
STJA-GCN: A Multi-Branch Spatial–Temporal Joint Attention Graph Convolutional Network for Abnormal Gait Recognition


Abstract
:1. Introduction
2. Materials and Methods
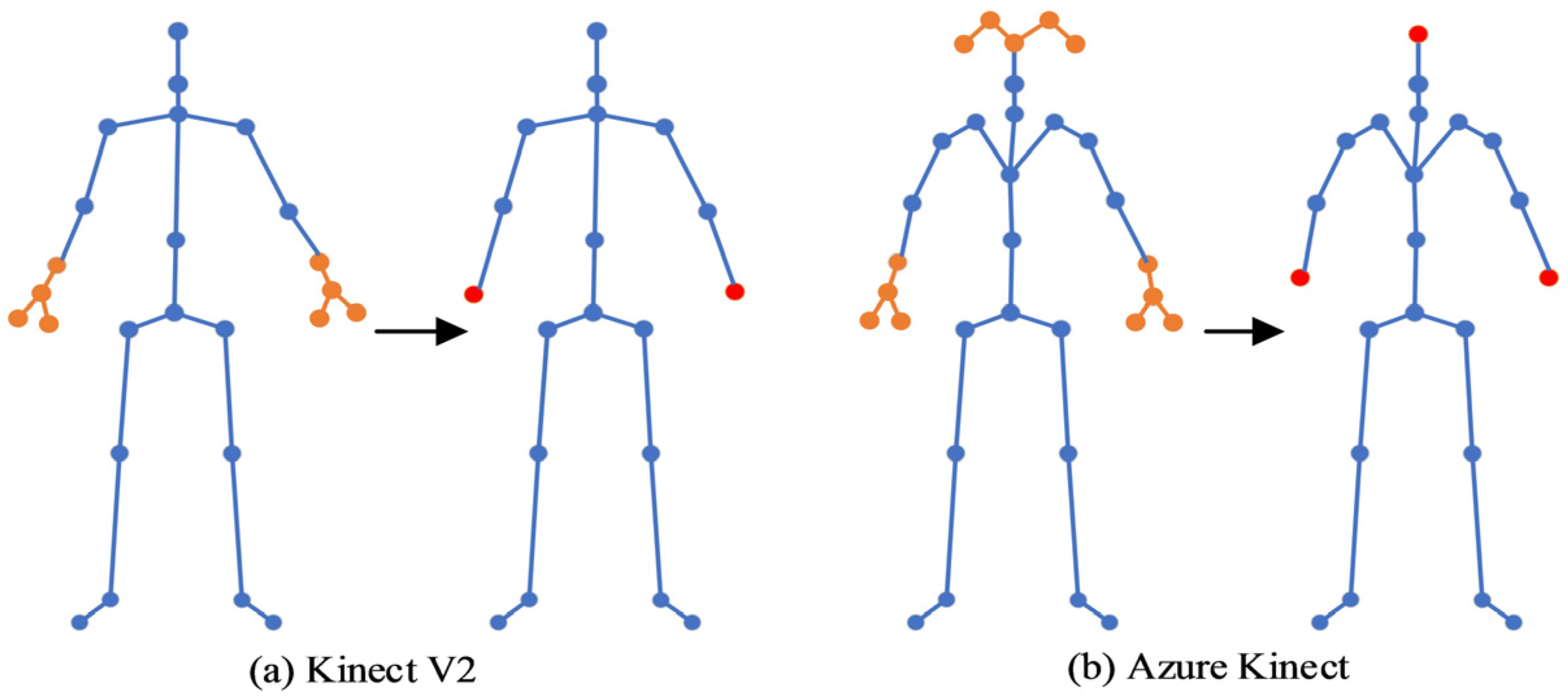
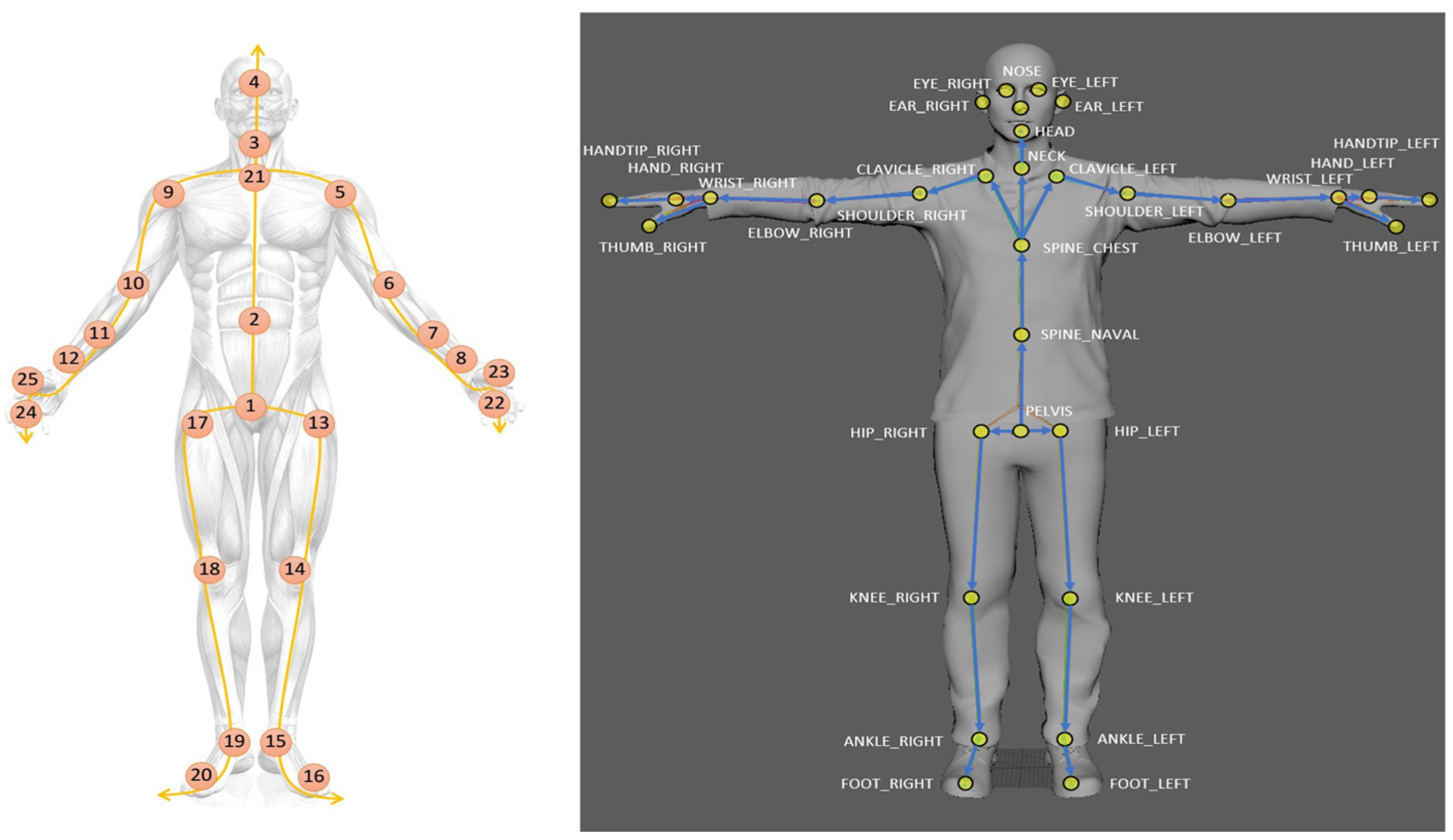
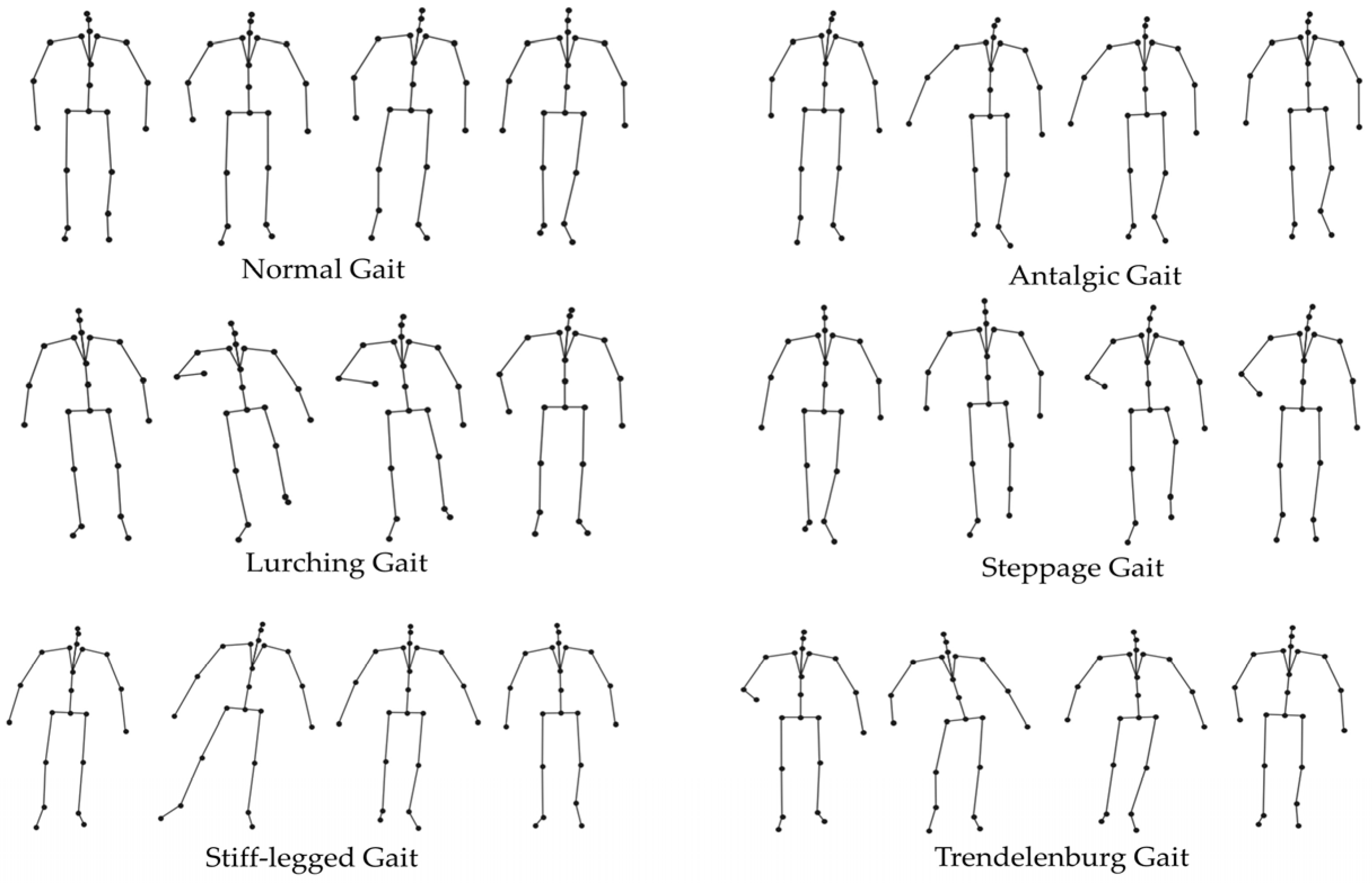
2.1. Human Skeleton Model for Abnormal Gait Recognition
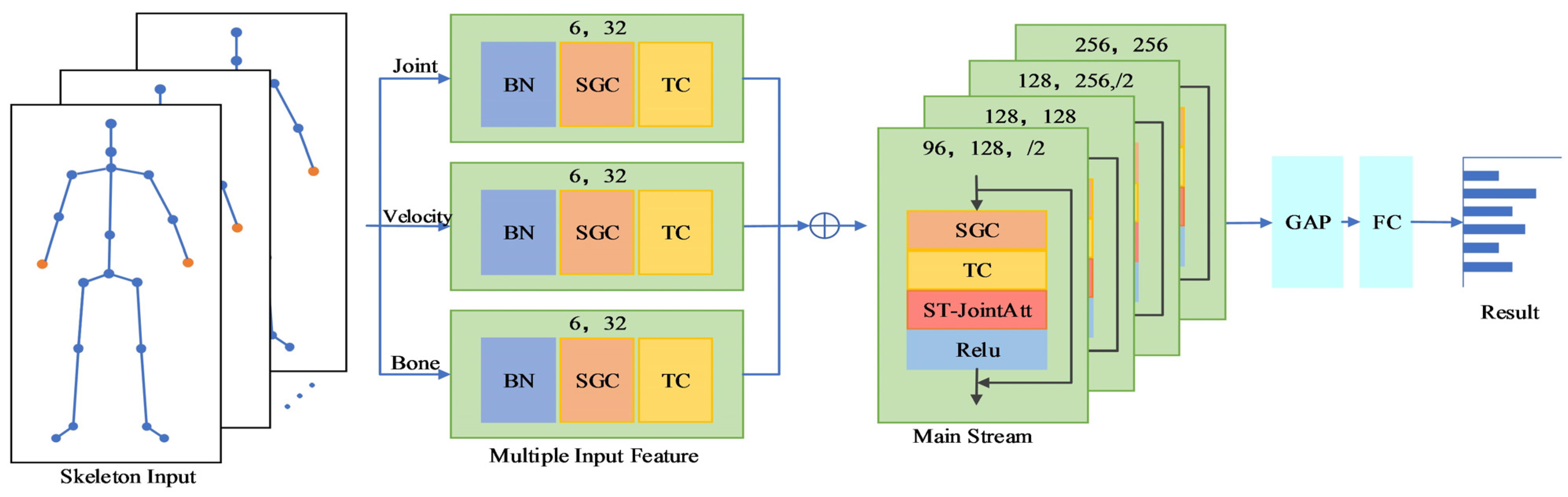
2.2. Early Multi-Branch Fusion of Spatial–Temporal Joint Attention GCN
2.2.1. Multi-Branch Input Features and Fusion
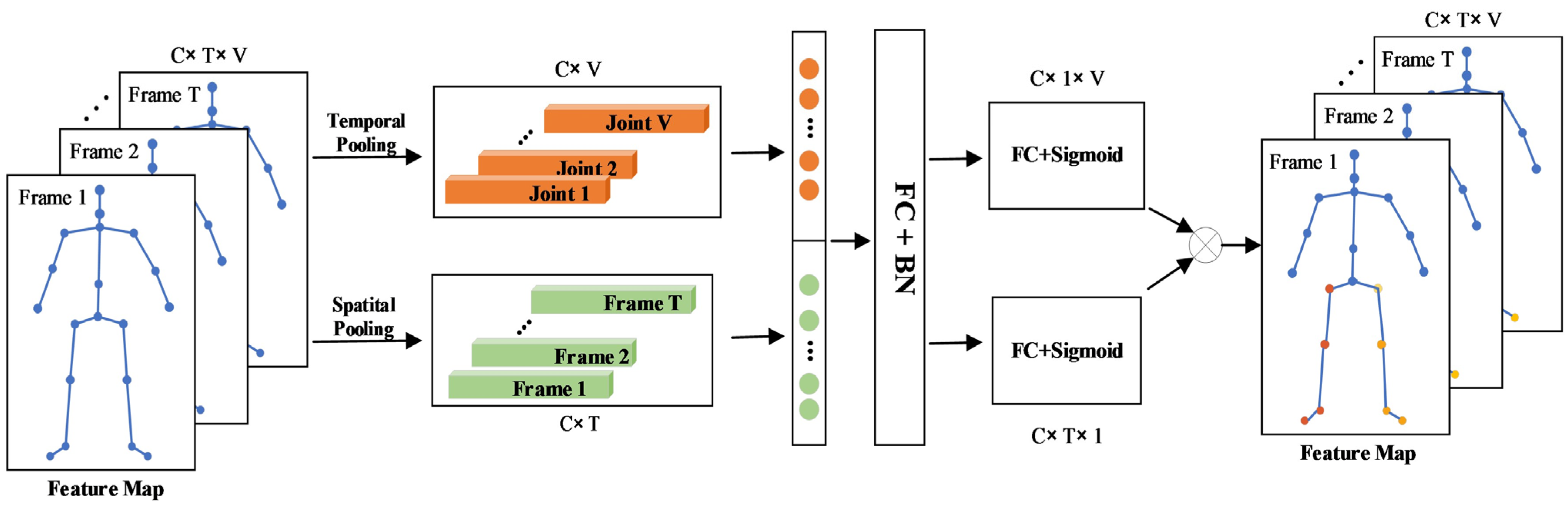
2.2.2. Spatial–Temporal Graph Convolutional Attention Module
3. Results
3.1. Datasets
- (1)
- Kinect25
- (2)
- Azure32
3.2. Experimental Setup
3.3. Ablation Experiments
3.3.1. Effectiveness of Joint Streamlining
3.3.2. Effectiveness of Attention Mechanisms
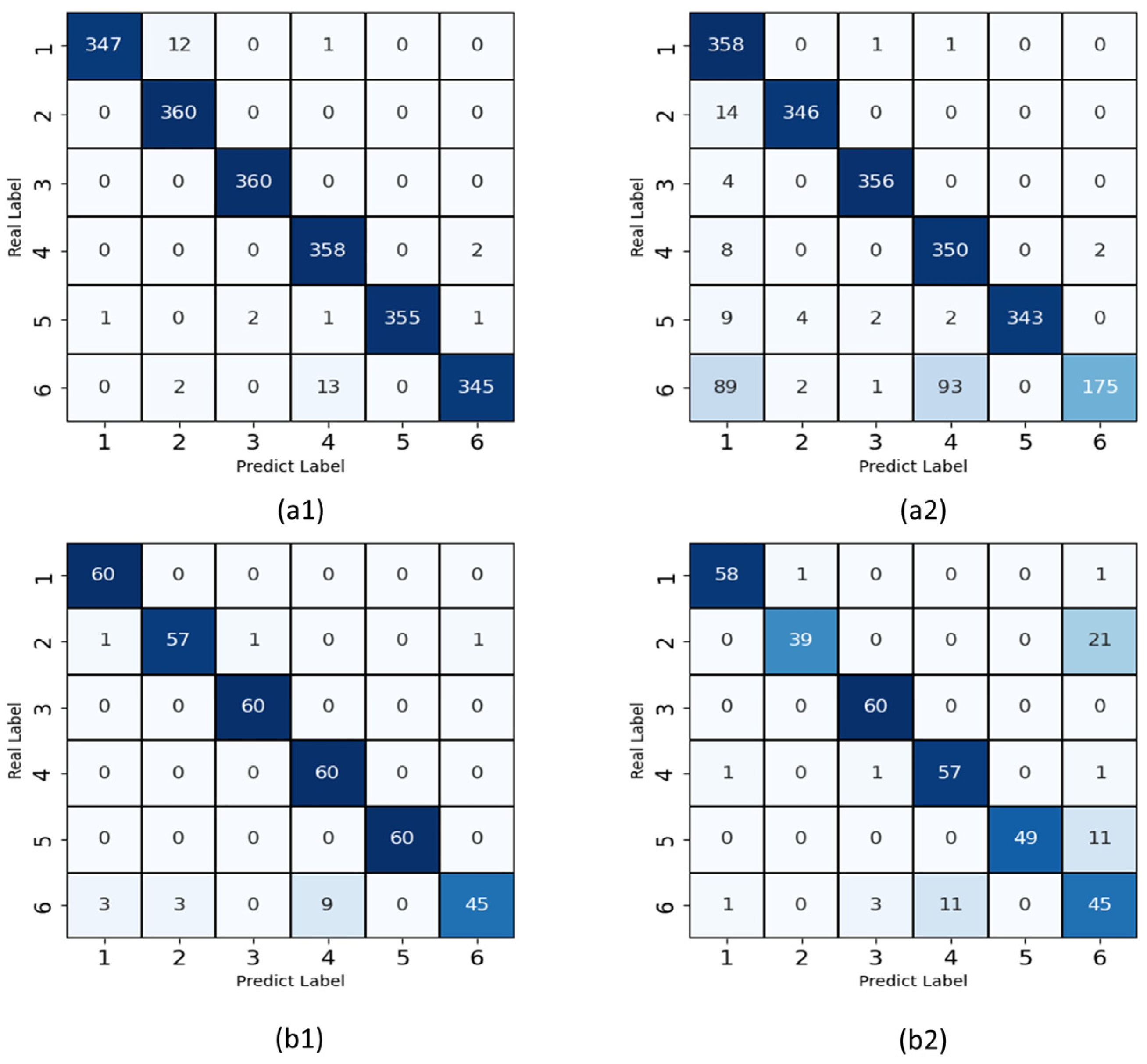
3.4. Comparison of Accuracy between Diffent Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, S.; Lach, J.; Lo, B.; Yang, G.Z. Toward pervasive gait analysis with wearable sensors: A systematic review. IEEE J. Biomed. Health Inform. 2016, 20, 1521–1537. [Google Scholar] [CrossRef] [PubMed]
