
Prediction Modeling of Ground Subsidence Risk Based on Machine Learning Using the Attribute Information of Underground Utilities in Urban Areas in Korea

Abstract
:1. Introduction
2. Method and Data Characteristics
2.1. Subsection Flow of the Study
2.2. Characteristics of the Data
2.3. Density
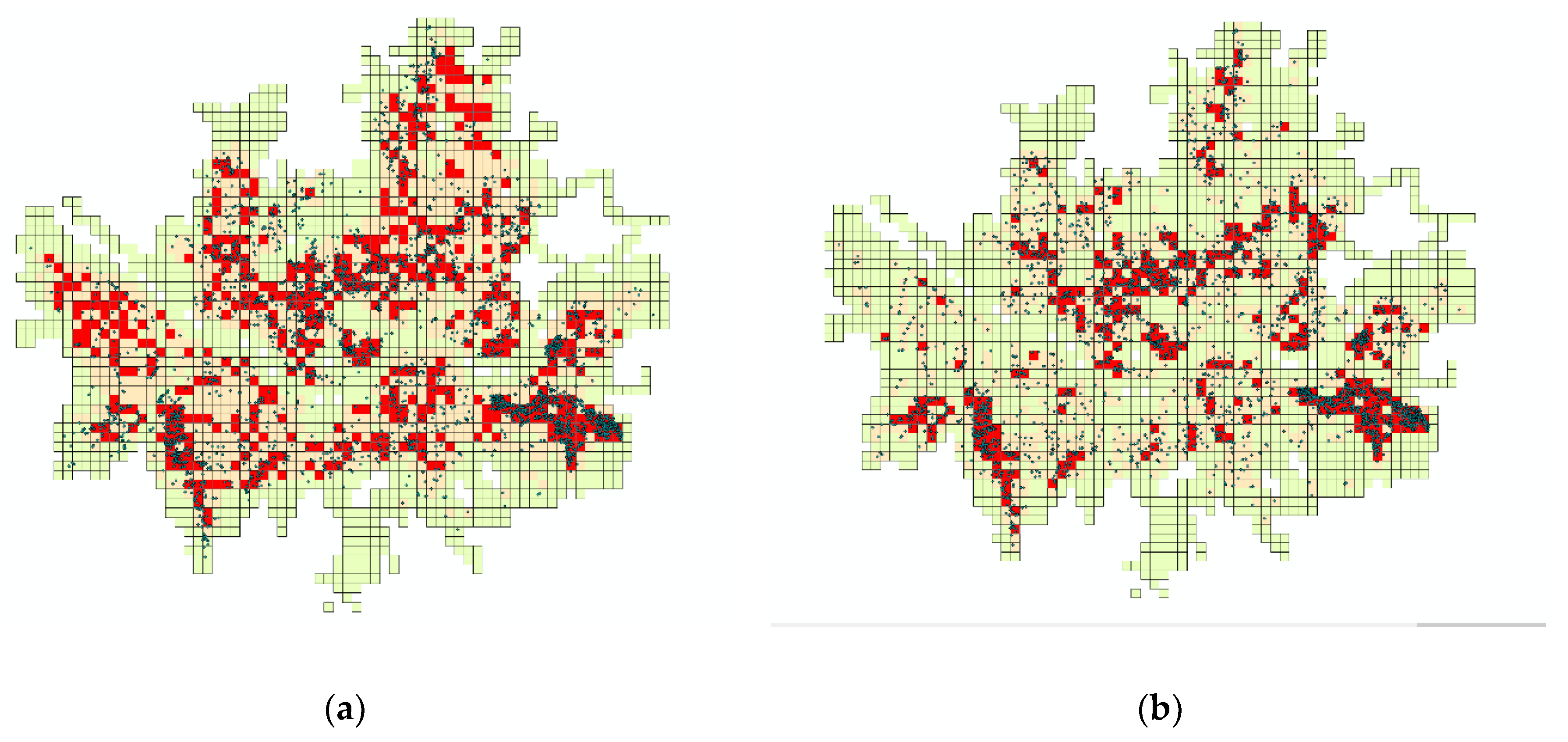
2.4. Risk Level of Ground Subsidence
2.5. Data Correlation Analysis
3. Results of Analysis of Ground Subsidence Risk Levels Using Machine Learning
3.1. Random Forest
3.2. XGBoost (eXtreme Gradient Boosting)
3.3. LightGBM (Light Gradient Boosting Machine)
3.4. Evaluation Indexes of Machine Learning Algorithms
3.5. Results of Applying Machine Learning
3.6. Map of Ground Subsidence Risk
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, S.Y.; Kang, J.M.; Kim, J.Y. Development of Machine Learning Model to predict the ground subsidence risk grade according to the Characteristics of underground facility. J. Korean Geo-Environ. Soc. 2022, 23, 5–10. [Google Scholar]
- Seoul city, Cause Analysis of Cavity at Seokchon Underground Roadway and Road Cavity, Seokchon-dong Cavity Cause Investigation Committee. 2014.
