


Finsformer: A Novel Approach to Detecting Financial Attacks Using Transformer and Cluster-Attention
Abstract
:1. Introduction
2. Related Work
2.1. Cluster-Based Attack Detection Methods
2.1.1. K-Means Clustering
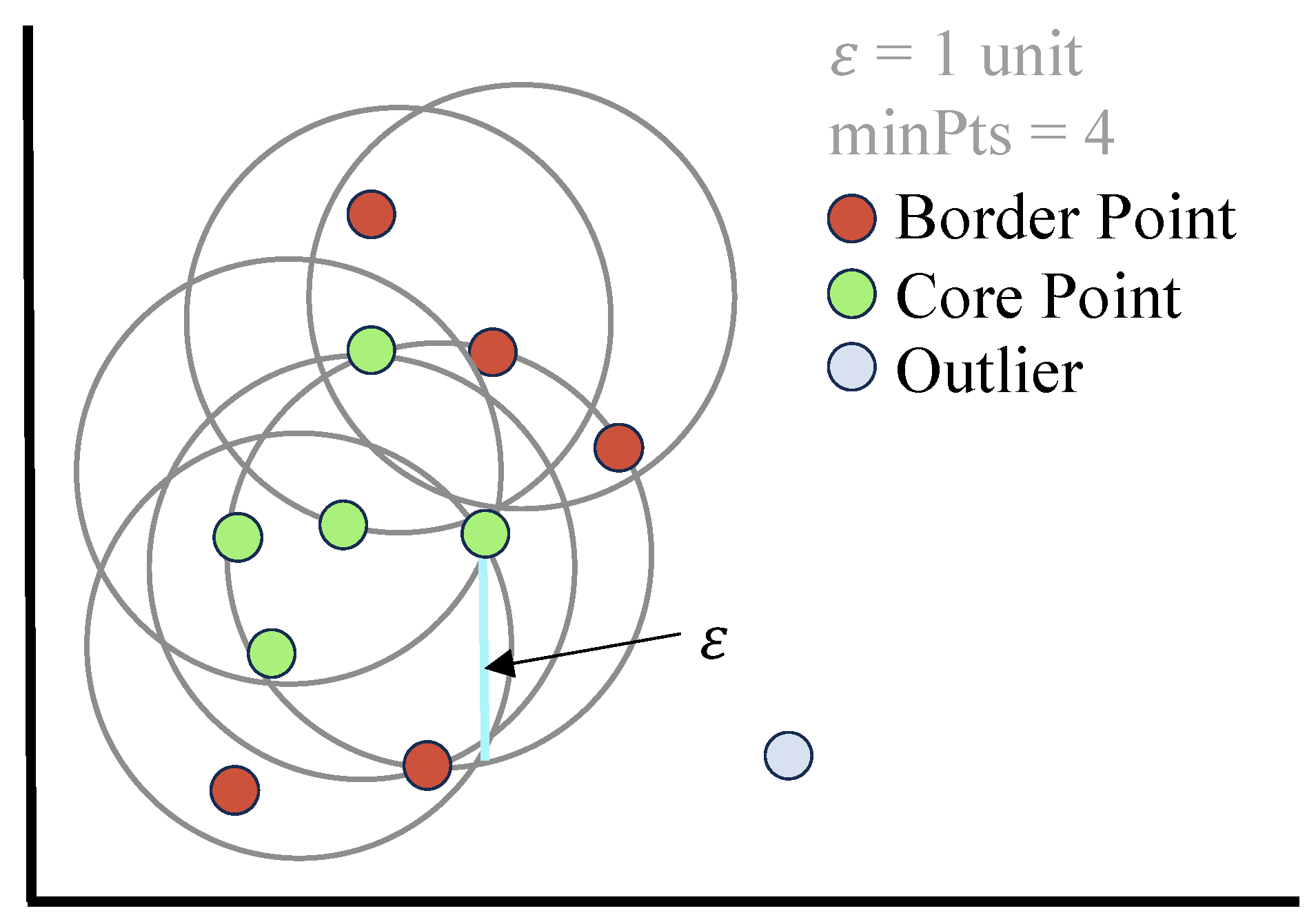
2.1.2. Density-Based Clustering
2.1.3. Hierarchical Clustering
2.2. Attack Detection Methods Based on Deep Learning Models
2.2.1. Recurrent Neural Networks
2.2.2. Autoencoder
3. Materials and Methods
3.1. Dataset Collection
- Public financial transaction records: Data from publicly available sources, such as stock and credit card transactions, typically include information on transaction time, amount, and parties involved. The advantages of public data lie in their transparency and accessibility, contributing to the study’s general applicability and reproducibility.