- Martínez-Martín, P.; Gil-Nagel, A.; Gracia, L.M.; Gómez, J.B.; Martínez-Sarriés, J.; Bermejo, F. Unified Parkinsons-Disease Rating-Scale Characteristics and Structure. Mov. Disord. 1994, 9, 76–83. [Google Scholar] [CrossRef] [PubMed]
- Dunsky, A.; Dickstein, R.; Marcovitz, E.; Levy, S.; Deutsch, J.E. Home-Based Motor Imagery Training for Gait Rehabilitation of People with Chronic Poststroke Hemiparesis. Arch. Phys. Med. Rehabil. 2008, 89, 1580–1588. [Google Scholar] [CrossRef] [PubMed]
- Tao, W.; Liu, T.; Zheng, R.; Feng, H. Gait analysis using wearable sensors. Sensors 2012, 12, 2255–2283. [Google Scholar] [CrossRef] [PubMed]
- Suppa, A.; Kita, A.; Leodori, G.; Zampogna, A.; Nicolini, E.; Lorenzi, P.; Rao, R.; Irrera, F. l-DOPA and Freezing of Gait in Parkinson’s Disease: Objective Assessment through a Wearable Wireless System. Front. Neurol. 2017, 8, 406. [Google Scholar] [CrossRef] [PubMed]
- Paul, S.; Banerjee, A.; Ghoshal, R.; Tibarewala, D.N. Development of ultrasonic tachography system for gait analysis. Int. J. Biomed. Eng. Technol. 2016, 20, 66–95. [Google Scholar] [CrossRef]
