
Adaptive Driver Face Feature Fatigue Detection Algorithm Research

Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
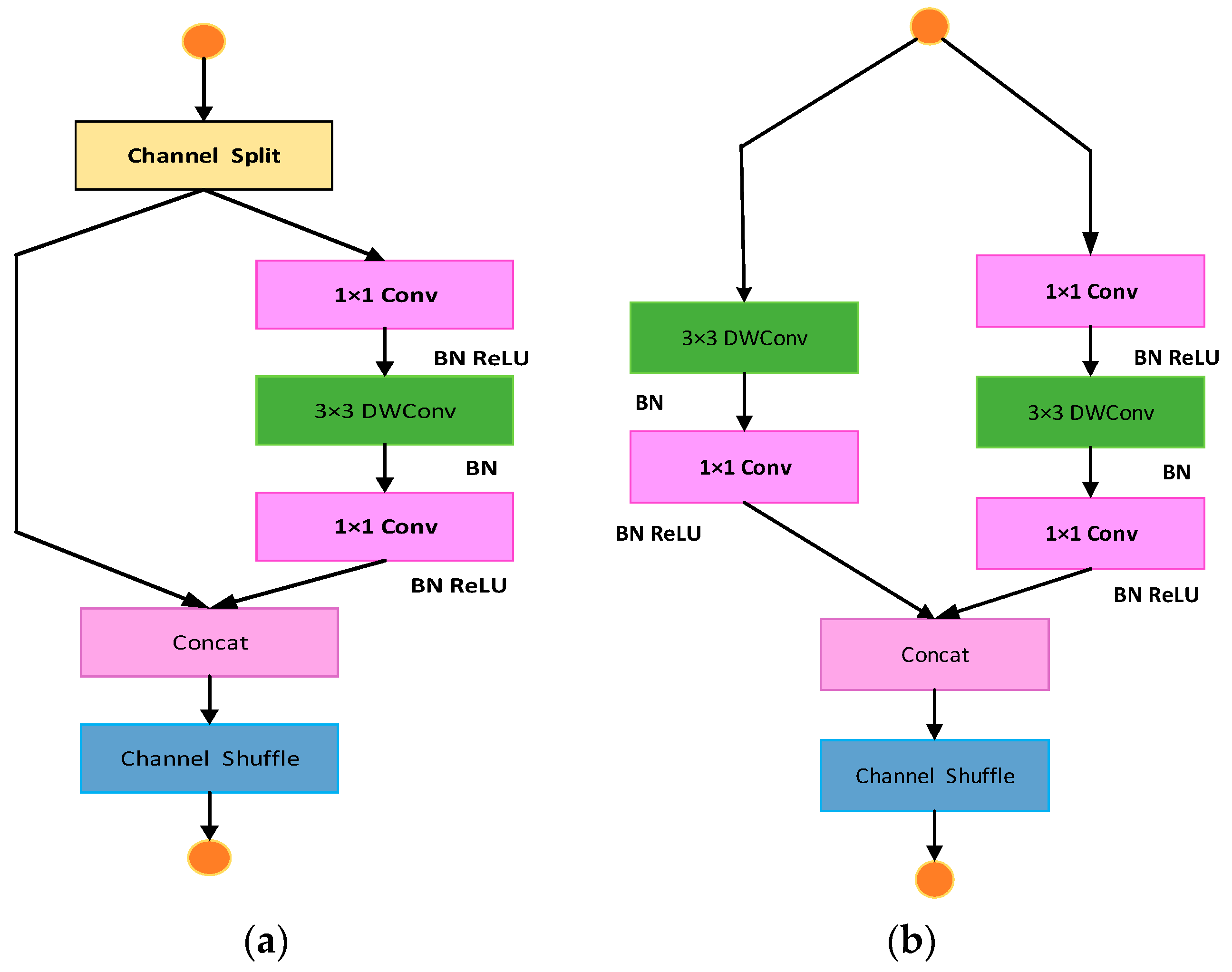
3.1. Face Detection and Special Point Localization
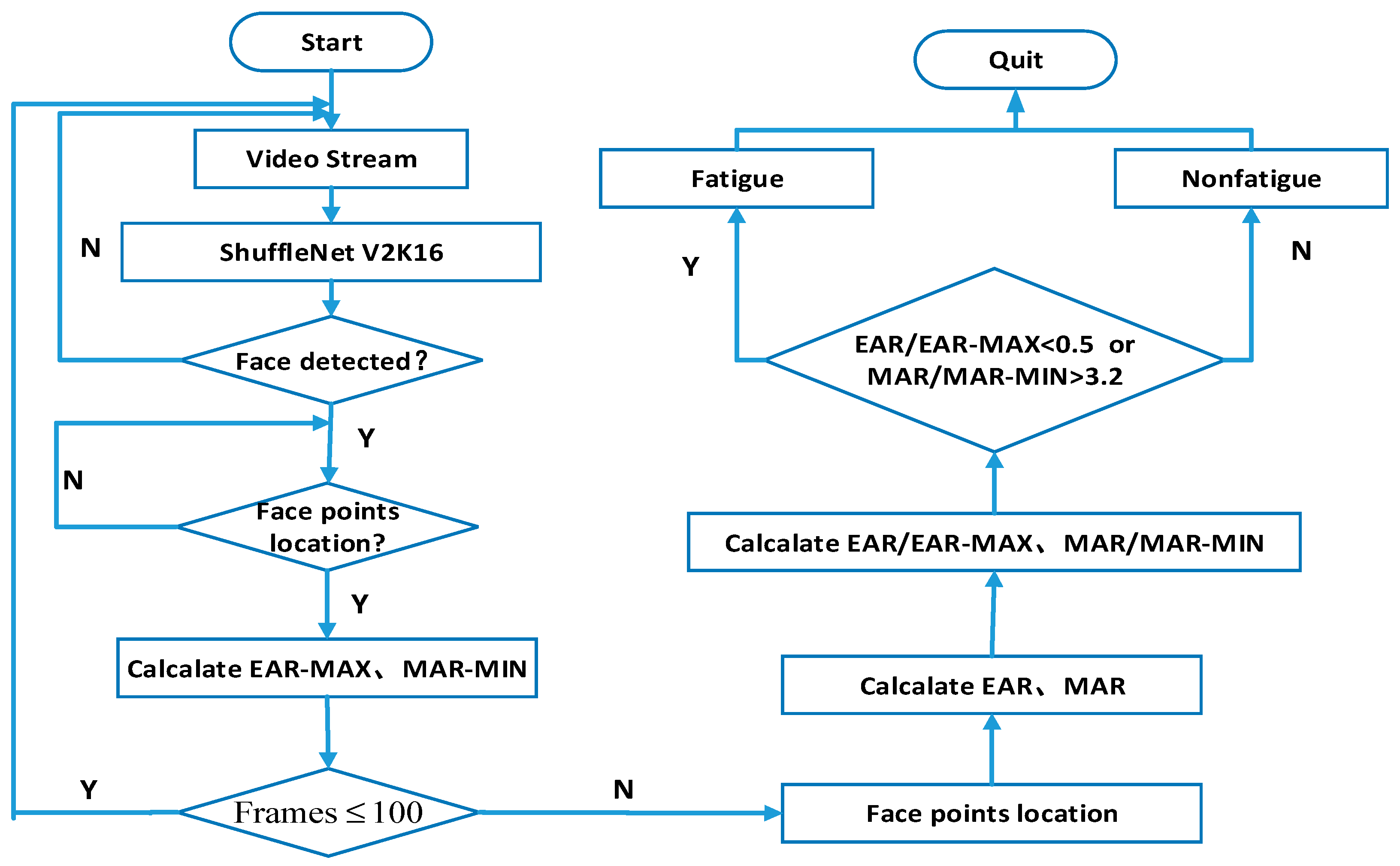
3.2. The MAX-MIN Algorithm
3.2.1. Eye Condition Evaluation Index
3.2.2. Mouth Condition Evaluation Index
3.2.3. The MAX-MIN Algorithm Evaluation Metrics
4. Experiment and Analysis
4.1. Simulation Environment
4.2. The Datasets
4.3. Training and Evaluation Index for Target Detection
4.4. Fatigue Testing Experiments
4.4.1. MAX-MIN Threshold Setting
4.4.2. Fatigue Testing and Comparison Experiment
4.4.3. The MAX-MIN Algorithm Fatigue State Detection Experiments
4.5. Actual Scene Detection Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lal, S.; Craig, A. A critical review of the psychophysiology of driver fatigue—ScienceDirect. Biol. Psychol. 2001, 55, 173–194. [Google Scholar] [CrossRef]
- He, J.; Chen, J.; Liu, J.; Li, H. A Lightweight Architecture For Driver Status Monitoring Via Convolutional Neural Networks. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Abtahi, S.; Omidyeganeh, M.; Shirmohammadi, S.; Hariri, B. YawDD: A yawning detection dataset. In Proceedings of the 5th ACM Multimedia Systems Conference, Virtual Event, China, 20–24 October 2014; pp. 24–28. [Google Scholar]
- Guo, X.; Li, S.; Yu, J.; Zhang, J.; Ma, J.; Ma, L.; Liu, W.; Ling, H. PFLD: A practical facial landmark detector. arXiv 2019, arXiv:1902.10859. [Google Scholar]
- Kreiss, S.; Bertoni, L.; Alahi, A. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE/CVF Conferaence on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11977–11986. [Google Scholar]
- Hu, Y.; Lu, M.; Lu, X. Driving behavior recognition from still images by using multi-stream fusion CNN. Mach. Vis. Appl. 2019, 30, 851–865. [Google Scholar] [CrossRef]
