
Research on a Mongolian Text to Speech Model Based on Ghost and ILPCnet

Abstract
:Featured Application
Abstract
1. Introduction
2. Para-WaveNet Mongolian Speech Synthesis Model
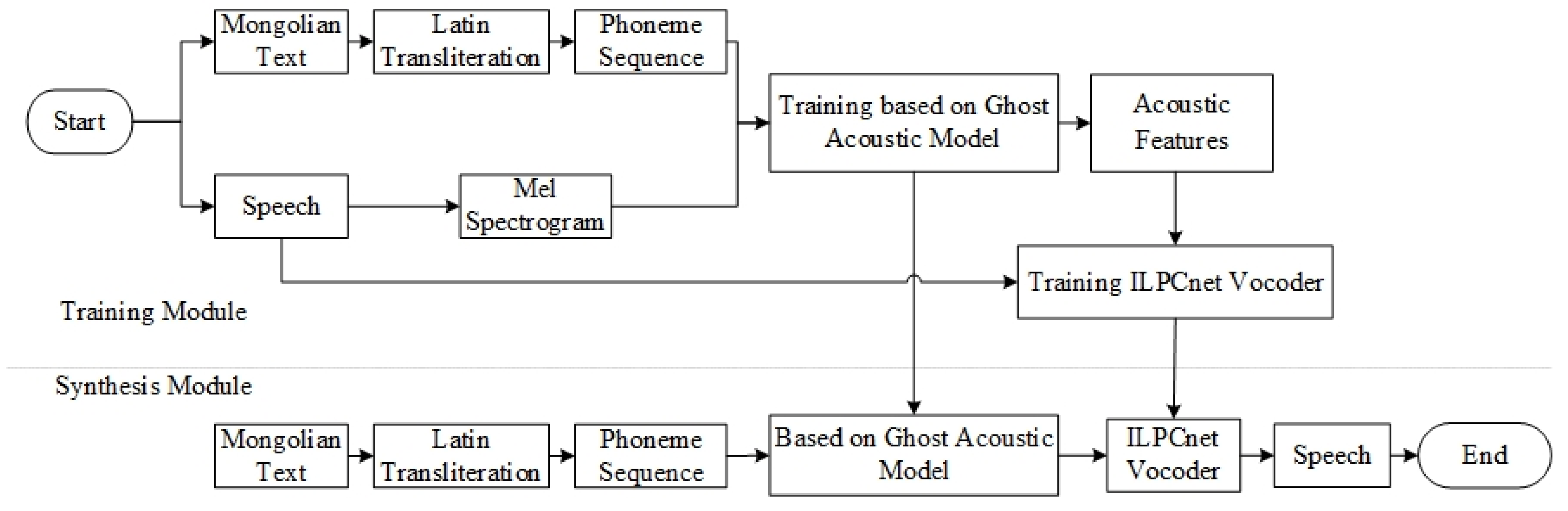
3. Mongolian Speech Synthesis Model Based on Ghost-ILPCnet
3.1. Mongolian Phoneme Pre-Training Model Based on Bang
3.2. Encoder–Decoder
3.2.1. Multi-Resolution STFT Auxiliary Loss
3.2.2. Ghost Module
3.3. ILPCnet Vocoder
4. Data Experiment
4.1. Experimental Data
4.2. Model Training Platform
4.3. Indicators for Model Performance Evaluation
4.4. Experiment Process
4.5. Data Test for the Model and Results
4.5.1. Training Loss Curve
4.5.2. Word Error Rate Analysis
4.5.3. Real-Time Rate Analysis
4.5.4. MOS Subjective Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Klatt, D.H. Review of Text-to-speech Conversion for English. J. Acoust. Soc. Am. 1987, 82, 737–793. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Sotelo, J.; Mehri, S.; Kumar, K.; Santos, J.F.; Kastner, K.; Courville, A.; Bengio, Y. Char2wav: End-to-end Speech Synthesis. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Mehri, S.; Kumar, K.; Gulrajani, I.; Kumar, R.; Jain, S.; Sotelo, J.; Courville, A.; Bengio, Y. SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. arXiv 2016, arXiv:1612.07837. [Google Scholar]
- Arik, S.O.; Chrzanowski, M.; Coates, A.; Diamos, G.; Gibiansky, A.; Kang, Y.; Li, X.; Miller, J.; Ng, A.; Raiman, J.; et al. Deep Voice: Real-time Neural text-to-speech. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 195–204. [Google Scholar]
- Deri, A.; Knight, K. Grapheme-to-phoneme Models for (almost) any Language. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 399–408. [Google Scholar]
- Gibiansky, A.; Arik, S.; Diamos, G.; Miller, J.; Peng, K.; Ping, W.; Raiman, J.; Zhou, Y. Deep voice 2: Multi-speaker Neural text-to-speech. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, LA, USA, 4–9 December 2017; pp. 2962–2970. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.O.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep Voice 3: 2000-Speaker Neural Text-to-Speech. arXiv 2017. [Google Scholar] [CrossRef]
- Peng, K.; Ping, W.; Song, Z.; Zhao, K. Non-autoregressive Neural text-to-speech. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 7586–7598. [Google Scholar]