- Sun, B.; Zuo, Z.; Zeng, X.; Liu, T.; Lu, Q. Movement disorder detection via adaptively fused gait analysis based on kinect sensors. IEEE Sens. J. 2018, 18, 7305–7314. [Google Scholar]
- Clark, R.A.; Mentiplay, B.F.; Hough, E.; Pua, Y.H. Three-dimensional cameras and skeleton pose tracking for physical function assessment: A review of uses, validity, current developments and Kinect alternatives. Gait Posture 2019, 68, 193–200. [Google Scholar] [CrossRef] [PubMed]
- Galna, B.; Barry, G.; Jackson, D.; Mhiripiri, D.; Olivier, P.; Rochester, L. Accuracy of the Microsoft Kinect sensor for measuring movement in people with Parkinson’s disease. Gait Posture 2014, 39, 1062–1068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tölgyessy, M.; Dekan, M.; Chovanec, Ľ. Skeleton Tracking Accuracy and Precision Evaluation of Kinect V1, Kinect V2, and the Azure Kinect. Appl. Sci. 2021, 11, 5756. [Google Scholar] [CrossRef]
- Albert, J.A.; Owolabi, V.; Gebel, A.; Brahms, C.M.; Granacher, U.; Arnrich, B. Evaluation of the Pose Tracking Performance of the Azure Kinect and Kinect v2 for Gait Analysis in Comparison with a Gold Standard: A Pilot Study. Sensors 2020, 20, 5104. [Google Scholar] [CrossRef] [PubMed]
- Procházka, A.; Vyšata, O.; Vališ, M.; Ťupa, O.; Schätz, M.; Mařík, V. Bayesian classification and analysis of gait disorders using image and depth sensors of Microsoft Kinect. Digit. Signal. Process. 2015, 47, 169–177. [Google Scholar] [CrossRef]
- Dranca, L.; de Abetxuko Ruiz de Mendarozketa, L.; Goñi, A.; Illarramendi, A.; Navalpotro Gomez, I.; Delgado Alvarado, M.; Rodríguez-Oroz, M.C. Using Kinect to classify Parkinson’s disease stages related to severity of gait impairment. BMC Bioinform. 2018, 19, 471. [Google Scholar] [CrossRef]
- Ťupa, O.; Procházka, A.; Vyšata, O.; Schätz, M.; Mareš, J.; Vališ, M.; Mařík, V. Motion tracking and gait feature estimation for recognising Parkinson’s disease using MS Kinect. Biomed. Eng. Online 2015, 14, 97. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Deligianni, F.; Gu, X.; Yang, G.