

Research on Rolling Bearing Fault Diagnosis Method Based on ECA-MRANet
Abstract
:1. Introduction
2. Fault Feature Extraction of Rolling Bearings
2.1. Time–Frequency-Diagram-Based Signal Characterisation Methods
2.2. Feature Extraction Method for Rolling Bearings Based on SSA Optimization VMD
2.2.1. Variational Mode Decomposition
2.2.2. Sparrow Search Algorithm
2.2.3. Establishing a SSA-VMD Algorithm Framework
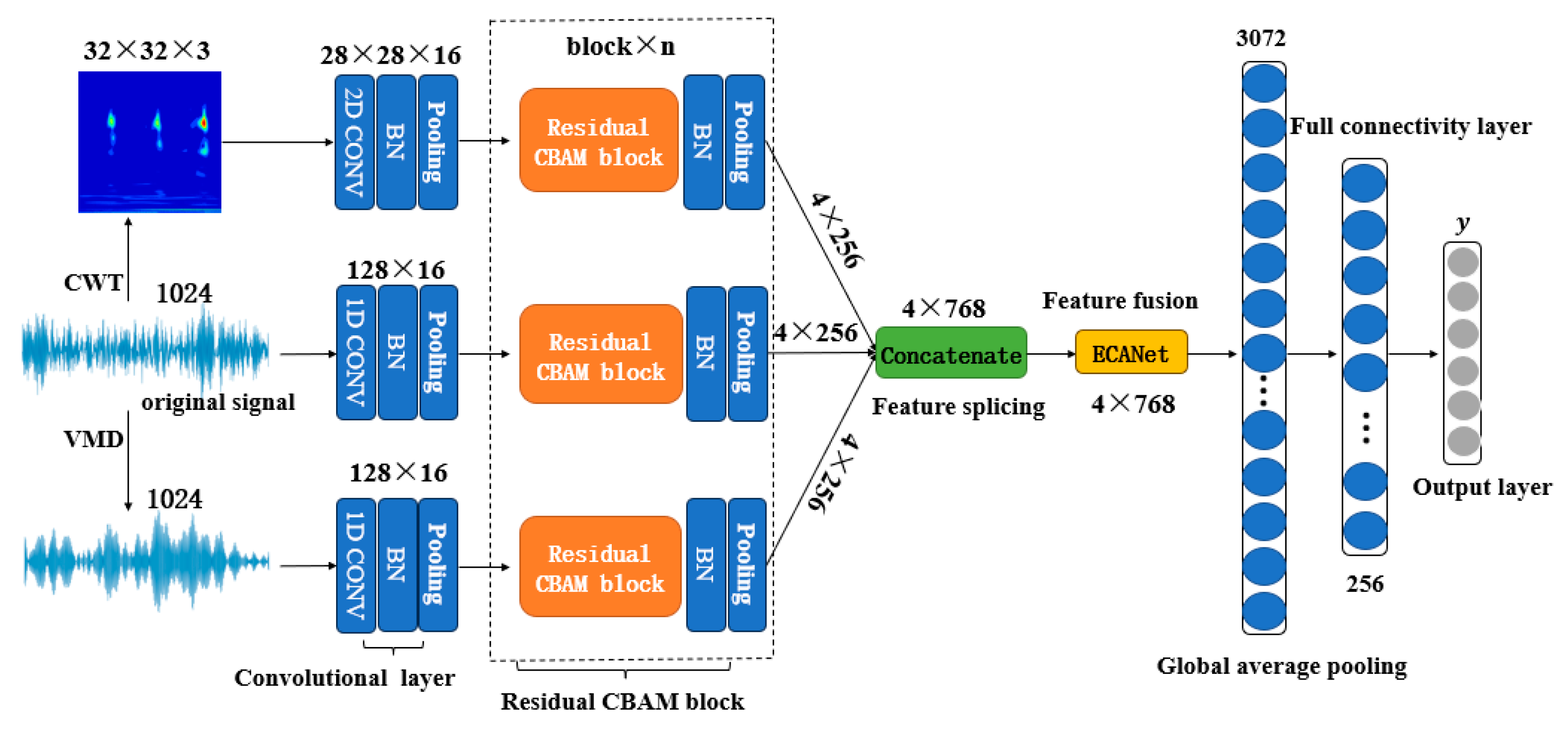
3. Fault Diagnosis Method Based on ECA-MRANet
3.1. Based on Improved Residual Block Feature Extraction
3.1.1. Convolutional Block Attention Module
3.1.2. Residual CBAM Block
3.2. Efficient Channel Attention
3.3. ECA-MRANet Network Model
4. Experimentation and Analysis
4.1. Description of Experimental Data
4.2. Experimental Data Preprocessing
4.2.1. A Time–Frequency-Diagram–Based Characterization Method for Experimental Data
4.2.2. VMD Decomposition of Experimental Data
4.3. Selection of the Main Parameters of the ECA-MRANet Model and Their Effects
4.3.1. Selection of the Number of Residual CBAM Blocks
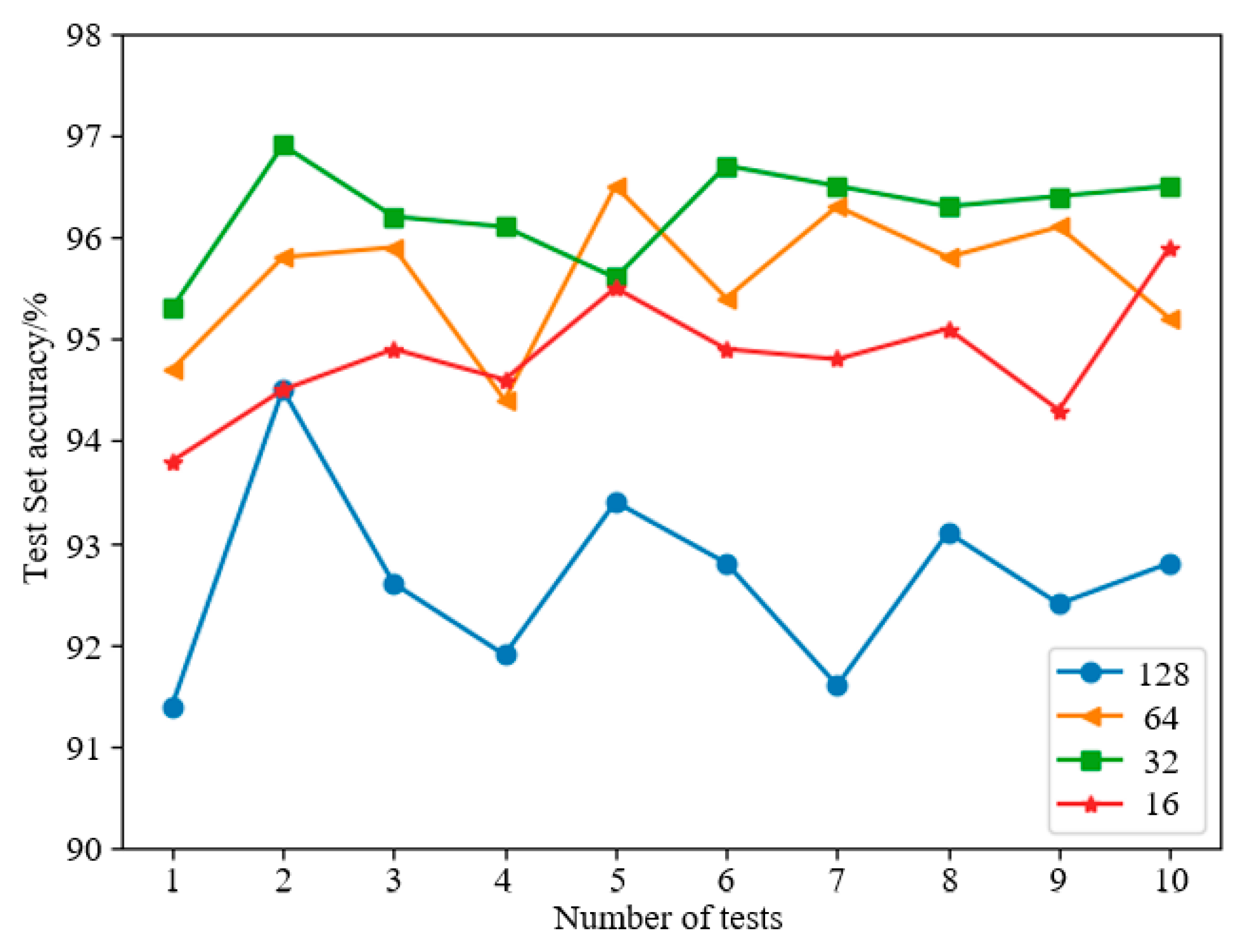