- Synthetic data: Considering the sensitivity and difficulty in obtaining real financial data, synthetic data serve as an essential supplement. Algorithms are utilized to generate synthetic data with realistic characteristics, such as using Monte Carlo simulations for transaction patterns. This approach aids in simulating complex attack scenarios while preserving privacy.
- Anonymized data from financial institutions: In collaboration with financial institutions, a portion of real financial transaction data were obtained. These data were anonymized before sharing to protect customer privacy. The authenticity and complexity of these data are crucial in enhancing the practicality and accuracy of the model.
3.2. Dataset Annotation
- Annotation criteria: A series of criteria based on transaction characteristics, such as transaction frequency, amount, and historical behavior of the parties involved, were established. For instance, frequent large transactions might be flagged as suspicious attacks.
- Expert review: The annotation process involved the participation of experts in the financial field. They conducted preliminary annotations based on their experience and industry knowledge, especially for complex or ambiguous cases.
- Algorithmic assistance: To enhance efficiency, simple machine learning algorithms were used for pre-annotation, followed by manual expert review. This method combines the efficiency of algorithms with the accuracy of human expert judgment.
- Iterative optimization: The annotation process is iterative. After initial training on pre-annotated data, the model’s predictions are used to guide further manual annotations, forming a feedback loop.
3.3. Proposed Method
3.3.1. Finsformer Overview
- Input processing: The raw financial transaction data undergo preprocessing, including feature extraction, data cleansing, and normalization. The data, in the form of time series, include transaction amounts, timestamps, and account information. To effectively process these data, feature extraction and normalization are first carried out, transforming the raw data into a format that the model can handle.
- Clustering and attention mechanism application: The cluster-attention mechanism is applied to the preprocessed data. Through cluster analysis, the model identifies key patterns in the data and focuses attention on these patterns. Differing from the traditional self-attention mechanism, the cluster-attention mechanism first clusters input data based on similarity, then applies the attention mechanism to these clusters. This approach enables the model to focus more on key patterns in the data, thereby enhancing the accuracy of detecting attack behaviors.
- Feature extraction: After processing with the cluster-attention mechanism, the data are passed to the encoder and decoder layers. These layers further extract and process features, preparing for the final classification task.
- Classification and detection: Finally, the model classifies the transactions based on the extracted features, determining whether each transaction is normal or an attack behavior.
3.3.2. Transformer-Based Attack Behavior Detection Framework
3.3.3. Cluster-Attention Mechanism
- Data clustering: The cluster-attention mechanism initially clusters the input data, aiming to identify potential groups or patterns within it. This approach allows the model to concentrate on transactions with similar features, thereby more effectively identifying anomalous behavior.
- Attention weight calculation: Following the clustering, attention weights are calculated within each cluster. This method results in a more concentrated distribution of attention, helping to highlight significant transaction patterns.
