3.1. Overall Structure
In this paper, a continuous subgraph matching scheme that can solve the problems of existing continuous subgraph matching algorithms is proposed. In the proposed method, a query refers to a request for subgraph matching. When a graph stream is input, the proposed method performs a filter-then-verify (FTV) process based on trie indexing to respond to a query on continuous subgraph matching. It is more efficient to handle the same or similar queries at once than to handle each registered query in the process of managing queries on continuous subgraph matching based on a graph stream updated in real time. Hence, the proposed algorithm indexes a common pattern of queries by considering the redundancy of queries. It performs continuous subgraph matching by comparing a graph stream updated in real time with indexed queries. The intermediate query results should be contained in the memory and used owing to the characteristics of continuous query processing. To reuse intermediate query results efficiently, the proposed method generates intermediate query results in the form of a materialized view and manages these results based on a cache.
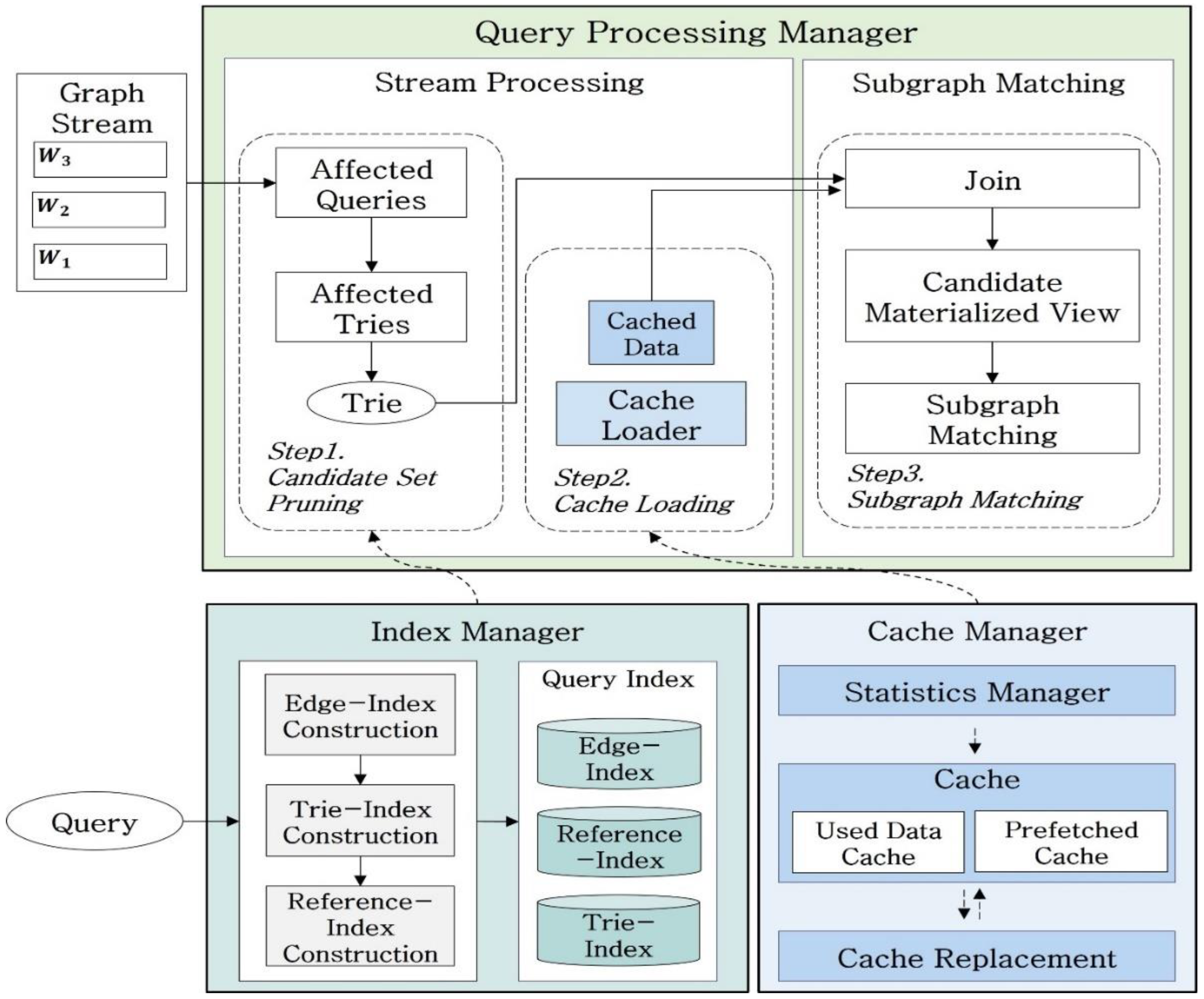
Figure 1 shows the overall system structure of the proposed method, which consists of an Index Manager, Cache Manager, and Query Processing Manager. The Query Processing Manager comprises a stream processing module that performs graph stream processing and a subgraph matching module that performs subgraph matching in response to queries. The Index Manager conducts the process of indexing a query graph, called query indexing, in advance. Trie query indexing is applied to respond to multiple subgraph matching queries efficiently. The Query Processing Manager conducts continuous subgraph matching based on a graph stream updated in real time. The stream processing module extracts a set of candidates for subgraph matching based on a graph stream. This module uses existing intermediate results loaded in a cache to execute query processing efficiently. The subgraph matching module performs join operations by using a set of candidates for subgraph matching and the intermediate results loaded in a cache. Through join operations, a material view that represents intermediate results is generated. Based on the materialized view, the proposed method performs final subgraph matching. The Cache Manager conducts query processing based on a two-level caching technique and constantly records statistical data based on the Statistics Manager. When the space of a cache is insufficient, the statistics-based cache replacement strategies proposed herein are adopted to replace data in a cache.
In this study, a graph is defined as G = (V, E, L(V), L(E)) where a direction and label are applied. V is a set of vertices, E is a set of edges, L(V) is a set of labels of vertices, and L€ is a set of labels of edges. Each vertex (v∈V) has a unique number (v_id) and unique label (v_label). Each edge (e∈E) is a pair of vertices (e = (s, t)). Here, s is a root vertex (source vertex), and t is an end vertex (target vertex). A query graph is defined as Qi = (VQi, EQi, L(V), L(E)). A graph stream is input based on the unit of a sliding window. It is assumed that a graph stream is input in the form of an edge stream (v1_id, v2_id, v1_label, v2_label, and e_label, t). The unique numbers and labels of each vertex and the labels of each edge are input. Here, t refers to the time of generation of a graph stream.
