
Trust-Aware Evidence Reasoning and Spatiotemporal Feature Aggregation for Explainable Fake News Detection

Abstract
:1. Introduction
- We developed a transparent and highly interpretable neural structure reasoning model that incorporates a random walk model and capsule network structure into the processes of evidence reasoning and aggregation, respectively, which not only provides reliable evidence for fake news detection, but also enhances the transparency of the model reasoning process;
- Our evidence representation module can capture the semantic interactions between posts in a fine-grained manner based on the spatiotemporal structure of message propagation to enrich the semantic representation of posts (source information or comments);
- The designed evidence aggregation module automatically captures the false portions of source information while aggregating the implicit bias of the evidence in source information;
- Extensive experiments on public datasets illustrate that TRSA achieves more a promising performance than previous state-of-the-art approaches, as well as providing interpretations for fake news detection results.
2. Related Work
3. Problem Statement
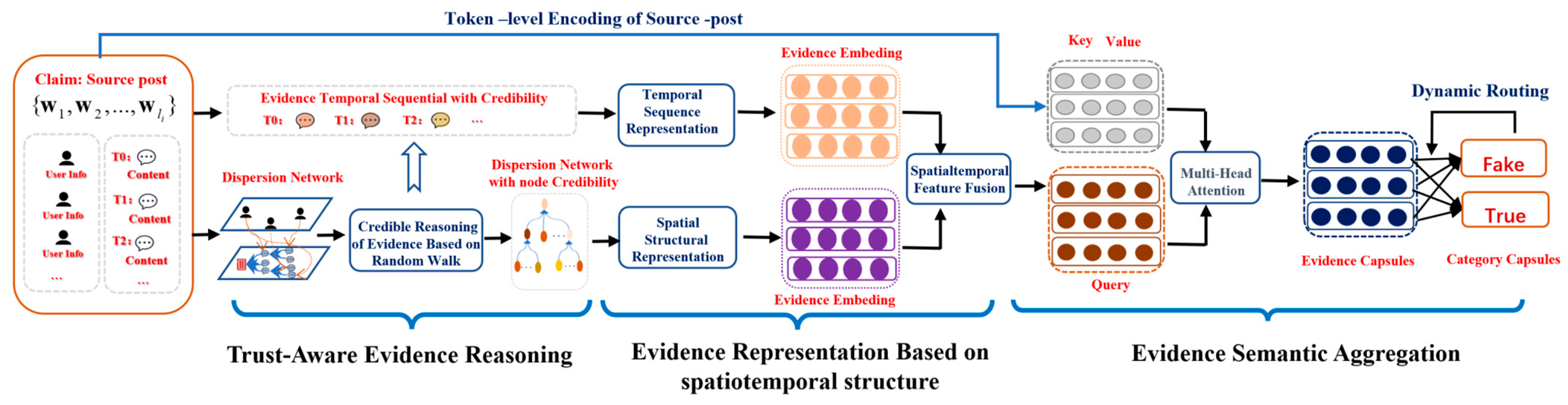
4. TRSA: Trust-Aware Evidence Reasoning and Spatiotemporal Feature Aggregation Model
4.1. Trust-Aware Evidence Reasoning
- (1)
- Authority of users who publish comments: the higher the authority of users, the more reliable their comments [40]. In other words, users tend to receive information published by users with high authority;
- (2)
- Degree of recognition of other comments in the information propagation process: comments recognized by other highly credible comments have high credibility.
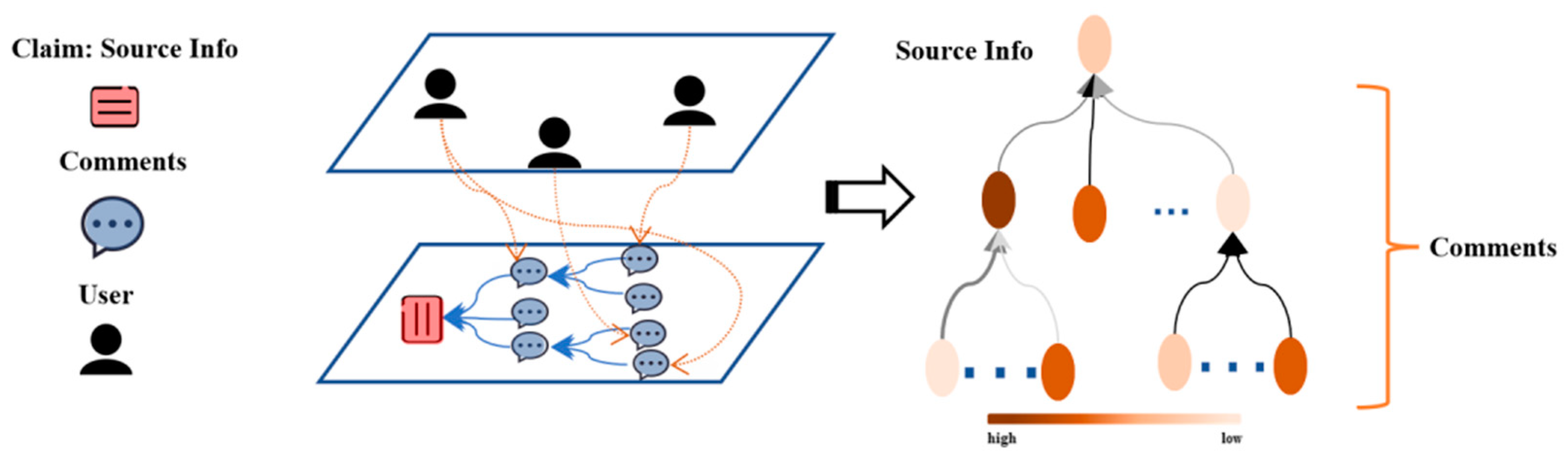
4.1.1. Information Dispersion Network Construction
4.1.2. Credible Reasoning of Evidence Based on a Random Walk
4.2. Evidence Representation Based on Spatiotemporal Structure
4.2.1. Evidence Temporal Sequence Representation Unit
4.2.2. Evidence Spatial Structure Representation Unit
4.2.3. Spatiotemporal Feature Fusion Unit
4.3. Semantic Aggregation of Evidence Based on a Capsule Network
4.3.1. Semantic Interactions between Evidence and Source Information Based on Multi-Head Attention
4.3.2. Evidence Aggregation Based on a Dynamic Routing Mechanism
| Algorithm 1 Dynamic Routing Mechanism |
| Input: Output: 1: Init the coupling parameter 2: for each iteration do 3: Update 4: Update all the class capsules based on Equation (15) 5: Update 6: end for 7: return |
4.3.3. Detection
5. Experiments and Discussion
- EI1: Can TRSA achieve better performance than the state-of-the-art models?