4.3.2. Batch Samples Size Selection
4.4. ECA-MRANet Model Performance Analysis
4.4.1. Model Performance Analysis under the Same Operating Conditions
4.4.2. Model Performance Analysis across Working Conditions
4.4.3. Small-Sample Transfer Learning under Different Working Conditions
5. Conclusions and Prospects
5.1. Conclusions
- The network is capable of simultaneously taking in original data, wavelet-transformed time–frequency diagrams, and the optimal Intrinsic Mode Function (IMF) of Variational Mode Decomposition (VMD). This enriched input ensures that the network processes a diverse set of fault information. T-SNE visualization of features extracted by ECA-MRANet demonstrates its ability to significantly enhance feature distinctiveness, effectively improving the model’s feature learning and diagnostic accuracy.
- Under identical working conditions, the diagnostic accuracy of the ECA-MRANet model shows notable improvement compared with other traditional network models, achieving an average accuracy of 96.96%. This underscores the importance of enhancing the input of fault diagnosis network models.
- Utilizing ECA-MRANet for transfer learning on fault data across different working conditions yields an accuracy rate exceeding 90%, indicating robust generalization capabilities.
5.2. Prospects
- The ECA-MRANet fault diagnosis model proposed in this paper has made some progress in extracting fault characteristics and performing under different working conditions. However, cross-platform cross-device experiments need to be verified. In addition, the network is more complex and the number of parameters is relatively large, so determining how to carry out lightweight processing on the network without sacrificing the diagnostic accuracy is worth further research.
- Rolling bearing faults can usually be detected and diagnosed by a variety of signals (vibration, electrical, temperature, etc.). In this paper, the bearing vibration signal is used as input data to study bearing faults. Therefore, determining how to effectively fuse different signal data and studying fault diagnosis under multi-mode data input, thereby improving the accuracy and reliability of fault detection, is another important research direction.
