
A Parallel Privacy-Preserving k-Means Clustering Algorithm for Encrypted Databases in Cloud Computing


Abstract
:1. Introduction
- This paper proposes decimal-based encryption operation protocols, like ASMIN and ASMINn. The proposed protocols address the challenges of the existing binary-based encryption operation protocols, where the performance degradation is proportional to the data size. The proposed protocols overcome the limitation, providing excellent processing performance independently of data size.
- This paper proposes a privacy-preserving k-means clustering algorithm that utilizes the proposed decimal-based encryption operation protocols. While providing superior processing performance, the proposed k-means clustering algorithm ensures that data, queries, and data access patterns are safeguarded in order to protect original databases and user information in cloud computing.
- This paper proposes a privacy-preserving parallel k-means clustering algorithm. To the best of our knowledge, this is the first work to study a privacy-preserving parallel k-means clustering algorithm. To perform parallel processing, we utilize a thread pool to prevent data bottlenecks and parallelize encryption operation protocols for efficient support of k-means clustering. However, when parallelizing homomorphic encryption techniques, there is the issue of the increased operational overhead per core, leading to bottlenecks and performance degradation. To mitigate this bottleneck, we use a random value pool to reduce the computational cost by preprocessing operations that generate random values for hiding data and encrypting them in the encryption operation protocol.
2. Background and Related Research
2.1. Background Knowledge
- Homomorphic addition: The multiplication of two ciphertexts E(m1) and E(m2) generates the ciphertext of the sum of their plaintexts m1 and m2 (Equation (1)).
- Homomorphic multiplication: The m2-th power of ciphertext E(m1) generates the ciphertext of the multiplication of m1 and m2 (Equation (2)).
- Semantic security: Encryptions of the same plaintexts generate different ciphertexts in the same public key (Equation (3)).
2.2. Related Work
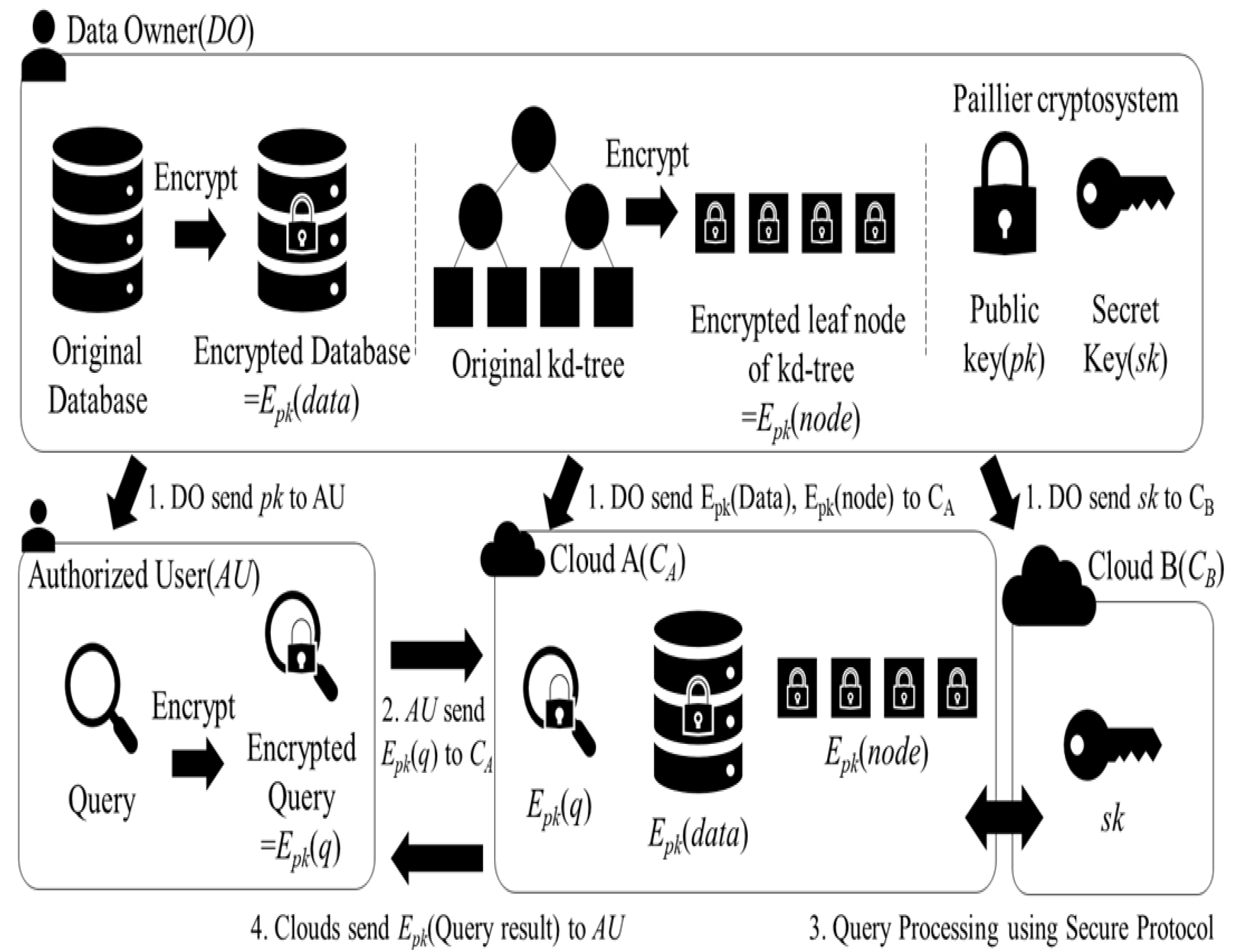
3. Overall System Architecture
3.1. System Architecture
3.2. Secure Protocol
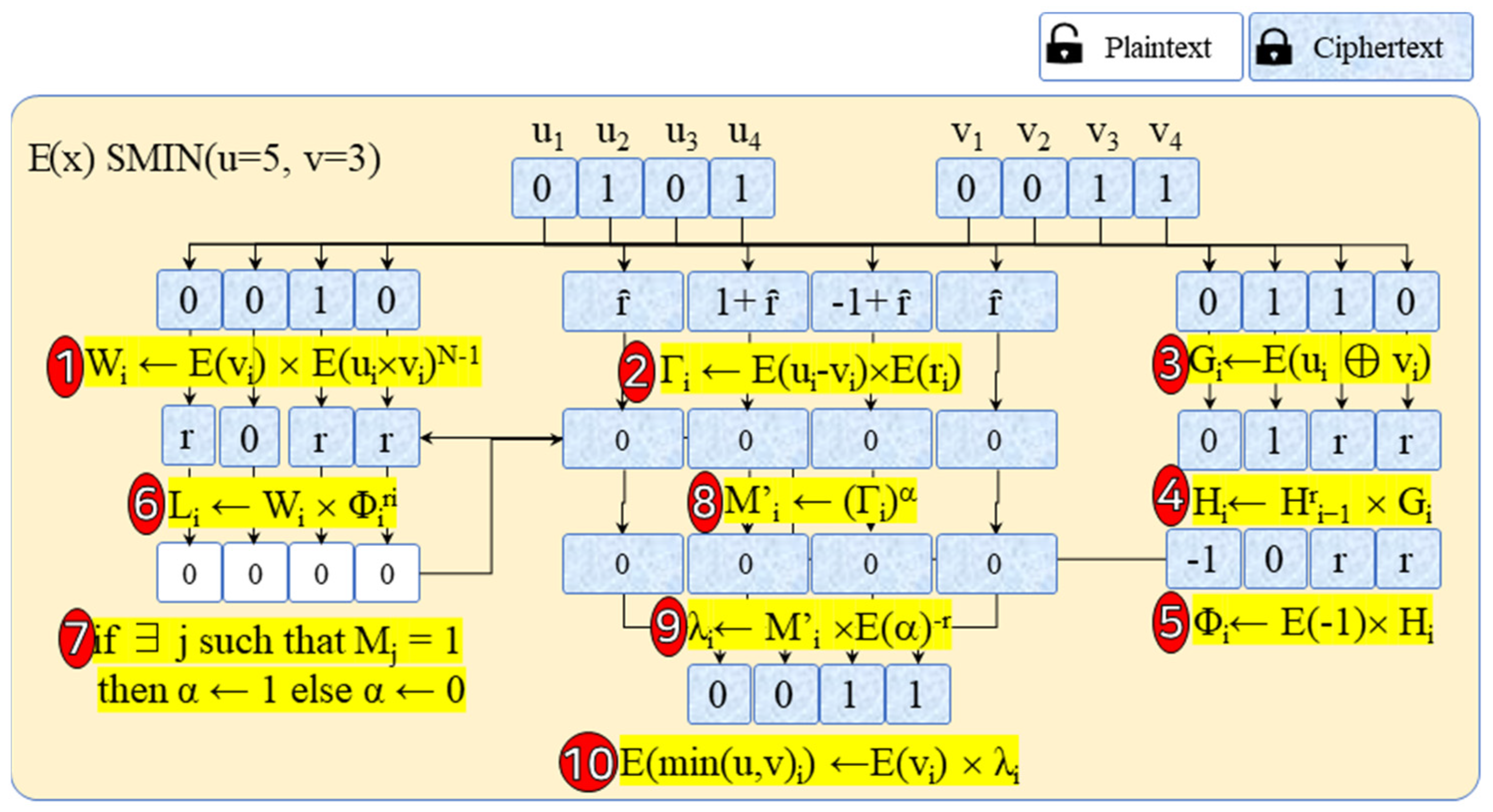
3.2.1. Advanced Secure MINimum (ASMIN) Protocol
| Algorithm 1 ASMIN (Advanced Secure MINimum) |
