1. Introduction
Sunspots, dark regions that appear on the surface of the solar photosphere, are concentrated areas of magnetic fields. They appear as objects with reduced brightness, such as pores without penumbra and sunspots consisting of dark umbra surrounded by lighter penumbra. Some of them are isolated structures and are often found in groups. Hereafter, we will use the term sunspots to denote all objects described above. They cover various sizes over the high-resolution, full-disk, solar continuum images. Sunspots with different scales have been discussed insofar as they correspond to different magnetic field strengths [
1,
2] and have different consequences of interactions between magnetic fields and moving plasma [
3]. It is well known that small sunspots are more common than large ones [
4,
5,
6,
7]. High-resolution observations make it possible to detect multiscale sunspots, especially small sunspots.
Figure 1 shows a high-resolution, full-disk continuum image observed by SDO/HMI on 24 October 2014 at 4:00 UT. It can be seen there are sunspots of multiple scales; some representative sunspots are labeled in boxes from a to f. The regions marked as d, e, and f are very small, so they are magnified six times in dashed boxes.
The projected area of sunspots in millionths of the solar hemisphere (msh) is used to evaluate their size. Corresponding to an image resolution of 4096 × 4096 pixels
, a sunspot occupying 12 pixels has an area of about 1 msh, which corresponds to a circular feature of about 4 pixels in diameter (equivalent diameter) and approximates 0.7 millionths of the image; a sunspot with an area of about 10 msh occupies 116 pixels, corresponding to an equivalent diameter of 12 pixels and 7 millionths of the image, and so on. In
Figure 1, the sunspot group in region c has a very large size with over 8000 msh. Both the sunspot marked in region b and the biggest sunspot marked in region f have similar sizes of about 200 msh. The sunspot marked in region a and the sunspot marked in the bottom-left corner of region f have similar sizes of about 15 msh. The sunspot marked in region d and the sunspot marked on the left side of region f have a similar size of about 5 msh. The sunspot marked in region e has a size of only about 1 msh. This is how multi-scale sunspots appear in a high-resolution full-disk image.
Many automated sunspot detection methods have been proposed in recent years. Traditional image-processing methods for detecting sunspots mainly depend on the intensity of sunspots because sunspots appear to be darker in comparison to their surroundings; these include edge detection [
8], watershed [
9], morphological operations [
9,
10,
11,
12], region growing [
13], level-set [
14,
15], and so on. Whichever method is used, the intensity threshold is essential because almost all of these methods require thresholds to segment sunspots from the background. Some assistive technologies were adopted to set thresholds, such as the statistical Bayesian method [
16], fuzzy-sets [
17], and the simulated annealing genetic method [
18]. Recently, an adaptive method was adopted to process images under various conditions, while processing multiple images taken within a short time to eliminate the seeing effect [
19], and a localized sunspot detection scheme was proposed using the fractional-order derivative mask [
20]. The threshold is very critical for sunspot detection, in which a larger threshold could miss some of the pixels that are part of the sunspots while a smaller threshold could increase noise. Besides that, removing solar limb-darkening and smoothing operations are inevitable during image preprocessing, because the solar atmosphere’s line-on-sight thickness that changes from the disk center to limb leads to limb-darkening in solar full-disk images. These preprocesses are obviously good at extracting larger and darker sunspots; however, tiny, faint sunspots are generally removed by the above operations, especially threshold, smoothing, and morphological operations.
