
A Method Improves Speech Recognition with Contrastive Learning in Low-Resource Languages

Abstract
:1. Introduction
- We propose the false negatives impact elimination (FNIE) method and optimize the corresponding loss function to improve the quality of the negative sample set of speech, allowing the model to learn better speech representations and achieve better results in low-resource speech recognition;
- We found that simply increasing the number of negative samples does not improve the model’s ability to learn speech representations;
- By training our model on a variety of low-resource languages, we have validated its feasibility and effectiveness.
2. Related Work
2.1. Contrastive Predictive Coding
2.2. wav2vec
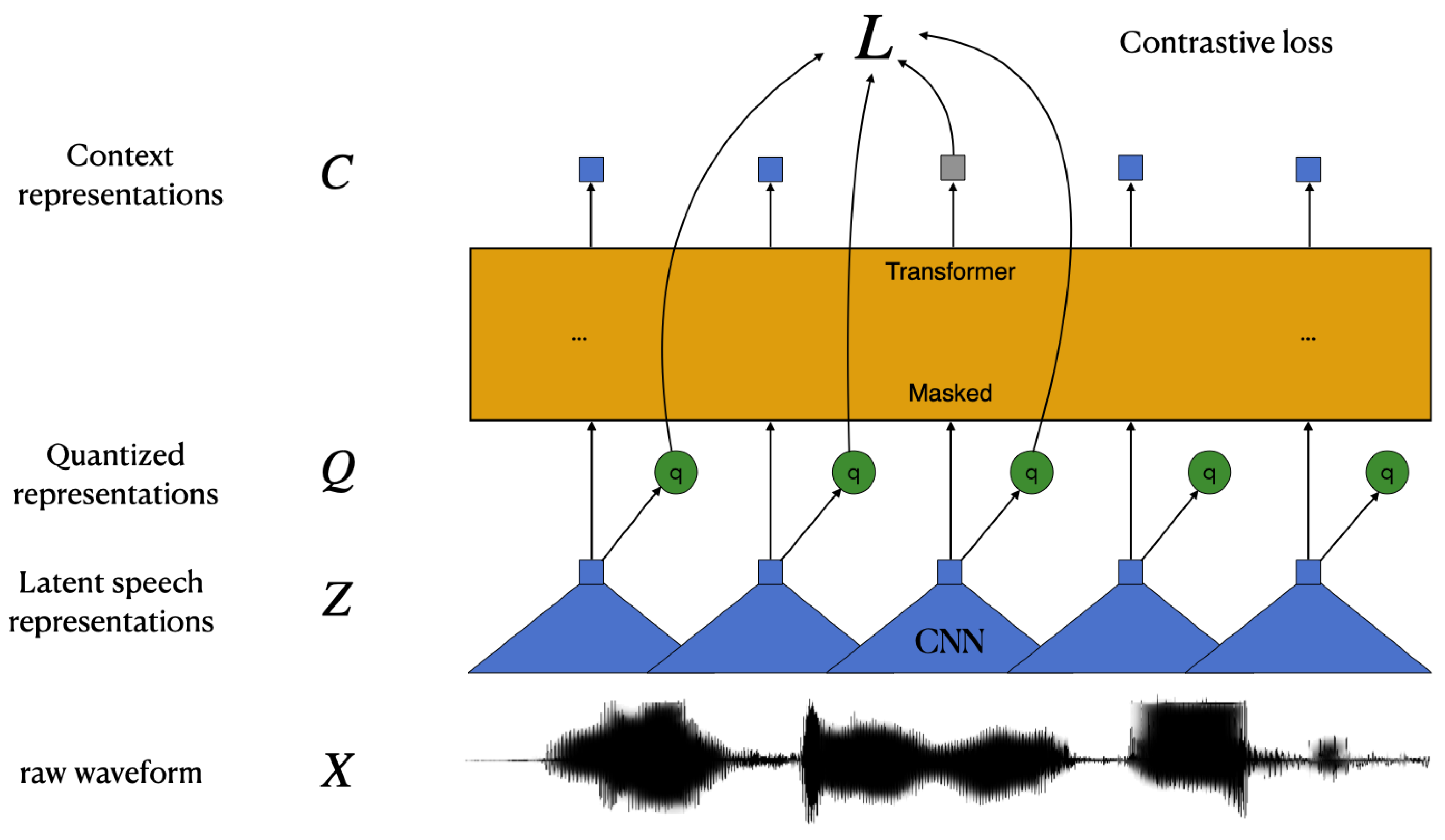
2.3. wav2vec 2.0
3. Mathods
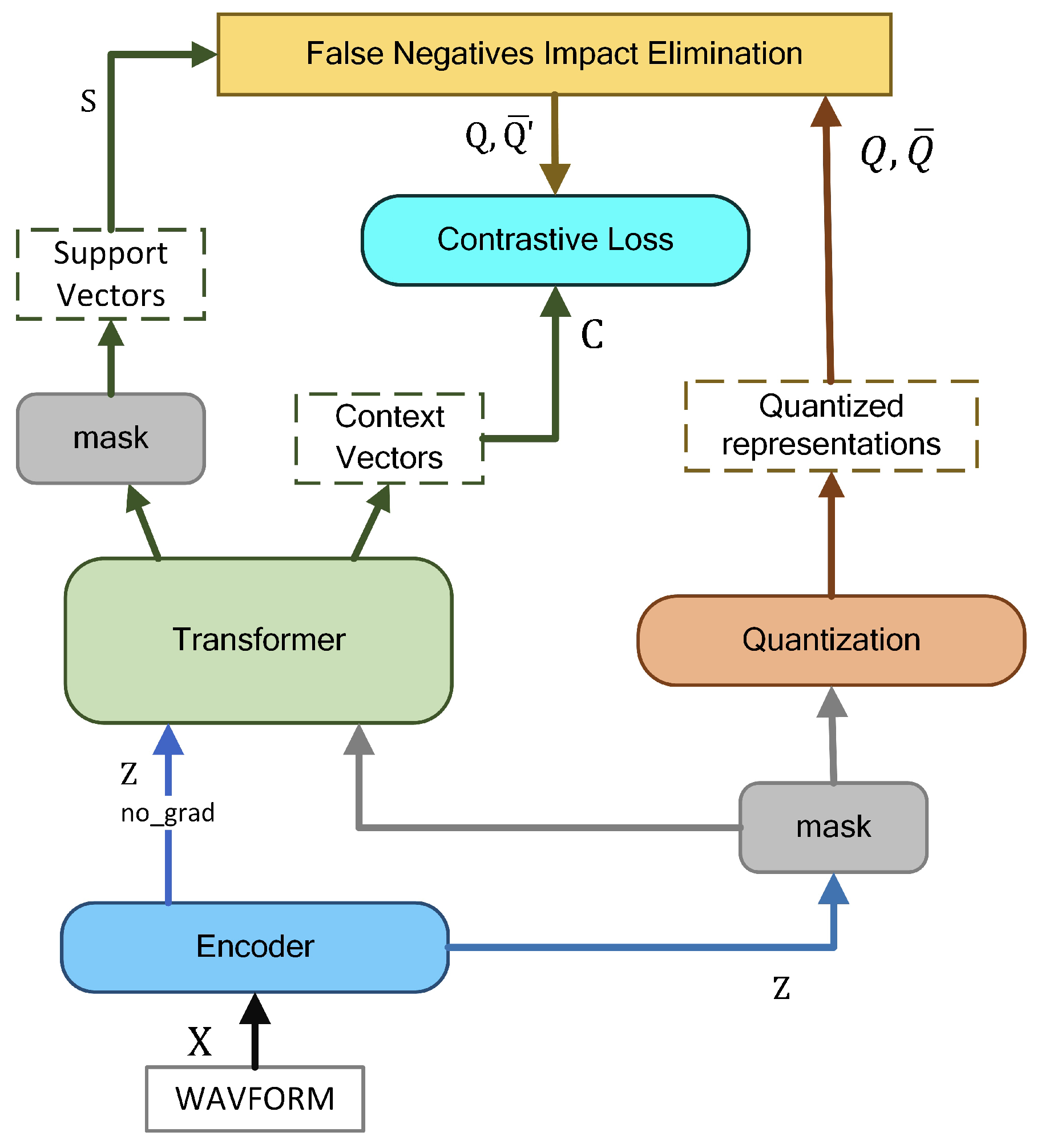
3.1. Model
3.2. FNIE
3.2.1. Finding False Negative Samples
- For each time step t, the original audio feature is transformed by a Transformer function. to produce the support vector .
- For each negative sample and each support vector , calculate the similarity score, .
- For each negative sample and the corresponding support vector, calculate the similarity and sort the scores in descending order: .
- Define a set of potential false negative samples , where the negative samples are the N most similar to the support vector at that step, , and .
