
A Two-Phase Iterative Mathematical Programming-Based Heuristic for a Flexible Job Shop Scheduling Problem with Transportation


Abstract
:1. Introduction
- While certain problems of other domains apply feedback to guide the solution search, the FJSP + T model serves as a heuristic to mitigate the lack of it by providing good machine-operation assignments.
- In conventional approaches, first-phase solutions might sometimes be infeasible for the second phase. Each JSPT network, however, is feasible as the routing network is generated from first-phase results.
- The proposed JSPT model is a network flow model and considers job pre-emption, which has yet to be considered.
- The solution methodology structure facilitates the independent usage of both submodels. The JSPT is tailored for scenarios where organizational preferences such as machine-operation assignments have already been fixed [24], while FJSP + T can be used for coarse planning purposes.
2. FJSPT (Overall) Problem Description
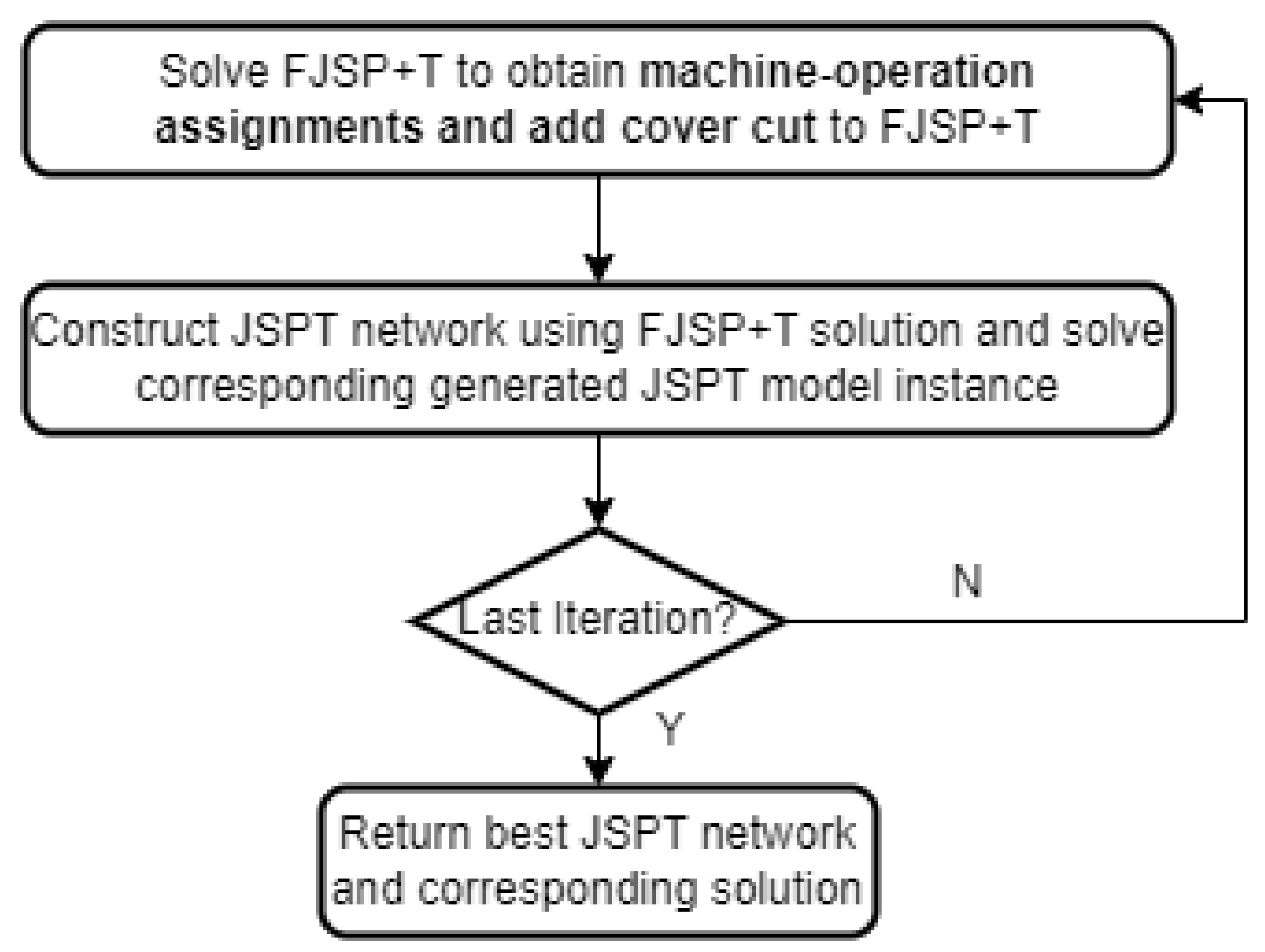
3. A Two-Phase Iterative Solution Methodology
| Algorithm 1: General scheme of two-phase iterative approach |
| Input: solution set, , Input: iteration counter, Input: Objective value of best solution, Output: Best solution, Output: objective value of best solution, Output: Current solution, Output: objective value of current solution, repeat Solve the FJSP + T and obtain for each Add (cover) cut to FJSP + T Construct basic JSPT network Enhance and cluster basic JSPT network Formulate current JSPT problem If : Add objective cut, to current JSPT problem Solve the JSPT problem If problem is infeasible: else if : until return |
3.1. The FJSP + T Problem
FJSP + T Problem Formulation
- Only intermachine transportation timings are augmented, neglecting L/U-machine distances.
- All jobs are assumed to be already located at the corresponding machines, which are used to process their first operations after assignment and are stored at the buffers of each assigned machine after job completion.
- The notation used by FJSP + T is listed in Table 1.