| Input: E(u), E(v) Output: E(u) when u ≤ v, otherwise E(v) CA: 01. select <ra, E(ra)>, <rb, E(rb)> in the random value pool 02. E(u × ra) ← E(u)ram 03. E(v × ra) ← E(v)ra 04. E(u × ra + rb) ← E(u × ra) × E(rb) 05. E(v × ra + rb) ← E(v × ra) × E(rb) 06. if F0: E(u × ra + rb) then, E(v × ra + rb) send to CB 07. else if F1: E(v × ra + rb) then, E(u × ra + rb) send to CB CB: 08. Decrypt E(u × ra + rb), E(v × ra + rb) 09. if (u × ra + rb ≤ v × ra + rb) then, <E(α), E(β)> ← <E(1), E(0)> 10. else then, <E(α), E(β)> ← <E(0), E(1)> 11. send <E(α), E(β)> to CA CA: 12. if F0 then, E(result) = SM(E(α), E(u)) × SM(E(β), E(v)) 13. else then, E(result) = SM(E(β)), E(u)) × SM(E(α), E(v)) 14. return E(result) End Algorithm |
3.2.2. Advanced Secure MINimum out of n Numbers (ASMINn) Protocol
| Algorithm 2 ASMINn (Advanced Secure MINimum out of n Numbers) |
| Input: E(d1), …, E(dn) Output: E(dmin) CA: 01. E(dʹi) ← E(di) (for 1 ≤ i ≤ n) and num ← n 02. for 1 ≤ i ≤ ⌈log2n⌉ 03. for 1 ≤ j ≤ ⌊num/2⌋ 04. if i = 1 then 05. left ← 2 × j − 1; right = 2 × j 06. else 07. left ← 2i(j − 1) + 1; right = 2ij − 1 08. E(dʹleft) ← ASMIN(E(dʹleft), E(dʹright)) 09. num ← ⌈num/2⌉ 10. return E(dmin) ← E(dʹI) End Algorithm |
4. Privacy-Preserving k-Means Clustering Algorithm
4.1. Preprocessing Phase
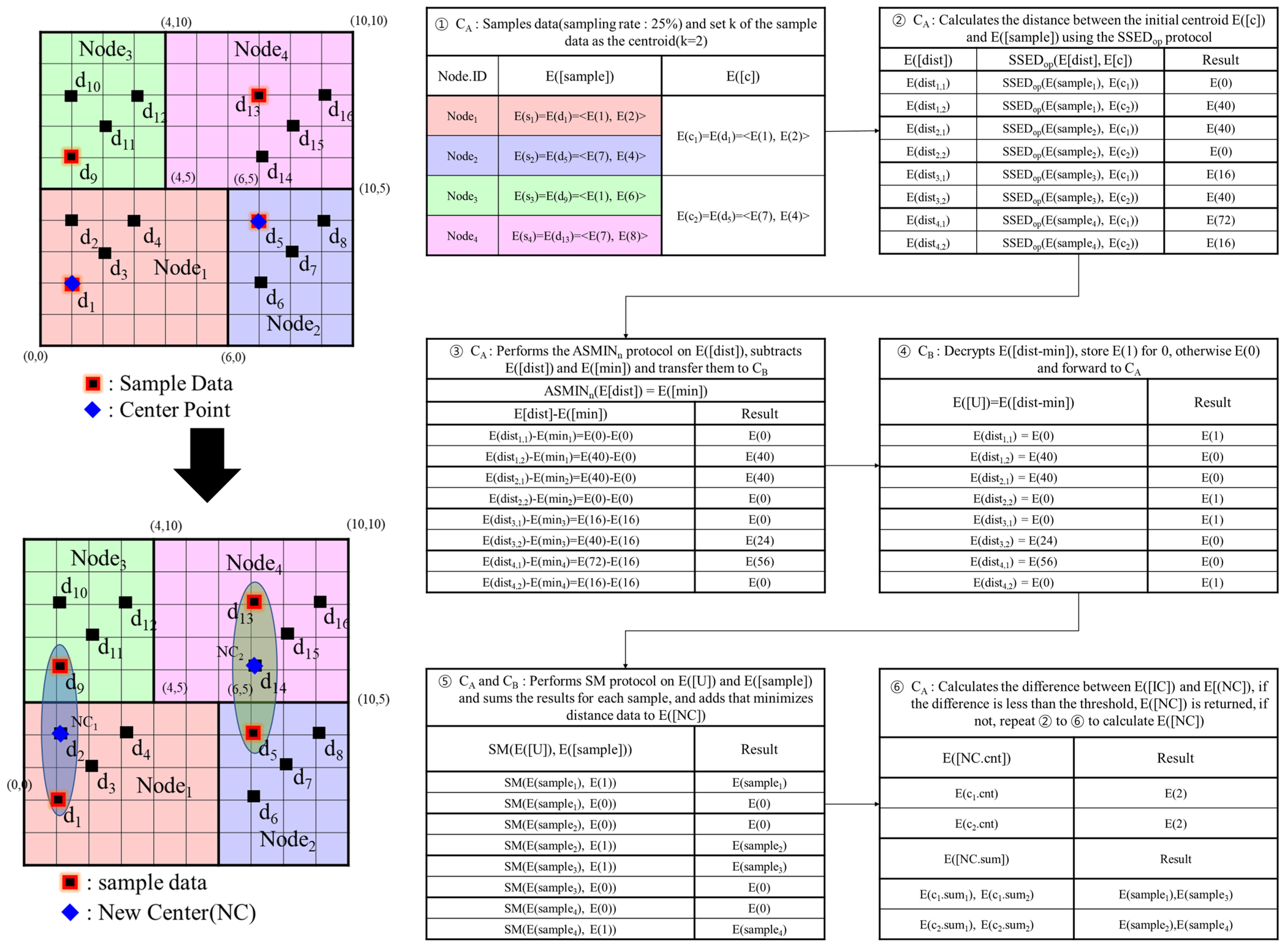
- Calculate the number of data points (i.e., cnt) to be selected from each node based on the sampling ratio (line 1).
- Initialize the initial centroids for the preprocessing step (lines 2–5). Here, the Paillier cryptosystem cannot encrypt real numbers, so the centroids (i.e., initial_center) are represented by the sum of centroids (i.e., initial_center.sum) and the count of centroids (i.e., initial_center.cnt).
- Select and store the sampled data (i.e., E(sample_data)) from each node, amounting the data points to cnt (line 7–9).
- Calculate the distances between E(sample_data) and E(initial_center) using the SSEDop protocol and find the minimum distance using the ASMINn protocol (lines 10–13). The SSEDop protocol is a distance calculation protocol that was proposed by F. Rao et al. [23] for determining distances between centroids and data points.
- Calculate the difference between E(dist_min) and each encrypted distance, perform random insertion and permutation, and transmit the result to CB (lines 14–18).
- CB decrypts each element of the received E(β), sets E(Ui) = E(1) if β = 0, and sets E(Ui) = E(0) otherwise. CB then sends E(U) to CA (lines 19–22).
- CA reverses E(U) and stores it in E(V) (line 23).
- Perform the SM protocol for E(Vj) and E(sample_datai,l), summing the results for each dimension, and add the sample data with a distance of E(dist_min) to the new centroid E(new_center) = <E(new_center.sum), E(new_center.cnt) > (lines 24–28).