- Kim, J.Y.; Kang, J.M.; Choi, C.H.; Park, D.H. Correlation Analysis of Sewer Integrity and Ground Subsidence. J. Korean Geo-Environ. Soc. 2017, 18, 31–37. [Google Scholar]
- Kuwano, R.; Horii, T.; Kohashi, H.; Yamauchi, K. Defects of sewer pipes causing cave-in’s in the road. In Proceedings of the 5th International Symposium on New Technologies for Urban Safety of Mega Cities in Asia, Phuket, Thailand, 16–17 November 2006; pp. 347–353. [Google Scholar]
- Mukunoki, T.; Kuwano, N.; Otani, J.; Kuwano, R. Visualization of three dimensional failure in sand due to water inflow and soil drainage from defected underground pipe using X-ray CT. Soils Found. 2009, 49, 959–968. [Google Scholar] [CrossRef]
- Masud, M.; Bairagi, A.K.; Nahid, A.A.; Sikder, N.; Rubaiee, S.; Ahmed, A.; Anand, D. A Pneumonia Diagnosis Scheme Based on Hybrid Features Extracted from Chest Radiographs Using an Ensemble Learning Algorithm. J. Healthc. Eng. 2021, 2021, 11. [Google Scholar] [CrossRef] [PubMed]
- Takeuchi, D.; Fukatani, W.; Miyamoto, T.; Yokota, T. Using decision tree analysis to extract factors affecting road subsidence. J. Jpn. Sew. Work. Assoc. 2007, 54, 124–133. [Google Scholar]
- Jin, Y.S. The Analysis on Correlation of Precipitation and Risk Factors to the Soil Subsidence. Ph.D. Dissertation, Chonnam National University, Gwangju, Republic of Korea, 2018; pp. 104–105. [Google Scholar]
- Kim, K.Y. Susceptibility Model for Sinkholes Caused by Damaged Sewer Pipes Based on Logistic Regression. Master’s Thesis, Seoul National University, Seoul, Republic of Korea, 2018. [Google Scholar]
- Han, M.S. A Risk Assessment of Ground Subsidence by GPR and CCTV Investigation. Master’s Thesis, Seoul National University of Science and Technology, Seoul, Republic of Korea, 2017. [Google Scholar]
- Kim, J.Y.; Kang, J.M.; Choi, C.H. Correlation Analysis of the Occurrence of Ground Subsidence According to the Density of Underground Pipelines. J. Korean Geo-Environ. Soc. 2021, 22, 23–29. [Google Scholar]
- Muhammad, F.I.; Ganjar, A.; Muhammad, S.; Rhee, J. Hybrid Prediction Model for Type 2 Diabetes and Hypertension Using DBSCAN-Based Outlier Detection, Synthetic Minority Over Sampling Technique (SMOTE), and Random Forest. Appl. Sci. 2018, 8, 1325. [Google Scholar] [CrossRef]
- Mimi, M.; Matloob, K. SMOTE-ENC: A Novel SMOTE-Based Method to Generate Synthetic Data for Nominal and Continuous Features. Appl. Syst. Innov. 2021, 4, 18. [Google Scholar] [CrossRef]
- Georgios, D.; Fernado, B.; Joao, F.; Manvel, K. Imbalanced Learning in Land Cover Classification: Improving Minority Classes’ Prediction Accuracy Using the Geometric SMOTE Algorithm. Remote Sens. 2019, 11, 3040. [Google Scholar] [CrossRef]
