

A Novel Opportunistic Network Routing Method on Campus Based on the Improved Markov Model
 ,
,
Abstract
:1. Introduction
1.1. Background
1.2. Motivation
1.3. Contribution
- In this study, we distinguish between intra-group forwarding and extra-group forwarding when it comes to messaging. When a message needs to be sent between groups, we use a novel Markov model to determine the probability that the sender and the recipient will be in the same place. We then send the message to the nodes with a higher probability of doing so. The message only needs to be delivered within the group when the recipient and the source node are both members of the same group. This not only gets the message to its target quickly but also saves a significant amount of cache space by sending the message to those nodes that have high centrality within the group.
- The utility value of a message is defined in terms of both the message’s degree of diffusion and the present node’s energy usage. According to our theory, if a message has a high degree of diffusion, there are likely already some copies of it in the network. As a result, priority should be given to receiving messages with a lower degree of diffusion. Moreover, if a message requires a lot of energy from the current node that node might not be the best choice to serve as its relay.
- The node also keeps track of both the message list and the delivered message list, prompting the node to remove any messages that have already been delivered.
- Our suggested strategy enhances network performance in terms of packet delivery rate, average delivery delay, average cost and overhead when compared to current methods.
2. Related Works
- Epidemic [21], which is a flooding-based routing method where a node passes a message copy to every node it encounters. By creating numerous message duplicates, it increases the probability that the message will be delivered when it comes across the destination node. However, a lot of copies use up network resources, such as cache space and node energy.
- Prophet [22] is a method that is frequently used to send messages based on predictions. Two nodes exchange vectors of transmission probabilities for recognized destinations when they come into contact. Messages can be sent to nodes that meet regularly by updating the transmission probability between nodes based on how long it has been since their last encounter. Nevertheless, it ignores the location information of the nodes and the number of encounters between them.
- RDR, which chooses the next-hop node based on the node’s estimated latency, estimated speed variation, the direction of motion, available space in the buffer, and previously sent messages. It provides a constrained amount of replicas, reducing the network resource footprint. With this approach, the amount of network resources used can be drastically decreased, and the size of the cache area has less of an impact. However, messages may not be delivered for a long time, and it requires a longer message survival time.
- FCIM, where each relay node is rewarded with some points when the source node sends a message to its target, increases the message delivery rate by motivating selfish nodes to actively participate in message forwarding. Nodes are permitted to engage in some acceptable selfish behaviors under this strategy, such as rejecting messages when the cache is full. However, no more properties are considered, such as the energy consumption of nodes to forward messages.
3. Materials and Methods
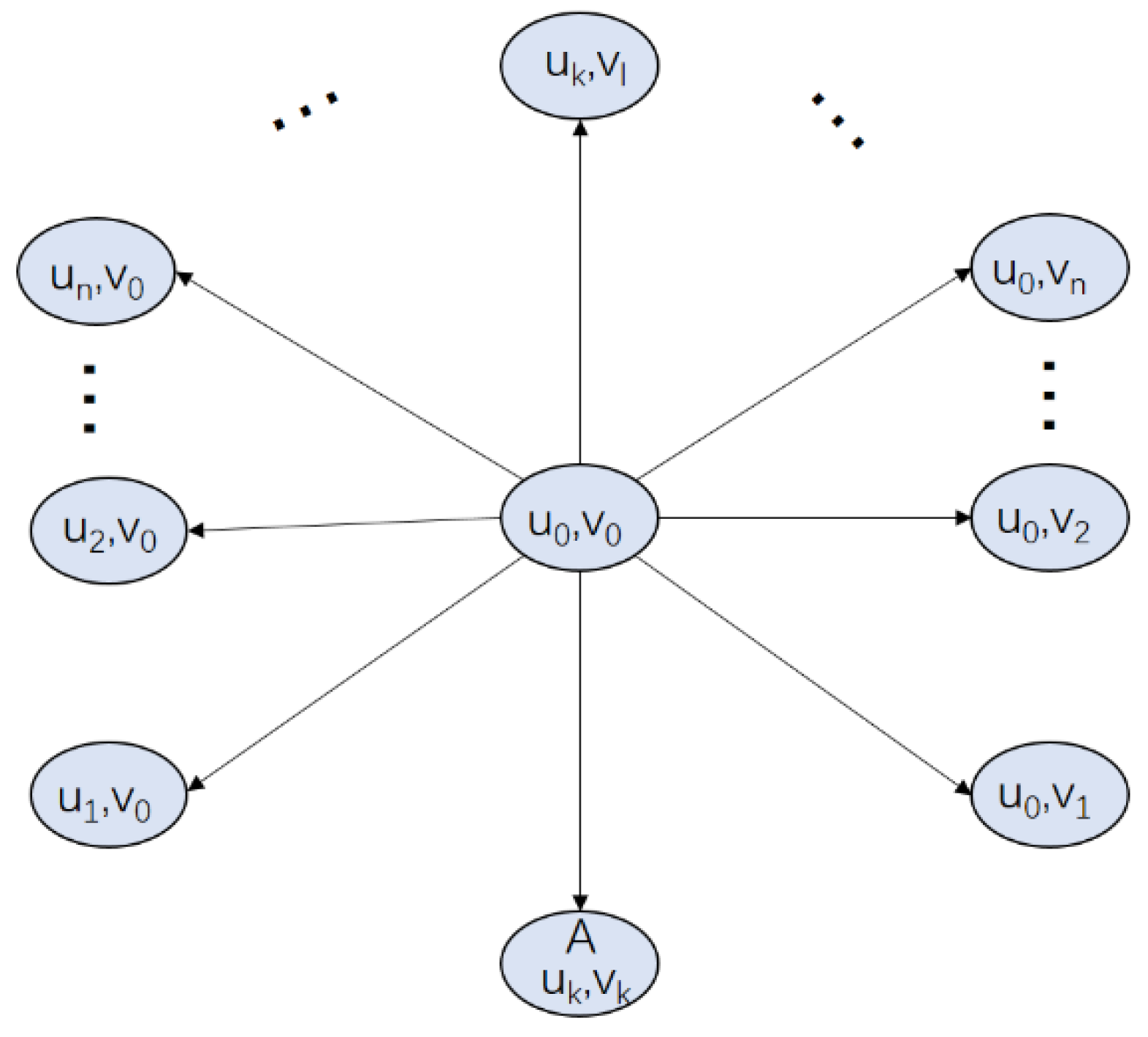