- Use the SETC protocol to calculate the termination condition (i.e., α) between the initial and new centroids. Then, store new_center in initial_center, and if α is 1, return initial_center; otherwise, repeat the clustering protocol from line 10 (lines 29–34). Here, the Secure Minimum out of n Numbers (SETC) protocol, proposed in [25], checks the termination condition of the k-means clustering algorithm. It returns 1 if the difference between the previous and new centroids is less than the threshold provided by the user, and 0 otherwise.
| Algorithm 3 Encrypted initial center selection for k-means clustering |
| Input: E(data), E(node), E(threshold) Output: E(initial_center) = <E(initial_center1), …, E(initial_centerk)>, E(initial_centeri) = <E(initial_centeri.sum), E(initial_centeri.cnt)>, E(initial_centeri.sum) = <E(initial_centeri.sum1), …, E(initial_centeri.summ)> CA: 01. cnt = Fanout/sampling rate//Fanout is #_of data in each node 02. for 1 ≤ i ≤ k 03. E(initial_centeri.cnt) ← E(1) 04. for 1 ≤ j ≤ m 05. generate random number r 06. E(initial_centeri.sumj) ← E(r) 07. for 1 ≤ i ≤ NumNode 08. for 1 ≤ j ≤ cnt 09. E(sample_data) ← E(nodei.dataj) 10. for 1 ≤ i ≤ cnt 11. for 1 ≤ j ≤ k 12. E(distj) = SSEDop(E(sample_datai), E(initial_centeri)) 13. E(dist_min) ← ASMINn(E(dist1), …, E(distk)) 14. for 1 ≤ i ≤ k 15. E(δi) ← E(dist_min) × E(disti)N – 1 16. E(δʹi) ← E(δi)ri 17. E(β) ← π(E(δʹi)) 18. send E(β) to CB CB: 19. for 1 ≤ i ≤ cnt 20. if D(E(βi)) = 0 then E(Ui) ← E(1) 21. else E(Ui) ← E(0) 22. send E(U) to CA CA: 23. E(V) ← π−1(E(U)) 24. for 1 ≤ j ≤ k 25. for 1 ≤ l ≤ m 26. E(V’j,l)←SM(E(Vj), E(sample_datai,l)) 27. E(new_centerj.suml) ← E(new_centerj.suml) × E(V’j,l) //E(new_center) is the same structure with E(initial_center) 28. E(new_centerj.cnt) ← E(new_centerj.cnt) × E(Vj) 29. α = SETC(E(initial_center), E(new_center), E(threshold)) 30. E(initial_center) ← E(new_center) 31. if α = 1 32. return E(initial_center) 33. else 34. go to line 10 in Algorithm 3 |
4.2. k-Means Clustering Phase
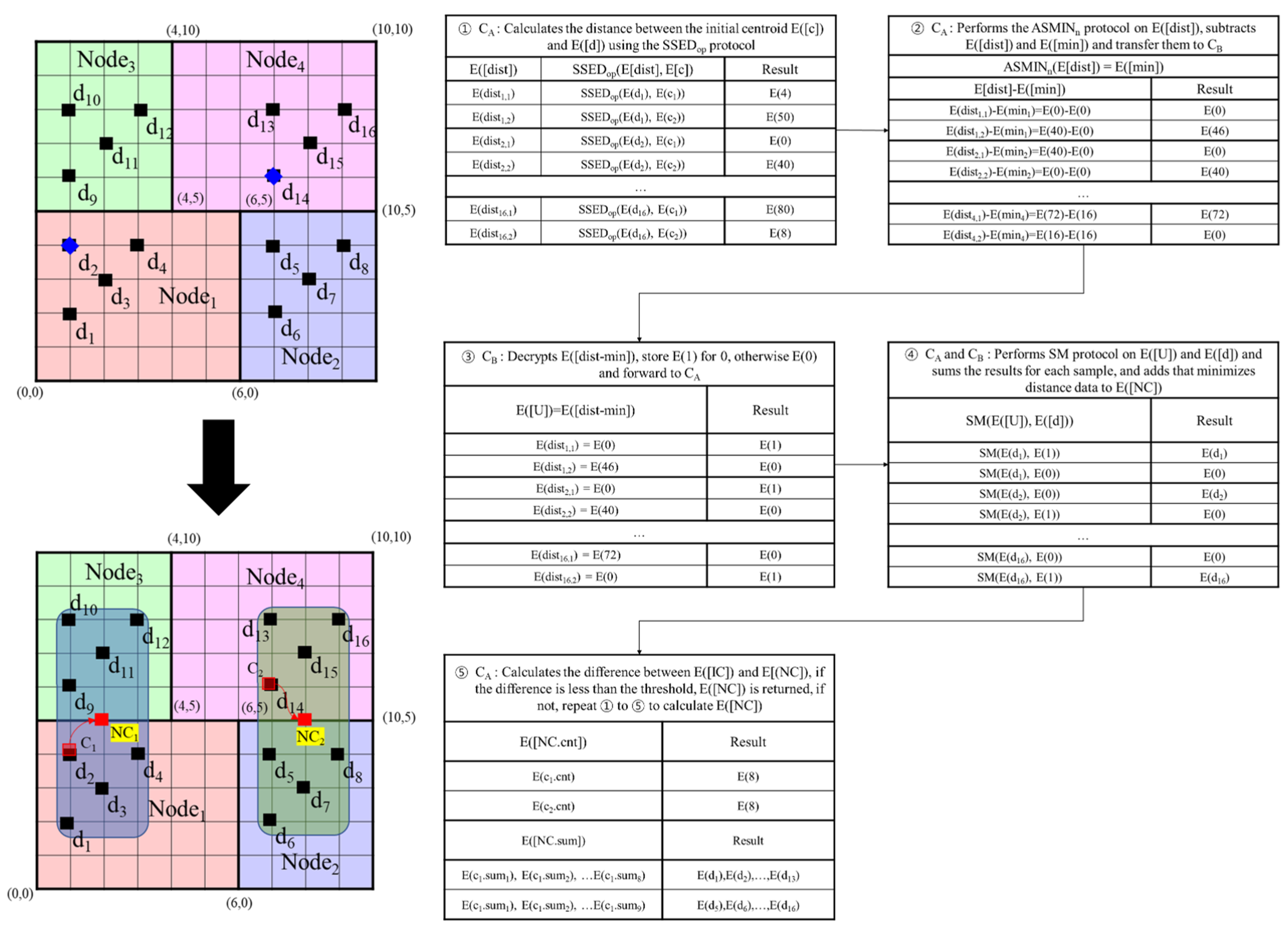
- Calculate the distances between E(data) and E(initial_center) using the SSEDop protocol and determine the smallest distance (i.e., E(dist_min)) through the proposed ASMINn protocol (lines 1–4).
- CA calculates the difference between E(dist_min) and each encrypted distance, performs random insertion and permutation, and transmits the result to CB (lines 5–9).
- CB decrypts each element of the received E(β), sets E(Ui) = E(1) if β = 0, and sets E(Ui) = E(0) otherwise. CB then sends E(U) to CA (lines 10–13).
- CA reverses E(U) and stores it in E(V) (line 14).
- Perform the SM protocol for E(Vj) and E(datai,l), summing the results for each dimension, and add the data with a distance of E(dist_min) to the new centroid E(new_center) (lines 15–19).
| Algorithm 4 Encrypted center search phase for k-means clustering |
| Input: E(data), E(node), E(threshold), E(initial_center) Output: cluster_center CA: 01. for 1 ≤ i ≤ n 02. for 1 ≤ j ≤ k 03. E(distj) = SSEDOP(E(datai), E(initial_center)) 04. E(dist_min) ← ASMINn(E(dist1), …, E(distk)) 05. for 1 ≤ i ≤ k 06. E(δi) ← E(dist_min) × E(disti)N − 1 07. E(δʹi) ← E(δi)ri 08. E(β) ← π(E(δʹi)) 09. send E(β) to CB CB: 10. for 1 ≤ i ≤ cnt 11. if D(E(βi)) = 0 then E(Ui) ← E(1) 12. else E(Ui) ← E(0) 13. send E(U) to CA CA: 14. E(V) ← π − 1(E(U)) 15. for 1 ≤ j ≤ k 16. for 1 ≤ l ≤ m 17. E(V’j,l)←SM(E(Vj), E(datai,l)) 18. E(new_centerj.suml) ← E(new_centerj.suml) × E(V’j,l) 19. E(new_centerj.cnt) ← E(new_centerj.cnt) × E(Vj) 20. α = SETC(E(initial_center), E(new_center), E(threshold)) 21. if α = 1 22. for 1 ≤ i ≤ k 23. for 1 ≤ j ≤ m 24. E(new_centeri.sumj+r)←E(new_centeri.sumj) × E(r) 25. E(new_centeri.cnt+r)←E(new_centeri.cnt) × E(r) 26. else 27. E(initial_center)←E(new_center) 28. go to line 1 in Algorithm 4 29. send r to AU and send E(new_center + r) to CB CB: 30. for 1 ≤ i ≤ k 31. for 1 ≤ j ≤ m 32. new_centeri.sumj + r ← D(E(new_centeri.sumj + r)) 33. new_centeri.cnt + r ← D(E(new_centeri.cnt + r)) 34. send new_center + r to AU AU: 35. receive new_center + r from CB and r from CA 36. cluster_center = new_center.sum/new_center.cnt |
5. Privacy-Preserving Parallel k-Means Clustering Algorithm
5.1. Parallel Preprocessing Phase
- CA calculates the number of data points to be selected from each node based on the sampling ratio (cnt) (line 1).
- CA initializes the initial center of the preprocessing phase (lines 2~5). In this case, as the Paillier encryption system cannot encrypt real numbers, the center point (initial_center) is represented by the sum of center points (initial_center.sum) and the count of center points (initial_center.cnt).
- Each node selects and stores cnt samples of data (i.e., E(sample_data)) (lines 7~9).