- Lee, S.Y.; Kang, J.M.; Kim, J.Y. Ground Subsidence Risk Grade Prediction Model Based on Machine Learning According to the Underground Facility Properties and Density. J. Korean Geo-Environ. Soc. 2023, 24, 23–29. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.; Olshen, R. Classification and Regression Trees; Taylor & Francis: Abingdon, UK, 1984. [Google Scholar]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Park, E.J.; Park, J.H.; Kim, H.H. Mapping Species-Specific Optimal Plantation Sites Using Random Forest in Gyeongsangnam-do Province, South Korea. J. Agric. Life Sci. 2019, 53, 65–74. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009; p. 745. [Google Scholar]
- Lee, S.H.; Yoon, Y.A.; Jung, J.H.; Sim, H.S.; Chang, T.W.; Kim, Y.S. A Machine Learning Model for Predicting Silica Concentrations through Time Series Analysis of Mining Data. J. Korean Soc. Qual. Manag. 2020, 48, 511–520. [Google Scholar]
- Louppe, G. Understanding Random Forests; University of Liege: Liege, Belgium, 2014; p. 211. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System, KDD’16. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, Y.; Haghani, A. A gradient boosting method to improve travel time prediction. Transportation Research Part C. Emerg. Technol. 2015, 58, 308–324. [Google Scholar] [CrossRef]
- Zhang, D.; Chen, H.D.; Zulfiqar, H.; Yuan, S.S.; Huang, Q.L.; Zhang, Z.Y.; Deng, K.J. iBLP: An XGBoost-Based Predictor for Identifying Bioluminescent Proteins. Comput. Math. Methods Med. 2021, 2021, 15. [Google Scholar] [CrossRef]
- Le NQ, K.; Do, D.T.; Le, Q.A. A sequence-based prediction of Kruppel-like factors proteins using XGBoost and optimized features. Gene 2021, 787, 145643. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T. LightGBM: A Highly Efficient Gradient Boosting Decision Tree, Part of Advances in Neural Information Processing Systems. Adv. Neural Inf. Process. Syst. 2017, 30, 1. [Google Scholar]
- Lv, J.; Wang, C.; Gao, W.; Zhao, Q. An Economic Forecasting Method Based on the LightGBM-Optimized LSTM and Time-Series Model. Comput. Intell. Neurosci. 2021, 2021, 10. [Google Scholar] [CrossRef]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond Accuracy, F-Score and ROC: A Family of Discriminant Measures for Performance Evaluation. In Proceedings of the Advances in Artificial Intelligence (AI 2006) Lecture Notes in Computer Science; Springer: Heidelberg, Germany, 2006; Volume 4304, pp. 1015–1021. [Google Scholar]
- Wang, L.; Chu, F.; Xie, W. Accurate cancer classification using expressions of very few genes. IEEE/ACM Trans. Comput. Biol. Bioinf. 2007, 4, 40–53. [Google Scholar] [CrossRef]