In recent years, some deep learning methods have been used in the field of sunspots, for example, sunspot extraction from Chinese sunspot drawings [
21,
22]. Chola [
23] adopted AlexNet for classifying sun images into an active sun or quiet sun. Ali K. Abed [
24] built a traditional convolutional neural network to detect sunspot groups for predicting solar flares. He [
25] adopted a CornerNet-Saccade deep learning method for classifying sunspot groups based on Mount Wilson classification. Santos [
26] applied the YOLOv5 network to detect sunspots; however, only clearly visible sunspots were detected correctly. The solar images were multiplied down-sampled by these deep learning methods without exception because deep convolution requires a lot of memory. This is not a problem when only sunspots clearly distinguished in active regions are the focus. However, it is unfriendly to smaller sunspots. For instance, a sunspot occupying 256 pixels, 10 millionths of a 4096 × 4096 pixel
image, and an area of about 22 msh corresponds to an equivalent diameter of 18 pixels. If the image is down-sampled to 1024 × 1024 pixels
, it will be reduced to a target occupied by 16 pixels corresponding to an equivalent diameter of 4 pixels. If the image is down-sampled continually to 256 × 256 pixels
, it remains a mere 1 × 1 pixel
, and even disappears. In fact, we hope that such small sunspots can also be detected for the aim of studying solar magnetic fields more comprehensively.
In the field of target detection and segmentation, targets that are about a thousandth of the size can be called small targets. So, the tiny sunspots in these high-resolution solar images, smaller than one in ten thousand or even smaller than one in a million, can be called ultra-small targets. Until now, it has been a major challenge in the field of detection and segmentation of ultra-small targets, whether using the deep learning method or other well-known segmentation methods that use variational techniques, such as the Chan–Vese model [
27], Geodesic active contours [
28], Generalized Fast marching [
29], Segmentation under geometric constraints [
30], deformable models [
31,
32], and so on.
This paper proposes a new deep learning model, SIPNet, in which a new Switchable Atrous Spatial Pyramid Pooling (SASPP) is proposed, and an IoU-aware dense object detector and prototype mask generation are adopted. Furthermore, an open-source framework called Slicing Aided Hyper Inference (SAHI) is integrated on top of the trained SIPNet model. SAHI provides a generic slicing aided inference for small object detection on high-resolution images while maintaining higher memory utilization. The results and comparison show that such an integrated system achieves good performance for multiscale sunspots, especially for small and ultra-small sunspots.
The structure of this paper is as follows. In
Section 2, we introduce the data set.
Section 3 explains SIPNet and (and represents integration) SAHI in detail, including how to train and test SIPNet. The results and discussion are detailed in
Section 4. In
Section 5, the conclusions are presented.
2. Data
The Helioseismic and Magnetic Imager [
33,
34] onboard the Solar Dynamics Observatory [
35] provides high-resolution, full-disk images of the solar white-light continuum intensity in the Fe II absorption line at 6173 Å. The spatial resolution of these images is 1
, with a sampling of 0.5
/pixel. Some corrections such as exposure time, dark current, flat field, and cosmic-ray hits were applied to the level-1 data. About 15,000 continuum intensity images from 2010 May to 2017 December, with a four-hour cadence, were downloaded.
The first step of this work is to build a dataset to train and test the deep learning model for multiscale sunspot detection and segmentation. The dataset was built using about 800 images, which correspond to two types: full-disk solar images and local region images. A total of 600 full-disk solar images in 2014 were selected, and about 200 local region existing sunspots with different scales or different characteristics were cropped from the full-disk images in other years. All images were resized to 860 × 860 pixels
, including multiscale sunspots. About 27,000 sunspots were labeled by Labelme [
36], an open-source image polygon annotation software (
https://github.com/wkentaro/labelme, 1 July 2023), which is used to generate annotation data by annotating the polygon of the samples. The annotation data was converted into a mature labeling format: Microsoft Common Objects in Context [
37]. Finally, the dataset was divided into a training set and a validation set with a ratio of 9:1.
The test set was built from a total of 100 different high-resolution, full-disk solar images of 4096 × 4096 pixels spanning the years 2010 to 2017, which is not an intersection with the training set and the validation set.
3. Method
To extract and segment multiscale sunspots, we built a new deep learning model, SIPNet, which includes a new Switchable Atrous Spatial Pyramid Pooling (SASPP) based on ASPP [
38], an IoU-aware dense object detector proposed in VarifocalNet [
39], and a prototype mask generation by Bolya et al. [
40].
