
A Survey of Sentiment Analysis: Approaches, Datasets, and Future Research

Abstract
:1. Introduction
- A comprehensive overview of the state-of-the-art studies on sentiment analysis, which are categorized as conventional machine learning, deep learning, and ensemble learning, with a focus on the preprocessing techniques, feature extraction methods, classification methods, and datasets used, as well as the experimental results.
- An in-depth discussion of the commonly used sentiment analysis datasets and their challenges, as well as a discussion about the limitations of the current works and the potential for future research in this field.
2. Sentiment Analysis Algorithms
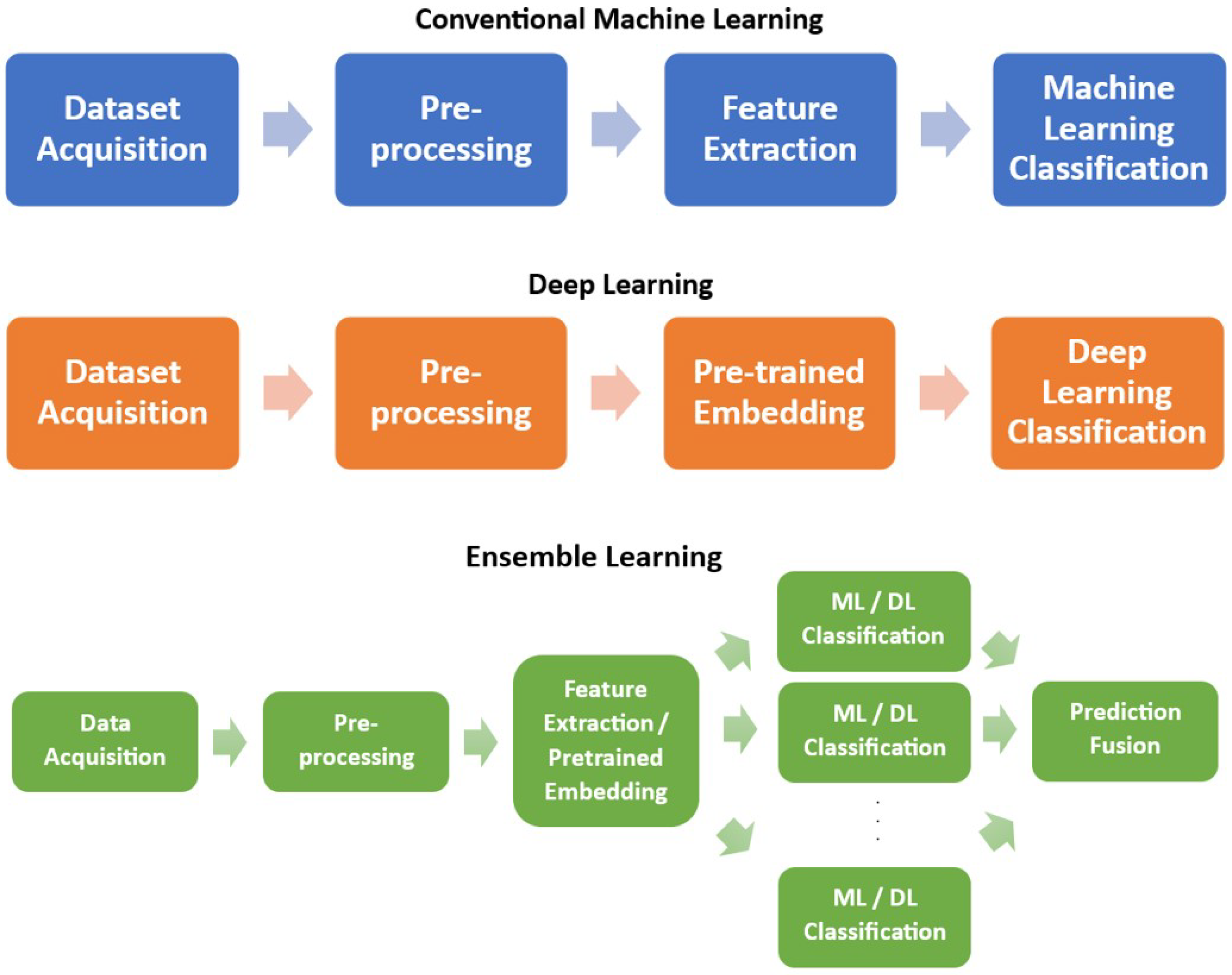
2.1. Machine Learning Approach
2.2. Deep Learning Approach
3. Ensemble Learning Approach
4. Sentiment Analysis Datasets
4.1. Internet Movie Database (IMDb)
4.2. Twitter US Airline Sentiment
4.3. Sentiment140
4.4. SemEval-2017 Task 4
5. Limitations and Future Research Prospects
- Poorly Structured and Sarcastic Texts: Many sentiment analysis methods rely on structured and grammatically correct text, which can lead to inaccuracies in analyzing informal and poorly structured texts, such as social media posts, slang, and sarcastic comments. This is because the sentiments expressed in these types of texts can be subtle and require contextual understanding beyond surface-level analysis.
