
A Dynamic Grid Index for CkNN Queries on Large-Scale Road Networks with Moving Objects
Abstract
:1. Introduction
2. Related Work
3. Methodology Overview and Problem Definition
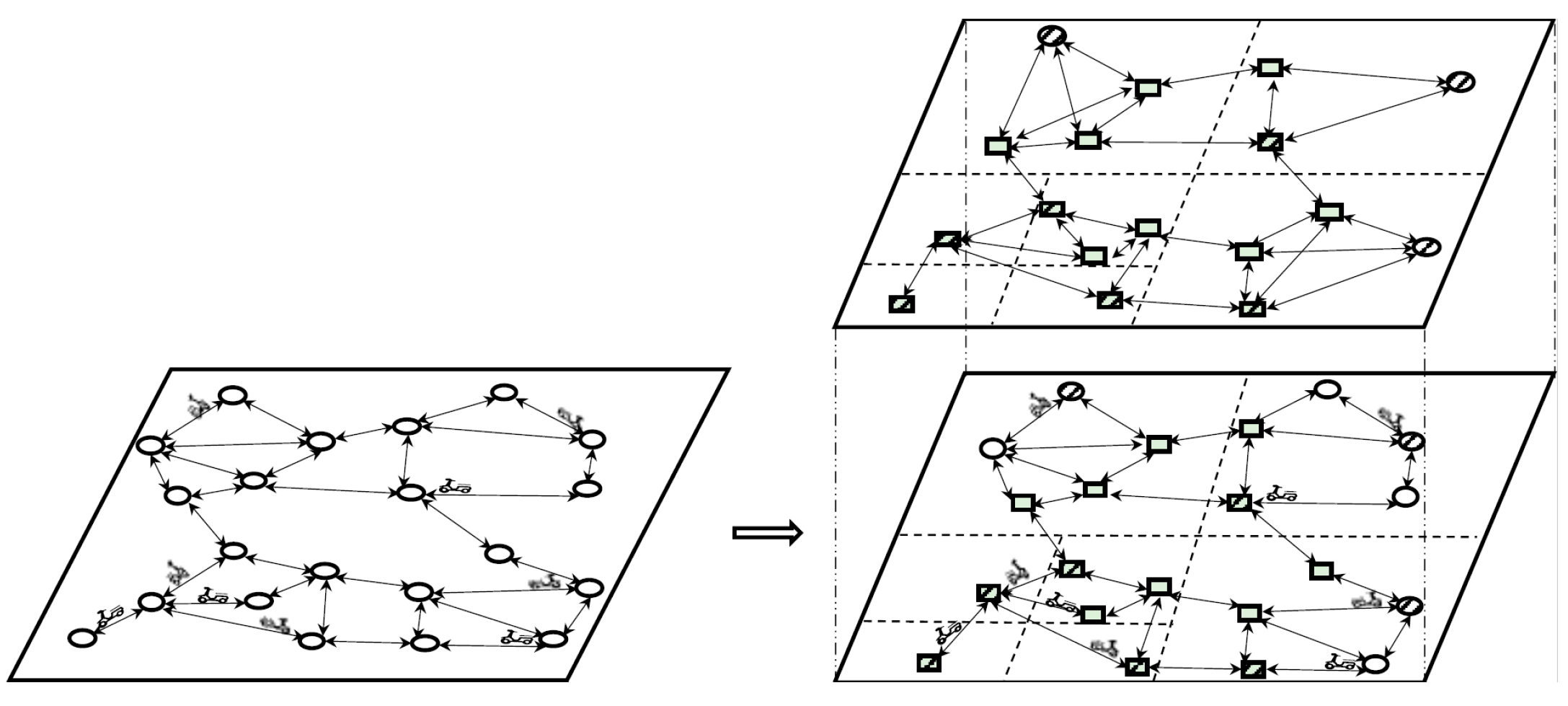
3.1. Methodology Overview
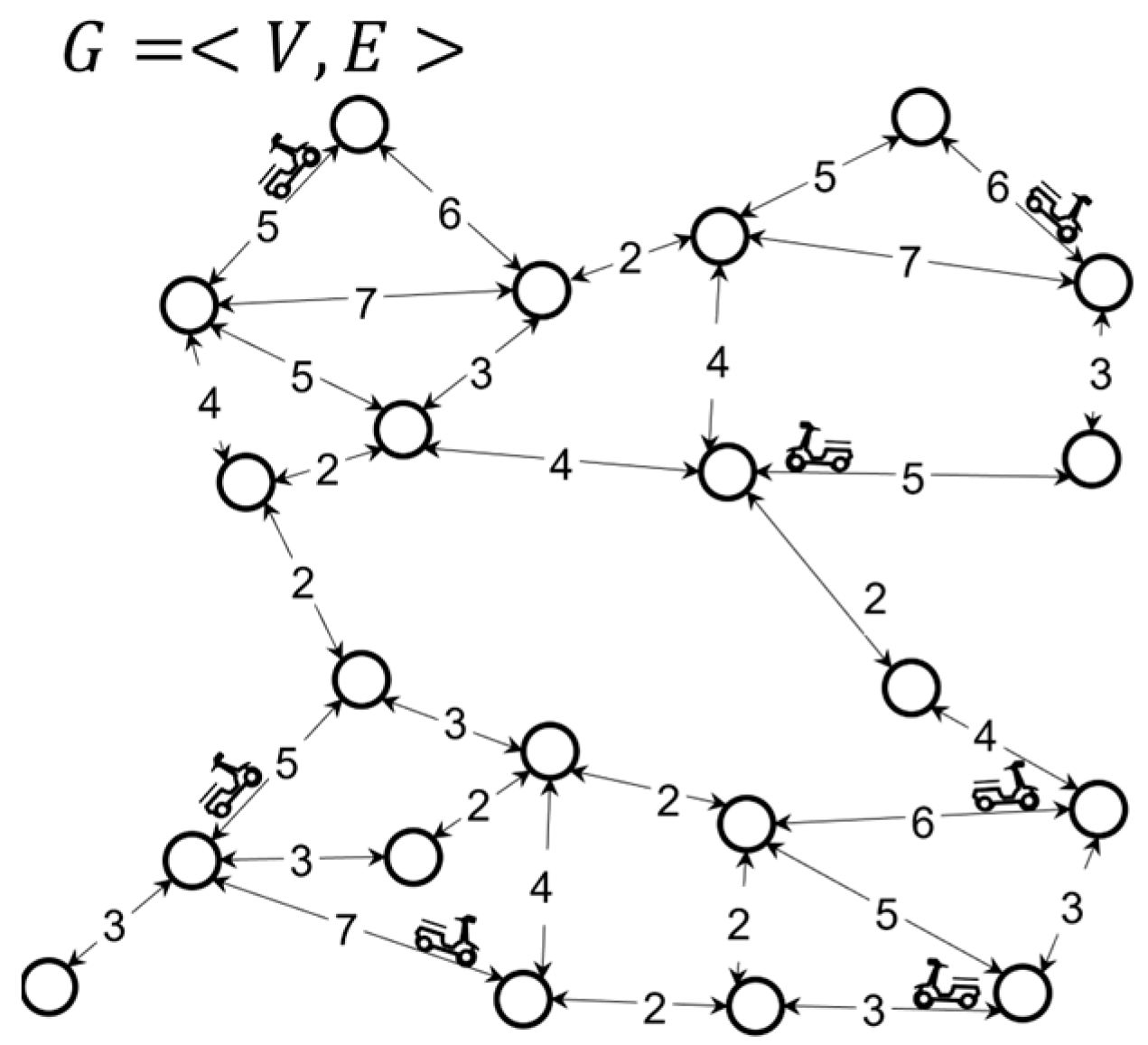
3.2. Problem Definition
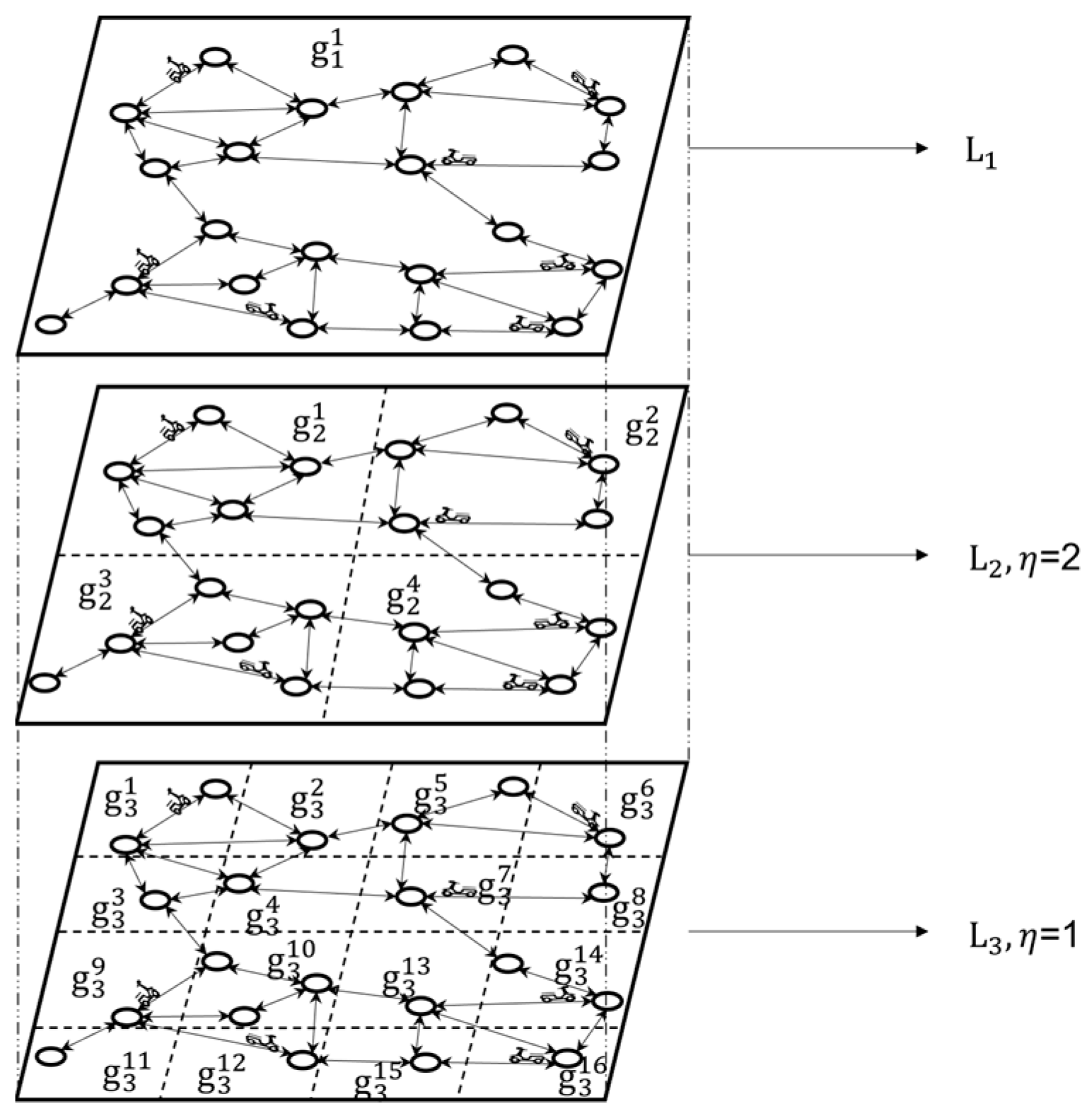
