

Explainable Machine-Learning Predictions for Peak Ground Acceleration
Abstract
:1. Introduction
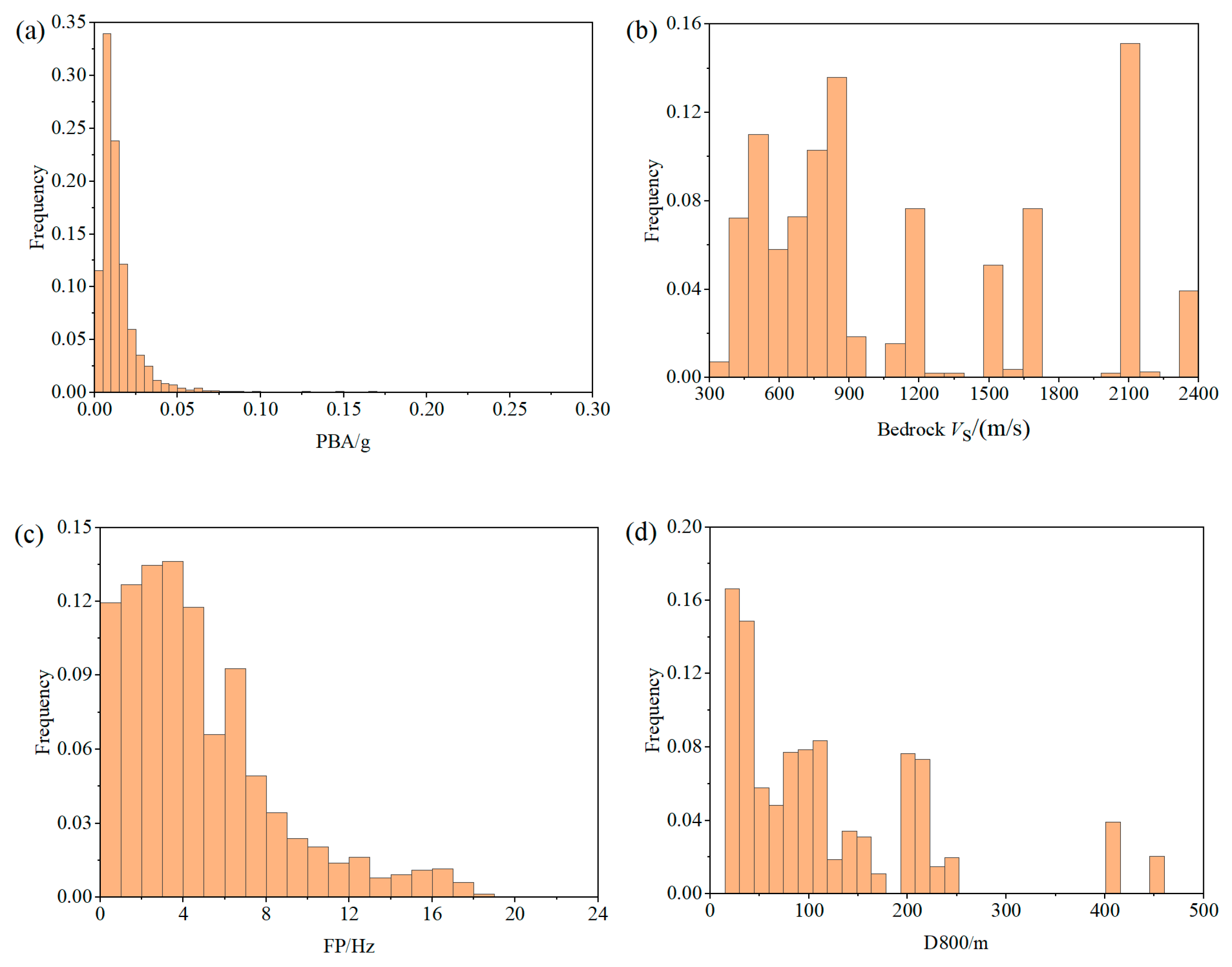
2. Establishment of the Dataset
3. Establishment of the Machine Learning Model
3.1. Algorithm Principle
3.1.1. Decision Tree Model
- (1)
- Enter the training dataset and stop calculation conditions;
- (2)
- Select the optimal segmentation dimension j and segmentation point s of the training dataset;
- (3)
- Use the optimal segmentation dimension j and segmentation point s to segment regions;
- (4)
- For the two divided sub-regions R1, R2, the above second and third steps are recursively called until the stopping condition is satisfied;
- (5)
- Finally, the input space is divided into M regions R1, R2, … Rm, and finally, the CART regression decision tree is generated.
- (1)
- The number of samples in the node is less than the predetermined value;
- (2)
- The Gini coefficient (classification)/square error (regression) of the sample dataset is less than the predetermined value;
- (3)
- No more features.
