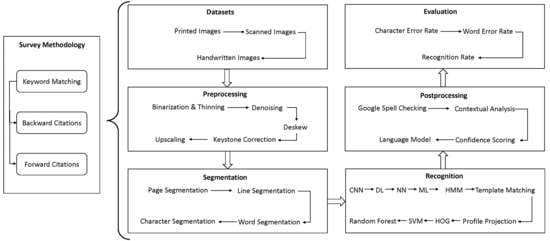
3.2. Segmentation
Segmentation is an important step in OCR involving separation of an image into its constituent parts, such as lines, words, and characters, for recognition. Three types of segmentation techniques are mainly used, i.e., line, word, and character segmentation. Word segmentation, specifically, is challenging in cursive languages such as Arabic due to a lack of clear separation between characters. Traditional segmentation methods in Arabic OCR rely on rules and heuristics based on character features, but deep learning techniques such as convolutional and recurrent neural networks have shown promising results in automatic segmentation. Accurate segmentation is crucial for recognition, and improving Arabic OCR segmentation can have significant implications for document digitization, text-to-speech conversion, and language translation.
The techniques used in [
67] include image processing techniques such as thresholding to convert the image into a binary image, morphological operations to perform operations such as erosion and dilation on the binary image, and connected component analysis to identify and label connected regions in the image. The authors use two databases for evaluating the performance of the proposed method. The first database is the publicly available RDI-Arabic dataset, which consists of 1000 images of Arabic text documents. The second database is a new dataset created by the authors and consists of 1000 images of Arabic text documents. The research results show that the proposed image-processing techniques can accurately segment Arabic text documents into text lines, words, and characters with a high degree of accuracy. The researchers use several evaluation metrics, such as F-score, precision, and recall, to evaluate the performance of the proposed method. The results show that the proposed method outperforms traditional methods regarding segmentation accuracy.
Urdu language characters are the super-set of Arabic language characters, and certain challenges are faced when performing segmentation of Urdu-like cursive languages [
68]. Arabic is mainly written in Naskh, while Urdu is written in Nastaliq style. There are some challenges in the segmentation of Urdu script, i.e., cursive nature, difficult fonts such as Nastaliq, and letters changing their shape into different forms as required in the word; and cue points are hard to find in the Naskh or Nastaliq style. That is why segmentation is challenging, and character segmentation has been considered difficult in previous research. Researchers mostly used the projection profile method for segmentation, which can perform a vertical projection of the given text. However, in Arabic or Urdu, text writing starts from right to left and top to bottom, so vertical and horizontal projection is required. Analytical approaches are difficult and give the wrong character recognition results, but explicit and implicit recognition systems also give better accuracy. At the same time, holistic approaches are considered best by researchers for better accuracy with the correct recognition. Furthermore, there are better approaches than segmentation-free approaches for large vocabularies. For a reasonable accuracy rate, segmentation should perform well using the approaches that are correct and appropriate for segmentation.
Thorat et al. [
69] presented a survey to discuss the methods used by previous researchers. It discussed OCR systems, tools, applications, phases, and methods. There are two types of documents, i.e., unilingual and multilingual documents. Some OCR systems are discussed, i.e., Google Docs OCR, Tesseract, ABBYY FineReader, Transym, and I2OCR, which help to provide services and help to extract text from different types of documents with different languages, whether they are unilingual or multilingual. Multilingual documents contain text from multiple languages, and the techniques used are binarization, layout analysis, page segmentation, preprocessing, feature extraction, classification, and recognition. Some approaches are used for the segmentation-free approach and HMM. There are some applications where OCR systems are used to ease use and increase work productivity in healthcare, education, banking, insurance, automatic exam paper checking, bills and invoices, newspapers, and comics. Some phases are discussed to process the document to get better accuracy, including image acquisition, preprocessing, segmentation, classification and recognition, and postprocessing. Moreover, methods used by previous researchers are matrix matching, fuzzy logic, structural analysis, and neural networks.
3.2.1. Line Segmentation
In line segmentation, the skew-corrected image is divided into lines. Line segmentation is an important step in OCR as it allows the separation of the image into individual lines so that the OCR system can process them one-by-one and improve the recognition of the text in the image. Connected component analysis, project profile, and machine learning-based approaches can be used to perform line segmentation. Once the lines of text have been segmented, the OCR system can process each line individually, which can improve the accuracy of the character recognition process.
A method for line segmentation of printed Arabic text with diacritics using a divide-and-conquer algorithm is presented in [
70]. It breaks the image of printed text into smaller blocks, applies image processing techniques to extract the text lines, and then applies a set of heuristic rules to remove false positives and adjust the segments as necessary. It uses image processing techniques such as thresholding, morphological operations, and connected component analysis. The research results show that the proposed method can accurately segment printed Arabic text with diacritics into text lines with a high degree of accuracy. The research uses several evaluation metrics such as F-score, precision, recall, and F-Measure to evaluate the performance of the proposed method.
Brodic et al. [
71,
72] proposed a basic standardized test framework for evaluating the quality of text line segmentation algorithms in OCR systems for accurate handwritten text recognition. Their proposed framework includes experiments for measuring the accuracy of text line segmentation, skew rate, and reference text line evaluation.
