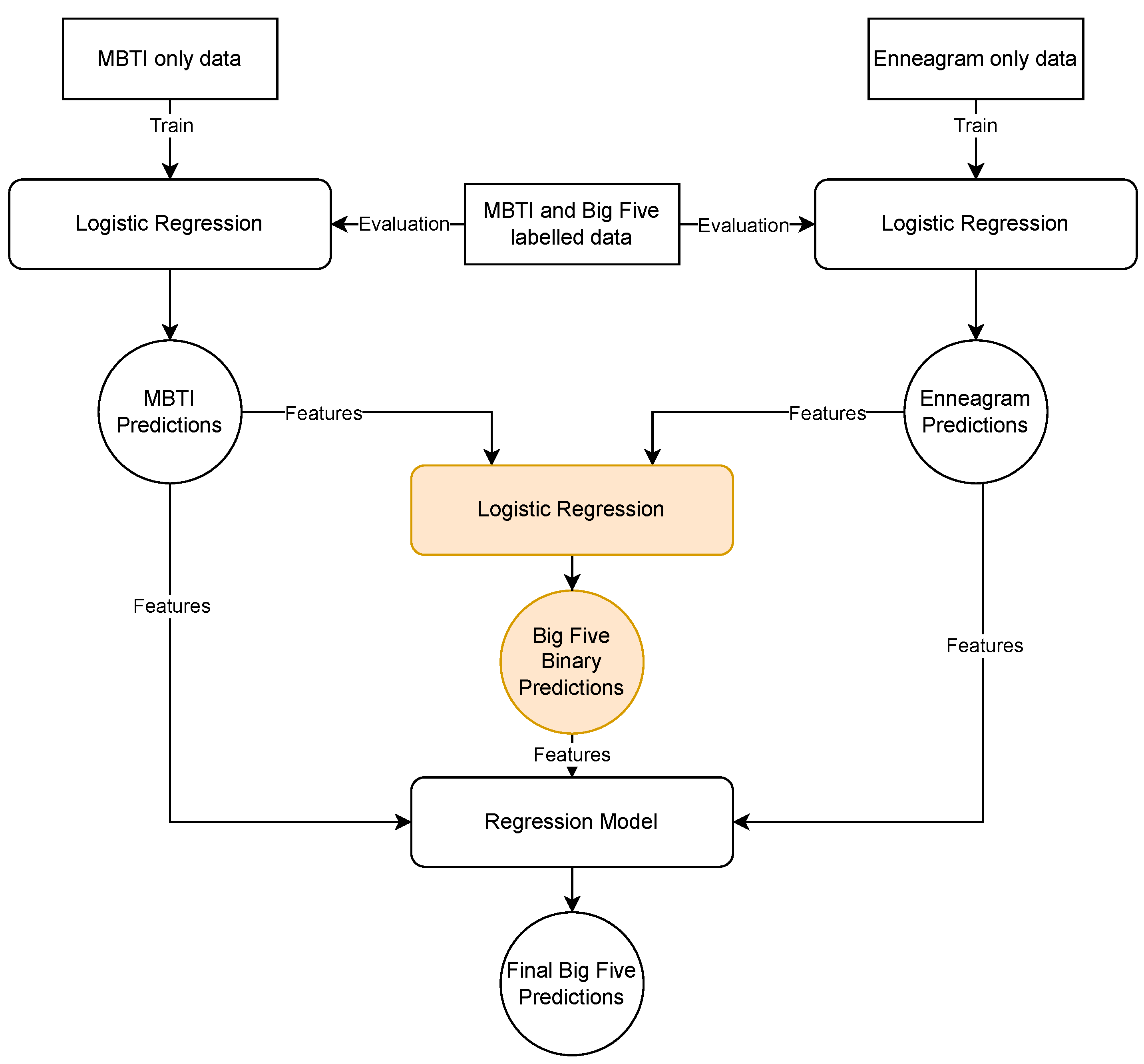
Before detailing the results of our experiments, we briefly go over the results of the baseline approach as well as the evaluation criteria. Gjurković et al. [
7] were the first to test the hypothesis of using MBTI and Enneagram predictions to successfully predict Big Five labels. In their experiments, they used several different feature sets, such as
n-grams and MBTI/Enneagram predictions that were the result of logistic regression models. These features were later combined with regression models to acquire the predicted Big Five labels. In
Table 4, we present the correlations between the predicted MBTI types and Big Five traits with the ground truth labels present in the PANDORA dataset as reported by Gjurković et al. [
7].