- EI2: How effective is each component of TRSA in improving detection performance?
- EI3: Can TRSA make detection results easy to understand using the evidence reasoning and evidence aggregation modules?
- EI4: What is the performance of the model for the early detection of fake news?
5.1. Experimental Datasets and Settings
5.1.1. Datasets
5.1.2. Comparison Methods
- DTC [8]: This method utilizes multi-dimensional statistical features from the four perspectives of text content, user characteristics, forwarding behavior, and communication mode, and implements decision trees to determine the truthfulness of information;
- HSA-BLSTM [49]: HSA-BLSTM is a hierarchical neural network model used to describe the semantic features of different levels of rumor events (a rumor event is composed of source information and multiple forwarded or commented posts, and each post is composed of words);
- SVM-TS [50]: This method utilizes SVMs with linear kernel function to model temporal features for false information;
- DTCA [21]: This model considers user comments as an evidence source for the truthfulness judgment of a claim and uses a co-attention network to enhance the semantic interactions between evidence and source information;
- BERT-Emo [35]: BERT-Emo uses a pretrained language model to obtain the text semantic representation and the emotions difference between an information publisher and their audience;
- GLAN [22]: GLAN is a novel neural network model that can corporately model local semantic features and global propagating features;
- BiGCN [23]: BiGCN is a two-layer graph convolutional network model used to capture the bidirectional propagating structure of information. It also integrates source post information into each layer of the GCN to enhance the impact of source information;
- DDGCN [31]: DDGCN is a dynamic graph convolution neural network model used to capture the characteristics of the information propagation structure and knowledge entity structure at each point in time. Since our model only concentrates on the contents and social contexts, we do not introduce a dynamic knowledge structure.
5.1.3. Experimental Setup
5.2. Performance Comparison
- The deep neural network models are superior to the models based on feature engineering (DTC, SVM-TS). The most fundamental reason is that deep neural network models can automatically learn implicit high-level semantic representations, whereas traditional machine learning methods that rely on feature engineering can only capture obvious false information in the presentation layer, which leads to various limitations;