- Gu, Q.; Zhu, L.; Cai, Z. Evaluation measures of the classification performance of imbalanced data sets. In Proceedings of the ISICA 2009—The 4th International Symposium on Computational Intelligence and Intelligent Systems, Communications in Computer and Information Science, Huangshi, China, 23–25 October 2009; Springer: Heidelberg, Germany, 2009; Volume 51, pp. 461–471. [Google Scholar]
- Bekkar, M.; Djemaa, H.K.; Alitouche, T.A. Evaluation measures for models assessment over imbalanced data sets. J. Inf. Eng. Appl. 2013, 3, 27–38. [Google Scholar]
- Akosa, J.S. Predictive accuracy: A misleading performance measure for highly imbalanced data. In Proceedings of the SAS Global Forum 2017 Conference, Orlando, FL, USA, 2–5 April 2017; SAS Institute Inc.: Cary, NC, USA, 2017; pp. 942–2017. [Google Scholar]
- Davide, C.; Giuseppe, J. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar]
- Nguyen, Q.K.L.; Nguyen, T.T.D.; Ou, Y.Y. Identifying the molecular functions of electron transport proteins using radial basis function networks and biochemical properties. J. Mol. Graph. Model. 2017, 73, 166–178. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Unit | Category |
|---|---|---|
| Year (year) | 5 | 1~5, 6~10, 11~15, 16~20, 21~25, 26~30, 31~35, 36~40, 41~45, 46~50 |
| 10 | 1~10, 11~20, 21~30, 31~40, 41~50 | |
| Diameter (mm) | 50 | 1~50, 51~100, 101~150, 151~200, 201~250, 251~300, 301~350, 351~400, 401~450, 451~500, 501~550, 551~600 |
| 100 | 1~100, 101~200, 201~300, 301~400, 401~500, 501~600 | |
| Risk level (Sum of occurrences of ground subsidence in grid) | 1 | 0 |
| 2 | 1, 1~2, 1~3 | |
| 3 | 2~, 3~, 4~ |
| No. | Grid | Year (Year) | Diameter (mm) | Risk Level (Level 2′s Range) |
|---|---|---|---|---|
| 1 | 500 m × 500 m | 5 | 50 | 3 (1) |
| 2 | 3 (1–2) | |||
| 3 | 3 (1–3) | |||
| 4 | 100 | 3 (1) | ||
| 5 | 3 (1–2) | |||
| 6 | 3 (1–3) | |||
| 7 | 10 | 50 | 3 (1) | |
| 8 | 3 (1–2) | |||
| 9 | 3 (1–3) | |||
| 10 | 100 | 3 (1) | ||
| 11 | 3 (1–2) | |||
| 12 | 3 (1–3) |
| Risk Level | 1 | 2 | 3 | |
|---|---|---|---|---|
| Range of Risk Level 2 | ||||
| 1 | 1374 (57%) | 348 (15%) | 669 (28%) | |
| 1–2 | 1374 (57%) | 635 (27%) | 382 (16%) | |
| 1–3 | 1374 (57%) | 706 (30%) | 311 (13%) | |
| Model No. | 1 | 2 | 3 | |||
| Factor | Corr | p-Value | Corr | p-Value | Corr | p-Value |
| 5Y_5 | −0.138 | 0.000 | −0.149 | 0.000 | −0.150 | 0.000 |
| 5Y_10 | −0.108 | 0.000 | −0.098 | 0.000 | −0.096 | 0.000 |
| 5Y_15 | −0.004 | 0.858 | −0.007 | 0.724 | −0.049 | 0.017 |
| 5Y_20 | −0.141 | 0.000 | −0.178 | 0.000 | −0.171 | 0.000 |
| 5Y_25 | −0.108 | 0.000 | −0.161 | 0.000 | −0.154 | 0.000 |
| 5Y_30 | −0.065 | 0.002 | −0.099 | 0.000 | −0.106 | 0.000 |
| 5Y_35 | −0.150 | 0.000 | −0.165 | 0.000 | −0.173 | 0.000 |