3.2. Index Manager
A uniform response to a common pattern of queries is an efficient method for multiple subgraph matching processing tasks. The Index Manager is used to analyze patterns of duplicated queries and index a duplicated query area. When common patterns are indexed at once, the cost of indexing new similar queries can be reduced. As the Index Manager calculates query processing results in a duplicated area, it also reduces the query processing cost. The query decomposition and indexing technique proposed by [
19] is used in this study. The Index Manager divides a query into max covering paths, which are a set of the shortest paths including all the vertices and edges of a query graph. A query Q
i is divided into k paths (MCP(Q
i) = {P
1, P
2, …, P
k}). The edge indexing process records information on a query (Q
i) including the corresponding edges of each path to determine a query affected by an input graph stream during query processing. The trie indexing process stores the edges of each path in trie nodes. Each node maintains its unique node number and information on parent nodes and child nodes. This process conducts join operations based on the parent and child nodes of the corresponding node during query processing to generate query results. The reference indexing process records reference information on the last terminal node in a path stored in the trie indexing process according to queries. The Index Manager detects a query affected by the edge indexing process and identifies the location of the node that contains the corresponding edges based on reference information. Based on the method described above, the Index Manager records queries with the same path in the same trie node and uses shared information on similar queries to respond to multiple queries efficiently.
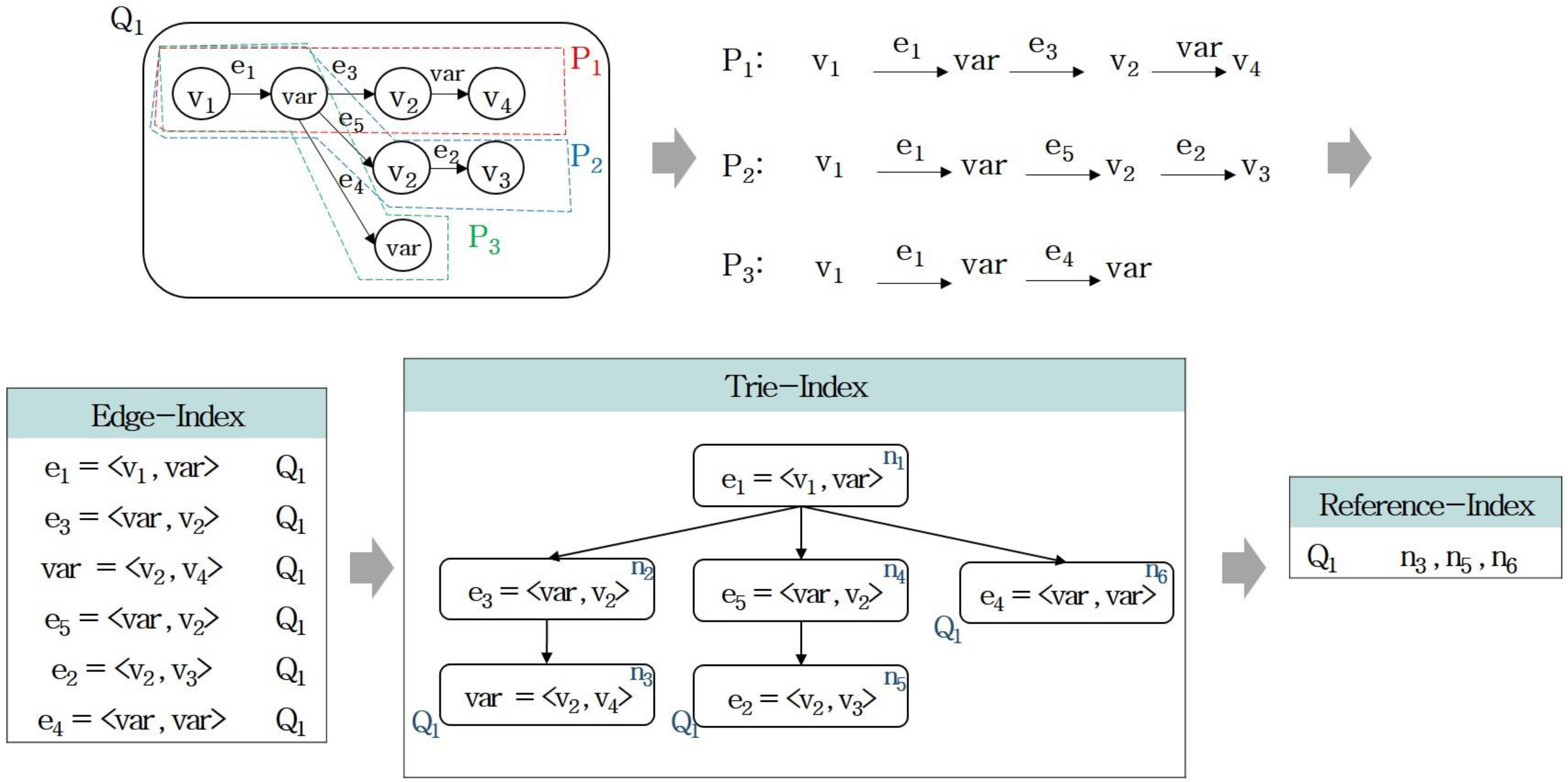
Figure 2 shows the process of indexing a query graph Q
1. Q
1 is divided into three max covering paths (MCP(Q
1) = {P
1, P
2, P
3}). For example, P
1 indicates the following three edges: e
1 = <v
1, var>, e
3 = <var, v
2>, and var = <v
2, v
4>. Here, var refers to a wildcard operation. This operation indicates that information on vertices and edges has not been specified and that vertices or edges can be randomly connected. The edge, trie, and reference indexing processes are applied to the max covering paths. In the edge indexing process, information on each edge of MCP(Q
1) and the current query (Q
1) included in the information on edges (e
1 = <v
1, var>, e
3 = <var, v
2>, and var = <v
2, v
4>) are stored in P
1. The trie indexing process stores edges included in each path in trie nodes. The edges (e
1 = <v
1, var>, e
3 = <var, v
2>, and e
2 = <v
2, v
4>) included in P
1 are stored in trie nodes n
1, n
2, and n
3. The reference indexing process stores a reference on the last location of a path and stores the reference information on a node (n
3) storing the last edge of P
1. Furthermore, e
1 = <v
1, var>, an edge found in each path of Q
1 in common, is stored in a node to facilitate path exchange.