- The models that add semantic interactions between claims and comments (DTCA, BERT-Emo) perform better than the models that work with text and hierarchical time-series structure (HSA\_BLSTM). DTCA automatically captures controversial portions of source information through a co-attention mechanism. The BERT-Emo model constructs a dual emotional feature set by measuring the difference between the emotions of an information publisher and their audience to improve false information detection performance;
- The models based on information propagation structure are superior to the models based on text semantics (DTCA, BERT-Emo, HAS-BLSTM). For example, GLAN, BiGCN, and DDGCN achieved improvements of approximately 0.5% to 3.2% in terms of accuracy on the two datasets compared to DTCA. This indicates that mining the hidden structural features of information propagation is very helpful for improving detection performance. However, in terms of precision, because DTCA uses decision trees to filter out some low-credibility noise comments, its performance was approximately 1.5% higher than that of the aforementioned models on PHEME. Moreover, it can be observed that DDGCN showed better performance than BiGCN and GLAN, indicating that spatiotemporal structure features can finely depict the semantic interaction in message propagation and thus improve performance;
- The proposed model outperformed most post-based models and propagation-based models in terms of most indicators on the two real datasets. Compared to DTCA, the proposed model enriched the claim and comment semantic information from the perspective of time and space propagation structures. Its performance was 5.7%, 3.2%, 7.15%, and 5.3% higher than that of DTCA in terms of accuracy, precision, recall, and F1, respectively. Compared to DDGCN, these four indicators were 3%, 4%, 2.65%, and 3.5% higher on average. This is because DDGCN treated all comments equally, which introduces noise. In contrast, our model reduced noise by calculating the credibility of comments.
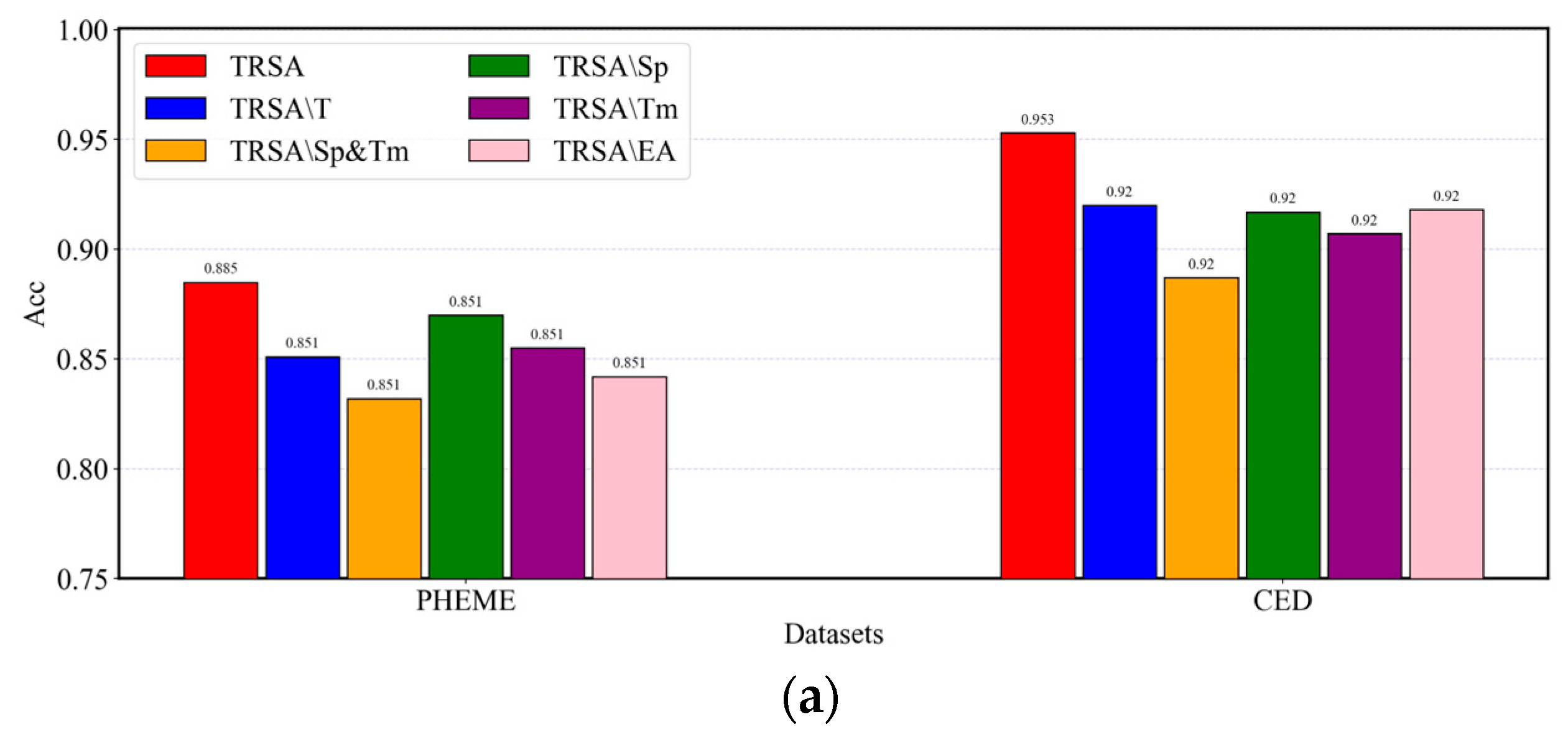
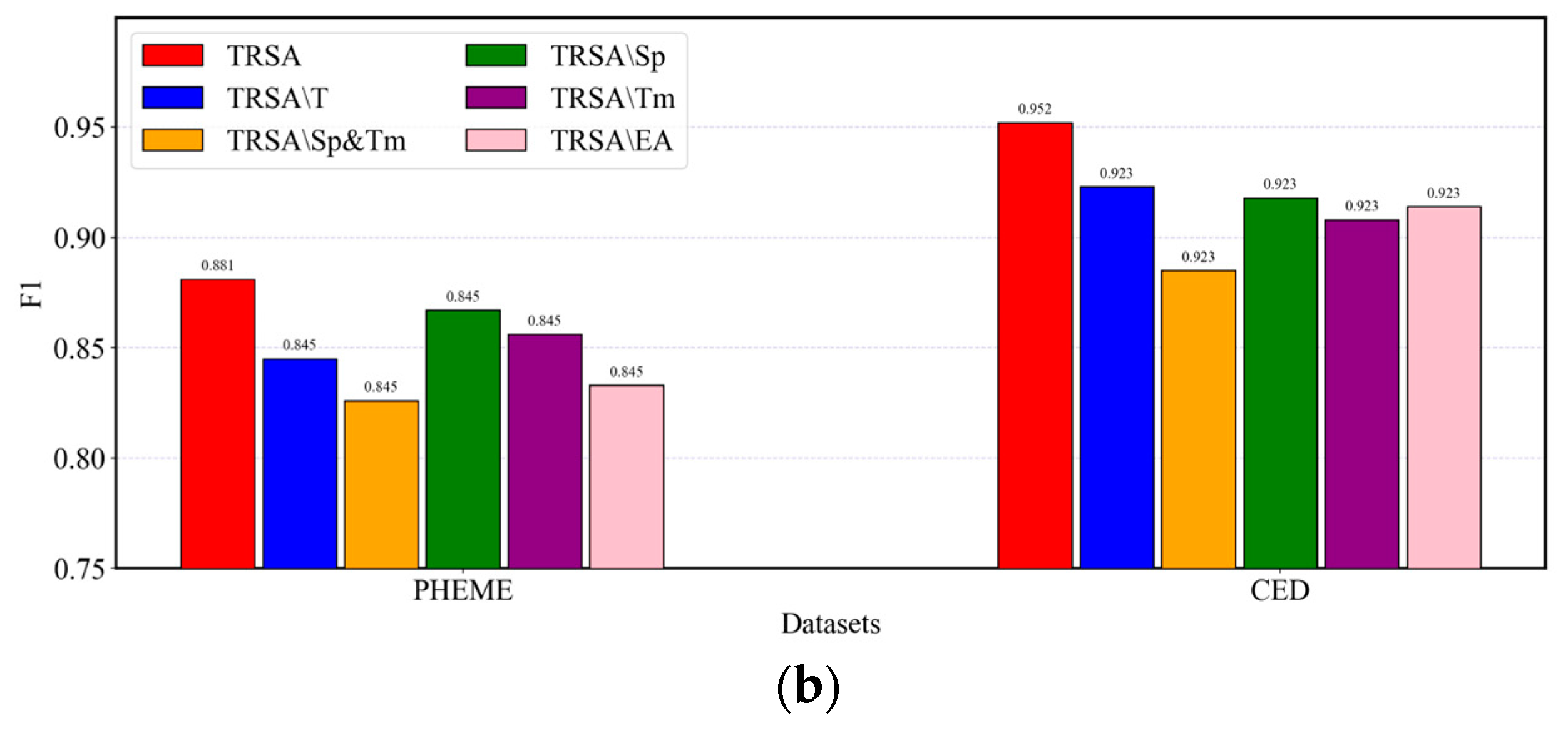
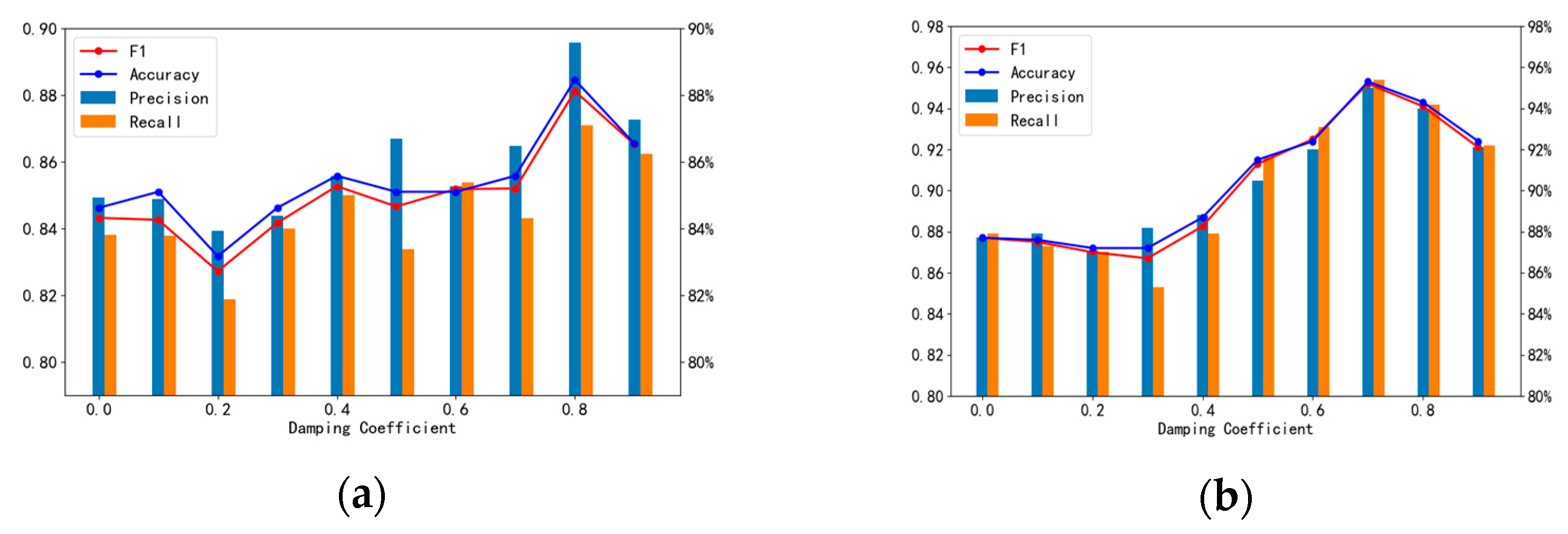
5.3. Ablation Study
5.4. Explainable Analysis
- First, we focused on each token in the source information by accumulating the attention values of the interactions between evidence (high-quality comments) and claims (source information) in the information propagation process, which is represented by the size and color of each word. The larger the font, the darker the color of the word, indicating that more attention is assigned to the word in the process of information propagation and the word is more controversial. One can see that “Emergency”, “distress”, and “# 4U9525” have been widely discussed by users in the process of information propagation, which further demonstrates that our model can automatically capture controversial content;
