
A Dual-Tree–Complex Wavelet Transform-Based Infrared and Visible Image Fusion Technique and Its Application in Tunnel Crack Detection

Abstract
:1. Introduction
2. Image Alignment
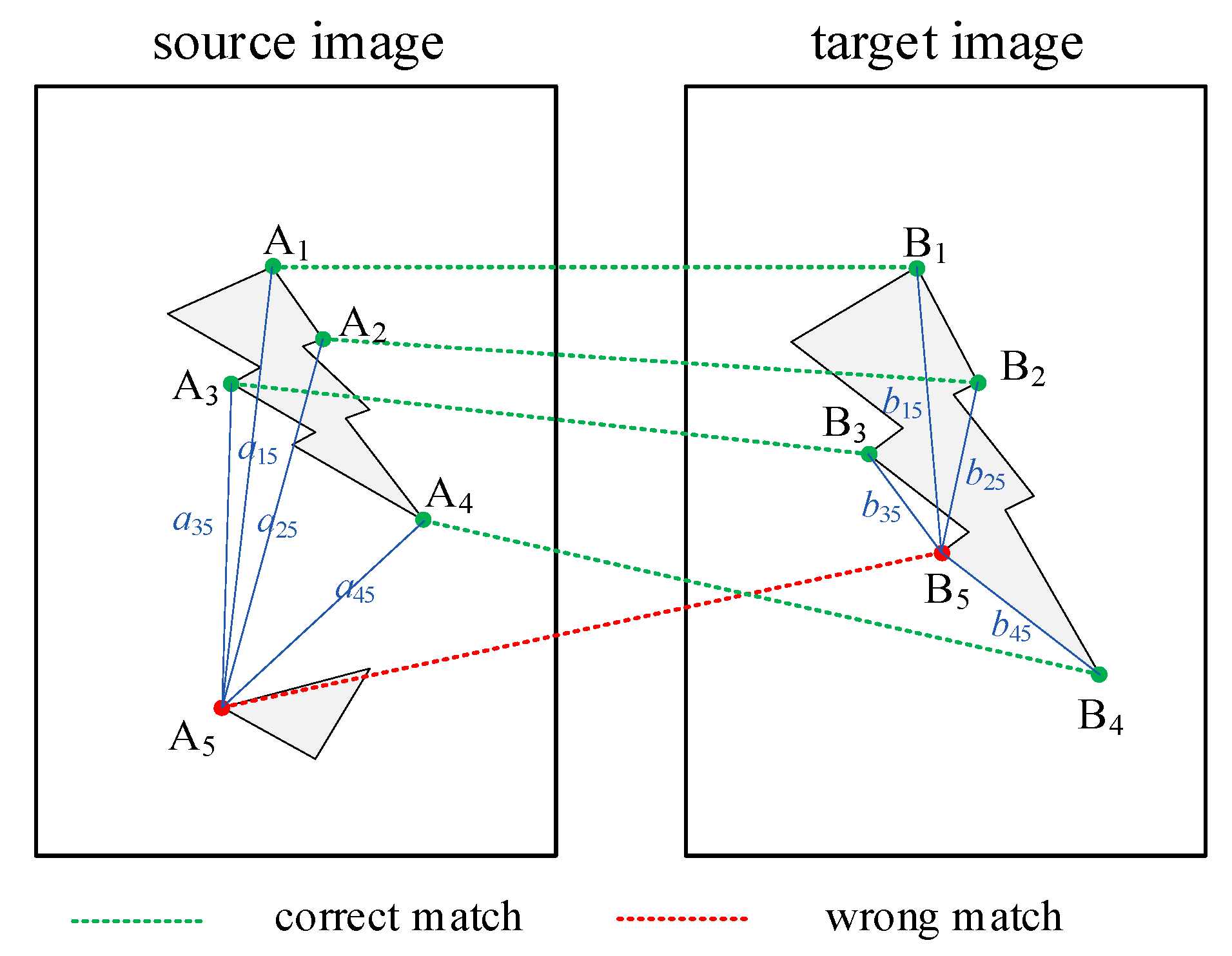
2.1. Matching Feature Points
- (1)
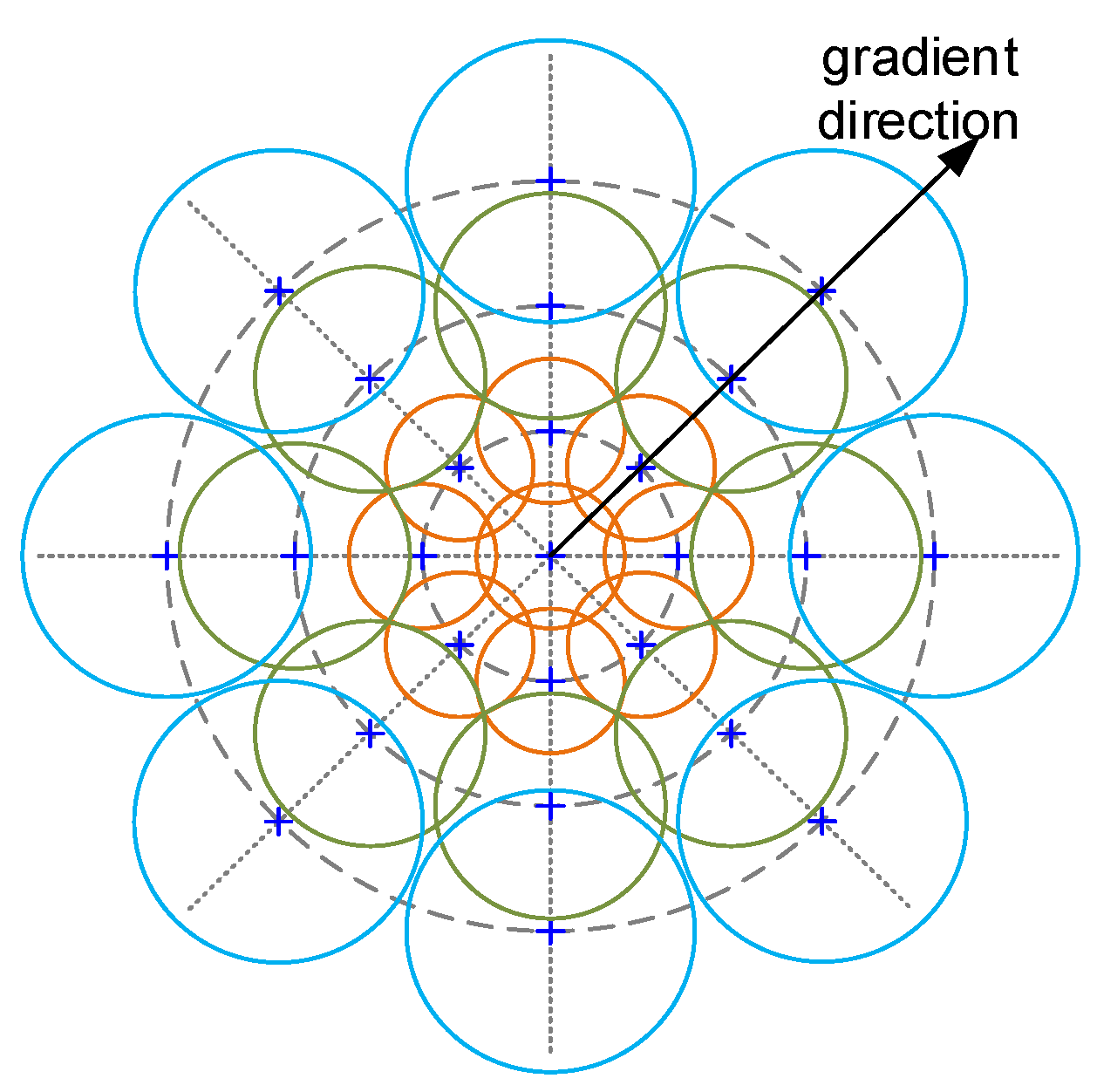
- The gradient of the input image I in direction d is calculated. Only those values with gradients greater than zero are retained in the result. The gradient matrix is denoted as , where the operator (·)+ = max(·, 0). The gradient calculation needs to be decomposed in the x direction and y direction separately. Let the angle between the gradient direction and the positive x direction be θ. The formula for the gradient matrix iswhere the convolutions in the x and y directions are applied using one-dimensional convolution kernels [1, −1] and [1, −1]T, respectively.
- (2)
- We use Gaussian convolution kernels with different scales to perform separate convolution operations on the gradient matrix Gd to form different scaled convolution matrices , which are calculated as follows:where GΣ denotes a Gaussian convolution kernel with Σ standard deviation.
