
HiTIM: Hierarchical Task Information Mining for Few-Shot Action Recognition

Abstract
:1. Introduction
- We designed to mine the key discriminative information of tasks, generating task-specific features.
- We designed a matching module with , consisting of two branches for STM and CM. These branches mine the key spatiotemporal regions of features and the strongly correlated parts between features, with the shared further optimizing both branches.
- We propose an end-to-end few-shot action recognition method named HiTIM, which can use either a 2D convolutional neural network (CNN) or 3D CNN as embedding. In experiments involving the UCF101, HMDB51, and Kinetics datasets, HiTIM achieved recognition accuracy that outperformed or was comparable to other SOTA few-shot action recognition methods on five-way one-shot and five-way five-shot tasks.
2. Related Work
2.1. Few-Shot Learning
2.2. Few-Shot Action Recognition
2.3. Dynamic Network
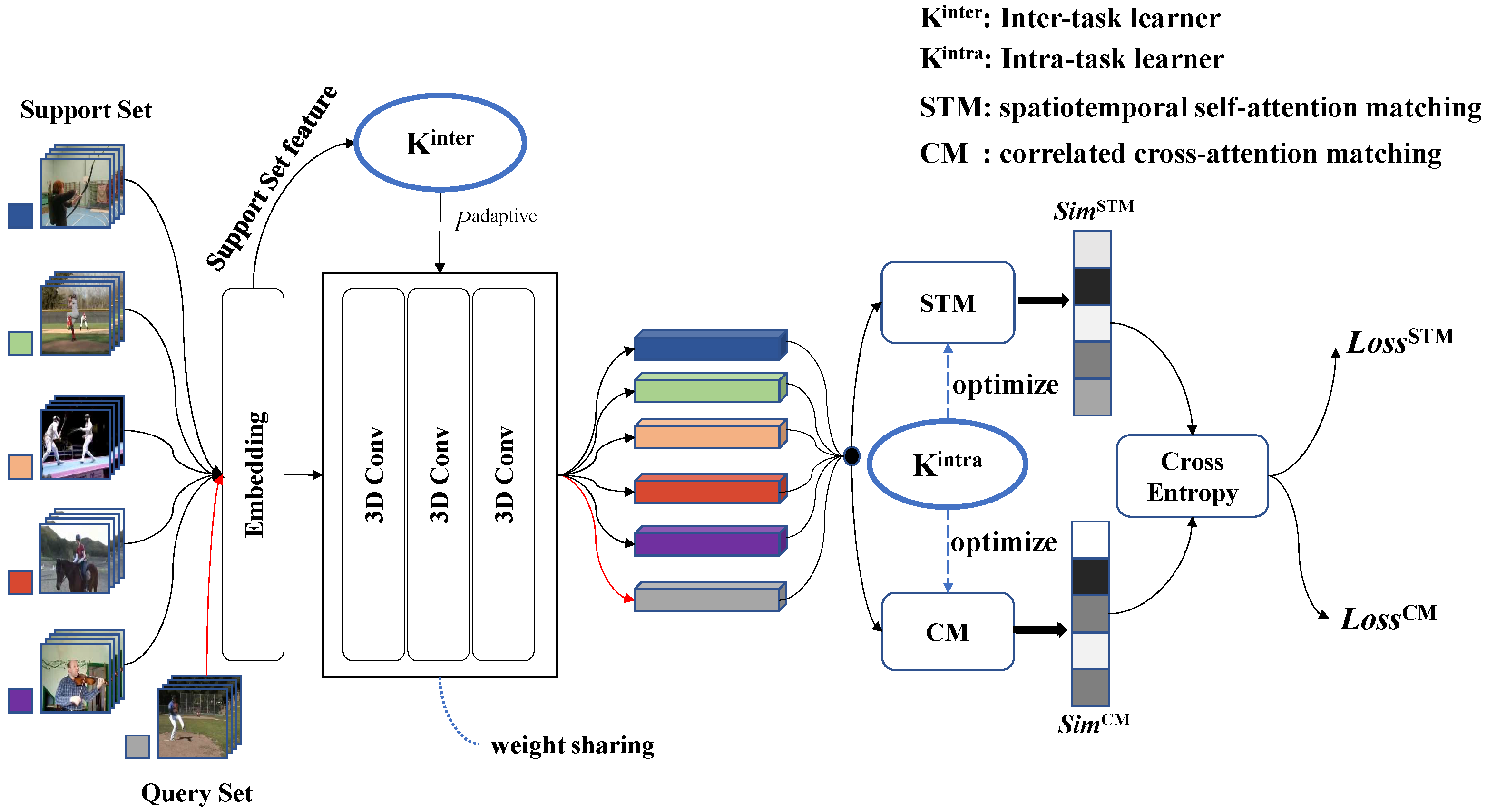
3. Method
3.1. Problem Definition
3.2. HiTIM
3.2.1. Inter-Task Learner
3.2.2. Intra-Task Learner
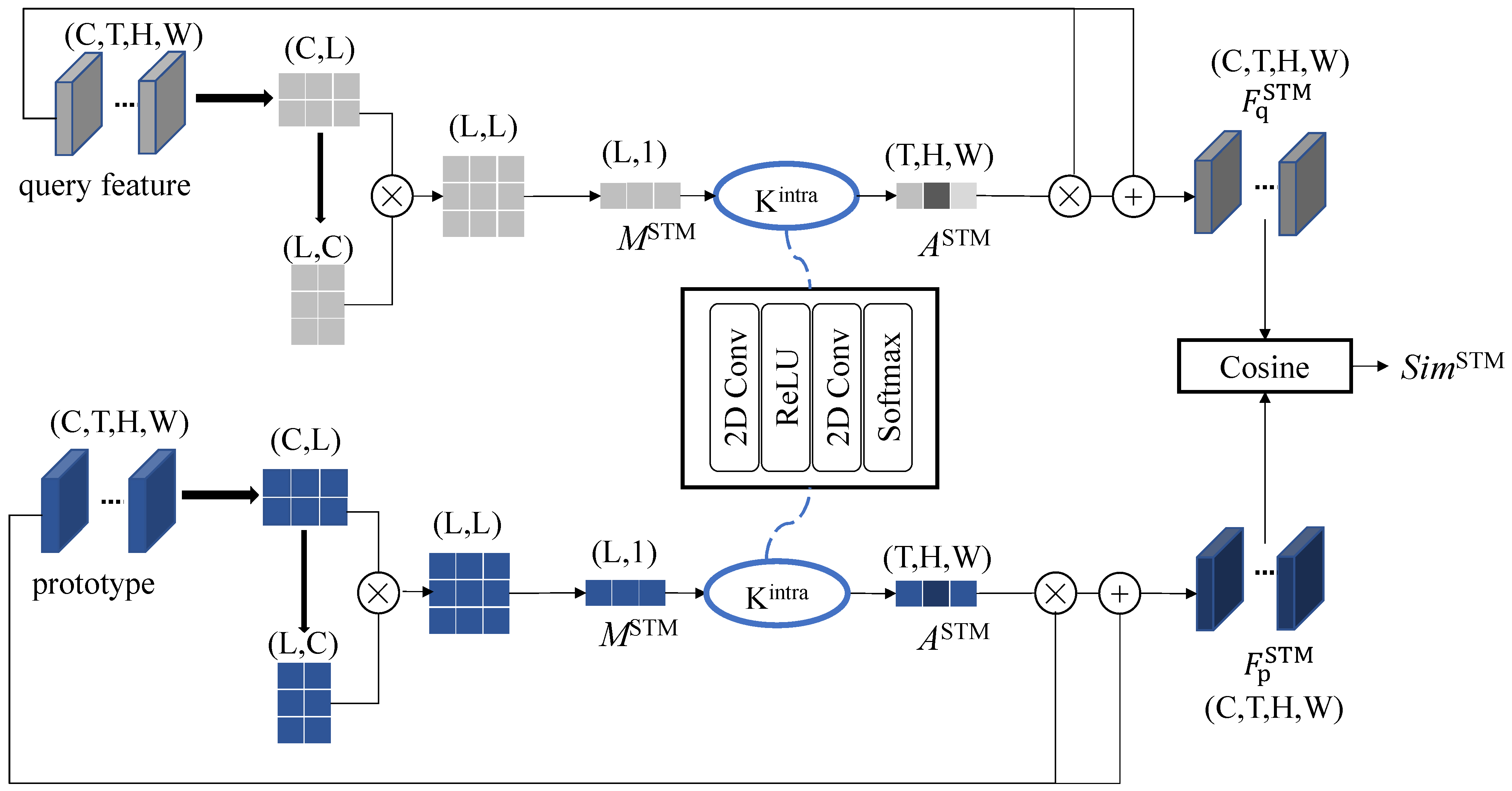
3.2.3. Spatiotemporal Self-Attention Matching
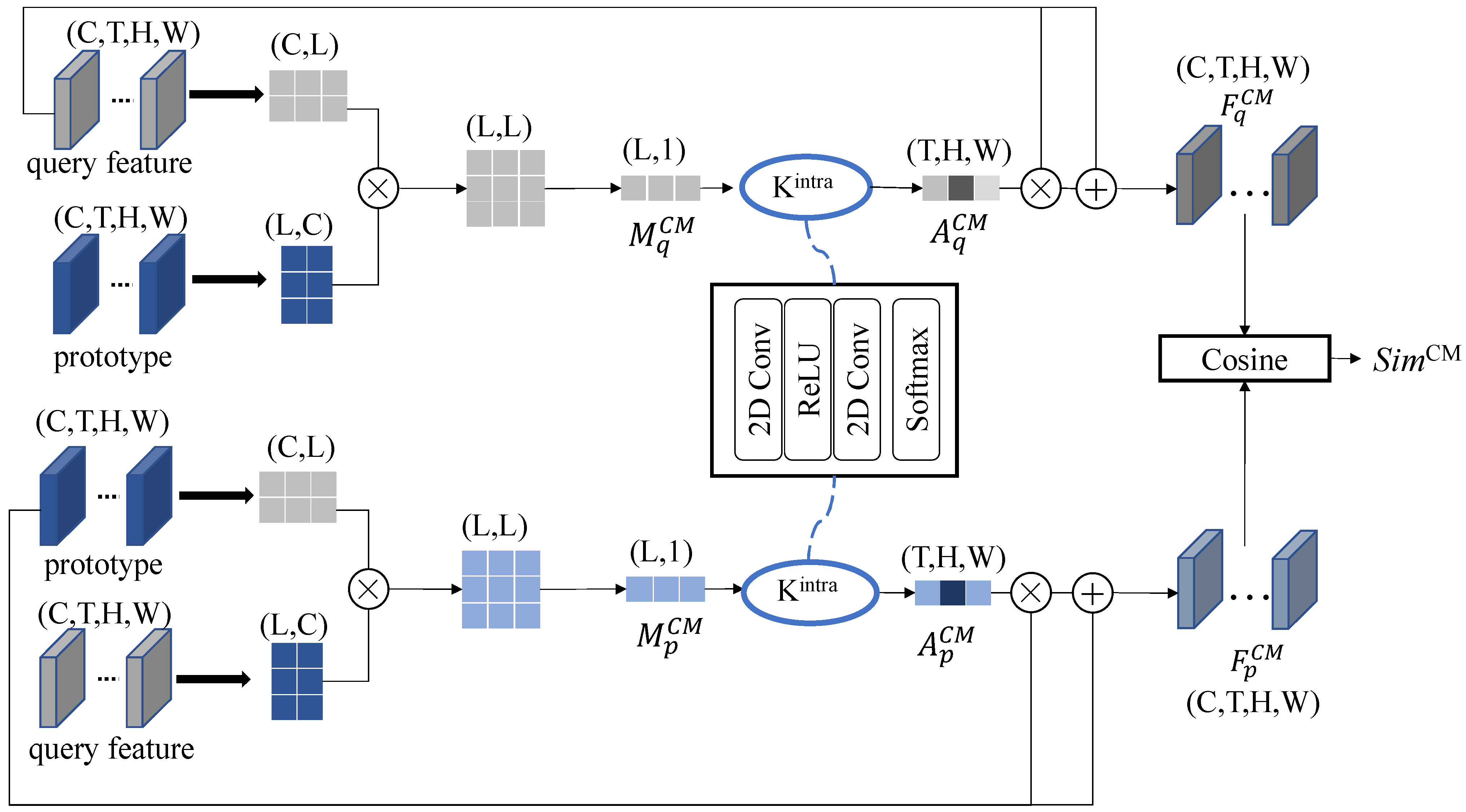
3.2.4. Correlated Cross-Attention Matching
4. Experiments
4.1. Datasets and Experimental Setups
4.2. Comparative Experiments
4.2.1. Using 3D CNN Embedding without Pre-Training
4.2.2. Using 2D CNN Embedding Pre-Trained on ImageNet
4.3. Ablation Study
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| HiTIM | Hierarchical task information mining |
| STM | Spatiotemporal self-attention matching |
| CM | Correlated cross-attention matching |
| 3D | Tree-dimensional |
| CNN | Convolutional neural network |
| C3D | 3D convolutional network |
| D3D | Deformable 3D convolution |