- Liu, R.; Bao, F.; Gao, G. Mongolian Text-to-Speech System Based on Deep Neural Network. In Proceedings of the National Conference on Man-Machine Speech Communication, Lianyungang, China, 11–13 October 2017; pp. 99–108. [Google Scholar]
- Liu, Z. Research on End-to-End Mongolian Speech. Master’s Thesis, Inner Mongolia University, Hohhot, China, 2019. [Google Scholar]
- Liu, R.; Kang, S.; Gao, G.; Li, J.; Bao, F. MonTTS: A Real-time and High-fidelity Mongolian TTS Model with Pure Non-autoregressive Mechanism. J. Chin. Inf. Process. 2022, 36, 86–97. [Google Scholar]
- Bao, F.L.; Gao, G.L.; Yan, X.L. Research on Grapheme to Phoneme Conversion for Mongolian. Appl. Res. Comput. 2013. [Google Scholar]
- Dong, C.; Xie, Y.; Ding, B.; Shen, Y.; Li, Y. Collaborating Heterogeneous Natural Language Processing Tasks via Federated Learning. arXiv 2022, arXiv:2212.05789. [Google Scholar]
- Peng, H.; Kasai, J.; Pappas, N.; Yogatama, D.; Wu, Z.; Kong, L.; Schwartz, R.; Smith, N.A. ABC: Attention with Bounded-Memory Control. arXiv 2021, arXiv:2110.02488. [Google Scholar]
- Zhang, Y.; Zhu, H.; Wang, Y.; Xu, N.; Li, X.; Zhao, B. A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-Wise Perspective in Angular Space. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 4892–4903. [Google Scholar]
- Zheng, W. Pre-Trained Models for Natural Language Processing Editorial. ZTE Technol. J. 2022, 28, 1–2. [Google Scholar]
- Yeshambel, T.; Mothe, J.; Assabie, Y. Learned Text Representation for Amharic Information Retrieval and Natural Language Processing. Information 2023, 14, 195. [Google Scholar] [CrossRef]
- Chifu, A.-G.; Fournier, S. Sentiment Difficulty in Aspect-Based Sentiment Analysis. Mathematics 2023, 11, 4647. [Google Scholar] [CrossRef]
- Jin, W.; Cheng, Y.; Shen, Y.; Chen, W.; Ren, X. A Good Prompt is Worth Millions of Parameters? Low-Resource Prompt-Based Learning for Vision-Language Models. arXiv 2021, arXiv:2110.08484. [Google Scholar]
- Kalchbrenner, N.; Elsen, E.; Simonyan, K.; Noury, S.; Casagrande, N.; Lockhart, E.; Stimberg, F.; Oord, A.; Dieleman, S.; Kavukcuoglu, K. Efficient Neural Audio Synthesis. arXiv 2018, arXiv:1802.08435. [Google Scholar]