- The thread pool performs parallel processing of the calculate_new_center procedure. The calculate_new_center procedure involves the following steps. First, each thread on CA calculates the distance between E(sample_data) and E(initial_center) using the SSEDop protocol. Then, it determines the smallest distance using the ASMINn protocol. Second, each thread on CA calculates the difference between E(dist_min) and each encrypted distance. After inserting random numbers and changing the order, this information is sent to CB. Third, each thread on CB decrypts the received E(β), setting E(Ui) to E(1) if β = 0; otherwise, E(Ui) is set to E(0). CB then sends E(U) back to CA. Fourth, each thread on CA reverses E(U) and stores it in E(V). Fifth, each thread on CA performs the SM protocol on E(Vj) and E(sample_datai,l). By summing the results for each dimension, it adds the sample data with a distance of E(dist_min) to the new center point E(new_center) = <E(new_center.sum), E(new_center.cnt)>. Sixth, the thread pool allows for the parallel computation of the new center point E(new_center) through the five steps mentioned above.
- The SETC protocol calculates the termination condition (α) between the initial center point and the new center point. Subsequently, new_center is stored in initial_center. If α is 1, initial_center is returned; otherwise, clustering is re-executed from line 10 (lines 12~17).
| Algorithm 5 Parallel encrypted initial center selection for k-means clustering |
| Input: E(data), E(node), E(threshold) Output: E(initial_center) = <E(initial_center1), …, E(initial_centerk)> //E(initial_centeri) = <E(initial_centeri.sum), E(initial_centeri.cnt)>, E(initial_centeri.sum) = <E(initial_centeri.sum1), …, E(initial_centeri.summ)> CA: 01. cnt = node.cnt/sampling rate 02. for 1 ≤ i ≤ k 03. E(initial_centeri.cnt) ← E(1) 04. for 1 ≤ j ≤ m 05. select random number r from the random value pool 06. E(initial_centeri.sumj) ← E(r) 07. for 1 ≤ i ≤ NumNode 08. for 1 ≤ j ≤ cnt 09. E(sample_data) ← E(nodei.dataj) 10. for 1 ≤ i ≤ cnt 11. thread_pool_push(calculate_new_center(k, m, cnt, E(sample_data), E(initial_center), E(new_center))) 12. α = SETC(E(initial_center), E(new_center), E(threshold)) 13. E(initial_center) ← E(new_center) 14. if α = 1 15. return E(initial_center) 16. else 17. go to line 10 in Algorithm 5 Procedure 1. calculate_new_center(E(data), E(nodei), E(distk), E(δi)) Begin Procedure CA: 01. for 1 ≤ j ≤ k 02. E(distj) = SSEDop(E(sample_datai), E(initial_centeri)) 03. E(dist_min) ← ASMINn(E(dist1), …, E(distk)) 04. for 1 ≤ i ≤ k 05. E(δi) ← E(dist_min) × E(disti)N − 1 06. E(δʹi) ← E(δi)ri 07. E(β) ← π(E(δʹi)) 08. send E(β) to CB CB: 09. for 1 ≤ i ≤ cnt 10. if D(E(βi)) = 0 then E(Ui) ← E(1) 11. else E(Ui) ← E(0) 12. send E(U) to CA CA: 13. E(V) ← π − 1(E(U)) 14. for 1 ≤ j ≤ k 15. for 1 ≤ l ≤ m 16. E(V’j,l)←SM(E(Vj), E(sample_datai,l)) 17. E(new_centerj.suml) ← E(new_centerj.suml) × E(V’j,l) 18. E(new_centerj.cnt) ← E(new_centerj.cnt) × E(Vj) 19. return E(δi) End Procedure |
5.2. Parallel k-Means Clustering Phase
- The thread pool performs parallel processing of the calculate_new_center procedure. The calculate_new_center procedure is the same as Procedure 1 in Algorithm 5.
- The SETC protocol calculates the termination condition (α) between the initial center point and the new center point (line 3).