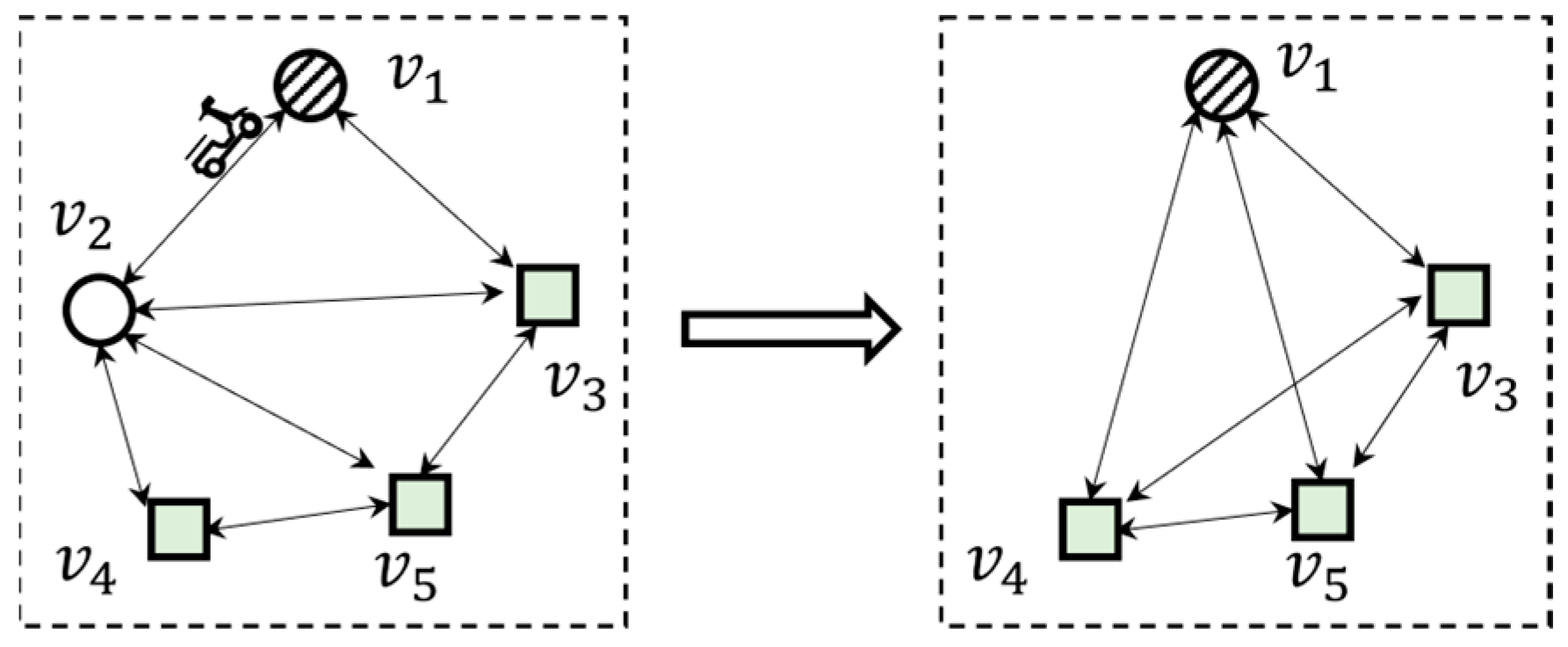
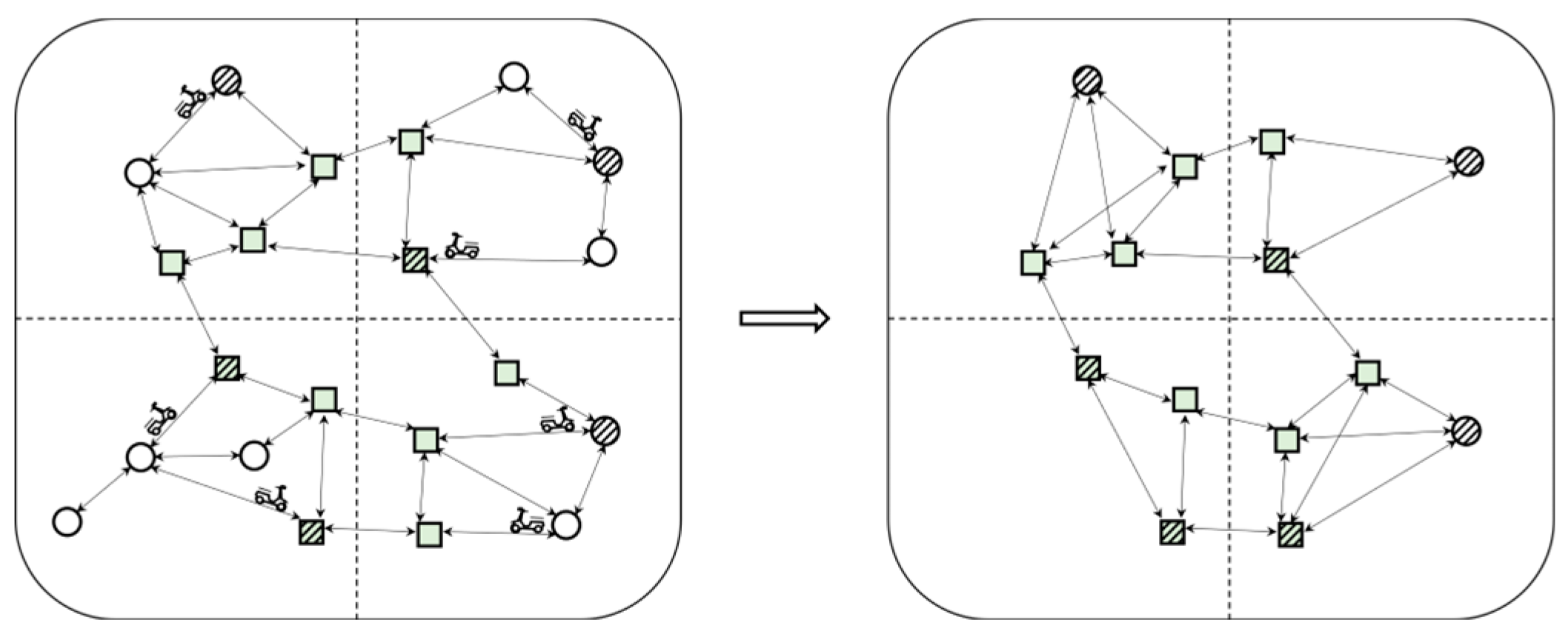
4. Dynamic V-Tree Double-Layer Grid Index
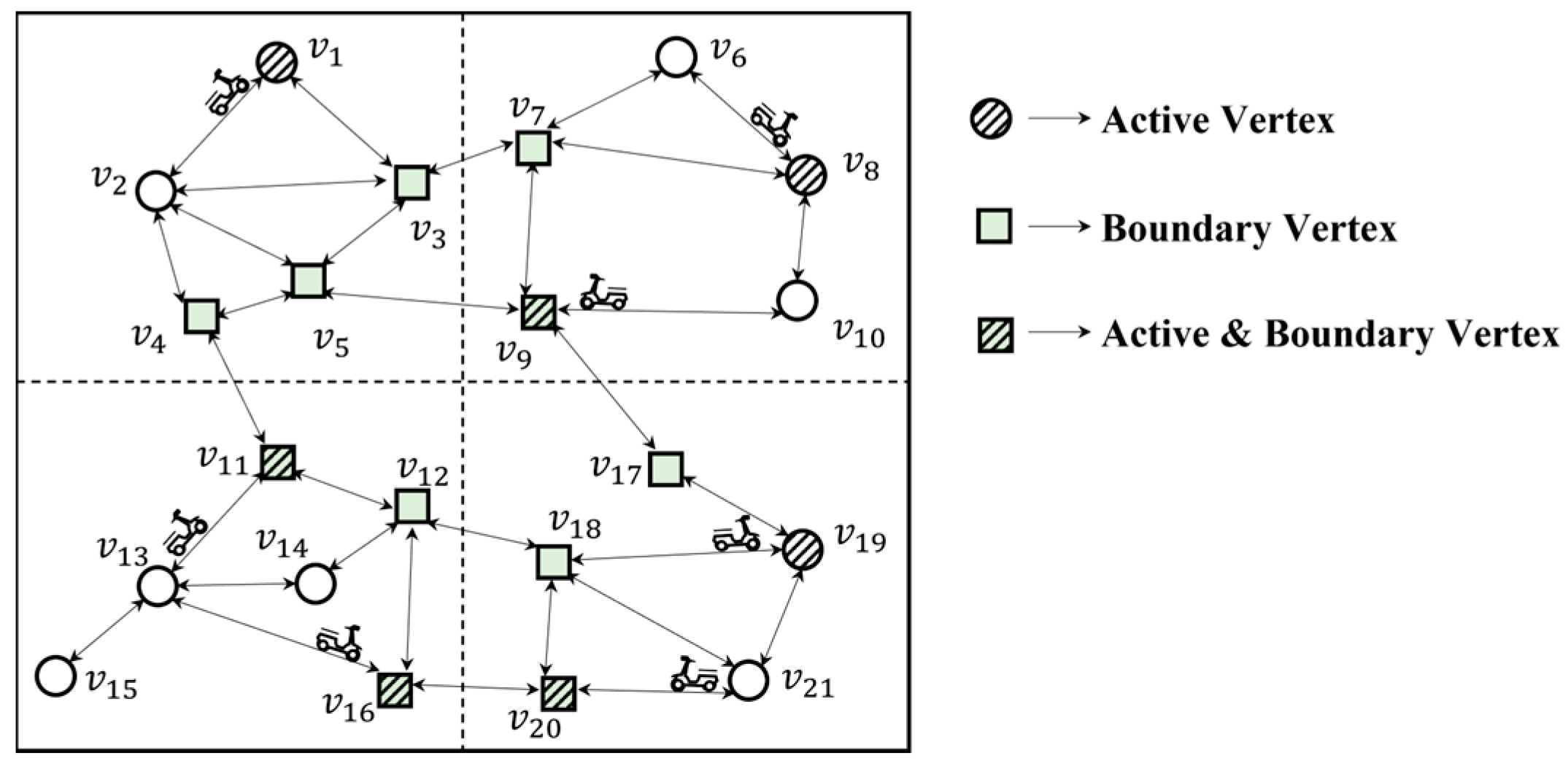
4.1. Building the Index
- ;
- represents the edge between, then is and and other boundary vertices, that is, ;
- represents the distance of side , that is, .