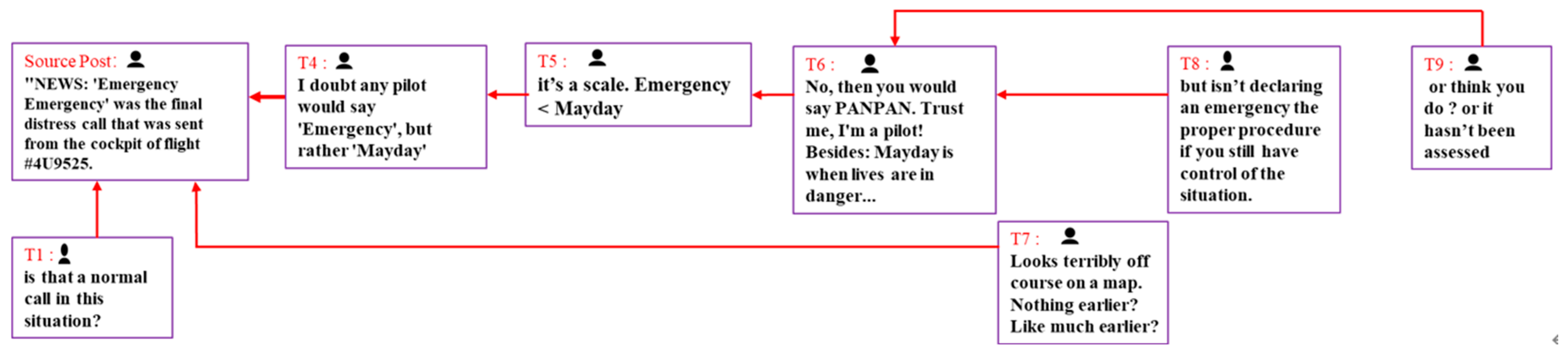
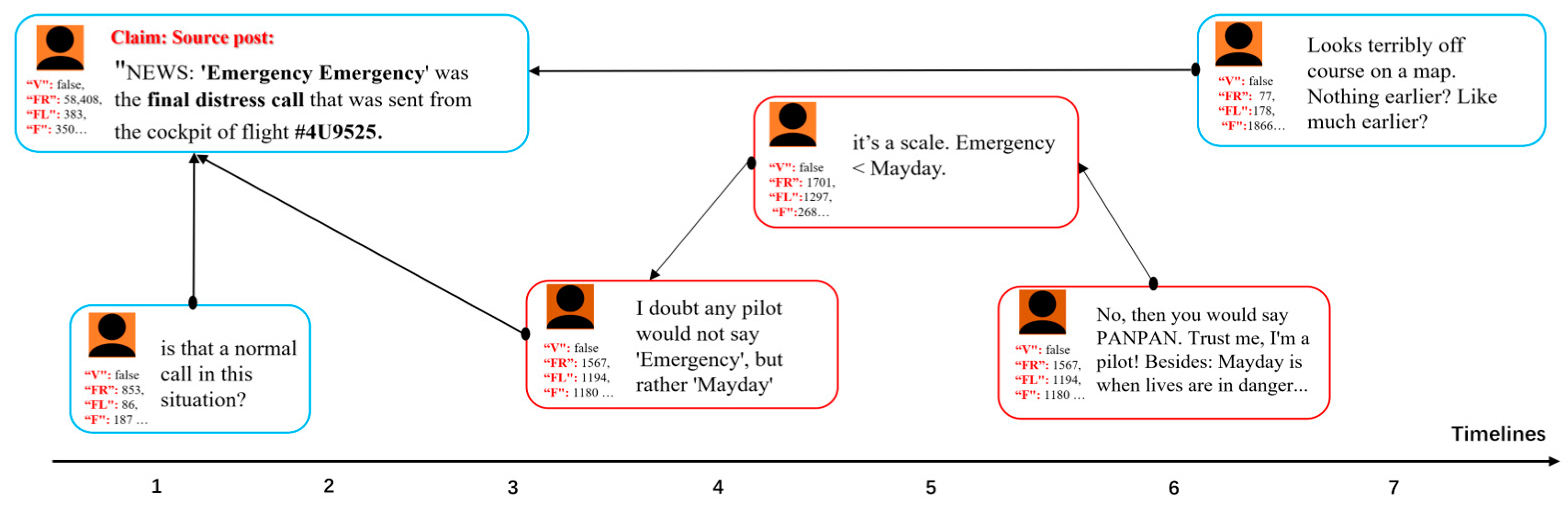
- Second, we used Gephi to draw the information dispersion network, where the sizes of nodes were determined by their credibility (the higher the credibility of the node, the larger the node). One can see that the black nodes represented source information, and the other nodes represented related forwarding or comment posts. Comments endowed with high credibility weights could be used as evidence to prove that the source information is fake. Consider the following comments. “I doubt that any pilot would not say ‘Emergency,’ but rather ‘Mayday’.” “No, then you would say ‘PANPAN’. Trust me, I’m a pilot! Besides, ‘Mayday’ is a time when life is in danger.” “By the way: Cabin pressure loss in an airliner is a classic case for Mayday! \# 4u9525?”. The “PANPAN” and “Mayday” terms appearing in these comments are internationally used radio crisis call signals, indicating that the “Emergency” term in the source information is incorrect. This indicates that the trust-aware evidence reasoning module can provide highly reliable evidence to explain the model results. To measure the support of evidence for results objectively, we examined the implicit bias distribution of evidence by visualizing the aggregation probabilities of the underlying evidence capsules into the high-level category capsule in the evidence aggregation module. One can see that most of the highly credible evidence refutes the source information content;
- To unfold user attention distribution differences between fake and true news content, we randomly selected three fake (0–2) and three true (3–5) news stories, and plotted their token weight distributions based on the attention of the interactions between the evidence and claims. As shown in Figure 7, the horizontal direction from left to right represented the word sequence. In the vertical direction, the first three entries represented fake information (0–2) and the last three represented true information (3–5). One can see that some parts of fake news had attracted widespread attention, while the attention to various components of real news was relatively uniform. The results show that to determine whether a piece of news is fake, one should first examine the distribution of users’ attention to news content. The evidence of fake news in terms of users’ attention may be unevenly concentrated on certain parts of news content.