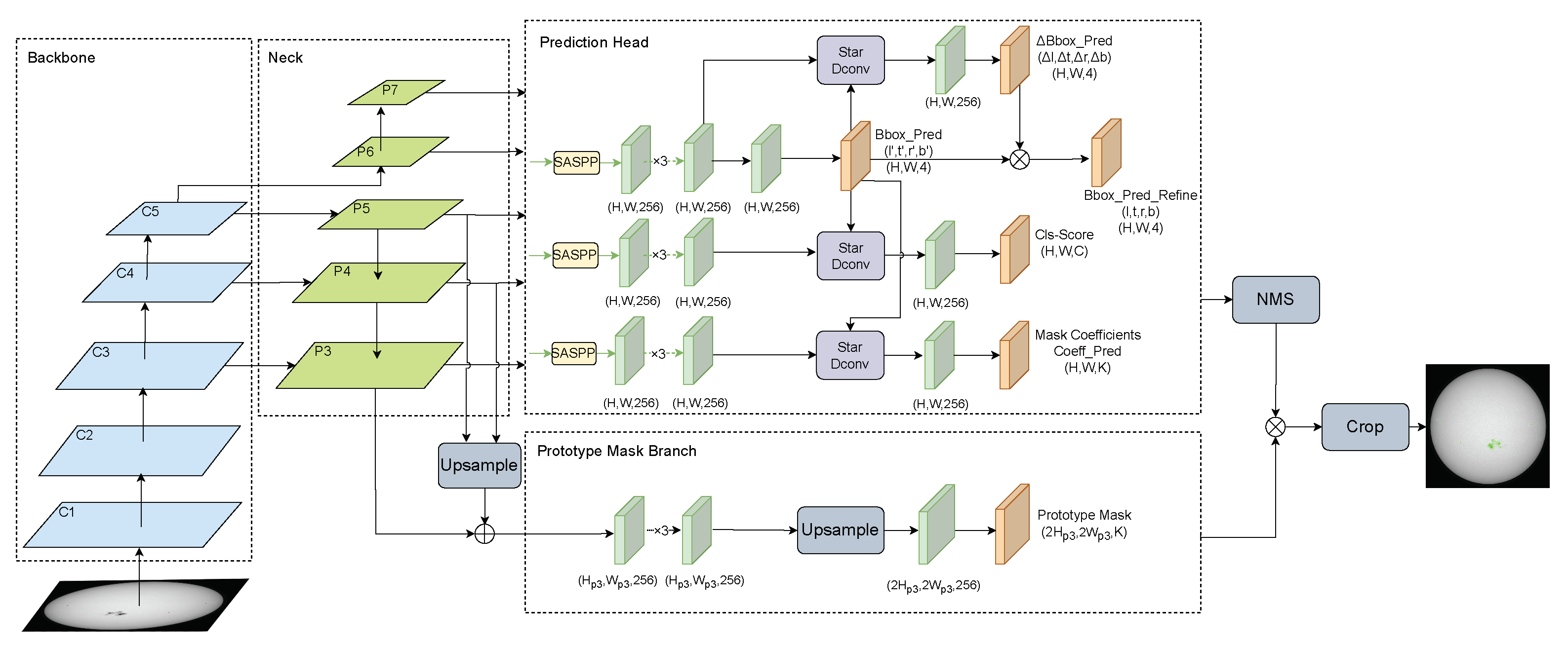
Figure 2 shows the main structure of SIPNet, which includes four modules: the backbone, neck, prediction head, and prototype mask branch. After the model was efficiently trained and tested, we integrated an open-source framework called SAHI [
41] on top of the trained model. SAHI provides generic slicing-assisted inference for small object detection on high-resolution images while maintaining higher memory utilization.
3.1. Backbone and Neck
We adopted an excellent combination, Residual-Network [
42] and Feature Pyramid Network [
43], as the backbone and neck. This combination takes advantage of ResNet’s deep residual connections and FPN’s multiscale feature fusion. It can result in a robust architecture that effectively utilizes both high-level and low-level features, leading to improved performance in object detection and segmentation tasks. The combination is, therefore, well suited to the detection of sunspots, which have large differences in size and characteristics on high-resolution solar images.