- Coarse-Grained Sentiment Analysis: Although positive, negative, and neutral classes are commonly used in sentiment analysis, they may not capture the full range of emotions and intensities that a person can express. Fine-grained sentiment analysis, which categorizes emotions into more specific categories such as happy, sad, angry, or surprised, can provide more nuanced insights into the sentiment expressed in a text.
- Lack of Cultural Awareness: Sentiment analysis models trained on data from a specific language or culture may not accurately capture the sentiments expressed in texts from other languages or cultures. This is because the use of language, idioms, and expressions can vary widely across cultures, and a sentiment analysis model trained on one culture may not be effective in analyzing sentiment in another culture.
- Dependence on Annotated Data: Sentiment analysis algorithms often rely on annotated data, where humans manually label the sentiment of a text. However, collecting and labeling a large dataset can be time-consuming and resource-intensive, which can limit the scope of analysis to a specific domain or language.
- Shortcomings of Word Embeddings: Word embeddings, which are a popular technique used in deep learning-based sentiment analysis, can be limited in capturing the complex relationships between words and their meanings in a text. This can result in a model that does not accurately represent the sentiment expressed in a text, leading to inaccuracies in analysis.
- Bias in Training Data: The training data used to train a sentiment analysis model can be biased, which can impact the model’s accuracy and generalization to new data. For example, a dataset that is predominantly composed of texts from one gender or race can lead to a model that is biased toward that group, resulting in inaccurate predictions for texts from other groups.
- Fine-Grained Sentiment Analysis: The current sentiment analysis models mainly classify the sentiment into three coarse classes: positive, negative, and neutral. However, there is a need to extend this to a fine-grained sentiment analysis, which consists of different emotional intensities, such as strongly positive, positive, neutral, negative, and strongly negative. Researchers can explore various deep learning architectures and techniques to perform fine-grained sentiment analysis. One such approach is to use hierarchical attention networks that can capture the sentiment expressed in different parts of a text at different levels of granularity.
- Sentiment Quantification: Sentiment quantification is an important application of sentiment analysis. It involves computing the polarity distributions based on the topics to aid in strategic decision making. Researchers can develop more advanced models that can accurately capture the sentiment distribution across different topics. One way to achieve this is to use topic modeling techniques to identify the underlying topics in a corpus of text and then use sentiment analysis to compute the sentiment distribution for each topic.
- Handling Ambiguous and Sarcastic Texts: Sentiment analysis models face challenges in accurately detecting sentiment in ambiguous and sarcastic texts. Researchers can explore the use of reinforcement learning techniques to train models that can handle ambiguous and sarcastic texts. This involves developing models that can learn from feedback and adapt their predictions accordingly.
- Cross-lingual Sentiment Analysis: Currently, sentiment analysis models are primarily trained on English text. However, there is a growing need for sentiment analysis models that can work across multiple languages. Cross-lingual sentiment analysis would help to better understand the sentiment expressed in different languages, making sentiment analysis accessible to a larger audience. Researchers can explore the use of transfer learning techniques to develop sentiment analysis models that can work across multiple languages. One approach is to pretrain models on large multilingual corpora and then fine-tune them for sentiment analysis tasks in specific languages.