3.2. The JSPT Subproblem
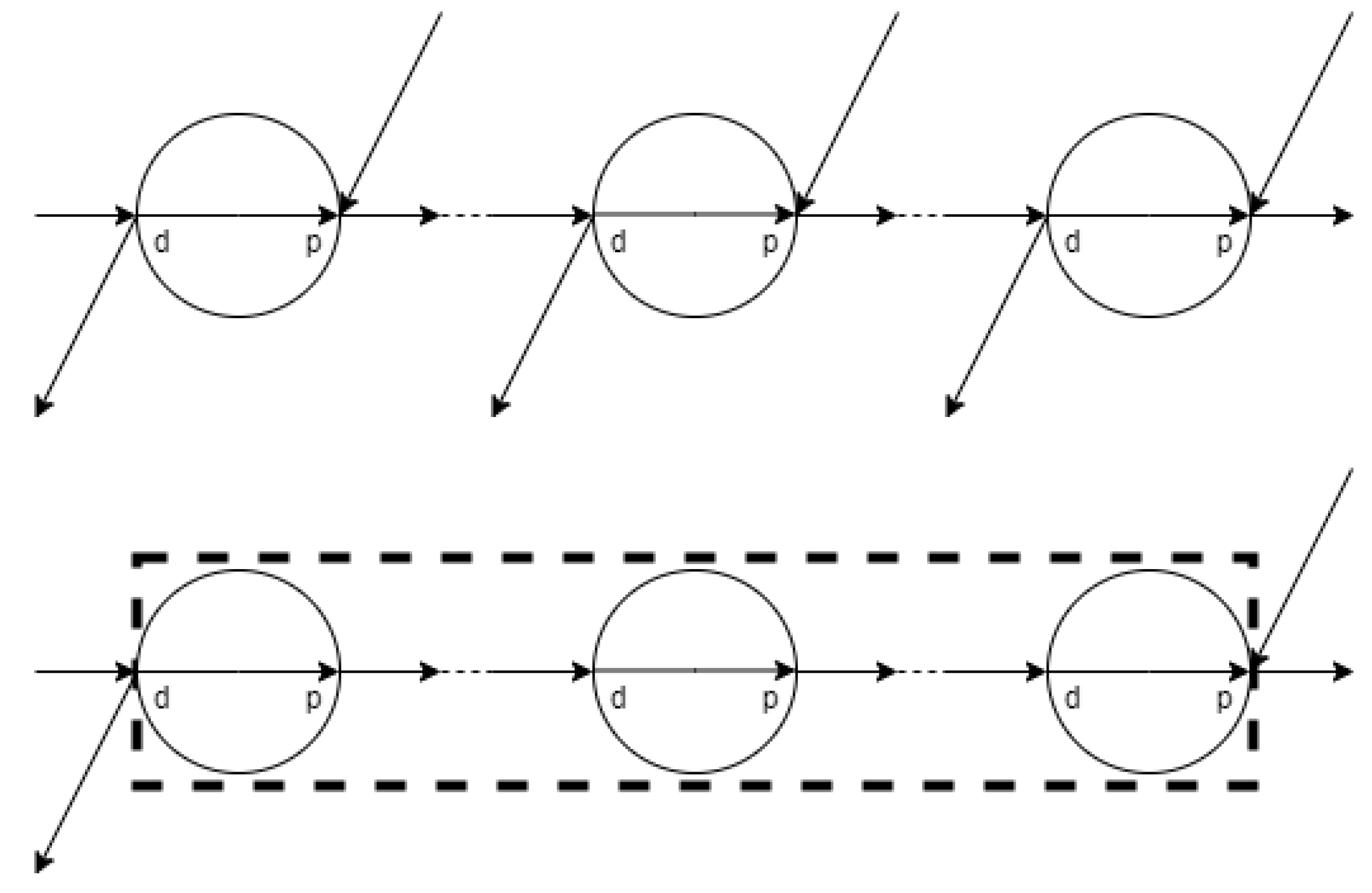
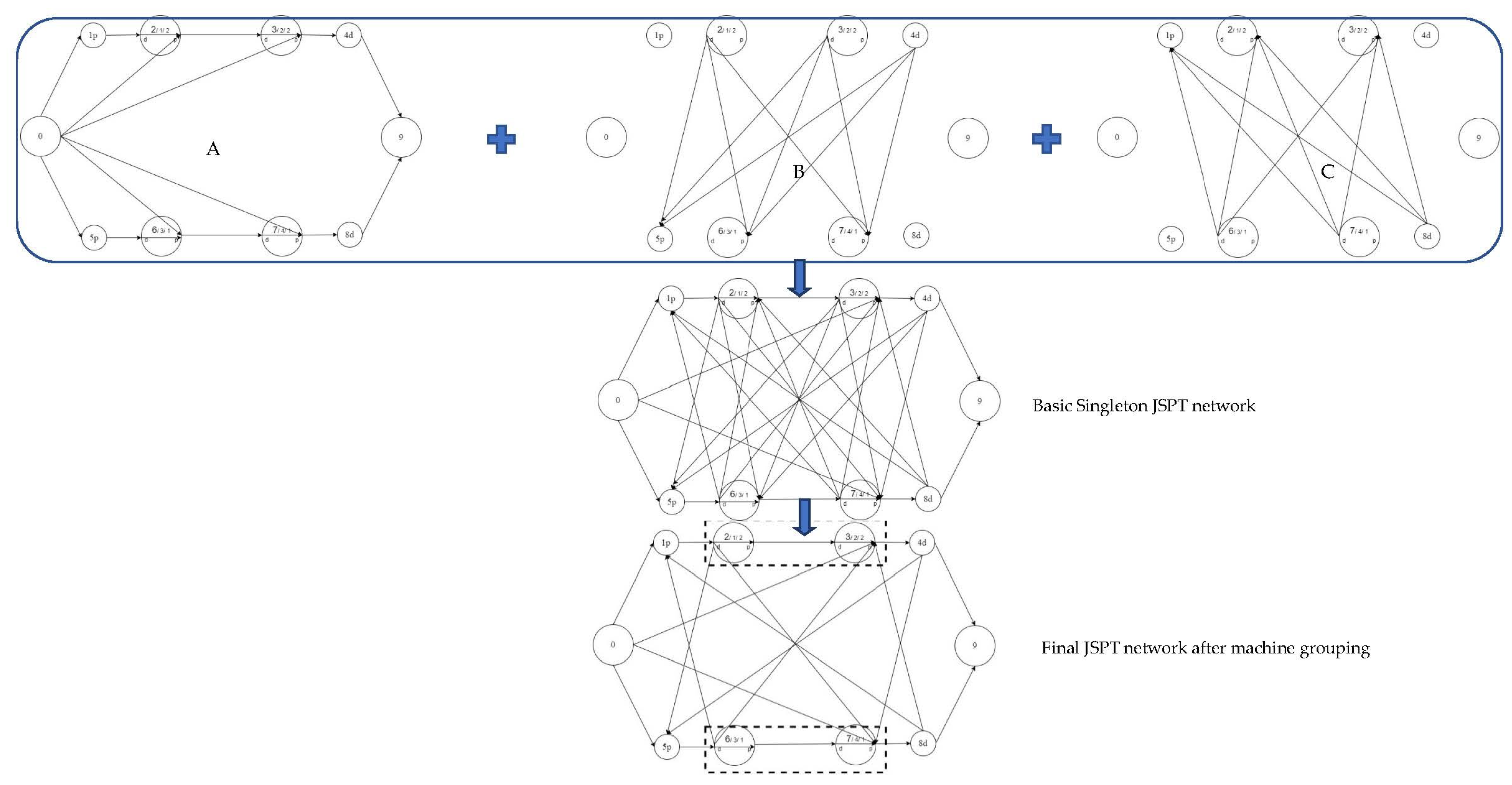
3.2.1. JSPT Network Construction
3.2.2. JSPT Problem Formulation
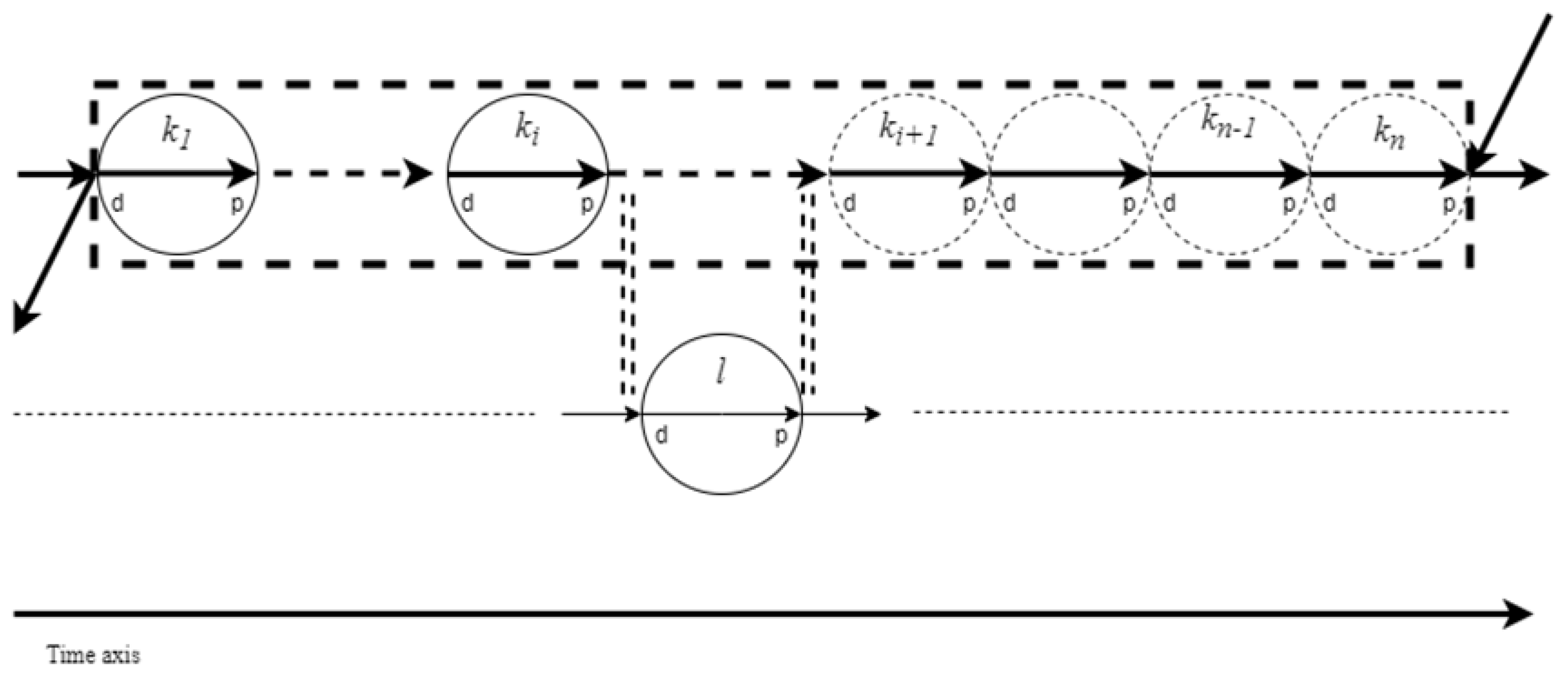
- For each singleton and the last station of each machine group within each job , let be the set of nodes connected to the p node of l, comprising O, or any of the d nodes of the dummy or processing stations from other jobs (sans its d node):
- For each singleton and the first station of each machine group within each job , let be the set of p nodes connected to the d node of l, comprising any of the p nodes of the dummy or processing stations from other jobs (sans its p node):
Trans-Shipment Logic Cuts
Non-Overlapping Processing Cuts
- At most, one permutation of all processing sequences is chosen for duplicate machines belonging to three different jobs.
- At most, one combination of processing sequence is chosen for duplicate machines, of which one belongs to one job and the other two belong to another job:
Decision Variable Restriction Constraints
4. Results and Discussion
4.1. Data Set 1 Benchmarking Instances
4.2. Data Set 2 Benchmarking Instances
4.2.1. Instances with Ratio Less Than 0.25
4.2.2. Instances with Ratio Greater Than 0.25
- Incorporating the makespan within the objective to ensure the minimization of the makespan.
- Weighting the makespan with noise, , which is a random number in the interval [0.05, 0.25] in increments of 0.01 to expedite the search process through diversification.
4.3. Data Set 3 Benchmarking Instances
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Executive Summary World Robotics 2021—Industrial Robots. Available online: https://ifr.org/img/worldrobotics/Executive_Summary_WR_Industrial_Robots_2021.pdf (accessed on 7 July 2021).
- Vox. How Robots Are Transforming Amazon Warehouse Jobs—For Better and Worse. Available online: https://www.vox.com/recode/2019/12/11/20982652/robots-amazon-warehouse-jobs-automation (accessed on 9 October 2021).
- Executive Summary World Robotics 2021—Service Robots. Available online: https://ifr.org/img/worldrobotics/Executive_Summary_WR_Service_Robots_2021.pdf (accessed on 7 July 2021).