3.1. Markov-Based Next Destination Prediction
- Within mutually exclusive time intervals, the number of times that nodes choose the place as a destination point is independent of one another;
- The probability distribution of the number of times that a node chooses this location in period is independent of s, where ;
- is the likelihood that a node will choose the same place more than once in a sufficiently little period of time.
- For a sufficiently small ;
- Furthermore;
- .
3.2. Node Centering Degree
3.3. Historical Information Exchange
3.4. Forwarding Strategy
- Out-group forwarding
- 2.
- In-group forwarding
4. Routing Algorithms Based on Node Path Prediction and Cache Management
4.1. Utility Value of the Message
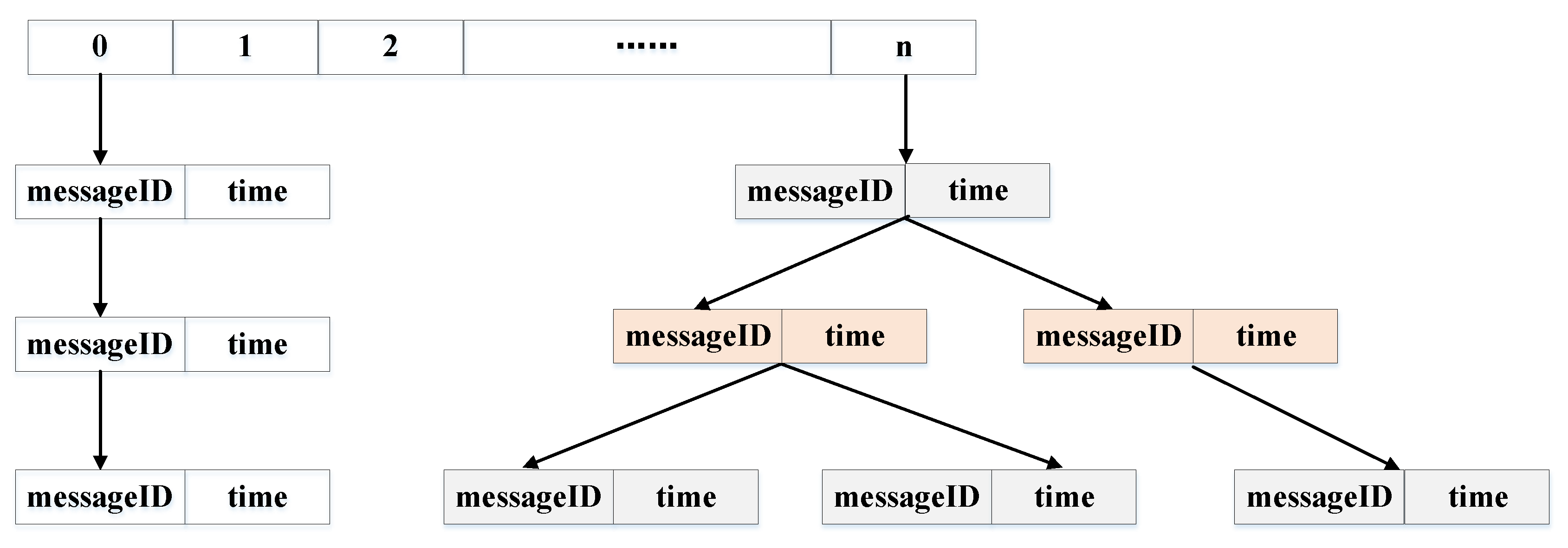
4.2. Scheduled Cache Management Mechanism
4.3. Markov Path Prediction and Cache Management
| Algorithm 1. MPCM strategy |
| INPUT: node , node |
| OUTPUT: Messages |
START:
|
| END |
5. Results
5.1. Experimental Scheme Design
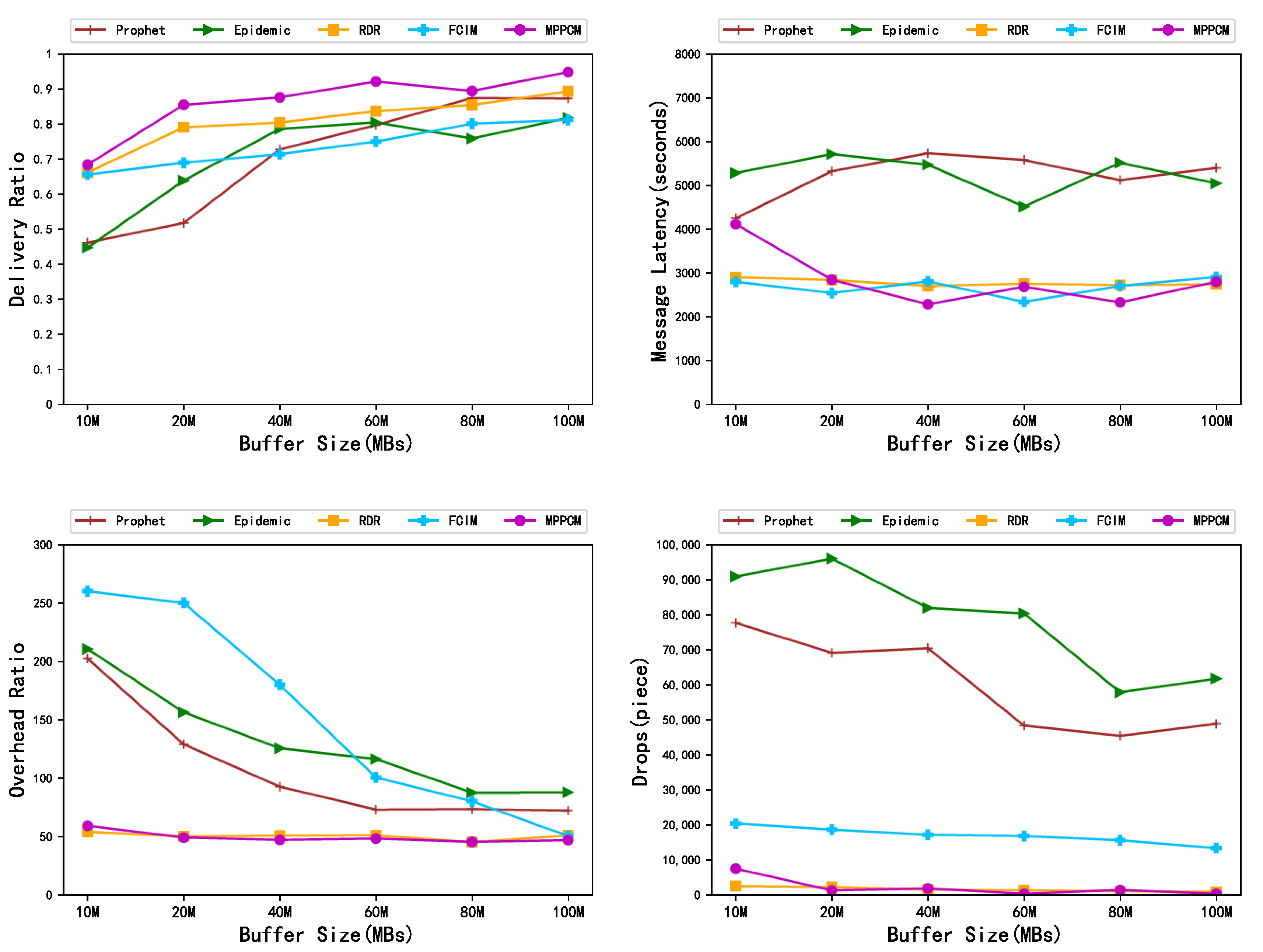
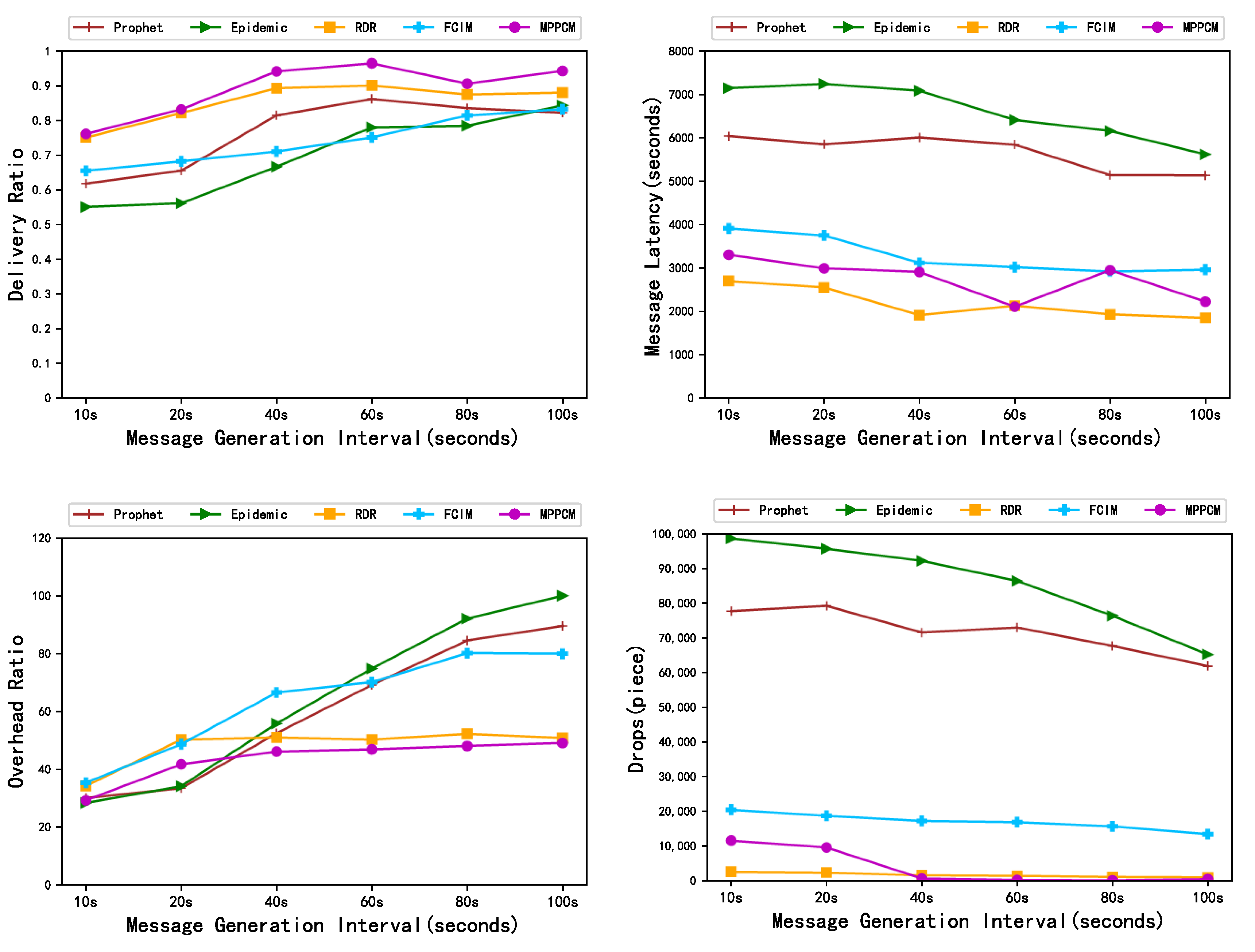
5.2. Experimental Results Analysis
5.2.1. Different Cache Spaces
5.2.2. Different Message Generation Intervals
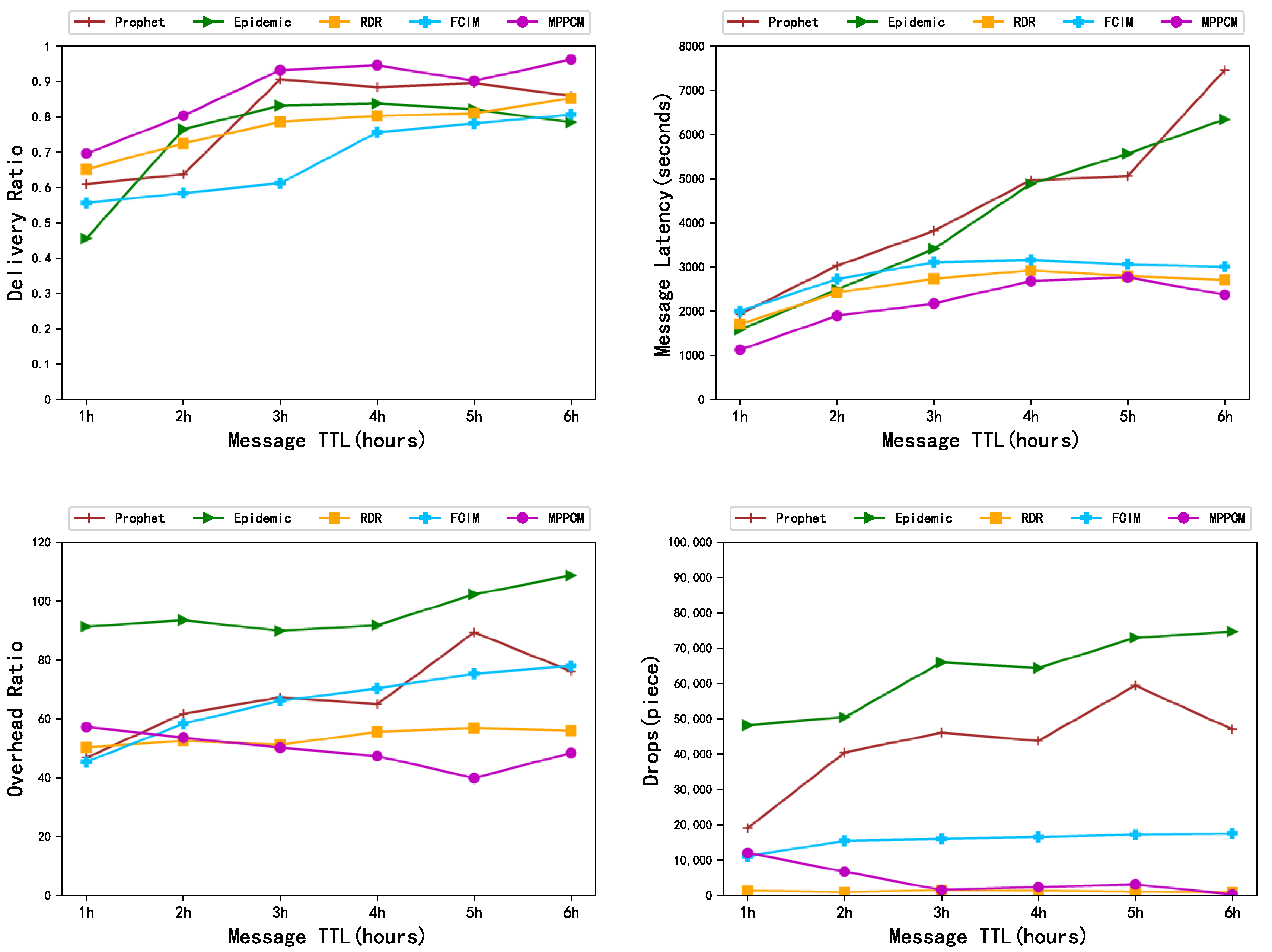
5.2.3. Different Time to Live of Messages (TTL)
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sachdeva, R.; Dev, A. Review of opportunistic network: Assessing past, present, and future. Int. J. Commun. Syst. 2021, 34, e4860. [Google Scholar] [CrossRef]
- LI, P.; Wang, X.M.; Zhang, L.C.; LU, J.L.; Zhu, T.J.; Zhang, D. A Novel Method of Video Data Fragmentary and Progressive Transmission in Opportunistic Network. Acta Electonica Sin. 2018, 46, 2165. [Google Scholar]
