
LBFNet: A Tomato Leaf Disease Identification Model Based on Three-Channel Attention Mechanism and Quantitative Pruning

Abstract
:1. Introduction
2. Materials and Methods
2.1. LBFtomato Leaf Image Datasets
2.2. Test Environment
2.3. Use Cascading Structures to Reduce Model Loss
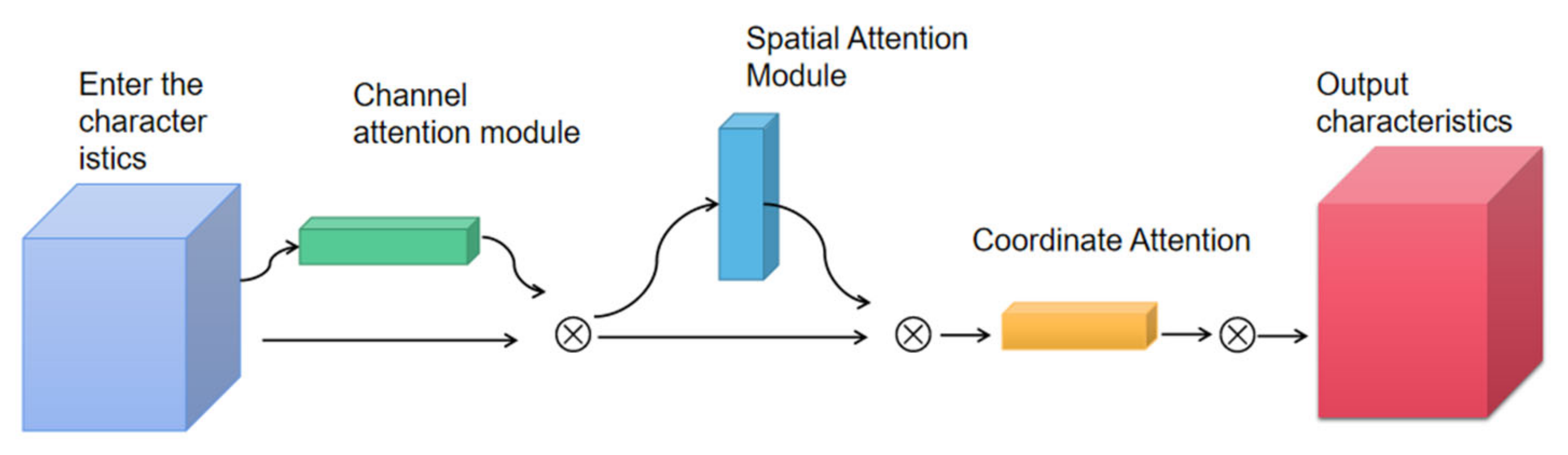
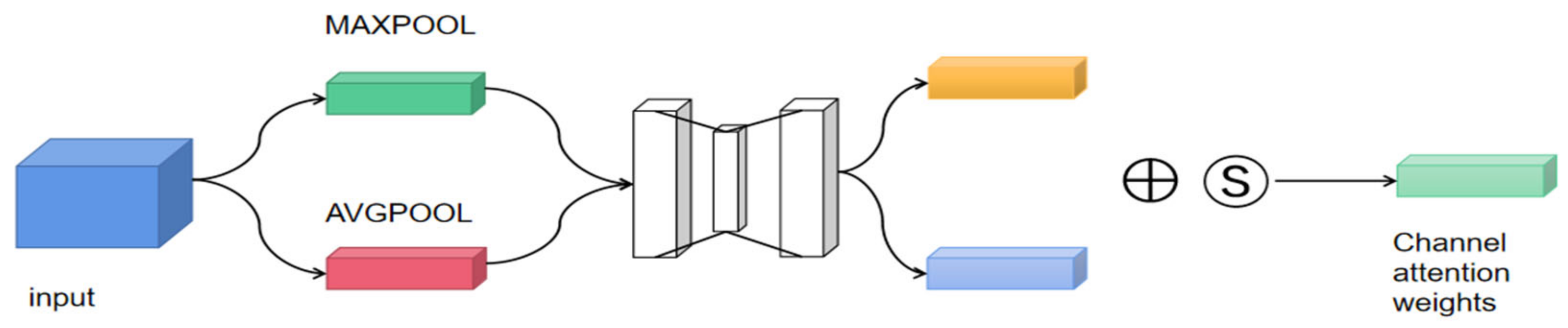
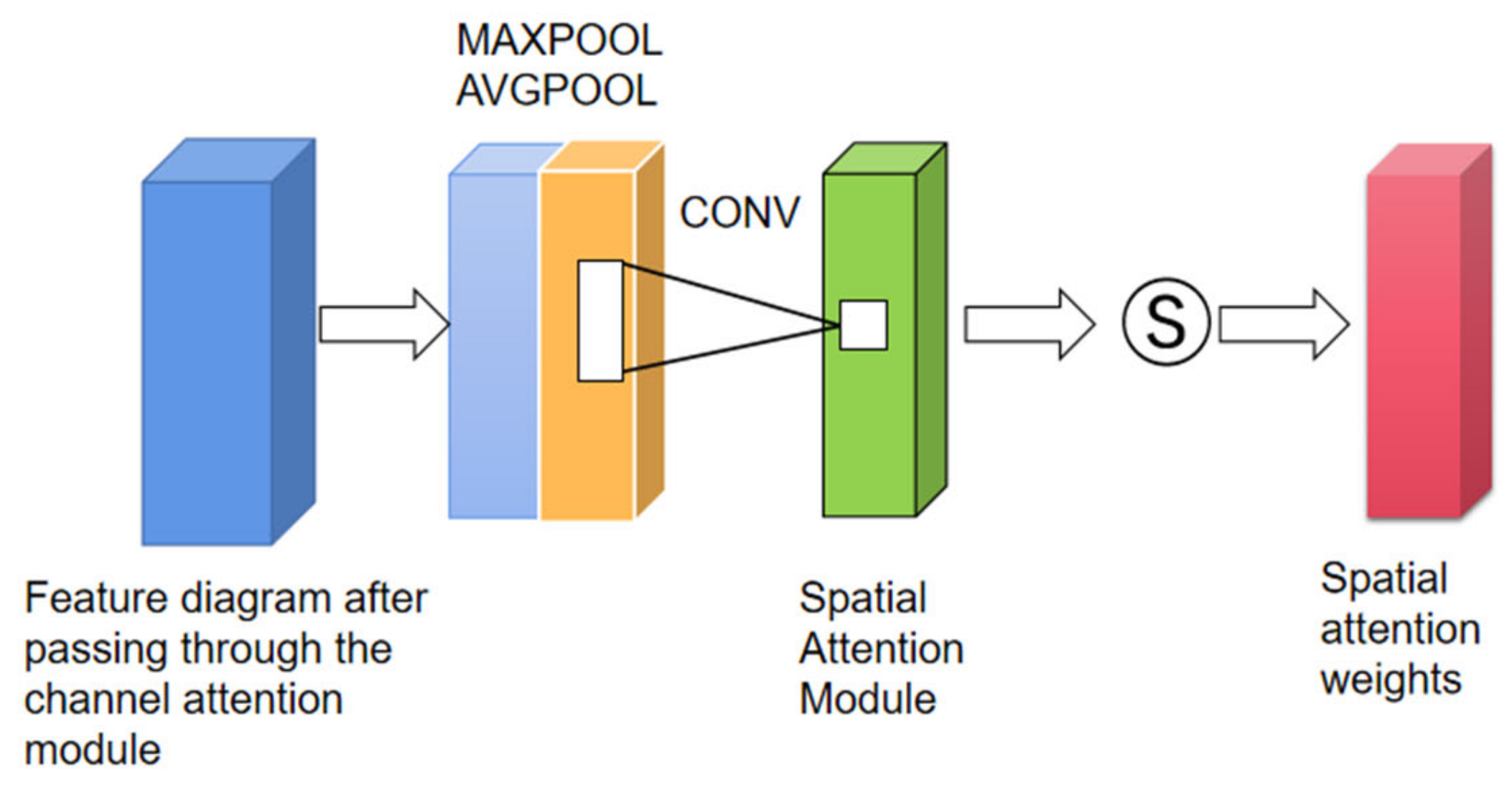
2.4. Using Three-Channel Attention Mechanism to Enhance Model Robustness
2.5. Reducing Model Parameters Using Vgg-Style Convolutional Neural Network
3. Results
3.1. Research on Tomato Leaf Disease Classification Based on LBFNet Model
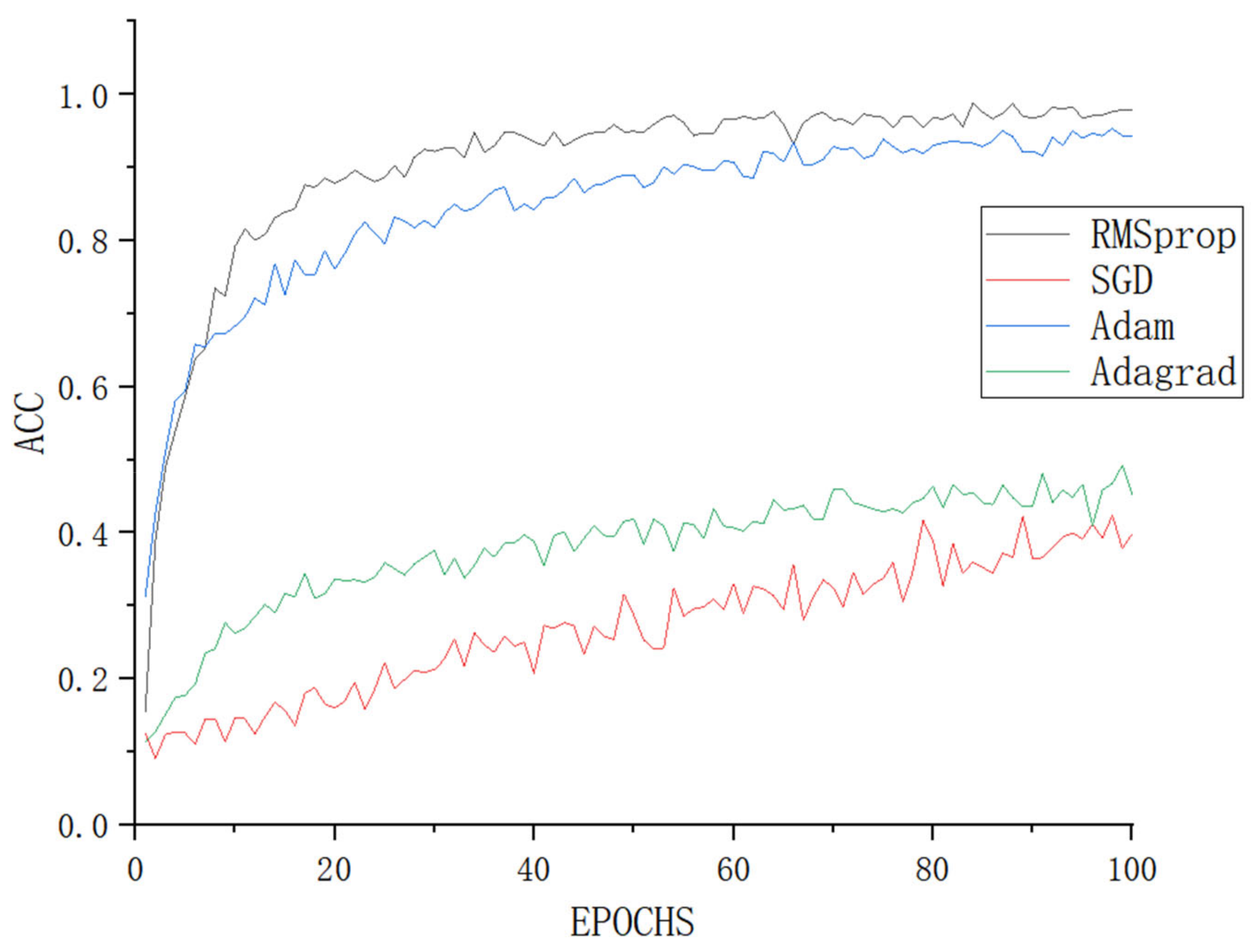
3.1.1. The Impact of Different Optimizers on the Model
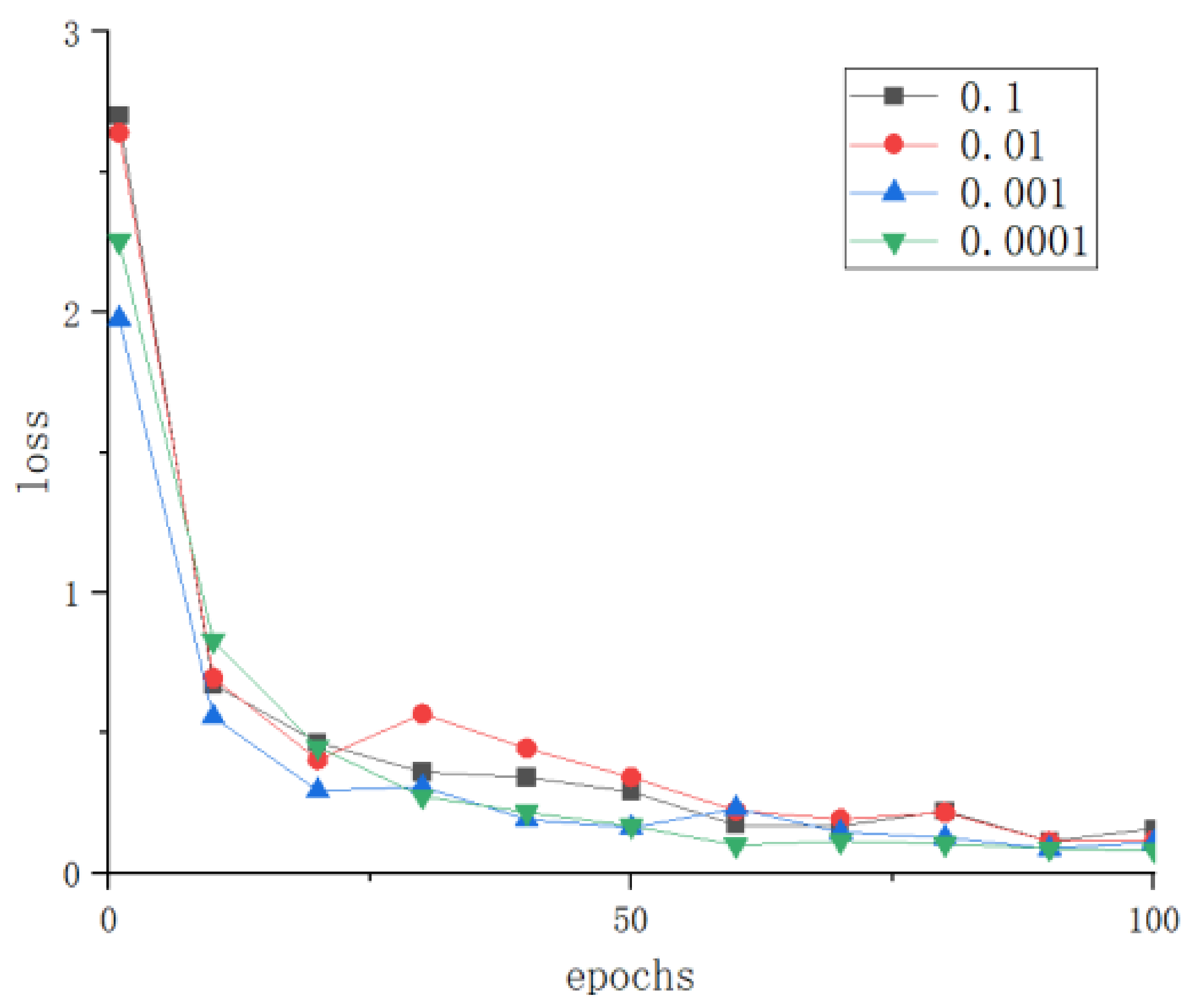
3.1.2. The Impact of Different Learning Rate Parameters on the Model
3.1.3. The Impact of Different Attention Mechanisms on the Model
3.2. Model Performance Comparison
3.2.1. Parameter Settings
3.2.2. Evaluation Indicators
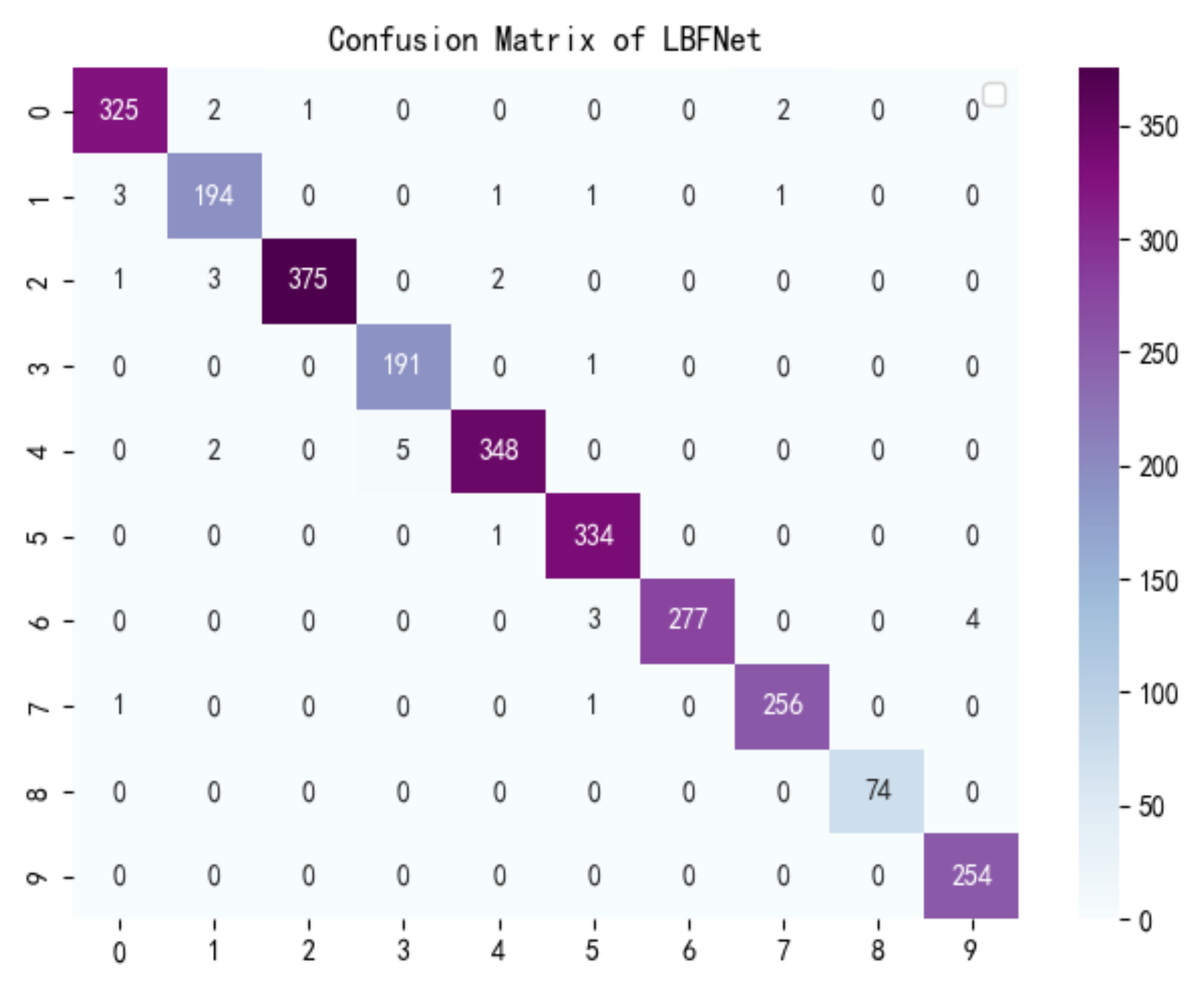
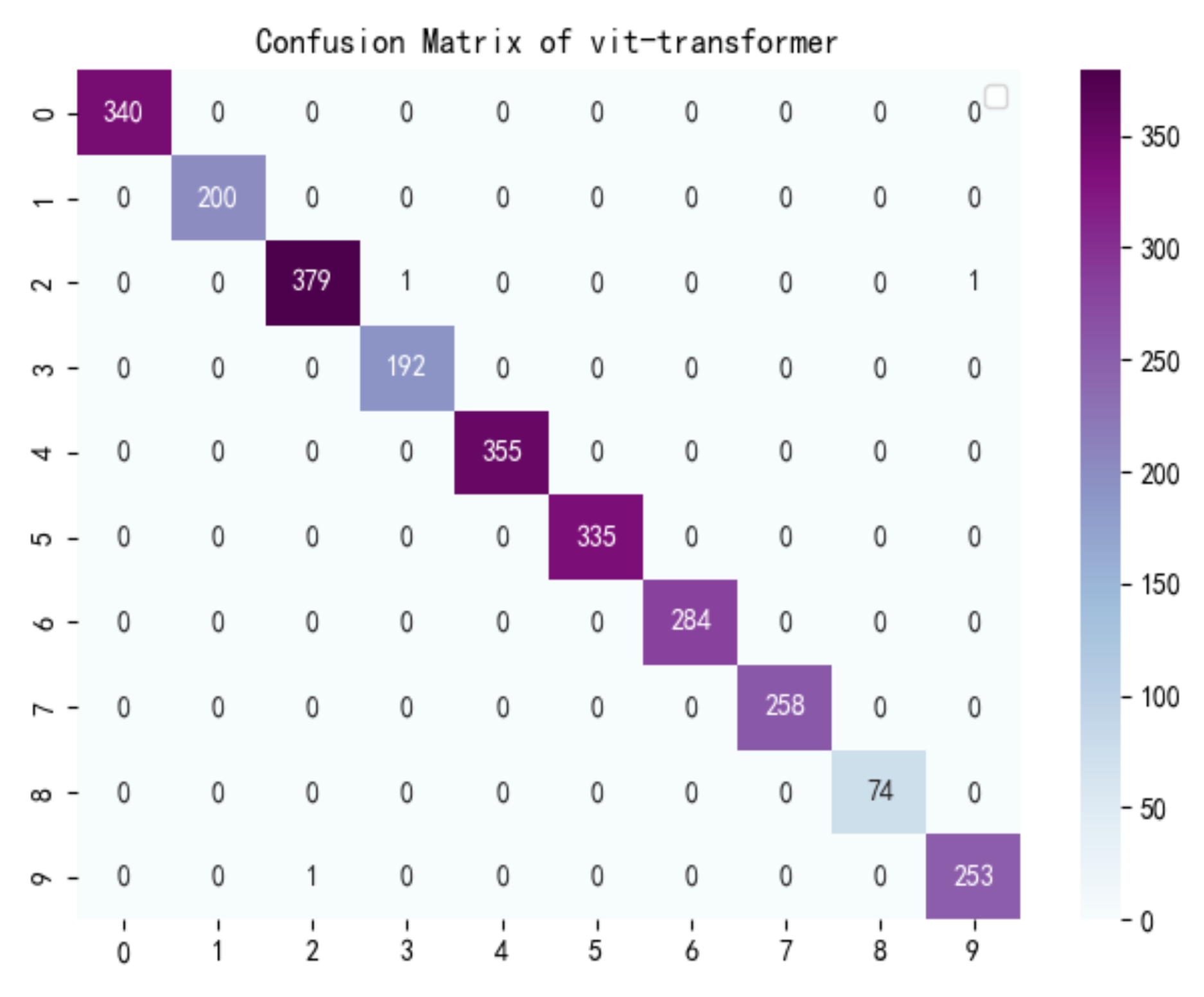
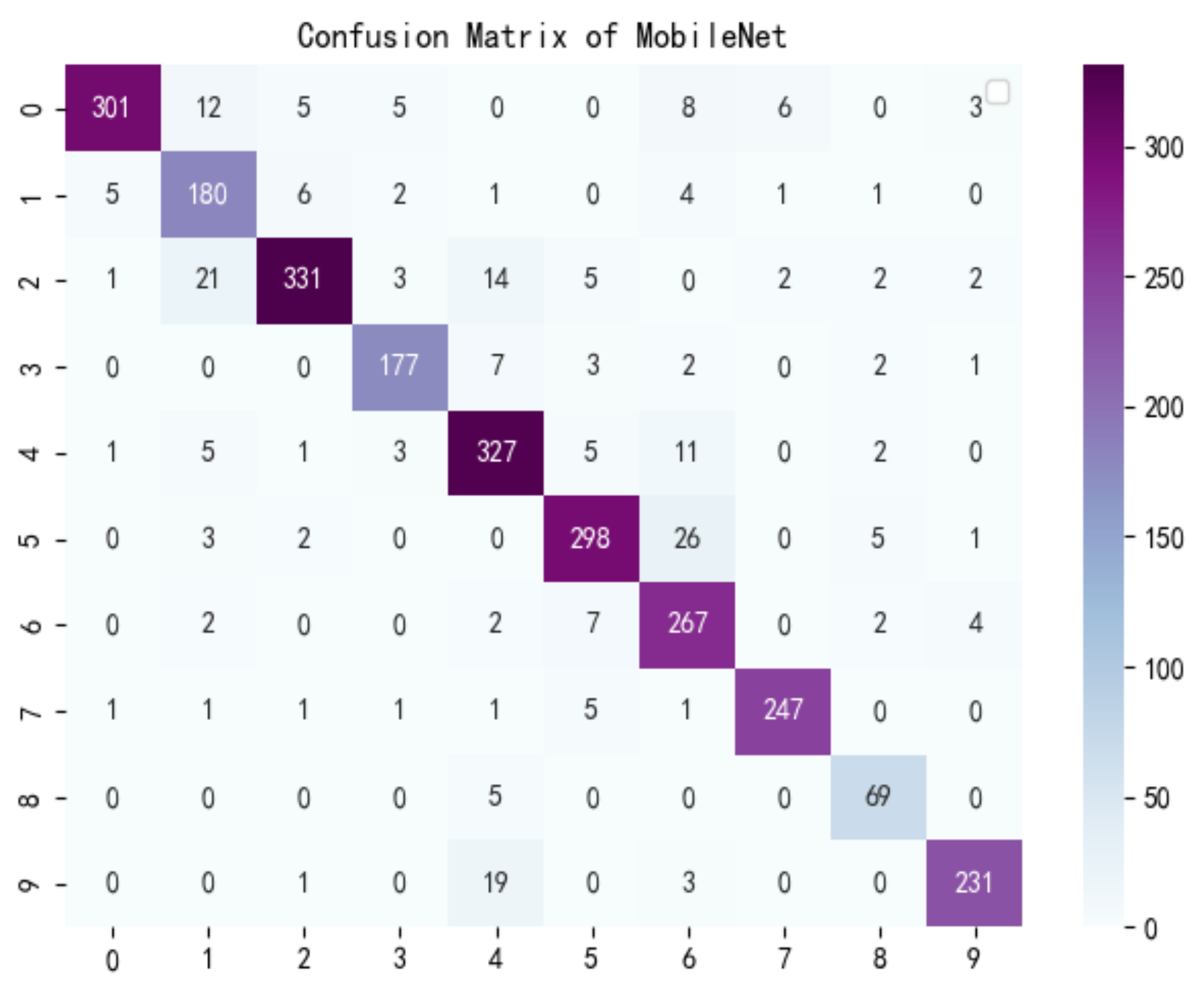
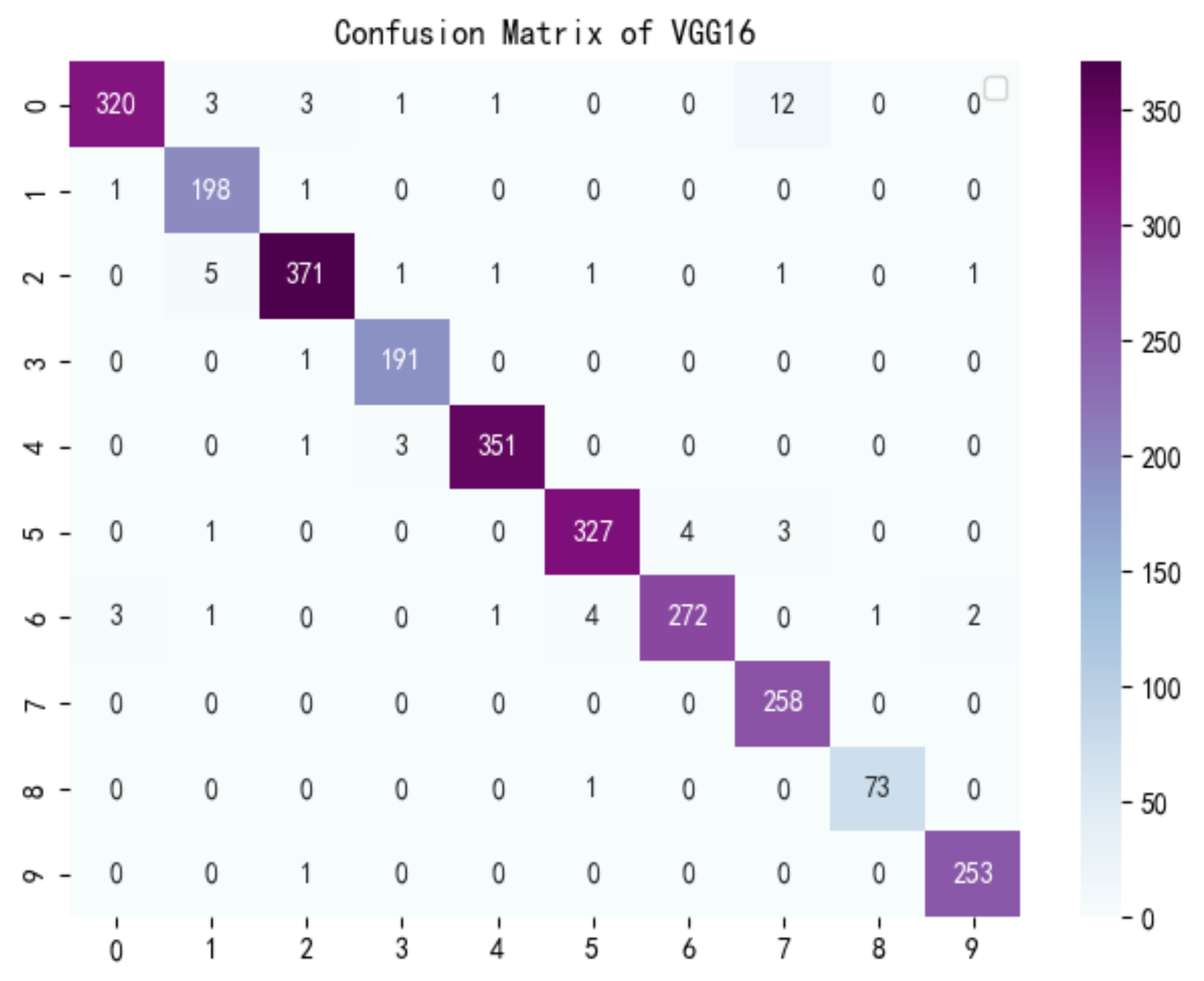
3.2.3. Comparative Analysis Result
3.2.4. Reduce Model Size Using Quantitative Pruning
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Wang, X. Plant diseases and pests detection based on deep learning: A review. Plant Methods 2021, 17, 22. [Google Scholar] [CrossRef] [PubMed]
- Abade, A.; Ferreira, P.A.; de Barros Vidal, F. Plant diseases recognition on images using convolutional neural networks: A systematic review. Comput. Electron. Agric. 2021, 185, 106125. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Gui, P.; Dang, W.; Zhu, F.; Zhao, Q. Towards automatic field plant disease recognition. Comput. Electron. Agric. 2021, 191, 106523. [Google Scholar] [CrossRef]