- Deroussi, L.; Norre, S. Simultaneous Scheduling of Machines and Vehicles for the Flexible Job Shop Problem. In Proceedings of the International Conference on Metaheuristics and Nature Inspired Computing, Djerba, Tunisia, 27–31 October 2010; pp. 1–2. [Google Scholar]
- Garey, M.R.; Johnson, D.S.; Sethi, R. The Complexity of Flowshop and Jobshop Scheduling. Math. Oper. Res. 1976, 1, 117–129. [Google Scholar] [CrossRef]
- Gao, K.; Yang, F.; Zhou, M.; Pan, Q.; Suganthan, P.N. Flexible Job-Shop Rescheduling for New Job Insertion by Using Discrete Jaya Algorithm. IEEE Trans. Cybern. 2019, 49, 1944–1955. [Google Scholar] [CrossRef]
- Gao, K.; Cao, Z.; Zhang, L.; Chen, Z.; Han, Y.; Pan, Q. A review on swarm intelligence and evolutionary algorithms for solving flexible job shop scheduling problems. IEEE/CAA J. Autom. Sin. 2019, 6, 904–916. [Google Scholar] [CrossRef]
- An, Y.; Chen, X.; Gao, K.; Zhang, L.; Li, Y.; Zhao, Z. A hybrid multi-objective evolutionary algorithm for solving an adaptive flexible job-shop rescheduling problem with real-time order acceptance and condition-based preventive maintenance. Expert Syst. Appl. 2023, 212, 118711. [Google Scholar] [CrossRef]
- Lenstra, J.K.; Kan, A.H. Complexity of Vehicle Routing and Scheduling Problems. Networks 1981, 11, 221–227. [Google Scholar] [CrossRef]
- Bilge, Ü.; Ulusoy, G. A Time Window Approach to Simultaneous Scheduling of Machines and Material Handling System in an FMS. Oper Res. 1995, 43, 1058–1070. [Google Scholar] [CrossRef]
- Kumar, M.V.S.; Janardhana, R.; Rao, C.S.P. Simultaneous Scheduling of Machines and Vehicles in an FMS Environment with Alternative Routing. Int. J. Adv. Manuf. Technol. 2011, 53, 339–351. [Google Scholar] [CrossRef]
- Babu, A.G.; Jerald, J.; Haq, A.N.; Luxmi, V.M.; Vigneswaralu, T.P. Scheduling of Machines and Automated Guided Vehicles in FMS Using Differential Evolution. Int. J. Prod. Res. 2010, 48, 4683–4699. [Google Scholar] [CrossRef]
- Zhang, Q.; Manier, H.; Manier, M.-A. A Genetic Algorithm with Tabu Search Procedure for Flexible Job Shop Scheduling with Transportation Constraints and Bounded Processing Times. Comput. Oper. Res. 2012, 39, 1713–1723. [Google Scholar] [CrossRef]
- Zhang, Q.; Manier, H.; Manier, M.-A. A Modified Shifting Bottleneck Heuristic and Disjunctive Graph for Job Shop Scheduling Problems with Transportation Constraints. Int. J. Prod. Res. 2014, 52, 985–1002. [Google Scholar] [CrossRef]
- Deroussi, L. A Hybrid PSO Applied to the Flexible Job Shop with Transport. In Swarm Intelligence Based Optimization, Proceedings of the First International Conference, ICSIBO 2014, Mulhouse, France, 13–14 May 2014; Springer: Cham, Switzerland, 2014; pp. 115–122. [Google Scholar]
- Nouri, H.E.; Driss, O.B.; Ghédira, K. Simultaneous Scheduling of Machines and Transport Robots in Flexible Job Shop Environment Using Hybrid Metaheuristics Based on Clustered Holonic Multiagent Model. Comput. Ind. Eng. 2016, 102, 488–501. [Google Scholar] [CrossRef]
- Ham, A. Transfer-Robot Task Scheduling in Flexible Job Shop. J. Intell. Manuf. 2020, 31, 1783–1793. [Google Scholar] [CrossRef]
- Homayouni, S.M.; Fontes, D.B.M.M. Production and Transport Scheduling in Flexible Job Shop Manufacturing Systems. J. Glob. Optim. 2021, 79, 463–502. [Google Scholar] [CrossRef]
- Li, J.; Deng, J.; Li, C.; Han, Y.; Tian, J.; Zhang, B.; Wang, C. An improved Jaya algorithm for solving the flexible job shop scheduling problem with transportation and setup times. KBS 2020, 200, 106032. [Google Scholar] [CrossRef]
- Ren, W.; Yan, Y.; Hu, Y.; Guan, Y. Joint optimisation for dynamic flexible job-shop scheduling problem with transportation time and resource constraints. Int. J. Prod. Res. 2021, 60, 5675–5696. [Google Scholar] [CrossRef]
- Elahipanah, M.; Desaulniers, G.; Lacasse-Guay, È. A Two-Phase Mathematical-Programming Heuristic for Flexible Assignment of Activities and Tasks to Work Shifts. J. Sched. 2013, 16, 443–460. [Google Scholar] [CrossRef]
- Absi, N.; Archetti, C.; Dauzère-Pérès, S.; Feillet, D. A Two-Phase Iterative Heuristic Approach for the Production Routing Problem. Transp. Sci. 2015, 49, 784–795. [Google Scholar] [CrossRef]
- Ríos-Solís, Y.A.; Ibarra-Rojas, O.J.; Cabo, M.; Possani, E. A Heuristic Based on Mathematical Programming for a Lot-Sizing and Scheduling Problem in Mold-Injection Production. Eur. J. Oper. Res. 2020, 284, 861–873. [Google Scholar] [CrossRef]
- Ball, M.O. Heuristics Based on Mathematical Programming. Surv. Oper. Res. Manag. Sci. 2011, 16, 21–38. [Google Scholar] [CrossRef]
- Karimi, S.; Ardalan, Z.; Naderi, B.; Mohammadi, M. Scheduling Flexible Job-Shops with Transportation Times: Mathematical Models and a Hybrid Imperialist Competitive Algorithm. Appl. Math. Model. 2017, 41, 667–682. [Google Scholar] [CrossRef]
- Özgüven, C.; Özbakır, L.; Yavuz, Y. Mathematical Models for Job-Shop Scheduling Problems with Routing and Process Plan Flexibility. Appl. Math. Model. 2010, 34, 1539–1548. [Google Scholar] [CrossRef]
- Cortés, C.E.; Matamala, M.; Contardo, C. The Pickup and Delivery Problem with Transfers: Formulation and a Branch-and-Cut Solution Method. Eur. J. Oper. Res. 2010, 200, 711–724. [Google Scholar] [CrossRef]
- Rais, A.; Alvelos, F.; Carvalho, M.S. New Mixed Integer-Programming Model for the Pickup-and-Delivery Problem with Transshipment. Eur. J. Oper. Res. 2014, 235, 530–539. [Google Scholar] [CrossRef]
- Fattahi, P.; Mehrabad, M.S.; Jolai, F. Mathematical Modeling and Heuristic Approaches to Flexible Job Shop Scheduling Problems. J. Intell. Manuf. 2007, 18, 331–342. [Google Scholar] [CrossRef]
- Hart, W.E.; Watson, J.; Woodruff, D.L. Pyomo: Modeling and Solving Mathematical Programs in Python. Math. Program. Comput. 2011, 3, 219–260. [Google Scholar] [CrossRef]
- Hart, W.E.; Laird, C.D.; Watson, J.; Woodruff, D.L.; Hackebeil, G.A.; Nicholson, B.L.; Siirola, J.D. Pyomo–Optimization Modeling in Python; Springer: Berlin, Germany, 2017; Volume 67, p. 277. [Google Scholar]
- Gurobi. Gurobi Optimizer Reference Manual. Available online: www.gurobi.com (accessed on 10 October 2022).