| ARN | Few-shot action recognition with permutation-invariant attention |
| SoSN | Power normalizing second-order similarity network for few-shot learning |
| MR | Few-shot action recognition using task-adaptive parameters |
References
- Leong, M.C.; Prasad, D.K.; Lee, Y.T.; Lin, F. Semi-CNN architecture for effective spatio-temporal learning in action recognition. Appl. Sci. 2020, 10, 557. [Google Scholar] [CrossRef]
- Yang, H.; Gu, Y.; Zhu, J.; Hu, K.; Zhang, X. PGCN-TCA: Pseudo graph convolutional network with temporal and channel-wise attention for skeleton-based action recognition. IEEE Access 2020, 8, 10040–10047. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2017; pp. 6299–6308. [Google Scholar]
- Sahoo, S.P.; Modalavalasa, S.; Ari, S. DISNet: A sequential learning framework to handle occlusion in human action recognition with video acquisition sensors. Digit. Signal Process. 2022, 131, 103763. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Li, H.; Eigen, D.; Dodge, S.; Zeiler, M.; Wang, X. Finding task-relevant features for few-shot learning by category traversal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1–10. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Zhou, K.; Liu, Z.; Qiao, Y.; Xiang, T.; Loy, C.C. Domain generalization: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4396–4415. [Google Scholar] [CrossRef] [PubMed]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In Proceedings of the European Conference Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 69–84. [Google Scholar]
- Balaji, Y.; Sankaranarayanan, S.; Chellappa, R. MetaReg: Towards domain generalization using meta-regularization. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, Canada, 3–8 December 2018; pp. 1006–1016. [Google Scholar]