- Yang, C.; Teng, Z.; Dong, C.; Lin, Y.; Chen, R.; Wang, J. In-Field Citrus Disease Classification via Convolutional Neural Network from Smartphone Images. Agriculture 2022, 12, 1487. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Nguyen, T.N.; Ngo, B.V. A VGG-19 Model with Transfer Learning and Image Segmentation for Classification of Tomato Leaf Disease. AgriEngineering 2022, 4, 871–887. [Google Scholar] [CrossRef]
- Chen, S.; Xiong, J.; Jiao, J.; Xie, Z.; Huo, Z.; Hu, W. Citrus fruits maturity detection in natural environments based on convolutional neural networks and visual saliency map. Precis. Agric. 2022, 23, 1515–1531. [Google Scholar] [CrossRef]
- Mishra, S.; Sachan, R.; Rajpal, D. Deep convolutional neural network based detection system for real-time corn plant disease recognition. Procedia Comput. Sci. 2020, 167, 2003–2010. [Google Scholar] [CrossRef]
- Dong, C.; Zhang, Z.; Yue, J.; Zhou, L. Automatic recognition of strawberry diseases and pests using convolutional neural network. Smart Agric. Technol. 2021, 1, 100009. [Google Scholar] [CrossRef]
- Xu, W.; Zhao, L.; Li, J.; Shang, S.; Ding, X.; Wang, T. Detection and classification of tea buds based on deep learning. Comput. Electron. Agric. 2022, 192, 106547. [Google Scholar] [CrossRef]
- Liu, C.; Zhu, H.; Guo, W.; Han, X.; Chen, C.; Wu, H. EFDet: An efficient detection method for cucumber disease under natural complex environments. Comput. Electron. Agric. 2021, 189, 106378. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Q.; Gao, L. Visual tea leaf disease recognition using a convolutional neural network model. Symmetry 2019, 11, 343. [Google Scholar] [CrossRef]