The backbone is a network for extracting features from the input images as the first step in a detector model. Some excellent backbones have been proposed in recent years, such as VGG [
44], Hourglass [
45], MobileNet [
46], ResNet, and so on. The shortcut connection of ResNet increases its information flow and alleviates the disappearance of the gradient caused by too great a depth. ResNet has several versions with different layers. Among them, ResNet-50 [
42] has a total of 50 layers, which lowers its complexity, leading to a good balance of accuracy and speed. The construction consists of five stages for extracting five-level feature maps with different sizes and channels, e.g., stages 1 to 5 separately generate the feature maps whose size is from 1/4 to 1/32 of the input image, such as C1 to C5 in
Figure 2. Stage 1 is a normal convolution operator consisting of a 7 × 7 convolution and 7 × 7 max pooling. Other stages consist of the residual blocks, which range in number from 3 to 6. The residual block is the key component of ResNet, which includes three common convolution layers and an identity link that builds from input to output to overcome the degradation problem of deep networks. The final layer of ResNet-50 is a fully connected layer.
The FPN combines the low-level detail information and the high-level semantic information from the different level feature maps outputted from the backbone. This allows each level to gain more contextual information; the low-level layer plays a particularly crucial role in detecting small targets. Due to the large size of C1 and C2, only feature maps from C3 to C5 are selected for fusion by FPN. This step generates objects of different sizes in feature maps at different levels, named P3 to P7. P6 is produced by convolving C5 with a kernel size of 3 × 3 and a step size of 2. P7 follows by convolving P6 with the same kernel size and the same step size. P5 is created by convolving C5 with a kernel size of 3 × 3. P4 is created by merging upsampled P5 with C4 and then P3. As a result of the neck, the fused feature maps from P3 to P7 are fed into the prediction head and the maps from P3 to P5 are fed into the prototype mask branch.
3.2. Prediction Head
The prediction head consists of three branches, one for the bounding box prediction, one for the classification prediction, and one for the mask coefficients prediction. These three branches share the same weights for the outputs of the different levels of the neck.
3.2.1. SASPP
Before the fused feature maps are fed separately to the three branches, we proposed a new module called Switchable Atrous Spatial Pyramid Pooling, or SASPP, based on ASPP [
38]. SASPP improves ASPP’s ability to capture multiscale information and local context by incorporating switchable atrous convolutions and horizontal/vertical mean pooling.
Figure 3a shows the structure of ASPP, which fuses the denser feature maps by applying four parallel atrous convolutions with different atrous rates and global context information by global average pooling operation.
Atrous convolutions [
47] are effective techniques to enlarge the field of view of filters without increasing the number of parameters or the amount of computation, e.g., atrous convolution with atrous rate
r introduces
zeros between successive filter values, equivalently increasing the kernel size of a
k ×
k filter to
. ASPP using atrous convolutions with different atrous rates effectively captures multiscale information. However, the authors also point out that local and long-distance information are likely to be irrelevant.
So, we analyzed ASPP and then improved it.
Figure 3b shows the structure of the improved ASPP, called switchable atrous convolution (SASPP). In SASPP, two switchable atrous convolution (SAC) branches replace three atrous convolutions in ASPP. In addition, the global average pooling sub-branch in ASPP is replaced by two sub-branches, which are horizontal average pooling and vertical average pooling, respectively.
Figure 3c shows the structure of the switchable atrous convolution module (SAC, [
48]). SAC has three main components: two global context modules that are appended before and after the SAC component.
denotes the convolutional operation with weight
w and atrous rate
r, taking
x as input. Then, the description of SAC is as follows:
. Here,
is a hyperparameter of SAC,
is set to 3 ×
,
and
are trainable weights, and the switch function
S is implemented as an average pooling layer with a 5 × 5 kernel followed by a 1 × 1 convolutional layer (see
Figure 3c). A locking mechanism is applied by setting one weight as
and the other as
. After several experiments,
is set to 3 and 6 in two SAC sub-branches, respectively. This means that the atrous rate can be 3, 9, 6, or 18 depending on the function
S.