- Xiang, W.; Wu, X.; Li, C.; Zhang, W.; Li, F. Driving Fatigue Detection Based on the Combination of Multi-Branch 3D-CNN and Attention Mechanism. Appl. Sci. 2022, 12, 4689. [Google Scholar] [CrossRef]
- Ansari, S.; Naghdy, F.; Du, H.; Pahnwar, Y.N. Driver mental fatigue detection based on head posture using a new modified reLU-BiLSTM deep neural network. IEEE Trans. Intell. Transp. Syst. 2021, 23, 10957–10969. [Google Scholar] [CrossRef]
- Jia, H.; Xiao, Z.; Ji, P. Fatigue driving detection based on deep learning and multi-index fusion. IEEE Access 2021, 9, 147054–147062. [Google Scholar] [CrossRef]
- Han, H.; Li, K.; Li, Y. Monitoring driving in a monotonous environment: Classification and recognition of driving fatigue based on long short-term memory network. J. Adv. Transp. 2022, 2022, 6897781. [Google Scholar] [CrossRef]
- Moslemi, N.; Azmi, R.; Soriano, M. Driver distraction recognition using 3d convolutional neural networks. In Proceedings of the 2019 4th International Conference on Pattern Recognition and Image Analysis (IPRIA), Tehran, Iran, 6–7 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 145–151. [Google Scholar]
- Zhu, T.; Zhang, C.; Wu, T.; Ouyang, Z.; Li, H.; Na, X.; Ling, J.; Li, W. Research on a real-time driver fatigue detection algorithm based on facial video sequences. Appl. Sci. 2022, 12, 2224. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Jin, S.; Xu, L.; Xu, J.; Wang, C.; Liu, W.; Qian, C.; Ouyang, W.; Luo, P. Whole-Body Human Pose Estimation in the Wild. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Akrout, B.; Mahdi, W. A novel approach for driver fatigue detection based on visual characteristics analysis. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 527–552. [Google Scholar] [CrossRef]