- Singh, A.K.; Sreenivasu, S.V.N.; Mahalaxmi, U.S.B.K.; Sharma, H.; Patil, D.D.; Asenso, E. Hybrid feature-based disease detection in plant leaf using convolutional neural network, bayesian optimized SVM, and random forest classifier. J. Food Qual. 2022, 2022, 2845320. [Google Scholar] [CrossRef]
- Zhang, S.W.; Shang, Y.J.; Wang, L. Plant disease recognition based on plant leaf image. J. Anim. Plant Sci. 2015, 25, 42–45. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; Volume 4, p. 12. [Google Scholar]
- Abbas, A.; Jain, S.; Gour, M.; Vankudothu, S. Tomato plant disease detection using transfer learning with C-GAN synthetic images. Comput. Electron. Agric. 2021, 187, 106279. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 3. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 13733–13742. [Google Scholar]
- Zeng, W.; Li, M. Crop leaf disease recognition based on Self-Attention convolutional neural network. Comput. Electron. Agric. 2020, 172, 105341. [Google Scholar] [CrossRef]
- Deng, H.; Luo, D.; Chang, Z.; Li, H.; Yang, X. RAHC_GAN: A Data Augmentation Method for Tomato Leaf Disease Recognition. Symmetry 2021, 13, 1597. [Google Scholar] [CrossRef]
- Gong, C.; Wang, D.; Li, M.; Chandra, V.; Liu, Q. Keep Augment: A simple information-preserving data augmentation approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 1055–1064. [Google Scholar]