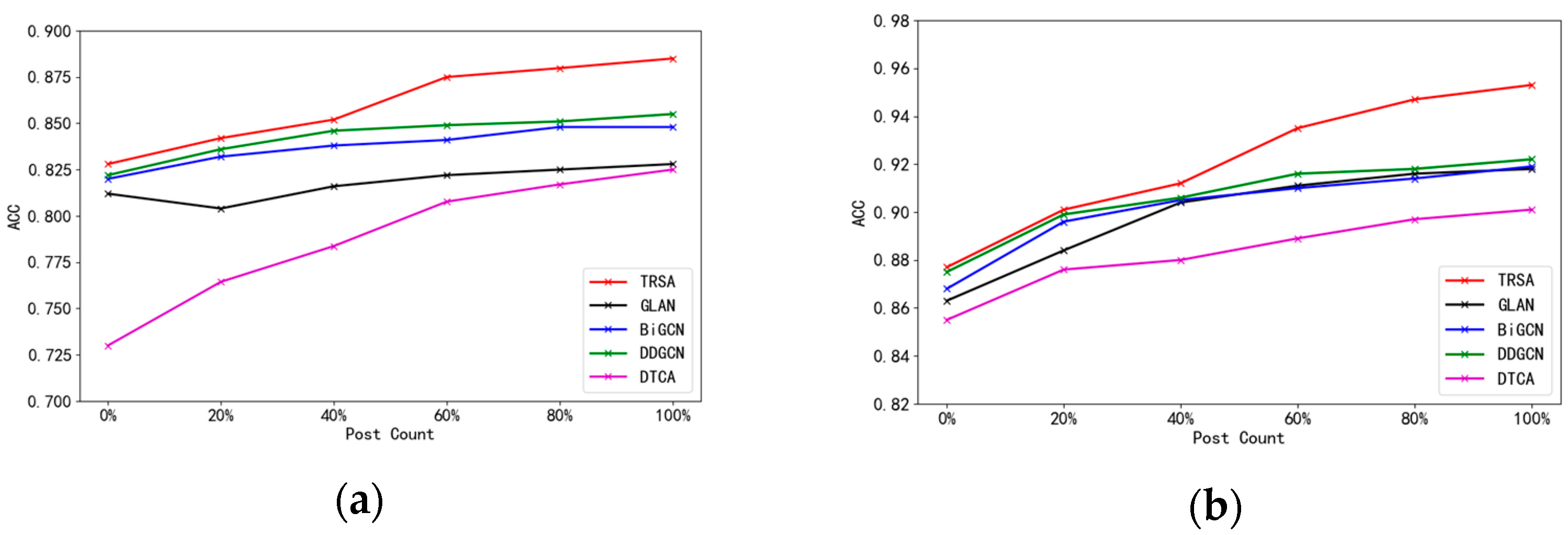
5.5. Early Fake News Detection Performance
- To answer EI4, we sorted all comments (or forwarded posts) according to their publishing time and evaluated the changes in TRSA’s detection performance by changing the number of posts received (0%, 20%, 40%, 60%, 80%, 100%). Figure 8 presents the early detection results of the model for both datasets. One can see that when only the first 40% of comments were considered, the accuracy of the proposed model could reach 85.2% and 91.2% on the two datasets, which was superior to the results of the baseline models. This indicates that our model performed well in terms of early detection. Additionally, we observed that the accuracies of the GLAN, BiGCN, and DDGCN models increased slowly over time, whereas the proposed model exhibited significantly improved performance over time. This is because the dispersion network structure of information becomes more complex and the types of posts become more diversified over time. The proposed model has a module for filtering noise posts. Therefore, they had good robustness.