3.1.2. Random Forest Regression Model
3.1.3. XGBoost Regression Model
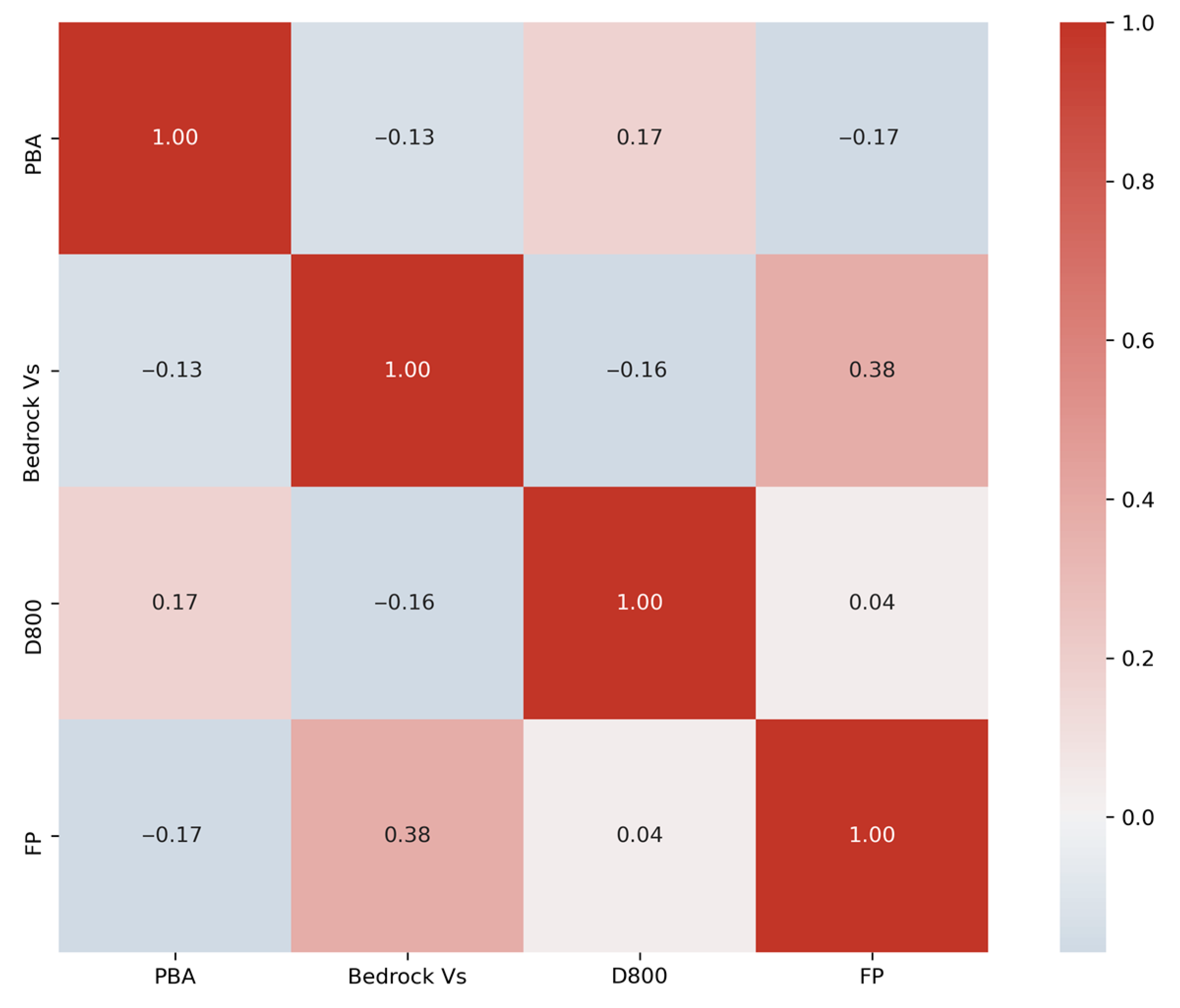
3.2. Feature Selection
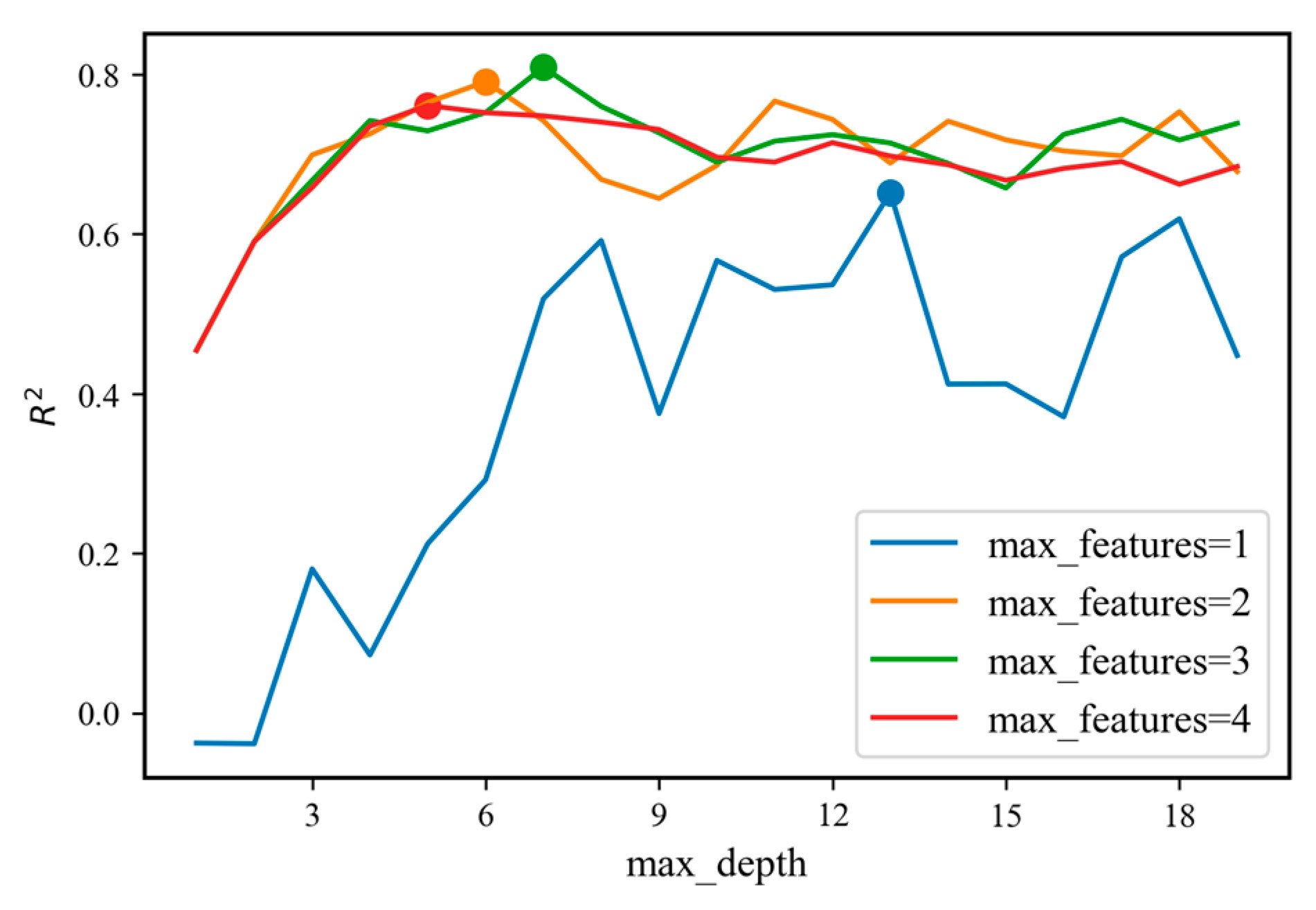
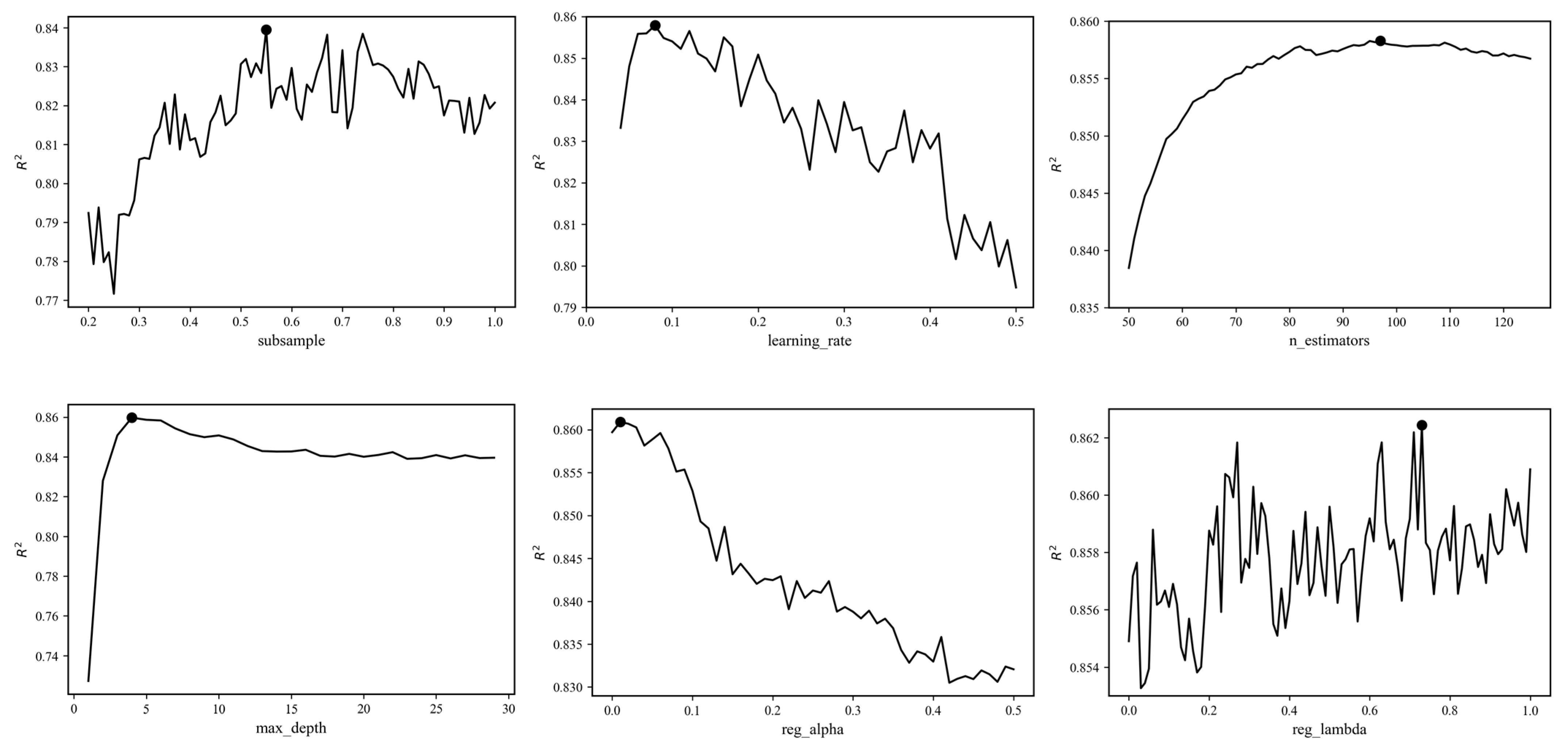
3.3. Model Training
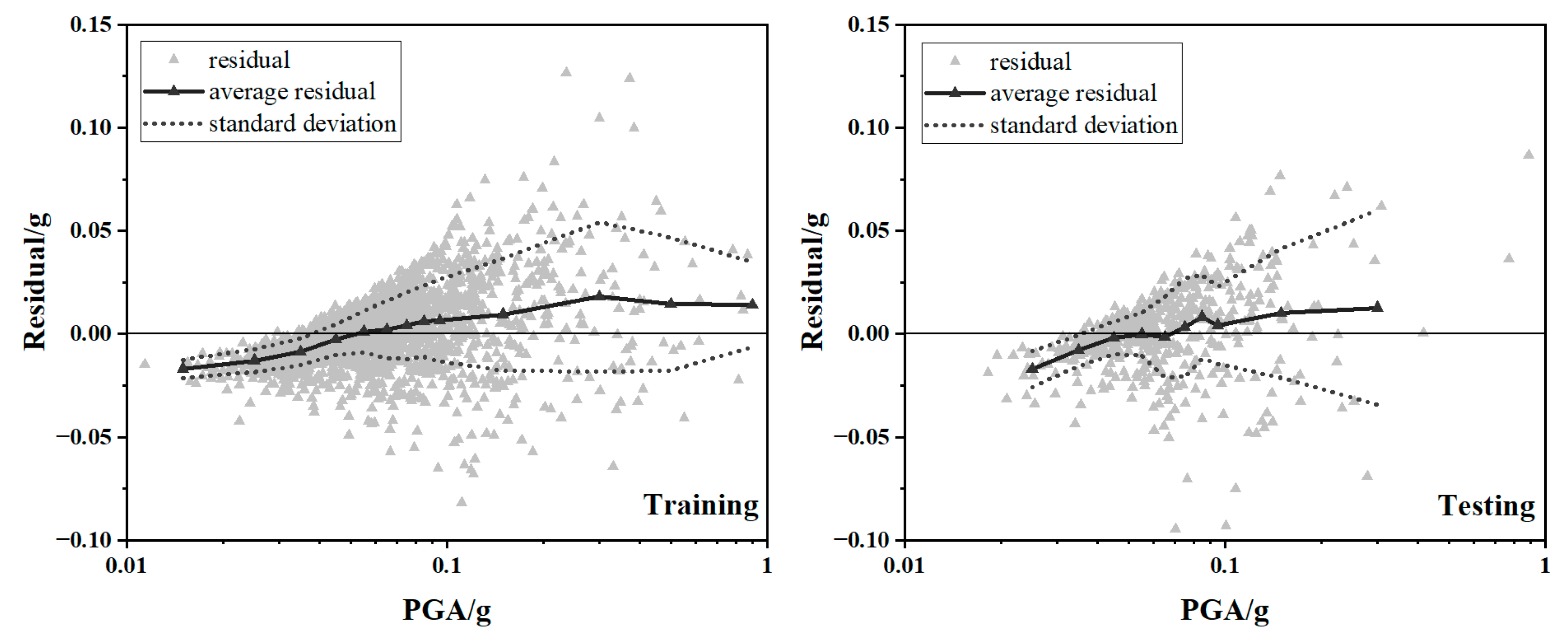
3.4. Analysis of XGBoost Model Results
4. Explanation of the Prediction Model Based on SHAP
4.1. Principle of the SHAP Method
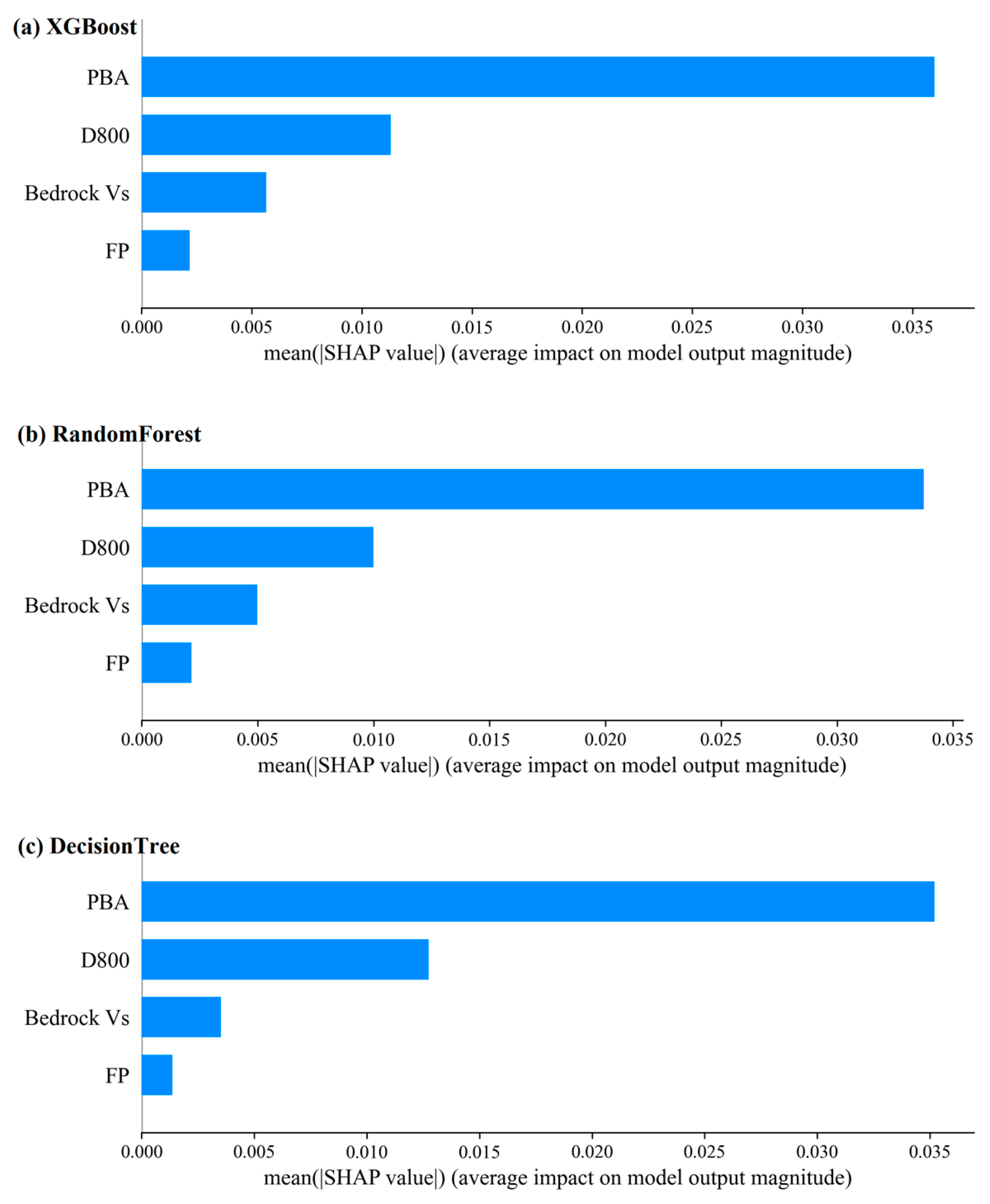
4.2. SHAP Global Analysis
4.3. Visualization and Analysis of SHAP Values of a Single Sample
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gutenberg, B.; Richter, C.F. Earthquake magnitude, intensity, energy, and acceleration (Second paper). Bull. Seismol. Soc. Am. 1942, 32, 105–145. [Google Scholar] [CrossRef]
- Hershberger, J. A comparison of earthquake accelerations with intensity ratings. Bull. Seismol. Soc. Am. 1956, 46, 317–320. [Google Scholar] [CrossRef]
- Bose, M.; Heaton, T.; Hauksson, E. Rapid Estimation of Earthquake Source and Ground-Motion Parameters for Earthquake Early Warning Using Data from a Single Three-Component Broadband or Strong-Motion Sensor. Bull. Seismol. Soc. Am. 2012, 102, 738–750. [Google Scholar] [CrossRef] [Green Version]
- Cremen, G.; Galasso, C. Earthquake early warning: Recent advances and perspectives. Earth-Sci. Rev. 2020, 205, 103184. [Google Scholar] [CrossRef]
- Güllü, H. Prediction of peak ground acceleration by genetic expression programming and regression: A comparison using likelihood-based measure. Eng. Geol. 2012, 141–142, 92–113. [Google Scholar] [CrossRef]
- Falcone, G.; Vacca, V.; Mori, F.; Naso, G.; Spina, D. Evaluation of building seismic retrofitting costs foundedon experimental data. The case study of “San Benedetto” School (Norcia, Italy). Ital. J. Geosci. 2021, 140, 365–381. [Google Scholar] [CrossRef]