- Sentiment Analysis in Social Media: Social media platforms generate huge amounts of data every day, making it difficult to manually process the data. Researchers can explore the use of domain-specific embeddings that are trained on social media text to improve the accuracy of sentiment analysis models. They can also develop models that can handle noisy or short social media text by incorporating contextual information and leveraging user interactions.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Systematic reviews in sentiment analysis: A tertiary study. Artif. Intell. Rev. 2021, 54, 4997–5053. [Google Scholar] [CrossRef]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment analysis based on deep learning: A comparative study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef] [Green Version]
- Chakriswaran, P.; Vincent, D.R.; Srinivasan, K.; Sharma, V.; Chang, C.Y.; Reina, D.G. Emotion AI-driven sentiment analysis: A survey, future research directions, and open issues. Appl. Sci. 2019, 9, 5462. [Google Scholar] [CrossRef] [Green Version]
- Jung, Y.G.; Kim, K.T.; Lee, B.; Youn, H.Y. Enhanced Naive Bayes classifier for real-time sentiment analysis with SparkR. In Proceedings of the 2016 IEEE International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2016; pp. 141–146. [Google Scholar]
- Athindran, N.S.; Manikandaraj, S.; Kamaleshwar, R. Comparative analysis of customer sentiments on competing brands using hybrid model approach. In Proceedings of the 2018 IEEE 3rd International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 15–16 November 2018; pp. 348–353. [Google Scholar]
- Vanaja, S.; Belwal, M. Aspect-level sentiment analysis on e-commerce data. In Proceedings of the 2018 IEEE International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 11–12 July 2018; pp. 1275–1279. [Google Scholar]
- Iqbal, N.; Chowdhury, A.M.; Ahsan, T. Enhancing the performance of sentiment analysis by using different feature combinations. In Proceedings of the 2018 IEEE International Conference on Computer, Communication, Chemical, Material and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 8–9 February 2018; pp. 1–4. [Google Scholar]
- Rathi, M.; Malik, A.; Varshney, D.; Sharma, R.; Mendiratta, S. Sentiment analysis of tweets using machine learning approach. In Proceedings of the 2018 IEEE Eleventh International Conference on Contemporary Computing (IC3), Noida, India, 2–4 August 2018; pp. 1–3. [Google Scholar]
- Tariyal, A.; Goyal, S.; Tantububay, N. Sentiment Analysis of Tweets Using Various Machine Learning Techniques. In Proceedings of the 2018 IEEE International Conference on Advanced Computation and Telecommunication (ICACAT), Bhopal, India, 28–29 December 2018; pp. 1–5. [Google Scholar]
- Hemakala, T.; Santhoshkumar, S. Advanced classification method of twitter data using sentiment analysis for airline service. Int. J. Comput. Sci. Eng. 2018, 6, 331–335. [Google Scholar] [CrossRef]
- Rahat, A.M.; Kahir, A.; Masum, A.K.M. Comparison of Naive Bayes and SVM Algorithm based on sentiment analysis using review dataset. In Proceedings of the 2019 IEEE 8th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 22–23 November 2019; pp. 266–270. [Google Scholar]
- Makhmudah, U.; Bukhori, S.; Putra, J.A.; Yudha, B.A.B. Sentiment Analysis of Indonesian Homosexual Tweets Using Support Vector Machine Method. In Proceedings of the 2019 IEEE International Conference on Computer Science, Information Technology, and Electrical Engineering (ICOMITEE), Jember, Indonesia, 16–17 October 2019; pp. 183–186. [Google Scholar]
- Wongkar, M.; Angdresey, A. Sentiment analysis using Naive Bayes Algorithm of the data crawler: Twitter. In Proceedings of the 2019 IEEE Fourth International Conference on Informatics and Computing (ICIC), Semarang, Indonesia, 16–17 October 2019; pp. 1–5. [Google Scholar]
- Madhuri, D.K. A machine learning based framework for sentiment classification: Indian railways case study. Int. J. Innov. Technol. Explor. Eng. (IJITEE) 2019, 8, 441–445. [Google Scholar]
