
A Robust Deep Learning-Based Damage Identification Approach for SHM Considering Missing Data


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methodology
2.1. Conventional Deep Neural Network and Dropout Mechanism
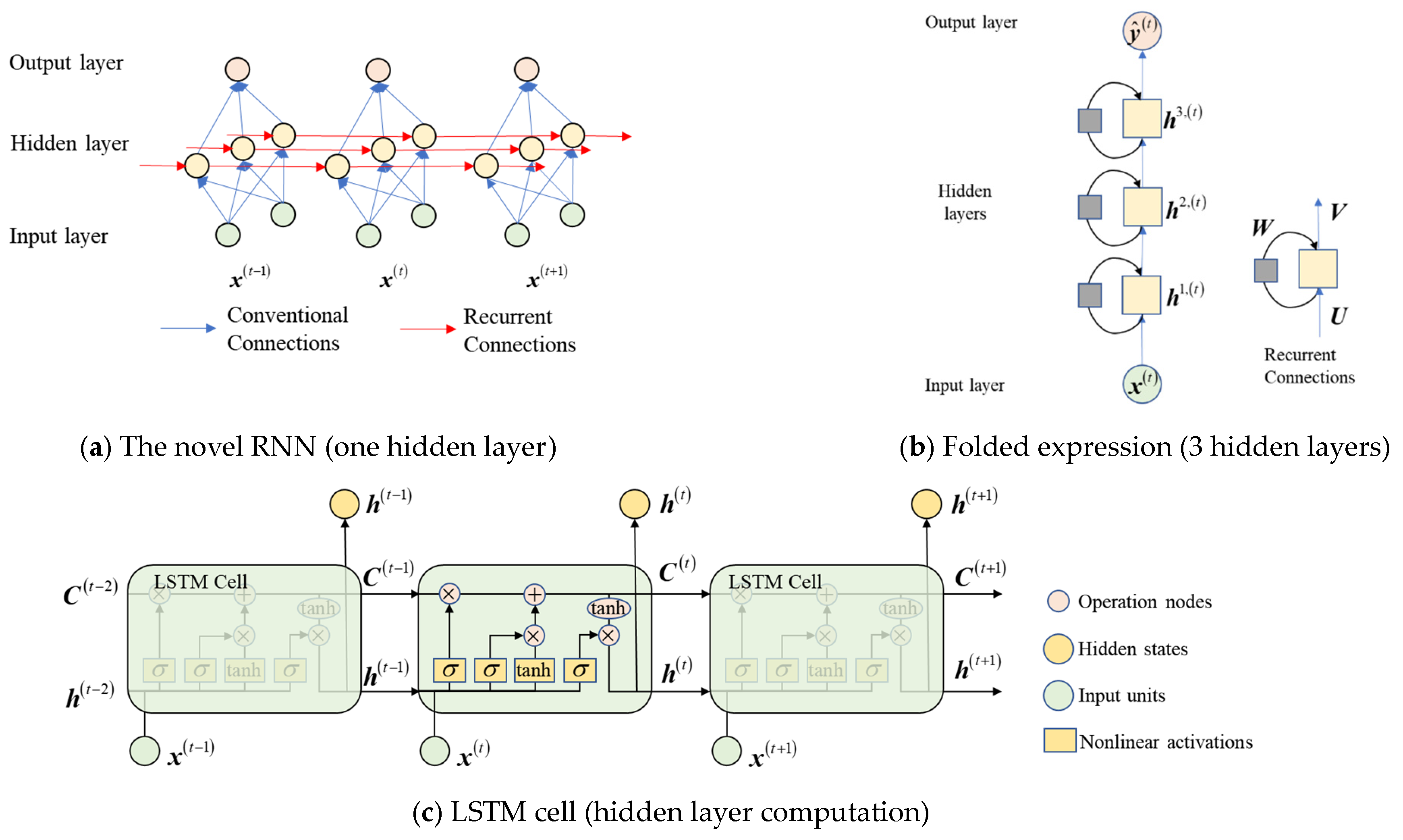
2.2. LSTM: Long-Short-Term Memory
2.3. AE: Autoencoder
2.4. The Robust Damage Identification Model Based on LSTM
3. Case Study
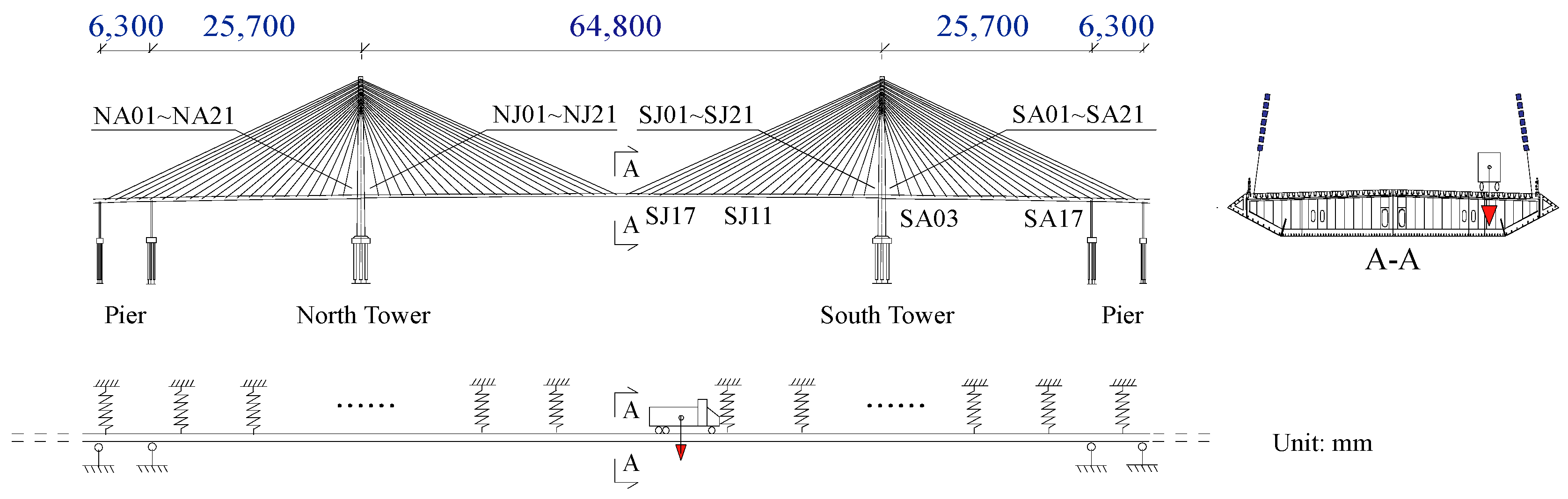
3.1. Dataset
3.2. Preprocessing
3.3. Implementation Details
| Algorithm 1: LSTM-structured autoencoder training |
| 1. Initialize parameters ; |
| 2. Specifies batch_size, the length of the input T, learning rate ; |
| 3. For |
| 4. Randomly generates batch_size integers from ; |
| 5. Generates normalized training set , , randomly sets dimensions in to 0 to obtain ; |
| 6. Updating model parameters using AdamOptimizer. |
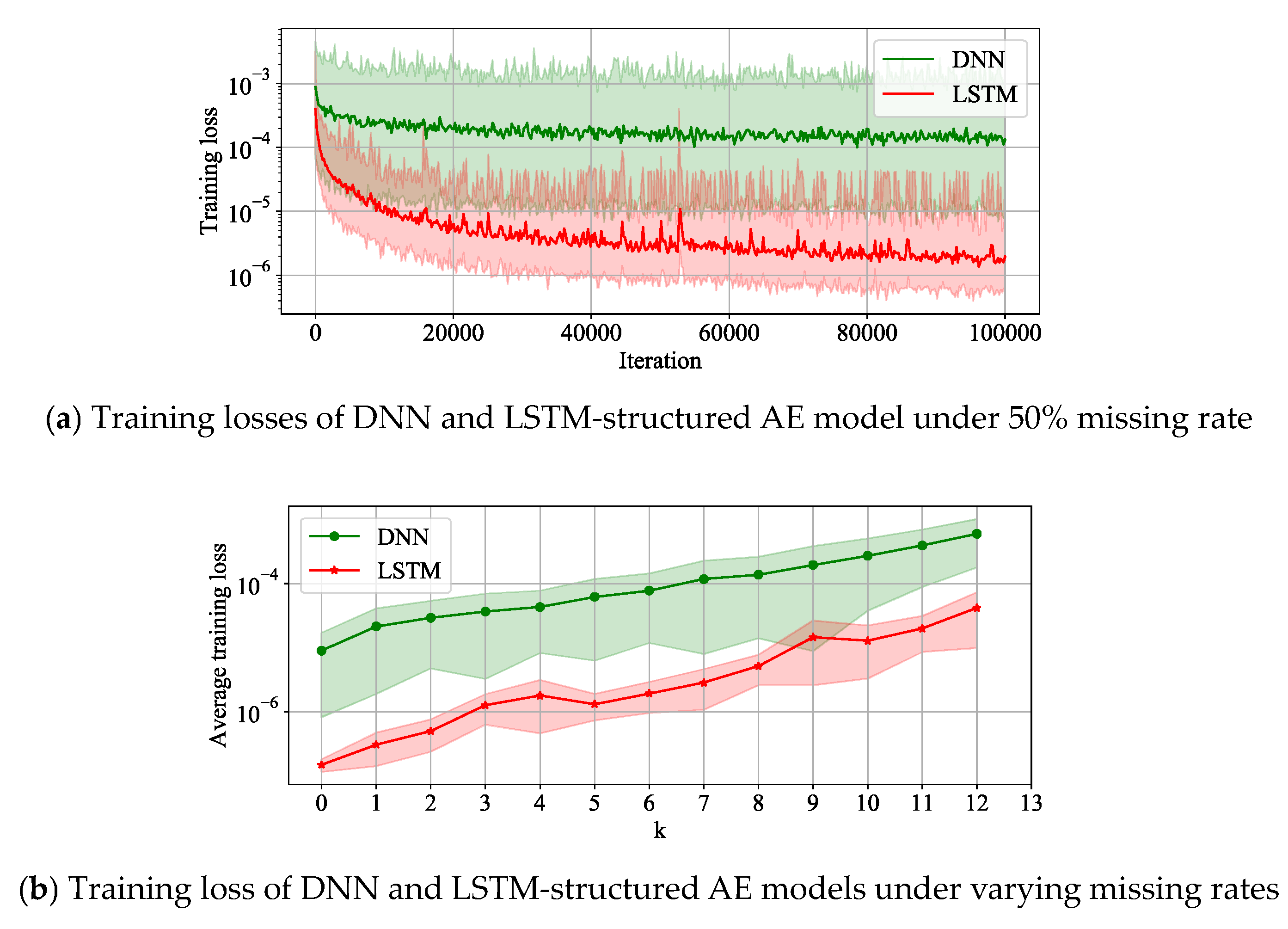
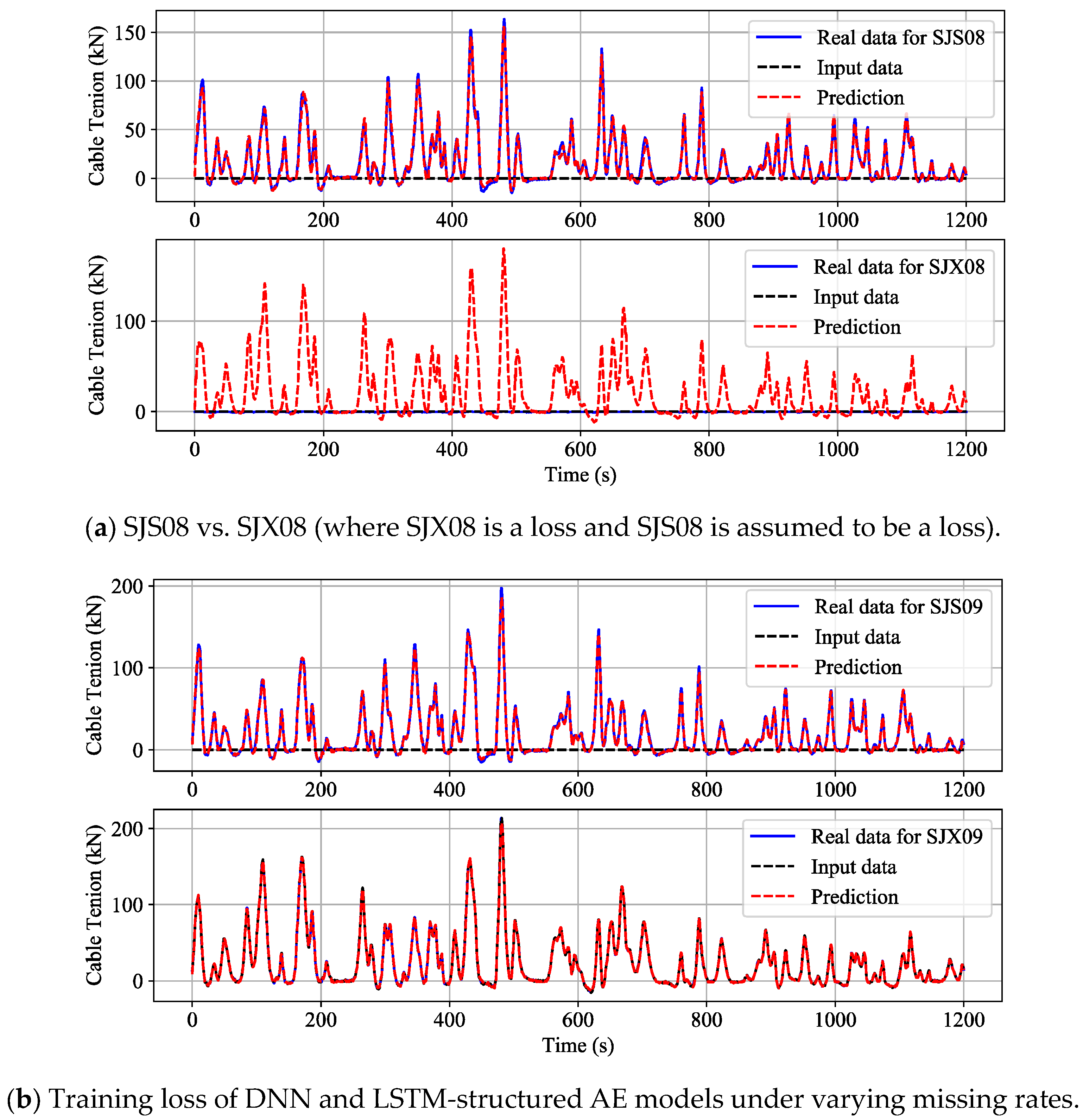
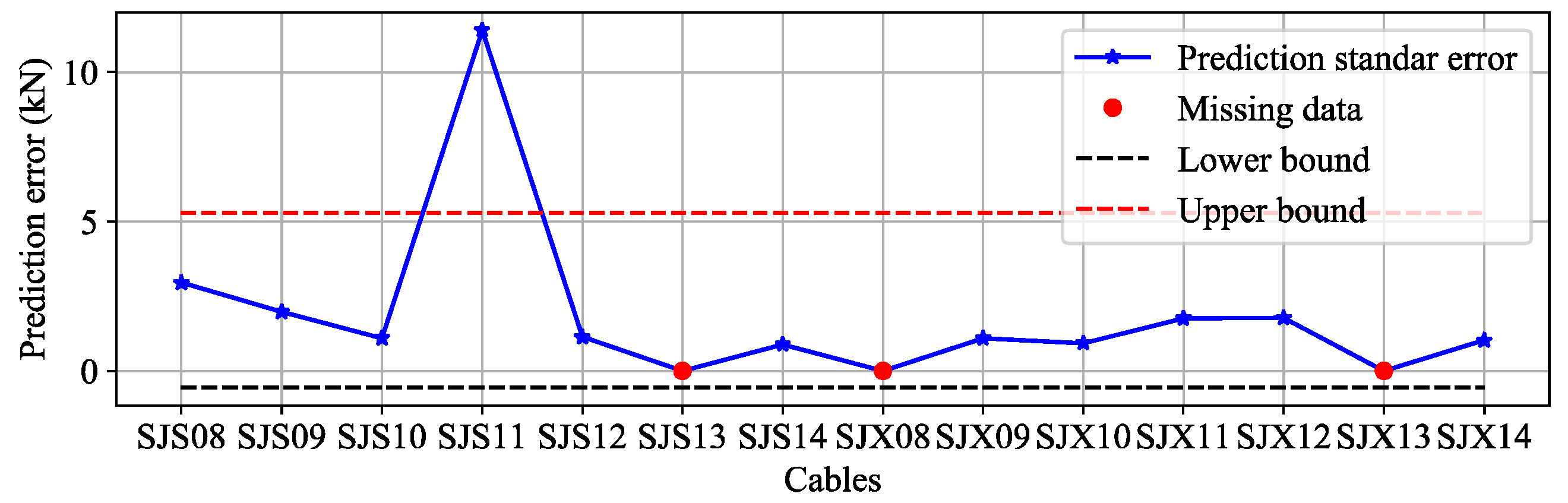
3.4. Results
4. Conclusions
5. Discussions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| List of symbols | |||
| Inputs of the model | Nonlinear activation function | ||
| Targets of the model | Tanh-formed activation function | ||
| Outputs of the model | Hidden state of the l-th layer | ||
| Number of layers (Depth) | Nonlinear mapping function/model | ||
| Loss function | Inputs at t step in LSTM | ||
| Weights of the l-th layer | Short memory state at t step in LSTM | ||
| Bias of the l-th layer | Long memory state at t step in LSTM | ||
| Weights for states of forget/input/output gate and state update in LSTM | |||
| Weights for inputs of forget/input/output gate and state update in LSTM | |||
| Bias of forget/input/output gate and state update in LSTM | |||