- (3)
- Let denote the feature vector of location (u, v) after convolution by a Gaussian kernel of standard deviation Σ. H denotes the number of gradient directions in the feature vector. Let be the normalized feature vector. The DAISY descriptor D of the feature point location (u, v) is denoted aswhere Q is the number of layers, and T is the number of sampling points in each layer. li(u,v,Rj) denotes the location of the ith sampling point above the jth concentric ring centered at the point (u, v). Rj is the distance between the sampling point and the center point (u, v).
| Algorithm 1. Key point matching |
| Input: The key point set of the source image A = (A1, A2, …, AN), the key point set of the source image B = (B1, B2, …, BN), where A1.x and A1.y are the x-coordinate and y-coordinate of point A1, respectively. |
| Output: classified index set K |
| 1: Initial ind = 0; N = length(A); a = {}; b = {}; c = {};//Initialize arrays a, b and c. |
| 2: for (the = 1 to N) do |
| 3: for (j = 1 to N) do |
| 4: if (the <= j) then |
| 5: break; |
| 6: end if |
| 7: a(ind) = sqrt((Ai.x − Aj.x)2 + (Ai.y − Aj.y)2); |
| 8: b(ind) = sqrt((Bi.x − Bj.x)2 + (Bi.y − Bj.y)2); |
| 9: c(ind, 1) = the; c(ind, 2) = j; //Record the index of the key points |