- Wang, H.; Song, H.; Wu, H.; Zhang, Z.; Deng, S.; Feng, X. Multilayer feature fusion and attention-based network for crops and weeds segmentation. J. Plant Dis. Prot. 2022, 129, 1475–1489. [Google Scholar] [CrossRef]
- Fang, W.; Guan, F.; Yu, H.; Bi, C.; Guo, Y.; Cui, Y.; Su, L.; Zhang, Z. Identification of wormholes in soybean leaves based on multi-feature structure and attention mechanism. J. Plant Dis. Prot. 2022, 130, 401–412. [Google Scholar] [CrossRef]
- Wang, S.H.; Fernandes, S.L.; Zhu, Z.; Zhang, Y.D. AVNC: Attention-based VGG-style network for COVID-19 diagnosis by three-channel attention mechanism. IEEE Sens. J. 2021, 22, 17431–17438. [Google Scholar] [CrossRef] [PubMed]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar]
- Chefer, H.; Gur, S.; Wolf, L. Transformer interpretability beyond attention visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 782–791. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Rajput, D.S.; Reddy, M.P.K.; Lakshmanna, K.; Bhattacharya, S.; Singh, S.; Jolfaei, A. A novel PCA–whale optimization-based deep neural network model for classification of tomato plant diseases using GPU. J. Real-Time Image Process. 2021, 18, 1383–1396. [Google Scholar] [CrossRef]
- Gonzalez-Huitron, V.; León-Borges, J.A.; Rodriguez-Mata, A.E.; Amabilis-Sosa, L.E.; Ramírez-Pereda, B.; Rodriguez, H. Disease detection in tomato leaves via CNN with lightweight architectures implemented in Raspberry Pi 4. Comput. Electron. Agric. 2021, 181, 105951. [Google Scholar] [CrossRef]
- Rangarajan, A.K.; Purushothaman, R.; Ramesh, A. Tomato crop disease classification using pre-trained deep learning algorithm. Procedia Comput. Sci. 2018, 133, 1040–1047. [Google Scholar] [CrossRef]