Figure 3 shows a query graph Q
2 input under the condition where a query graph Q
1 is indexed. Like Q
1, Q
2 can also be divided into max covering paths. Consequently, Q
2 is divided into two max covering paths (MCP(Q
2) = {P
1, P
2}). When the edge indexing process indexes each max covering path, information on Q
2 is added to existing information on edges e
1 = <v
1, var> and e
4 = <var, var>. Accordingly, a new edge (e
2 = <v
1, var>) is added. The trie indexing process stores the edges of each path in trie nodes. When the path of Q
2 is equivalent to the existing path of Q
1, the corresponding trie node is shared. For example, P
1 (e
1 = <v
1, var>, e
4 = <var, var>) is equivalent to P
3, the path of Q
1. Consequently, the same trie node is shared. A newly created path is stored in the root node. Furthermore, e
2 = <v
1, var>, the edge of P
2, is stored in a new node n
7. In the reference indexing process, reference information {n
6, n
7} on the last terminal nodes in each path is added.
As the trie indexing technique shares the path observed in each query in common it can lead to the efficient indexing of similar queries.
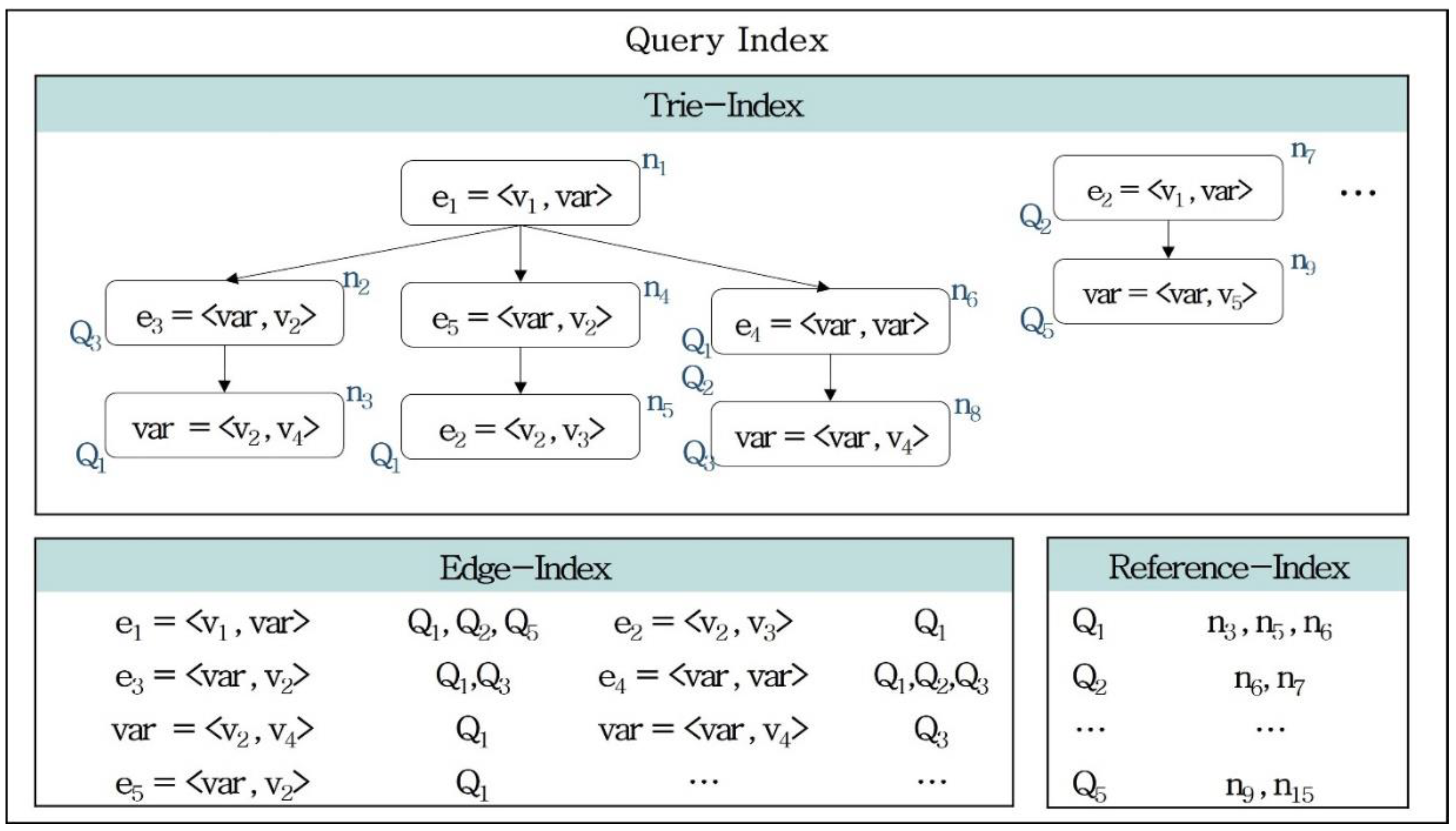
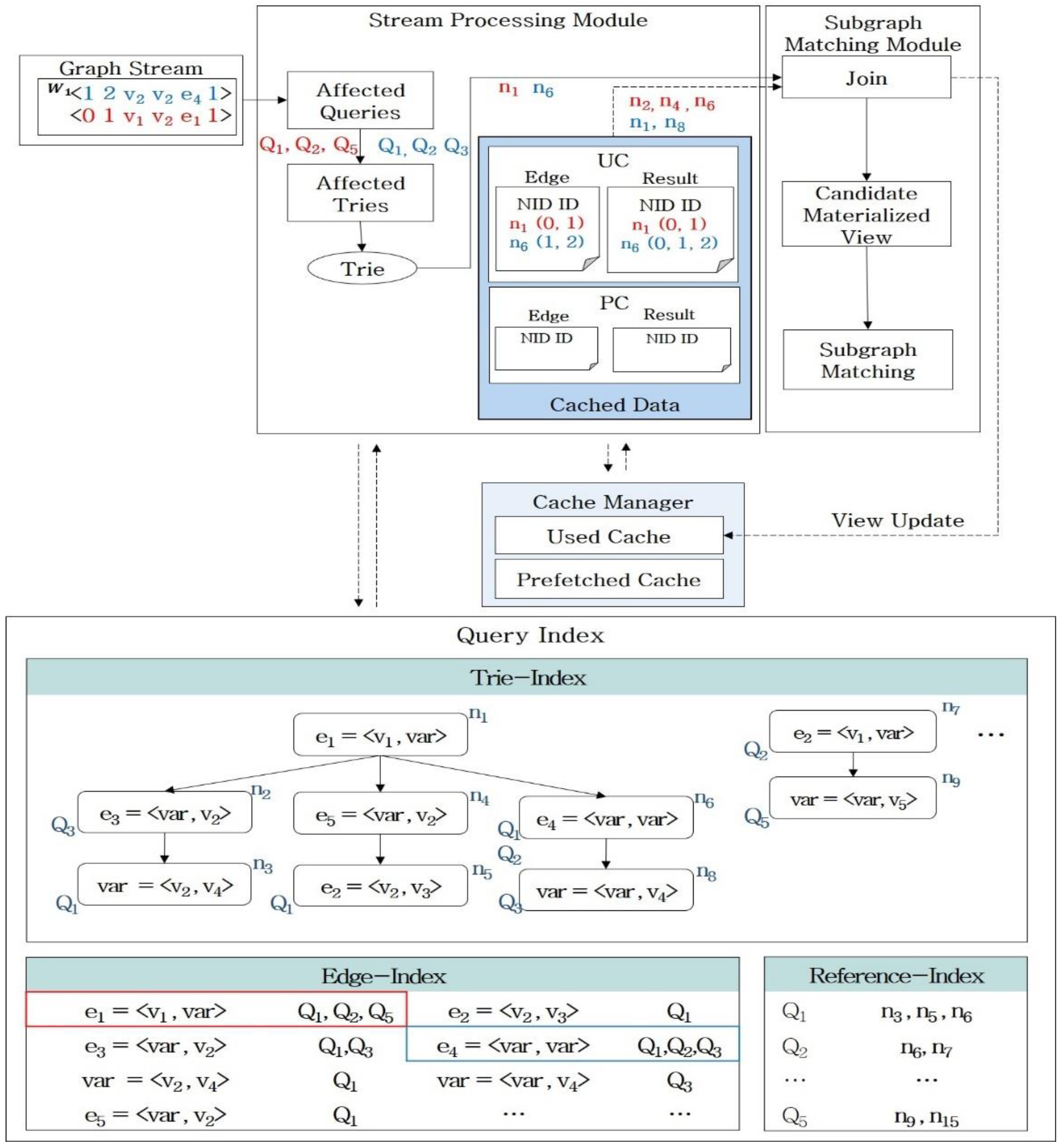
Figure 4 shows the indexing structure based on queries Q
1 to Q
5, including query graphs Q
1 and Q
2. The query indexing processes consist of trie indexing, edge indexing, and reference indexing.
3.3. Cache Manager
In this study, a two-level caching technique [