| Forget gate, input gate, and output gate | |||
| Parameter set of weights and bias for a neural network model | |||
| Encoder and Decoder in the Autoencoder frame | |||
References
- Brownjohn, J.M.W.; De Stefano, A.; Xu, Y.L.; Wenzel, H.; Aktan, A.E. Vibration-Based monitoring of civil infrastructure: Challenges and successes. J. Civ. Struct. Health Monit. 2011, 1, 79–95. [Google Scholar] [CrossRef]
- Ni, Y.Q.; Xia, H.W.; Wong, K.Y.; Ko, J.M. In-Service Condition Assessment of Bridge Deck Using Long-Term Monitoring Data of Strain Response. J. Bridg. Eng. 2012, 17, 876–885. [Google Scholar] [CrossRef]
- Yang, Y.; Sanchez, L.; Zhang, H.; Roeder, A.; Bowlan, J.; Crochet, J.; Farrar, C.; Mascareñas, D. Estimation of full-field, full-order experimental modal model of cable vibration from digital video measurements with physics-guided unsupervised machine learning and computer vision. Struct. Control Health Monit. 2019, 26, e2358. [Google Scholar] [CrossRef]
- Camassa, D.; Vaiana, N.; Castellano, A. Modal Testing of Masonry Constructions by Ground-Based Radar Interferometry for Structural Health Monitoring: A Mini Review. Front. Built Environ. 2023, 8, 302. [Google Scholar] [CrossRef]
- Ramos, L.F.; Marques, L.; Lourenço, P.B.; De Roeck, G.; Campos-Costa, A.; Roque, J. Monitoring historical masonry structures with operational modal analysis: Two case studies. Mech. Syst. Signal Process. 2010, 24, 1291–1305. [Google Scholar] [CrossRef]
- Gentile, C.; Saisi, A. Ambient vibration testing of historic masonry towers for structural identification and damage assessment. Constr. Build. Mater. 2007, 21, 1311–1321. [Google Scholar] [CrossRef]
- Klun, M.; Kryžanowski, A. Dynamic monitoring as a part of structural health monitoring of dams. Arch. Civ. Eng. 2022, 68, 569–578. [Google Scholar]
