short-term memory networks (LSTM) as feature extractors to alleviate the problem of long-distance dependencies. However, these methods only consider word-level semantic features and ignore character-level implicit information. Kim Y. et al. [
7] proposed a language model that utilizes subword information through character-level CNN and extracts contextual features using LSTM while normalizing them with the SoftMax function. Kuru O. et al. [
8], on the other hand, input character sequences into BiLSTM to extract character-level contextual features. They output label probabilities for each character and use Viterbi decoder to convert these probabilities into word-level entity labels. Additionally, this approach also performs well in handling NER tasks in multiple languages.
In the English NER field, named entity boundaries align with word boundaries. However, Chinese does not have clear natural boundaries; therefore, Chinese NER usually involves segmenting input text data before feeding it into models for entity recognition. This segmentation operation can introduce errors that lead to inaccuracies in entity recognition.
Dong C. et al. [
9] proposed a Chinese radical-level LSTM to capture the pictographic root features, combined with a character-based BiLSTM-CRF model, achieving better performance on Chinese NER tasks. Zhang Y. et al. [
10] used a lattice structure to integrate lexical information and designed a named entity recognition model called Lattice-LSTM based on the LSTM model. In this model, memory units calculate the weighted sum of the character-level input and all potential words, integrating both lexical and character information. Compared to direct-word segmentation methods, it alleviates errors caused by word segmentation operations. In 2018, Google released the natural language processing model BERT [
11], introducing the concept of pre-training models into the field of natural language processing. The BERT model is trained on large-scale unlabeled corpora and has strong generalization ability, setting new records for multiple NER tasks. Dai Z. et al. [
12] applied the BERT pre-training model to Chinese NER tasks, combining it with the BiLSTM-CRF model for feature extraction and sequence labeling, achieving significantly better results than other contemporary Chinese named entity recognition models.
The construction of a knowledge graph for network security belongs to the problem of constructing a vertical domain knowledge graph [
13], which is different from general domain knowledge graphs such as DBpedia [
14], Freebase [
15], and Yago [
16]. It is constructed from data in the field of network security. In addition to building a network security knowledge graph based on expert systems, researchers both domestically and internationally have also studied other methods for constructing network security knowledge graphs. Fang Y. et al. [
17] proposed a network security entity recognition model called CyberEyes, which combines graph convolutional neural networks with BiLSTM models to extract both contextual and graphical-level, non-local dependency relationships simultaneously. The performance of this model on the network security corpus is higher than that of traditional CNN-BiLSTM-CRF models. Yi F. et al. [
18] fully utilize the features of security data and the correlations between entities, proposing a named entity recognition model for network security based on regular matching, external dictionaries, CRF, and feature templates. By jointly constraining multiple conditions, more accurate entity recognition results are obtained. Sills M. et al. [
19], in order to enhance AI-based network defense systems in capturing, detecting, and preventing known and future attacks, propose a system that generates various medical device vulnerability intelligence and known vulnerability threat intelligence resources through enhanced graph embedding techniques to generate higher quality graphical representations. Tikhomirov M. et al. [
20] study BERT models and their variant models’ performance on Russian language Network Security Named Entity Recognition tasks, and propose a method of enhancing Network Security Domain Data by adding names after descriptors or replacing descriptors with names.
Jia Y. et al. [
21] designed a network security ontology that covers assets, vulnerabilities, and attacks. They used machine learning methods to construct a network security knowledge base based on the five-tuple model deduction rules. Shang Huaijun [
22] constructed a vulnerability-based ontology in the field of network security and improved the effectiveness of network security entity recognition by using rule-based and dictionary feature-based methods for specific entities. This ultimately achieved the update and visualization of the network security knowledge base. Wang Tong et al. [
23] conducted research on threat intelligence graph construction techniques, proposing a model that can automatically extract entities and relationships from threat intelligence data, and realized visual presentation of threat intelligence knowledge graphs. Peng Jiayi et al. [
24] proposed a BiLSTM-CRF model using active learning methods to improve the accuracy of named entity recognition tasks in small-sample information security domains. Zhang Ruobin et al. [
25] addressed the problem of identifying security vulnerability entities by proposing a BiLSTM-CRF model that uses dictionary correction to improve identification results while significantly reducing the cost of manually selecting features. Qin Ya and Shen Guowei et al. [
26] proposed an improved CRF algorithm based on Hadoop, which effectively partitions datasets to enhance accuracy in recognizing security entities. Qin Ya also proposed a network security identification model that extracts local contextual features using artificial feature templates, character features using CNN, and global text features using BiLSTM; this model outperforms other methods on large-scale network security datasets.