- Vacca, V.; Occhipinti, G.; Mori, F.; Spina, D. The Use of SMAV Model for Computing Fragility Curves. Buildings 2022, 12, 1213. [Google Scholar] [CrossRef]
- Fayjaloun, R.; Negulescu, C.; Roullé, A.; Auclair, S.; Gehl, P.; Faravelli, M. Sensitivity of Earthquake Damage Estimation to the Input Data (Soil Characterization Maps and Building Exposure): Case Study in the Luchon Valley, France. Geosciences 2021, 11, 249. [Google Scholar] [CrossRef]
- Riga, E.; Apostolaki, S.; Karatzetzou, A.; Danciu, L.; Pitilakis, K. The role of modelling of site conditions and amplification in seismic hazard and risk assessment at urban scale. The case of Thessaloniki, Greece. Ital. J. Geosci. 2022, 141, 198–215. [Google Scholar] [CrossRef]
- Sabetta, F.; Fiorentino, G.; Bocchi, F.; Sinibaldi, M.; Falcone, G.; Mendicelli, A. Influence of local site effects on seismic risk maps and ranking of Italian municipalities. Bull. Earthq. Eng. 2023, 21, 2441–2468. [Google Scholar] [CrossRef]
- Du, K.; Ding, B.; Bai, W.; Sun, J.; Bai, J. Quantifying Uncertainties in Ground Motion-Macroseismic Intensity Conversion Equations. A Probabilistic Relationship for Western China. J. Earthq. Eng. 2022, 26, 1976–2000. [Google Scholar] [CrossRef]
- Dhanya, J.; Raghukanth, S.T.G. Ground Motion Prediction Model Using Artificial Neural Network. Pure Appl. Geophys. 2018, 175, 1035–1064. [Google Scholar] [CrossRef]
- Boore, D.M.; Atkinson, G.M. Ground-Motion Prediction Equations for the Average Horizontal Component of PGA, PGV, and 5%-Damped PSA at Spectral Periods between 0.01 s and 10.0 s. Earthq. Spectra 2008, 24, 99–138. [Google Scholar] [CrossRef] [Green Version]
- Du, K.; Ding, B.; Luo, H.; Sun, J. Relationship between Peak Ground Acceleration, Peak Ground Velocity, and Macroseismic Intensity in Western China. Bull. Seismol. Soc. Am. 2019, 109, 284–297. [Google Scholar] [CrossRef]