- If the result of the SETC protocol (i.e., α) is 0, re-execute from line 1.
- If the result of the SETC protocol (i.e., α) is 1, CB adds a random number (i.e., r) to E(new_center) and sends it to the AU. Simultaneously, the random number r is sent to CB by the AU.
- CB decrypts E(new_center + r) and forwards it to the AU. Authenticated users perform the subtraction of r from new_center + r received from CB, obtaining the final k-means clustering result (lines 4~19).
| Algorithm 6 Parallel encrypted center search phase for k-means clustering |
| Input: E(data), E(node), E(threshold), E(initial_center) Output: cluster_center CA: 01. for 1 ≤ i ≤ n 02. thread_pool_push(calculate_new_center(k, m, cnt, E(data), E(initial_center), E(new_center)))//calculate_new_center() is the Procedure 1 in Algorithm 5 03. α = SETC(E(initial_center), E(new_center), E(threshold)) 04. if α = 1 05. for 1 ≤ i ≤ k 06. for 1 ≤ j ≤ m 07. E(new_centeri.sumj + r)←E(new_centeri.sumj) × E(r) 08. E(new_centeri.cnt + r)←E(new_centeri.cnt)×E(r) 09. else 10. E(initial_center)←E(new_center) 11. go to line 1 in Algorithm 6 12. send r to the AU and send E(new_center + r) to CB CB: 13. for 1 ≤ i ≤ k 14. for 1 ≤ j ≤ m 15. new_centeri.sumj + r ← D(E(new_centeri.sumj+r)) 16. new_centeri.cnt + r ← D(E(new_centeri.cnt+r)) 17. send new_center + r to the AU AU: 18. receive new_center + r from CB and r from CA 19. cluster_center = new_center.sum/new_center.cnt |
6. Security Analysis
6.1. Security Analysis of Security Protocols
- (1)
- ASMIN Protocol
- (2)
- ASMINn Protocol
6.2. Security Analysis of the k-Means Clustering Algorithm
6.3. Security Analysis of the Parallel k-Means Clustering Algorithm
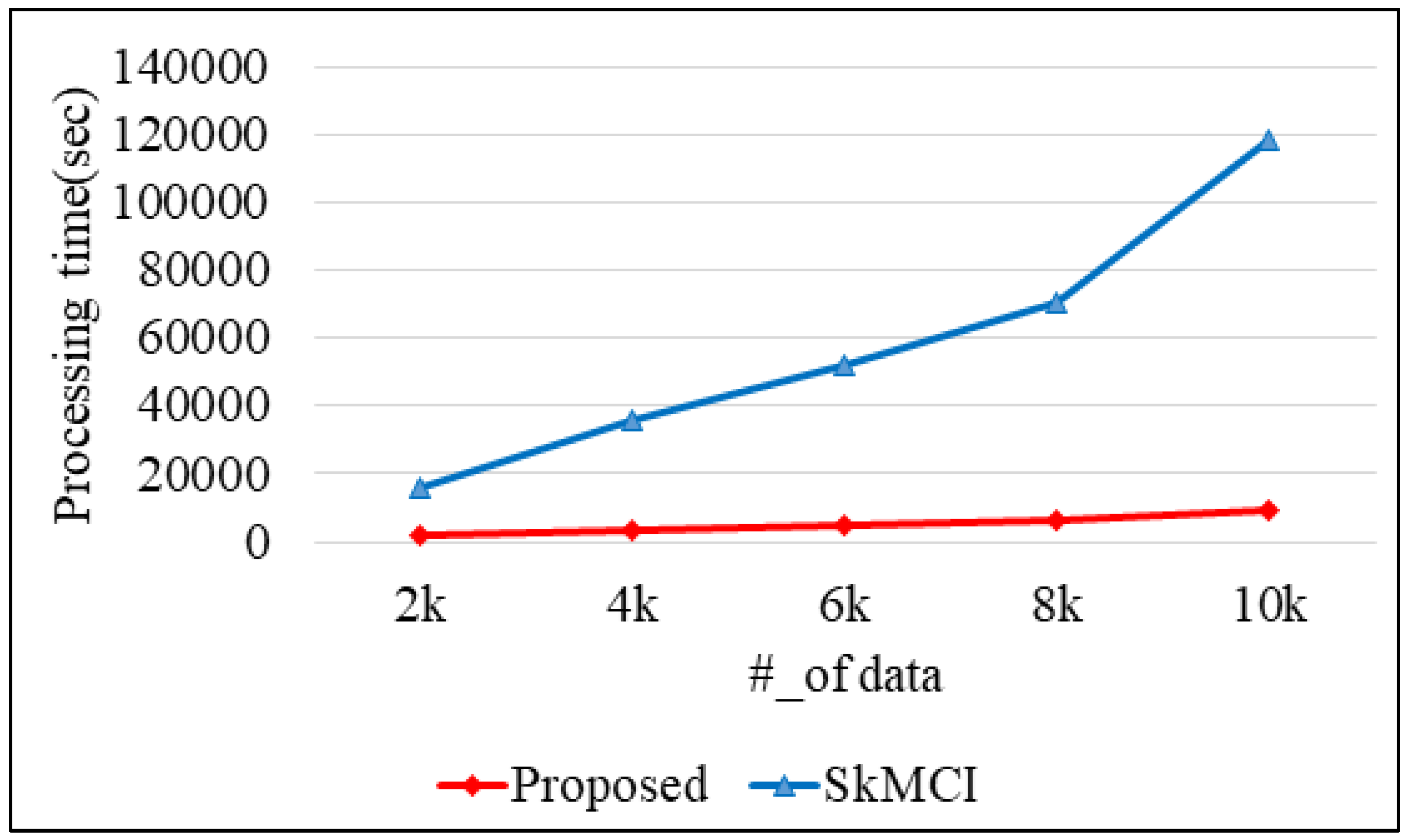
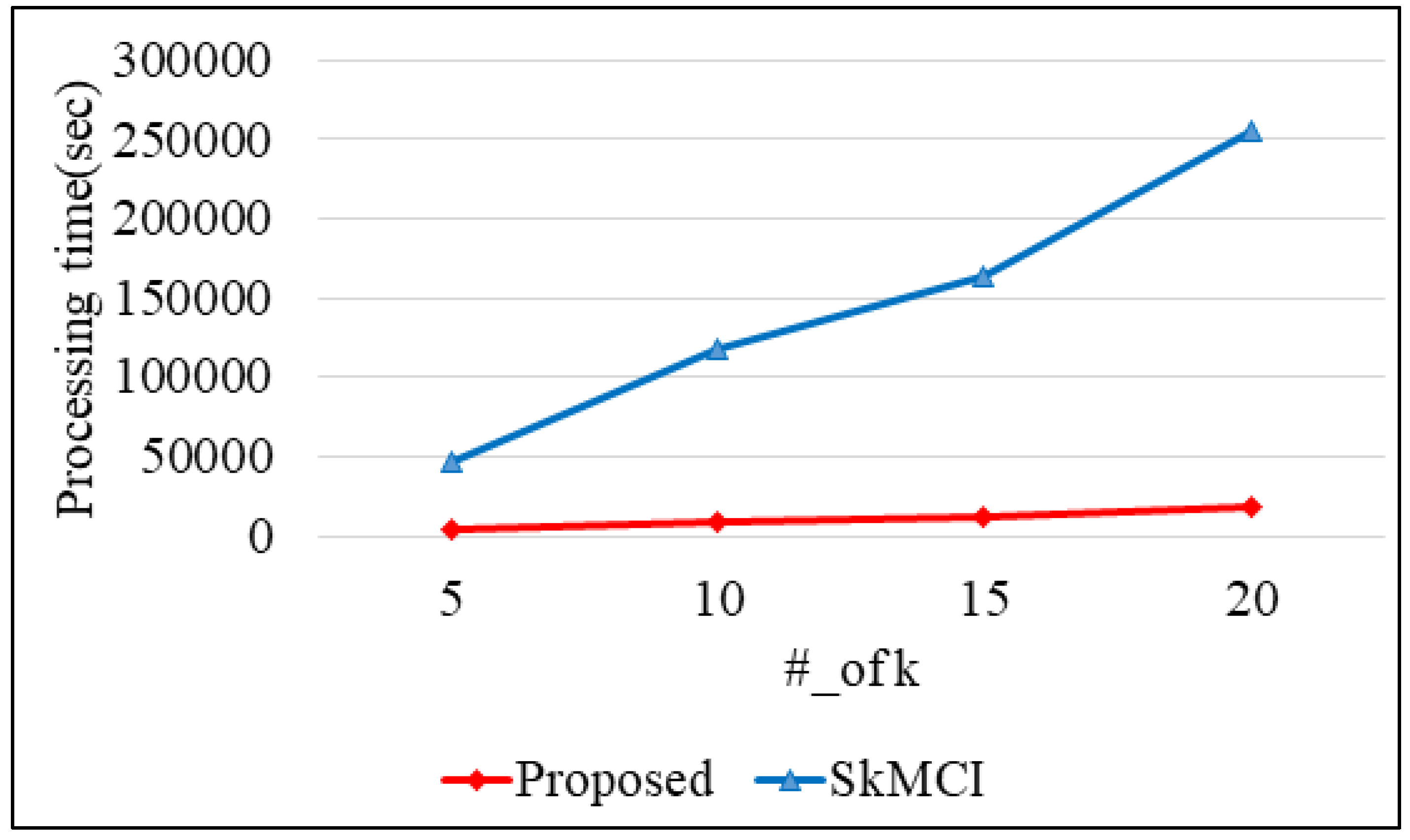
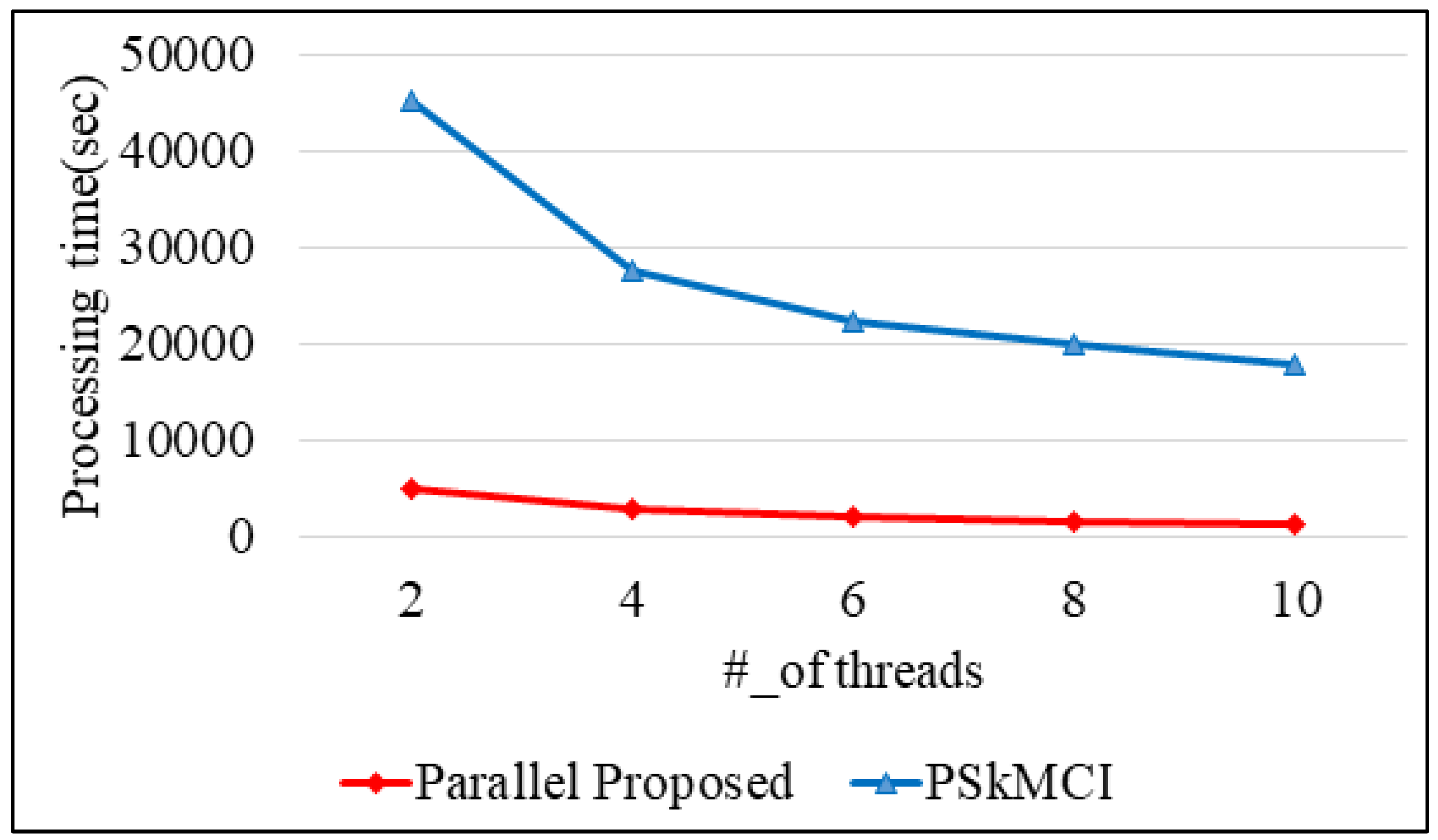
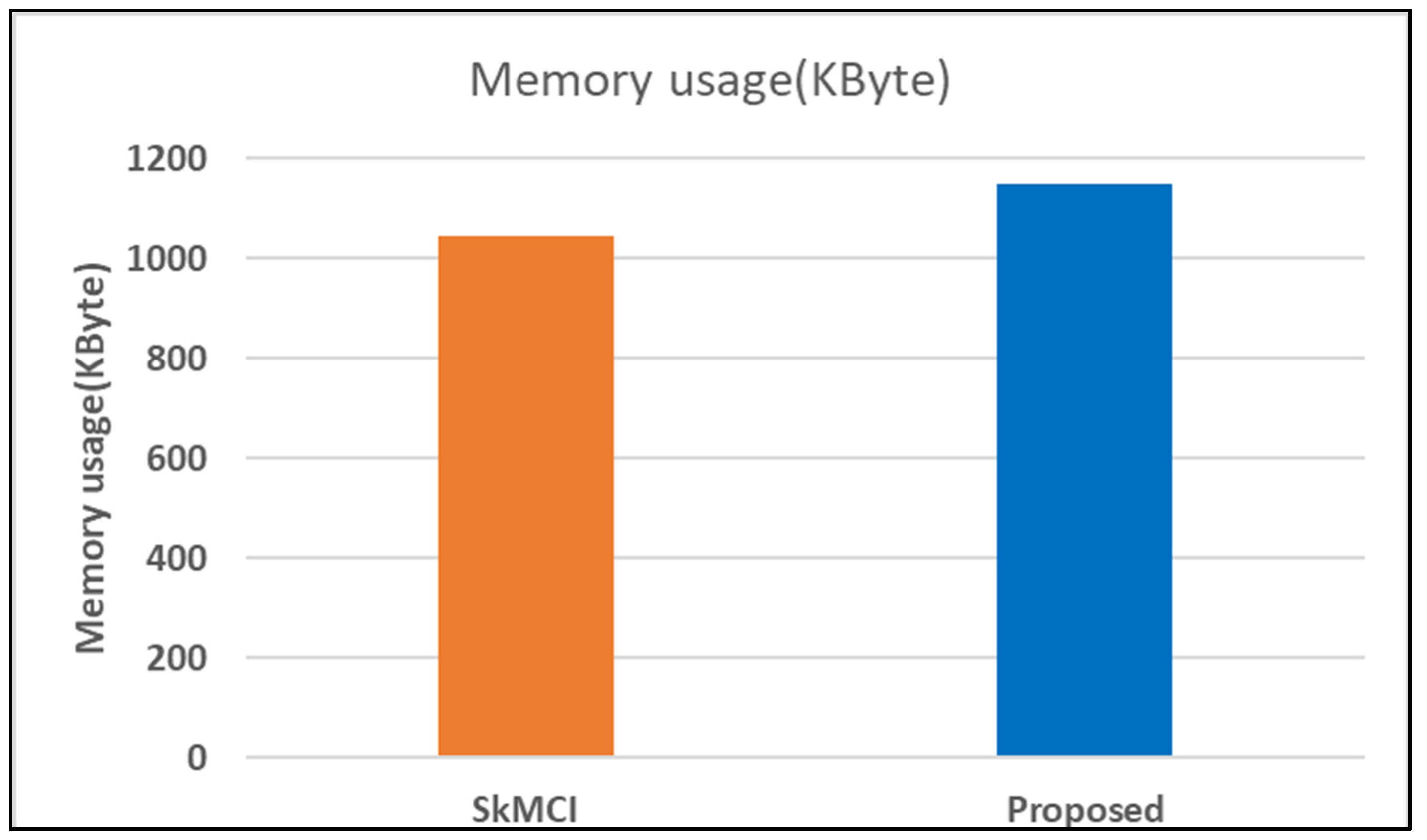
7. Performance Analysis
8. Discussion
8.1. The Time Complexity of the Proposed Secure Protocols
8.2. The Time Complexity of the Proposed k-Means Clustering Algorithm
8.3. Theoretical Analysis of the Proposed Algorithm in Terms of Privacy
- (1)
- Theoretical analysis of data privacy
- (2)
- Theoretical analysis of query privacy
- (3)
- Theoretical analysis of access pattern privacy
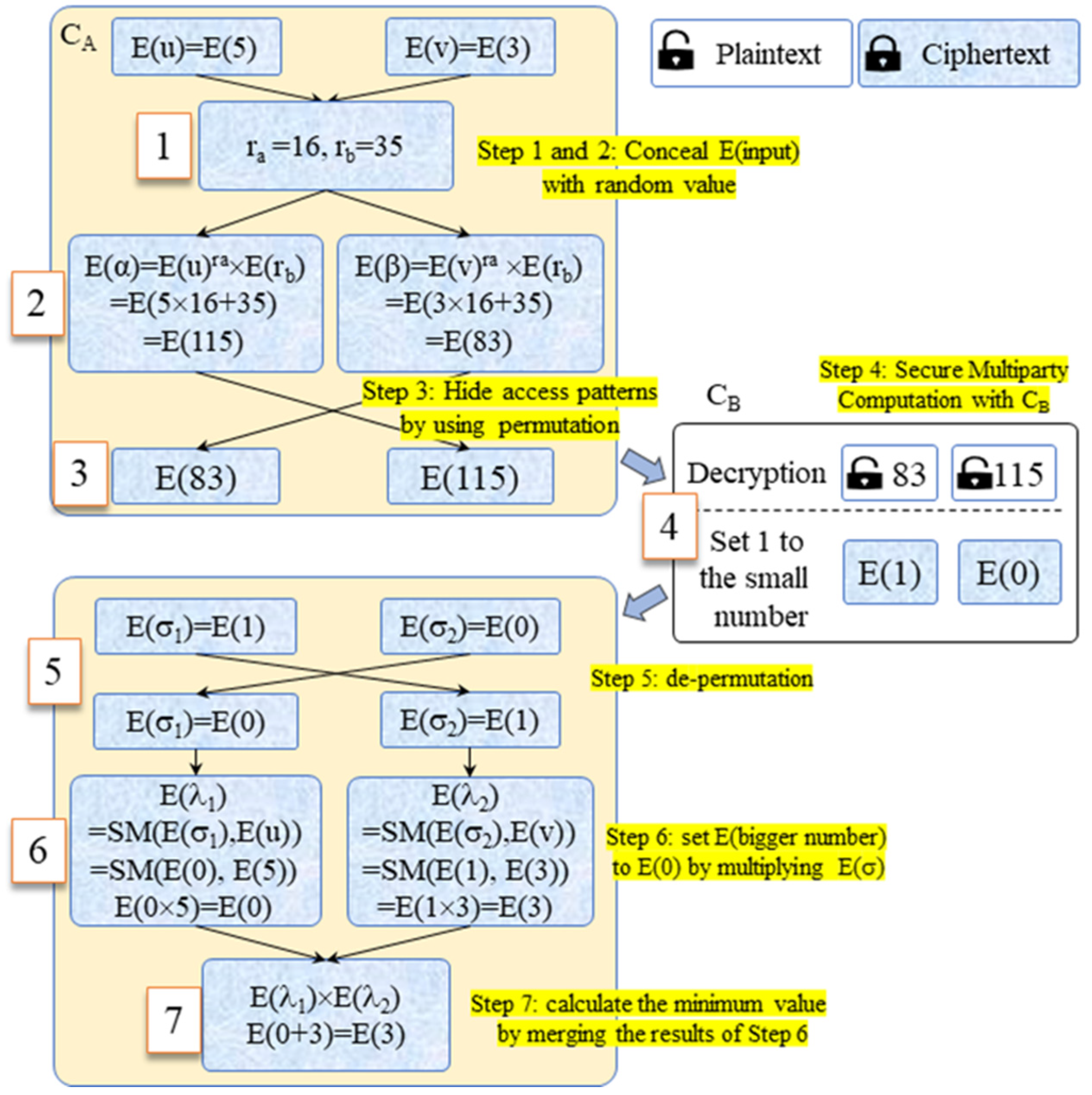
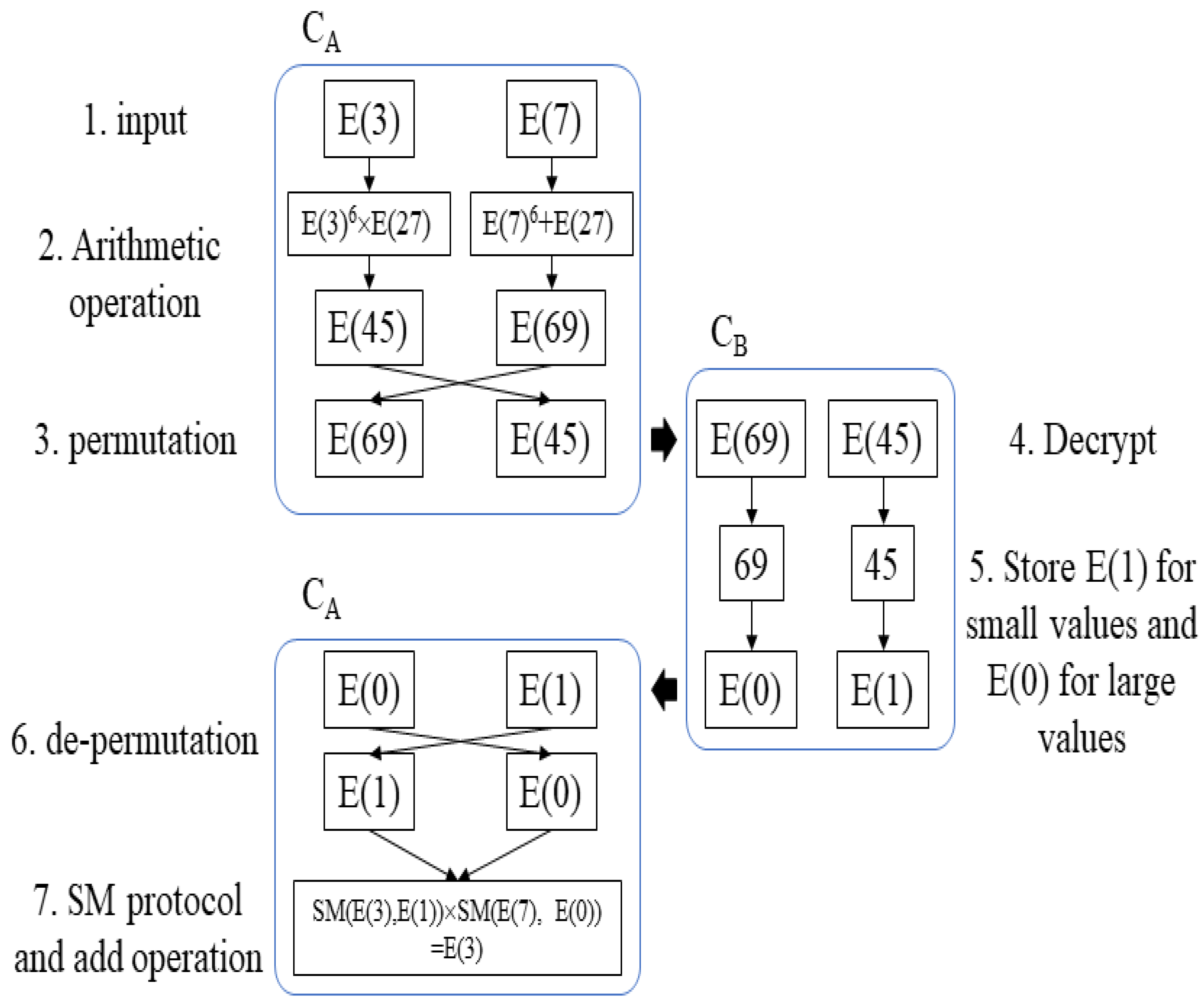
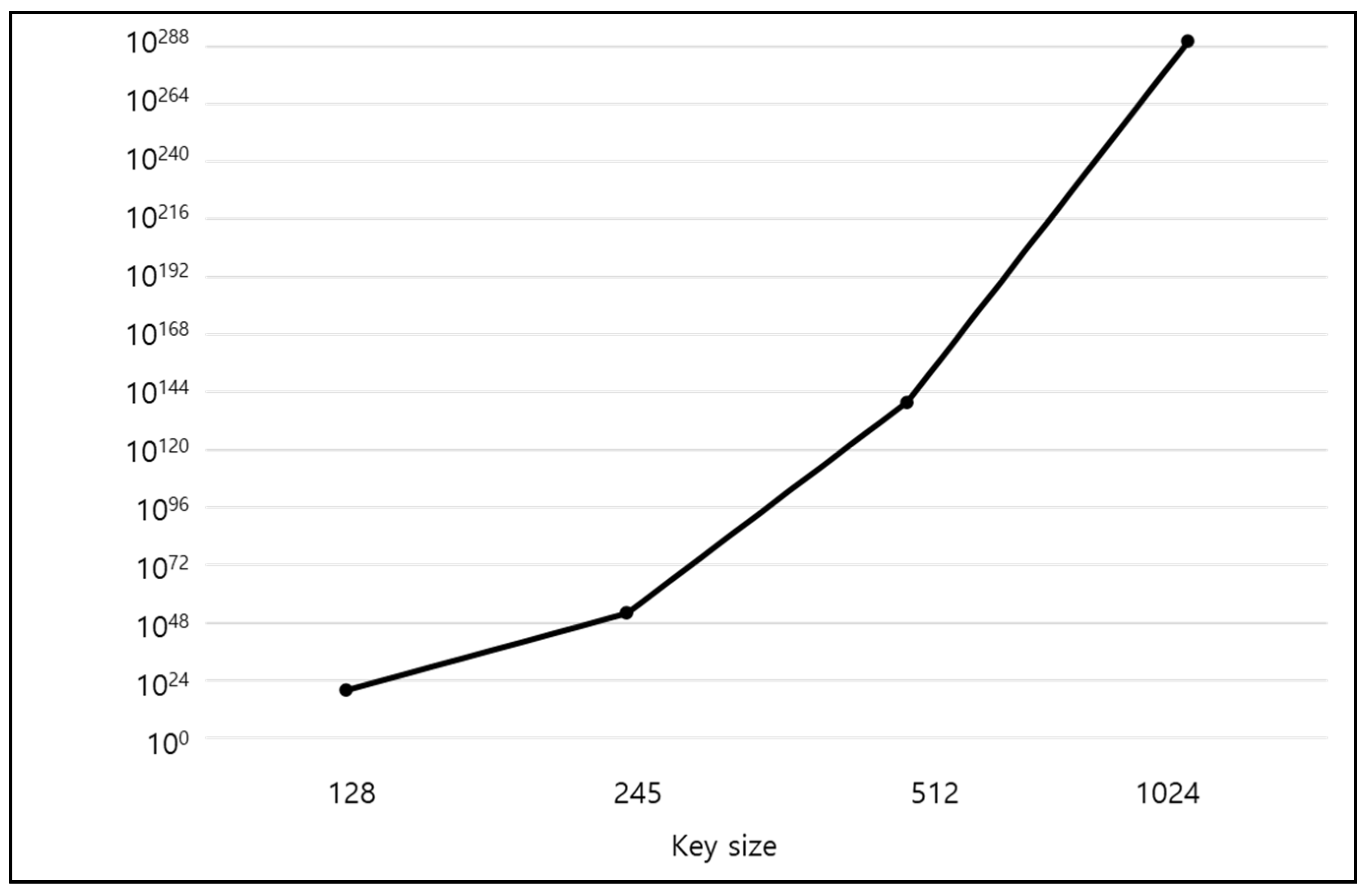
8.4. Practical Example of the Proposed k-Means Clustering Algorithm
9. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Agrawal, D.; Das, S.; Abbadi, A.E. Data management in the cloud: Challenges and opportunities. In Synthesis Lectures on Data Management; Springer Nature: Cham, Switzerland, 2012; Volume 4, p. 138. [Google Scholar] [CrossRef]
- Grolinger, K.; Higashino, W.A.; Tiwari, A.; Capretz, M.A. Data management in cloud environments: NoSQL and NewSQL data stores. J. Cloud Comput. Adv. Syst. Appl. 2013, 2, 22. [Google Scholar] [CrossRef]
- Zhao, L.; Sakr, S.; Liu, A.; Bouguettaya, A. Conclusions. In Cloud Data Management; Springer: Berlin/Heidelberg, Germany, 2014; p. 189. [Google Scholar] [CrossRef]
- Bisht, J.; Vampugani, V.S. Load and cost-aware min-min workflow scheduling algorithm for heterogeneous resources in fog, cloud, and edge scenarios. Int. J. Cloud Appl. Comput. (IJCAC) 2022, 12, 1–20. [Google Scholar] [CrossRef]