- Gupta, A.; Singh, A.; Pandita, I.; Parashar, H. Sentiment analysis of Twitter posts using machine learning algorithms. In Proceedings of the 2019 IEEE 6th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 13–15 March 2019; pp. 980–983. [Google Scholar]
- Prabhakar, E.; Santhosh, M.; Krishnan, A.H.; Kumar, T.; Sudhakar, R. Sentiment analysis of US Airline Twitter data using new AdaBoost approach. Int. J. Eng. Res. Technol. (IJERT) 2019, 7, 1–6. [Google Scholar]
- Hourrane, O.; Idrissi, N. Sentiment Classification on Movie Reviews and Twitter: An Experimental Study of Supervised Learning Models. In Proceedings of the 2019 IEEE 1st International Conference on Smart Systems and Data Science (ICSSD), Rabat, Morocco, 3–4 October 2019; pp. 1–6. [Google Scholar]
- AlSalman, H. An improved approach for sentiment analysis of arabic tweets in twitter social media. In Proceedings of the 2020 IEEE 3rd International Conference on Computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–4. [Google Scholar]
- Saad, A.I. Opinion Mining on US Airline Twitter Data Using Machine Learning Techniques. In Proceedings of the 2020 IEEE 16th International Computer Engineering Conference (ICENCO), Cairo, Egypt, 29–30 December 2020; pp. 59–63. [Google Scholar]
- Alzyout, M.; Bashabsheh, E.A.; Najadat, H.; Alaiad, A. Sentiment Analysis of Arabic Tweets about Violence Against Women using Machine Learning. In Proceedings of the 2021 IEEE 12th International Conference on Information and Communication Systems (ICICS), Valencia, Spain, 24–26 May 2021; pp. 171–176. [Google Scholar]
- Jemai, F.; Hayouni, M.; Baccar, S. Sentiment Analysis Using Machine Learning Algorithms. In Proceedings of the 2021 IEEE International Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 775–779. [Google Scholar]
- Ramadhani, A.M.; Goo, H.S. Twitter sentiment analysis using deep learning methods. In Proceedings of the 2017 IEEE 7th International Annual Engineering Seminar (InAES), Yogyakarta, Indonesia, 1–2 August 2017; pp. 1–4. [Google Scholar]
- Demirci, G.M.; Keskin, Ş.R.; Doğan, G. Sentiment analysis in Turkish with deep learning. In Proceedings of the 2019 IEEE International Conference on Big Data, Honolulu, HI, USA, 29–31 May 2019; pp. 2215–2221. [Google Scholar]
- Raza, G.M.; Butt, Z.S.; Latif, S.; Wahid, A. Sentiment Analysis on COVID Tweets: An Experimental Analysis on the Impact of Count Vectorizer and TF-IDF on Sentiment Predictions using Deep Learning Models. In Proceedings of the 2021 IEEE International Conference on Digital Futures and Transformative Technologies (ICoDT2), Islamabad, Pakistan, 20–21 May 2021; pp. 1–6. [Google Scholar]
- Dholpuria, T.; Rana, Y.; Agrawal, C. A sentiment analysis approach through deep learning for a movie review. In Proceedings of the 2018 IEEE 8th International Conference on Communication Systems and Network Technologies (CSNT), Bhopal, India, 24–26 November 2018; pp. 173–181. [Google Scholar]
- Harjule, P.; Gurjar, A.; Seth, H.; Thakur, P. Text classification on Twitter data. In Proceedings of the 2020 IEEE 3rd International Conference on Emerging Technologies in Computer Engineering: Machine Learning and Internet of Things (ICETCE), Jaipur, India, 7–8 February 2020; pp. 160–164. [Google Scholar]
- Uddin, A.H.; Bapery, D.; Arif, A.S.M. Depression Analysis from Social Media Data in Bangla Language using Long Short Term Memory (LSTM) Recurrent Neural Network Technique. In Proceedings of the 2019 IEEE International Conference on Computer, Communication, Chemical, Materials and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 11–12 July 2019; pp. 1–4. [Google Scholar]
- Alahmary, R.M.; Al-Dossari, H.Z.; Emam, A.Z. Sentiment analysis of Saudi dialect using deep learning techniques. In Proceedings of the 2019 IEEE International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019; pp. 1–6. [Google Scholar]
- Yang, Y. Convolutional neural networks with recurrent neural filters. arXiv 2018, arXiv:1808.09315. [Google Scholar]