- Zhang, H.; Zhang, L.; Qi, X.; Li, H.; Torr, P.H.; Koniusz, P. Few-shot action recognition with permutation-invariant attention. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 525–542. [Google Scholar]
- Carlucci, F.M.; D’Innocente, A.; Bucci, S.; Caputo, B.; Tommasi, T. Domain generalization by solving jigsaw puzzles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2229–2238. [Google Scholar]
- Liu, Q.; Dou, Q.; Heng, P.A. Shape-aware meta-learning for generalizing prostate MRI segmentation to unseen domains. In Proceedings of the Medical Image Computing and Computer Assisted Intervention(MICCAI), Lima, Peru, 4–8 October 2020; pp. 475–485. [Google Scholar]
- Li, H.; Dong, W.; Mei, X.; Ma, C.; Huang, F.; Hu, B.G. LGM-Net: Learning to generate matching networks for few-shot learning. In Proceedings of the International Conference on Machine Learning(ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 3825–3834. [Google Scholar]
- Zong, P.; Chen, P.; Yu, T.; Yan, L.; Huan, R. Few-shot action recognition using task-adaptive parameters. Electron. Lett. 2021, 57, 848–850. [Google Scholar] [CrossRef]
- Han, Y.; Huang, G.; Song, S.; Yang, L.; Wang, H.; Wang, Y. Dynamic neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7436–7456. [Google Scholar] [CrossRef]
- Zhang, H.; Koniusz, P. Power normalizing second-order similarity network for few-shot learning. In Proceedings of the Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1185–1193. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Chen, D.; Zhang, T.; Zhou, P.; Yan, C.; Li, C. OFPI: Optical Flow Pose Image for Action Recognition. Mathematics 2023, 11, 1451. [Google Scholar] [CrossRef]