-Z. 3-D canonical pose estimation and abnormal gait recognition with a single RGB-D camera. IEEE Robot. Autom. Lett. 2019, 4, 3617–3624. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Cui, X.; Zhao, Z.; Zhang, D.; Ma, C.; Zhang, X.; Liao, H. Gait acquisition and analysis system for osteoarthritis based on hybrid prediction model. Comput. Med. Imaging Graph. 2020, 85, 101782. [Google Scholar] [CrossRef] [PubMed]
- Jun, K.; Lee, D.-W.; Lee, K.; Lee, S.; Kim, M.S. Feature extraction using an RNN autoencoder for skeleton-based abnormal gait recognition. IEEE Access. 2020, 8, 19196–19207. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, Z.; Li, S.; Yang, B.; Li, Q.; Liu, H. Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021. [Google Scholar]
- Cheng, K.; Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Song, Y.-F.; Zhang, Z.; Shan, C.; Wang, L. Stronger, faster and more explainable: A graph convolutional baseline for skeleton-based action recognition. In Proceedings of the 28th ACM international conference on multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Jun, K.; Lee, Y.; Lee, S.; Lee, D.-W.; Kim, M. Pathological Gait Classification Using Kinect v2 and Gated Recurrent Neural Networks. IEEE Access. 2020, 8, 139881–139891. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Multi-Stream Adaptive Graph Convolutional Networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.F.; Zhang, Z.; Wang, L. Richly Activated Graph. Convolutional Network for Action. Recognition with Incomplete Skeletons. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Song, Y.-F.; Zhang, Z.; Shan, C.; Wang, L. Richly Activated Graph Convolutional Network for Robust Skeleton-Based Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1915–1925. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Year | Number of Streams | Description |
|---|---|---|---|
| ST-GCN [18] | 2018 | 1 s | Firstly constructed a spatial–temporal graph. The parameters of each layer are fixed. |
| 2s-AGCN [19] | 2019 | 2 s | Added adaptive graph convolutional layers. The network has a large amount of calculation. |