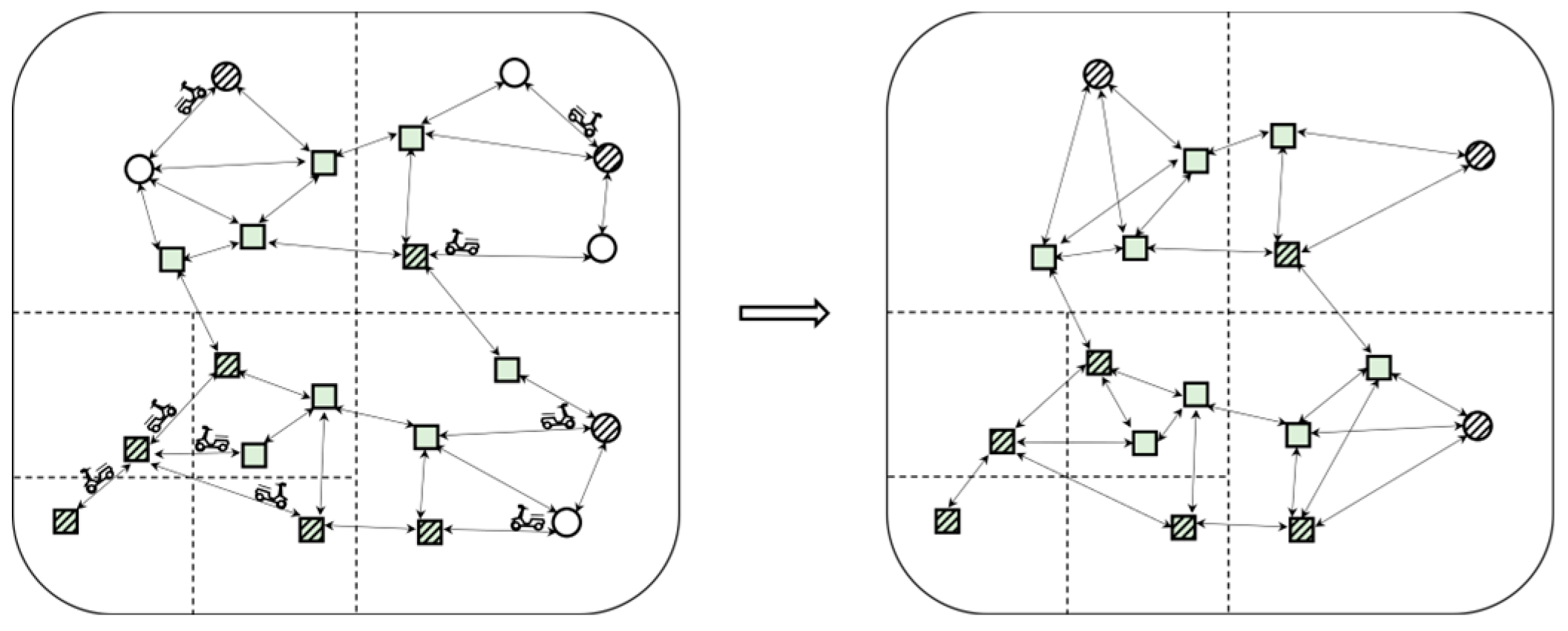
4.2. Update Mechanism of the DVTG-Index
4.2.1. Update of Moving Objects
- Add moving object: we added a new object on edge , and moved towards vertex , for example, a taxi driver just exited the car or just finished the last task.
- Delete a moving object: we deleted a moving object from the edge , for example, the driver finished a task and left work, or the car broke down and could no longer carry passengers.
- Update the moving object: the position of the moving object changed, which was the most common situation. We further subdivided it into two cases according to the variation in moving objects. The first case was that was still on the edge ; however, the distance from the active vertex changed. In this case, we only needed to change the attribute in , and the time complexity was only O(1); the second case was that the side where was located changed, for example, moved from side to side . At this time, we only needed to combine the operations of (1) and (2), delete from edge , and add on edge , that is, the cross-edge movement of the moving object was realized.
4.2.2. Index Update
5. DVTG-CkNN Query Algorithm
5.1. Query-Point Processing
5.2. The First k-Nearest Neighbor Query
| Algorithm 1. The first k-nearest neighbor query |
| Input: ,k // Find the k closest moving objects to the query point |
| Output: // Returns the k-nearest neighbor query queue |
5.3. Continuous k-Nearest Neighbor Query
| Algorithm 2. Continuous k-nearest neighbor query |
| Input: // Find the k closest moving objects to the query point |
| Output: // Returns the k-nearest neighbor query queue |
5.4. Time and Space Complexity of the DVTG-CkNN Algorithm
5.4.1. Time Complexity
5.4.2. Space Complexity
6. Experiment Analysis
6.1. Experiment Settings
6.2. Baseline Algorithm
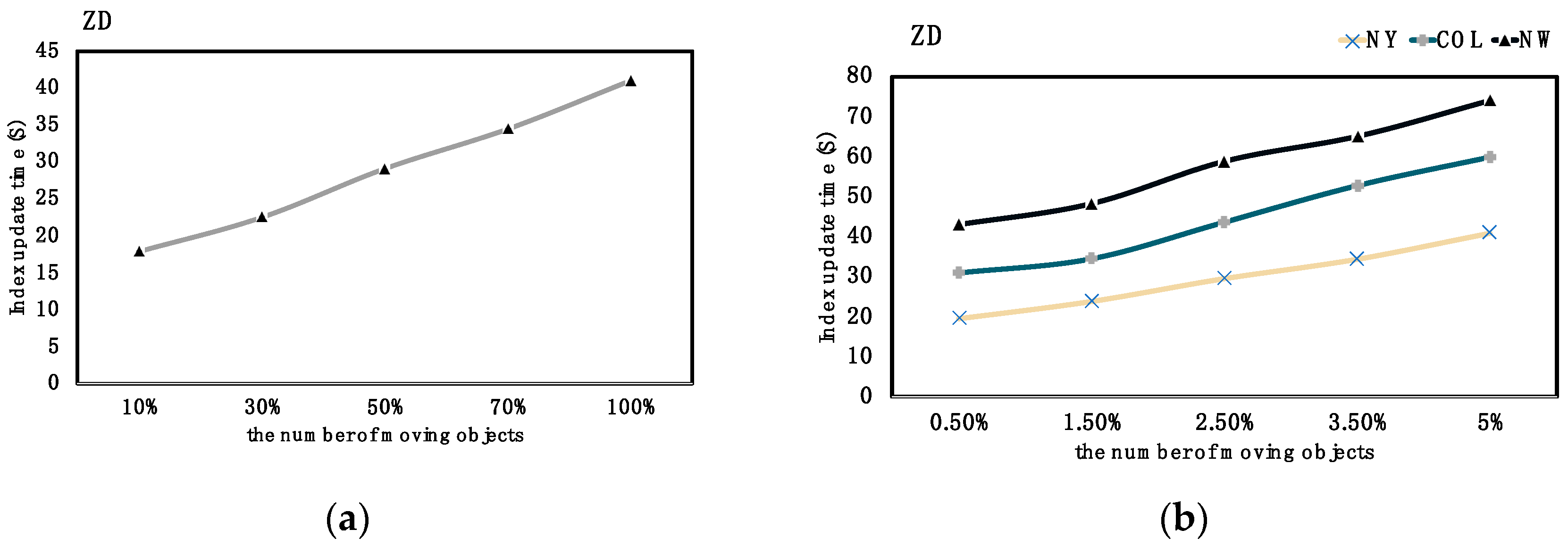
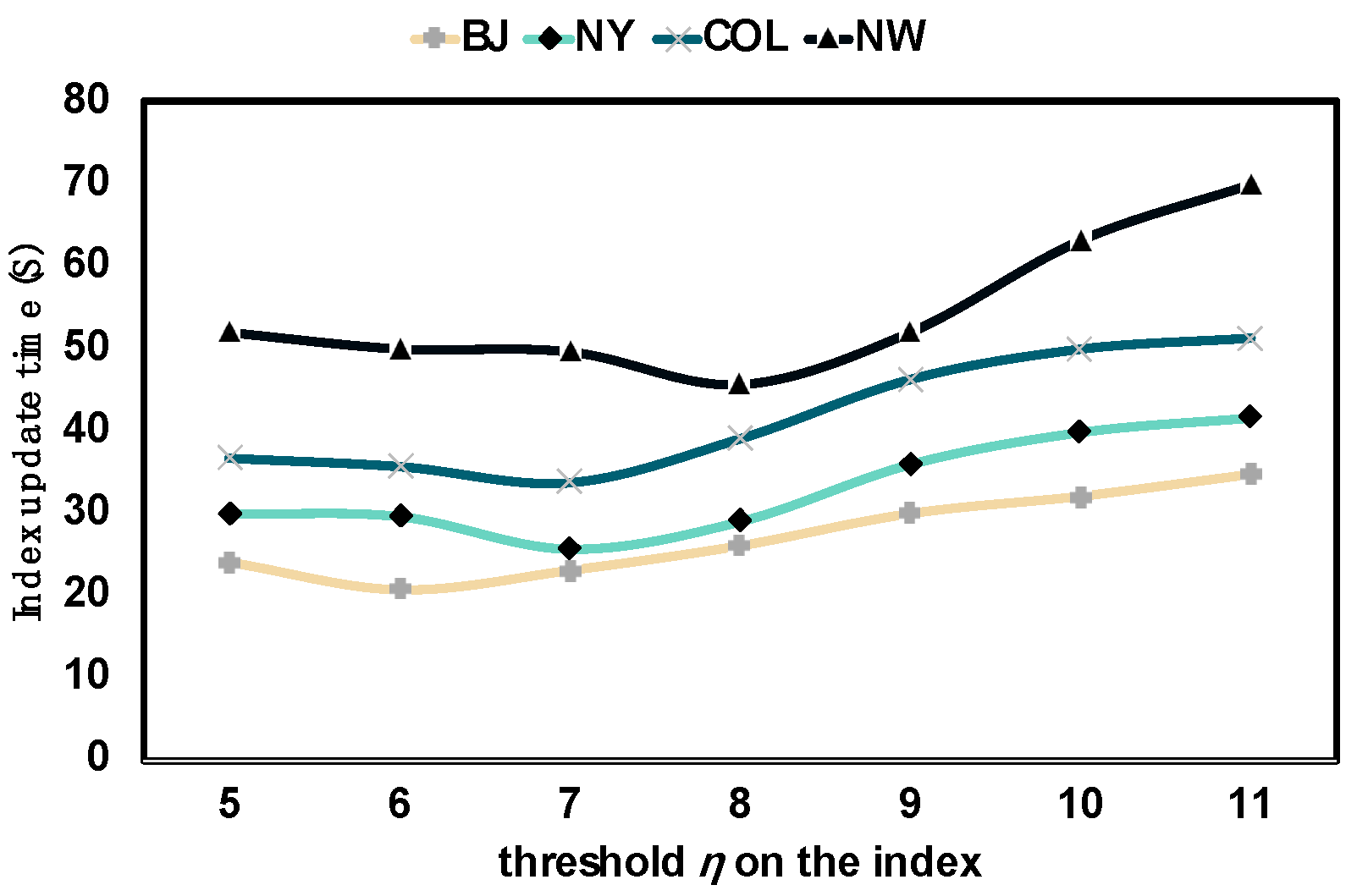
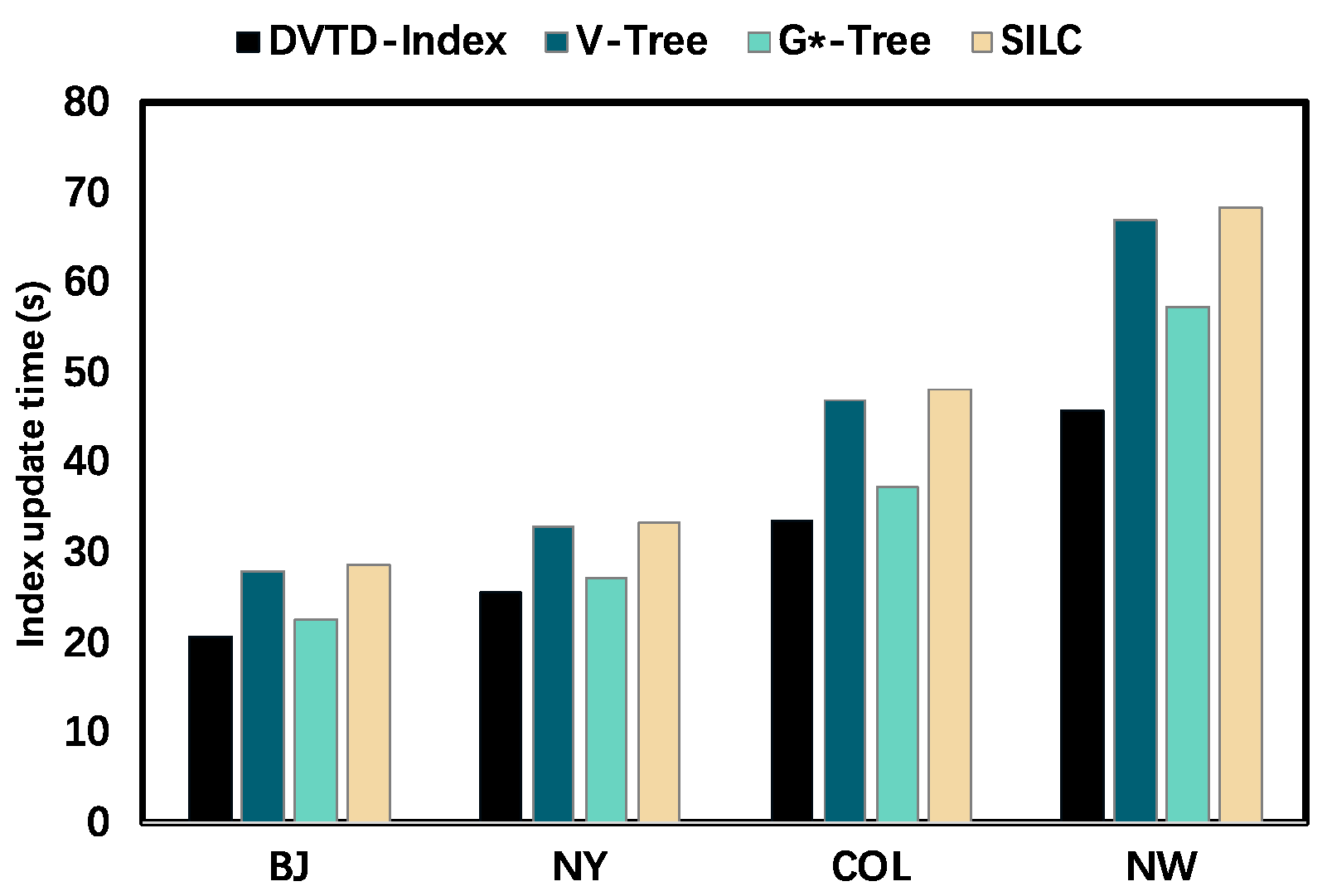
6.3. DVTG-Index Experiment Situation
6.4. Experimental Situation of the DVTG-CkNN Algorithm
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liao, Z.; Yang, Z.; Huang, P.; Pang, N.; Zhao, X. Multi-Model Fusion-Based Hierarchical Extraction for Chinese Epidemic Event. Data Sci. Eng. 2023, 8, 73–83. [Google Scholar] [CrossRef]