- Bagirathan, K.; Palanisamy, A. Opportunistic routing protocol based EPO--BES in MANET for optimal path selection. Wirel. Pers. Commun. 2022, 123, 473–494. [Google Scholar] [CrossRef]
- Gautam, T.; Dev, A. Improving Packet Queues Using Selective Epidemic Routing Protocol in Opportunistic Networks (SERPO) BT—Advances in Computing and Data Sciences. In Advances in Computing and Data Sciences, 4th International Conference, ICACDS 2020, Valletta, Malta, 24–25 April 2020; Revised Selected Papers 4; Springer: Singapore, 2020; pp. 382–394. [Google Scholar]
- Bansal, A.; Gupta, A.; Sharma, D.K.; Gambhir, V. Iicar-inheritance inspired context aware routing protocol for opportunistic networks. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 2235–2253. [Google Scholar] [CrossRef]
- Sharma, D.K.; Kukreja, D.; Chugh, S.; Kumaram, S. Supernode routing: A grid-based message passing scheme for sparse opportunistic networks. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 1307–1324. [Google Scholar] [CrossRef]
- Singh, J.; Obaidat, M.S.; Dhurandher, S.K. Location based Routing in Opportunistic Networks using Cascade Learning. In Proceedings of the 2021 International Conference on Computer, Information and Telecommunication Systems (CITS), Istanbul, Turkey, 29–31 July 2021; pp. 1–5. [Google Scholar]
- Dhurandher, S.K.; Singh, J.; Nicopolitidis, P.; Kumar, R.; Gupta, G. A blockchain-based secure routing protocol for opportunistic networks. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 2191–2203. [Google Scholar] [CrossRef]
- Sharma, D.K.; Rodrigues, J.J.P.C.; Vashishth, V.; Khanna, A.; Chhabra, A. RLProph: A dynamic programming based reinforcement learning approach for optimal routing in opportunistic IoT networks. Wirel. Netw. 2020, 26, 4319–4338. [Google Scholar] [CrossRef]