- Xiang, Z.-Q.; Pan, J.-W.; Wang, J.-T.; Chi, F.-D. Improved approach for vibration-based structural health monitoring of arch dams during seismic events and normal operation. Struct. Control Health Monit. 2022, 29, e2955. [Google Scholar]
- Li, Y.; Bao, T.; Gao, Z.; Shu, X.; Zhang, K.; Xie, L.; Zhang, Z. A new dam structural response estimation paradigm powered by deep learning and transfer learning techniques. Struct. Health Monit. 2022, 21, 770–787. [Google Scholar] [CrossRef]
- Farrar, C.R.; Worden, K. An introduction to structural health monitoring. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2007, 365, 303–315. [Google Scholar] [CrossRef]
- Lynch, J.P. An overview of wireless structural health monitoring for civil structures. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2007, 365, 345–372. [Google Scholar] [CrossRef] [PubMed]
- Brownjohn, J.M.W. Structural health monitoring of civil infrastructure. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2007, 365, 589–622. [Google Scholar] [CrossRef] [PubMed]
- Bao, Y.; Chen, Z.; Wei, S.; Xu, Y.; Tang, Z.; Li, H. The State of the Art of Data Science and Engineering in Structural Health Monitoring. Engineering 2019, 5, 234–242. [Google Scholar] [CrossRef]
- Zhao, J.; Bao, Y.; Guan, Z.; Zuo, W.; Li, J.; Li, H. Video-Based multiscale identification approach for tower vibration of a cable-stayed bridge model under earthquake ground motions. Struct. Control Health Monit. 2019, 26, e2314. [Google Scholar] [CrossRef]
- Zhou, W.; Li, H.; Yuan, F.G. Guided wave generation, sensing and damage detection using in-plane shear piezoelectric wafers. Smart Mater. Struct. 2014, 23, 15014. [Google Scholar] [CrossRef]