- Wang, Q.; Qi, F.; Sun, M.; Qu, J.; Xue, J. Identification of tomato disease types and detection of infected areas based on deep convolutional neural networks and object detection techniques. Comput. Intell. Neurosci. 2019, 2019, 9142753. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, C.; Zhang, D. Deep learning-based object detection improvement for tomato disease. IEEE Access 2020, 8, 56607–56614. [Google Scholar] [CrossRef]
- Chakravarthy, A.S.; Raman, S. Early blight identification in tomato leaves using deep learning. In Proceedings of the 2020 International conference on contemporary computing and applications (IC3A), Lucknow, India, 5–7 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 154–158. [Google Scholar]
- Ahmed, S.; Hasan, M.B.; Ahmed, T.; Sony, R.K.; Kabir, H. Less is more: Lighter and faster deep neural architecture for tomato leaf disease classification. IEEE Access 2022, 10, 68868–68884. [Google Scholar] [CrossRef]
- Yu, H.; Liu, J.; Chen, C.; Heidari, A.A.; Zhang, Q.; Chen, H. Optimized deep residual network system for diagnosing tomato pests. Comput. Electron. Agric. 2022, 195, 106805. [Google Scholar] [CrossRef]
- Singh, D.; Jain, N.; Jain, P.; Kayal, P.; Kumawat, S.; Batra, N. PlantDoc: A dataset for visual plant disease detection. In Proceedings of the 7th ACM IKDD CoDS and 25th COMAD, Hyderabad, India, 5–7 January 2020; pp. 249–253. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Karen, S.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.484. [Google Scholar]
- Alexey, D.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA; 2022; pp. 11966–11976. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tomato Picture Category Name | Train Images | Validation Images |