- CPU Benchmarks. Intel Xeon E5-1630 v4 @ 3.70GHz vs. Intel Core i7-6700 @ 3.40GHz. Available online: https://www.cpubenchmark.net/compare/Intel-Xeon-E5-1630-v4-vs-Intel-i7-6700/2827vs2598 (accessed on 10 October 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sets | |
|---|---|
| J | Set of jobs. |
| N | Set of operations, , where nj is the number of operations of job j, . |
| Nj | Set of operations of jobs indexed before job j. , total number of operations of jobs indexed before job j, where nj is total number of operations in a job j. By definition, |
| I | , index set of all operations, where overall, first operation is first operation of the first job, and the overall last operation is the last operation of last job. |
| Ij | Set of indices in I associated with job j in J. |
| M | Set of (original) machines. |
| Mi | Set of (original) machines that are capable of processing operation i. |
| Parameters | |
| pik | Processing time of operation i when processed by machine k, . |
| tkl | Distance between any two machines k and l, . |
| F | A large number used to bound FJSP + T constraints. |
| Variables | |
| Cmax | Makespan. |
| Cik | Completion time of operation i when processed by machine k, . |
| Sik | Start time of operation i when processed by machine k, . |
| Uik | 1, when machine k is selected to process operation i, . 0, otherwise. |
| Yi,i+1,k,l | 1, when consecutive operations i, i + 1 of a particular job j, are processed using machines k and l, respectively, . 0, otherwise. |
| Zihk | 1, operation i precedes operation h when processed by machine k, . 0, otherwise. |
| Sets | |
|---|---|
| Set of arcs | |
| Set of nodes | |
| J | Set of jobs |
| Set of transporters | |
| N’ | Set of stations, , where nj’ is the number of stations of job j, |
| Nj’ | Set of stations indexed before job j, , total number of stations of the jobs indexed before job j where nj’ is total number of stations in a particular job j. By definition, |
| I’ | , index set of all stations |
| Ij’ | set of indices in I’ associated with job j in J |
| O | Duplicated loading and unloading area |
| E | Duplicate of O |
| Dummy p node for job j, | |
| Set of duplicate machines | |
| Dummy d node for job j, , | |
| Set of all stations, | |
| p node(s) of any set of stations | |
| d node(s) of any set of stations | |
| Union of p nodes for job j, | |
| Union of d nodes for job j, | |
| Set of nodes connected to , forming arcs that directed towards | |
| Set of nodes connected to forming arcs that directed away | |
| Ordered (grouped) set of n consecutive duplicate machine ki, ki+1, … ki+n−1 within job j, , | |
| Set of all ordered sets of of job | |
| Set of singletons within job | |
| nth element of | |
| Set of nth elements within each | |
| Length of respective within . | |
| Set of singleton machines within job | |
| Union of p nodes comprising singletons and last station of each cluster within job | |
| Union of d nodes comprising singletons and first station of each cluster within job | |
| Set of machine stations duplicated from the original station k, | |
| Original machine obtained from inverse mapping of duplicated machine, | |
| Set containing permutations of elements, | |
| Ordered set of duplicate machines from different jobs | |
| Set of duplicate machine stations k, l, m: | |
| Ordered set of duplicate machines where, , completes processing before the next machine, , starts, | |
| Parameters | |
| pk’ | Processing time of duplicate machine k, |
| tkl’ | Distance between any two stations k and l, |
| G | A large number used to bound JSPT constraints |
| Variables | |
| Cmax’ | Makespan |
| Arrival time of transporter at node k, | |
| Departure time of transporter from node k, | |
| Ck’ | Completion time of operation processed by machine k, |
| Sk’ | Start time of operation processed by machine k, |
| Translated timing from . If a transporter travels from k to l, then . Otherwise, . | |