| Shift-GCN [21] | 2020 | 4 s | Proposed non-local shift graph convolution. High computational complexity due to shift operations. |
| MS-G3D [22] | 2020 | 2 s | Redefined the k-order adjacency matrix. Designed a unified spatio-temporal graph convolution operator. |
| Res-GCN [23] | 2020 | 1 s | Introduced a residual GCN with bottleneck structure and part-wise attention module. |
| MST-GCN [20] | 2021 | 4 s | Proposed a multi-scale spatial and temporal graph convolution module. |
| Number of Joints | Top-1 (%) | FLOPs (×109) |
|---|---|---|
| 25 | 83.2 ± 7.88 | 5.44 |
| 19 | 83.95 ± 4.05 | 4.13 |
| Model | Top-1 (%) | FLOPs (×109) | #Params (×106) |
|---|---|---|---|
| STGCN | 83.95 ± 4.05 | 4.13 | 3.07 |
| +STCAtt | 86.42 ± 2.69 | 4.14 | 3.37 |
| +PartAtt | 84.47 ± 10.87 | 4.15 | 3.47 |
| +ST-JointAtt | 88.81 ± 6.55 | 4.16 | 3.47 |
| Model | Top-1 (%) | FLOPs (×109) | #Params (×106) |
|---|---|---|---|
| ST-GCN | 83.95 ± 4.05 | 5.44 | 3.07 |
| RA-GCNv1(3s) | 91.21 ± 5.97 | 8.29 | 6.05 |
| RA-GCNv2(3s) | 91.23 ± 3.78 | 8.29 | 6.05 |
| 2s-AGCN | 91.06 ± 3.93 | 9.46 | 6.94 |