Based on the above analysis, it is found that English-language network security knowledge graph construction techniques are relatively mature, but research on Chinese-language network security knowledge graphs is still in its early stages. Due to significant differences between Chinese and English languages, existing techniques for constructing English-language networks cannot be directly applied to Chinese-language network security knowledge graph construction. There is a lack of Chinese-language named entity recognition methods specifically designed for the Chinese environment in network security NER. To address this, this paper proposes a CSBERT-IDCNN-BiLSTM-CRF method for Chinese-language network security NER, with the following main research work.
- (1)
From a model perspective, using the CSBERT pre-trained model based on network security can project input representations into the network security semantic space, greatly improving the performance of neural network models on small datasets. By utilizing IDCNN and BiLSTM, the model is endowed with the ability to capture long dependency features and local features, combining these two types of features to better accomplish entity recognition tasks in the field of network security.
- (2)
A reliable dataset is constructed. Currently, most knowledge graphs related to network security face issues such as insufficient data or outdated Chinese domain data that lags current developments in network security. To address this dataset problem, this paper used China National Vulnerability Database (CNNVD) as a source for constructing a network security dataset centered around vulnerability data. The text corpus for dataset construction consists of vulnerability reports and vulnerability data from CNNVD. Automated scripts are used to crawl vulnerability report data, download XML format vulnerability data directly, and utilize YEDDA [
27] tool for data annotation to complete dataset construction.
- (3)
This paper has accomplished the training and testing of the model on its own constructed dataset, mitigating issues associated with poor model training due to low-quality datasets. Experimental results indicate that the proposed CSBERT-IDCNN-BiLSTM-CRF model boasts certain advantages in terms of the efficiency and accuracy of entity recognition.
4. Experimental Design and Analysis
4.1. Data Annotation
In deep learning, named entity recognition problems are often treated as sequence labeling problems. Therefore, the datasets used for NER are usually saved in a form where each character corresponds to an entity label. Common data annotation methods include BIO, BIOES, BMESO, etc. The dataset used by the model in this paper is annotated using the BIO annotation method. Taking the Chinese sentence “API存在跨站脚本漏洞”(API has a cross-site scripting vulnerability) as an example, the annotation result obtained using the BIO annotation method is shown in
Figure 7.
In the above BIO annotation method, “B” represents the starting character of an entity, “I” in BIO annotation indicates characters other than the starting character within an entity, i.e., middle and ending characters of the entity, and “0” indicates that the word is unrelated to the current named entity under consideration. In the final dataset, we used the BIO annotation method to label a total of 710,000 rows of data for model training.
4.2. Dataset Construction
The data source of the network security dataset used in this paper is the China National Vulnerability Database (CNNVD) at
https://www.cnnvd.org.cn (accessed on 9 September 2023). The website provides information related to hot vulnerabilities, vulnerability reports, and other information related to network security vulnerabilities. It has a high-quality network security corpus, which is suitable for constructing the network security dataset in this paper. By extracting and cleaning data from CNNVD’s raw corpus, the YEDDA tool is used for data annotation. Based on the network security text corpus, eleven entity types are designed for the network security dataset: person names (PERSON), organization names (ORGANIZATION), company names (COMPANY), location names (LOCATION), software names (SOFTWARE), program names (PROGRAM), hardware names (HARDWARE), vulnerability names (VULNERABILITY), actions (ACTION), network entities (NETWORKENTITY), and version numbers (VERSION). Data annotation using the YEDDA tool is shown in
Figure 8.
Person (PERSON) includes software developers, company owners, legal representatives, etc.; organization (ORGANIZATION) includes hacker groups, non-profit organizations, open-source software communities, software foundations, etc.; company (COMPANY) specifically refers to for-profit entities such as Apple Inc., Google LLC, Huawei Technologies Co., Ltd., etc.; location (LOCATION) includes countries, regions, specific addresses, etc.; software name (SOFTWARE) includes but is not limited to specific application platforms, operating systems, software plugins; program name (PROGRAM) includes APIs, components within the software system, processes/modules in the software system, variables in the software system, scripts and codes; hardware name (HARDWARE) includes various hardware components such as CPU, GPU, memory, disk drives, routers, and switches; vulnerability name (VULNERABILITY) includes various vulnerabilities such as cross-site scripting vulnerability (SQL injection vulnerability); action (ACTION) includes actual impact of vulnerabilities and specific operations to achieve attack objectives; network entity (NETWORKENTITY) includes various difficult-to-determine network elements that have a greater association with the Internet than other types of entities, such as protocols and protocol implementations, browsers, clients, front-end, C language (programming language), files, and other abstract concepts; version number (VERSION) includes specific version codes for various software and hardware.