- Kumar, P.; Chauhan, N.; Chand, N. Node activity based routing in opportunistic networks. In Proceedings of the International Conference on Futuristic Trends in Network and Communication Technologies, Taganrog, Russia, 14–16 October 2019; pp. 265–277. [Google Scholar]
- Gou, F.; Wu, J. Triad link prediction method based on the evolutionary analysis with IoT in opportunistic social networks. Comput. Commun. 2022, 181, 143–155. [Google Scholar] [CrossRef]
- Chunyue, Z.; Hui, T.; Yaocong, D. An Energy-Saving Routing Algorithm for Opportunity Networks Based on Sleeping Mode. In Proceedings of the 2019 20th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Gold Coast, Australia, 5–7 December 2019; pp. 13–18. [Google Scholar]
- Derakhshanfard, N.; Soltani, R. Opportunistic routing in wireless networks using bitmap-based weighted tree. Comput. Netw. 2021, 188, 107892. [Google Scholar] [CrossRef]
- Chithaluru, P.; Tiwari, R.; Kumar, K. AREOR–Adaptive ranking based energy efficient opportunistic routing scheme in Wireless Sensor Network. Comput. Netw. 2019, 162, 106863. [Google Scholar] [CrossRef]
- Hernández-Orallo, E.; Borrego, C.; Manzoni, P.; Marquez-Barja, J.M.; Cano, J.C.; Calafate, C.T. Optimising data diffusion while reducing local resources consumption in Opportunistic Mobile Crowdsensing. Pervasive Mob. Comput. 2020, 67, 101201. [Google Scholar] [CrossRef]
- Raverta, F.D.; Fraire, J.A.; Madoery, P.G.; Demasi, R.A.; Finochietto, J.M.; D’argenio, P.R. Routing in Delay-Tolerant Networks under uncertain contact plans. Ad. Hoc. Netw. 2021, 123, 102663. [Google Scholar] [CrossRef]
- Das, P.; Nishantkar, P.; De, T. SECA on MIA-DTN: Tackling the Energy Issue in Monitor Incorporated Adaptive Delay Tolerant Network Using a Simplistic Energy Conscious Approach. J. Netw. Syst. Manag. 2019, 27, 121–148. [Google Scholar] [CrossRef]