- Goularas, D.; Kamis, S. Evaluation of deep learning techniques in sentiment analysis from Twitter data. In Proceedings of the 2019 IEEE International Conference on Deep Learning and Machine Learning in Emerging Applications (Deep-ML), Istanbul, Turkey, 26–28 August 2019; pp. 12–17. [Google Scholar]
- Hossain, N.; Bhuiyan, M.R.; Tumpa, Z.N.; Hossain, S.A. Sentiment analysis of restaurant reviews using combined CNN-LSTM. In Proceedings of the 2020 IEEE 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–5. [Google Scholar]
- Tyagi, V.; Kumar, A.; Das, S. Sentiment Analysis on Twitter Data Using Deep Learning approach. In Proceedings of the 2020 IEEE 2nd International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 18–19 December 2020; pp. 187–190. [Google Scholar]
- Rhanoui, M.; Mikram, M.; Yousfi, S.; Barzali, S. A CNN-BiLSTM model for document-level sentiment analysis. Mach. Learn. Knowl. Extr. 2019, 1, 832–847. [Google Scholar] [CrossRef] [Green Version]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.U.; Kim, J.W. Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Chundi, R.; Hulipalled, V.R.; Simha, J. SAEKCS: Sentiment analysis for English–Kannada code switchtext using deep learning techniques. In Proceedings of the 2020 IEEE International Conference on Smart Technologies in Computing, Electrical and Electronics (ICSTCEE), Bengaluru, India, 10–11 July 2020; pp. 327–331. [Google Scholar]
- Thinh, N.K.; Nga, C.H.; Lee, Y.S.; Wu, M.L.; Chang, P.C.; Wang, J.C. Sentiment Analysis Using Residual Learning with Simplified CNN Extractor. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019; pp. 335–3353. [Google Scholar]
- Janardhana, D.; Vijay, C.; Swamy, G.J.; Ganaraj, K. Feature Enhancement Based Text Sentiment Classification using Deep Learning Model. In Proceedings of the 2020 IEEE 5th International Conference on Computing, Communication and Security (ICCCS), Bihar, India, 14–16 October 2020; pp. 1–6. [Google Scholar]
- Chowdhury, S.; Rahman, M.L.; Ali, S.N.; Alam, M.J. A RNN Based Parallel Deep Learning Framework for Detecting Sentiment Polarity from Twitter Derived Textual Data. In Proceedings of the 2020 IEEE 11th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 17–19 December 2020; pp. 9–12. [Google Scholar]
- Vimali, J.; Murugan, S. A Text Based Sentiment Analysis Model using Bi-directional LSTM Networks. In Proceedings of the 2021 IEEE 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 8–10 July 2021; pp. 1652–1658. [Google Scholar]
- Anbukkarasi, S.; Varadhaganapathy, S. Analyzing Sentiment in Tamil Tweets using Deep Neural Network. In Proceedings of the 2020 IEEE Fourth International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 11–13 March 2020; pp. 449–453. [Google Scholar]
- Kumar, D.A.; Chinnalagu, A. Sentiment and Emotion in Social Media COVID-19 Conversations: SAB-LSTM Approach. In Proceedings of the 2020 IEEE 9th International Conference System Modeling and Advancement in Research Trends (SMART), Moradabad, India, 4–5 December 2020; pp. 463–467. [Google Scholar]
- Hossen, M.S.; Jony, A.H.; Tabassum, T.; Islam, M.T.; Rahman, M.M.; Khatun, T. Hotel review analysis for the prediction of business using deep learning approach. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 1489–1494. [Google Scholar]
- Younas, A.; Nasim, R.; Ali, S.; Wang, G.; Qi, F. Sentiment Analysis of Code-Mixed Roman Urdu-English Social Media Text using Deep Learning Approaches. In Proceedings of the 2020 IEEE 23rd International Conference on Computational Science and Engineering (CSE), Dubai, United Arab Emirates, 12–13 December 2020; pp. 66–71. [Google Scholar]
- Dhola, K.; Saradva, M. A Comparative Evaluation of Traditional Machine Learning and Deep Learning Classification Techniques for Sentiment Analysis. In Proceedings of the 2021 IEEE 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Uttar Pradesh, India, 28–29 January 2021; pp. 932–936. [Google Scholar]
- Tan, K.L.; Lee, C.P.; Anbananthen, K.S.M.; Lim, K.M. RoBERTa-LSTM: A Hybrid Model for Sentiment Analysis with Transformer and Recurrent Neural Network. IEEE Access 2022, 10, 21517–21525. [Google Scholar] [CrossRef]