4.3. Dataset Entity Statistics
The entity statistics of the network security dataset annotated using the YEDDA annotation tool are shown in
Table 1.
To visually display the distribution of samples, calculate the proportion of each entity in the dataset. The statistical results are shown in the
Figure 9.
4.4. Experimental Hyperparameter Settings
When training the model, the parameter settings in
Table 2 were used. Some parameters in the table will be adjusted according to the actual situation of model training to achieve optimal experimental results. The model fine-tunes CSBERT during the training process and separates the learning rates of CSBERT and other parameters to obtain better experimental performance. Additionally, to avoid overfitting during training, a dropout mechanism is introduced to randomly discard some neurons.
4.5. Entity Recognition Result Analysis
To verify the performance of the CSBERT-IDCNN-BiLSTM-CRF network security named entity recognition model proposed in this paper, different models were selected for experiments on the same dataset. The experimental results are shown in
Table 3. The network security entity recognition model proposed by Jia Y. et al. [
21] is used as a benchmark model. The remaining models include mainstream sequence labeling models such as the BiLSTM-CRF, CNN-BiLSTM-CRF model with convolutional neural networks introduced, and IDCNN-BiLSTM-CRF proposed in this paper for sequence labeling tasks. Furthermore, by introducing the BERT model and the cybersecurity pre-trained CSBERT model, a more comprehensive and precise comparative analysis was conducted, thereby accentuating the superior capability of this model in the recognition of Chinese cybersecurity entities. Model performance is evaluated and analyzed based on precision, F1 score, and recall using a classical evaluation system.
Through the line chart, the changes of various evaluation indicators between different models can be displayed more intuitively. The statistical graph of model performance is shown in
Figure 10:
The experiment was conducted on the nine models mentioned above. As shown in the figure, in the task of network security named entity recognition, the mainstream BiLSTM-CRF model performs better than Jia Y’s proposed network security entity recognition model. Peng Jiayi’s strategy of improving small-sample information security in the field by introducing active learning did indeed yield results slightly higher than those of the classic BiLSTM-CRF model. Zhang Ruobin used dictionary correction to improve representation outcomes, adding a correction step on top of the classic BiLSTM-CRF model and significantly increasing the model’s accuracy. However, due to differences in Chinese and English structures, using BiLSTM-CRF cannot effectively capture Chinese sequence information and local features. From the results of these two models, without addressing the effective capture of Chinese sequence information and local features, improvements based solely on the classic BiLSTM-CRF model are limited for Chinese entity recognition. After introducing CNN, the CNN-BiLSTM-CRF model has obtained the ability to capture local features and to some extent process Chinese specific structures to obtain sequence information. This can also be seen in Qin Ya’s model, where Qin Ya considered using a CNN-based model solution for entity recognition tasks in constructing a network security knowledge graph, and further improved the accuracy of the CNN+BiLSTM+CRF model by combining feature templates on this basis. But compared to IDCNN, traditional CNN has a smaller receptive field and cannot handle longer text sequences. The IDCNN-BiLSTM-CRF model can extract local features from long texts and then fuse them with long-term dependency features extracted by BiLSTM, enabling it to capture more semantic information.
After introducing BERT pre-training models, the performance of the BERT-IDCNN-BiLSTM-CRF model significantly improves compared to models without BERT. This indicates that pre-training models play an important role in improving entity recognition accuracy. When continuing pre-training BERT with network security corpora, a CSBERT pre-trained model more suitable for network security domain is obtained. The F1 scores of the CSBERT-IDCNN-BiLSTM-CRF model reach 87.31%. Compared with BERT-IDCNN-BiLSTM-CRF using general-purpose BERT pre-training models, CSBERT pre-trained models gain abundant prior knowledge in the field of network security through continued training specifically in this domain and ultimately acquire word vectors more suitable for this domain which enhances their performance. This demonstrates the importance of continued training within specific domains.
From the above experimental comparisons, it is necessary to continue training open-source pre-training models with network security corpora for network security named entity recognition tasks. Combining IDCNN as an IDCNN-BiLSTM feature extractor can simultaneously capture both local and long-term dependency features of the text. Compared to traditional BiLSTM, it can capture more semantic features and improve entity recognition accuracy.