| 5Y_40 | −0.150 | 0.000 | −0.169 | 0.000 | −0.168 | 0.000 |
| 5Y_45 | −0.167 | 0.000 | −0.187 | 0.000 | −0.167 | 0.000 |
| 5Y_50 | −0.135 | 0.000 | −0.134 | 0.000 | −0.144 | 0.000 |
| 50DTR_50 | 0.057 | 0.005 | 0.061 | 0.003 | 0.064 | 0.002 |
| 50DTR_100 | 0.146 | 0.000 | 0.147 | 0.000 | 0.148 | 0.000 |
| 50DTR_150 | 0.159 | 0.000 | 0.163 | 0.000 | 0.169 | 0.000 |
| 50DTR_200 | 0.117 | 0.000 | 0.116 | 0.000 | 0.112 | 0.000 |
| 50DTR_250 | 0.015 | 0.478 | 0.008 | 0.698 | 0.013 | 0.522 |
| 50DTR_300 | 0.153 | 0.000 | 0.155 | 0.000 | 0.158 | 0.000 |
| 50DTR_350 | 0.038 | 0.067 | 0.026 | 0.198 | 0.022 | 0.274 |
| 50DTR_400 | 0.059 | 0.004 | 0.062 | 0.002 | 0.059 | 0.004 |
| 50DTR_450 | 0.099 | 0.000 | 0.109 | 0.000 | 0.107 | 0.000 |
| 50DTR_500 | 0.043 | 0.035 | 0.044 | 0.032 | 0.052 | 0.011 |
| 50DTR_550 | 0.014 | 0.494 | −0.006 | 0.783 | −0.003 | 0.895 |
| 50DTR_600 | 0.082 | 0.000 | 0.090 | 0.000 | 0.089 | 0.000 |
| Density | 0.544 | 0.000 | 0.534 | 0.000 | 0.526 | 0.000 |
| Model No. | 4 | 5 | 6 | |||
| Factor | Corr | p-Value | Corr | p-Value | Corr | p-Value |
| 5Y_5 | −0.138 | 0.000 | −0.149 | 0.000 | −0.150 | 0.000 |
| 5Y_10 | −0.108 | 0.000 | −0.098 | 0.000 | −0.096 | 0.000 |
| 5Y_15 | −0.004 | 0.858 | −0.007 | 0.724 | −0.049 | 0.017 |
| 5Y_20 | −0.141 | 0.000 | −0.178 | 0.000 | −0.171 | 0.000 |
| 5Y_25 | −0.108 | 0.000 | −0.161 | 0.000 | −0.154 | 0.000 |
| 5Y_30 | −0.065 | 0.002 | −0.099 | 0.000 | −0.106 | 0.000 |
| 5Y_35 | −0.150 | 0.000 | −0.165 | 0.000 | −0.173 | 0.000 |
| 5Y_40 | −0.150 | 0.000 | −0.169 | 0.000 | −0.168 | 0.000 |
| 5Y_45 | −0.167 | 0.000 | −0.187 | 0.000 | −0.167 | 0.000 |
| 5Y_50 | −0.135 | 0.000 | −0.134 | 0.000 | −0.144 | 0.000 |
| 100DTR_100 | 0.131 | 0.000 | 0.134 | 0.000 | 0.136 | 0.000 |
| 100DTR_200 | 0.152 | 0.000 | 0.154 | 0.000 | 0.155 | 0.000 |
| 100DTR_300 | 0.128 | 0.000 | 0.127 | 0.000 | 0.132 | 0.000 |
| 100DTR_400 | 0.067 | 0.001 | 0.064 | 0.002 | 0.060 | 0.004 |
| 100DTR_500 | 0.103 | 0.000 | 0.111 | 0.000 | 0.113 | 0.000 |
| 100DTR_600 | 0.083 | 0.000 | 0.089 | 0.000 | 0.088 | 0.000 |
| Density | 0.544 | 0.000 | 0.534 | 0.000 | 0.526 | 0.000 |
| Model No. | 7 | 8 | 9 | |||
| Factor | Corr | p-Value | Corr | p-Value | Corr | p-Value |
| 10Y_10 | 0.085 | 0.000 | 0.077 | 0.000 | 0.071 | 0.000 |
| 10Y_20 | 0.123 | 0.000 | 0.126 | 0.000 | 0.131 | 0.000 |
| 10Y_30 | 0.150 | 0.000 | 0.156 | 0.000 | 0.159 | 0.000 |
| 10Y_40 | 0.108 | 0.000 | 0.113 | 0.000 | 0.116 | 0.000 |
| 10Y_50 | 0.107 | 0.000 | 0.117 | 0.000 | 0.118 | 0.000 |
| 50DTR_50 | 0.057 | 0.005 | 0.061 | 0.003 | 0.064 | 0.002 |
| 50DTR_100 | 0.146 | 0.000 | 0.147 | 0.000 | 0.148 | 0.000 |
| 50DTR_150 | 0.159 | 0.000 | 0.163 | 0.000 | 0.169 | 0.000 |