- Kumbhojkar, N.R.; Menon, A.B. Integrated predictive experience management framework (IPEMF) for improving customer experience: In the era of digital transformation. Int. J. Cloud Appl. Comput. (IJCAC) 2022, 12, 1–13. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, J.; Zhu, G. Data security and privacy in cloud computing. Int. J. Distrib. Sens. Netw. 2014, 10, 190903. [Google Scholar] [CrossRef]
- Sharma, Y.; Gupta, H.; Khatri, S.K. A security model for the enhancement of data privacy in cloud computing. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 898–902. [Google Scholar] [CrossRef]
- Garigipati, N.; Krishna, R.V. A study on data security and query privacy in cloud. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 337–341. [Google Scholar] [CrossRef]
- Sen, J. Security and Privacy Issues in Cloud Computing. Cloud Technol. Concepts Methodol. Tools Appl. 2015, 2015, 1585–1630. [Google Scholar] [CrossRef]
- Jansen, W.A. Cloud hooks: Security and privacy issues in cloud computing. In Proceedings of the 2011 44th Hawaii International Conference on System Sciences, Kauai, HI, USA, 4–7 January 2011; pp. 1–10. [Google Scholar] [CrossRef]
- Yiu, M.L.; Ghinita, G.; Jensen, C.S.; Kalnis, P. Enabling search services on outsourced private spatial data. VLDB J. 2010, 19, 363–384. [Google Scholar] [CrossRef]
- Boldyreva, A.; Chenette, N.; Lee, Y.; O’Neill, A. Order-preserving symmetric encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Cologne, Germany, 26–30 April 2009; pp. 224–241. [Google Scholar] [CrossRef]
- Boldyreva, A.; Chenette, N.; O’Neill, A. Order-preserving encryption revisited: Improved security analysis and alternative solutions. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; pp. 578–595. [Google Scholar] [CrossRef]
- Qi, Y.; Atallah, M.J. Efficient privacy-preserving k-nearest neighbor search. In Proceedings of the 28th International Conference on Distributed Computing Systems, Beijing, China, 17–20 June 2008; pp. 311–319. [Google Scholar] [CrossRef]
- Shaneck, M.; Kim, Y.; Kumar, V. Privacy preserving nearest neighbor search. In Machine Learning in Cyber Trust: Security, Privacy, and Reliability; Yu, P.S., Tsai, J.J.P., Eds.; Springer: Boston, MA, USA, 2009; pp. 247–276. [Google Scholar] [CrossRef]
- Vaidya, J.; Clifton, C. Privacy-preserving top-k queries. In Proceedings of the 21st International Conference on Data Engineering (ICDE’05), Tokyo, Japan, 5–8 April 2005; pp. 545–546. [Google Scholar] [CrossRef]
- Elmehdwi, Y.; Samanthula, B.K.; Jiang, W. Secure k-nearest neighbor query over encrypted data in outsourced environments. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 664–675. [Google Scholar] [CrossRef]
- Kim, H.J.; Kim, H.I.; Chang, J.W. A privacy-preserving kNN classification algorithm using Yao’s garbled circuit on cloud computing. In Proceedings of the 2017 IEEE 10th International Conference on Cloud Computing (CLOUD), Honolulu, HI, USA, 25–30 June 2017; pp. 766–769. [Google Scholar] [CrossRef]
- Zhou, L.; Zhu, Y.; Castiglione, A. Efficient k-NN query over encrypted data in cloud with limited key-disclosure and offline data owner. Comput. Secur. 2017, 69, 84–96. [Google Scholar] [CrossRef]
- Kim, H.I.; Kim, H.J.; Chang, J.W. A secure kNN query processing algorithm using homomorphic encryption on outsourced database. Data Knowledge. Eng. 2019, 123, 101602. [Google Scholar] [CrossRef]