| 1, if machine k of job j, , finishes processing before machine l of another job j’, starts processing, 0, otherwise | |
| 1, 0, otherwise |
| Characteristics | 2-Phase | MILP | LAHC (1000) | LAHC (100) | MSB | GATS | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instance | M | J | O | A | Nodes | CMAX | σ % | Titer/run | Iterbest | CMAX | T | CMAX | σ % | CMAX | σ % | CMAX | CMAX | |||
| fjsp1 | 8 | 7 | 19 | 2 | 35 | 136 | 0 | 8.28 | 0.85 | 3 | 134 | 554 | 138 | 1.7 | 16 | 138 | 1.3 | 2.7 | 146 | 144 |
| fjsp2 | 8 | 6 | 15 | 2 | 29 | 114 | 0 | 3.68 | 0.8 | 4 | 114 | 17 | 114 | 1.4 | 9.2 | 114 | 1.1 | 2.3 | 118 | 118 |
| fjsp3 | 8 | 6 | 16 | 2 | 30 | 120 | 0 | 0.84 | 0.12 | 2 | 120 | 4 | 120 | 1.2 | 16 | 120 | 1.1 | 2.4 | 124 | 124 |
| fjsp4 | 8 | 5 | 19 | 2 | 31 | 118 | 0 | 3.18 | 0.15 | 2 | 114 | 281 | 114 | 2.5 | 22 | 118 | 1.3 | 3 | 124 | 124 |
| fjsp5 | 8 | 5 | 13 | 2 | 25 | 94 | 0 | 0.97 | 0.06 | 5 | 94 | 2 | 94 | 0 | 6 | 94 | 0 | 2.1 | 94 | 94 |
| fjsp6 | 8 | 6 | 18 | 2 | 32 | 138 | 0 | 18 | 3.26 | 5 | 138 | 42 | 138 | 1.1 | 18 | 142 | 0.9 | 2.7 | 144 | 144 |
| fjsp7 | 8 | 8 | 19 | 2 | 37 | 112 | 0 | 272.9 | 14.89 | 8 | 110 | 9852 | 112 | 2.2 | 15 | 114 | 1.6 | 2.7 | 122 | 122 |
| fjsp8 | 8 | 6 | 20 | 2 | 34 | 178 | 0 | 6.6 | 4.05 | 1 | 178 | 132 | 178 | 0.6 | 21 | 178 | 0.9 | 3.1 | 180 | 181 |
| fjsp9 | 8 | 5 | 17 | 2 | 29 | 146 | 0 | 11.4 | 1.14 | 13 | 144 | 43 | 144 | 1.5 | 16 | 144 | 1.4 | 2.6 | 146 | 150 |
| fjsp10 | 8 | 6 | 21 | 2 | 35 | 174 | 0 | 236 | 3.95 | 60 | 174 | 1397 | 174 | 0.9 | 28 | 174 | 1.4 | 3.3 | 178 | 178 |
| Characteristics | 2-Phase | MILP | LAHC (1000) | LAHC (100) | PDE-1 | PDE-2 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instance | M | J | O | A | Nodes | CMAX | σ % | Titer/run | Iterbest | CMAX | T | CMAX | σ % | CMAX | σ % | CMAX | CMAX | |||
| EX_110 | 4 | 5 | 13 | 3 | 25 | 94 | 0 | 0.18 | 1.55 | 1 | 94 | 37 | 94 | 2.23 | 9.3 | 94 | 2.28 | 3.6 | 96 | 94 |
| EX_210 | 4 | 6 | 15 | 3 | 29 | 105 | 0 | 16.44 | 4.05 | 4 | 104 | 1206 | 104 | 1.61 | 11.2 | 106 | 1.23 | 4.3 | 104 | 104 |
| EX_410 | 4 | 5 | 19 | 3 | 31 | 92 | 0 | 29.27 | 3.94 | 8 | — | — | 92 | 2.25 | 28 | 92 | 2.11 | 4.8 | 92 | 92 |
| EX_510 | 4 | 5 | 13 | 3 | 25 | 77 | 0 | 0.41 | 0.25 | 1 | 77 | 28 | 77 | 0 | 7.8 | 77 | 0 | 3.6 | 77 | 77 |
| EX_710 | 4 | 8 | 19 | 3 | 37 | 102 | 1.03 | 55.23 | 4.27 | 13 | — | — | 103 | 1.78 | 11.4 | 104 | 1.76 | 3.7 | 103 | 103 |
| EX_810 | 4 | 6 | 20 | 3 | 34 | 141 | 0.28 | 52.87 | 4.06 | 13 | — | — | 141 | 1.57 | 20 | 142 | 1.76 | 4 | 142 | 142 |
| EX_910 | 4 | 5 | 17 | 3 | 29 | 118 | 0 | 32.42 | 4.05 | 8 | 118 | 1825 | 118 | 1.51 | 19.2 | 121 | 1.32 | 5.5 | — | — |
| EX_120 | 4 | 5 | 13 | 3 | 25 | 91 | 0 | 2.4 | 2.06 | 2 | 91 | 24 | 91 | 1.71 | 10.4 | 93 | 1 | 3.5 | 96 | 93 |
| EX_220 | 4 | 6 | 15 | 3 | 29 | 102 | 0 | 4.26 | 4.04 | 1 | 102 | 979 | 102 | 1.33 | 11 | 103 | 0.88 | 3.6 | — | — |
| EX_420 | 4 | 5 | 19 | 3 | 31 | 88 | 0 | 12.37 | 4.04 | 3 | 88 | 6526 | 88 | 2.42 | 27.2 | 88 | 2.16 | 4.4 | 88 | 91 |
| EX_520 | 4 | 5 | 13 | 3 | 25 | 76 | 0 | 0.27 | 0.25 | 1 | 76 | 13 | 76 | 0 | 6 | 76 | 0 | 3.5 | 76 | 76 |
| EX_720 | 4 | 8 | 19 | 3 | 37 | 98 | 0 | 23.04 | 4.16 | 5 | — | — | 99 | 1.57 | 12.8 | 100 | 2.03 | 3.3 | 100 | 100 |
| EX_820 | 4 | 6 | 20 | 3 | 34 | 138 | 0.57 | 24.83 | 4.06 | 6 | — | — | 138 | 2.03 | 21.4 | 138 | 2.17 | 3.8 | 138 | 140 |
| EX_920 | 4 | 5 | 17 | 3 | 29 | 116 | 0 | 35.78 | 4.04 | 9 | 116 | 2535 | 116 | 1.68 | 18 | 118 | 1.27 | 4.5 | — | — |
| EX_130 | 4 | 5 | 13 | 3 | 25 | 92 | 0 | 0.78 | 1.66 | 1 | 92 | 31 | 92 | 1.53 | 5.5 | 92 | 1.93 | 3.4 | 92 | 92 |
| EX_230 | 4 | 6 | 15 | 3 | 29 | 102 | 0 | 8.42 | 4.03 | 2 | 102 | 1290 | 102 | 1.48 | 11.9 | 103 | 1.52 | 2.7 | 102 | 102 |
| EX_430 | 4 | 5 | 19 | 3 | 31 | 89 | 0 | 11.82 | 4.03 | 3 | 89 | 4723 | 89 | 2.64 | 25 | 90 | 2.3 | 4.2 | 92 | 91 |
| EX_530 | 4 | 5 | 13 | 3 | 25 | 77 | 0 | 0.27 | 0.19 | 1 | 77 | 11 | 77 | 0 | 6.6 | 77 | 0.34 | 3.4 | 77 | 77 |
| EX_730 | 4 | 8 | 19 | 3 | 37 | 100 | 0 | 15.43 | 4.16 | 3 | — | — | 101 | 1.58 | 13.2 | 101 | 1.67 | 3.5 | 101 | 102 |