- Zhao, L.; Liu, C.; Liu, X.; Zhang, L. Prolate spheroidal wave functions signal time-frequency analysis based on Fourier series. J. Mod. Electron. Technol. 2022, 17, 35–40. [Google Scholar]
- Gao, E. Research on the application of linear prediction in speech signal processing. China New Telecommun. 2022, 24, 72–74. [Google Scholar]
- Qi, X.; BORJIGIN, B.T.; Sun, Y.; Zhao, X. A dataset of Mongolian-Chinese speech translation. China Sci. Data 2022, 7, 2. [Google Scholar]
- Song, N. Research on SignLanguage-to-Mandarin/Tibetan EmotionalSpeech Conversion by Combining FacialExpression Recognition. Master’s Thesis, Northwest Normal University, Lanzhou, China, 2019. [Google Scholar]
- Tang, J.; Zhang, L.; Li, J. A real-time robust speech synthesis method based on improved attention mechanism. J. Signal Process. 2022, 3, 527–535. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation | Input Output |
|---|---|
| ordinary convolution | |
| linear transformation | |
| concat |
| Audio File Name | Corresponding Mongolian Text |
|---|---|
| ahei40-0001 | ᠡᠭᠦᠳᠡᠨ ᠲᠢᠩᠬᠢᠮ ᠤᠨ ᠳᠤᠤᠷᠠ ᠲᠠᠯᠠ ᠳ᠋ᠦ᠍ ᠪᠤᠢ |
| ahei40-0002 | ᠪᠢ ᠤᠳᠤ ᠲᠠᠨ ᠳ᠋ᠦ᠍ ᠨᠢᠭᠡ ᠬᠡᠰᠡᠭ ᠠᠪᠴᠦ ᠦᠭ᠍ᠭᠦᠶᠡ |
| ahei40-0003 | ᠬᠡᠷᠪᠡ ᠲᠠ ᠪᠠᠰᠠ ᠶᠠᠮᠠᠷ ᠱᠠᠭᠠᠷᠳᠠᠯᠭᠠ ᠪᠠᠶᠢᠪᠠᠯ ᠨᠠᠳᠠ ᠳ᠋ᠦ᠍ ᠬᠡᠯᠡᠬᠦ ᠪᠤᠯᠪᠠᠤ |
| ahei40-0004 | ᠲᠡᠭᠦᠨ ᠳ᠋ᠦ᠍ ᠰᠠᠨᠠᠭᠠ ᠵᠤᠪᠠᠬᠤ ᠬᠡᠷᠡᠭ ᠦᠬᠡᠢ |
| Mongolian Text | Latin Sequence |
|---|---|
| ᠡᠭᠦᠳᠡᠨ ᠲᠢᠩᠬᠢᠮ ᠤᠨ ᠳᠤᠤᠷᠠ ᠲᠠᠯᠠ ᠳ᠋ᠦ᠍ ᠪᠤᠢ | u: den tinghimon dvr tald bvi |
| ᠪᠢ ᠤᠳᠤ ᠲᠠᠨ ᠳ᠋ᠦ᠍ ᠨᠢᠭᠡ ᠬᠡᠰᠡᠭ ᠠᠪᠴᠦ ᠦᠭ᠍ᠭᠦᠶᠡ | bi vdv: tand nege heseg abcv ugye |
| ᠬᠡᠷᠪᠡ ᠲᠠ ᠪᠠᠰᠠ ᠶᠠᠮᠠᠷ ᠱᠠᠭᠠᠷᠳᠠᠯᠭᠠ ᠪᠠᠶᠢᠪᠠᠯ ᠨᠠᠳᠠ ᠳ᠋ᠦ᠍ ᠬᠡᠯᠡᠬᠦ ᠪᠤᠯᠪᠠᠤ | herbe ta: bas yamar sha: rdelge baibe: l naded heleh bvlbasv |
| ᠲᠡᠭᠦᠨ ᠳ᠋ᠦ᠍ ᠰᠠᠨᠠᠭᠠ ᠵᠤᠪᠠᠬᠤ ᠬᠡᠷᠡᠭ ᠦᠬᠡᠢ | tegund sana: jvbehv hereg ugei |
| Name | Parameters |
|---|---|
| CPU | Intel Core i5-10500 CPU@3.10GHz |
| GPU | Nvidia Tesla P100 |
| Operating system | Ubuntu 18.04.5 |
| Programming language | Python 3.6.13 |
| Deep learning framework | Pytorch 0.4.1 |
| MOS Score | Voice-Quality Evaluation Standards |
|---|---|
| 1 | Extremely poor, the pronunciation is not clear, the delay is long, and it is impossible to distinguish |
| 2 | Severe distortion, blurred speech, obvious delay, and almost indistinguishable |
| 3 | Obvious distortion, certain delay, and there is noise, but the clarity is acceptable |