Their best performing model was a L2 regularized linear regression model that used a combination of
n-grams and predictions of the MBTI/Enneagram labels as features, yielding the best results for nearly all of the Big Five personality traits. The only exception was the
Openness trait, which demonstrated better performances when the same regression model was used, only without the MBTI/Enneagram predictions in the feature set. The metric used to evaluate the performance of these models is known as the Pearson correlation coefficient [
113]. The results of their experiments are reported in
Table 5 for the sake of providing a reference when comparing the results with those achieved through experiments.
While Gjurković et al. chose the Pearson correlation coefficient for their evaluation metric, it is essential to note that various metrics have been used in personality computing to evaluate the performances of different models [
6]. When focusing strictly on regression problems, the Pearson r correlation is not an uncommon metric; however, in the cases where the data do not follow a normal distribution, Spearman’s rank correlation coefficient might be a slightly better choice. Additionally, it was proposed by Fang et al. [
19] to use more than a single metric when evaluating personality-recognition approaches.
For example, using the mean squared error (MSE) in addition to correlation metric would reveal the absolute difference between predictions and how the model follows the trend. In our work, we chose to focus on exploring the effectiveness of different features and algorithms for personality prediction, and how they capture the relationship between multiple models. For the sake of allowing direct comparisons with previous work, we decided to use only a single metric that has been used, which is the Pearson r correlation coefficient.
For the sake of readability, when reporting correlation scores for the four MBTI dichotomies, we report a score for only a single value out of the two in a dichotomy. The reason behind this decision can be explained by the fact that a score for the other value would be equal to the same number being multiplied by , as each value represents an antipodal point of the other. For example, if the Introverted value of the E-I type shows correlation of , the correlation of the Extroverted value would be .
5.1. Feature Analysis
5.1.1. Big Five Classification Predictions—Median Split
When observing the results of the Big Five predictions achieved through the classification method, we notice that the overall correlation coefficients, in fact, decreased in comparison to the baseline approach (
Table 6). While the correlations between the predicted Big Five traits treated as classes and the actual Big Five labels seem to be comparable to the results previously reported in the work of Gjurković et al. [
7], the predictions of every single personality trait decreased, with the only exception being the
Openness trait.
The likely reason for this is due to the predicted values made by the classification model of the
Openness trait being more statistically independent from other personality traits, when compared to the statistical correlation exhibited by predictions made by the regression model (
Table 7).
5.1.2. Big Five Classification Predictions—Quartile Split
When treating the prediction of Big Five traits as a three-class classification problem rather than a two-class one, we note that the correlations between these features and actual Big Five labels were worse than when the median value was used as suggested by the results reported in
Table 8. While
Openness remains the only personality trait to see improvements over the baseline approach, this is only when MBTI/Enneagram predictions are included in the feature set (
Table 9).
5.1.3. Language-Based Features
When conducting analysis into psycholinguistic features, it should be noted that several researchers in the past have found correlations between the Big Five traits and different LIWC dimensions [
49,
59,
104]. However, as the exact list of LIWC dimensions that correlate with each Big Five trait tends to differ on a dataset basis, it is possible that contextual information, in addition to personality, can have a huge influence on language usage that is measured by LIWC.
While it is possible to perform detailed research into how the Big Five personality traits have influenced language usage on the social media platform Reddit, such a study and its results could potentially introduce information leak into the prediction model if used for the regression task. In addition to this, the usage of psycholinguistic information based on its relationship with the Big Five personality traits would possibly minimize the effectiveness of MBTI/Enneagram predictions present in the feature set.
Instead, we focused on a statistical analysis of the MBTI types and how they influence language use on Reddit, as suggested by data present in the PANDORA dataset. Through this approach, we not only open the possibility of this information being leveraged in our prediction model but also provide insight into the linguistic nature of MBTI types.