3.2.2. Word segmentation
After line segmentation, each word from the line is segmented by dividing the line of the text into individual words. Several techniques are used for word segmentation, i.e., the Spacing method involves using the spaces between words to segment the text into words. The dictionary-based method uses a dictionary of words to match against the text and segments the text into words based on the matches. Character-based methods use a combination of known character patterns, such as word breaks and punctuation, to segment the text into words. Deep-learning approaches use supervised learning on annotated datasets to learn the complex relationships between adjacent characters in order to infer word boundaries [
73,
74].
The authors of [
75] present word segmentation in Arabic handwritten images using a convolutional recurrent neural network (CRNN) architecture. The authors employ a sliding-window approach for word segmentation, where each window is classified as either a word or non-word using a support vector machine (SVM) classifier. The experimental results show that the proposed CRNN architecture achieves state-of-the-art performance in Arabic handwriting word recognition, with an accuracy of
on the IFN/ENIT dataset.
Patil et al. [
76] propose a semantic segmentation approach for images containing mixed text to segment the image into different regions based on their content. The segmented regions are then processed using different OCR methods that are specifically tailored to the type of text in each region.
3.2.3. Character Segmentation
Character-level segmentation is a technique used to segment an image of a single word into individual letters and characters. It is an optional step depending on the context of the OCR system that is being used. It may be unnecessary if the text has separate letters within a word, as the letters and characters can be segmented in the previous step using a threshold. However, character-level segmentation must be performed if the text has cursive handwriting or a nature where letters are joined.
A method for recognizing and transcribing text from a visual Arabic scripting news ticker from a broadcast stream is presented in [
77]. The technique used in this research includes image processing techniques such as thresholding, morphological operations, and connected component analysis to segment the text from the background. It uses machine learning algorithms such as CNNs and long short-term memory (LSTM) to transcribe text. The research results show that the proposed method can accurately recognize and transcribe text from a visual Arabic scripting news ticker from a broadcast stream. The research uses several evaluation metrics, such as character error rate (CER) and word error rate (WER), to evaluate the performance of the proposed method. The results show that the proposed method outperforms traditional methods in recognition accuracy, achieving a lower CER and WER than traditional methods on the dataset used in the research.
Alginahi [
78] discusses Arabic character segmentation approaches, including traditional methods such as vertical and horizontal projection, contour tracing and thinning, template matching, neural networks and HMM, holistic approaches and segmentation-free approaches, projection profile, baseline, contour tracing, graph theory, and morphology. The paper also discusses the challenges and limitations of each approach and suggests areas for future research. It also discusses the benefits and problems with character segmentation, especially in Arabic; problems are due to its cursive nature and the different shapes of each character depending on the word’s appearance. Problems also occur because of datasets. Therefore, the Arabic Language Technology Center (ALTEC) have provided limited free access to a reliable dataset.
A method for segmenting characters, letters, and digits from Arabic handwritten document images using a hybrid approach is presented in [
79]. The method uses image processing techniques, such as thresholding, morphological operations, and connected component analysis, to segment the text from the background and to separate the characters. In addition, machine learning algorithms, including
k-means clustering and a Random Forest Classifier, are used to classify the segments into individual characters. The research demonstrates that the proposed method can accurately segment characters from Arabic handwritten document images with a high degree of accuracy. The method outperforms traditional methods regarding segmentation accuracy, as evidenced by several evaluation metrics, including F-score, precision, and recall. The proposed method achieves a higher F-score, precision, and recall than traditional methods on the dataset used in the research.