- Kang, M.W.; Chung, Y.W. An improved hybrid routing protocol combining MANET and DTN. Electronics 2020, 9, 439. [Google Scholar] [CrossRef]
- Pirzadi, S.; Pourmina, M.A.; Safavi-Hemami, S.M. A novel routing method in hybrid DTN--MANET networks in the critical situations. Computing 2022, 104, 2137–2156. [Google Scholar] [CrossRef]
- Mao, Y.; Zhou, C.; Qi, J.; Zhu, X. A fair credit-based incentive mechanism for routing in DTN-based sensor network with nodes’ selfishness. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 1–18. [Google Scholar] [CrossRef]
- Vahdat, A.; Becker, D. Epidemic Routing for Partially-Connected Ad Hoc Networks. In Handbook of Systemic Autoimmune Diseases; Elsevier: Amsterdam, The Netherlands, 2000. [Google Scholar]
- Lindgren, A.; Doria, A.; Schelén, O. Probabilistic Routing in Intermittently Connected Networks. ACM Sigmobile Mob. Comput. Commun. Rev. 2003, 7, 19–20. [Google Scholar] [CrossRef]
- Rehman, G.U.; Haq, M.I.U.; Zubair, M.; Mahmood, Z.; Singh, M.; Singh, D. Misbehavior of nodes in IoT based vehicular delay tolerant networks VDTNs. Multimed. Tools Appl. 2023, 82, 7841–7859. [Google Scholar] [CrossRef]
- Rehman, G.U.; Ghani, A.; Zubair, M.; Naqvi, S.H.A.; Singh, D.; Muhammad, S. IPS: Incentive and Punishment Scheme for Omitting Selfishness in the Internet of Vehicles (Iov). IEEE Access 2019, 7, 109026–109037. [Google Scholar] [CrossRef]
- Rehman, G.U.; Zubair, M.; Qasim, I.; Badshah, A.; Mahmood, Z.; Aslam, M.; Jilani, S.F. EMS: Efficient Monitoring System to Detect Non-Cooperative Nodes in IoT-Based Vehicular Delay Tolerant Networks (VDTNs). Sensors 2023, 23, 99. [Google Scholar] [CrossRef] [PubMed]