- Cao, K.; Ji, J.; Cao, Z.; Chang, C.Y.; Niebles, J.C. Few-shot video classification via temporal alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10618–10627. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. arXiv 2018, arXiv:1804.06055. [Google Scholar]
- Tasnim, N.; Islam, M.K.; Baek, J.H. Deep learning based human activity recognition using spatio-temporal image formation of skeleton joints. Appl. Sci. 2021, 11, 2675. [Google Scholar] [CrossRef]
- Perrett, T.; Masullo, A.; Burghardt, T.; Mirmehdi, M.; Damen, D. Temporal-relational crosstransformers for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 475–484. [Google Scholar]
- Wang, X.; Zhang, S.; Qing, Z.; Tang, M.; Zuo, Z.; Gao, C.; Jin, R.; Sang, N. Hybrid relation guided set matching for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–24 June 2022; pp. 19948–19957. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 12894–12904. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Gao, Y. Efficiently comparing face images using a modified Hausdorff distance. IEEE-Proc.-Vision Image Signal Process. 2003, 150, 346–350. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the International Conference on Neural Information Processing Systems, Beach, CA, USA, 4–9 December 2017; pp. 4080–4090. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Sydney, New South Wales, 2016; Volume 29. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhu, X.; Toisoul, A.; Perez-Rua, J.M.; Zhang, L.; Martinez, B.; Xiang, T. Few-shot action recognition with prototype-centered attentive learning. arXiv 2021, arXiv:2101.08085. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 4489–4497. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Huang, G.; Liu, S.; Van der Maaten, L.; Weinberger, K.Q. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2752–2761. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inf. Process. Syst. 2019, 32, 1307–1318. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognitio (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11030–11039. [Google Scholar]