| 50DTR_200 | 0.117 | 0.000 | 0.116 | 0.000 | 0.112 | 0.000 |
| 50DTR_250 | 0.015 | 0.478 | 0.008 | 0.698 | 0.013 | 0.522 |
| 50DTR_300 | 0.153 | 0.000 | 0.155 | 0.000 | 0.158 | 0.000 |
| 50DTR_350 | 0.038 | 0.067 | 0.026 | 0.198 | 0.022 | 0.274 |
| 50DTR_400 | 0.059 | 0.004 | 0.062 | 0.002 | 0.059 | 0.004 |
| 50DTR_450 | 0.099 | 0.000 | 0.109 | 0.000 | 0.107 | 0.000 |
| 50DTR_500 | 0.043 | 0.035 | 0.044 | 0.032 | 0.052 | 0.011 |
| 50DTR_550 | 0.014 | 0.494 | −0.006 | 0.783 | −0.003 | 0.895 |
| 50DTR_600 | 0.082 | 0.000 | 0.090 | 0.000 | 0.089 | 0.000 |
| Density | 0.544 | 0.000 | 0.534 | 0.000 | 0.526 | 0.000 |
| Model No. | 10 | 11 | 12 | |||
| Factor | Corr | p-Value | Corr | p-Value | Corr | p-Value |
| 10Y_10 | 0.085 | 0.000 | 0.077 | 0.000 | 0.071 | 0.000 |
| 10Y_20 | 0.123 | 0.000 | 0.126 | 0.000 | 0.131 | 0.000 |
| 10Y_30 | 0.150 | 0.000 | 0.156 | 0.000 | 0.159 | 0.000 |
| 10Y_40 | 0.108 | 0.000 | 0.113 | 0.000 | 0.116 | 0.000 |
| 10Y_50 | 0.107 | 0.000 | 0.117 | 0.000 | 0.118 | 0.000 |
| 100DTR_100 | 0.131 | 0.000 | 0.134 | 0.000 | 0.136 | 0.000 |
| 100DTR_200 | 0.152 | 0.000 | 0.154 | 0.000 | 0.155 | 0.000 |
| 100DTR_300 | 0.128 | 0.000 | 0.127 | 0.000 | 0.132 | 0.000 |
| 100DTR_400 | 0.067 | 0.001 | 0.064 | 0.002 | 0.060 | 0.004 |
| 100DTR_500 | 0.103 | 0.000 | 0.111 | 0.000 | 0.113 | 0.000 |
| 100DTR_600 | 0.083 | 0.000 | 0.089 | 0.000 | 0.088 | 0.000 |
| Density | 0.544 | 0.000 | 0.534 | 0.000 | 0.526 | 0.000 |
| Model | RF | XGB | LGBM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. | Train Score | Test Score | F1-Score (Macro) | AUC (Macro) | Train Score | Test Score | F1-Score (Macro) | AUC (Macro) | Train Score | Test Score | F1-Score (Macro) | AUC (Macro) |
| 1 | 0.742 | 0.670 | 0.450 | 0.780 | 0.725 | 0.668 | 0.480 | 0.770 | 0.765 | 0.676 | 0.480 | 0.800 |
| 2 | 0.766 | 0.645 | 0.500 | 0.800 | 0.719 | 0.628 | 0.490 | 0.790 | 0.714 | 0.666 | 0.550 | 0.800 |
| 3 | 0.745 | 0.649 | 0.490 | 0.810 | 0.768 | 0.660 | 0.560 | 0.800 | 0.759 | 0.643 | 0.560 | 0.810 |
| 4 | 0.791 | 0.676 | 0.470 | 0.780 | 0.724 | 0.674 | 0.490 | 0.770 | 0.763 | 0.670 | 0.480 | 0.790 |
| 5 | 0.764 | 0.664 | 0.530 | 0.800 | 0.719 | 0.628 | 0.500 | 0.790 | 0.758 | 0.660 | 0.550 | 0.810 |
| 6 | 0.751 | 0.664 | 0.520 | 0.810 | 0.732 | 0.658 | 0.550 | 0.810 | 0.768 | 0.666 | 0.570 | 0.820 |
| 7 | 0.736 | 0.639 | 0.420 | 0.750 | 0.696 | 0.641 | 0.410 | 0.750 | 0.714 | 0.645 | 0.440 | 0.750 |
| 8 | 0.681 | 0.591 | 0.310 | 0.750 | 0.694 | 0.601 | 0.390 | 0.750 | 0.655 | 0.591 | 0.360 | 0.760 |
| 9 | 0.732 | 0.635 | 0.390 | 0.770 | 0.680 | 0.620 | 0.410 | 0.770 | 0.715 | 0.616 | 0.410 | 0.770 |