Table 10 and
Table 11 include information about all the correlations present between LIWC dimensions and MBTI types.
The results reported in
Table 10 and
Table 11 highlight that the two MBTI types that tend to correlate with most of the LIWC dimensions are
T-F with 69 and
J-P with 54 statistically significant correlations. To establish whether an entire set of correlating LIWC dimensions can contribute to better predicting Big Five traits, we tested all the correlating LIWC dimensions as features, sorting them into four different groups—one for each MBTI type—and a fifth group that includes all 78 LIWC dimensions that were found to correlate with at least one type. The results of combining these features with
n-grams, as well as MBTI/Enneagram predictions in the set of features, are reported in
Table 12.
5.1.4. Identifying Useful LIWC Dimensions
While the results of predictions that utilize correlating LIWC dimensions gave promising results for predicting certain traits, it was only when paired with the previously computed MBTI/Enneagram predictions in the feature set that the results improved over baseline. This signals that, despite the LIWC features being an efficient indicator of personality traits, it is only when the relationship between the multiple personality models is leveraged that they become the most effective.
This is especially apparent for the Conscientiousness trait, which had some of the worst results without the MBTI/Enneagram predictions in the feature set but ended up outperforming the baseline results when predictions of the type-based personality models were reintroduced into the feature set. It is worth noting, however, that, due to a large amount of LIWC dimensions correlating with several MBTI types, that the potential benefit of certain psycholinguistic features are reduced by the sudden increase in the number of features.
Since this overlap between the LIWC dimensions that correlate with two or more MBTI types ranges from % shared between the J-P and S-N types to % between the E-I and T-F types, we needed to analytically determine which LIWC dimensions best describe the relationship between MBTI types and the Big Five traits that correlate with them. However, we suggest that several factors can be considered in order to improve the results by helping to select the adequate LIWC dimensions for the feature set.
The first factor is too high of a correlation with the MBTI type. While most of the correlations reported in
Table 10 and
Table 11 tend to be marginally significant, those that have exceeded the absolute value of
indicate a stronger relationship with the MBTI type, and as such are not a good indicator of the relationship present between MBTI and Big Five models. The second factor is the degree of correlation between MBTI types themselves. If the LIWC category correlates with both of the MBTI types that tend to correlate with each other, that LIWC category should be disregarded from the feature set. Finally, the third factor is the relationship present between the LIWC dimensions themselves. If the LIWC dimensions correlate with one another, only a single one should be selected, as LIWC categories need to be statistically independent from one another.
Using these three factors as criteria, we were left with the following list of LIWC dimensions that correlate with each of the four MBTI types:
Extroverted/Introverted (E-I) type:
shehe—third person singular pronouns (she, her, him…)
incl—inclusive words (e.g., with, and…)
number—numbers (first, thousand…)
present—present tense verbs (is, does, do…)
posemo—words associated with positive emotions (love, happy, hope...)
pronoun—total pronouns (I, they, it…)
Sensing/Intuitive (S-N) type:
WPS—average words per sentence
past—past tense verbs (walked, were…)
social—social words (we, thank, care…)
ipron—impersonal pronouns (that, what, it…)
Colon—number of colons (:)
Thinking/Feeling (T-F) type:
you—second person singular pronouns (u, yourself, you…)
article—number of article (a, an, the…)
sad—words relating to sadness (:(, cry…)
Judging/Perceiving (J-P) type:
Exclam—number of exclamations (!)
i—first person singular pronouns (me, myself, I…)
hear—auditory words (hear, sound…)
tentat—tentative phrases (if, any, something…)
Combining these LIWC dimensions in combination with their respective MBTI types, we achieved results in predicting the Big Five traits, which are reported in
Table 13.