| 10: ind++; |
| 11: end for |
| 12: end for |
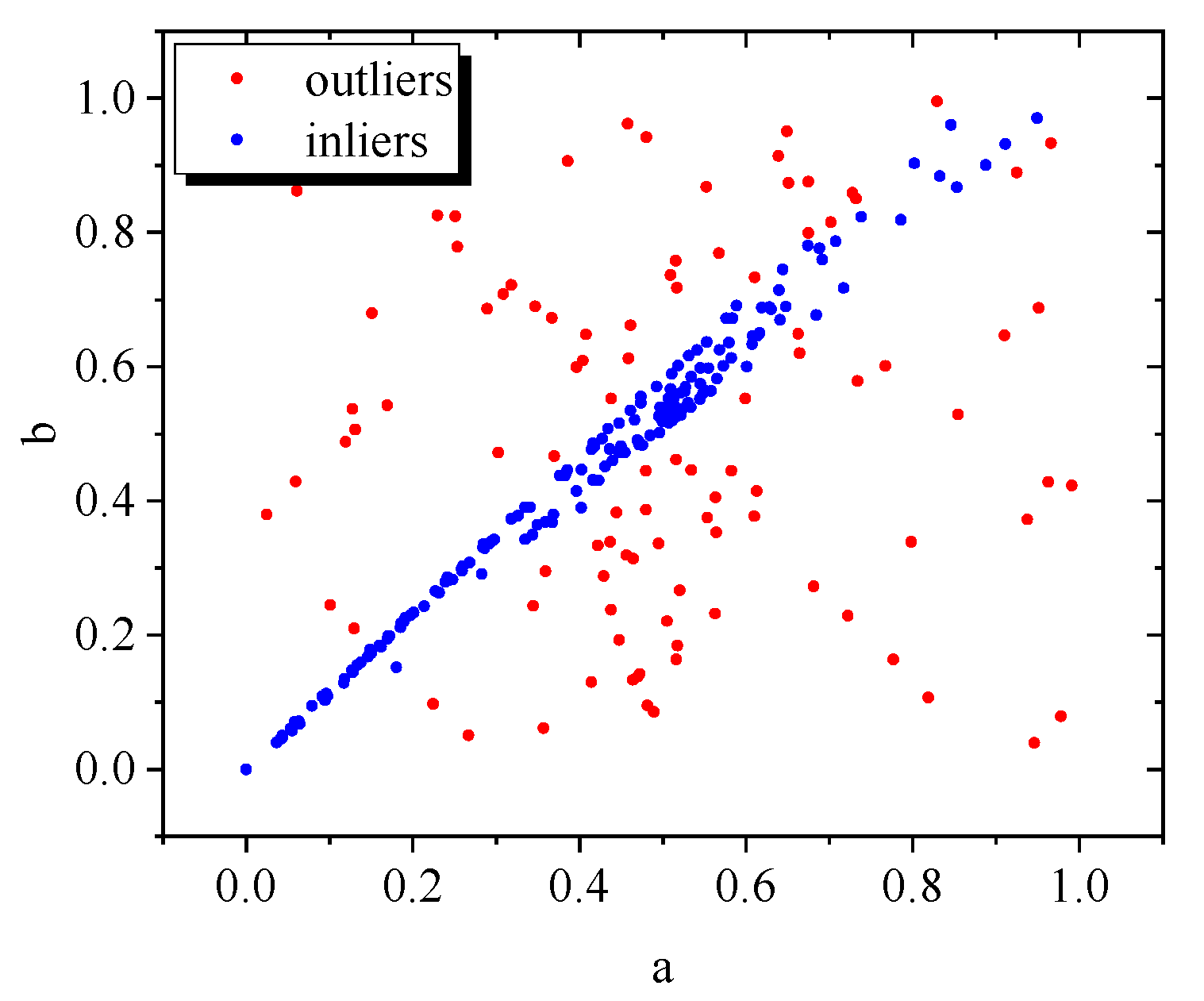
| 13: f = RANSAC(a, b)//Output the set of indices of the outlier f. |
| 14: sk = zeros(N); Nf = length(f); |
| 15: for (the = 1 to Nf) do//Count the indices of all outliers |
| 16: ind = f(i); |
| 17: sk(c(ind, 1))++; sk(c(ind, 2))++; |
| 18: end for |
| 19: for (the = 1 to Nk) do |
| 20: if (sk(i) > N/2) then |
| 21: K.append(i)//Put index the into the array K. |
| 22: end if |
| 23: end for |
| 24: return K; |
2.2. Perspective Transform
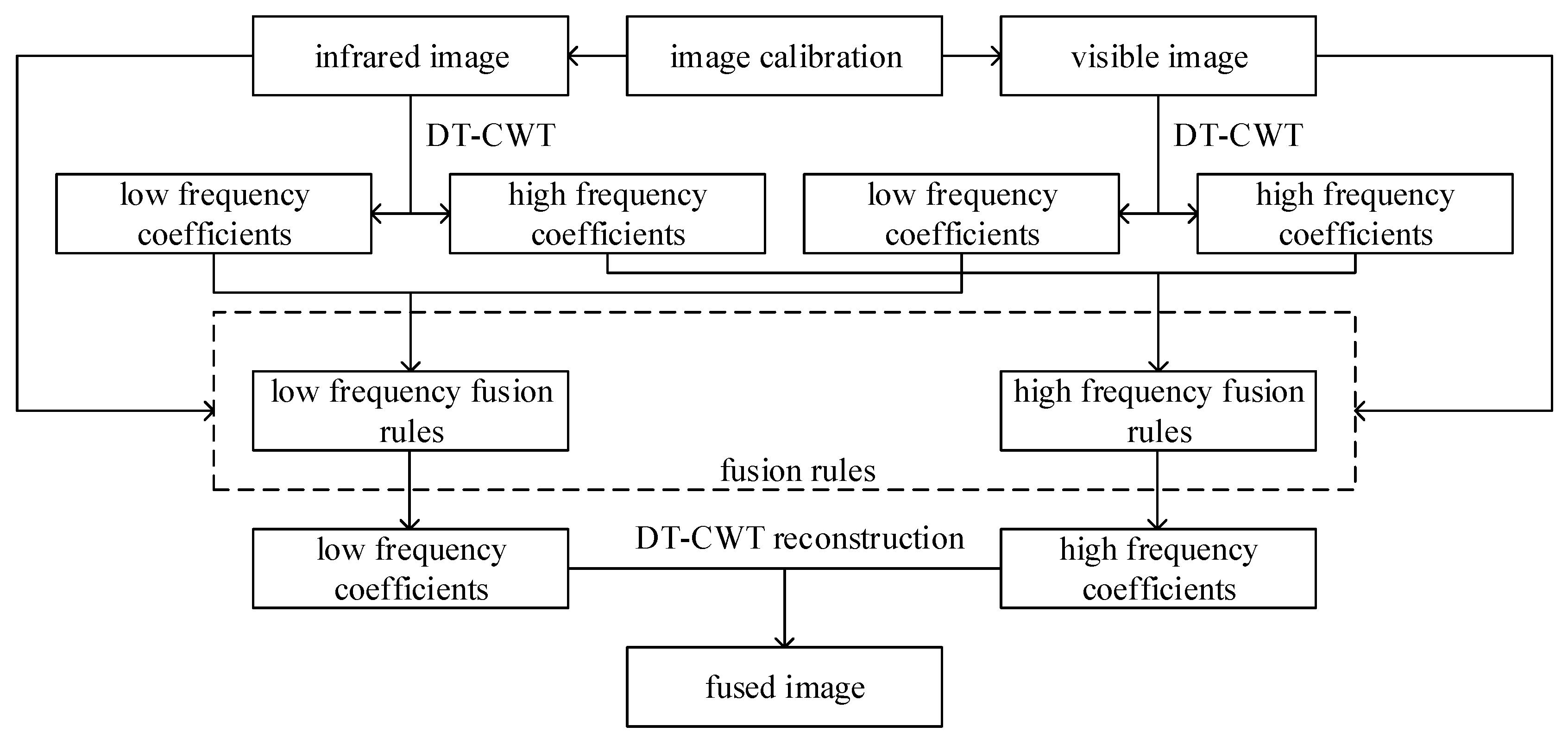
3. Infrared and Visible Image Fusion
3.1. DT-CWT Multiscale Decomposition
3.2. Fusion Rules for Low-Frequency Subbands
3.3. Fusion Rules for High-Frequency Subbands
| Algorithm 2. Image fusion method based on multi-scale decomposition |
| Input: IIR: Luminance matrix for infrared image; IVIS: Luminance matrix for visible image; J: number of decomposition level; |
| Output: IFU: Reconstructed image after fusion processing; |
| 1: [LIR, HIR] = DTCWT(IIR, J); [LVIS, HVIS] = DTCWT(IVIS, J); [w, h] = size(LIR); |
| 2: GIR,x = ∂IIR,x/∂x; GIR,y = ∂IIR,y/∂y; GVIS,x = ∂IVIS,x/∂x; GVIS,y = ∂IVIS,y/∂y;//Calculate the gradient in the x-direction and y-direction. |