24] is developed to perform continuous subgraph matching efficiently in a limited memory environment. The developed algorithm is applied to facilitate efficient subgraph query processing. Existing intermediate results stored in a cache are used to perform query processing efficiently. A used cache manages intermediate query results that are frequently used in query processing, and a prefetched cache manages intermediate query results that are likely to be used for the next query processing task. To apply [
24] to this study, the trie indexing results and intermediate results were adjusted to be indexed. Accordingly, a prefetched cache was adjusted to manage the trie indexing results that are likely to be accessed. As for intermediate query results, information on the corresponding edges and information on results are separated for management. The information on edges includes the unique numbers of the corresponding edges recorded, whereas the information on results includes the unique numbers of join operation results. As the root trie node is regarded as results, both the information on edges and the information on results are updated to contain information on this node. When a target node is not the root trie node, the results on the current trie node are updated based on the information on the edges of the target node, the results on the parent trie node, and the results of the join operation. Moreover, the results on the child trie node are repeatedly updated based on the results on the current trie node, the information on the edges of the child trie node, and the results of the join operation.
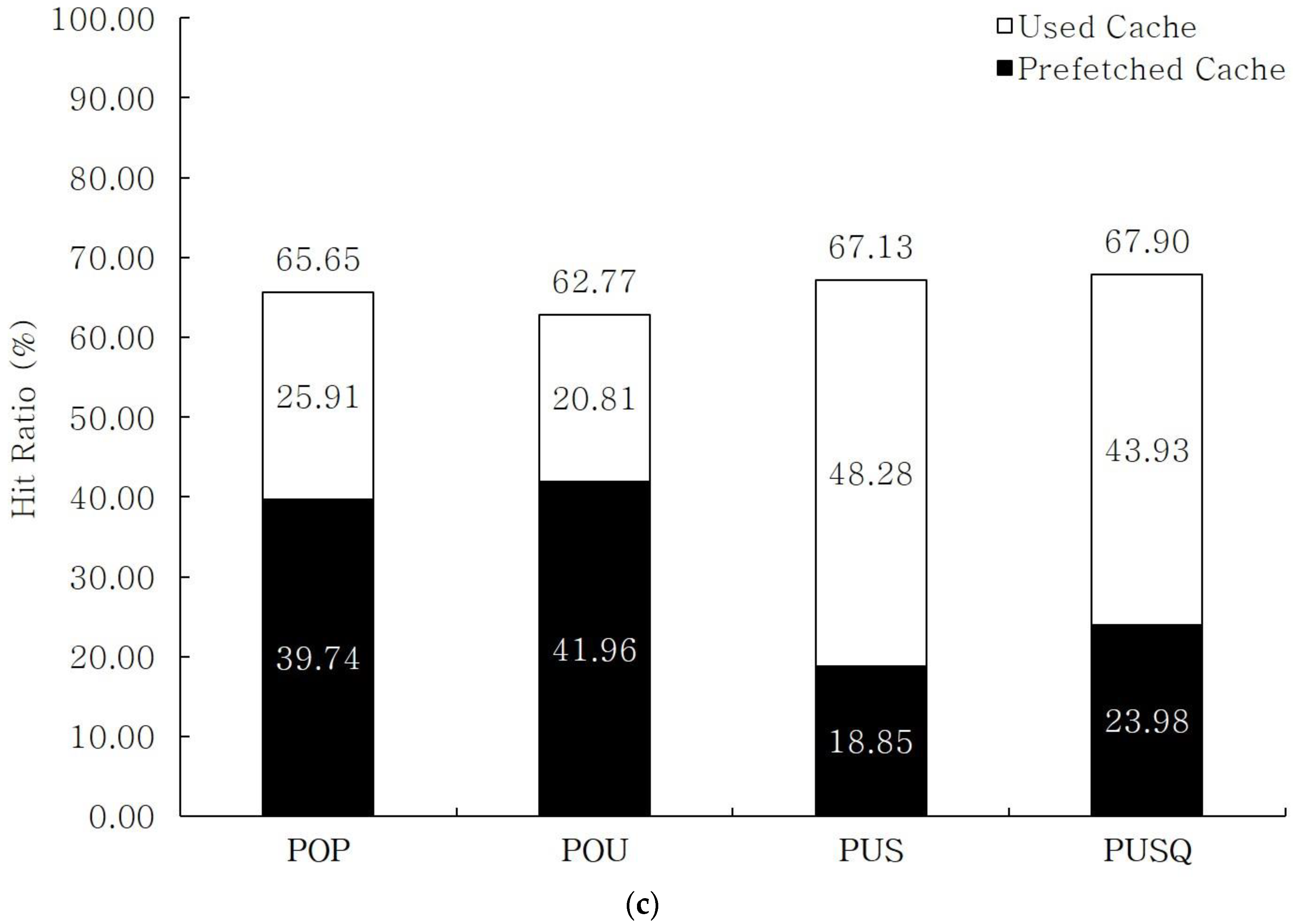
Figure 5 shows the operation of the Cache Manager.