- Régnier, J.; Bonilla, L.F.; Bard, P.; Bertrand, E.; Hollender, F.; Kawase, H.; Sicilia, D.; Arduino, P.; Amorosi, A.; Asimaki, D.; et al. International Benchmark on Numerical Simulations for 1D, Nonlinear Site Response (PRENOLIN): Verification Phase Based on Canonical Cases. Bull. Seismol. Soc. Am. 2016, 106, 2112–2135. [Google Scholar] [CrossRef]
- Régnier, J.; Bonilla, L.; Bard, P.; Bertrand, E.; Hollender, F.; Kawase, H.; Sicilia, D.; Arduino, P.; Amorosi, A.; Asimaki, D.; et al. PRENOLIN: International Benchmark on 1D Nonlinear Site-Response Analysis—Validation Phase Exercise. Bull. Seismol. Soc. Am. 2018, 108, 876–900. [Google Scholar] [CrossRef] [Green Version]
- Moczo, P.; Kristek, J.; Bard, P.-Y.; Stripajová, S.; Hollender, F.; Chovanová, Z.; Kristeková, M.; Sicilia, D. Key structural parameters affecting earthquake ground motion in 2D and 3D sedimentary structures. Bull. Earthq. Eng. 2018, 16, 2421–2450. [Google Scholar] [CrossRef] [Green Version]
- Gatmiri, B.; Arson, C. Seismic site effects by an optimized 2D BE/FE method II. Quantification of site effects in two-dimensional sedimentary valleys. Soil Dyn. Earthq. Eng. 2008, 28, 646–661. [Google Scholar] [CrossRef]
- Maufroy, E.; Chaljub, E.; Hollender, F.; Kristek, J.; Moczo, P.; Klin, P.; Priolo, E.; Iwaki, A.; Iwata, T.; Etienne, V.; et al. Earthquake Ground Motion in the Mygdonian Basin, Greece: The E2VP Verification and Validation of 3D Numerical Simulation up to 4 Hz. Bull. Seismol. Soc. Am. 2015, 105, 1398–1418. [Google Scholar] [CrossRef] [Green Version]
- Schnabel, P.B.; Lysmer, J.; Seed, H.B. SHAKE: A Computer Program For Earthquake Response Analysis of Horizontally Layered Sites; Earthquake Engineering Research Center, Report No. UBC/EERC-72-12; University of California: Berkeley, CA, USA, 1972. [Google Scholar]
- Hashash, Y.M.; Park, D. Non-linear one-dimensional seismic ground motion propagation in the Mississippi embayment. Eng. Geol. 2001, 62, 185–206. [Google Scholar] [CrossRef]