- Farrar, C.R.; Duffey, T.A.; Doebling, S.W.; Nix, D.A. A Statistical Pattern Recognition Paradigm for Vibration-Based Structural Health Monitoring. In Proceedings of the 2nd International Workshop on Structural Health Monitoring, Standford, CA, USA, 10–12 September 2019; pp. 10–20. [Google Scholar]
- Khan, A.T.; Li, S.; Zhang, Y.; Stanimirovic, P.S. Eagle perching optimizer for the online solution of constrained optimization. Mem.-Mater. Devices Circuits Syst. 2023, 4, 100021. [Google Scholar] [CrossRef]
- Khan, A.T.; Cao, X.; Li, S.; Hu, B.; Katsikis, V.N. Quantum beetle antennae search: A novel technique for the constrained portfolio optimization problem. Sci. China Inf. Sci. 2021, 64, 1–14. [Google Scholar] [CrossRef]
- Khan, A.T.; Cao, X.; Li, Z.; Li, S. Enhanced beetle antennae search with zeroing neural network for online solution of constrained optimization. Neurocomputing 2021, 447, 294–306. [Google Scholar] [CrossRef]
- Worden, K.; Staszewski, W.J.; Hensman, J.J. Natural computing for mechanical systems research: A tutorial overview. Mech. Syst. Signal Process. 2011, 25, 4–111. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Ou, J.P. The state of the art in structural health monitoring of cable-stayed bridges. J. Civ. Struct. Health Monit. 2016, 6, 43–67. [Google Scholar] [CrossRef]
- Sun, L.M.; Shang, Z.Q.; Xia, Y.; Bhowmick, S.; Nagarajaiah, S. Review of Bridge Structural Health Monitoring Aided by Big Data and Artificial Intelligence: From Condition Assessment to Damage Detection. J. Struct. Eng. 2020, 146, 04020073. [Google Scholar] [CrossRef]
- Bao, Y.; Li, H. Machine learning paradigm for structural health monitoring. Struct. Health Monit. 2021, 20, 1353–1372. [Google Scholar] [CrossRef]