4.6. Analysis of Entity Recognition Results by Category
The experimental results of
Section 4.5 are the weighted average of evaluation indicators for each entity category, with the evaluation indicators for each entity shown in
Table 4.
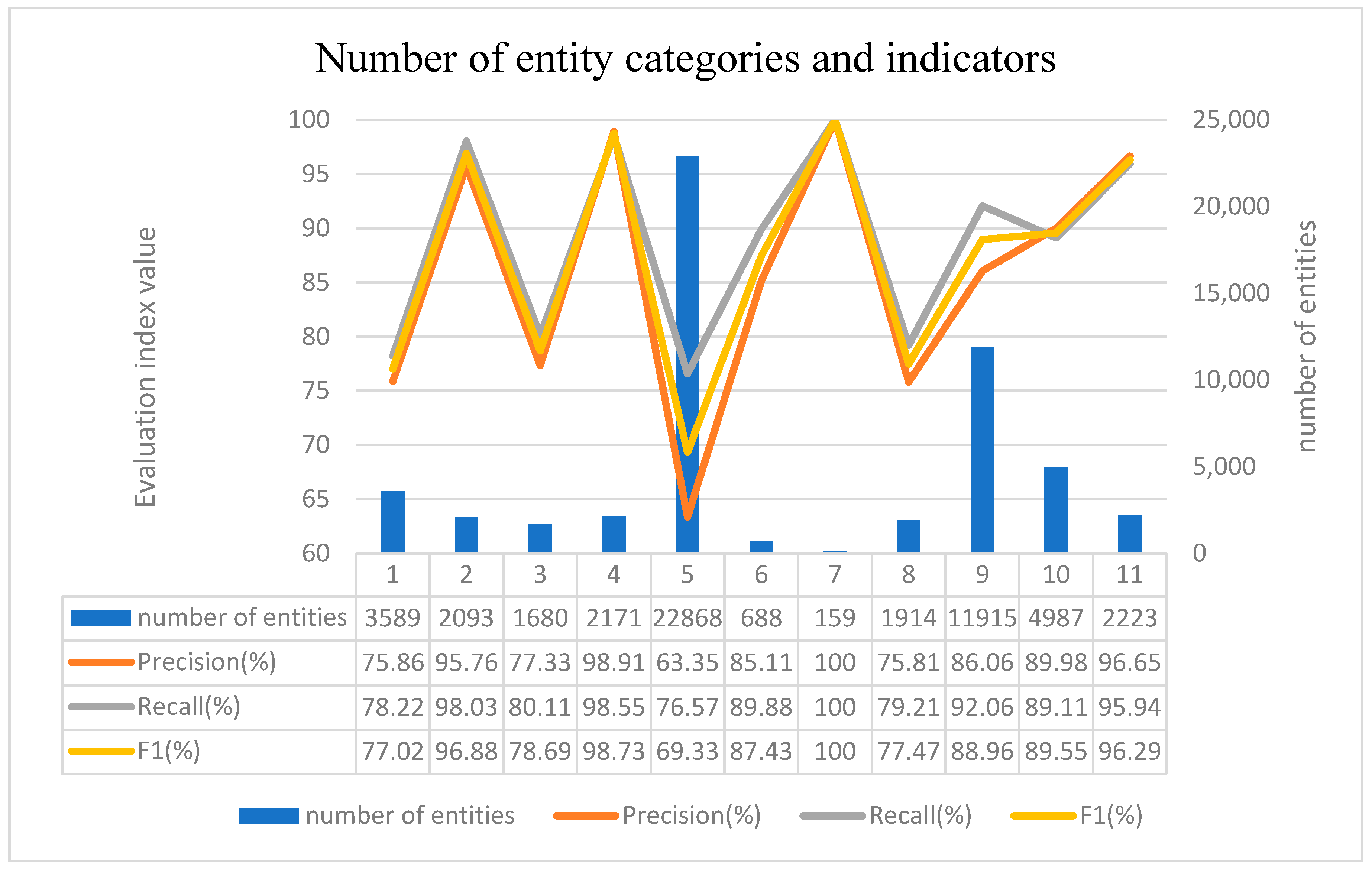
To analyze the experimental results of the CSBERT-IDCNN-BiLSTM-CRF model in detail, the experimental indicators of each entity category are merged with the corresponding quantity in the dataset and analyzed in
Figure 11.