In addition, there are two identical global context modules before and after the main component of SAC. The input features to the module are first compressed by a global average pooling layer; then convolved with a 1 × 1 kernel; and, finally, the output is added to the input. The front global context module can make the function S more stable in its switching predictions.
Also, the global pooling sub-branch in ASPP was replaced by two sub-branches: horizontal average pooling (X_Avg_Pool) and vertical average pooling (Y_Avg_Pool). This is because global pooling encodes spatial information globally but squeezes global spatial information into a channel descriptor; thus, it is difficult to preserve positional information. Therefore, the global average pooling in ASPP was improved based on the idea of the Coordinate Attention mechanism [
49]. To spatially capture long-range interactions with precise positional information, two spatial extents of the pooling kernels (
H; 1) or (1;
W) encode each channel along the horizontal and vertical coordinates, respectively. The features are aggregated along the two spatial directions, yielding a pair of directional feature maps that correspond to long-range interactions along one spatial direction and preserve precise positional information along the other spatial direction.
The features after horizontal mean pooling and vertical mean pooling are then passed through 1 × 1 convolution, batch normalization, and another 1 × 1 convolution; are separately upsampled; and then dot product as one.
Finally, all resulting features from all branches are concatenated into an output that has effectively captured multiscale information as far as possible. They are fed separately to the next three prediction sub-branches.
3.2.2. Prediction Sub-Branches
There are three sub-branches in this prediction head: one for regressing the localization of the bounding box, one for predicting the IoU-aware classification score based on a star-shaped representation of the bounding box features using star-shaped deformable convolution (Star Dconv), and the other for predicting the mask coefficients.
The localization sub-branch performs bounding box regression and subsequent refinement. It sequentially takes as input the feature maps from P3 to P7 processed by SASPP. First, the input is applied by three 3 × 3 conv layers with ReLU activation, producing a feature map with 256 channels. One localization sub-branch convolves the feature map again and outputs a 4D distance vector per spatial location, representing the initial bounding box. The other sub-branch applies a star-shaped deformable convolution and produces the distance scaling factor (l, t, r,b), which is multiplied by the initial distance vector to produce the refined bounding box .
The star-shaped bounding box feature representation uses the features at nine fixed sampling points to represent a bounding box with a deformable convolution. This representation can capture the geometry of a bounding box and its nearby contextual information, which is essential for encoding the misalignment between the predicted bounding box and the ground truth.
Given a sampling location on the feature map, an initial bounding box from it is encoded by a 4D vector , which is the distance from the location to the left, top, right, and bottom of the bounding box, respectively. With this distance vector, nine sampling points at , , , , , , , , and are mapped onto the feature map. Their relative offsets to the point serve as the offsets for the deformable convolution; then, the features at these nine projected points are convolved by the deformable convolution to represent a bounding box.
The second sub-branch aims to predict the IoU-Aware Classification Score (IACS) [
39], which is a joint representation of object presence confidence and localization accuracy. It is defined as a scalar element of a classification score vector, where the value at the ground truth class label position is the Intersection over Union (IoU) between the predicted bounding box and its ground truth, and is 0 at other positions. The star-shaped bounding box feature representation is used for IACS prediction. It has a similar structure to the localization sub-branch except that it outputs a vector of the class number and elements per spatial location, where each element jointly represents the object presence confidence and localization accuracy.
The third sub-branch has a similar structure to the classification sub-branch in that it aims to predict k mask coefficients on a pixel-by-pixel basis by a small full convolution network (FCN) applied to each predicted bounding box. The k mask coefficients correspond to each prototype encoding the representation of an instance coming from the prototype mask branch (here, k is set to 32).
3.3. Prototype Mask Branch
The prototype mask branch generates a set of k prototype masks for the fused feature maps from the neck. The input is a fused feature map by fusing P3, upsampled P4, and upsampled P5. This is useful for more robust masks, higher quality masks, and better performance on smaller objects. The branch is also an FCN whose last layer has k channels (one for each prototype). It consists of three conv layers, and an upsample that increases in size following a conv layer. The output is finally activated by ReLU for more interpretable prototypes.