| STJA-GCN | 93.17 ± 2.76 | 2.44 | 2.18 |
| Model | Top-1 (%) | FLOPs (×109) | #Params (×106) |
|---|---|---|---|
| ST-GCN | 71.43 ± 4.11 | 4.79 | 3.07 |
| RA-GCNv1(3s) | 73.38 ± 4.85 | 9.60 | 6.05 |
| RA-GCNv2(3s) | 35.41 ± 4.51 | 9.60 | 6.05 |
| 2s-AGCN(3s) | 77.06 ± 6.97 | 10.94 | 6.94 |
| STJA-GCN | 92.08 ± 2.92 | 2.82 | 2.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Z.; Jiang, Y.; Zheng, J.; Yu, H. STJA-GCN: A Multi-Branch Spatial–Temporal Joint Attention Graph Convolutional Network for Abnormal Gait Recognition. Appl. Sci. 2023, 13, 4205. https://doi.org/10.3390/app13074205
Yin Z, Jiang Y, Zheng J, Yu H. STJA-GCN: A Multi-Branch Spatial–Temporal Joint Attention Graph Convolutional Network for Abnormal Gait Recognition. Applied Sciences. 2023; 13(7):4205. https://doi.org/10.3390/app13074205
Chicago/Turabian StyleYin, Ziming, Yi Jiang, Jianli Zheng, and Hongliu Yu. 2023. "STJA-GCN: A Multi-Branch Spatial–Temporal Joint Attention Graph Convolutional Network for Abnormal Gait Recognition" Applied Sciences 13, no. 7: 4205. https://doi.org/10.3390/app13074205