| EX_830 | 4 | 6 | 20 | 3 | 34 | 139 | 0 | 4.27 | 4.06 | 1 | — | — | 139 | 1.43 | 20.3 | 139 | 2.33 | 3.9 | 141 | 141 |
| EX_930 | 4 | 5 | 17 | 3 | 29 | 117 | 0 | 8.37 | 4.09 | 2 | 117 | 624 | 118 | 1.46 | 13.2 | 119 | 2.03 | 4.5 | — | — |
| EX_140 | 4 | 5 | 13 | 3 | 25 | 97 | 0 | 11.77 | 1.54 | 9 | 97 | 89 | 97 | 2.04 | 6.9 | 97 | 2.93 | 3.3 | 99 | 99 |
| EX_241 | 4 | 6 | 15 | 3 | 29 | 153 | 0 | 4.36 | 4.04 | 1 | 153 | 73 | 154 | 1.34 | 13.5 | 154 | 1.37 | 4 | 154 | 157 |
| EX_441 | 4 | 5 | 19 | 3 | 31 | 131 | 1.07 | 63.43 | 4.05 | 16 | 131 | 12,727 | 134 | 1.45 | 28.6 | 134 | 1.67 | 4.5 | 135 | 134 |
| EX_541 | 4 | 5 | 13 | 3 | 25 | 113 | 0 | 0.22 | 0.82 | 1 | 113 | 15 | 113 | 0 | 8.2 | 113 | 0.23 | 3.5 | 113 | 113 |
| EX_740 | 4 | 8 | 19 | 3 | 37 | 104 | 0.96 | 57.92 | 4.43 | 12 | — | — | 105 | 2.07 | 17.9 | 105 | 2.31 | 3.6 | 107 | 107 |
| EX_741 | 4 | 8 | 19 | 3 | 37 | 149 | 1.41 | 44.88 | 4.31 | 10 | — | — | 150 | 1.53 | 14.7 | 151 | 1.38 | 3.6 | 151 | 150 |
| EX_840 | 4 | 6 | 20 | 3 | 34 | 144 | 0.28 | 52.94 | 4.06 | 13 | — | — | 144 | 1.2 | 26.4 | 147 | 1.54 | 4 | 147 | 144 |
| EX_940 | 4 | 5 | 17 | 3 | 29 | 120 | 1.96 | 50.55 | 4.05 | 13 | 119 | 3256 | 121 | 1.16 | 13.7 | 122 | 2.27 | 5.7 | — | — |
| Characteristics | 2-Phase | MILP | LAHC (1000) | LAHC (100) | PDE-1 | PDE-2 | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instance | M | J | O | A | Nodes | CMAX | σ % | Titer/run | Iterbest | CMAX | T | CMAX | σ % | CMAX | σ % | CMAX | CMAX | |||
| EX_11 | 4 | 5 | 13 | 3 | 25 | 70 | 0 | 4.68 | 1.33 | 10 | 70 | 1619 | 70 | 0.7 | 10.2 | 70 | 2.26 | 3.6 | 74 | 74 |
| EX_21 | 4 | 6 | 15 | 3 | 29 | 74 | 0 | 6.62 | 1.96 | 4 | — | — | 74 | 2.38 | 11.8 | 74 | 2.38 | 3.7 | 77 | 77 |
| EX_41 | 4 | 5 | 19 | 3 | 31 | 72 | 0 | 3.06 | 2.02 | 2 | — | — | 72 | 0 | 26.7 | 72 | 1.89 | 4.6 | 73 | 73 |
| EX_51 | 4 | 5 | 13 | 3 | 25 | 61 | 0 | 12.29 | 1.72 | 11 | 59 | 872 | 59 | 2.14 | 9.3 | 59 | 1.65 | 3.2 | 61 | 61 |
| EX_71 | 4 | 8 | 19 | 3 | 37 | 81 | 0 | 35.33 | 5.58 | 6 | — | — | 81 | 1.8 | 22.6 | 81 | 1.67 | 4.2 | 81 | 81 |
| EX_81 | 4 | 6 | 20 | 3 | 34 | 95 | 1.84 | 57.56 | 2.06 | 28 | — | — | 94 | 1.59 | 38.3 | 95 | 2.45 | 4.8 | 93 | 94 |
| EX_91 | 4 | 5 | 17 | 3 | 29 | 82 | 0 | 6.46 | 1.84 | 6 | — | — | 82 | 1.77 | 20.7 | 82 | 1.37 | 4.4 | 82 | 82 |
| EX_12 | 4 | 5 | 13 | 3 | 25 | 56 | 0 | 46.91 | 1.45 | 38 | 56 | 267 | 56 | 3.54 | 11.8 | 56 | 3.05 | 3.8 | 59 | 59 |
| EX_22 | 4 | 6 | 15 | 3 | 29 | 63 | 0 | 14.78 | 1.96 | 8 | 61 | 18,899 | 62 | 1.64 | 25.6 | 63 | 1.96 | 3.6 | 62 | 63 |
| EX_42 | 4 | 5 | 19 | 3 | 31 | 56 | 5.27 | 50.93 | 2 | 26 | — | — | 56 | 2.74 | 27.4 | 59 | 1.91 | 4.6 | 60 | 60 |
| EX_52 | 4 | 5 | 13 | 3 | 25 | 47 | 0 | 53.72 | 1.68 | 36 | 47 | 274 | 48 | 2.45 | 8.9 | 48 | 2.06 | 3.3 | 50 | 50 |
| EX_72 | 4 | 8 | 19 | 3 | 37 | 63 | 1.43 | 83.53 | 2.63 | 30 | — | — | 62 | 2.27 | 15.5 | 63 | 4.18 | 4.2 | 63 | 64 |
| EX_82 | 4 | 6 | 20 | 3 | 34 | 83 | 1.14 | 46.18 | 4.04 | 12 | — | — | 82 | 1.32 | 32.8 | 84 | 1.55 | 5 | 83 | 83 |
| EX_92 | 4 | 5 | 17 | 3 | 29 | 72 | 0 | 37.24 | 3.22 | 16 | 69 | 3744 | 69 | 2.24 | 21.7 | 70 | 1.66 | 4.3 | 71 | 71 |
| EX_13 | 4 | 5 | 13 | 3 | 25 | 62 | 0 | 3.62 | 1.24 | 8 | 62 | 108 | 62 | 0.96 | 11.3 | 62 | 1.03 | 3.7 | 64 | 64 |
| EX_23 | 4 | 6 | 15 | 3 | 29 | 67 | 0 | 77.92 | 1.97 | 40 | — | — | 67 | 1.37 | 12.5 | 67 | 1.51 | 3.6 | 67 | 67 |
| EX_43 | 4 | 5 | 19 | 3 | 31 | 62 | 0 | 10.61 | 3.64 | 4 | — | — | 61 | 1.62 | 28.1 | 62 | 2.72 | 4.6 | 66 | 64 |
| EX_53 | 4 | 5 | 13 | 3 | 25 | 53 | 1.04 | 68.14 | 1.82 | 40 | 52 | 614 | 52 | 2.4 | 9 | 52 | 1.7 | 3.5 | 52 | 52 |
| EX_73 | 4 | 8 | 19 | 3 | 37 | 66 | 2.88 | 26.08 | 2.99 | 6 | — | — | 66 | 3.21 | 13.9 | 66 | 3.15 | 4 | 68 | 69 |
| EX_83 | 4 | 6 | 20 | 3 | 34 | 86 | 0 | 59.8 | 4.05 | 15 | — | — | 85 | 1.71 | 35.2 | 87 | 1.58 | 4.8 | 84 | 84 |
| EX_93 | 4 | 5 | 17 | 3 | 29 | 74 | 0 | 35.26 | 1.84 | 21 | — | — | 73 | 2.38 | 19.3 | 73 | 1.79 | 4.3 | 74 | 74 |