- Zhou, W.; Xu, C.; Ge, T.; McAuley, J.; Xu, K.; Wei, F. Bert loses patience: Fast and robust inference with early exit. Adv. Neural Inf. Process. Syst. 2020, 33, 18330–18341. [Google Scholar]
- Shen, J.; Wang, Y.; Xu, P.; Fu, Y.; Wang, Z.; Lin, Y. Fractional skipping: Towards finer-grained dynamic CNN inference. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5700–5708. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Ying, X.; Wang, L.; Wang, Y.; Sheng, W.; An, W.; Guo, Y. Deformable 3d convolution for video super-resolution. IEEE Signal Process. Lett. 2020, 27, 1500–1504. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, S.; Liu, H.; Qian, R.; Li, Y.; See, J.; Fei, M.; Yu, X.; Lin, W. TA2N: Two-stage action alignment network for few-shot action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, Canada, 22 February–1 March 2022; Volume 36, pp. 1404–1411. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | HMDB51 | UCF101 | ||
|---|---|---|---|---|
| 5-Way 1-Shot | 5-Way 5-Shot | 5-Way 1-Shot | 5-Way 5-Shot | |
| 3D Prototypical Networks [33] | 38.05 ± 1.02 | 53.15 ± 0.73 | 57.05 ± 1.02 | 78.25 ± 0.73 |
| 3D Relation Network [35] | 38.23 ± 0.97 | 53.17 ± 0.86 | 58.21 ± 1.02 | 78.35 ± 0.72 |
| 3D SoSN [17] | 40.83 ± 0.96 | 55.18 ± 0.86 | 62.57 ± 1.03 | 81.51 ± 0.73 |
| ARN [11] | 42.41 ± 0.99 | 56.81 ± 0.87 | 64.48 ± 1.06 | 82.37 ± 0.72 |
| ARN [11] + SsSA-rotation | 45.15 ± 0.96 | 60.56 ± 0.86 | 66.32 ± 0.99 | 83.12 ± 0.70 |
| MR [15] | 42.62 ± 0.52 | 58.39 ± 0.84 | 65.17 ± 0.38 | 83.51 ± 0.65 |
| HiTIM | 46.92 ± 0.42 | 61.74 ± 0.67 | 66.54 ± 0.51 | 84.71 ± 0.53 |