| 10 | 0.729 | 0.643 | 0.430 | 0.740 | 0.697 | 0.647 | 0.420 | 0.740 | 0.715 | 0.635 | 0.420 | 0.750 |
| 11 | 0.651 | 0.597 | 0.330 | 0.750 | 0.686 | 0.599 | 0.380 | 0.740 | 0.681 | 0.603 | 0.360 | 0.750 |
| 12 | 0.729 | 0.635 | 0.400 | 0.770 | 0.683 | 0.599 | 0.350 | 0.760 | 0.706 | 0.610 | 0.350 | 0.760 |
| Model | RF | XGB | LGBM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. | Train Score | Test Score | F1-Score (Macro) | AUC (Macro) | Train Score | Test Score | F1-Score (Macro) | AUC (Macro) | Train Score | Test Score | F1-Score (Macro) | AUC (Macro) |
| 1 | 0.676 | 0.626 | 0.560 | 0.790 | 0.648 | 0.608 | 0.560 | 0.770 | 0.716 | 0.628 | 0.560 | 0.790 |
| 2 | 0.683 | 0.593 | 0.550 | 0.790 | 0.705 | 0.608 | 0.580 | 0.800 | 0.656 | 0.593 | 0.560 | 0.800 |
| 3 | 0.718 | 0.608 | 0.550 | 0.790 | 0.744 | 0.644 | 0.590 | 0.800 | 0.706 | 0.620 | 0.570 | 0.810 |
| 4 | 0.662 | 0.624 | 0.560 | 0.790 | 0.679 | 0.585 | 0.510 | 0.770 | 0.656 | 0.582 | 0.520 | 0.790 |
| 5 | 0.687 | 0.595 | 0.560 | 0.800 | 0.666 | 0.587 | 0.550 | 0.790 | 0.690 | 0.597 | 0.550 | 0.800 |
| 6 | 0.699 | 0.585 | 0.540 | 0.800 | 0.712 | 0.612 | 0.560 | 0.800 | 0.729 | 0.624 | 0.570 | 0.820 |
| 7 | 0.671 | 0.603 | 0.530 | 0.760 | 0.655 | 0.580 | 0.520 | 0.770 | 0.668 | 0.580 | 0.520 | 0.770 |
| 8 | 0.645 | 0.543 | 0.460 | 0.750 | 0.615 | 0.553 | 0.500 | 0.740 | 0.655 | 0.545 | 0.490 | 0.750 |
| 9 | 0.632 | 0.501 | 0.380 | 0.740 | 0.628 | 0.553 | 0.490 | 0.770 | 0.627 | 0.551 | 0.490 | 0.760 |
| 10 | 0.682 | 0.597 | 0.520 | 0.770 | 0.660 | 0.578 | 0.520 | 0.760 | 0.669 | 0.578 | 0.510 | 0.770 |
| 11 | 0.608 | 0.541 | 0.450 | 0.750 | 0.647 | 0.555 | 0.490 | 0.740 | 0.651 | 0.570 | 0.500 | 0.750 |
| 12 | 0.636 | 0.511 | 0.390 | 0.750 | 0.615 | 0.532 | 0.460 | 0.760 | 0.676 | 0.568 | 0.490 | 0.750 |
| Model | Hyper Parameter |
|---|---|
| XGB | Estimators (300), learning rate (0.002), max depth (4) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Kang, J.; Kim, J. Prediction Modeling of Ground Subsidence Risk Based on Machine Learning Using the Attribute Information of Underground Utilities in Urban Areas in Korea. Appl. Sci. 2023, 13, 5566. https://doi.org/10.3390/app13095566
Lee S, Kang J, Kim J. Prediction Modeling of Ground Subsidence Risk Based on Machine Learning Using the Attribute Information of Underground Utilities in Urban Areas in Korea. Applied Sciences. 2023; 13(9):5566. https://doi.org/10.3390/app13095566
Chicago/Turabian StyleLee, Sungyeol, Jaemo Kang, and Jinyoung Kim. 2023. "Prediction Modeling of Ground Subsidence Risk Based on Machine Learning Using the Attribute Information of Underground Utilities in Urban Areas in Korea" Applied Sciences 13, no. 9: 5566. https://doi.org/10.3390/app13095566