| 3: for (j = 1 to J) do |
| 4: for (x = 1 to w) do |
| 5: for (y = 1 to h) do |
| 6: //low-frequency subband fusion |
| 7: μIR(x, y) = average[IIR(x − δ/2, y − δ/2),…, IIR(x + δ/2, y + δ/2)]; |
| 8: μVIS(x, y) = average[IVIS(x − δ/2, y − δ/2),…, IVIS(x + δ/2, y + δ/2)]; |
| 9: σIR(x, y) = variance[IIR(x − δ/2, y − δ/2),…, IIR(x + δ/2, y + δ/2)]; |
| 10: σVIS(x, y) = variance[IIR(x − δ/2, y − δ/2),…, IIR(x + δ/2, y + δ/2)]; |
| 11: SIR(x, y) = IIR(x, y) − μIR(x, y); |
| 12: SVIS(x, y) = IVIS(x, y) − μVIS(x, y); |
| 13: wVIS(x, y) = log(1+|SIR − SVIS|/(2σVIS(x, y)^2)) |
| 14: wIR(x, y) = exp(|SIR − SVIS|/(2σIR(x, y)^2)) |
| 15: if (|SIR(x, y) −SVIS(x, y)| >= SthIR && SIR(x, y) < 0 && SVIS(x, y) < 0) then |
| 16: LF(j)(x, y) = wVIS(x, y)LVIS(x, y) + (1 −wVIS(x, y)) LIR(x, y) |
| 17: else if (|SIR(x, y) −SVIS(x, y)| < SthIR && SIR(x, y) < 0 && SVIS(x, y) < 0) then |
| 18: LF(j)(x, y) = wIR(x, y)LIR(x, y) + (1 − wIR(x, y)) LVIS(x, y); |
| 19: else then |
| 20: LF(j)(x, y) = 0.5(LIR(x, y) + LVIS(x, y)); |
| 21: end if |
| 22: //high-frequency subband fusion |
| 23: Gth,d(x, y) = 0.7max(|GVIS,d(x, y) − GIR,d(x, y)|) |
| 24: if (|GVIS,d(x, y) − GIR,d(x, y)| <= Gth,d && SIR(x, y) < 0 && SVIS(x, y) < 0) then |