- Fatima, B.; Shahid, A.R.; Ziauddin, S.; Safi, A.A.; Ramzan, H. Driver Fatigue Detection Using Viola Jones and Principal Component Analysis. Appl. Artif. Intell. 2020, 34, 456–483. [Google Scholar] [CrossRef]
- Chen, L.; Xin, G.; Liu, Y.; Huang, J. Driver Fatigue Detection Based on Facial Key Points and LSTM. Secur. Commun. Netw. 2021, 2021, 5383573. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Parameter |
|---|---|
| CPU | Inter (R) Core(TM)i7-10870H CPU |
| GPU | NVIDIA GeForce RTX 4090 |
| CUDA version | CUDA 10.1 |
| System environment | Windows 10 |
| Gender | Category | Number | The Precision of MAX-MIN Algorithm |
|---|---|---|---|
| Female | Eye Open | 2032 | 98.7% |
| Eye Closed | 1258 | 98.5% | |
| Mouth Open | 5862 | 99.0% | |
| Mouth Closed | 2684 | 98.6% | |
| Male | Eye Open | 1768 | 98.6% |
| Eye Closed | 1006 | 98.7% | |
| Mouth Open | 6184 | 99.1% | |
| Mouth Closed | 3531 | 98.4% |
| Dataset | Gender | Precision | Recall | F-Score |
|---|---|---|---|---|
| YawDD | Female | 99.1% | 89.7% | 94.2% |
| Male | 98.7% | 90.2% | 94.3% | |
| SBD | Female | 98.8% | 90.3% | 94.4% |
| Male | 98.6% | 90.6% | 94.4% | |
| Average | 98.8% | 90.2% | 94.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, H.; Wang, Y.; Liu, X. Adaptive Driver Face Feature Fatigue Detection Algorithm Research. Appl. Sci. 2023, 13, 5074. https://doi.org/10.3390/app13085074
Zheng H, Wang Y, Liu X. Adaptive Driver Face Feature Fatigue Detection Algorithm Research. Applied Sciences. 2023; 13(8):5074. https://doi.org/10.3390/app13085074
Chicago/Turabian StyleZheng, Han, Yiding Wang, and Xiaoming Liu. 2023. "Adaptive Driver Face Feature Fatigue Detection Algorithm Research" Applied Sciences 13, no. 8: 5074. https://doi.org/10.3390/app13085074