

Chinese News Text Classification Method via Key Feature Enhancement

Abstract
:Featured Application
Abstract
1. Introduction
- (i)
- A key feature-enhanced Chinese news text classification method is proposed, which can complete data enhancement based on part of the original labeled data and construct a high-quality labeled sample set to solve the problem of large-scale Chinese news text classification;
- (ii)
- We improve the overall classification performance and interpretability of the model through the feature engineering technology with key feature extraction and semantic information expansion and complete the compression of the model size through zero–one binary vector integer quantization technology;
- (iii)
- We discuss the necessity of sampling enhancement in the Chinese news classification task and also provide a simple and efficient solution.
2. Related Work
3. Key Feature-Enhanced Chinese News Text Classification Method
3.1. Data Augmentation
3.1.1. Key Feature Extraction
3.1.2. Key Feature Semantic Extensions
- Step 1: Input a sample whose original text length is less than 300 and initialize an empty semantic extension list SE, then go to Step 2;
- Step 2: Use the key feature extraction algorithm in Section 3.1.1 to extract a list of all key feature words from the original text, then go to Step 3;
- Step 3: Loop through the list of key feature words in Step 2, use each word as a query, input the large-scale word2vec word vector tool that is open source in the literature [21] and call the similar_by_word (query, 5) method to return the current query and the top-five most semantically-relevant feature words and their corresponding semantic similarity dictionary, T, then go to Step 4;
- Step 4: If T is empty, go directly to Step 3 to start the expansion of the next query;
- Step 5: If T is not empty, loop through the dictionary T and then add all the words in T with a semantic similarity value greater than S (in the experiment, S is set to 0.85) into the semantic expansion list SE, then go to Step 3 and start the next query extension;
- Step 6: After traversing all queries, output the SE list as the final semantic extension features list.
3.2. KFE-CNN Text Classification Method
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Hyperparameter Settings for KFE-CNN Models
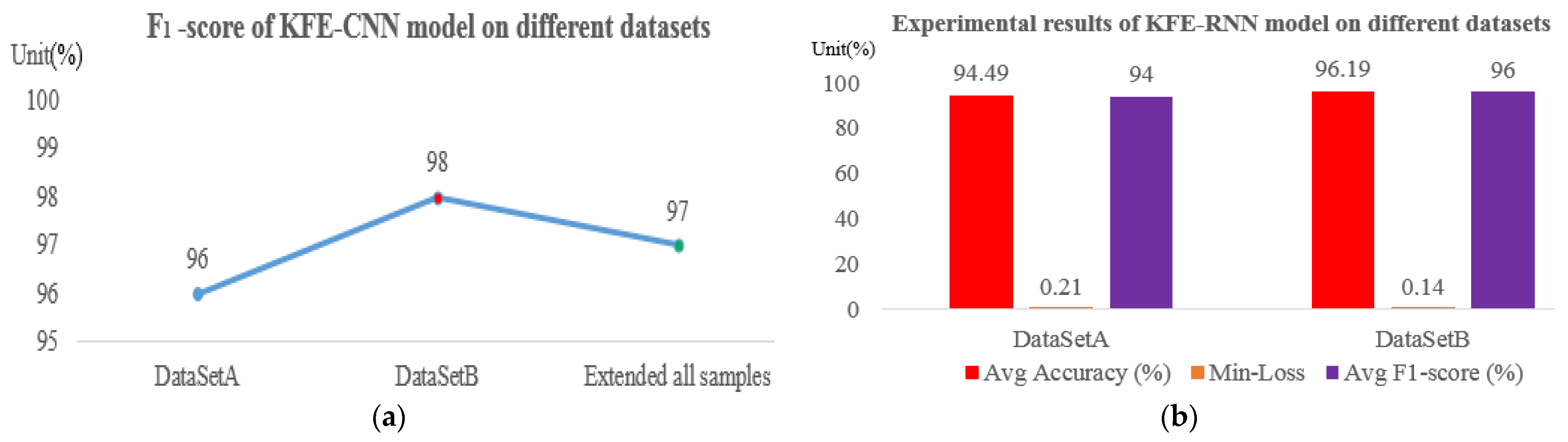
4.4. Experimental Results and Analysis
4.5. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Methods | Large-Scale Manual Annotation Dataset | Pre-Training Language Model | Volume of Model | Classification Performance |
|---|---|---|---|---|
| Traditional classification model (TF-IDF/NB/SVM) | Independency | Not required | Smaller | Relatively low |
| Popular neural network model (FastText/LSTM/RNN/TextGCN/CNN) | Dependency | Generally required | Large | Relatively high |
| Our method | Barely dependent | Not required | Smaller | Relatively high |
References
- Kadhim, A.I. Survey on supervised machine learning techniques for automatic text classification. Artif. Intell. Rev. 2019, 52, 273–292. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning-based text classification: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A survey of the usages of deep learning for natural language processing. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 604–624. [Google Scholar] [CrossRef] [PubMed]