- Huang, H.; Gartner, G.; Krisp, J.M.; Raubal, M.; Van De Weghe, N. Location based services: Ongoing evolution and research agenda. J. Locat. Based Serv. 2018, 12, 63–93. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Liu, G.; Qi, J.; Xu, H.; Yu, G.; Zhang, R. The moving k diversified nearest neighbor query. IEEE Trans. Knowl. Data Eng. 2016, 28, 2778–2792. [Google Scholar] [CrossRef]
- Zhong, W.; Chen, C. REMIX: Efficient range query for LSM-trees. In Proceedings of the 19th USENIX Conference on File and Storage Technologies, Santa Clara, CA, USA, 23–25 February 2021. [Google Scholar]
- Li, C.; Gu, Y.; Qi, J.; Yu, G.; Zhang, R.; Yi, W. Processing moving k nn queries using influential neighbor sets. Proc. VLDB Endow. 2014, 8, 113–124. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Lei, Y.; Zhang, Z.; Peng, C. A Communication Efficient ADMM-based Distributed Algorithm Using Two-Dimensional Torus Grouping AllReduce. Data Sci. Eng. 2023, 8, 61–72. [Google Scholar] [CrossRef]
- Kumar, B.K.; Priya, R.H.; Lakshmi, M.D.; Asha, S.; Mercy, J.J. Enhancing the Privacy and Content-Protection using Location Based Queries. J. Crit. Rev. 2022, 4, 306–313. [Google Scholar]
- Yin, Q.; Wang, J.; Du, S.; Leng, J.; Li, J.; Hong, Y.; Zhang, F.; Chai, Y.; Zhang, X.; Zhao, X.; et al. An Adaptive Elastic Multi-model Big Data Analysis and Information Extraction System. Data Sci. Eng. 2022, 7, 328–338. [Google Scholar] [CrossRef]
- Zhong, H.; He, W.; Cui, L.; Liu, L.; Yan, Z.; Zhao, K. Joint Attention Networks with Inherent and Contextual Preference-Awareness for Successive POI Recommendation. Data Sci. Eng. 2022, 7, 370–382. [Google Scholar] [CrossRef]
- Tang, C.; Wan, J.; Xie, C. Fencekv: Enabling efficient range query for key-value separation. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 3375–3386. [Google Scholar] [CrossRef]
- Jiang, T.; Zhang, B.; Lin, D.; Gao, Y.; Li, Q. Efficient parallel processing of high-dimensional spatial k NN queries. Soft Comput. 2022, 26, 12291–12316. [Google Scholar] [CrossRef]
- Arshad, S.; Hu, S.; Ashraf, B.N. Zipf’s law and city size distribution: A survey of the literature and future research agenda. Phys. A Stat. Mech. Its Appl. 2018, 492, 75–92. [Google Scholar] [CrossRef]
- Nutanong, S.; Zhang, R.; Tanin, E.; Kulik, L. Analysis and evaluation of v*-k nn: An efficient algorithm for moving k nn queries. VLDB J. 2010, 19, 307–332. [Google Scholar] [CrossRef]
- Wei, H.; Chen, Y.; Tan, J.; Wang, T. Sambot: A self-assembly modular robot system. IEEE/ASME Trans. Mechatron. 2010, 16, 745–757. [Google Scholar] [CrossRef]