| Algorithm 1 K-means clustering algorithm |
| Input: Data points X, Number of clusters k Output: Cluster centers , Cluster labels for data points Initialize cluster centers randomly from X repeat Assign each point to the nearest cluster center: for each point do end for Update each cluster center to the mean of assigned points: for to k do end for until cluster centers do not change return , Cluster labels for each |
| Algorithm 2 DBSCAN clustering algorithm |
| Input: Data points X, Radius , Minimum points Output: Cluster labels for data points Initialize all points as unvisited for each point do if p is visited then continue to next point end if Mark p as visited if number of points in then Mark p as noise else end if end for function expandCluster() for each point do if q is not visited then Mark q as visited if number of points in then end if end if if q is not yet member of any cluster then Add q to cluster C end if end for function regionQuery() return all points within p’s -neighborhood (including p) |
3.4. Experiment Design
3.4.1. Experiment Configuration
3.4.2. Testbed
3.4.3. Evaluation Index
4. Results and Discussion
4.1. Attack Behavior Detection Results
4.2. Ablation Study on Cluster-Attention Mechanism
4.3. Ablation Study on Transformer Feature Extractor
4.4. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huo, H.; Guo, J.; Yang, X.; Lu, X.; Wu, X.; Li, Z.; Li, M.; Ren, J. An Accelerated Method for Protecting Data Privacy in Financial Scenarios Based on Linear Operation. Appl. Sci. 2023, 13, 1764. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, C.; Sun, Y.; Pang, K.; Jing, L.; Wa, S.; Lv, C. FinChain-BERT: A High-Accuracy Automatic Fraud Detection Model Based on NLP Methods for Financial Scenarios. Information 2023, 14, 499. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, R.; Li, Z.; Li, J.; Ge, Y.; Wa, S.; Huang, S.; Lv, C. Time-Series Neural Network: A High-Accuracy Time-Series Forecasting Method Based on Kernel Filter and Time Attention. Information 2023, 14, 500. [Google Scholar] [CrossRef]
- Diaz-Verdejo, J.; Munoz-Calle, J.; Estepa Alonso, A.; Estepa Alonso, R.; Madinabeitia, G. On the Detection Capabilities of Signature-Based Intrusion Detection Systems in the Context of Web Attacks. Appl. Sci. 2022, 12, 852. [Google Scholar] [CrossRef]
- Saez-de Camara, X.; Luis Flores, J.; Arellano, C.; Urbieta, A.; Zurutuza, U. Clustere d fe derate d learning architecture for network anomaly detection in large scale heterogeneous IoT networks. Comput. Secur. 2023, 131, 103299. [Google Scholar] [CrossRef]
- Abdulganiyu, O.H.; Tchakoucht, T.A.; Saheed, Y.K. A systematic literature review for network intrusion detection system (IDS). Int. J. Inf. Secur. 2023, 22, 1125–1162. [Google Scholar] [CrossRef]
- Yang, W.; Lam, K.Y. Effective Anomaly Detection Model Training with only Unlabeled Data by Weakly Supervised Learning Techniques. In Lecture Notes in Computer Science, PT I, Proceedings of the ICICS 2021: Information and Communications Security, Chongqing, China, 19–21 November 2021; Gao, D., Li, Q., Guan, X., Liao, X., Eds.; Springer: Cham, Switzerland, 2021; Volume 12918, pp. 402–425. [Google Scholar] [CrossRef]
- Yang, S.; Ding, Y.; Xie, B.; Guo, Y.; Bai, X.; Qian, J.; Gao, Y.; Wang, W.; Ren, J. Advancing Financial Forecasts: A Deep Dive into Memory Attention and Long-Distance Loss in Stock Price Predictions. Appl. Sci. 2023, 13, 12160. [Google Scholar] [CrossRef]
- Elsaeidy, A.A.; Jagannath, N.; Sanchis, A.G.; Jamalipour, A.; Munasinghe, K.S. Replay Attack Detection in Smart Cities Using Deep Learning. IEEE Access 2020, 8, 137825–137837. [Google Scholar] [CrossRef]
- Waqar, M.; Fareed, S.; Kim, A.; Malik, S.U.R.; Imran, M.; Yaseen, M.U. Malware Detection in Android IoT Systems Using Deep Learning. CMC—Comput. Mater. Contin. 2023, 74, 4399–4415. [Google Scholar] [CrossRef]