- Most current deep learning methods rely on offline training and offline inference, which cannot meet real-time requirements. Therefore, studying real-time rolling bearing fault diagnosis based on deep learning is a future research direction.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, G.; Yan, T.; Yang, G.; Chai, H.; Cao, C. A review on rolling bearing fault signal detection methods based on different sensors. Sensors 2022, 22, 8330. [Google Scholar] [CrossRef] [PubMed]
- Ma, H.; Li, H.F.; Yu, K.; Zeng, J. Dynamic modeling and vibration analysis of rolling bearings with local faults. J. Northeast. Univ. Nat. Sci. 2020, 41, 343. [Google Scholar]
- Shao, J.; Chen, Z.; Xuan, Q. Generative Adversial Network Enhanced Bearing Roller Defect Detection and Segmentation. Deep Learning Applications. In Computer Vision, Signals and Networks; World Scientific Book: Singapore, 2023; pp. 41–60. [Google Scholar]
- Guo, J.; Liu, X.; Li, S.; Wang, Z. Bearing intelligent fault diagnosis based on wavelet transform and convolutional neural network. Shock Vib. 2020, 2020, 1–14. [Google Scholar] [CrossRef]
- Liu, J.; Wang, C.; Wu, Q. Application of Improved Generative Adversarial Network in Bearing Fault Diagnosis. Noise Vib. Control 2021, 41, 89. [Google Scholar]
- Liu, W.; Zhang, Z.; Zhang, J.; Huang, H.; Zhang, G.; Peng, M. A Novel Fault Diagnosis Method of Rolling Bearings Combining Convolutional Neural Network and Transformer. Electronics 2023, 12, 1838. [Google Scholar] [CrossRef]
- Mohiuddin, M.; Islam, M.S.; Islam, S.; Miah, M.S.; Niu, M.B. Intelligent Fault Diagnosis of Rolling Element Bearings Based on Modified AlexNet. Sensors 2023, 23, 7764. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Sun, W.; Li, H.; Hussain, Z.; Liu, A. The method of rolling bearing fault diagnosis based on multi-domain supervised learning of convolution neural network. Energies 2022, 15, 4614. [Google Scholar] [CrossRef]
- Luo, H.; Bo, L.; Peng, C.; Hou, D. An Improved Convolutional-Neural-Network-Based Fault Diagnosis Method for the Rotor–Journal Bearings System. Machines 2022, 10, 503. [Google Scholar] [CrossRef]
- Jiao, J.; Zhao, M.; Lin, J.; Liang, K. A comprehensive review on convolutional neural network in machine fault diagnosis. Neurocomputing 2020, 417, 36–63. [Google Scholar] [CrossRef]
- Liang, B.; Feng, W. Bearing Fault Diagnosis Based on ICEEMDAN Deep Learning Network. Processes 2023, 11, 2440. [Google Scholar] [CrossRef]
- Liu, Y.; Xiang, H.; Jiang, Z.; Xiang, J. A Domain Adaption ResNet Model to Detect Faults in Roller Bearings Using Vibro-Acoustic Data. Sensors 2023, 23, 3068. [Google Scholar] [CrossRef] [PubMed]
- Hao, X.; Zheng, Y.; Lu, L.; Pan, H. Research on intelligent fault diagnosis of rolling bearing based on improved deep residual network. Appl. Sci. 2021, 11, 10889. [Google Scholar] [CrossRef]
- Xu, Z.; Tang, X.; Wang, Z. A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples. Machines 2023, 11, 277. [Google Scholar] [CrossRef]
- Mateo Domingo, C.; Talavera Martín, J.A. Short-time fourier transform with the window size fixed in the frequency domain. Digit. Signal Process. 2018, 77, 13–21. [Google Scholar] [CrossRef]
- Available online: http://csegroups.case.edu/bearingdatacenter/pages/welcome-case-western-reserve university-bearing-data-center-website (accessed on 20 September 2023).