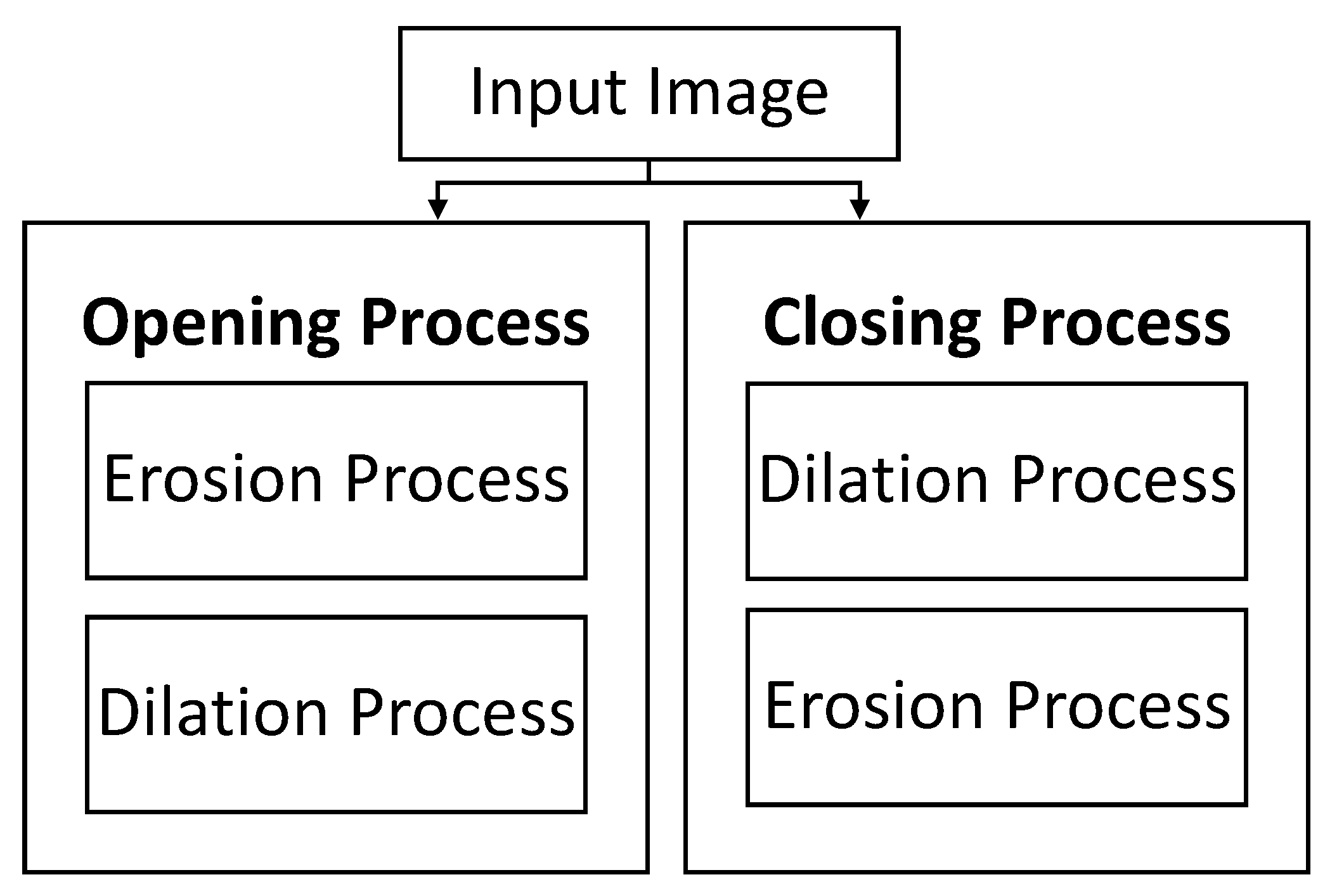
Morphological operators are also used for segmenting Arabic handwritten words [
80]. The process involves using morphological operations, such as erosion and dilation, to extract the text from the background and segment the words. The technique used in this research is based on morphological operators, which perform operations such as erosion and dilation on binary images, to extract the text and separate the words. The method also uses image processing techniques, such as thresholding, to convert the image into a binary image and connected component analysis to identify and label connected regions corresponding to words. The research results show that the proposed method can accurately segment Arabic handwritten words with a high degree of accuracy. The research used several evaluation metrics, such as F-score, precision, and recall, to evaluate the performance of the proposed method. The results show that the proposed method outperforms traditional methods in terms of segmentation accuracy.
Some previous works have proposed segmentation-free approaches for Arabic and Urdu OCR, but they do not produce accurate results on clean text. The authors of [
18] apply a machine learning model on clean Urdu and Arabic datasets, producing
and
accuracy on clean UPTI datasets. The authors of [
34] review current approaches and challenges unique to Urdu OCR and suggest that future research should focus on developing more-sophisticated algorithms, improving training data, and addressing the unique challenges of the Urdu script. They also propose that integrating Urdu OCR with other technologies, such as machine learning and computer vision, would provide new opportunities for research in the field.
Handwritten digit recognition is discussed in [
81]. It has various applications and is used in different fields such as postal mail sorting, bank check numbering, amount processing, and number entries of various forms such as taxes, insurance, and utility bills. There are handwritten images of 10 digits in the dataset from 0 to 9, and this dataset is taken from MNIST, which contains 60,000 and 10,000 images for training and testing purposes, respectively. Then, some phases and approaches are used to process the images to train and test the model, which helps to get better accuracy and gives a maximum recognition rate. Discussed phases and approaches are preprocessing and feature extraction, and then classification is used. In classification, machine learning approaches, i.e., Decision Tree, Support Vector Machine (SVM), and Artificial Neural Network (ANN), are used. The deep learning approach implements a Visual Geometry Group model with 16 layers (VGG16 model); this model is used for deep-learning image-classification problems. By using the proposed techniques, we get better recognition and a high accuracy rate; i.e., in decision tree
, SVM
, ANN
, and CNN
accuracy is achieved.
3.3. Recognition
Recognition, also called classification in some previous works, is the process of identifying and assigning a specific character or set of characters to a given input image. After preprocessing and segmentation, the OCR system compares the extracted features of each character or group of characters with a set of predefined templates or models. The OCR system creates these templates during a training phase, where a large dataset of sample images is used to teach the system how to recognize each character.
The classification/recognition process can involve several algorithms, including template matching, neural networks, and support vector machines. Template matching involves comparing the features of each character to predefined templates and selecting the template with the closest match to the recognized character. Neural networks and support vector machines use machine learning algorithms to learn and classify patterns in the data and can often achieve higher accuracy than template matching.