3.2.2. Delete
3.2.3. Assimilate
4. Experimental Methods
4.1. Corpus
4.2. Implementation Details
5. Experimental Results
5.1. Results of Deleting False Negative Samples
5.2. Results of Assimilating False Negative Samples
5.3. Discussion on the Number of Negative Samples
5.4. Results of Different Languages
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011; IEEE Signal Processing Society: Piscataway, NJ, USA, 2011. [Google Scholar]
- Li, J.; Ye, G.; Das, A.; Zhao, R.; Gong, Y. Advancing acoustic-to-word CTC model. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5794–5798. [Google Scholar]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X.; et al. A comparative study on transformer vs rnn in speech applications. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 449–456. [Google Scholar]
- Nakatani, T. Improving transformer-based end-to-end speech recognition with connectionist temporal classification and language model integration. In Proceedings of the Proceedings Interspeech, Graz, Austria, 15–19 September 2019; Volume 2019. [Google Scholar]
- Dong, L.; Xu, S.; Xu, B. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5884–5888. [Google Scholar]
- Kim, C.; Gowda, D.; Lee, D.; Kim, J.; Kumar, A.; Kim, S.; Garg, A.; Han, C. A review of on-device fully neural end-to-end automatic speech recognition algorithms. In Proceedings of the 2020 54th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 1–5 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 277–283. [Google Scholar]
- David, M.; Simons, G.F.; Fennig, C.D. Ethnologue: Languages of the World, 26th ed.; SIL International: Dallas, TX, USA, 2023; Available online: http://www.ethnologue.com (accessed on 16 December 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR: London, UK, 2020; pp. 1597–1607. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. Simcse: Simple contrastive learning of sentence embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Song, X.; Huang, L.; Xue, H.; Hu, S. Supervised prototypical contrastive learning for emotion recognition in conversation. arXiv 2022, arXiv:2210.08713. [Google Scholar]
- Zhang, R.; Ji, Y.; Zhang, Y.; Passonneau, R.J. Contrastive Data and Learning for Natural Language Processing. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Tutorial Abstracts, Online, 10–15 July 2022; pp. 39–47. [Google Scholar]
- Thota, M.; Leontidis, G. Contrastive domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2209–2218. [Google Scholar]
- Wang, T.; Isola, P. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR: London, UK, 2020; pp. 9929–9939. [Google Scholar]
- Hoffmann, D.T.; Behrmann, N.; Gall, J.; Brox, T.; Noroozi, M. Ranking info noise contrastive estimation: Boosting contrastive learning via ranked positives. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 897–905. [Google Scholar]
- Huynh, T.; Kornblith, S.; Walter, M.R.; Maire, M.; Khademi, M. Boosting contrastive self-supervised learning with false negative cancellation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2785–2795. [Google Scholar]
- Kalantidis, Y.; Sariyildiz, M.B.; Pion, N.; Weinzaepfel, P.; Larlus, D. Hard negative mixing for contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21798–21809. [Google Scholar]
- Zhang, Y.; Zhang, R.; Mensah, S.; Liu, X.; Mao, Y. Unsupervised sentence representation via contrastive learning with mixing negatives. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 11730–11738. [Google Scholar]
- Cao, R.; Wang, Y.; Liang, Y.; Gao, L.; Zheng, J.; Ren, J.; Wang, Z. Exploring the Impact of Negative Samples of Contrastive Learning: A Case Study of Sentence Embeddin. arXiv 2022, arXiv:2202.13093. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Gutmann, M.; Hyvärinen, A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 297–304. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised pre-training for speech recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Baevski, A.; Schneider, S.; Auli, M. vq-wav2vec: Self-supervised learning of discrete speech representations. arXiv 2019, arXiv:1910.05453. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Bai, J.; Li, B.; Zhang, Y.; Bapna, A.; Siddhartha, N.; Sim, K.C.; Sainath, T.N. Joint unsupervised and supervised training for multilingual asr. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6402–6406. [Google Scholar]