Figure 5a is an example of the first window. When a graph stream <0, 1, v
1, v
2, e
1, 1> is input, this stream is compared with the trie indexing results to determine a candidate set {n
1} for subgraph matching. As the trie node n
1 is the root node, a prefetched cache loads intermediate results on the child trie nodes {n
2, n
4, n
6} of n
1 for query processing. These results are not loaded in the current cache, which does not contain any data. In the subgraph matching process, the Cache Manager updates information on a used cache and relevant statistical information. The information on edges for a used cache includes the unique numbers of trie nodes and the unique numbers of the vertices of edges used for query processing. Consequently, (n
1, (0, 1)) is recorded. As n
1 is the root node, it is regarded as query results. Consequently, the result on n1 (0, 1) is applied as intermediate query results in the form of a materialized view. Statistical information comprises the unique number of a trie node, load time, last hit time, the number of hits, the number of joins, and the size of the intermediate result. As for statistical information on n1, the Statistics Manager records a load time as the current window time 1 and the size of intermediate results as 2.
Figure 5b is an example of the second window. Like the processes described above, a candidate set {n
6} is determined based on an input stream. To perform the processing of a trie node (n
6) instead of the root node, intermediate results on the parent trie node (n
1) and the child trie node (n
8) in the form of a materialized view are loaded in a prefetched cache. A prefetched cache is used to load the data to be used for the next query processing in advance. Hence, when a used cache exists, it is instantly used. In (a), n
1 is loaded in a cache while it is used for query processing. Hence, it is resident in a used cache. Then, subgraph matching based on the loaded data is conducted. The result on n
6 (0, 1, 2) is updated as the intermediate result in the form of a materialized view based on the result on the parent trie node (n
1) loaded in a cache and join operation results. As for statistical information on n6, the Statistics Manager records a load time as the current window time 1 and the size of intermediate results as 3. It also updates statistical information on n1 by applying the last hit time as 1, the number of hits as 1, and the number of joins as 1. When the size of the data to be loaded exceeds the size of the cache, cache replacement based on statistical information and a cache replacement strategy is performed.
When graph data are input, the Query Processing Manager undergoes the FTV process based on trie indexing to implement query processing. To perform query processing efficiently, it uses intermediate results loaded in a cache. The Cache Manager uses the Statistics Manager to record the load time of a cache, the number of hits, the number of joins, and the size of intermediate results constantly. When the space of a cache is insufficient, the statistics-based cache replacement strategy is adopted to replace the data in a cache.
When a cache of limited capacity becomes full of necessary subgraphs for query processing, the subgraphs stored in a cache should be replaced. At this time, the Cache Manager manages statistical data according to subgraph matching query processing and conducts a cache replacement based on the updated statistical information.