- Kerh, T.; Ting, S.B. Neural network estimation of ground peak acceleration at stations along Taiwan high-speed rail system. Eng. Appl. Artif. Intell. 2005, 18, 857–866. [Google Scholar] [CrossRef]
- Arjun, C.R.; Kumar, A. Artificial Neural Network-Based Estimation of Peak Ground Acceleration. ISET J. Earthq. Technol. 2009, 501, 19–28. [Google Scholar]
- Günaydın, K.; Günaydın, A. Peak Ground Acceleration Prediction by Artificial Neural Networks for Northwestern Turkey. Math. Probl. Eng. 2008, 2008, 919420. [Google Scholar] [CrossRef] [Green Version]
- Derras, B.; Bard, P.-Y.; Cotton, F.; Bekkouche, A. Adapting the Neural Network Approach to PGA Prediction: An Example Based on the KiK-net Data. Bull. Seismol. Soc. Am. 2012, 102, 1446–1461. [Google Scholar] [CrossRef]
- Zhu, C.; Cotton, F.; Kawase, H.; Nakano, K. How well can we predict earthquake site response so far? Machine learning vs physics-based modeling. Earthq. Spectra 2022, 39, 478–504. [Google Scholar] [CrossRef]
- Mori, F.; Mendicelli, A.; Falcone, G.; Acunzo, G.; Spacagna, R.L.; Naso, G.; Moscatelli, M. Ground motion prediction maps using seismic-microzonation data and machine learning. Nat. Hazards Earth Syst. Sci. Discuss. 2021, 22, 947–966. [Google Scholar] [CrossRef]
- Ribeiro, M.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, San Diego, CA, USA, 12–17 June 2016; pp. 97–101. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4766–4775. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. Consistent feature attribution for tree ensembles. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Johnsen, P.V.; Riemer-Sørensen, S.; DeWan, A.T.; Cahill, M.E.; Langaas, M. A new method for exploring gene–gene and gene–environment interactions in GWAS with tree ensemble methods and SHAP values. BMC Bioinform. 2021, 22, 230. [Google Scholar] [CrossRef]