|---|---|---|
| Tomato___Bacterial_spot | 1410 | 717 |
| Tomato___Early_blight | 670 | 330 |
| Tomato___healthy | 940 | 651 |
| Tomato___Late_blight | 1140 | 769 |
| Tomato___Leaf_Mold | 570 | 382 |
| Tomato___Septoria_leaf_spot | 1060 | 711 |
| Tomato___Spider_mites Two-spotted_spider_mite | 1060 | 616 |
| Tomato___Target_Spot | 950 | 454 |
| Tomato___Tomato_mosaic_virus | 270 | 103 |
| Tomato___Tomato_Yellow_Leaf_Curl_Virus | 3810 | 1547 |
| Tomato Picture Category Name | Train Images | Validation Images |
|---|---|---|
| Tomato___Bacterial_spot | 1071 | 340 |
| Tomato___Early_blight | 1000 | 200 |
| Tomato___healthy | 1081 | 254 |
| Tomato___Late_blight | 925 | 381 |
| Tomato___Leaf_Mold | 1000 | 192 |
| Tomato___Septoria_leaf_spot | 1083 | 355 |
| Tomato___Spider_mites Two-spotted_spider_mite | 1115 | 335 |
| Tomato___Target_Spot | 1029 | 284 |
| Tomato___Tomato_mosaic_virus | 1000 | 74 |
| Tomato___Tomato_Yellow_Leaf_Curl_Virus | 1085 | 258 |
| Module | Accuracy | Loss | Parameters | Train Time/s |
|---|---|---|---|---|
| LBFB | 0.6267 | 1.0625 | 689,034 | 4633 |
| LBFB + cascade | 0.9567 | 0.1513 | 955,722 | 2158 |
| LBFB + three-channel attention mechanism | 0.9688 | 0.1034 | 798,276 | 1347 |
| LBFB + cascade + three-channel attention mechanism | 0.9906 | 0.0408 | 897,188 | 966 |
| LBFB + SE | 0.5578 | 1.2754 | 691,098 | 5194 |
| LBFB + cascade + SE | 0.9465 | 0.1703 | 957,786 | 2879 |
| LBFB + CA | 0.8922 | 0.3146 | 776,914 | 1552 |
| LBFB + CA + cascade | 0.9683 | 0.1220 | 962,386 | 2312 |
| LBFB + ECA | 0.8745 | 0.3650 | 773,584 | 1432 |
| LBFB + ECA + cascade | 0.9615 | 0.1405 | 955,728 | 1786 |