The results reported in
Table 13 indicate that choosing LIWC dimensions with the method we described can further increase the results when predicting Big Five traits, especially in cases when the MBTI type and the Big Five trait have been found to statistically correlate with one other. This is visible for all the MBTI types as the prediction results for
Openness increased when using LIWC dimensions that were selected for the
S-N type,
Agreeableness increased when using LIWC features for
T-F, and so on. However, it should be noted that, despite the prediction scores for the
Neuroticism trait increasing when using LIWC dimensions selected for the
E-I and
S-N types, we propose that this can be attributed either to a possible relationship between Enneagram and
Neuroticism or due to the nature of the data, as
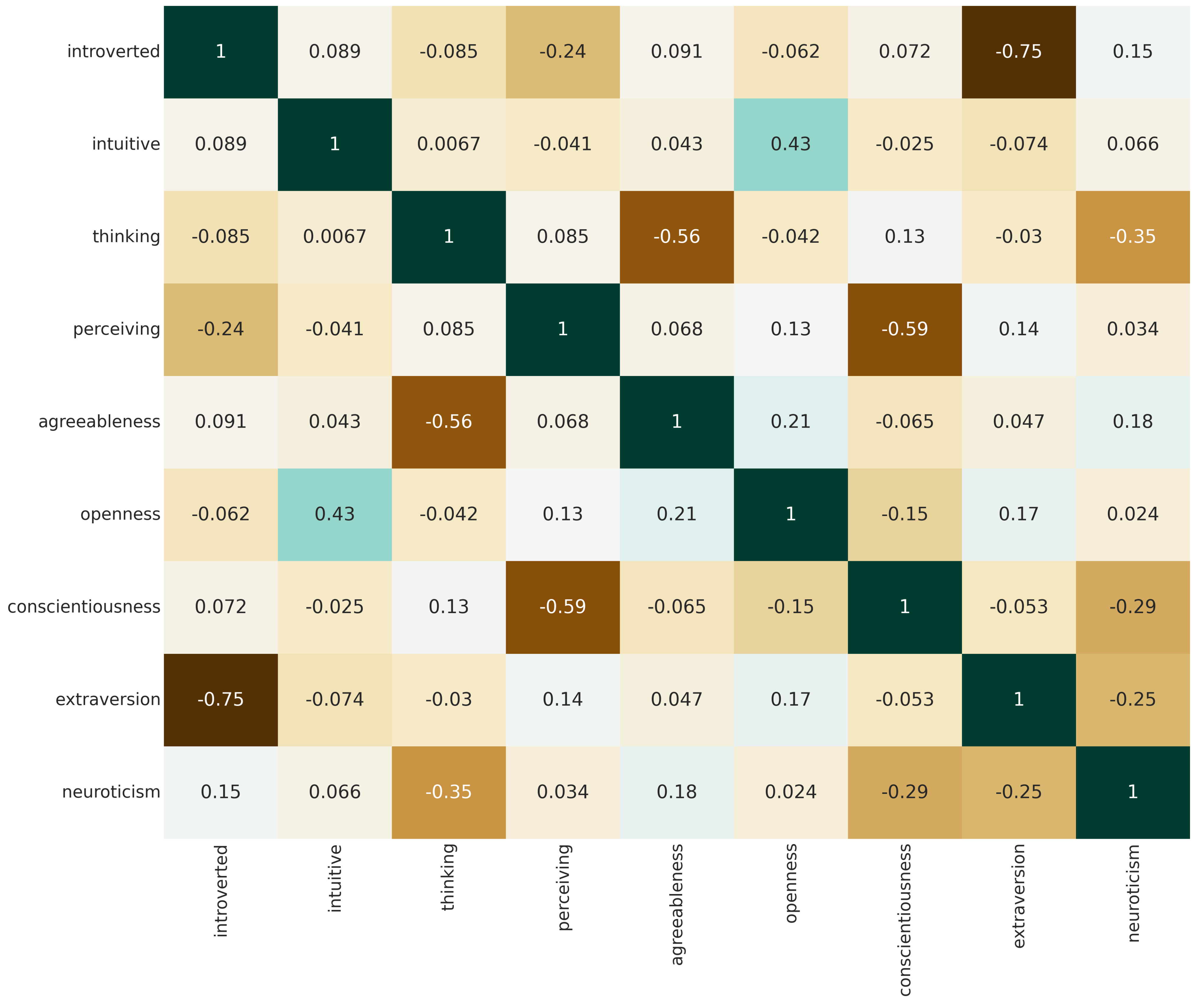
Neuroticism is the only trait to follow a bimodal distribution in this dataset (
Figure 6).