- Lauritsen, S.M.; Kristensen, M.; Olsen, M.V.; Larsen, M.S.; Lauritsen, K.M.; Jørgensen, M.J.; Lange, J.; Thiesson, B. Explainable artificial intelligence model to predict acute critical illness from electronic health records. Nat. Commun. 2020, 11, 3852. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.-W.; Newman, S.-F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef]
- Guo, Y.; Ma, W.; Li, J.; Liu, W.; Qi, P.; Ye, Y.; Guo, B.; Zhang, J.; Qu, C. Effects of microplastics on growth, phenanthrene stress, and lipid accumulation in a diatom, Phaeodactylum tricornutum. Environ. Pollut. 2020, 257, 113628. [Google Scholar] [CrossRef] [PubMed]
- Mangalathu, S.; Hwang, S.-H.; Jeon, J.-S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Yan, F.; Song, K.; Liu, Y.; Chen, S.; Chen, J. Predictions and mechanism analyses of the fatigue strength of steel based on machine learning. J. Mater. Sci. 2020, 55, 15334–15349. [Google Scholar] [CrossRef]
- Cakiroglu, C.; Bekdaş, G.; Kim, S.; Geem, Z.W. Explainable Ensemble Learning Models for the Rheological Properties of Self-Compacting Concrete. Sustainability 2022, 14, 14640. [Google Scholar] [CrossRef]
- Chen, M.; Wang, H. Explainable machine learning model for prediction of ground motion parameters with uncertainty quanti-fication. Chin. J. Geophys. 2022, 65, 3386–3404. (In Chinese) [Google Scholar] [CrossRef]
- Okada, Y.; Kasahara, K.; Hori, S.; Obara, K.; Sekiguchi, S.; Fujiwara, H.; Yamamoto, A. Recent progress of seismic observation networks in Japan—Hi-net, F-net, K-NET and KiK-net—. Earth Planets Space 2004, 56, 15–28. [Google Scholar] [CrossRef] [Green Version]
- GB50011-2010; Code for Seismic Design of Buildings. China Architecture & Building Press: Beijing, China, 2010. (In Chinese)