- Rao, K.; Sak, H.; Prabhavalkar, R. Exploring architectures, data and units for streaming end-to-end speech recognition with rnn-transducer. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 193–199. [Google Scholar]
- Zhu, H.; Wang, L.; Wang, J.; Cheng, G.; Zhang, P.; Yan, Y. Wav2vec-S: Semi-Supervised Pre-Training for Low-Resource ASR. arXiv 2021, arXiv:2110.04484. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Li, M.; Huang, P.Y.; Chang, X.; Hu, J.; Yang, Y.; Hauptmann, A. Video pivoting unsupervised multi-modal machine translation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3918–3932. [Google Scholar] [CrossRef] [PubMed]
- Afham, M.; Rodrigo, R. Visual-Semantic Contrastive Alignment for Few-Shot Image Classification. arXiv 2022, arXiv:2210.11000. [Google Scholar]
- Yan, C.; Chang, X.; Li, Z.; Guan, W.; Ge, Z.; Zhu, L.; Zheng, Q. Zeronas: Differentiable generative adversarial networks search for zero-shot learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9733–9740. [Google Scholar] [CrossRef] [PubMed]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 5206–5210. [Google Scholar]
- Bu, H.; Du, J.; Na, X.; Wu, B.; Zheng, H. Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline. In Proceedings of the 2017 20th Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Republic of Korea, 1–3 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Wang, D.; Zhang, X. Thchs-30: A free chinese speech corpus. arXiv 2015, arXiv:1512.01882. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common voice: A massively-multilingual speech corpus. arXiv 2019, arXiv:1912.06670. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A fast, extensible toolkit for sequence modeling. arXiv 2019, arXiv:1904.01038. [Google Scholar]
- Heafield, K. KenLM: Faster and smaller language model queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburgh, UK, 30–31 July 2011; pp. 187–197. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Language | Durations | Format | Sampling Rate | Speakers | Units |
|---|---|---|---|---|---|---|
| LibriSpeech-train-clean-100 h | English | 100 h | FLAC | 16 kHZ | 251 | subword |
| AISHELL-1 | Mandarin | 150 h | WAV | 16 kHZ | 340 | character |
| THCHS-30 | Mandarin | 33.5 h | WAV | 16 kHZ | 40 | character |
| Common Voice Corpus 11.0-Uyghur | Uyghur | 113 h | MP3 | 32 kHZ | 747 | subword |
| Common Voice Corpus 11.0-Uzbek | Uzbek | 258 h | MP3 | 32 kHZ | 2025 | subword |
| Method | K | N | Mandarin | ||
|---|---|---|---|---|---|
| CER% | |||||
| wav2vec 2.0 | 100 | 100 | 0 | 27.853 | |
| FNIE | 101 | 100 | 1 | 27.791 | |
| 102 | 100 | 2 | 27.335 | ||
| 104 | 100 | 4 | 26.755 | ||
| Method | English | ||||
| CER% | WER% | ||||
| wav2vec 2.0 | 100 | 100 | 0 | 11.753 | 23.998 |
| FNIE | 101 | 100 | 1 | 12.115 | 24.062 |
| 102 | 100 | 2 | 11.805 | 23.353 | |
| 104 | 100 | 4 | 12.18 | 24.254 | |
| Method | K | N | Mandarin | ||
|---|---|---|---|---|---|
| CER% | |||||
| wav2vec 2.0 | 100 | 100 | 0 | 27.853 | |
| FNIE | 101 | 100 | 1 | 26.725 | |
| 102 | 100 | 2 | 27.9 | ||
| Method | English | ||||
| CER% | WER% | ||||
| wav2vec 2.0 | 100 | 100 | 0 | 11.753 | 23.998 |
| FNIE | 101 | 100 | 1 | 11.694 | 23.315 |
| 102 | 100 | 2 | 11.862 | 24.023 | |
| Method | Loss | K | N | English | ||
|---|---|---|---|---|---|---|
| CER% | WER% | |||||
| FNIE | ass | 101 | 100 | 1 | 11.694 | 23.315 |
| del | 102 | 100 | 2 | 11.805 | 23.353 | |
| wav2vec 2.0 | - | 100 | 100 | 0 | 11.753 | 23.998 |
| - | 101 | 101 | 0 | 11.294 | 24.587 | |
| - | 102 | 102 | 0 | 11.328 | 24.909 | |
| - | 104 | 104 | 0 | 11.517 | 25.145 | |
| Method | Loss | K | N | Uyghur | |
|---|---|---|---|---|---|
| WER% | |||||
| wav2vec 2.0 | - | 100 | 100 | 0 | 5.76 |
| FNIE | ass | 101 | 100 | 1 | 5.423 |
| del | 102 | 100 | 2 | 4.936 | |
| Method | Loss | Uzbek | |||
| WER% | |||||
| wav2vec 2.0 | - | 100 | 100 | 0 | 16.789 |
| FNIE | ass | 101 | 100 | 1 | 12.019 |
| del | 102 | 100 | 2 | 10.902 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Yolwas, N.; Jiang, L. A Method Improves Speech Recognition with Contrastive Learning in Low-Resource Languages. Appl. Sci. 2023, 13, 4836. https://doi.org/10.3390/app13084836
Sun L, Yolwas N, Jiang L. A Method Improves Speech Recognition with Contrastive Learning in Low-Resource Languages. Applied Sciences. 2023; 13(8):4836. https://doi.org/10.3390/app13084836
Chicago/Turabian StyleSun, Lixu, Nurmemet Yolwas, and Lina Jiang. 2023. "A Method Improves Speech Recognition with Contrastive Learning in Low-Resource Languages" Applied Sciences 13, no. 8: 4836. https://doi.org/10.3390/app13084836