- Rehman, G.U.; Ghani, A.; Zubair, M.; Saeed, M.I.; Singh, D. SOS: Socially omitting selfishness in IoT for smart and connected communities. Int. J. Commun. Syst. 2023, 36, e4455. [Google Scholar] [CrossRef]
- Scott, J.; Hui, P.; Crowcroft, J.; Diot, C. Haggle: A networking architecture designed around mobile users. In Proceedings of the Third IFIP Wireless on Demand Network Systems Conference, Les Menuires, France, 18–20 January 2006. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Limitations of Existing Works | Novelties of This Paper |
|---|---|
| The previous section describes how nodes can reduce network resource usage by providing a restricted number of copies, but messages with a short survival time may not be delivered. | In this paper, we transmit messages based on the probability that the nodes will meet at the next location which can guarantee the successful transmission of messages in a short time. |
| The prediction-based routing presented above takes into account the encounter interval of the nodes. | We consider the probability that nodes will meet one another at various places and the number of contacts between nodes. |
| FCIM considers the caching of networks. | Description of the message’s energy consumption and the network’s degree of message spread was added to the node. |
| They encourage selfish nodes to engage in collaboration. | Skip selfish nodes to avoid being impacted by them. |
| Notation | Description |
|---|---|
| Node and node | |
| Probability and meet | |
| Message m | |
| Centrality degree of node | |
| Destination node of message m |
| Parameter | Value |
|---|---|
| dataset | haggle6-infocom6 |
| simulation time/h | 72 |
| simulation area/ | 4500 × 3400 |
| number of nodes | 98 |
| message generation interval/s | 100 |
| message size/kb | 50 k~5000 k |
| message TTL/h | 5 |