- Kokab, S.T.; Asghar, S.; Naz, S. Transformer-based deep learning models for the sentiment analysis of social media data. Array 2022, 14, 100157. [Google Scholar] [CrossRef]
- AlBadani, B.; Shi, R.; Dong, J.; Al-Sabri, R.; Moctard, O.B. Transformer-based graph convolutional network for sentiment analysis. Appl. Sci. 2022, 12, 1316. [Google Scholar] [CrossRef]
- Tiwari, D.; Nagpal, B. KEAHT: A knowledge-enriched attention-based hybrid transformer model for social sentiment analysis. New Gener. Comput. 2022, 40, 1165–1202. [Google Scholar] [CrossRef] [PubMed]
- Tesfagergish, S.G.; Kapočiūtė-Dzikienė, J.; Damaševičius, R. Zero-shot emotion detection for semi-supervised sentiment analysis using sentence transformers and ensemble learning. Appl. Sci. 2022, 12, 8662. [Google Scholar] [CrossRef]
- Maghsoudi, A.; Nowakowski, S.; Agrawal, R.; Sharafkhaneh, A.; Kunik, M.E.; Naik, A.D.; Xu, H.; Razjouyan, J. Sentiment Analysis of Insomnia-Related Tweets via a Combination of Transformers Using Dempster-Shafer Theory: Pre–and Peri–COVID-19 Pandemic Retrospective Study. J. Med Internet Res. 2022, 24, e41517. [Google Scholar] [CrossRef]
- Jing, H.; Yang, C. Chinese text sentiment analysis based on transformer model. In Proceedings of the 2022 IEEE 3rd International Conference on Electronic Communication and Artificial Intelligence (IWECAI), Sanya, China, 14–16 January 2022; pp. 185–189. [Google Scholar]
- Alrehili, A.; Albalawi, K. Sentiment analysis of customer reviews using ensemble method. In Proceedings of the 2019 IEEE International Conference on Computer and Information Sciences (ICCIS), Aljouf, Saudi Arabia, 3–4 April 2019; pp. 1–6. [Google Scholar]
- Bian, W.; Wang, C.; Ye, Z.; Yan, L. Emotional Text Analysis Based on Ensemble Learning of Three Different Classification Algorithms. In Proceedings of the 2019 IEEE 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Metz, France, 18–21 September 2019; Volume 2, pp. 938–941. [Google Scholar]
- Gifari, M.K.; Lhaksmana, K.M.; Dwifebri, P.M. Sentiment Analysis on Movie Review using Ensemble Stacking Model. In Proceedings of the 2021 IEEE International Conference Advancement in Data Science, E-learning and Information Systems (ICADEIS), Bali, Indonesia, 13–14 October 2021; pp. 1–5. [Google Scholar]
- Parveen, R.; Shrivastava, N.; Tripathi, P. Sentiment Classification of Movie Reviews by Supervised Machine Learning Approaches Using Ensemble Learning & Voted Algorithm. In Proceedings of the IEEE 2nd International Conference on Data, Engineering and Applications (IDEA), Bhopal, India, 28–29 February 2020; pp. 1–6. [Google Scholar]
- Aziz, R.H.H.; Dimililer, N. Twitter Sentiment Analysis using an Ensemble Weighted Majority Vote Classifier. In Proceedings of the 2020 IEEE International Conference on Advanced Science and Engineering (ICOASE), Duhok, Iraq, 23–24 December 2020; pp. 103–109. [Google Scholar]
- Varshney, C.J.; Sharma, A.; Yadav, D.P. Sentiment analysis using ensemble classification technique. In Proceedings of the 2020 IEEE Students Conference on Engineering & Systems (SCES), Prayagraj, India, 10–12 July 2020; pp. 1–6. [Google Scholar]
- Athar, A.; Ali, S.; Sheeraz, M.M.; Bhattachariee, S.; Kim, H.C. Sentimental Analysis of Movie Reviews using Soft Voting Ensemble-based Machine Learning. In Proceedings of the 2021 IEEE Eighth International Conference on Social Network Analysis, Management and Security (SNAMS), Gandia, Spain, 6–9 December 2021; pp. 1–5. [Google Scholar]
- Nguyen, H.Q.; Nguyen, Q.U. An ensemble of shallow and deep learning algorithms for Vietnamese Sentiment Analysis. In Proceedings of the 2018 IEEE 5th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 23–24 November 2018; pp. 165–170. [Google Scholar]
- Kamruzzaman, M.; Hossain, M.; Imran, M.R.I.; Bakchy, S.C. A Comparative Analysis of Sentiment Classification Based on Deep and Traditional Ensemble Machine Learning Models. In Proceedings of the 2021 IEEE International Conference on Science & Contemporary Technologies (ICSCT), Dhaka, Bangladesh, 5–7 August 2021; pp. 1–5. [Google Scholar]