- Sun, X.; Wang, X.; Xia, Z.; Fu, Z.; Li, T. Dynamic multi-keyword top-k ranked search over encrypted cloud data. Int. J. Secur. Its Appl. 2014, 8, 319–332. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, S.; Xia, Z. A distributed privacy-preserving data aggregation scheme for smart grid with fine-grained access control. J. Inf. Secur. Appl. 2022, 66, 103118. [Google Scholar] [CrossRef]
- Hozhabr, M.; Asghari, P.; Javadi, H.H.S. Dynamic secure multi-keyword ranked search over encrypted cloud data. J. Inf. Secur. Appl. 2021, 61, 102902. [Google Scholar] [CrossRef]
- Liu, D.; Bertino, E.; Yi, X. Privacy of outsourced k-means clustering. In Proceedings of the 9th ACM Symposium on Information, Computer and Communications Security, Kyoto, Japan, 4–6 June 2014; pp. 123–134. [Google Scholar] [CrossRef]
- Rao, F.Y.; Samanthula, B.K.; Bertino, E.; Yi, X.; Liu, D. Privacy-preserving and outsourced multi-user k-means clustering. In Proceedings of the 2015 IEEE Conference on Collaboration and Internet Computing (CIC), Hangzhou, China, 27–30 October 2015; pp. 80–89. [Google Scholar] [CrossRef]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Hazay, C.; Lindell, Y. Efficient Secure Two-Party Protocols: Techniques and Constructions. In Information Security and Cryptography; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef]
- Zhu, H.; Meng, X.; Kollios, G. Privacy Preserving Similarity Evaluation of Time Series Data. In Proceedings of the 17th International Conference on Extending Database Technology, Athens, Greece, 24–28 March 2014; pp. 499–510. [Google Scholar] [CrossRef]
- Hu, H.; Xu, J.; Xu, X.; Pei, K.; Choi, B.; Zhou, S. Private search on key-value stores with hierarchical indexes. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 628–639. [Google Scholar] [CrossRef]
- Liu, A.; Zhengy, K.; Liz, L.; Liu, G.; Zhao, L.; Zhou, X. Efficient secure similarity computation on encrypted trajectory data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Republic of Korea, 13–17 April 2015; pp. 66–77. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, X.; Guo, W.; Liu, X.; Chang, V. Privacy-preserving smart IoT-based healthcare big data storage and self-adaptive access control system. Inf. Sci. 2019, 479, 567–592. [Google Scholar] [CrossRef]
- Bugiel, S.; Nurnberger, S.; Sadeghi, A.R.; Schneider, T. Twin clouds: An architecture for secure cloud computing. In Proceedings of the Workshop on Cryptography and Security in Clouds, Zurich, Switzerland, 15–16 March 2011. [Google Scholar]
- Goldreich, O. Foundations of Cryptography: Volume 2, Basic Applications; Cambridge University Press: Cambridge, UK, 2009; Volume 2. [Google Scholar]
- Gray, J.; Sundaresan, P.; Englert, S.; Baclawski, K.; Weinberger, P.J. Quickly generating billion-record synthetic databases. In Proceedings of the 1994 ACM SIGMOD international conference on Management of data, Minneapolis, MN, USA, 24–27 May 1994; pp. 243–252. [Google Scholar] [CrossRef]
- Hashi, E.K.; Zaman, M.S.U.; Hasan, M.R. An expert clinical decision support system to predict disease using classification techniques. In Proceedings of the 2017 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 16–18 February 2017; pp. 396–400. [Google Scholar] [CrossRef]
- Khalili-Damghani, K.; Abdi, F.; Abolmakarem, S. Solving customer insurance coverage recommendation problem using a two-stage clustering-classification model. Int. J. Manag. Sci. Eng. Manag. 2019, 14, 9–19. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Data Privacy | Query Privacy | Hiding Data Access Pattern | Index | Computational Overhead | Encryption | User Involvement Computation | Security Risk | |