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the KDD ’16: 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Oweis, I.; Urzua, A.; Dobry, R. Simplified Procedures for Estimating the Fundamental Period of a Soil Profile. Bull. Seismol. Soc. Am. 1975, 66, 51–58. [Google Scholar]
- Boore, D.M.; Thompson, E.M.; Cadet, H. Regional Correlations of VS30 and Velocities Averaged Over Depths Less Than and Greater Than 30 Meters. Bull. Seismol. Soc. Am. 2011, 101, 3046–3059. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Qi, J.L. Soil Seismic Response Prediction Model Method Based on Machine Learning Algorithms. Master’s Thesis, Institute of Engineering Mechanics, China Earthquake Administration, Harbin, China, 2021. (In Chinese). [Google Scholar]
- Ma, L.; Zhou, C.; Lee, D.; Zhang, J. Prediction of axial compressive capacity of CFRP-confined concrete-filled steel tubular short columns based on XGBoost algorithm. Eng. Struct. 2022, 260, 114239. [Google Scholar] [CrossRef]
- Somala, S.N.; Chanda, S.; Karthikeyan, K.; Mangalathu, S. Explainable Machine learning on New Zealand strong motion for PGV and PGA. Structures 2021, 34, 4977–4985. [Google Scholar] [CrossRef]
- Mangalathu, S.; Shin, H.; Choi, E.; Jeon, J.-S. Explainable machine learning models for punching shear strength estimation of flat slabs without transverse reinforcement. J. Build. Eng. 2021, 39, 102300. [Google Scholar] [CrossRef]
- Sun, R.; Yuan, X. A holistic equivalent linear method for site response analysis. Soil Dyn. Earthq. Eng. 2021, 141, 106476. [Google Scholar] [CrossRef]
- Darendeli, M.B. Development of a New Family of Normalized Modulus Reduction and Material Damping Curves. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 2001. [Google Scholar]
- Shapley, L.S. A Value for N-Person Games. In Contributions to the Theory of Games; Princeton University Press: Princeton, NJ, USA, 1952. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shear Wave Velocity of Rock Vs or Equivalent Shear Wave Velocity of Soil Vse (m/s) | Site Class and Overburden Thickness | ||||