- Al Wazrah, A.; Alhumoud, S. Sentiment Analysis Using Stacked Gated Recurrent Unit for Arabic Tweets. IEEE Access 2021, 9, 137176–137187. [Google Scholar] [CrossRef]
- Tan, K.L.; Lee, C.P.; Lim, K.M.; Anbananthen, K.S.M. Sentiment Analysis with Ensemble Hybrid Deep Learning Model. IEEE Access 2022, 10, 103694–103704. [Google Scholar] [CrossRef]
- Maas, A.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the IEEE 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter sentiment classification using distant supervision. CS224N Proj. Rep. Stanf. 2009, 1, 2009. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. SemEval-2017 task 4: Sentiment analysis in Twitter. arXiv 2019, arXiv:1912.00741. [Google Scholar]



{kind=link}
{kind=link}
| Literature | Features | Classifier | Dataset | Accuracy (%) |
|---|---|---|---|---|
| Jung et al. (2016) [4] | MNB | Sentiment140 | 85 | |
| Athindran et al. (2018) [5] | NB | Self-collected dataset (from Tweets) | 77 | |
| Vanaja et al. (2018) [6] | A priori algorithm | NB, SVM | Self-collected dataset (from Amazon) | 83.42 |
| Iqbal et al. (2018) [7] | Unigram, Bigram | NB, SVM, ME | IMDb | 88 |
| Sentiment140 | 90 | |||
| Rathi et al. (2018) [8] | TF-IDF | DT | Sentiment140, Polarity Dataset, and University of Michigan dataset | 84 |
| AdaBoost | 67 | |||
| SVM | 82 | |||
| Hemakala and Santhoshkumar (2018) [10] | AdaBoost | Indian Airlines | 84.5 | |
| Tariyal et al. (2018) [9] | Regression Tree | Own dataset | 88.99 | |
| Rahat et al. (2019) [11] | SVC | Airline review | 82.48 | |
| MNB | 76.56 | |||
| Makhmudah et al. (2019) [12] | TF-IDF | SVM | Tweets related to homosexuals | 99.5 |
| Wongkar and Angdresey (2019) [13] | NB | Twitter (2019 presidential candidates of the Republic of Indonesia) | 75.58 | |
| Madhuri (2019) [14] | SVM | Twitter (Indian Railways) | 91.5 | |
| Gupta et al. (2019) [15] | TF-IDF | Neural Network | Sentiment140 | 80 |
| Prabhakar et al. (2019) [16] | AdaBoost (Bagging and Boosting) | Skytrax and Twitter (Airlines) | 68 F-score | |
| Hourrane et al. (2019) [17] | TF-IDF | Ridge Classifier | IMDb | 90.54 |
| Sentiment 140 | 76.84 | |||
| Alsalman (2020) [18] | TF-IDF | MNB | Arabic Tweets | 87.5 |
| Saad et al. (2020) [19] | Bag of Words | SVM | Twitter US Airline Sentiment | 83.31 |
| Alzyout et al. (2021) [20] | TF-IDF | SVM | Self-collected dataset | 78.25 |
| Jemai et al. (2021) [21] | NB | NLTK corpus | 99.73 |
| Literature | Embedding | Classifier | Dataset | Accuracy (%) |
|---|---|---|---|---|
| Ramadhani et al. (2017) [22] | MLP | Korean and English Tweets | 75.03 | |
| Demirci et al. (2019) [23] | word2vec | MLP | Turkish Tweets | 81.86 |
| Raza et al. (2021) [24] | Count Vectorizer and TF-IDF Vectorizer | MLP | COVID-19 reviews | 93.73 |
| Dholpuria et al. (2018) [25] | CNN | IMDb (3000 reviews) | 99.33 | |
| Harjule et al. (2020) [26] | LSTM | Twitter US Airline Sentiment | 82 | |
| Sentiment140 | 66 | |||
| Uddin et al. (2019) [27] | LSTM | Bangla Tweets | 86.3 | |
| Alahmary and Al-Dossari (2018) [28] | word2vec | BiLSTM | Saudi dialect Tweets | 94 |
| Yang (2018) [29] | GloVe | Recurrent neural filter-based CNN and LSTM | Stanford Sentiment Treebank | 53.4 |
| Goularas and Kamis (2019) [30] | word2vec and GloVe | CNN and LSTM | Tweets from semantic evaluation | 59 |
| Hossain and Bhuiyan (2019) [31] | word2vec | CNN and LSTM | Foodpanda and Shohoz Food | 75.01 |
| Tyagi et al. (2020) [32] | GloVe | CNN and BiLSTM | Sentiment140 | 81.20 |
| Rhanoui et al. (2019) [33] | doc2vec | CNN and BiLSTM | French articles and international news | 90.66 |
| Jang et al. (2020) [34] | word2vec | hybrid CNN and BiLSTM | IMDb | 90.26 |
| Chundi et al. (2020) [35] | Convolutional BiLSTM | English, Kannada, and a mixture of both languages | 77.6 | |
| Thinh et al. (2019) [36] | 1D-CNN with GRU | IMDb | 90.02 | |
| Janardhana et al. (2020) [37] | GloVe | Convolutional RNN | Movie reviews | 84 |
| Chowdhury et al. (2020) [38] | word2vec, GloVe, and sentiment-specific word embedding | BiLSTM | Twitter US Airline Sentiment | 81.20 |