A survey of feature extraction and classification techniques is presented in [
82]. The techniques include digitization, preprocessing, segmentation, feature extraction, and postprocessing. Statistical, structural, template matching, artificial neural network, and kernel classification methods are also discussed.
An efficient feature-descriptor selection for improved Arabic handwritten word recognition is presented in [
83]. The approach uses three image features, Histogram Oriented Gradient (HOG), Gabor Filter (GF), and Local Binary Pattern (LBP), for feature extraction, and trains a
kNN algorithm to build models. The best model achieved an accuracy of
. A publicly available IFN/ENIT Arabic dataset is also introduced. The researcher use the global approach in the research, which is considered successful and in many cases is used more than the analytical approach.
Various methods and techniques are used in multilingual OCR [
84], including preprocessing, binarization, segmentation, feature extraction, and recognition. Segmentation uses three different approaches, i.e., top-down, bottom-up, and hybrid approach, including page, line, and word/character level. The research also explores the challenges to and limitations of current multilingual OCR systems, such as dealing with different scripts and languages and the need for large amounts of annotated training data. The paper highlights the importance of multilingual OCR for applications such as digital libraries, document archiving, and machine translation. Overall, the paper provides a comprehensive overview of the current state of multilingual OCR research and its potential applications. The paper highlights the importance of multilingual OCR for various applications such as digital libraries, document archiving, and machine translation.The authors of [
85] discuss the ongoing design of a tool for automatically extracting knowledge and cataloging documents in Arabic, Persian, and Azerbaijani using OCR, text processing, and information-extraction techniques.
A method using a combination of CNN and RNN for recognizing Arabic text in natural scene images is presented in [
86]. The method utilizes an attention mechanism to focus on the most relevant parts of the image and improve text recognition accuracy. Two datasets are used in this research for training purposes, i.e., ACTIV and ALIF. ACTIV contains 21520 images of text lines, while ALIF contains 6532 images of text lines; both datasets are extracted from different news channels. Testing is done on the Arabic natural scene text dataset (ANST) the authors created. The proposed method is evaluated on this dataset, which shows that it outperformed the state-of-the-art methods for Arabic text recognition in natural scene images with an accuracy of
. The model uses CNN to extract features from the image and RNN to process the features and generate the text recognition output. At the same time, the attention mechanism improves the accuracy of recognition (
https://tc11.cvc.uab.es/datasets/type/11, accessed on 18 March 2023).
Language detection, document categorization, and region of interest (RoI) identification with KERAS and TensorFlow are used to perform manuscript analysis and recognition in OCR systems [
87]. The RoI includes tables, titles, paragraphs, figures, and lists. The deep-learning-trained model uses bounding-box regression to identify the target and serves as a reference point for object detection. The system integrates the fast gradient sign method (FGSM) and uses deep learning to recognize multilingual systems. It also investigates page segmentation methods to enhance accuracy. The system performs well against adversarial attacks on Arabic manuscripts and achieves an accuracy of
. It uses Hierarchical Agglomerate Clustering (HAC) to group objects in clusters based on similarity/relation. The research aims to improve preprocessing and identify parameters to enhance the accuracy of page segmentation methods.
A survey of various methods and techniques used for recognizing text in natural images and videos is presented in [
88]. The authors discuss various challenges and propose approaches for recognizing text in the wild due to font, color, and background variations. The paper covers traditional methods as well as more-recent methods based on deep learning, such as CNN and RNN. The authors also discuss evaluation metrics and datasets used for text recognition in the wild. Overall, the paper provides an overview of the state-of-the-art in text recognition in the wild and highlights areas that need further research. Additionally, the authors provide a comprehensive review of publicly available resources on their Github repository (
https://github.com/HCIILAB/Scene-Text-Recognition, accessed on 22 March 2023).
Bouchakour et al. [
89] use the CNN classifier for printed Arabic OCR using a combination of texture, shape, and statistical features. Evaluation of the proposed method achieves an accuracy of
, which shows the effectiveness of combining image features with a CNN classifier. Similarly, the authors of [
90] conduct experiments to analyze the impact of different hyper-parameters and network architectures on the performance of a CNN model for OCR of handwritten digits.