5.6. Limitations Analysis of TRSA
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
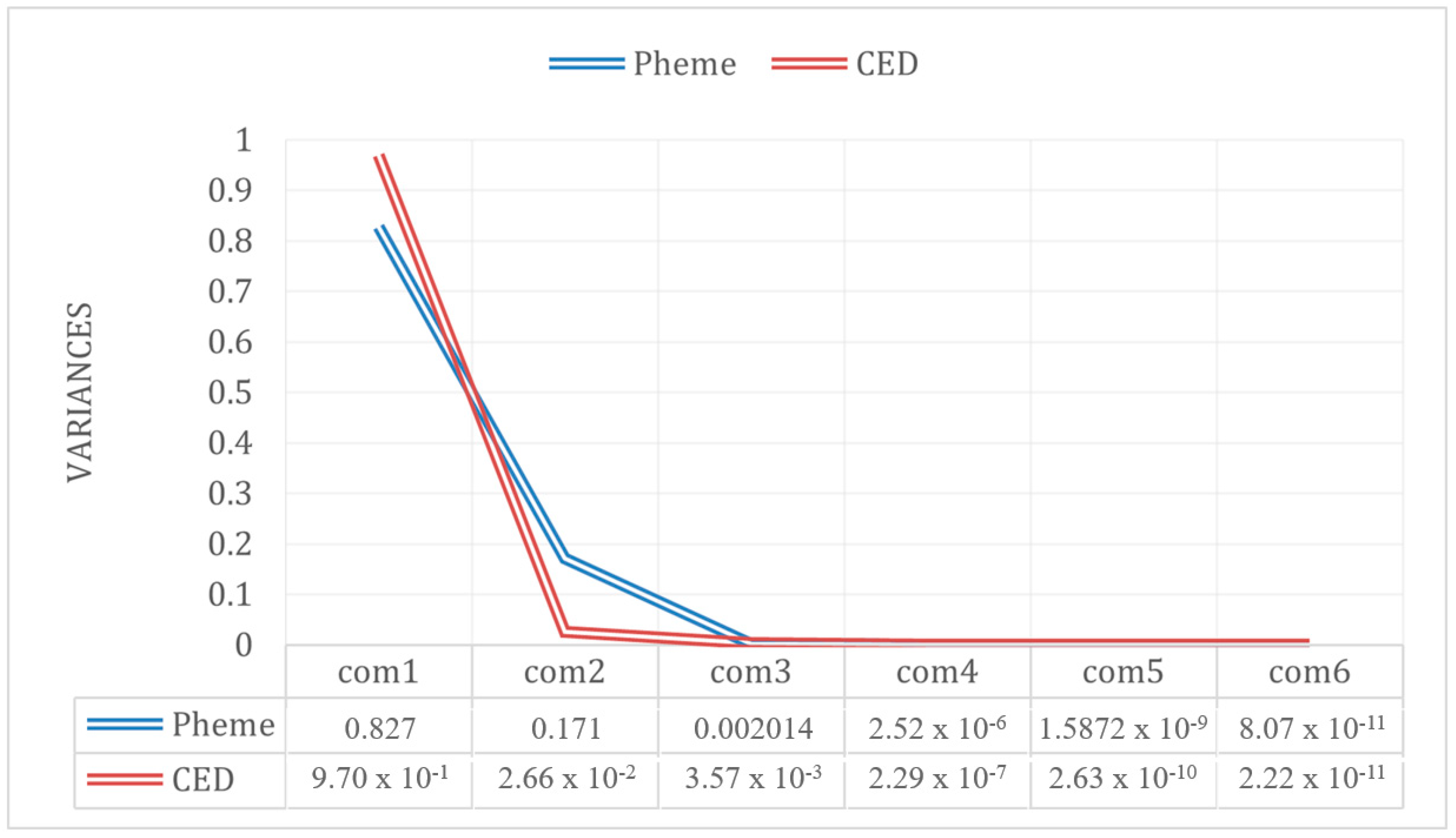
Appendix A. User Authority Calculation Method Based on Multidimensional Attribute Weighted Fusion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Multidimensional Metadata | Weights | |
|---|---|---|---|
| PHEME | CED | ||
| BOOL | verified(V) | 1.20 × 10−6 | 2.19 × 10−7 |
| whether there is homepage introduction (D) | 1.00 × 10−5 | 2.25 × 10−4 | |
| whether geo-spatial positioning is allowed (GEO) | 1.26 × 10−5 | 8.08 × 10−6 | |
| Long Int | fans (FL) | 2.11 × 10−1 | 1.26 × 10−1 |
| friends (FR) | 9.58 × 10−1 | 1.06 × 10−2 | |
| favorites (F)(PHEME)/message (M)(CED) | 1.91 × 10−1 | 9.91 × 10−1 | |

Appendix B. A Proof of the Irreducible and Aperiodic Property of the Transfer Matrix
Appendix C. Optimal Parameter Configuration of the TRSA Model on Two Datasets
| Notations | Descriptions |
|---|---|
| Si | the news (source information) to be detected |
| a d-dimensional vector denoting the semantic feature of token in Si | |
| the authority of user i | |
| the temporal structure of , where is a d-dimensional vector representing the post (comment or forwarded) content at time j in the propagation of information and is the time at which post is generated | |
| G(Si) = <V, E> | the propagation graph of news Si, V is the node collection of G(Si), denoting posts in source information propagation. E denotes the edge collection, describing the association relationship between nodes in G(Si) |
| the recognition degree of post i relative to the content of post j | |
| n-dimensional vectors denoting the visiting probability distribution of random walkers to all nodes in the information dispersion. | |
| the semantic representation of the temporal structure of evidence i | |
| the semantic representation of the spatial structure of evidence i | |
| the semantic representation of the spatiotemporal structure of evidence i | |
| the collections of underlying evidence capsules; is the semantic representation of an underlying evidence capsule | |
| the semantic representation of a category capsule |
| Hyperparameters | Descriptions | Values |
|---|---|---|
| LEARNING_RATE | the initial learning rate of the model | 2 × 10−5 |
| BATCH_SIZE | num. of training samples in one session | 8 |
| EPOCH | num. of iterations | 15 |
| MAX_SEQUENCE_LENGTH | the maximum number of tokens contained in the news required by model | 70 |
| LEN_COM | the maximum number of posts associated with the news required by model | 50 |
| NHEADS | number of heads with multi-head attention | 8 |
| LSTM_hidden size | the number of hidden units in the LSTM, which are used to control the dimensions of | 384 |
| GAT_hidden size | the number of hidden units in the GAT, which are used to control the dimensions of | 96 |
| Multi_Head Attention_outsize | the number of hidden units in Multi_Head Attention, which are used to control the dimensions of | 200 |
| Capsule_out_dim | the number of hidden units in category capsule, which are used to control the dimensions of | 200 |

References
- Sheng, Q.; Cao, J.; Bernard, H.R.; Shu, K.; Li, J.; Liu, H. Characterizing multi-domain false news and underlying user effects on chinese weibo. Inf. Process. Manag. 2022, 59, 102959. [Google Scholar] [CrossRef]
- Fourney, A.; Racz, M.Z.; Ranade, G.; Mobius, M.; Horvitz, E. Geographic and temporal trends in fake news consumption during the 2016 us presidential election. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Association for Computing Machinery, Singapore, 6–10 November 2017; pp. 2071–2074. [Google Scholar]
- Islam, M.S.; Sarkar, T.; Khan, S.H.; Kamal, A.H.M.; Hasan, S.M.; Kabir, A.; Yeasmin, D.; Islam, M.A.; Chowdhury, K.I.A.; Anwar, K.S.; et al. COVID-19-Related Infodemic and Its Impact on Public Health: A Global Social Media Analysis. Am. J. Trop. Med. Hyg. 2020, 103, 1621–1629. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.-W.; Kim, J.-H. Fake Sentence Detection Based on Transfer Learning: Applying to Korean COVID-19 Fake News. Appl. Sci. 2022, 12, 6402. [Google Scholar] [CrossRef]
- Verri Lucca, A.; Augusto Silva, L.; Luchtenberg, R.; Garcez, L.; Mao, X.; García Ovejero, R.; Miguel Pires, I.; Luis Victória Barbosa, J.; Reis Quietinho Leithardt, V. A Case Study on the Development of a Data Privacy Management Solution Based on Patient Information. Sensors 2020, 20, 6030. [Google Scholar] [CrossRef]
- Alghamdi, J.; Lin, Y.; Luo, S. Does Context Matter? Effective Deep Learning Approaches to Curb Fake News Dissemination on Social Media. Appl. Sci. 2023, 13, 3345. [Google Scholar] [CrossRef]
- Bazmi, P.; Asadpour, M.; Shakery, A. Multi-view co-attention network for fake news detection by modeling topic-specific user and news source credibility. Inf. Process. Manag. 2023, 60, 103146. [Google Scholar] [CrossRef]
- Qazvinian, V.; Rosengren, E.; Radev, D.; Mei, Q. Rumor has it: Identifying misinformation in microblogs. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, Scotland, UK, 27–31 July 2011; pp. 1589–1599. [Google Scholar]
- Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on twitter. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 675–684. [Google Scholar]