Unlike the MBTI types, Enneagram types have shown no presence of a statistically significant correlation with any of the LIWC dimensions.
5.1.5. Effect of Enneagram Predictions on the Big Five Predictions
While MBTI and Big Five personality models have been previously compared in the works of several authors [
13,
18,
66,
86], the relationship between the Enneagram and Big Five traits has not been thoroughly explored. This can be largely attributed to Enneagram often being underutilized in both academia and consulting—the two areas where the Big Five model and MBTI have enjoyed success, respectively. However, taking a closer look into the possible relationship between these models can help to better answer the question as to how Enneagram predictions can help the process of predicting Big Five personality traits.
The results reported in
Table 14 indicate that, for certain Big Five traits, the results change drastically when the Enneagram predictions are removed from the feature set. This is visible when comparing them to the results reported in
Table 13 as well as the results reported for the baseline approach. With this in mind, we make the following observations:
The model’s performance when predicting the Neuroticism trait without Enneagram predictions in the feature set decreases in comparison to all the feature sets that previously included Enneagram predictions.
The model’s performance when predicting both Conscientiousness and Agreeableness increases in almost every case when Enneagram predictions are removed from the feature set. The only exception to this is when the following LIWC dimensions appear in the feature set: shehe, incl, number, present, posemo and pronoun.
Predictions of the Openness trait either stay the same or only slightly fluctuate when Enneagram predictions are removed from the feature set, indicating that predicting this trait benefits only slightly from the Enneagram predictions.
The first of these three observations points towards the possible relationship existing between the Enneagram types and Big Five’s
Neuroticism trait. This can be confirmed when observing the correlations between the Enneagram types and the Big Five traits that Gjurković et al. [
7] reported in their work, which we list in
Table 15 for reference.
Despite these results, it is still difficult to conclude whether the relationship between Enneagram and Neuroticism is result of the data’s nature, or a case of language usage that is associated with Neuroticism being shared with many of the Enneagram types. This is largely due to a lack of literature comparing Enneagram types to Big Five traits, especially from the perspective of language usage. As the PANDORA dataset contains a rather small number of Enneagram labels, as well as Big Five ones, it would be difficult to conduct an in-depth analysis into the topic from this dataset alone. However, we hope that these findings can help to motivate future research into the relationship between Enneagram types, Big Five traits and language usage shared between them, as we propose that it would be greatly beneficial for personality computing tasks conducted in the future.
5.1.6. Subreddit Participation
Analysing data from the PushShift dataset, we found that, in the period between the chronologically first and last comments present in the PANDORA dataset there has been activity on 879,826 different subreddits. Out of all these subreddits, the 50 most popular ones have mostly been those with a more general topics, such as r/AskReddit and r/worldnews. However, it is worth noting that, in the set of most popular subreddits, several personality related ones were included, e.g., r/mbti and several subreddits dedicated to specific MBTI types, such as r/INTP and r/ENFP. On the other hand, the PANDORA dataset included information on some 46,214 different subreddits, a considerably smaller number.
After forming feature vectors based on either the number of unique users participating in subreddits within the time window matching that of the PANDORA dataset or on the number of total comments, we found that these two feature vectors are nearly identical. This is due to the fact that total number of comments and number of unique users participating in subbreddits showed a high Pearson correlation of
. Consequently, we decided to only focus on the feature vector that is formed by using the total number of comments as a measurement of subreddit popularity. The results of predictions when using these features in the feature set are shown in
Table 16.
While subreddit participation is visibly less effective when predicting Openness and Neuroticism, it caused a slight increase in the results when predicting Conscientiousness and Agreeableness with the success rates of predicting Extroversion remaining the same. We suggest that this is caused by the fact that vast numbers of subreddits present in the feature vector tend to be more general in nature, rather than topic-specific. This has contributed to them attracting different people that all, most likely, do not share much in the way of personality traits. However, as the relationship between interests and MBTI types has not been thoroughly studied in the existing literature, we decided not to further investigate the usefulness of this feature set, instead choosing to leave it for future works.