Finally, for each instance that survives Non-Maximum Suppression (NMS) (threshold as 0.5) [
50], a mask for that instance is constructed using a matrix multiplication with prototype mask. The operation can be described as follows:
where
represents sigmoid nonlinearity,
P is an
h ×
w ×
k matrix of prototype masks, and
C is an
n ×
k matrix of mask coefficients for
n instances surviving from NMS and score thresholding. The instance masks are then cropped according to the coordinates of the refined bounding box and thresholded.
3.4. Loss Function
The loss function plays a crucial role in continuously adjusting the weights of the parameters in a model to minimize the loss during training. The loss function is defined as a multitask loss:
Here, , , and represent the balance weights for different losses. They are empirically set to 1.5, 2.0, and 6.125, respectively. , , , and correspond to the classification loss, bbox loss, bbox_refine loss, and mask loss, respectively.
The classification loss adopts the varifocal loss [
39]. The varifocal loss is used in training a dense object detector to predict the IACS. The value at the position of the ground truth class label represents the IoU between the predicted bounding box and its ground truth, while other positions have a value of 0. Both the bbox loss and the bbox_refine loss adopt the GIoU loss [
51], which is an optimized IoU loss when there is no overlap between the bounding boxes of the prediction and the ground truth. The mask loss uses the binary cross-entropy (BCE) loss, which is a binary format of the cross-entropy loss.
3.5. SAHI
SIPNet has been designed to improve the performance of object detection and segmentation as much as possible. However, high-resolution solar images with sizes of up to 4096 × 4096 pixels demand more memory. If these original images are fed directly into the network, multiple downsampling operations will result in the object being reduced to a few pixels or even disappearing from higher level feature maps. For example, an object measuring 16 × 16 pixels in a 4096 × 4096 pixels image occupies only about one ten-thousandth of the entire image. When the original image is downsampled to 1024 × 1024 pixels, the size of the object is reduced to about 3 × 3 pixels. Similarly, downsampling to 256 × 256 pixels will cause it to disappear. On the other hand, an image of this size would require a significant amount of GPU memory during forward propagation. It will greatly increase the load on the GPU and increase the risk of GPU memory overflow, even leading to the program’s termination.
To handle the problem of detecting ultra-small objects in high-resolution images while maintaining higher memory utilization, we integrated an open-source generic framework called Slicing Aided Hyper Inference (SAHI) into the trained SIPNet (SIPNet & SAHI for short). The main idea of SAHI is that slicing the input images into overlapping patches results in relatively larger pixel areas for small objects compared to the images fed into the network.
The flow of SAHI during inference is detailed below and can also be seen in
Figure 4. First, the original image
I is sliced into 1 number of
M ×
N overlapping patches
. Then, each patch is resized while preserving the aspect ratio. After that, object detection forward passes by the trained SIPNet are applied to each overlapping patch independently. Meanwhile, an optional full-inference (FI) using the original image can be applied to detect larger objects. Finally, the overlapping prediction results are merged back to original size using NMS. During NMS, boxes with a higher IoU than a predefined matching threshold
(here, set to 0.5) are matched. For each match, detections with a detection probability lower than
(here, set to 0.4) are removed.
3.6. Training and Testing
The main environment for deploying SIPNet & SAHI consists of CUDA 11.1, Ubuntu 16.04, PyTorch 1.10.1, and Python 3.7.13. A GTX2080 GPU was used. We implemented SIPNet using an object detection toolbox, MMDetection 2.0 [
52], which contains a rich set of object detection, instance segmentation, and panoptic segmentation methods, as well as related components and modules based on PyTorch. The data labelling tool uses Labelme 5.0.1. Data augmentation was first performed by SAHI with a slice size of 320 × 320 pixels
and overlap rate of 0.2, and then by random image flipping. Multiscale training was used, where the input images were randomly resized to different scales to improve robustness. A linear warm-up policy [
52] was used, with the initial learning rate set to 0.00125 and the warm-up ratio set to 0.1. The specific settings for other parameters were as follows: momentum set to 0.9, weight decay set to 0.0001, optimizer set to SGD, and batch size set to 4. After repeated experiments, we adopted a 24-epoch training schedule [
52], which took about 13 h.