- Elmasri, R.; Wuu, G.T.; Kim, Y.J. The time index—An access structure for temporal data. In Proceedings of the Sixteenth International Conference on Very Large Databases, Brisbane, Australia, 13–16 August 1990; pp. 1–12. [Google Scholar]
- Huang, X.; Jensen, C.S.; Šaltenis, S. Multiple k nearest neighbor query processing in spatial network databases. In Proceedings of the Advances in Databases and Information Systems: 10th East European Conference, ADBIS 2006, Thessaloniki, Greece, 3–7 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 266–281. [Google Scholar]
- Tao, Y.; Papadias, D.; Sun, J. The tpr*-tree: An optimized spatio-temporal access method for predictive queries. In Proceedings of the 2003 VLDB Conference, Berlin, Germany, 9–12 September 2003; Elsevier: Amsterdam, The Netherlands, 2003; pp. 790–801. [Google Scholar]
- Goh, C.H.; Lu, H.; Ooi, B.C.; Tan, K.-L. Indexing temporal data using existing b+-trees. Data Knowl. Eng. 1996, 18, 147–165. [Google Scholar] [CrossRef]
- Lum, V.; Dadam, P.; Erbe, R.; Günauer, J.; Pistor, P.; Walch, G.; Werner, H.; Woodfill, J. Designing dbms support for the temporal dimension. ACM Sigmod Rec. 1984, 14, 115–130.71. [Google Scholar] [CrossRef]
- Rotem, D.; Segev, A. Physical organization of temporal data. In Proceedings of the 1987 IEEE Third International Conference on Data Engineering, Los Angeles, CA, USA, 3–5 February 1987; IEEE: New York, NY, USA, 1987; pp. 547–553. [Google Scholar]
- Lomet, D.; Salzberg, B. Access methods for multiversion data. ACM SIG-MOD Rec. 1989, 18, 315–324. [Google Scholar] [CrossRef] [Green Version]
- Kolovson, C.; Stonebraker, M. Indexing techniques for historical databases. In Proceedings of the Fifth International Conference on Data Engineering, Los Angeles, CA, USA, 6–10 February 1989; IEEE Computer Society: Washington, DC, USA, 1989; pp. 127–128. [Google Scholar]
- Bareche, I.; Xia, Y. A Distributed Hybrid Indexing for Continuous KNN Query Processing over Moving Objects. ISPRS Int. J. Geo-Inf. 2022, 11, 264. [Google Scholar] [CrossRef]
- Huang, C.; Su, B.; Lin, T.; Huang, Y. Downlink SCMA codebook design with low error rate by maximizing minimum Euclidean distance of superimposed codewords. IEEE Trans. Veh. Technol. 2022, 71, 5231–5245. [Google Scholar] [CrossRef]