| 25: HF,d(j)(x, y) = HVIS,d(j)(x, y); |
| 26: else then |
| 27: HF,d(j)(x, y) = HIR,d(j)(x, y); |
| 28: end if |
| 29: end for |
| 30: end for |
| 31: end for |
| 32: IFU = Idtcwt(LF, HF);//DT-CWT reconstruction |
| 33: return IFU |
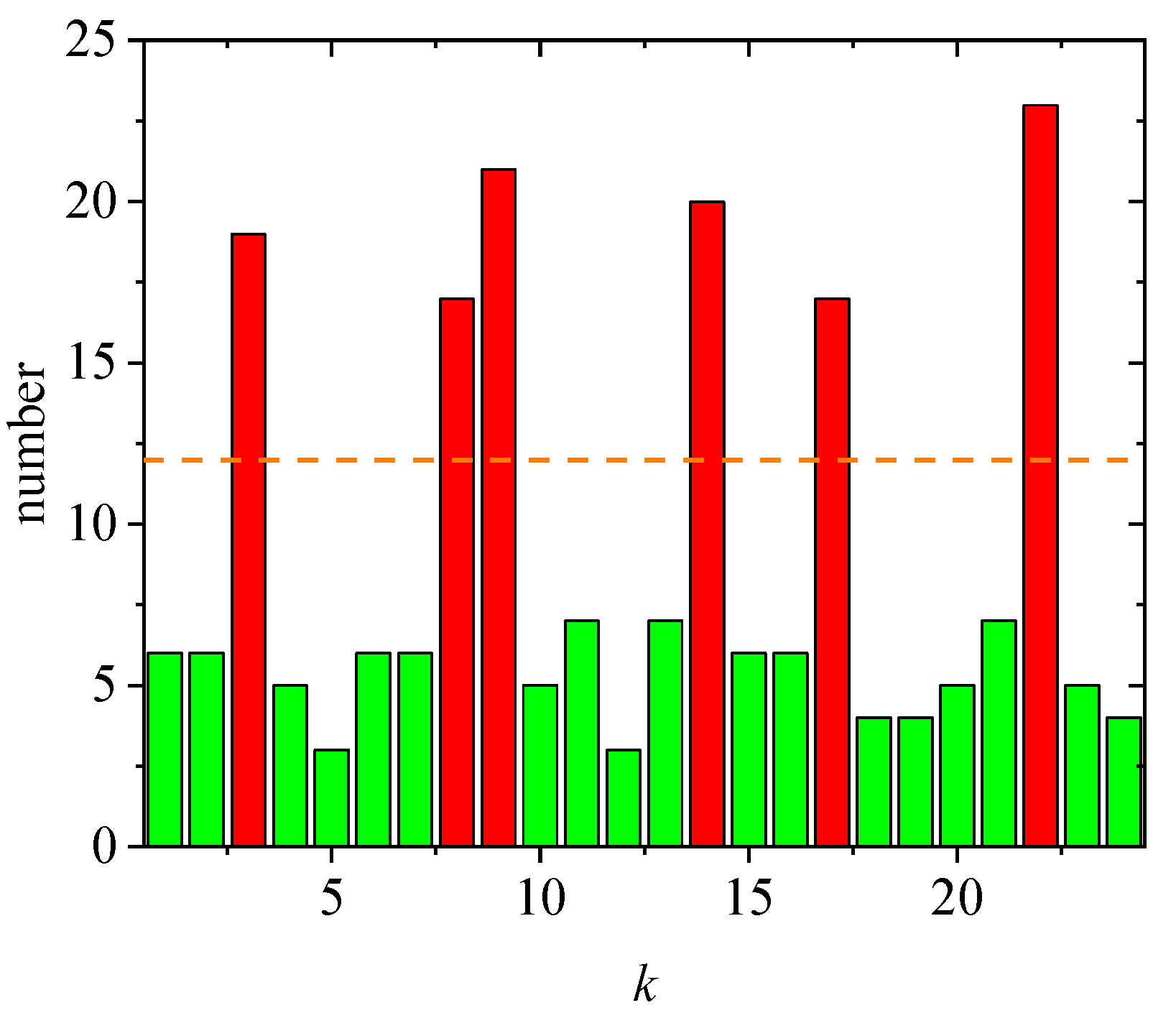
4. Experiment and Evaluation
5. Conclusions
- (1)
- A multiscale fusion method based on DT-CWT is developed, which incorporates separate fusion rules for low-frequency and high-frequency subbands. The fusion rules for low-frequency subbands utilize pixel saliency, while the fusion rules for high-frequency subbands utilize gradient difference. As a result, the fused image retains the high crack resolution observed in visible images while incorporating the background blurring effect from infrared images. This approach effectively enhances the contrast of the crack location.
- (2)
- In scenarios where there is a difference in brightness range and resolution between the infrared and visible images, both the DAISY descriptor and SIFT demonstrate accurate feature point-matching capabilities between the two images. When utilized in conjunction with perspective transformation, these techniques enable successful alignment of the images.