- Deng, X.; Li, Y.; Weng, J.; Zhang, J. Feature selection for text classification: A review. Multimed. Tools Appl. 2019, 78, 3797–3816. [Google Scholar] [CrossRef]
- VM, N.; Kumar, R.D. Implementation on Text Classification Using Bag of Words Model. In Proceedings of the Second International Conference on Emerging Trends in Science & Technologies for Engineering Systems, Sarigam, India, 17–18 May 2019; pp. 241–248. [Google Scholar]
- Samant, S.S.; Murthy, N.B.; Malapati, A. Improving term weighting schemes for short text classification in vector space model. IEEE Access 2019, 7, 166578–166592. [Google Scholar] [CrossRef]
- Hinton, G.E. Learning distributed representations of concepts. In Proceedings of the Eighth Annual Conference of the Cognitive Science Society, Amherst, MA, USA, 15–17 August 1986; pp. 1–12. [Google Scholar]
- Bagui, S.; Nandi, D.; Bagui, S.; White, R.J. Machine learning and deep learning for phishing email classification using one-hot encoding. J. Comput. Sci. 2021, 17, 610–623. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, T.T. GPT: Origin, Theory, Application, and Future. Ph.D. Thesis, University of Pennsylvania, Philadelphia, PA, USA, 2021; pp. 1–51. [Google Scholar]
- Zhao, Y.; Wang, F.; Xia, Y. Short Text Classification Method Based on Support Vector Machine. Comput. Mod. 2022, 2, 92–96. [Google Scholar]
- Le, C.C.; Prasad, P.; Alsadoon, A.; Pham, L.; Elchouemi, A. Text classification: Naïve Bayes classifier with sentiment Lexicon. IAENG Int. J. Comput. Sci. 2019, 46, 141–148. [Google Scholar]
- Yao, T.; Zhai, Z.; Gao, B. Text classification model based on fastText. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Information Systems, Tianjin, China, 28–28 June 2020; pp. 154–157. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Hu, S.; He, C.; Ge, B.; Liu, F. Enhanced Word Embedding Method in Text Classification. In Proceedings of the 2020 6th International Conference on Big Data and Information Analytics, Shenzhen, China, 4–6 December 2020; pp. 18–22. [Google Scholar]
- He, C.H.; Zhang, C.; Hu, S.Z.; Zhu, H.M.; Ge, B. Chinese News Text Classification Algorithm Based on Online Knowledge Extension and Convolutional Neural Network. In Proceedings of the 2019 16th International Computer Conference on Wavelet Active Media Technology and Information Processing, Chengdu, China, 13 December 2019; pp. 204–211. [Google Scholar]
- Bayer, M.; Kaufhold, M.A.; Reuter, C. A survey on data augmentation for text classification. ACM Comput. Surv. 2022, 55, 146. [Google Scholar] [CrossRef]
- Song, Y.; Shi, S.; Li, J.; Zhang, H. Directional Skip-Gram: Explicitly Distinguishing Left and Right Context for Word Embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics: New Orleans, LA, USA, 2018; Volume 2, pp. 175–180. [Google Scholar]
- Jiao, Z.; Sun, S.; Sun, K. Chinese lexical analysis with deep Bi-GRU-CRF network. arXiv 2018, arXiv:1807.01882. [Google Scholar]
- Zhang, Y.; Gong, L.; Wang, Y. An improved TF-IDF approach for text classification. J. Zhejiang Univ.-Sci. A 2005, 6, 49–55. [Google Scholar] [CrossRef]