Table 1 shows an example of a statistical table. ID is the unique number of a node, load time (LT) is the time of data loading, last hit (LH) is the last time a cache was hit, the number of hits (H) is the number of successful hits, the number of joins (J) is the number of successful join operations, the result size (S) is the scale of query results, and the query size (QS) is the scale of a query.
S is the sum of the size of all the intermediate results, and QS is the result of multiplying the number of vertices, edges, and unique labels included in a query. For example, the LT, LH, and H of the node 1 were 0, 50, and 100, respectively. The J, S, and QS of this node were 90, 100, and 20, respectively.
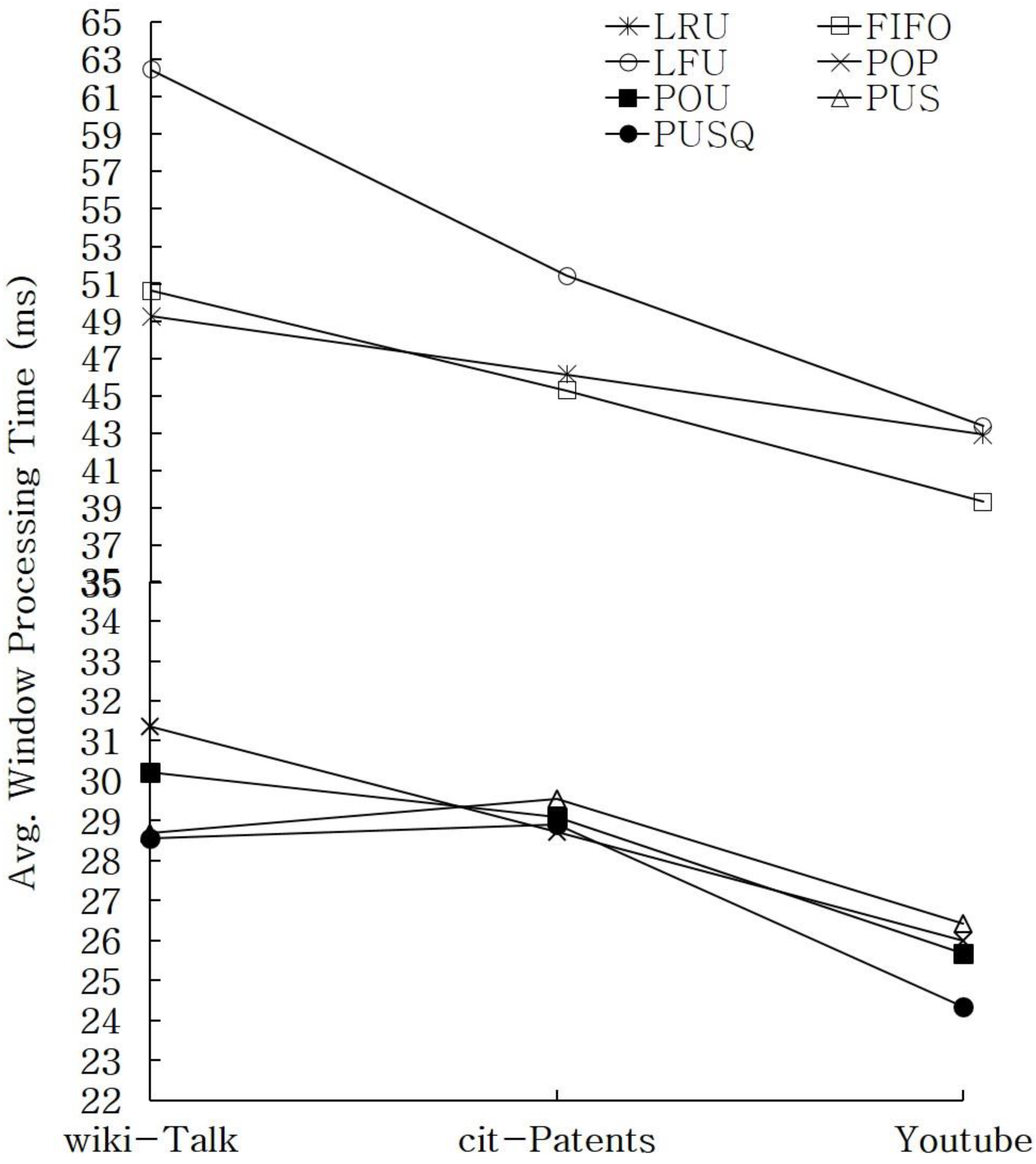
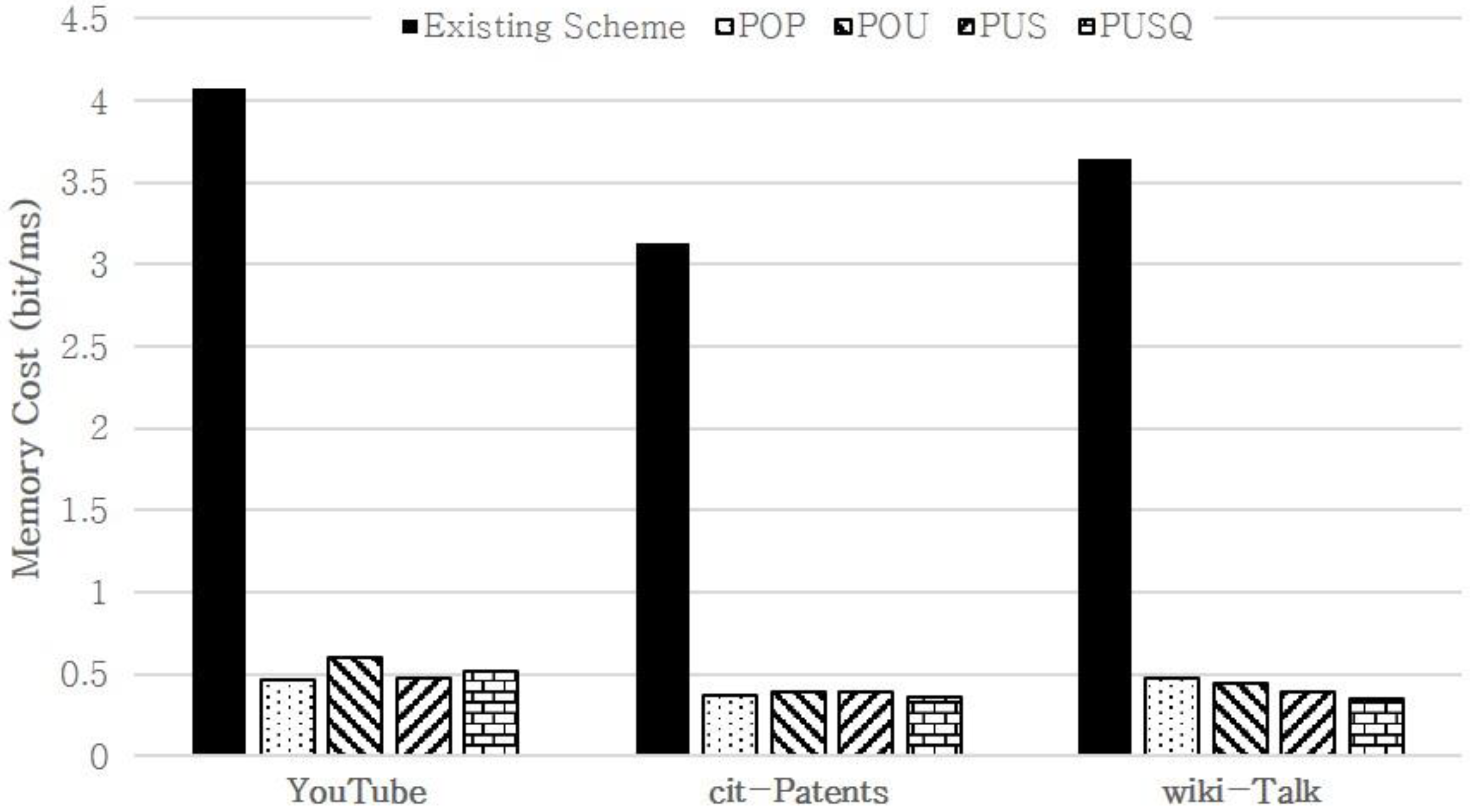
For example, when the least recently used (LRU) policy is applied in a situation where two caches should be replaced, the results on node 1 and node 3 will be replaced. However, this decision leads to a situation where node 1 is replaced owing to a high hit rate and where node 5, whose H is only 1, is resident in a cache. Consequently, the efficiency of a cache is likely to decrease. To increase the efficiency of a cache, the following four cache replacement strategies are proposed herein based on statistical information: the popularity (POP); popularity and usage (POU); popularity, usage, and size (PUS); and popularity, usage, size, and query size (PUSQ) strategies. In this study, the table of statistical information indicated in
Table 1 is used to select the targets to be replaced by the proposed strategies. The POP strategy replaces the low result of a node derived by dividing H by the time of residence of data in a cache as shown in Equation (1). Here, i is a trie index node stored in a cache, Hi is the number of hits, and Ai is the time of residence of data in a cache (current time–LT). The POU strategy replaces the low result of a node derived by multiplying the value obtained by the POP strategy by a ratio of joins (Ji/Hi), as shown in Equation (2). Ji is the number of join operations, and Hi is the number of hits. A large number of join operations compared with the hit rate indicates that join operations are likely to be performed for the next graph stream. In this regard, the POU value is calculated by considering this condition. The PUS strategy replaces the low result of a node derived by multiplying the value obtained by the POU strategy by a relative ratio of S (S/S
max). Here, S
max is the greatest result size and S
i is the result size. In
Table 1, the S (100) of Query 1 is S
max. When a cache includes a considerable amount of intermediate query results, this algorithm is adopted to facilitate the maximum residence of the intermediate query results in the cache. The PUSQ strategy replaces the low result of a node derived by multiplying the value obtained by the PUS strategy by a relative ratio of QS (QS/QS
max), as shown in Equation (4). Here, QS
max is the highest QS, and QS
i is QS. In
Table 1, the QS (100) of Query 4 is QS
max. As indicated in the case of the PUS strategy, the PUSQ strategy facilitates the residence of data in a cache that shows high QS to increase the filtering effect.