- Potthast, M.; Kiesel, J.; Reinartz, K.; Bevendorff, J.; Stein, B. A stylometric inquiry into hyperpartisan and fake news. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 231–240. [Google Scholar]
- Ito, J.; Song, J.; Toda, H.; Koike, Y.; Oyama, S. Assessment of tweet credibility with lda features. In Proceedings of the 24th International Conference on World Wide Web, Association for Computing Machinery, Florence, Italy, 18–22 May 2015; pp. 953–958. [Google Scholar]
- Kwon, S.; Cha, M.; Jung, K.; Chen, W.; Wang, Y. Prominent features of rumor propagation in online social media. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 1103–1108. [Google Scholar]
- Hu, X.; Tang, J.; Gao, H.; Liu, H. Social spammer detection with sentiment information. In Proceedings of the 2014 IEEE 14th International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 180–189. [Google Scholar]
- Karimi, H.; Tang, J. Learning hierarchical discourse-level structure for fake news detection. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 3432–3442. [Google Scholar]
- Shu, K.; Wang, S.; Liu, H. Beyond news contents: The role of social context for fake news detection. In Proceedings of the 12th ACM International Conference on Web Search and Data Mining, Association for Computing Machinery, Melbourne, VIC, Australia, 11–15 February 2019; pp. 312–320. [Google Scholar]
- Wang, Y.; Qian, S.; Hu, J.; Fang, Q.; Xu, C. Fake news detection via knowledge-driven multimodal graph convolutional networks. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Association for Computing Machinery, Dublin, Ireland, 8–11 June 2020; pp. 540–547. [Google Scholar]
- Hu, L.; Yang, T.; Zhang, L.; Zhong, W.; Tang, D.; Shi, C.; Duan, N.; Zhou, M. Compare to the knowledge: Graph neural fake news detection with external knowledge. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 754–763. [Google Scholar]
- Yan, R.; Yen, I.E.; Li, C.T.; Zhao, S.; Hu, X. Tackling the achilles heel of social networks: Influence propagation-based language model smoothing. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1318–1328. [Google Scholar]
- Shu, K.; Cui, L.; Wang, S.; Lee, D.; Liu, H. defend: Explainable fake news detection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Association for Computing Machinery, Anchorage, AK, USA, 4–8 August 2019; pp. 395–405. [Google Scholar]
- Wu, L.; Rao, Y.; Jin, H.; Nazir, A.; Sun, L. Different absorption from the same sharing: Sifted multi-task learning for fake news detection. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4644–4653. [Google Scholar]
- Wu, L.; Rao, Y.; Zhao, Y.; Liang, H.; Nazir, A. Dtca: Decision tree-based co-attention networks for explainable claim verification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1024–1035. [Google Scholar]
- Yuan, C.; Ma, Q.; Zhou, W.; Han, J.; Hu, S. Jointly embedding the local and global relations of heterogeneous graph for rumor detection. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 796–805. [Google Scholar]
- Bian, T.; Xiao, X.; Xu, T.; Zhao, P.; Huang, W.; Rong, Y.; Huang, J. Rumor detection on social media with bi-directional graph convolutional networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 549–556. [Google Scholar]
- Lu, Y.J.; Li, C.T. Gcan: Graph-aware co-attention networks for explainable fake news detection on social media. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 505–514. [Google Scholar]
- Song, Y.Z.; Chen, Y.S.; Chang, Y.T.; Weng, S.Y.; Shuai, H.H. Adversary-aware rumor detection. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP, Online, 1–6 August 2021; pp. 1371–1382. [Google Scholar]
- Xu, S.; Liu, X.; Ma, K.; Dong, F.; Riskhan, B.; Xiang, S.; Bing, C. Rumor detection on social media using hierarchically aggregated feature via graph neural networks. Appl. Intell. 2022, 53, 3136–3149. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Lv, Z.; Han, X.; Li, B.; Lu, M.; Li, D. Social bot-aware graph neural network for early rumor detection. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 6680–6690. [Google Scholar]
- Guo, B.; Jiang, Z.-b.; Kumar, M. What is the internet water army? A practical feature-based detection of large-scale fake reviews. Mob. Inf. Syst. 2023, 2023, 2565020. [Google Scholar] [CrossRef]
- Huang, Q.; Zhou, C.; Wu, J.; Liu, L.; Wang, B. Deep spatial–temporal structure learning for rumor detection on twitter. Neural Comput. Applic 2020, 1–11. [Google Scholar] [CrossRef]
- Xia, R.; Xuan, K.; Yu, J. A state-independent and time-evolving network for early rumor detection in social media. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), Online, 16–20 November 2020; pp. 9042–9051. [Google Scholar]
- Sun, M.; Zhang, X.; Zheng, J.; Ma, G. DDGCN: Dual Dynamic Graph Convolutional Networks for Rumor Detection on Social Media. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; pp. 4611–4619. [Google Scholar]
- Rosnow, R.L. Inside rumor: A personal journey. Am. Psychol. 1991, 46, 484. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.-F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA 9–15 July 2016; AAAI Press: New York, NY, USA, 2016; pp. 3818–3824. [Google Scholar]