- (3)
- Two semantic segmentation models, ResU-Net and R2U-Net, were used to evaluate the effect of image fusion. By analyzing the results of crack recognition and assessing objective metrics like precision, recall, and specificity, it can be concluded that the image preprocessed using the proposed method shows a decreased false detection rate and missed detection rate compared to methods that utilize the original image and other classical fusion algorithms. This makes it more suitable as a detection sample for semantic segmentation networks.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grosse, C.U. Acoustic emission localization methods for large structures based on beam forming and array techniques. In Proceedings of the NDTCE, Non-Destructive Testing in Civil Engineering, Nantes, France, 30 June–3 July 2009; p. 9. [Google Scholar]
- Kocherla, A.; Duddi, M.; Subramaniam, K.V.L. Embedded PZT sensors for monitoring formation and crack opening in concrete structures. Measurement 2021, 182, 109698. [Google Scholar] [CrossRef]
- Kim, J.-T.; Ryu, Y.-S.; Cho, H.-M.; Stubbs, N. Damage identification in beam-type structures: Frequency-based method vs mode-shape-based method. Eng. Struct. 2003, 25, 57–67. [Google Scholar] [CrossRef]
- Haddar, H.; Riahi, M.K. Near-field linear sampling method for axisymmetric eddy current tomography. Inverse Probl. 2021, 37, 105002. [Google Scholar] [CrossRef]
- Haddar, H.; Jiang, Z.; Riahi, M.K. A Robust Inversion Method for Quantitative 3D Shape Reconstruction from Coaxial Eddy Current Measurements. J. Sci. Comput. 2017, 70, 29–59. [Google Scholar] [CrossRef]
- Cheng, J.; Xiong, W.; Chen, W.; Gu, Y.; Li, Y. Pixel-level Crack Detection using U-Net. In Proceedings of the TENCON 2018 IEEE Region 10 Conference, Jeju, Republic of Korea, 28–31 October 2018; pp. 462–466. [Google Scholar]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Lau, S.L.H.; Chong, E.K.P.; Yang, X.; Wang, X. Automated pavement crack segmentation using u-net-based convolutional neural network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Li, G.; Ma, B.; He, S.; Ren, X.; Liu, Q. Automatic Tunnel Crack Detection Based on U-Net and a Convolutional Neural Network with Alternately Updated Clique. Sensors 2020, 20, 717. [Google Scholar] [CrossRef]
- James, A.P.; Dasarathy, B.V. Medical image fusion: A survey of the state of the art. Inf. Fusion 2014, 19, 4–19. [Google Scholar] [CrossRef]
- Simone, G.; Farina, A.; Morabito, F.; Serpico, S.; Bruzzone, L. Image fusion techniques for remote sensing applications. Inf. Fusion 2002, 3, 3–15. [Google Scholar] [CrossRef]
- Singh, R.; Vatsa, M.; Noore, A. Integrated multilevel image fusion and match score fusion of visible and infrared face images for robust face recognition. Pattern Recognit. 2008, 41, 880–893. [Google Scholar] [CrossRef]
- Yu, D.; He, Z. Digital twin-driven intelligence disaster prevention and mitigation for infrastructure: Advances, challenges, and opportunities. Nat. Hazards 2022, 112, 1–36. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Ma, Y.; Fan, F.; Zhang, Y.; Huang, J. Infrared and visible image fusion via saliency analysis and local edge-preserving multi-scale decomposition. J. Opt. Soc. Am. A 2017, 34, 1400–1410. [Google Scholar] [CrossRef] [PubMed]
- Han, L.; Shi, L.; Yang, Y.; Song, D. Thermal Physical Property-Based Fusion of Geostationary Meteorological Satellite Visible and Infrared Channel Images. Sensors 2014, 14, 10187–10202. [Google Scholar] [CrossRef]
- Bulanon, D.; Burks, T.; Alchanatis, V. Image fusion of visible and thermal images for fruit detection. Biosyst. Eng. 2009, 103, 12–22. [Google Scholar] [CrossRef]
- Fu, Z.; Wang, X.; Xu, J.; Zhou, N.; Zhao, Y. Infrared and visible images fusion based on RPCA and NSCT. Infrared Phys. Technol. 2016, 77, 114–123. [Google Scholar] [CrossRef]
- Gao, H.; Wang, X.; Zhang, W. Infrared and visible image fusion based on non-subsampled contourlet transform. In Proceedings of the ICMLCA 2021; 2nd International Conference on Machine Learning and Computer Application, Shenyang, China, 17–19 December 2021; pp. 1–5. [Google Scholar]
- Adu, J.; Gan, J.; Wang, Y.; Huang, J. Image fusion based on nonsubsampled contourlet transform for infrared and visible light image. Infrared Phys. Technol. 2013, 61, 94–100. [Google Scholar] [CrossRef]