Figure 6 shows the processes of the four cache replacement strategies developed in this study. The Statistics Manager applies each strategy based on the table of statistical information indicated in
Table 1. If the POP strategy is applied for calculation under the assumption that the current time is 100, the scores for Nodes 1, 2, 3, 4, and 5 are calculated to be 1, 0.75, 0.7, 0.625, and 1, respectively. Consequently, the POP strategy selects Nodes 3 and 4, which obtained the lowest scores, as the target nodes for replacement. At this time, Node 5’s residence in the cache can decrease the efficiency of the cache. When the POU strategy is applied for calculation, Nodes 2 and 3 are selected as the target nodes for replacement. When the PUS algorithm is applied for calculation, Nodes 3 and 4 are selected as the target nodes for replacement. When the PUSQ strategy is applied for calculation, Nodes 2 and 5 are replaced. Through the aforementioned processes, Node 2, which shows a comparatively low efficiency for join operations, and Node 5, which shows a small size of intermediate results, are replaced in the cache. The Cache Manager performs subgraph matching on a graph stream and updates the cache and the Statistics Manager. Then, it applies each cache replacement strategy to the updated table of statistical information to calculate statistical values.
3.4. Query Processing Manager
The Query Processing Manager executes different processes according to the input types of stream data. If graph data is input, it analyzes if the graph data can be included in the query results managed by the current system. If the graph data can be included in the query results, it additionally generates query results. If a query graph is input, a query index is created according to the procedures described above.
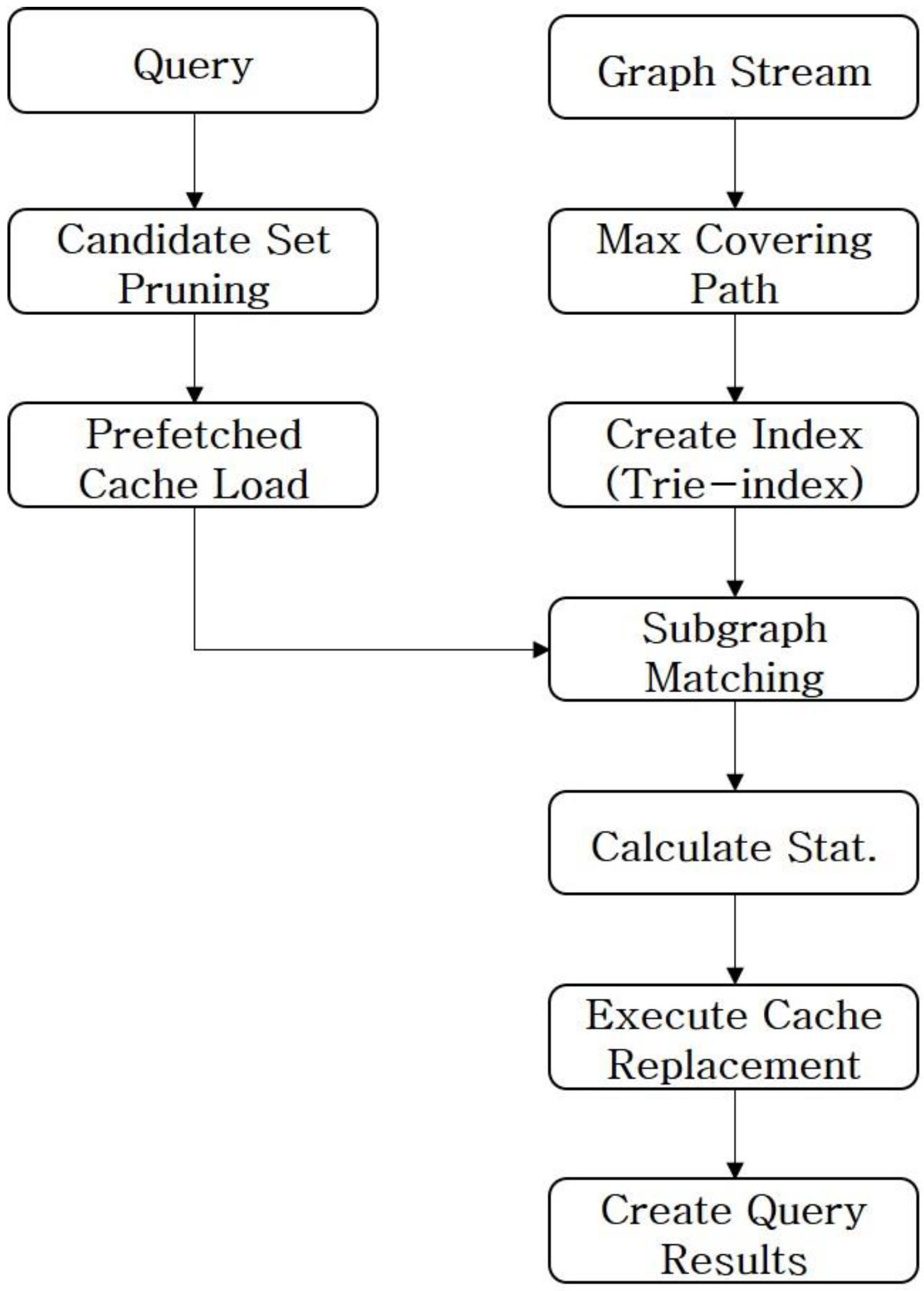
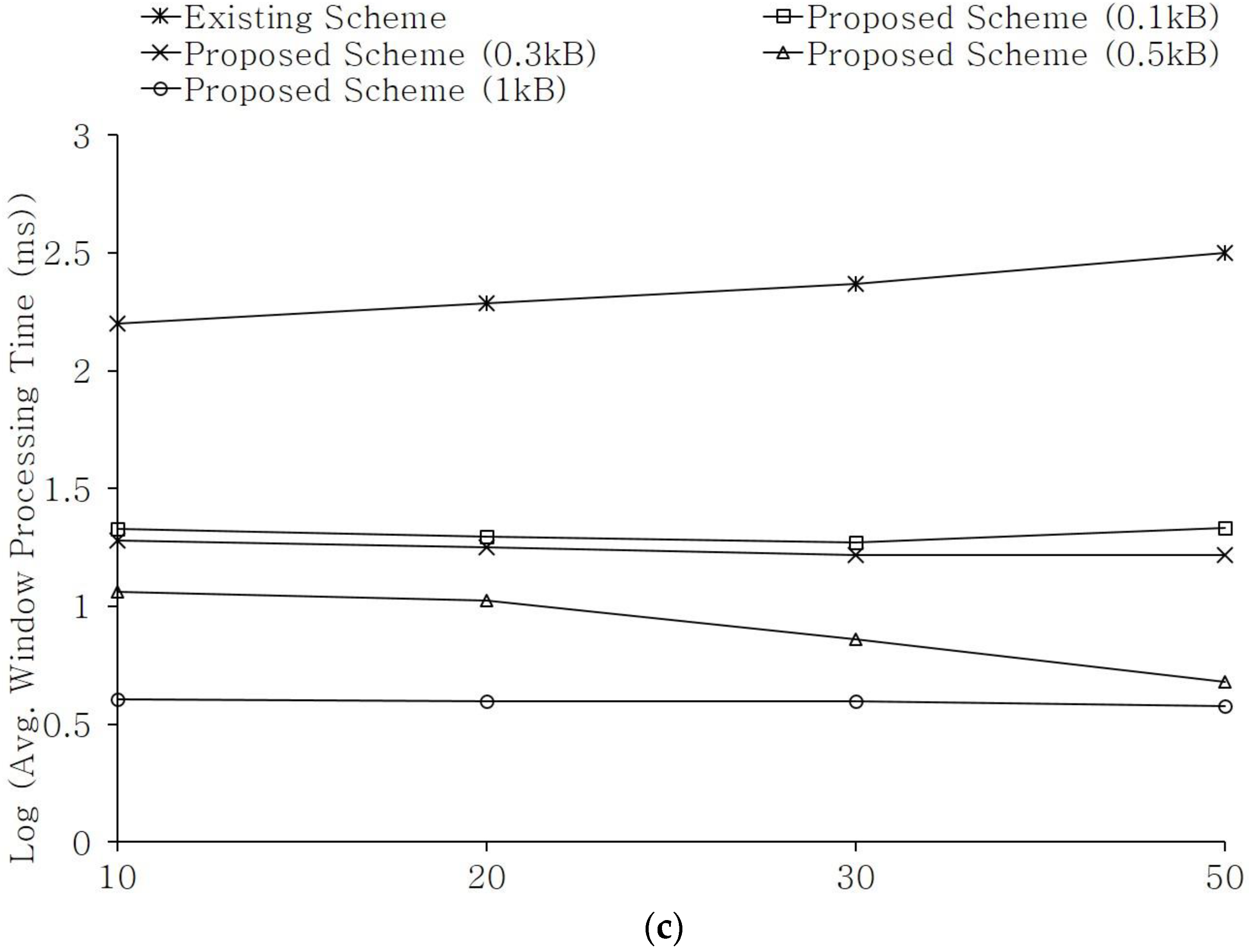
Figure 7 shows the procedures for query processing. When a query is requested, the Index Manager divides the query into max covering paths and creates a trie index based on each path of the query. The Query Processing Manager establishes a trie index by considering wildcard (var) operations on the query graph. In a trie, var vertices and edges are regarded and treated as nodes like vertices and indexes, including labels. When a graph stream is input after the establishment of a trie index, the stream processing module extracts a set (information on trie nodes) of candidates for subgraph matching based on the input stream. At this time, the Query Processing Manager inspects if the data of a set of candidates exist in a prefetched cache or a used cache prior to performing subgraph matching. If such data are not loaded in caches, the Cache Manager loads intermediate results on the parent and child nodes in a prefetched cache. The subgraph matching module performs subgraph matching based on join operations by using intermediate query results loaded in a prefetched cache or a used cache. The Query Processing Manager responds to subgraph matching queries, whereas the Statistics Manager of the Cache Manager constantly records statistical information, such as the hit rate, the ratio of join operations, and the size of intermediate results. As for cache data, a TTL(Time-To-Live) value is determined based on statistics. After performing subgraph matching, the Query Processing Manager analyzes if the data exceeded the size of the cache. If the size of the cache is still sufficient, the Query Processing Manager outputs subgraph matching results. If the size of the cache is not sufficient, the Query Processing Manager replaces the data in the cache based on statistics and outputs subgraph matching results.