| Methods | HMDB51 | UCF101 | ||
|---|---|---|---|---|
| 5-Way 1-Shot | 5-Way 5-Shot | 5-Way 1-Shot | 5-Way 5-Shot | |
| 2D Prototypical Networks [33] | 54.2 | 68.4 | 74.0 | 89.6 |
| OTAM [20] | 54.5 | 68.0 | 79.9 | 88.9 |
| TRX [23] | 53.1 | 75.6 | 78.2 | 96.1 |
| PAL [37] | 60.9 | 75.8 | 85.3 | 95.2 |
| [48] | 59.7 | 73.9 | 81.9 | 95.1 |
| HyRSM [24] | 60.3 | 76.0 | 83.9 | 94.7 |
| HiTIM | 61.0 | 77.4 | 84.6 | 94.9 |
| Methods | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|
| OTAM [20] | 73.0 | 85.8 |
| TRX [23] | 63.6 | 85.9 |
| PAL [37] | 74.2 | 87.1 |
| [48] | 73.0 | 85.8 |
| HyRSM [24] | 73.7 | 86.1 |
| HiTIM | 74.3 | 86.0 |
| Setting | HMDB51 | UCF101 |
|---|---|---|
| HiTIM* | 44.61 ± 0.92 | 63.95 ± 0.64 |
| HiTIM* + Kinter | 46.02 ± 0.81 | 65.06 ± 0.50 |
| HiTIM* + Kinter | 45.28 ± 0.86 | 64.81 ± 0.42 |
| HiTIM* +Kinter* + Kintra | 46.18 ± 0.46 | 65.45 ± 0.38 |
| HiTIM | 46.92 ± 0.42 | 66.54 ± 0.41 |
| Match | HMDB51 | UCF101 |
|---|---|---|
| Cosine | 40.28 ± 0.95 | 58.71 ± 1.12 |
| STM | 45.73 ± 0.68 | 65.37 ± 0.52 |
| CM | 45.41 ± 0.56 | 64.81 ± 0.43 |
| STM + CM | 46.92 ± 0.42 | 66.54 ± 0.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, L.; Yu, J.; Dang, Y.; Chen, P.; Huan, R. HiTIM: Hierarchical Task Information Mining for Few-Shot Action Recognition. Appl. Sci. 2023, 13, 5277. https://doi.org/10.3390/app13095277
Jiang L, Yu J, Dang Y, Chen P, Huan R. HiTIM: Hierarchical Task Information Mining for Few-Shot Action Recognition. Applied Sciences. 2023; 13(9):5277. https://doi.org/10.3390/app13095277
Chicago/Turabian StyleJiang, Li, Jiahao Yu, Yuanjie Dang, Peng Chen, and Ruohong Huan. 2023. "HiTIM: Hierarchical Task Information Mining for Few-Shot Action Recognition" Applied Sciences 13, no. 9: 5277. https://doi.org/10.3390/app13095277