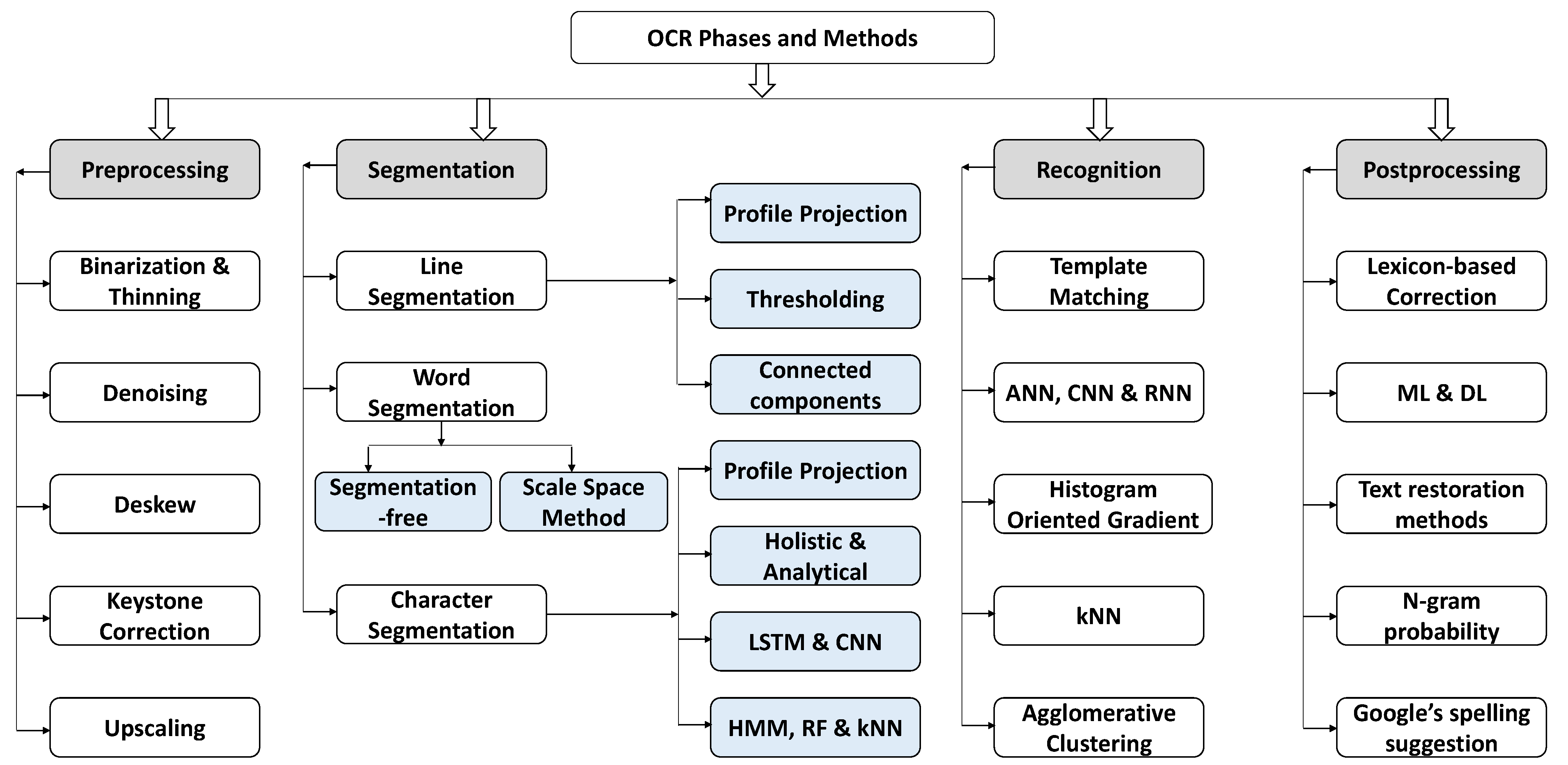
The authors of [
91] survey OCR methodologies for Urdu fonts, such as Nastaliq and Naskh, and other similar languages having Urdu-like scripts, such as Arabic, Pashtu, and Sindhi. Moreover, the main focus of this survey is to compare all of the phases involved in OCR, i.e., Image Acquisition, Preprocessing, Segmentation, Feature Extraction, Classification, and Recognition. The Urdu Printed Text Images (UPTI) dataset is divided into training, testing, and validation. It contains about 10,000 text images; so for implementation, multidimensional LSTM-RNN is used, and it achieves an accuracy of
. Many stages in the phases make the OCR system better, and it is important to follow all of the stages to make a perfect system, as shown in
Figure 7. In the past, researchers used multiple datasets and found a specific output such as character recognition or ligatures recognition and achieved good accuracy.
An artificial neural network (ANN) classifier to identify the characters in a text is presented in [
92]. The dataset is generated from different documents with different qualities of the result. A preprocessing step is used to eliminate noise; then, the segmentation phase is done using multiple steps, i.e., line, word, and character segmentation. A feature-extraction step for the character’s image is performed to obtain features for all the pixels. The authors trained the ANN classifier on a dataset of printed Arabic text and then evaluated its performance on a separate test set. The results show that the system can accurately recognize the characters in the test set with high recognition rates. A KERAS model is used with a three-layer ANN classifier for character classification. Noise density and multi-spatial resolution matrices are used for evaluation, showing a fast, efficient, high-performance OCR system.
Mittal and Garg [
93] review the various techniques used for text extraction from images and documents using OCR; they also discuss the challenges and limitations of text extraction. Reviewed papers are grouped on the basis of the types of OCR techniques that are used. The authors found that the most-used OCR techniques are based on machine learning, specifically deep learning. They also found that the OCR techniques that use multiple-recognition engines and preprocessing techniques perform better than single-recognition-engine-based techniques.
Deep learning models such as CNN, RNN, and attention-based models are discussed in [
94]. The paper discusses the performance of models on different Arabic handwritten datasets, and these models show much-improved character recognition rate, word recognition rate, and overall recognition rate. The researchers also discussed challenges dealing with different handwriting styles and sizes.