| 4 | The distortion is not obvious, the delay is short, there is noise, and the voice can be heard clearly |
| 5 | Smooth and natural, short delays, flawless, and clear pronunciation |
| Parameters | Value |
|---|---|
| SqueezeExcite | se_ratio: 0.25 reduced_base_chs = None act_layer = nn.ReLU gate_fn = hard_sigmoid divisor = 4 |
| ConvBnAct | stride = 1 act_layer = nn.ReLU |
| GhostNet | num_classes: 1000 width: 1.0 dropout: 0.3 |
| Bang | DEFAULT_MAX_SOURCE_POSITIONS: 512 DEFAULT_MAX_TARGET_POSITIONS: 512 |
| Model | STFT Loss | Missing Words | Wrong Words | Error Rate |
|---|---|---|---|---|
| ParaNet (character) | 11 | 11 | 60% | |
| ParaNet (phoneme) | 10 | 10 | 53% | |
| Para-WaveNet (character) | 13 | 13 | 66% | |
| Para-WaveNet (phoneme) | 10 | 10 | 56% | |
| Improved Para-WaveNet (phoneme) | 9 | 9 | 53% | |
| Transfomer (phoneme) | 3 | 3 | 17% | |
| Transfomer (phoneme) | 2 | 2 | 10% | |
| Ghost-ILPCnet (phoneme) (without Bang pre-training) | 1 | 1 | 10% | |
| Ghost-ILPCnet (phoneme) (Bang pre-training) | 1 | 1 | 6% |
| Model | RTF |
|---|---|
| Mel + WaveNet | 0.2412 |
| ParaNet | 0.1886 |
| Improved Para-WaveNet | 0.0859 |
| Transformer | 0.9141 |
| Tactron2 | 0.9411 |
| Mel + ILPCnet | 0.1921 |
| Ghost-ILPCnet (without Bang pre-training) | 0.0021 |
| Ghost-ILPCnet (Bang pre-training) | 0.0041 |
| Model | MOS Score |
|---|---|
| Real Voice | 4.62 |
| Mel + WaveNet | 4.01 |
| ParaNet | 4.32 |
| Improved Para-WaveNet | 4.21 |
| Transformer | 4.34 |
| Tactron2 | 4.45 |
| Mel + ILPCnet | 4.03 |
| Ghost-ILPCnet (without Bang pre-training) | 4.22 |
| Ghost-ILPCnet (Bang pre-training) | 4.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Q.-D.-E.-J.; Wang, L.; Zhang, W.; Li, L. Research on a Mongolian Text to Speech Model Based on Ghost and ILPCnet. Appl. Sci. 2024, 14, 625. https://doi.org/10.3390/app14020625
Ren Q-D-E-J, Wang L, Zhang W, Li L. Research on a Mongolian Text to Speech Model Based on Ghost and ILPCnet. Applied Sciences. 2024; 14(2):625. https://doi.org/10.3390/app14020625
Chicago/Turabian StyleRen, Qing-Dao-Er-Ji, Lele Wang, Wenjing Zhang, and Leixiao Li. 2024. "Research on a Mongolian Text to Speech Model Based on Ghost and ILPCnet" Applied Sciences 14, no. 2: 625. https://doi.org/10.3390/app14020625