| LBFB + DUAL | 0.8853 | 0.3411 | 794,060 | 2434 |
| LBFB + DUAL + cascade | 0.9588 | 0.1261 | 976,204 | 2755 |
| LBFB + CBAM | 0.9089 | 0.3053 | 794,940 | 1537 |
| LBFB + cascade + CBAM | 0.9790 | 0.0815 | 777,468 | 1172 |
| Model | Accuracy | Loss | Parameters | Train Time/s | Test Time/s | F1-Score | Recall | Precision |
|---|---|---|---|---|---|---|---|---|
| Resnet50 [38] | 0.9482 | 0.1579 | 23,608,202 | 28,377 | 0.51 | 0.92 | 0.91 | 0.92 |
| Vgg16 [39] | 0.9590 | 0.0891 | 165,758,794 | 41,577 | 0.23 | 0.96 | 0.96 | 0.96 |
| Mobilenet [18] | 0.9492 | 0.1449 | 2,279,714 | 10,142 | 0.40 | 0.90 | 0.91 | 0.91 |
| Googlenet [40] | 0.8633 | 0.3947 | 10,360,590 | 7857 | 0.32 | 0.87 | 0.87 | 0.87 |
| LBFNet | 0.9906 | 0.0408 | 897,188 | 966 | 0.21 | 0.98 | 0.98 | 0.98 |
| vit-transformer [41] | 1.0 | 0.012 | 85,806,346 | 365,320 | 0.28 | 1.0 | 0.97 | 0.98 |
| ConvNeXt [42] | 0.9884 | 0.071 | 27,827,818 | 197,320 | 0.42 | 0.99 | 0.99 | 0.98 |
| Model | Accuracy | Loss | Parameters | Train Time/s | Test Time/s | F1-Score | Recall | Precision |
|---|---|---|---|---|---|---|---|---|
| Resnet50 | 0.8965 | 0.3025 | 23,608,202 | 27,837 | 0.54 | 0.81 | 0.79 | 0.80 |
| Vgg16 | 0.8175 | 0.5938 | 165,758,794 | 41,926 | 0.25 | 0.80 | 0.79 | 0.77 |
| Mobilenet | 0.7920 | 0.5924 | 2,279,714 | 15,858 | 0.45 | 0.77 | 0.79 | 0.80 |
| Googlenet | 0.8281 | 0.5588 | 10,360,590 | 7172 | 0.36 | 0.82 | 0.84 | 0.82 |
| LBFNet | 0.9756 | 0.2696 | 897,188 | 1420 | 0.23 | 0.97 | 0.98 | 0.98 |
| vit-transformer | 0.9943 | 0.015 | 85,806,346 | 412,702 | 0.41 | 0.99 | 0.98 | 0.99 |
| ConvNeXt | 0.978 | 0.089 | 27,827,818 | 277,456 | 0.52 | 0.97 | 0.98 | 0.97 |