- Farrar, C.R.; Worden, K. Structural Health Monitoring: A Machine Learning Perspective; John Wiley & Sons, Ltd.: Chichester, UK, 2012. [Google Scholar]
- Wickramarachchi, C.T.; Brennan, D.S.; Lin, W.; Maguire, E.; Harvey, D.Y.; Cross, E.J.; Worden, K. Towards Population-Based Structural Health Monitoring, Part V: Networks and Databases. In Data Science in Engineering; Springer: Berlin/Heidelberg, Germany, 2022; Volume 9, pp. 1–8. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Bao, Y.Q.; Tang, Z.Y.; Li, H.; Zhang, Y.F. Computer vision and deep learning–based data anomaly detection method for structural health monitoring. Struct. Health Monit. 2019, 18, 401–421. [Google Scholar] [CrossRef]
- Yang, Z.; Jerath, K. Observability Variation in Emergent Dynamics: A Study using Krylov Subspace-based Model Order Reduction. In Proceedings of the 2020 American Control Conference (ACC), Denver, CO, USA, 1–3 July 2020; pp. 3461–3466. [Google Scholar]
- Yang, Z.; Haeri, H.; Jerath, K. Renormalization Group Approach to Cellular Automata-Based Multi-Scale Modeling of Traffic Flow. In Proceedings of the Unifying Themes in Complex Systems X: The Tenth International Conference on Complex Systems, Nashua, NH, USA, 26–31 July 2021; pp. 17–27. [Google Scholar]
- Guo, Z.; Wan, Y.; Ye, H. A data imputation method for multivariate time series based on generative adversarial network. Neurocomputing 2019, 360, 185–197. [Google Scholar] [CrossRef]
- Cao, W.; Wang, D.; Li, J.; Zhou, H.; Li, L.; Li, Y. Brits: Bidirectional Recurrent Imputation for Time Series; Curran Associates Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Hong, C.; Yu, J.; Wan, J.; Tao, D.; Wang, M. Multimodal Deep Autoencoder for Human Pose Recovery. IEEE Trans. Image Process. 2015, 24, 5659–5670. [Google Scholar] [CrossRef]