| Algorithm /Score | Success Rate | Overhead | Latency | Packet Drops | Total Score |
|---|---|---|---|---|---|
| Epidemic | 0 | 0.2687 | 0 | 0 | 0.2687 |
| Prophet | 0.0034 | 0.4460 | 0.0092 | 0.2374 | 0.696 |
| RDR | 0.6362 | 0.9897 | 0.9639 | 1 | 3.5898 |
| FCIM | 0.1840 | 0 | 1 | 0.7987 | 1.9827 |
| MPCM | 1 | 1 | 0.9388 | 0.9935 | 3.9323 |
| Algorithm /Score | Success Rate | Overhead | Latency | Packet Drops | Total Score |
|---|---|---|---|---|---|
| Epidemic | 0.3631 | 0 | 0 | 0 | 0.3631 |
| Prophet | 0 | 0.2107 | 0.2123 | 0.1656 | 0.5886 |
| RDR | 0.8048 | 0.776 | 1 | 1 | 3.5808 |
| FCIM | 0.2226 | 0.0354 | 0.7517 | 0.8169 | 1.8266 |
| MPCM | 1 | 1 | 0.8713 | 0.9753 | 3.8466 |
| Algorithm /Score | Success Rate | Overhead | Latency | Packet Drops | Total Score |
|---|---|---|---|---|---|
| Epidemic | 0.6064 | 0 | 0.1506 | 0 | 0.757 |
| Prophet | 0.34914 | 0.6095 | 0 | 0.3269 | 1.28554 |
| RDR | 0.4633 | 0.9084 | 0.8289 | 1 | 3.2006 |
| FCIM | 0 | 0.6547 | 0.6942 | 0.765 | 2.1139 |
| MPCM | 1 | 1 | 1 | 0.9492 | 3.9492 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, Y.; Li, P.; Liang, T.; Wu, X.; Wang, X.; Cui, Y. A Novel Opportunistic Network Routing Method on Campus Based on the Improved Markov Model. Appl. Sci. 2023, 13, 5217. https://doi.org/10.3390/app13085217
Cao Y, Li P, Liang T, Wu X, Wang X, Cui Y. A Novel Opportunistic Network Routing Method on Campus Based on the Improved Markov Model. Applied Sciences. 2023; 13(8):5217. https://doi.org/10.3390/app13085217
Chicago/Turabian StyleCao, Yumei, Peng Li, Tianmian Liang, Xiaojun Wu, Xiaoming Wang, and Yuanru Cui. 2023. "A Novel Opportunistic Network Routing Method on Campus Based on the Improved Markov Model" Applied Sciences 13, no. 8: 5217. https://doi.org/10.3390/app13085217