- Sandouka, S.B.; Bazi, Y.; Al Rahhal, M.M. EfficientNet Combined with Generative Adversarial Networks for Presentation Attack Detection. In Proceedings of the 2020 International Conference on Artificial Intelligence & Modern Assistive Technology (ICAIMAT), Riyadh, Saudi Arabia, 24–26 November 2020. [Google Scholar] [CrossRef]
- Alshingiti, Z.; Alaqel, R.; Al-Muhtadi, J.; Haq, Q.E.U.; Saleem, K.; Faheem, M.H. A Deep Learning-Based Phishing Detection System Using CNN, LSTM, and LSTM-CNN. Electronics 2023, 12, 232. [Google Scholar] [CrossRef]
- Ozcan, A.; Catal, C.; Donmez, E.; Senturk, B. A hybrid DNN-LSTM model for detecting phishing URLs. Neural Comput. Appl. 2023, 35, 4957–4973. [Google Scholar] [CrossRef] [PubMed]
- Afzal, S.; Asim, M.; Javed, A.R.; Beg, M.O.; Baker, T. URLdeepDetect: A Deep Learning Approach for Detecting Malicious URLs Using Semantic Vector Models. J. Netw. Syst. Manag. 2021, 29, 21. [Google Scholar] [CrossRef]
- Pastor, A.; Mozo, A.; Vakaruk, S.; Canavese, D.; Lopez, D.R.; Regano, L.; Gomez-Canaval, S.; Lioy, A. Detection of Encrypted Cryptomining Malware Connections With Machine and Deep Learning. IEEE Access 2020, 8, 158036–158055. [Google Scholar] [CrossRef]
- Wang, B.; Yuan, X.; Duan, L.; Ma, H.; Su, C.; Wang, W. DeFiScanner: Spotting DeFi Attacks Exploiting Logic Vulnerabilities on Blockchain. IEEE Trans. Comput. Soc. Syst. 2022. [Google Scholar] [CrossRef]
- Alkhatib, I.K.; Al-Aiad, I.A.; Almahmoud, M.H.; Elayan, O.N. Credit Card Fraud Detection Based on Deep Neural Network Approach. In Proceedings of the 2021 12th International Conference on Information and Communication Systems (ICICS), Valencia, Spain, 24–26 May 2021; pp. 153–156. [Google Scholar] [CrossRef]
- Fursov, I.; Morozov, M.; Kaploukhaya, N.; Kovtun, E.; Rivera-Castro, R.; Gusev, G.; Babaev, D.; Kireev, I.; Zaytsev, A.; Burnaev, E. Adversarial Attacks on Deep Models for Financial Transaction Records. In Proceedings of the KDD ’21: 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021; pp. 2868–2878. [Google Scholar] [CrossRef]
- Qasaimeh, M.; Abu Hammour, R.; Yassein, M.B.; Al-Qassas, R.S.; Torralbo, J.A.L.; Lizcano, D. Advanced security testing using a cyber-attack forecasting model: A case study of financial institutions. J. Softw. Evol. Process 2022, 34, e2489. [Google Scholar] [CrossRef]
- Iftikhar, S.; Asim, M.; Zhang, Z.; Muthanna, A.; Chen, J.; El-Affendi, M.; Sedik, A.; Abd El-Latif, A.A. Target Detection and Recognition for Traffic Congestion in Smart Cities Using Deep Learning-Enabled UAVs: A Review and Analysis. Appl. Sci. 2023, 13, 3995. [Google Scholar] [CrossRef]
- Rizvi, S.; Orr, R.; Cox, A.; Ashokkumar, P.; Rizvi, M.R. Identifying the attack surface for IoT network. Internet Things 2020, 9, 100162. [Google Scholar] [CrossRef]
- Eisenbach, T.M.; Kovner, A.; Lee, M.J. Cyber risk and the US financial system: A pre-mortem analysis. J. Financ. Econ. 2022, 145, 802–826. [Google Scholar] [CrossRef]
- Ismagilova, E.; Hughes, L.; Rana, N.P.; Dwivedi, Y.K. Security, privacy and risks within smart cities: Literature review and development of a smart city interaction framework. Inf. Syst. Front. 2022, 24, 393–414. [Google Scholar] [CrossRef]
- Mohammadpourfard, M.; Khalili, A.; Genc, I.; Konstantinou, C. Cyber-resilient smart cities: Detection of malicious attacks in smart grids. Sustain. Cities Soc. 2021, 75, 103116. [Google Scholar] [CrossRef]
- Zhu, L.; Li, M.; Metawa, N. Financial risk evaluation Z-score model for intelligent IoT-based enterprises. Inf. Process. Manag. 2021, 58, 102692. [Google Scholar] [CrossRef]
- Alkhalil, Z.; Hewage, C.; Nawaf, L.; Khan, I. Phishing attacks: A recent comprehensive study and a new anatomy. Front. Comput. Sci. 2021, 3, 563060. [Google Scholar] [CrossRef]
- Barraclough, P.A.; Fehringer, G.; Woodward, J. Intelligent cyber-phishing detection for online. Comput. Secur. 2021, 104, 102123. [Google Scholar] [CrossRef]
- GILL, M.A.; AHMAD, N.; KHAN, M.; ASGHAR, F.; RASOOL, A. Cyber Attacks Detection Through Machine Learning in Banking. Bull. Bus. Econ. (BBE) 2023, 12, 34–45. [Google Scholar]