The authors of [
95] present a method for recognizing Arabic handwritten characters using different Holistic techniques, CNN, and deep learning models. At the same time, all of the techniques are well reviewed in this research, i.e., preprocessing, segmentation, feature extraction, recognition, and postprocessing. The authors found that using these models and techniques properly improves the recognition rate of the system by a significant margin.
In [
96], automatically extracting and processing text from images is discussed. The challenges that may arise in OCR stages are also explored, as well as the general phases of an OCR system, including preprocessing, segmentation, normalization, feature extraction, classification, and postprocessing. Additionally, the paper highlights OCR’s main applications and provides a review of the state-of-the-art at the time of its publication.
The approaches to processing text from documents are reviewed in [
97]. In this review, text detection and text transcription are discussed. Text detection is a task whereby a process detects or finds text in a document or image. It is a difficult task but can be detected easily by box bounding and text detection as object detection. Text detection as object detection is challenging but is solved using computer vision tasks such as single-shot multi-box detectors and fast R-CNN models. Meanwhile, in text transcription, the text is extracted in editable form from the document or image of interest. Document layout analysis is the dominant part of selecting the region of interest. Then, the authors identify some datasets used in past research: ICDAR, Total-Text, CYW1500, SynthText, and the updated dataset FUNSD.
3.4. Postprocessing
Postprocessing is the final step in the OCR process; it involves improving the accuracy and quality of the recognized text. Postprocessing techniques can include various methods, such as spell checking, contextual analysis, confidence scoring, and language-model integration. Spell checking involves comparing the recognized text against a dictionary of words to identify and correct spelling errors. Contextual analysis analyses the recognized text within the context of the surrounding text to identify and correct errors that may be caused by confusion with other words. Confidence scoring assigns a confidence score to each recognized character based on the certainty of the OCR system’s recognition, and characters with lower confidence scores are flagged for review or correction. The language model is also used to analyze the recognized text in the language context. Postprocessing significantly improves the accuracy and quality of the recognized text.
An overview of the different postprocessing techniques developed and applied to OCR output, including methods for correction of errors, text enhancement, and text restoration, is discussed in [
98]. Various methods are used in postprocessing, including spell checking, grammar checking, lexicon-based correction, machine learning, and deep-learning-based approaches. The paper also discusses using different types of features, such as character-level, word-level, and document-level features, as well as preprocessing techniques, such as segmentation and normalization.
Several approaches have been used in the postprocessing of OCR output to improve the accuracy and completeness of the recognized text:
Spell checking: checks the spelling of the recognized text and corrects any errors by comparing it to a dictionary [
99].
Grammar checking: checks the grammar of the recognized text and corrects any errors by comparing it to a set of grammar rules.
Lexicon-based correction: uses a lexicon (a list of words and their possible variations) to correct errors in the recognized text by comparing it to the lexicon and suggesting alternative words where there are errors.
Machine-learning-based approaches: uses machine learning algorithms, such as decision trees, random forests, and support vector machines, to correct errors in the recognized text.
Deep-learning-based approaches: uses deep learning algorithms, such as CNNs and RNNs, to correct errors in the recognized text.
Text enhancement: includes techniques to improve the recognized text’s visibility, legibility, and readability, such as binarization, deskewing and smoothing of text.
Text restoration: includes techniques to recover missing or degraded text, such as text in-painting, completion, and restoration.
The authors of [
98] also present the results of various experiments and evaluations conducted to assess the performance of postprocessing techniques. These include comparisons of different methods and systems, evaluations of the effects of different types of features and preprocessing techniques, and evaluations of the performance of systems on different types of OCR output and languages.
Doush et al. [
100] present a word-context and rule-based technique for OCR postprocessing. OCR is used to obtain text from scanned documents, and the output text is not always
accurate. Thus, after obtaining the text, postprocessing step is required to recognize and minimize the errors. The presented research is about printed documents, it lies in an offline OCR system. Cursive nature also causes problems in this step because characters in Arabic are connected, and there are other additional things such as diacritics and different shapes of each character in different words. These things bring more complications to this step. A very small amount of work has been done on the Arabic postprocessing technique because it shows a very high character and word error rate after recognition. Therefore, it is a less attractive side for researchers. In the proposed research, an Arabic text database is prepared, available in three formats, i.e., HTML, PDF, and scanned-document images. The database has 4581 files, and there are about 8994 scanned images. Thus, from the database, 1000 images are used for training by the rule-based method, which reduces the word error rate.