After training the network, the test dataset was fed into the trained model. The performance was evaluated using precision (P), recall (R), and average precision (AP). The definitions of these metrics are as follows:
Here, TP represents true positives, which is the number of positive class predictions correctly made within the positive samples. FP refers to false positives, which is the number of negative class samples incorrectly labeled as positive. FN, on the other hand, represents false negatives, i.e., the number of positive class samples that were incorrectly predicted as negative. In this work, only predicted targets with an IoU difference greater than 0.5 with the ground truth values are considered correct predictions. AP is the average of all recall values and ranges from 0 to 1. P(r) is the precision–recall curve. SIPNet obtained P, R, and AP values of 76.8%, 71.4%, and 77.0%, respectively.
During inference, the SAHI was integrated into the trained SIPNet. The slice size was set to 400 × 400 pixels and the overlap rate between slices was set to 0.2. A total of 1922 high-resolution solar images in 2013 with a size of 4096 × 4096 pixels were inferred by SIPNet & SAHI. The average time for an image was about 4 min (about 2 min without SAHI). After integrating SAHI into the trained SIPNet, the P, R, and AP values are improved to 95.7%, 90.2%, and 96.1%, respectively.
5. Conclusions
Sunspots are the most prominent features visible on the Sun’s surface, representing clusters of photospheric magnetic fields. They appear as large, medium, or small, and even ultra-small, in high-resolution, solar full-disk images. The different sizes of sunspots correspond to different magnetic field activities.
This study proposes a deep learning method for the extraction and segmentation of multiscale sunspots. Among multiscale sunspots, ultra-small sunspots are those smaller than one ten-thousandth, and even down to one million-thousandth, of high-resolution, solar full-disk images. First, a dataset was built using the continuous images provided by SDO/HMI from May 2010 to December 2017. The training and validation set (9 to 1 ratio) consists of more than 800 images of 860 × 860 pixels, including a total of 600 down-sampled full-disk images selected in 2014 and a total of local sunspot regions at their original resolution in the other years. Approximately 27,000 sunspot samples have been annotated. The test set was built from a total of 100 different high-resolution, full-disk solar images of 4096 × 4096 pixels spanning the years 2010 to 2017, which have no intersection with the training set and the validation set.
Second, a new network named SIPNet was proposed. It adopts some new technologies, including a new module called SASPP based on ASPP—an IoU-aware dense object detector—and a prototype mask generation method. The network consists of four main parts: the backbone, neck, prediction head, and prototype mask branch. The combination of ResNet-50 and FPN is used in the backbone and neck. The prediction head predicts and refines the positions, categories, and mask coefficients of all targets, while the prototype mask branch obtains the prototype mask. Subsequently, the mask of each target is derived from the mask coefficient vector and the prototype mask matrix.
Finally, an open-source framework, SAHI, is integrated on top of the trained SIPNet model.