- Yang, H.; Cai, J.; Zhu, M.; Liu, C.; Wang, Y. Traffic-informed multi-camera sensing (TIMS) system based on vehicle re-identification. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17189–17200. [Google Scholar] [CrossRef]
- Akyürek, E.; Bolukbasi, T.; Liu, F.; Xiong, B.; Tenney, I.; Andreas, J.; Guu, K. Tracing knowledge in language models back to the training data. arXiv 2022, arXiv:2205.11482. [Google Scholar]
- Li, J.; Ni, C.; He, D.; Li, L.; Xia, X.; Zhou, X. Efficient k NN query for moving objects on time-dependent road networks. VLDB J. 2022, 1–20. [Google Scholar] [CrossRef]
- Duan, R.; Deng, H.; Tian, M.; Deng, Y.; Lin, J. SODA: A large-scale open site object detection dataset for deep learning in construction. Autom. Constr. 2022, 142, 104499. [Google Scholar] [CrossRef]
- Segev, A.; Gunadhi, H. Event-Join Optimization in Temporal Relational Databases; Lawrence Berkeley National Lab. (LBNL): Berkeley, CA, USA, 1989.
- Maruta, A.; Kato, M.P. Intent-Aware Data Visualization Recommendation. Data Sci. Eng. 2022, 7, 301–315. [Google Scholar] [CrossRef]
- Yu, H.; Guo, X.; Luo, X.; Bian, W.; Zhang, T. Construct Trip Graphs by Using Taxi Trajectory Data. Data Sci. Eng. 2023, 8, 1–22. [Google Scholar] [CrossRef]
- Brinkhoff, T. A framework for generating network-based moving objects. Geoinformatica 2002, 6, 153–180. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Software and Hardware | Version/Model |
|---|---|
| Operating system | Windows 10 (1902) |
| CPU | Intel Core i7-7700 HQ |
| Memory | 8 GB |
| Hard disk | 1 TB |
| Java | Jdk1.8.2 |
| Dataset | Name | Number of Vertices | Number of Sides |
|---|---|---|---|
| BJ | Beijing | 188,229 | 436,648 |
| NY | New York City | 264,346 | 733,846 |
| COL | Colorado | 435,666 | 1,056,066 |
| NW | Northwest USA | 1,207,945 | 2,840,208 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, K.; Dong, Z.; Shi, W.; Gan, Z. A Dynamic Grid Index for CkNN Queries on Large-Scale Road Networks with Moving Objects. Appl. Sci. 2023, 13, 4946. https://doi.org/10.3390/app13084946
Tang K, Dong Z, Shi W, Gan Z. A Dynamic Grid Index for CkNN Queries on Large-Scale Road Networks with Moving Objects. Applied Sciences. 2023; 13(8):4946. https://doi.org/10.3390/app13084946
Chicago/Turabian StyleTang, Kailei, Zhiyan Dong, Wenxiang Shi, and Zhongxue Gan. 2023. "A Dynamic Grid Index for CkNN Queries on Large-Scale Road Networks with Moving Objects" Applied Sciences 13, no. 8: 4946. https://doi.org/10.3390/app13084946