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.; Liu, T.; Li, S.; Zhang, B.; Zhou, G.; Huang, T. Composite fault diagnosis for rolling bearing based on parameter-optimized VMD. Measurement 2022, 201, 111637. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Cao, Y.; Cheng, X.; Zhang, Q. An improved method for fault diagnosis of rolling bearings of power generation equipment in a smart microgrid. Front. Energy Res. 2022, 10, 1006215. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, C.; Liu, P. Application of time-domain index and crag analysis method in rolling bearing fault diagnosis. Mech. Transm. 2016, 40, 172–175. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Wang, J.; Mo, Z.; Zhang, H.; Miao, Q. A deep learning method for bearing fault diagnosis based on time-frequency image. IEEE Access 2019, 7, 42373–42383. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inner Ring Diameter | Outer Ring Diameter | Rolling Diameter | Pitch Diameter |
|---|---|---|---|
| 25 mm | 52 mm | 7.94 mm | 39.04 mm |
| IMF1 | IMF2 | IMF3 | IMF4 | |
|---|---|---|---|---|
| Kurtosis | 2.5034 | 4.0990 | 4.7254 | 4.1869 |
| Envelope entropy | 9.8568 | 9.7111 | 9.6121 | 9.7259 |
| fit | 10.2562 | 9.9551 | 9.8237 | 9.9648 |
| Labels | Bearing Health Status | Fault Type | Damage Volume |
|---|---|---|---|
| 0 | Inner ring fault | Crack Fault | 0.2 mm × 0.2 mm × 0.2 mm |
| 1 | Inner ring fault | Spalling Fault | Calibre: 0.6 mm, Depths: 0.5 mm |
| 2 | Outer ring fault | Crack Fault | 0.2 mm × 0.2 mm × 0.2 mm |
| 3 | Outer ring fault | Spalling Fault | Calibre: 0.6 mm, Depths: 0.5 mm |
| 4 | Rolling body fault | Spalling Fault | Calibre: 0.6 mm, Depths: 0.5 mm |
| 5 | Healthy | None | None |
| Condition Number | Rotational Speed (r/min) | Load Torque (N · m) | Radial Force (N) |
|---|---|---|---|
| I | 1500 r/min | 0.5 N · m | 1000 N |
| II | 900 r/min | 0.5 N · m | 1000 N |
| III | 1500 r/min | 0.1 N · m | 500 N |
| Labels | Data Set A | Data Set B | Data Set C | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Training Set | Validation Set | Test Set | Working Condition | Training Set | Validation Set | Test Set | Working Condition | Training Set | Validation Set | Test Set | Working Condition | |
| 0 | 600 | 75 | 75 | I | 600 | 75 | 75 | II | 600 | 75 | 75 | III |
| 1 | 600 | 75 | 75 | I | 600 | 75 | 75 | II | 600 | 75 | 75 | III |
| 2 | 600 | 75 | 75 | I | 600 | 75 | 75 | II | 600 | 75 | 75 | III |
| 3 | 600 | 75 | 75 | I | 600 | 75 | 75 | II | 600 | 75 | 75 | III |
| 4 | 600 | 75 | 75 | I | 600 | 75 | 75 | II | 600 | 75 | 75 | III |
| 5 | 600 | 75 | 75 | I | 600 | 75 | 75 | II | 600 | 75 | 75 | III |
| Types of Bearing Faults | Optimal IMF Components | |
|---|---|---|
| Inner ring crack | [1675,5] | IMF3 |
| Inner ring spalling | [1907,6] | IMF5 |
| Outer ring crack | [1884,6] | IMF5 |
| Outer ring spalling | [1560,4] | IMF1 |
| Rolling body spalling | [1984,3] | IMF2 |
| Healthy | [1532,3] | IMF2 |
| X1 | X2 | X3 | |
|---|---|---|---|
| Training set | Data Sets A and B | Data Sets A and C | Data Sets B and C |
| Test set | Data Set C | Data Set B | Data Set A |
| Model | X1 | X2 | X3 |
|---|---|---|---|
| ECA-MRANet | 96.75% | 97.14% | 96.98% |
| MRANet | 96.26% | 95.58% | 95.34% |
| RANet | 94.23% | 95.19% | 94.32% |
| CNN | 92.76% | 93.14% | 92.46% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, K.; Gao, B.; Shan, S.; Wang, R.; Wang, X. Research on Rolling Bearing Fault Diagnosis Method Based on ECA-MRANet. Appl. Sci. 2024, 14, 551. https://doi.org/10.3390/app14020551
Wang K, Gao B, Shan S, Wang R, Wang X. Research on Rolling Bearing Fault Diagnosis Method Based on ECA-MRANet. Applied Sciences. 2024; 14(2):551. https://doi.org/10.3390/app14020551
Chicago/Turabian StyleWang, Kai, Bo Gao, Shijie Shan, Rong Wang, and Xueyang Wang. 2024. "Research on Rolling Bearing Fault Diagnosis Method Based on ECA-MRANet" Applied Sciences 14, no. 2: 551. https://doi.org/10.3390/app14020551