- Ge, B.; He, C.; Zhang, C.; Hu, Y. Classification Algorithm of Chinese Sentiment Orientation Based on Dictionary and LSTM. In Proceedings of the 2nd International Conference on Big Data Research, Weihai China, 27–29 October 2018; pp. 119–126. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HA, USA, 29–31 January 2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Aljanabi, M.; Ghazi, M.; Ali, A.H.; Abed, S.A. ChatGPT: Open Possibilities. Iraqi J. Comput. Sci. Math. 2023, 4, 62–64. [Google Scholar]





| Dataset | #Training Samples | #Validation Samples | #Test Samples | #Sample Size | #Num_classes |
|---|---|---|---|---|---|
| #DataSetA (Original) | 50,000 (Original) | 5000 (Original) | 10,000 (Original) | 65,000 (Original) | 10 |
| #DataSetB (Enhanced) | 68,259 (Enhanced) | 5000 (Original) | 10,000 (Original) | 83,259 (Enhanced) | 10 |
| Confusion Matrix | System Results | ||
|---|---|---|---|
| Positive (Erroneous) | Negative (Correct) | ||
| Gold Standard | Positive | TP (True Positive) | FN (False Negative) |
| Negative | FP (False Positive) | TN (True Negative) | |
| Parameter Name | Parameter Value | Parameter Name | Parameter Value |
|---|---|---|---|
| Dropout_rate | 0.5 | Optimizer | Adam |
| Embedding_dim | 100 | Seq_length | 1200 |
| Num_filters | 256 | Num_classes | 10 |
| Kernel_size | 5 | Vocab_size | 15,000 |
| Hidden_dim | 128 | Learning_rate | 1 × 10−3 |
| Batch_size | 64 | Num_epochs | 12 |
| Model Name | Avg Accuracy (%) | Min-Loss | Avg F1-Score (%) |
|---|---|---|---|
| TF-IDF [23] | 89.26 | -- | 85 |
| Naive Bayes [14] | 90.13 | -- | 90 |
| SVM [13] | 92.39 | -- | 91 |
| FastText [15] | 92.24 | -- | 92 |
| LSTM [24] | 93.17 | 0.22 | 93 |
| RNN [17] | 94.49 | 0.21 | 94 |
| TextGCN [25] | 92.78 | 0.24 | 92 |
| CNN [16] | 96.26 | 0.13 | 96 |
| Dataset | Classification | Precision (%) | Recall (%) | F1 (%) |
| #DataSetA (Original) CNN | Sports | 99 | 99 | 99 |
| Finance | 95 | 99 | 97 | |
| Real Estate | 100 | 100 | 100 | |
| Home Furnishing | 99 | 87 | 92 | |
| Education | 88 | 95 | 91 | |
| Technology | 94 | 98 | 96 | |
| Fashion | 96 | 97 | 97 | |
| Current Affairs | 97 | 93 | 95 | |
| Games | 98 | 97 | 97 | |
| Entertainment | 98 | 97 | 98 | |
| Num_classes | Avg Accuracy (%) | Min-Loss | Avg F1-score (%) | |
| 10 | 96.26 | 0.13 | 96 | |
| Dataset | Classification | Precision (%) | Recall (%) | F1 (%) |
| #DataSetB (Enhanced) KFE-CNN | Sports | 100 (↑1%) | 100 (↑1%) | 100 (↑1%) |
| Finance | 98 (↑3%) | 99 | 98 (↑1%) | |
| Real Estate | 100 | 100 | 100 | |
| Home Furnishing | 97 (↓2%) | 93 (↑6%) | 95 (↑3%) | |
| Education | 96 (↑8%) | 97 (↑2%) | 96 (↑5%) | |
| Technology | 97 (↑3%) | 98 | 98 (↑2%) | |
| Fashion | 95 (↓2%) | 99 (↑2%) | 97 | |
| Current Affairs | 97 | 97 (↑4%) | 97 (↑2%) | |
| Games | 99 (↑1%) | 98 (↑1%) | 99 (↑2%) | |
| Entertainment | 99 (↑1%) | 98 (↑1%) | 99 (↑1%) | |
| Num_classes | Avg Accuracy (%) | Min-Loss | Avg F1-score (%) | |
| 10 | 97.84 (↑1.58) | 0.074 (↓0.056) | 98 (↑2%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, B.; He, C.; Xu, H.; Wu, J.; Tang, J. Chinese News Text Classification Method via Key Feature Enhancement. Appl. Sci. 2023, 13, 5399. https://doi.org/10.3390/app13095399
Ge B, He C, Xu H, Wu J, Tang J. Chinese News Text Classification Method via Key Feature Enhancement. Applied Sciences. 2023; 13(9):5399. https://doi.org/10.3390/app13095399
Chicago/Turabian StyleGe, Bin, Chunhui He, Hao Xu, Jibing Wu, and Jiuyang Tang. 2023. "Chinese News Text Classification Method via Key Feature Enhancement" Applied Sciences 13, no. 9: 5399. https://doi.org/10.3390/app13095399