| Vimali and Murugan (2021) [39] | BiLSTM | Self-collected | 90.26 | |
| Anbukkarasi and Varadhaganapathy (2020) [40] | DBLSTM | Self-collected (Tamil Tweets) | 86.2 | |
| Kumar and Chinnalagu (2020) [41] | SAB-LSTM | Self-collected | 29 (POS) 50 (NEG) 21 (NEU) | |
| Hossen et al. (2021) [42] | LSTM | Self-collected | 86 | |
| GRU | 84 | |||
| Younas et al. (2020) [43] | mBERT | Pakistan elections in 2018 (Tweets) | 69 | |
| XLM-R | 71 | |||
| Dhola and Saradva (2021) [44] | BERT | Sentiment140 | 85.4 | |
| Tan et a. (2022) [45] | RoBERTa-LSTM | IMDb | 92.96 | |
| Twitter US Airline Sentiment | 91.37 | |||
| Sentiment140 | 89.70 | |||
| Kokab et al. (2022) [46] | BERT | CBRNN | US airline reviews | 97 |
| Self-driving car reviews | 90 | |||
| US presidential election reviews | 96 | |||
| IMDb | 93 | |||
| AlBadani et al. (2022) [47] | ST-GCN | ST-GCN | SST-B | 95.43 |
| IMDB | 94.94 | |||
| Yelp 2014 | 72.7 | |||
| Tiwari and Nagpal (2022) [48] | BERT | KEAHT | COVID-19 vaccine | 91 |
| Indian Farmer Protests | 81.49 | |||
| Tesfagergish et al. (2022) [49] | Zero-shot transformer | Ensemble learning | SemEval 2017 | 87.3 |
| Maghsoudi et al. (2022) [50] | Transformer | DST | Self-collected | 84 |
| Jing and Yang (2022) [51] | Light-Transformer | Light-Transformer | NLPCC2014 Task2 | 76.40 |
| Literature | Feature Extractor | Classifier | Dataset | Accuracy (%) |
|---|---|---|---|---|
| Alrehili et al. (2019) [52] | NB + SVM + RF + Bagging + Boosting | Self-collected | 89.4 | |
| Bian et al. (2019) [53] | TF-IDF | LR + SVM + KNN | COVID-19 reviews | 98.99 |
| Gifari and Lhaksmana (2021) [54] | TF-IDF | MNB + KNN + LR | IMDb | 89.40 |
| Parveen et al. (2020) [55] | MNB + BNB + LR + LSVM + NSVM | Movie reviews | 91 | |
| Aziz and Dimililer (2020) [56] | TF-IDF | NB + LR + SGD + RF + DT + SVM | SemEval-2017 4A | 72.95 |
| SemEval-2017 4B | 90.8 | |||
| SemEval-2017 4C | 68.89 | |||
| Varshney et al. (2020) [57] | TF-IDF | LR + NB + SGD | Sentiment140 | 80 |
| Athar et al. (2021) [58] | TF-IDF | LR + NB + XGBoost + RF + MLP | IMDb | 89.9 |
| Nguyen and Nguyen (2018) [59] | TF-IDF, word2vec | LR + SVM + CNN + LSTM (Mean) | Vietnamese Sentiment | 69.71 |
| LR + SVM + CNN + LSTM (Vote) | Vietnamese Sentiment Food Reviews | 89.19 | ||
| LR + SVM + CNN + LSTM (Vote) | Vietnamese Sentiment | 92.80 | ||
| Kamruzzaman et al.(2021) [60] | GloVe | 7-Layer CNN + GRU + GloVe | Grammar and Online Product Reviews | 94.19 |
| Attention embedding | 7-Layer CNN + LSTM + Attention Layer | Restaurant Reviews | 96.37 | |
| Al Wazrah and Alhumoud (2021) [61] | AraVec | SGRU + SBi-GRU + AraBERT | Arabic Sentiment Analysis | 90.21 |
| Tan et a. (2022) [62] | RoBERTa-LSTM + RoBERTa-BiLSTM + RoBERTa-GRU | IMDb | 94.9 | |
| Twitter US Airline Sentiment | 91.77 | |||
| Sentiment140 | 89.81 |
| Dataset | Classes | Strongly Positive | Positive | Neutral | Negative | Strongly Negative | Total |
|---|---|---|---|---|---|---|---|
| IMDb | 2 | - | 25,000 | - | 25,000 | - | 50,000 |
| Twitter US Airline Sentiment | 3 | - | 2363 | 3099 | 9178 | - | 14,160 |
| Sentiment140 | 2 | - | 800,000 | - | 800,000 | - | 1,600,000 |
| SemEval-2017 4A | 3 | - | 22,277 | 28,528 | 11,812 | - | 62,617 |
| SemEval-2017 4B | 2 | - | 17,414 | - | 7735 | - | 25,149 |
| SemEval-2017 4C | 5 | 1151 | 15,254 | 19,187 | 6943 | 476 | 43,011 |
| SemEval-2017 4D | 2 | - | 17,414 | - | 7735 | - | 25,149 |
| SemEval-2017 4E | 5 | 1151 | 15,254 | 19,187 | 6943 | 476 | 43,011 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, K.L.; Lee, C.P.; Lim, K.M. A Survey of Sentiment Analysis: Approaches, Datasets, and Future Research. Appl. Sci. 2023, 13, 4550. https://doi.org/10.3390/app13074550
Tan KL, Lee CP, Lim KM. A Survey of Sentiment Analysis: Approaches, Datasets, and Future Research. Applied Sciences. 2023; 13(7):4550. https://doi.org/10.3390/app13074550
Chicago/Turabian StyleTan, Kian Long, Chin Poo Lee, and Kian Ming Lim. 2023. "A Survey of Sentiment Analysis: Approaches, Datasets, and Future Research" Applied Sciences 13, no. 7: 4550. https://doi.org/10.3390/app13074550