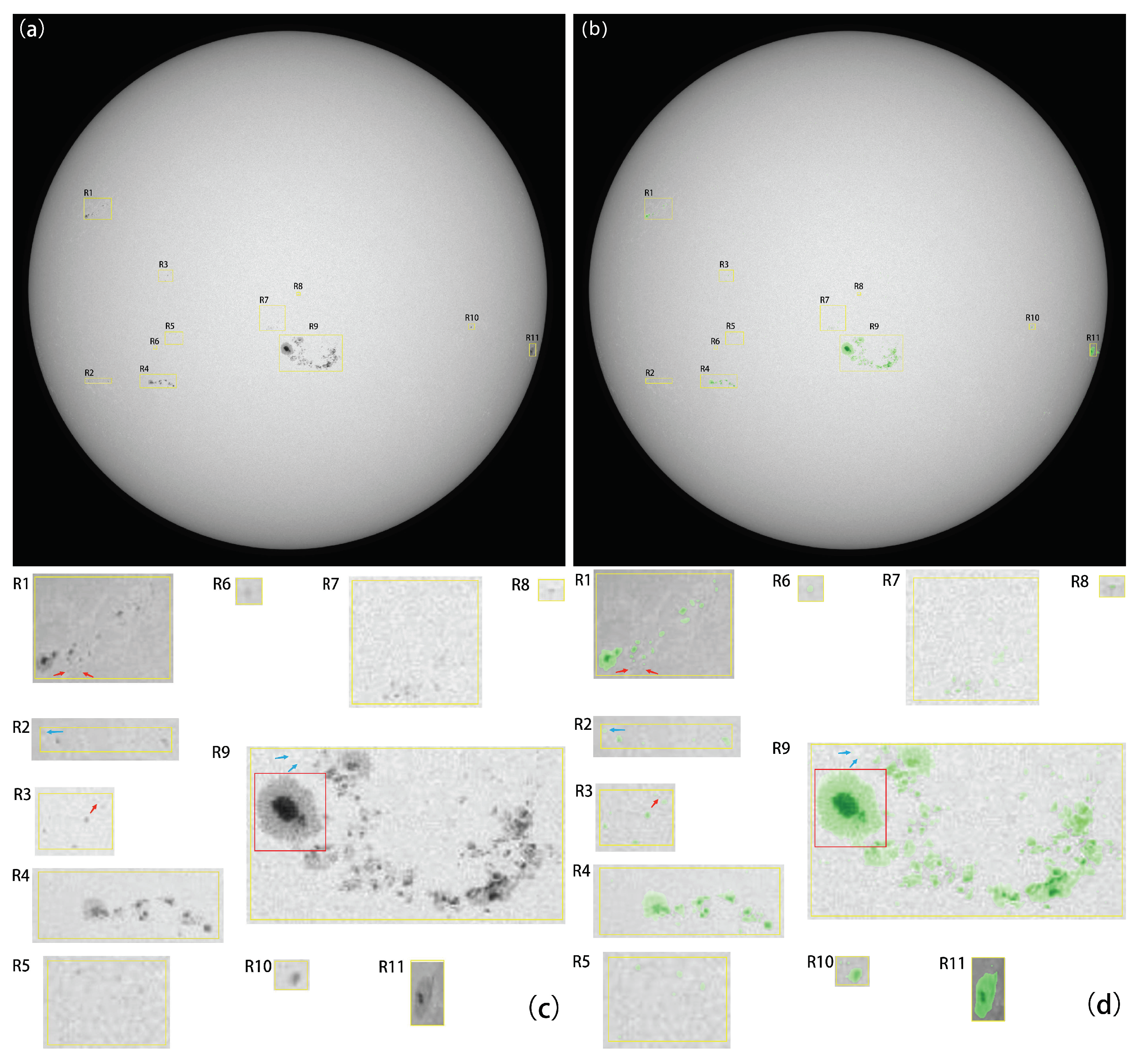
After training and testing, the evaluation metrics show that the SIPNet & SAHI method exhibits excellent performance, with P, R, and AP values of 95.7%, 90.2%, and 96.1%, respectively. Experimental results show that the SIPNet & SAHI method can more accurately segment sunspots of different sizes on high-resolution, solar full-disk images, especially for small and ultra-small sunspots. We have also compared our results with an adaptive thresholding algorithm, SAG. The results also show that the SIPNet & SAHI method effectively detects most of the small and ultra-small sunspots missed by SAG. The ablation experiment shows that SIPNet integrated with SAHI is very helpful for multiscale sunspots, especially for ultra-small sunspots. The method provides a good solution for similar applications in the field of solar physics, such as magnetic fields in the solar magnetogram, the photospheric bright spots located in intergranular lanes, the dots in the umbra, and so on. Other fields facing similar problems can also refer to it.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}