|---|---|---|---|---|---|---|---|---|---|
| Schemes | |||||||||
| D. Liu et al. [24] | Supported | Supported | Not supported | Order-preserving index | High | Homomorphic encryption | Partially involved | High | |
| F. Rao et al. [25] | Supported | Supported | Supported | None | High | Homomorphic encryption supporting addition | Not involved | Low | |
| Y. Yang et al. [31] | Supported | Supported | Not supported | None | High | Attribute-based encryption | Not involved | High | |
| Proposed | Supported | Supported | Supported | Kd-tree | Moderate | Paillier encryption | Not involved | Low | |
| Secure Protocol | Computational Cost without a Random Value Pool | Computational Cost with a Random Value Pool |
|---|---|---|
| SM protocol | 3 × E | 1 × E |
| ASMIN protocol | 10 × E | 4 × E |
| Execution Image of the ASMIN Protocol | Simulation Image | |
|---|---|---|
| CA | Input Data: E(α), E(β) Generated Variables: r1, r2, Output Data: E(min) | Input Data: E(u), E(v) Generated Variables: r1, r2, Output Data: E(min’) |
| CB | Input Data: X, Y Output Data: E(r1), E(r2) | Input Data: x, y Output Data: E(w1), E(w2) |
| CA’s Accessible Execution Image | Simulation Image | |
|---|---|---|
| Encrypted Data | E(data) | E(sim_data) |
| Encrypted Query | E(threshold) | E(sim_threshold) |
| Information Obtainable by CB | Simulation Image | |
|---|---|---|
| Encrypted Data Received from CA | E(data) | E(sim_data) |
| Decrypted Data | data | sim_data |
| Synthetic Uniform Data [34] Description: Synthetic Data with a Uniform Distribution | |
|---|---|
| Number of data points | 100,000 |
| Number of columns | 6 |
| Data domain | 0~512 |
| Proposed k-Means Clustering Algorithm (SkMCA) | SkMCI [25] |
|---|---|
| Proposed Parallel k-Means Clustering Algorithm (PSkMCA) | PSkMCI (Parallel processing version of SkMCI [25]) |
| Parameter | Values | Default |
|---|---|---|
| # of data points (n) | 2k, 4k, 6k, 8k, 10k | 10k |
| k | 5, 10, 15, 20 | 10 |
| # of data dimensions (m) | 2 | 2 |
| Encryption key size (K) | 512 | 512 |
| Bit length | 22 | 22 |
| Threshold | 10 | - |
| # of Threads | 2, 4, 6, 8, 10 | 10 |
| Encryption Operation Protocol | Function | Time Complexity |
|---|---|---|
| ASMIN protocol | MIN operation | O(8) ≈ O(1) |
| ASMINn protocol | MIN operation among n inputs | O(8 × log2n) ≈ O(log2n) |
| k-Means Clustering Algorithm | Time Complexity |
|---|---|
| SkMCA (proposed) | O(n × k × (log2k + m)) |
| SkMCI [23] | O(n × k × (l × log2k + m)) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Kim, H.-J.; Lee, H.-J.; Chang, J.-W. A Parallel Privacy-Preserving k-Means Clustering Algorithm for Encrypted Databases in Cloud Computing. Appl. Sci. 2024, 14, 835. https://doi.org/10.3390/app14020835
Song Y, Kim H-J, Lee H-J, Chang J-W. A Parallel Privacy-Preserving k-Means Clustering Algorithm for Encrypted Databases in Cloud Computing. Applied Sciences. 2024; 14(2):835. https://doi.org/10.3390/app14020835
Chicago/Turabian StyleSong, Youngho, Hyeong-Jin Kim, Hyun-Jo Lee, and Jae-Woo Chang. 2024. "A Parallel Privacy-Preserving k-Means Clustering Algorithm for Encrypted Databases in Cloud Computing" Applied Sciences 14, no. 2: 835. https://doi.org/10.3390/app14020835