| Size | Accuarcy | Loss | F1-Score | Recall | Precision | |
|---|---|---|---|---|---|---|
| LBFNet | 6.85 MB | 0.9906 | 0.0408 | 0.98 | 0.98 | 0.98 |
| pruned_quantized_model | 3.46 MB | 0.9766 | 0.0712 | 0.97 | 0.97 | 0.97 |
| F1-Score | Recall | Precision | Image Numbers | |
|---|---|---|---|---|
| Bacterial_spot | 0.96 | 0.98 | 0.97 | 340 |
| Early_blight | 0.97 | 0.96 | 0.97 | 200 |
| healthy | 0.98 | 0.98 | 0.98 | 381 |
| Late_blight | 0.99 | 0.99 | 0.99 | 192 |
| Leaf_Mold | 0.99 | 0.99 | 0.99 | 355 |
| Septoria_leaf_spot | 0.98 | 0.99 | 0.99 | 335 |
| Spider_mites | 0.99 | 0.96 | 0.99 | 284 |
| Target_Spot | 0.99 | 0.98 | 0.99 | 258 |
| mosaic_virus | 0.94 | 1.0 | 0.97 | 74 |
| yellow_Leaf_Curl_Virus | 0.99 | 0.99 | 0.99 | 254 |
| accuracy | 0.98 | 2673 | ||
| macro avg | 0.98 | 0.98 | 0.98 | 2673 |
| weighted avg | 0.98 | 0.98 | 0.98 | 2673 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Wang, Y.; Jiang, P.; Zhang, R.; Peng, J. LBFNet: A Tomato Leaf Disease Identification Model Based on Three-Channel Attention Mechanism and Quantitative Pruning. Appl. Sci. 2023, 13, 5589. https://doi.org/10.3390/app13095589
Chen H, Wang Y, Jiang P, Zhang R, Peng J. LBFNet: A Tomato Leaf Disease Identification Model Based on Three-Channel Attention Mechanism and Quantitative Pruning. Applied Sciences. 2023; 13(9):5589. https://doi.org/10.3390/app13095589
Chicago/Turabian StyleChen, Hailin, Yi Wang, Ping Jiang, Ruofan Zhang, and Jialiang Peng. 2023. "LBFNet: A Tomato Leaf Disease Identification Model Based on Three-Channel Attention Mechanism and Quantitative Pruning" Applied Sciences 13, no. 9: 5589. https://doi.org/10.3390/app13095589