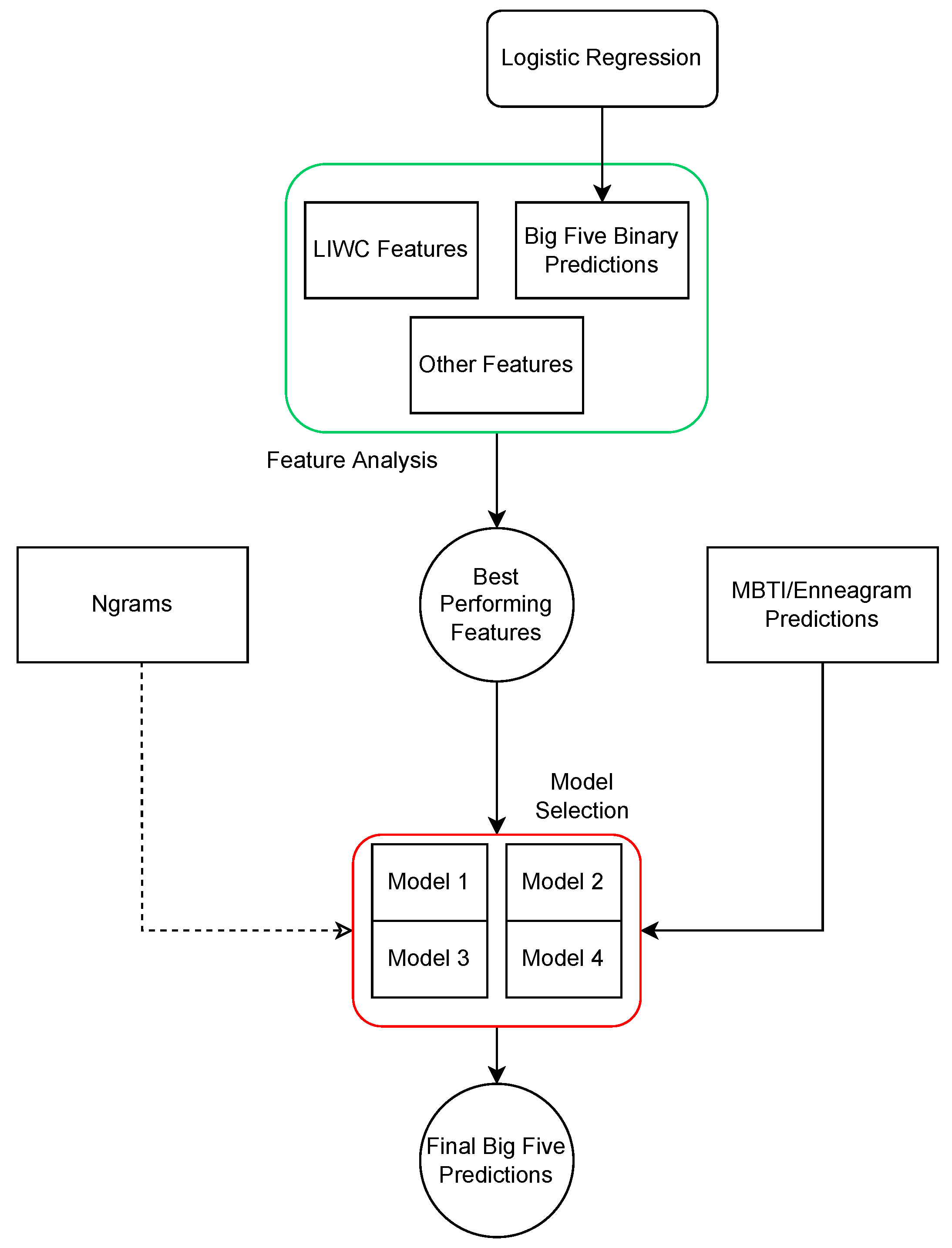
5.2. Model Selection
Features introduced in the previous subsection were all evaluated on the same L2 regularized regression model, which was also used as part of the method that achieved the baseline results. While some features led to improvements, they also, in turn, introduced additional complexity in the feature space. To additionally improve the results, we conducted experiments with several different regression models capable of weighing features in order to bring the most out of the them for the task of predicting Big Five traits.