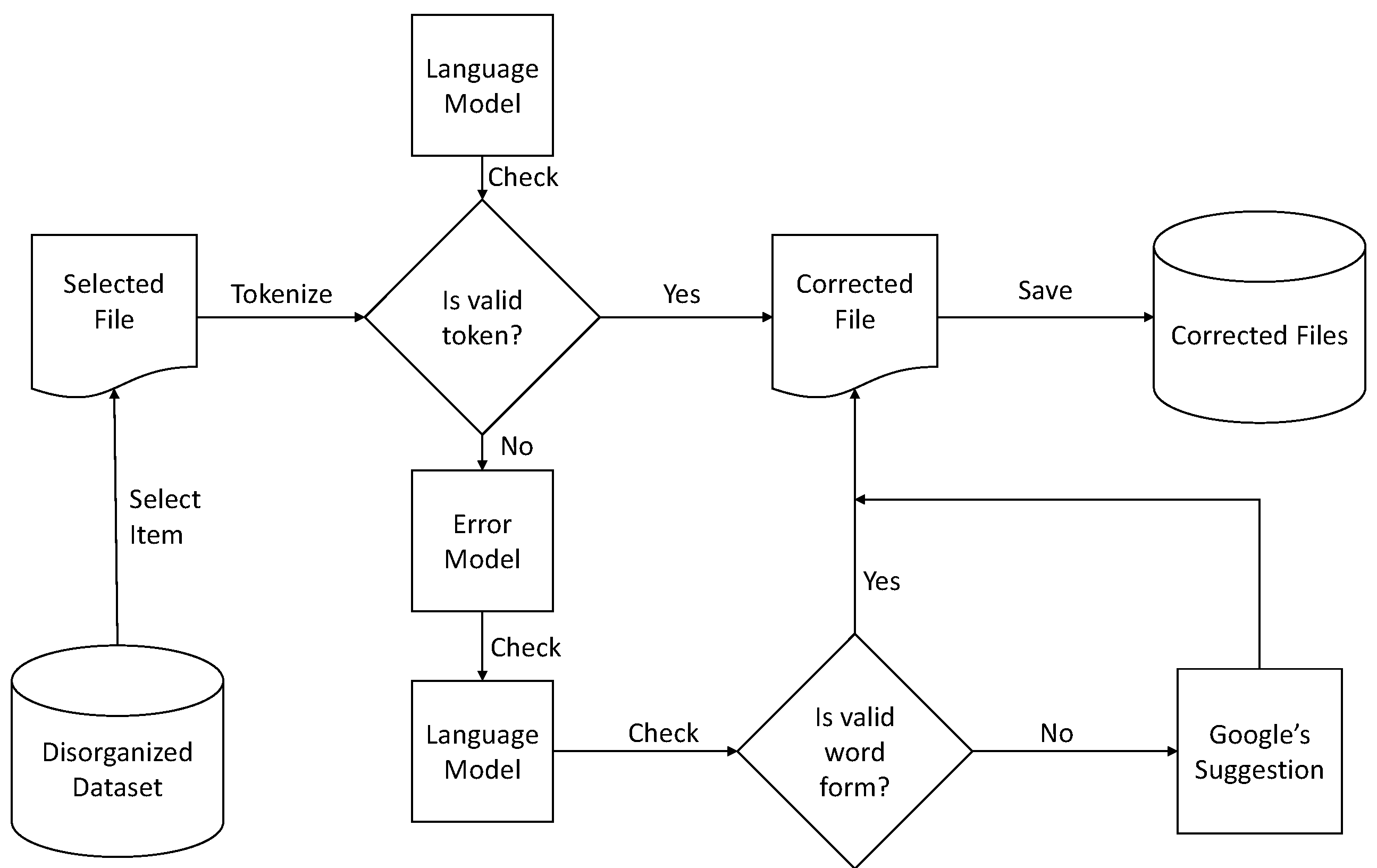
Bassil and Alwani propose an algorithm using Google’s online spelling suggestions [
101], which helps to improve the accuracy and suggest what should come after each character to make a meaningful word according to the sentence. All of the suggestions given by Google’s spelling suggestion algorithm are based on N-gram probability. The authors hybridize this method to make the proposed postprocessing technique. Therefore, the proposed hybrid postprocessing system starts with the generated OCR file (token). The language model checks each token, and if the language model does not find this token, then the error model takes this token and suggests the correct word. This token/word again goes into the language model in an attempt to find matches for the token. If it matches, then the model moves to the next word; otherwise, the error model again suggests the new token provided by Google’s spelling suggestion algorithm, as shown in
Figure 8.
The authors of [
102] present a corpus-based technique for improving the performance of an Arabic OCR system. The method involves using a large corpus of texts in Arabic to train the OCR system and improve its recognition accuracy. The corpus of texts is preprocessed to ensure that it is suitable for OCR training, and then it is used to train the OCR system. The performance of the OCR system is then evaluated using a set of test images, and the recognition accuracy is compared to that of traditional methods. The study also shows that using a larger corpus of texts leads to better performance of the OCR system. This phase helps to provide better recognition or reduce the word error rate and character error rate. The collection of a large corpus of texts in Arabic is used to train the OCR system and then preprocess the corpus to ensure that it is suitable for OCR training. The OCR system is trained using the preprocessed corpus, and the OCR system’s performance is evaluated using a set of test images. The research shows that the corpus-based technique improves the recognition accuracy of the OCR system by a significant margin compared to traditional methods. It also shows that using a larger corpus of texts leads to better performance of the OCR system.