- Jaques, N.; Taylor, S.; Sano, A.; Picard, R. Multimodal autoencoder: A deep learning approach to filling in missing sensor data and enabling better mood prediction. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 202–208. [Google Scholar]
- Tang, Z.; Bao, Y.; Li, H. Group sparsity-aware convolutional neural network for continuous missing data recovery of structural health monitoring. Struct. Health Monit. 2021, 20, 1738–1759. [Google Scholar] [CrossRef]
- Fang, C.; Wang, C. Time series data imputation: A survey on deep learning approaches. arXiv 2020, arXiv:2011.11347. [Google Scholar]
- Chen, Z.; Lei, X.; Bao, Y.; Deng, F.; Zhang, Y.; Li, H. Uncertainty quantification for the distribution-to-warping function regression method used in distribution reconstruction of missing structural health monitoring data. Struct. Health Monit. 2021, 20, 3436–3452. [Google Scholar] [CrossRef]
- Bao, Y.; Li, J.; Nagayama, T.; Xu, Y.; Spencer, B.F., Jr.; Li, H. The 1st International Project Competition for Structural Health Monitoring (IPC-SHM, 2020): A summary and benchmark problem. Struct. Health Monit. 2021, 20, 2229–2239. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3 April 2017; Volume 2, pp. 427–431. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Liu, Z.; Xu, Z.; Jin, J.; Shen, Z.; Darrell, T. Dropout Reduces Underfitting. arXiv 2023, arXiv:2303.01500. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. Available online: http://arxiv.org/abs/1609.08144 (accessed on 26 September 2016).
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 4, 3104–3112. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial Autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Dysart, J. Deep Learning of Representations for Unsupervised and Transfer Learning Yoshua. Can. Nurse 2008, 104, 4. [Google Scholar]