For the sake of conciseness, as well as for easier comparison between the results, we chose to report the results for all the different models within a single table (
Table 17). For features used as input to these models, we decided to select the best performing set, which was a combination of
n-grams, MBTI/Enneagram predictions and certain LIWC features, which were selected in the way described in the subsection detailing the methods for selecting the best language based features (
Section 5.1.4).
The first section of results in
Table 17 outlines the results achieved by using the Ridge regression model, which are same as those previously reported in
Table 13. When comparing these results to other sections of the table, we note that certain models, such as SVR, Huber regressor and Elastic-Net, led to improvements in predicting most of the Big Five traits, while Lasso regression, KerasRegressor and XGBoost demonstrated poor performance on the task overall. Out of the better performing models, Elastic-Net stands out as it scored the best on three out of five Big Five traits, namely
Openness,
Conscientiousness and
Extroversion, while the Huber regressor and SVR proved to be better choices for predicting the remaining two Big Five traits.
Analysing the performance of the Lasso regression, which ended up being the worst performing model overall, we note that, despite the L1 regularization employed in an effort to remove noise from the feature set, it is possible that this actually led to a loss of several important features that were indicative of finer differences between personalities. As personality is a complex concept, it often tends to be both affected and manifested through the smallest differences present between individuals. As such, we speculate that L1 regularization caused the model to be less effective in efforts to capture these small differences, in turn, leading to poor performances on the task of Big Five personality trait prediction.
KerasRegressor resulted in predictions that correlate slightly worse than the baseline approach across all of the personality traits. While these results indicate worse performances than any of the other models included in
Table 13, it should be noted that this approach outperformed the BERT-based method that Gjurković et al. [
7] experimented on. While we tested different architectures of the KerasRegressor for this task, it is possible that a more complex deep-learning model would be capable of better capturing the relationship between the features used and personality traits.
Similarly to the KerasRegressor model, XGBoost also demonstrated less than satisfactory results. Despite improving on predictions of the Neuroticism trait over the baseline, the results for the other four personality traits saw a significant decrease in comparison to the baseline. We propose that, due to the small size, the data-boosting algorithm struggled to correctly predict the right value for each of the personality traits. Additionally, while the LIWC dimensions differed between feature sets, XGBoost showed almost identical results for each of the experiments. This leads us to believe that XGBoost is less capable of leveraging this language-related information and instead prioritizes features, such as n-grams and MBTI/Enneagram predictions from the feature set.
The best performing solution for the Agreeableness trait was when using the SVR model that included a subset of LIWC dimensions correlating with the T-F MBTI type (e.g., you, article and sad) in the feature set. While not the best performing model, SVR still managed to outperform the baseline approach using several different feature sets, especially when predicting the Agreeableness trait, for which it outperformed the baseline on every single experiment conducted.
We propose that these results are largely due to the SVR’s nature to work well with smaller sets of data, as well as the error function on which it relies. However, we must remark that SVR had worse results than the baseline on both the Openness and Extroversion traits—both of which have shown the overall highest correlations with n-gram features, indicating that SVR places less importance on this particular set of features when making predictions.
Another well-performing model is the Huber regressor, which demonstrated overall exemplary performances when predicting the Conscientiousness and Neuroticism personality traits, with the results for the other three traits also showing promise. When it comes to predictions for the Neuroticism trait, we suggest that good results are due to the Huber regressors capability of working well with outliers, possibly being more capable of working with the Neuroticism trait, which demonstrated the presence of bimodal distribution.
Out of all the models, the overall best performing one seems to be Elastic-Net, which performed best when predicting three of the five Big Five traits, namely Openness, Conscientiousness and Extroversion. The effectiveness of Elastic-Net can be attributed largely to the good balance of both the L1 and L2 regularization norms, which eliminated noisy features while simultaneously keeping those that influenced personality prediction, thus, utilizing them to capture subtle differences in personality.
We indicate that, despite the SVR and Huber regressor slightly outperforming Elastic-Net when predicting the Agreeableness and Neuroticism dimensions, the consistent improvements in scores for many different feature sets point towards Elastic-Net being the best overall choice for the task of predicting Big Five traits with the MBTI/Enneagram predictions present in the feature set.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