- Sagduyu, Y.E.; Shi, Y.; Erpek, T. IoT network security from the perspective of adversarial deep learning. In Proceedings of the 2019 16th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Boston, MA, USA, 10–13 June 2019; pp. 1–9. [Google Scholar]
- Yuan, C.; Yang, H. Research on K-value selection method of K-means clustering algorithm. J 2019, 2, 226–235. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.S. Unsupervised K-means clustering algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Ikotun, A.M.; Ezugwu, A.E.; Abualigah, L.; Abuhaija, B.; Heming, J. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data. Inf. Sci. 2023, 622, 178–210. [Google Scholar] [CrossRef]
- Starczewski, A.; Goetzen, P.; Er, M.J. A new method for automatic determining of the DBSCAN parameters. J. Artif. Intell. Soft Comput. Res. 2020, 10, 209–221. [Google Scholar] [CrossRef]
- Hahsler, M.; Piekenbrock, M.; Doran, D. dbscan: Fast density-based clustering with R. J. Stat. Softw. 2019, 91, 1–30. [Google Scholar] [CrossRef]
- Deng, D. DBSCAN clustering algorithm based on density. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; pp. 949–953. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhao, Y. Design of a corporate financial crisis prediction model based on improved ABC-RNN+ Bi-LSTM algorithm in the context of sustainable development. PeerJ Comput. Sci. 2023, 9, e1287. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Binoy, S.J.; Jos, J. Financial Market Forecasting using Macro-Economic Variables and RNN. In Proceedings of the 2022 2nd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 28–29 April 2022; pp. 1366–1371. [Google Scholar]
- Chen, J.; Zhang, Y.; Wu, J.; Cheng, W.; Zhu, Q. SOC estimation for lithium-ion battery using the LSTM-RNN with extended input and constrained output. Energy 2023, 262, 125375. [Google Scholar] [CrossRef]
- Pirani, M.; Thakkar, P.; Jivrani, P.; Bohara, M.H.; Garg, D. A comparative analysis of ARIMA, GRU, LSTM and BiLSTM on financial time series forecasting. In Proceedings of the 2022 IEEE International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballari, India, 23–24 April 2022; pp. 1–6. [Google Scholar]
- Al Duhayyim, M.; Alsolai, H.; Al-Wesabi, F.N.; Nemri, N.; Mahgoub, H.; Hilal, A.M.; Hamza, M.A.; Rizwanullah, M. Optimized stacked autoencoder for IoT enabled financial crisis prediction model. CMC—Comput. Mater. Contin. 2022, 71, 1079–1094. [Google Scholar]
- Koch, K.R.; Koch, K.R. Bayes’ theorem. In Bayesian Inference with Geodetic Applications; Springer: Berlin/Heidelberg, Germany, 1990; pp. 4–8. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kurani, A.; Doshi, P.; Vakharia, A.; Shah, M. A comprehensive comparative study of artificial neural network (ANN) and support vector machines (SVM) on stock forecasting. Ann. Data Sci. 2023, 10, 183–208. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | Accuracy | F1-Score |
|---|---|---|---|---|
| RNN [38] | 0.83 | 0.81 | 0.82 | 0.82 |
| LSTM [41] | 0.88 | 0.86 | 0.87 | 0.87 |
| Transformer [39] | 0.90 | 0.88 | 0.89 | 0.89 |
| BERT [46] | 0.93 | 0.91 | 0.92 | 0.92 |
| Finsformer | 0.97 | 0.94 | 0.95 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, H.; Ma, R.; Yan, Y.; Chen, T.; Zhao, Y.; Li, P.; Li, J.; Wang, X.; Fan, D.; Lv, C. Finsformer: A Novel Approach to Detecting Financial Attacks Using Transformer and Cluster-Attention. Appl. Sci. 2024, 14, 460. https://doi.org/10.3390/app14010460
An H, Ma R, Yan Y, Chen T, Zhao Y, Li P, Li J, Wang X, Fan D, Lv C. Finsformer: A Novel Approach to Detecting Financial Attacks Using Transformer and Cluster-Attention. Applied Sciences. 2024; 14(1):460. https://doi.org/10.3390/app14010460
Chicago/Turabian StyleAn, Hao, Ruotong Ma, Yuhan Yan, Tailai Chen, Yuchen Zhao, Pan Li, Jifeng Li, Xinyue Wang, Dongchen Fan, and Chunli Lv. 2024. "Finsformer: A Novel Approach to Detecting Financial Attacks Using Transformer and Cluster-Attention" Applied Sciences 14, no. 1: 460. https://doi.org/10.3390/app14010460