| EX_14 | 4 | 5 | 13 | 3 | 25 | 78 | 0 | 4.21 | 1.21 | 9 | 78 | 920 | 78 | 1.07 | 10.4 | 78 | 1.28 | 3.8 | 80 | 80 |
| EX_24 | 4 | 6 | 15 | 3 | 29 | 84 | 0 | 27.19 | 2.09 | 13 | — | — | 84 | 1.99 | 16.8 | 84 | 1.94 | 3.6 | 87 | 87 |
| EX_44 | 4 | 5 | 19 | 3 | 31 | 80 | 0 | 28.2 | 2.02 | 14 | — | — | 80 | 1.14 | 27.8 | 80 | 2.16 | 4.9 | 83 | 83 |
| EX_54 | 4 | 5 | 13 | 3 | 25 | 64 | 0 | 28.4 | 1.63 | 22 | 64 | 1273 | 64 | 2.63 | 12.5 | 64 | 2.89 | 3.3 | 70 | 70 |
| EX_74 | 4 | 8 | 19 | 3 | 37 | 97 | 2.47 | 81.29 | 6.03 | 14 | — | — | 94 | 2.14 | 22.3 | 95 | 2.2 | 4.1 | 100 | 100 |
| EX_84 | 4 | 6 | 20 | 3 | 34 | 106 | 2.03 | 106.53 | 4.49 | 23 | — | — | 102 | 2.15 | 40.6 | 106 | 2.15 | 4.9 | 107 | 105 |
| EX_94 | 4 | 5 | 17 | 3 | 29 | 91 | 0 | 0.64 | 1.79 | 1 | — | — | 87 | 1.56 | 22.1 | 87 | 1.8 | 4.3 | 90 | 90 |
| Characteristics | 2-Phase | MILP | LAHC (1000) | LAHC (100) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Instance | M | J | O | A | Nodes | CMAX | σ % | Titer/run | Iterbest | CMAX | T | CMAX | σ % | CMAX | σ % | |||
| SFJST01 | 2 | 2 | 4 | 2 | 10 | 70 | 0 | 0.04 | 0.02 | 1 | 70 | 0.2 | 70 | 0 | 1.2 | 70 | 0 | 1.2 |
| SFJST02 | 2 | 2 | 4 | 1.5 | 10 | 111 | 0 | 0.02 | 0.002 | 1 | 111 | 0.2 | 111 | 0 | 1.3 | 111 | 0 | 1.4 |
| SFJST03 | 2 | 3 | 6 | 1.7 | 14 | 223 | 0 | 0.04 | 0.02 | 1 | 223 | 0.3 | 223 | 0 | 1.5 | 223 | 0 | 1.5 |
| SFJST04 | 2 | 3 | 6 | 1.7 | 14 | 359 | 0 | 0.05 | 0.02 | 1 | 359 | 0.3 | 359 | 0 | 1.5 | 359 | 0 | 1.4 |
| SFJST05 | 2 | 3 | 6 | 2 | 14 | 123 | 0 | 0.11 | 0.12 | 1 | 123 | 0.4 | 123 | 0 | 1.3 | 123 | 0 | 1.4 |
| SFJST06 | 3 | 3 | 9 | 1.7 | 17 | 324 | 0 | 0.09 | 0.13 | 1 | 324 | 0.4 | 324 | 0 | 1.9 | 324 | 0 | 1.9 |
| SFJST07 | 5 | 3 | 9 | 2 | 17 | 409 | 0 | 0.07 | 0.08 | 1 | 409 | 0.4 | 409 | 0 | 1.9 | 409 | 0 | 1.8 |
| SFJST08 | 4 | 3 | 9 | 2 | 17 | 269 | 0 | 0.16 | 0.19 | 1 | 269 | 0.6 | 269 | 0 | 5 | 269 | 0 | 2 |
| SFJST09 | 3 | 3 | 9 | 2 | 17 | 220 | 0 | 0.12 | 0.25 | 1 | 220 | 0.4 | 220 | 0 | 2.4 | 220 | 0 | 1.9 |
| SFJST10 | 5 | 4 | 12 | 1.7 | 22 | 531 | 0 | 0.15 | 0.1 | 1 | 531 | 0.5 | 531 | 0 | 4.6 | 531 | 0 | 2.4 |
| MFJST01 | 6 | 5 | 15 | 2.2 | 27 | 485 | 0 | 1.82 | 1.08 | 2 | 485 | 6 | 485 | 0.16 | 9.9 | 485 | 0.5 | 2.7 |
| MFJST02 | 7 | 5 | 15 | 2.6 | 27 | 463 | 0 | 1.41 | 2.29 | 1 | 463 | 14 | 463 | 0.86 | 12.5 | 463 | 0.83 | 2.5 |
| MFJST03 | 7 | 6 | 18 | 2.7 | 32 | 482 | 0 | 8.39 | 4 | 2 | 482 | 59 | 482 | 1.02 | 30.9 | 482 | 2.4 | 2.8 |
| MFJST04 | 7 | 7 | 21 | 2.7 | 37 | 576 | 0 | 5.45 | 4.09 | 1 | 576 | 3277 | 576 | 0.85 | 45.5 | 576 | 1.87 | 3.4 |
| MFJST05 | 7 | 7 | 21 | 2.6 | 37 | 532 | 0 | 8.39 | 4.04 | 2 | 532 | 694 | 532 | 2.15 | 47.3 | 532 | 2.54 | 3.5 |
| MFJST06 | 7 | 8 | 24 | 2.6 | 42 | 652 | 0 | 5.78 | 4.12 | 1 | 652 | 34,796 | 652 | 2.41 | 37.2 | 652 | 1.98 | 4 |
| MFJST07 | 7 | 8 | 32 | 2.4 | 50 | 898 | 0 | 34.03 | 30.22 | 1 | — | — | 898 | 3.58 | 109.4 | 907 | 2.75 | 5.8 |
| MFJST08 | 8 | 9 | 36 | 2.4 | 56 | 900 | 0 | 52.06 | 30.62 | 1 | — | — | 900 | 3.85 | 149.1 | 918 | 3.74 | 6.7 |
| MFJST09 | 8 | 11 | 44 | 2.3 | 68 | 1098 | 0 | 281.82 | 54.68 | 3 | — | — | 1120 | 1.46 | 202.1 | 1181 | 2.64 | 8.6 |
| MFJST10 | 8 | 12 | 48 | 2.3 | 74 | 1230 | 0.65 | 996.23 | 75.72 | 12 | — | — | 1238 | 1.87 | 232.4 | 1310 | 2.61 | 9.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, C.H.; Moon, S.K. A Two-Phase Iterative Mathematical Programming-Based Heuristic for a Flexible Job Shop Scheduling Problem with Transportation. Appl. Sci. 2023, 13, 5215. https://doi.org/10.3390/app13085215
Lim CH, Moon SK. A Two-Phase Iterative Mathematical Programming-Based Heuristic for a Flexible Job Shop Scheduling Problem with Transportation. Applied Sciences. 2023; 13(8):5215. https://doi.org/10.3390/app13085215
Chicago/Turabian StyleLim, Che Han, and Seung Ki Moon. 2023. "A Two-Phase Iterative Mathematical Programming-Based Heuristic for a Flexible Job Shop Scheduling Problem with Transportation" Applied Sciences 13, no. 8: 5215. https://doi.org/10.3390/app13085215