|---|---|---|---|---|---|
| I0 | I1 | II | III | IV | |
| Vs > 800 | 0 | ||||
| 800 ≥ Vs > 500 | 0 | ||||
| 500 ≥ Vse > 250 | <5 | ≥5 | |||
| 250 ≥ Vse > 150 | <3 | 3–50 | >50 | ||
| Vse ≤ 150 | <3 | 3–15 | 15–80 | >80 | |
| Site Class | Number of Stations | Number of Seismic Records |
|---|---|---|
| II | 6 | 1524 |
| III | 26 | 1296 |
| IV | 8 | 284 |
| Total | 40 | 3104 |
| Evaluation Indices | XGBoost | RF | DT | |||
|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | |
| R2 | 0.945 | 0.915 | 0.921 | 0.901 | 0.888 | 0.787 |
| MAE | 0.012 | 0.014 | 0.013 | 0.015 | 0.013 | 0.017 |
| RMSE | 0.017 | 0.022 | 0.020 | 0.024 | 0.024 | 0.034 |
| Bin Number | PGA(g) Range | Number of Motions | |
|---|---|---|---|
| Training Set | Testing Set | ||
| 1 | 0.00–0.01 | 0 | 0 |
| 2 | 0.01–0.02 | 18 | 2 |
| 3 | 0.02–0.03 | 155 | 18 |
| 4 | 0.03–0.04 | 449 | 70 |
| 5 | 0.04–0.05 | 542 | 122 |
| 6 | 0.05–0.06 | 370 | 102 |
| 7 | 0.06–0.07 | 245 | 69 |
| 8 | 0.07–0.08 | 164 | 46 |
| 9 | 0.08–0.09 | 129 | 29 |
| 10 | 0.09–0.10 | 76 | 25 |
| 11 | 0.10–0.20 | 283 | 77 |
| 12 | 0.20–0.40 | 78 | 10 |
| 13 | 0.40–0.60 | 13 | 1 |
| 14 | 0.60–1.00 | 7 | 2 |
| 15 | >1.00 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, R.; Qi, W.; Zheng, T.; Qi, J. Explainable Machine-Learning Predictions for Peak Ground Acceleration. Appl. Sci. 2023, 13, 4530. https://doi.org/10.3390/app13074530
Sun R, Qi W, Zheng T, Qi J. Explainable Machine-Learning Predictions for Peak Ground Acceleration. Applied Sciences. 2023; 13(7):4530. https://doi.org/10.3390/app13074530
Chicago/Turabian StyleSun, Rui, Wanwan Qi, Tong Zheng, and Jinlei Qi. 2023. "Explainable Machine-Learning Predictions for Peak Ground Acceleration" Applied Sciences 13, no. 7: 4530. https://doi.org/10.3390/app13074530