- Wang, Y.; Wang, L.; Yang, Y.; Lian, T. SemSeq4FD: Integrating global semantic relationship and local sequential order to enhance text representation for fake news detection. Expert Syst. Appl. 2020, 166, 0957–4174. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Cao, J.; Li, X.; Sheng, Q.; Zhong, L.; Shu, K. Mining dual emotion for fake news detection. In Proceedings of the Web Conference 2021, Association for Computing Machinery, Ljubljana, Slovenia, 19–23 April 2021; pp. 3465–3476. [Google Scholar]
- Luvembe, A.M.; Li, W.; Li, S.; Liu, F.; Xu, G. Dual emotion based fake news detection: A deep attention-weight update approach. Inf. Process. Manag. 2023, 60, 103354. [Google Scholar] [CrossRef]
- Shi, B.; Weninger, T. Discriminative predicate path mining for fact checking in knowledge graphs. Know.-Based Syst. 2016, 104, 123–133. [Google Scholar] [CrossRef]
- Ciampaglia, G.L.; Shiralkar, P.; Rocha, L.M.; Bollen, J.; Menczer, F.; Flammini, A. Computational fact checking from knowledge networks. PLoS ONE 2015, 10, e0128193. [Google Scholar]
- Chen, T.; Li, X.; Yin, H.; Zhang, J. Call attention to rumors: Deep attention based recurrent neural networks for early rumor detection. In Proceedings of the Paciffc-Asia Conference on Knowledge Discovery and Data Mining, Melbourne, VIC, Australia, 3–6 June 2018; pp. 40–52. [Google Scholar]
- Shan, Y. How credible are online product reviews? The effects of self-generated and system-generated cues on source credibility evaluation. Comput. Hum. Behav. 2016, 55, 633–641. [Google Scholar] [CrossRef]
- Sidorov, G.; Gelbukh, A.; Gómez-Adorno, H.; Pinto, D. Soft similarity and soft cosine measure: Similarity of features in vector space model. Comput. Sist. 2014, 18, 491–504. [Google Scholar] [CrossRef]
- Langville, A.N.; Meyer, C.D. Google’s PageRank and Beyond: The Science of Search Engine Rankings; Princeton University Press: Princeton, NJ, USA, 2006. [Google Scholar]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM Networks for Improved Phoneme Classification and Recognition. In Proceedings of the International Conference on Artificial Neural Networks, Warsaw, Poland, 11–15 September 2005. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3859–3869. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Curran Associates Inc., Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Zubiaga, A.; Liakata, M.; Procter, R.; Wong Sak Hoi, G.; Tolmie, P. Analysing how people orient to and spread rumours in social media by looking at conversational threads. PLoS ONE 2016, 11, e0150989. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Yang, C.; Chen, H.; Tu, C.; Liu, Z.; Sun, M. Ced: Credible early detection of social media rumors. IEEE Trans. Knowl. Data Eng. 2021, 33, 3035–3047. [Google Scholar] [CrossRef]
- Ma, J.; Gao, W.; Wei, Z.; Lu, Y.; Wong, K.-F. Detect rumors using time series of social context information on microblogging websites. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Association for Computing Machinery, Melbourne, Australia, 19–23 October 2015; pp. 1751–1754. [Google Scholar]
- Guo, H.; Cao, J.; Zhang, Y.; Guo, J.; Li, J. Rumor detection with hierarchical social attention network. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Association for Computing Machinery, Torino, Italy, 22–26 October 2018; pp. 943–951. [Google Scholar]









| Statistical Indicators | PHEME | CED |
|---|---|---|
| Source Tweets | 2402 | 3387 |
| Comments/rep | 30,723 | 1,275,179 |
| Users | 20,538 | 1,064,970 |
| Fake | 638 | 1538 |
| True | 1067 | 1849 |
| Uncertain | 697 | - |
| Methods | PHEME | CED | ||||||
|---|---|---|---|---|---|---|---|---|
| A | P | R | F | A | P | R | F1 | |
| DTC | 0.669 | 0.678 | 0.678 | 0.667 | 0.731 | 0.731 | 0.719 | 0.725 |
| SVM-TS | 0.722 | 0.788 | 0.758 | 0.721 | 0.857 | 0.859 | 0.858 | 0.859 |
| HSA_BLSTM | 0.757 | 0.772 | 0.731 | 0.745 | 0.878 | 0.877 | 0.876 | 0.876 |
| DTCA | 0.823 | 0.861 | 0.791 | 0.825 | 0.901 | 0.921 | 0.891 | 0.902 |
| BERT-Emo | 0.800 | 0.795 | 0.795 | 0.793 | 0.905 | 0.916 | 0.913 | 0.914 |
| GLAN | 0.828 | 0.824 | 0.822 | 0.823 | 0.918 | 0.917 | 0.914 | 0.915 |
| BiGCN | 0.847 | 0.840 | 0.834 | 0.835 | 0.919 | 0.918 | 0.916 | 0.917 |
| DDGCN | 0.855 | 0.846 | 0.841 | 0.844 | 0.922 | 0.920 | 0.931 | 0.925 |
| TRSA | 0.885 | 0.896 | 0.871 | 0.881 | 0.953 | 0.950 | 0.954 | 0.952 |
| News | A 1 on PEHEM | A on CED |
|---|---|---|
| News with posts ∈ [0, 3] | 0.826 | 0.879 |
| News with posts ∈ [3, 10] | 0.845 | 0.898 |
| News with posts ∈ [10, ∞] | 0.885 | 0.959 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Zhou, G.; Lu, J.; Wang, S.; Li, S. Trust-Aware Evidence Reasoning and Spatiotemporal Feature Aggregation for Explainable Fake News Detection. Appl. Sci. 2023, 13, 5703. https://doi.org/10.3390/app13095703
Chen J, Zhou G, Lu J, Wang S, Li S. Trust-Aware Evidence Reasoning and Spatiotemporal Feature Aggregation for Explainable Fake News Detection. Applied Sciences. 2023; 13(9):5703. https://doi.org/10.3390/app13095703
Chicago/Turabian StyleChen, Jing, Gang Zhou, Jicang Lu, Shiyu Wang, and Shunhang Li. 2023. "Trust-Aware Evidence Reasoning and Spatiotemporal Feature Aggregation for Explainable Fake News Detection" Applied Sciences 13, no. 9: 5703. https://doi.org/10.3390/app13095703