- Bao, Y.Q.; Shi, Z.Q.; Beck, J.L.; Li, H.; Hou, T.Y. Identification of time-varying cable tension forces based on adaptive sparse time-frequency analysis of cable vibrations. Struct. Control Health Monit. 2017, 24, e1889. [Google Scholar] [CrossRef]
- Li, S.; Zhu, S.; Xu, Y.; Chen, Z.; Li, H. Long-term condition assessment of suspenders under traffic loads based on structural monitoring system: Application to the Tsing Ma Bridge. Struct. Control Health Monit. 2012, 19, 82–101. [Google Scholar] [CrossRef]
- Li, S.L.; Wei, S.Y.; Bao, Y.Q.; Li, H. Condition assessment of cables by pattern recognition of vehicle-induced cable tension ratio. Eng. Struct. 2018, 155, 1–15. [Google Scholar] [CrossRef]
- Wei, S.; Zhang, Z.; Li, S.; Li, H. Strain features and condition assessment of orthotropic steel deck cable-supported bridges subjected to vehicle loads by using dense FBG strain sensors. Smart Mater. Struct. 2017, 26, 104007. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, F.; Tao, X.; Wei, P.; Wei, S. A Robust Deep Learning-Based Damage Identification Approach for SHM Considering Missing Data. Appl. Sci. 2023, 13, 5421. https://doi.org/10.3390/app13095421
Deng F, Tao X, Wei P, Wei S. A Robust Deep Learning-Based Damage Identification Approach for SHM Considering Missing Data. Applied Sciences. 2023; 13(9):5421. https://doi.org/10.3390/app13095421
Chicago/Turabian StyleDeng, Fan, Xiaoming Tao, Pengxiang Wei, and Shiyin Wei. 2023. "A Robust Deep Learning-Based Damage Identification Approach for SHM Considering Missing Data" Applied Sciences 13, no. 9: 5421. https://doi.org/10.3390/app13095421