Figure 8 shows the subgraph matching processes. The solid line indicates query processing, and the dotted line indicates cache data management. The first edge management process on a graph stream is marked in red, and the second edge management process is marked in blue. When the edges of graph data <0, 1, v
1, v
2, e
1> are input, the edge indexing process is implemented to identify the list {Q
1, Q
2, Q
5} of queries affected by edges. The reference indexing process determines the information on trie nodes, which indicates each query stored in a trie. For example, Q
1 is {n
3, n
5, n
6}. The trie indexing process detects the location of a trie node including the indexed information on current edges <v
1, v
2, e
1> by performing trie node traversal according to queries. As for a specific example, the trie indexing process determines a trie {n
1} practically affected by edges based on the result of trie node traversal on Q
1. A join operation on the parent and child trie nodes of the corresponding node is conducted to generate intermediate node results in the form of a materialized view. The materialized view includes the unique numbers of nodes and vertices recorded. As n1 is a node of a current edge that serves as the root node, this node is regarded as query results. Thus, (n
1, (0, 1)) is recorded in the result on the materialized view of n
1. If the current cache does not include any data, the result of a join operation on a trie node n1 and its child trie nodes {n
2, n
4, n
6} is not generated. The Query Processing Manager conducts subgraph matching by repeatedly applying the aforementioned processes to all the trie nodes included in a set of candidates. When edges <1, 2, v
2, v
2, e
5> are input, the Query Processing Manager obtains {n
6} from a trie based on the same processes indicated above. A trie node n
6 performs a join operation with its parent trie node n1 and its child trie node n
8 based on intermediate results in the form of a materialized view. As the result (0, 1) of the parent trie node n1 is loaded in the current cache, a join operation with the parent trie node generates a join result (0, 1, 2) of the trie node n
6. As a join operation with the child trie node n
8 does not generate any result, the result of n
8 is not created. In addition, the reference indexing process generates results of trie nodes according to queries (the results of n
3, n
5, and n
6 in the case of Q
1). When the results are generated, the Query Processing Manager conducts a join operation between trie nodes to generate the final subgraph matching results.
Figure 9 shows the processes of continuous subgraph matching based on a graph stream under the application of a sliding window. After performing query processing, the Query Processing Manager presents the results derived by reflecting intermediate results in a cache and subgraph matching results. Then, it applies the FTV process based on trie indexing to the input stream data to maintain query processing results in the form of a materialized view according to trie nodes. It generates the final subgraph matching results based on the join operation results on trie nodes conducted in the reference indexing process. Specifically, it generates the final subgraph matching results {(0, 1, 2), (0, 3)} for Q
2 based on join operations on the result (0, 1, 2) of a materialized view based on the candidate for n6 and the result (0, 3) of a materialized view based on the candidate for n7.

 ,
, 




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}