- Zhang, B.; Lu, X.; Pei, H.; Zhao, Y. A fusion algorithm for infrared and visible images based on saliency analysis and non-subsampled Shearlet transform. Infrared Phys. Technol. 2015, 73, 286–297. [Google Scholar] [CrossRef]
- Madheswari, K.; Venkateswaran, N. Swarm intelligence based optimisation in thermal image fusion using dual tree discrete wavelet transform. Quant. Infrared Thermogr. J. 2017, 14, 24–43. [Google Scholar] [CrossRef]
- Saeedi, J.; Faez, K. Infrared and visible image fusion using fuzzy logic and population-based optimization. Appl. Soft Comput. 2012, 12, 1041–1054. [Google Scholar] [CrossRef]
- Wang, X.; Hua, Z.; Li, J. Cross-UNet: Dual-branch infrared and visible image fusion framework based on cross-convolution and attention mechanism. Vis. Comput. 2022, 39, 4801–4818. [Google Scholar] [CrossRef]
- Liang, H.; Qiu, D.; Ding, K.-L.; Zhang, Y.; Wang, Y.; Wang, X.; Liu, T.; Wan, S. Automatic pavement crack detection in multi-source fusion images using similarity and difference features. IEEE Sens. J. 2023. [Google Scholar] [CrossRef]
- Su, T.-C. Assessment of cracking widths in a concrete wall based on tir radiances of cracking. Sensors 2020, 20, 4980. [Google Scholar] [CrossRef]
- Pozzer, S.; De Souza, M.P.V.; Hena, B.; Hesam, S.; Rezayiye, R.K.; Azar, E.R.; Lopez, F.; Maldague, X. Effect of different imaging modalities on the performance of a CNN: An experimental study on damage segmentation in infrared, visible, and fused images of concrete structures. NDT E Int. 2022, 132, 102709. [Google Scholar] [CrossRef]
- Attard, L.; Debono, C.J.; Valentino, G.; Di Castro, M. Tunnel inspection using photogrammetric techniques and image processing: A review. ISPRS J. Photogramm. Remote Sens. 2018, 144, 180–188. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the Computer Vision—ECCV 2006 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Tola, E.; Lepetit, V.; Fua, P. DAISY: An efficient dense descriptor applied to wide-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 815–830. [Google Scholar] [CrossRef]
- Brown, M.; Hua, G.; Winder, S. Discriminative learning of local image descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 43–57. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted res-unet for high-quality retina vessel segmentation. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 327–331. [Google Scholar]
- Alom, M.Z.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Nuclei segmentation with recurrent residual convolutional neural networks based U-Net (R2U-Net). In Proceedings of the NAECON 2018-IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 23–26 July 2018; pp. 228–233. [Google Scholar] [CrossRef]
- Toet, A. Image fusion by a ratio of low-pass pyramid. Pattern Recognit. Lett. 1989, 9, 245–253. [Google Scholar] [CrossRef]
- Nercessian, S.; Panetta, K.; Agaian, S. Image fusion using the parameterized logarithmic dual tree complex wavelet transform. In Proceedings of the 2010 IEEE International Conference on Technologies for Homeland Security (HST), Waltham, MA, USA, 8–10 November 2010; pp. 296–302. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Pre | Re | Spe | |||
|---|---|---|---|---|---|---|
| ResU-Net | R2U-Net | ResU-Net | R2U-Net | ResU-Net | R2U-Net | |
| Infrared image | 0.1991 | 0.2482 | 0.8300 | 0.9910 | 0.9778 | 0.9811 |
| Visible image | 0.2224 | 0.2877 | 0.9615 | 0.9676 | 0.9772 | 0.9841 |
| Algorithm A | 0.2817 | 0.2924 | 0.9965 | 0.9988 | 0.9831 | 0.9839 |
| Algorithm B | 0.1963 | 0.2174 | 0.9867 | 0.9818 | 0.9732 | 0.9770 |
| Proposed method | 0.5178 | 0.5884 | 0.9682 | 0.9647 | 0.9940 | 0.9955 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Chen, T. A Dual-Tree–Complex Wavelet Transform-Based Infrared and Visible Image Fusion Technique and Its Application in Tunnel Crack Detection. Appl. Sci. 2024, 14, 114. https://doi.org/10.3390/app14010114
Wang F, Chen T. A Dual-Tree–Complex Wavelet Transform-Based Infrared and Visible Image Fusion Technique and Its Application in Tunnel Crack Detection. Applied Sciences. 2024; 14(1):114. https://doi.org/10.3390/app14010114
Chicago/Turabian StyleWang, Feng, and Tielin Chen. 2024. "A Dual-Tree–Complex Wavelet Transform-Based Infrared and Visible Image Fusion Technique and Its Application in Tunnel Crack Detection" Applied Sciences 14, no. 1: 114. https://doi.org/10.3390/app14010114