Overall, the number of entities in the dataset does not directly correlate with their recognition accuracy. Where “COMPANY”, “LOCATION”, “ORGANIZATION”, “PERSON “COMPANY”, “LOCATION”, “ORGANIZATION”, “PERSON”, “SOFTWARE”, “VERSION” and “VULNERABILITY” have higher recognition accuracy, with F1 scores exceeding 85%. However, the recognition accuracy for entities such as “ACTION,” “HARDWARE,” “NETWORKENTITY,” and “PROGRAM” is relatively lower.
Figure 11.
The number of each entity and its evaluation indicators.
Figure 11.
The number of each entity and its evaluation indicators.
The low accuracy in identifying the entities “ACTION” and “PROGRAM” is due to their long lengths, as well as the overlap of some entity content with other entity categories. The model easily confuses the end tags of entities, resulting in incorrect label predictions.
On the other hand, the entity “HARDWARE” has similar features to “SOFTWARE,” and both can only be distinguished based on contextual information. However, there are far more instances of “SOFTWARE” entities in the dataset compared to “HARDWARE,” which leads to higher accuracy in recognizing “SOFTWARE” entities than “HARDWARE”.
As for the entity “NETWORKENTITY,” it contains too many concepts and is prone to being predicted as an ‘O’ (non-entity) by the model compared to other entities. Therefore, its recognition accuracy does not directly correlate with its quantity in the dataset.
Ultimately, we found that the number of entities has a significant impact on prediction accuracy when faced with relatively similar entity types, whereas it is not a major factor in other cases such as entity types with complex concepts.
4.7. Melting Experiment
To verify the effectiveness of the main modules proposed in this paper, a set of comparative experiments is conducted in this section. Based on the IDCNN-BiLSTM-CRF model, two groups are designed by replacing IDCNN with CNN and removing the IDCNN module as controls to validate the role of using the IDCNN module. The results of ablation experiments are shown in
Table 5 below.
The performance of the three models in the table decreases sequentially on the network security dataset. This indicates that both CNN and IDCNN can extract local information from text, but IDCNN has a larger receptive field, allowing it to handle long text information and further improve the performance of network security entity recognition models.
5. Conclusions
The Chinese knowledge graph of network security can effectively address the issue of fragmentation and difficulty in integrating information in the field of Chinese network security. Named entity recognition technology plays a pivotal role in the construction of the graph, and significantly enhances the accurate identification and associative analysis of cybersecurity-related entities. Accordingly, this paper introduces a NER method in the Chinese domain called CSBERT-IDCNN-BiLSTM-CRF, based on a cybersecurity pre-trained model. This method initially leverages the cybersecurity pre-trained model for further training, thereby generating more sophisticated word vectors pertinent to the cybersecurity field. Subsequently, considering the temporal nature of natural language, it is crucial to extract sequential features from the model; this is where the chained structure of RNN comes into play for natural language sequence modeling. However, as computational power increases and the length of input text grows, the traditional RNN model’s capability to process long texts becomes increasingly inadequate. Additionally, the original RNN models are prone to gradient vanishing, which leads to subpar performance in capturing long-distance dependent features; therefore, BiLSTM are used to resolve the issues with long-distance dependencies and to enhance the capacity to extract contextual information, thus extending the upper limit of natural language processing input texts. Following that, traditional CNN are employed as an auxiliary process to address issues where BiLSTM cannot fully extract the sequential information due to the unique textual structure of Chinese online texts. Nevertheless, the inherent limitation of CNN, after convolution operations followed by pooling, results in the loss of sequence information. Given that natural language consists mostly of sentences and the relatively small receptive field of CNN, which can only be increased by stacking convolution layers, risking overfitting, the paper introduces the DCNN with the atrous mechanism and establishes the IDCNN for processing longer text sequences via stacking techniques. Finally, a CRF is incorporated to consider the interdependency of labels at the sequence level, imposing constraints on the model’s output to ensure the legitimacy of the labels. By integrating local and contextual features, the model achieves superior performance. Using the data from the China National Vulnerability Database of Information Security and the YEDDA tool for label annotation, this paper constructs a Chinese cybersecurity dataset for training and testing the proposed model. Experimental results demonstrate that on the Chinese cybersecurity dataset, the CSBERT-IDCNN-BiLSTM-CRF model outperforms other Chinese entity recognition models, leading in terms of accuracy and F1 Score, which sufficiently proves the efficiency of the proposed CSBERT-IDCNN-BiLSTM-CRF model and provides more precise recognition results in the task of named entity recognition in the Chinese cybersecurity domain.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}