3.5. Evaluation
Evaluation measures the accuracy and quality of the recognized text output. OCR evaluation typically involves comparing the recognized text to the original input image or document and calculating various performance metrics to assess the quality of the OCR output. Some common metrics used in OCR evaluation include character error rate (CER), word error rate (WER), recall, precision, and F1 score. OCR evaluation can be performed using various methods depending on the goal of the application, such as manual inspection, crowdsourcing, or automated evaluation software. Evaluation is an important step in OCR development and deployment, as it allows developers and users to assess the accuracy and quality of the OCR output and make improvements or adjustments to the OCR system as needed.
An Arabic OCR evaluation tool is discussed in [
103]. The Arabic language is difficult to recognize due to its characters’/alphabets’ behavior in different words. Arabic OCR’s accuracy could be higher because of improper evaluation of performance metrics. Different tools and software have been introduced to help find the performance and accuracy of the applied algorithms. The introduced software is built specially to check Arabic OCR; it checks the performance based on objectives, i.e., accuracy and evaluation metrics. These tools briefly describe the text in characters with or without dots, baseline, and diacritics and the class in which the text lies. These tools include Tesseract, easy OCR, Paddle-Paddle OCR, and PyMuPdf. Recognition rate (RR), character error rate (CER), and word error rate (WER) are the evaluation measures used by these programs to evaluate OCR output.
Kiessling et al. [
104] discuss various open-source tools for Arabic OCR systems containing Tesseract (
https://github.com/tesseract-ocr/tesseract, accessed on 24 February 2023), OCRad (
https://www.gnu.org/software/ocrad/, accessed on 24 February 2023), and GOCR (
https://jocr.sourceforge.net/, accessed on 24 February 2023). These tools are evaluated using an Arabic dataset, and Tesseract gives better recognition results. However, it is slower than other evaluated tools. These tools give better accuracy for high-resolution documents, and the accuracy gets worse as the quality of documents decreases.
The authors of [
105] provide an overview of existing tools and metrics used to evaluate the OCR system in previous research. Their paper covers traditional evaluation techniques and discusses their pros and cons. It also discusses evaluation metrics such as character error rate, word error rate, and recognition rate. The detailed review also discusses the many challenges involved in evaluating the performance of the OCR system.
The performances of generative and discriminative recognition models for offline Arabic handwritten recognition are compared using generatively trained hidden Markov modeling (HMM), discriminatively trained conditional random fields (CRF), and discriminatively trained hidden-state CRF (HCRF) in [
106]. The study presents recognition outcomes for words and letters and assesses the efficiency of all three strategies using the Arabic IFN/ENIT dataset.
Singh et al. [
107] discussed offline handwritten word recognition in Devanagari. A holistic-based approach is used in this approach, wherein a word is considered a single entity, and the approach processes it further for extraction and recognition. A class of 50 words recognizes every word based on a feature vector set, uniform zoning, diagonal, centroid, and feature-based. The proposed system uses gradient-boosted algorithms to enhance the performance; furthermore, some other classifiers are used for this purpose, i.e.,
kNN and Random Forest Classifier. Thus, the overall achieved accuracy is
. The authors generate the dataset during the implementation, which is available on request. The paper also provided some information on previous research in this area, where researchers used Hidden Markov Model, Support Vector Machine, and Multi-Layer perceptron classifiers. The authors also highlighted the importance of the availability of quality datasets for the improved performance of OCR techniques.
The impact of OCR quality on the accuracy of short text classification tasks is presented in [
108]. A multi-class classification of short text is introduced. For this, the authors propose a dataset of beauty product images that contains 27,500 entries of labeled brand data and generate results based on targeting specific brands. The authors also show that preprocessing techniques such as text normalization and noise reduction can improve the performance of the classification model on low-quality OCR text.
In addition to papers improving specific processes involved in OCR, some previous papers present a combination of various OCR techniques for overall improved process accuracy. OCR4all [
109] is an open-source OCR software that combines state-of-the-art OCR components and continuous model training into a comprehensive workflow for processing historical printings and provides a user-friendly GUI and extensive configuration capabilities. The software outperforms commercial tools on moderate layouts. It achieves excellent character error rates (CER) on very complex early printed books, making it a valuable tool for non-technical users and providing an architecture allowing easy integration of newly developed tools.



 ,
,  , and
, and  . These letters change their shapes according to their usage in different words. Upper and lower case annotation does not exist. A total of 15 letters out of 28 have a point or dot above or under the letter. Arabic letters are connected from the right or left sides or both sides. However, six letters cannot be connected to their successors in a word; those letters are
. These letters change their shapes according to their usage in different words. Upper and lower case annotation does not exist. A total of 15 letters out of 28 have a point or dot above or under the letter. Arabic letters are connected from the right or left sides or both sides. However, six letters cannot be connected to their successors in a word; those letters are  . There is another term called Tanween, which produces sound at the end of the words; these symbols are
. There is another term called Tanween, which produces sound at the end of the words; these symbols are  in written form. Punctuation marks have their own format in Arabic; e.g., the question mark in English is written as ‘?’, but its shape in Arabic is ‘
in written form. Punctuation marks have their own format in Arabic; e.g., the question mark in English is written as ‘?’, but its shape in Arabic is ‘ ’.
’.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}