
Detecting COVID-19 Effectively with Transformers and CNN-Based Deep Learning Mechanisms

Abstract
:1. Introduction
- 1.
- We conducted an extensive analysis of the available research on using CT scans for COVID-19 detection.
- 2.
- We explored different techniques for creating models that can detect COVID-19.
- 3.
- We developed an enhanced model for detecting the virus.
2. Materials and Methods
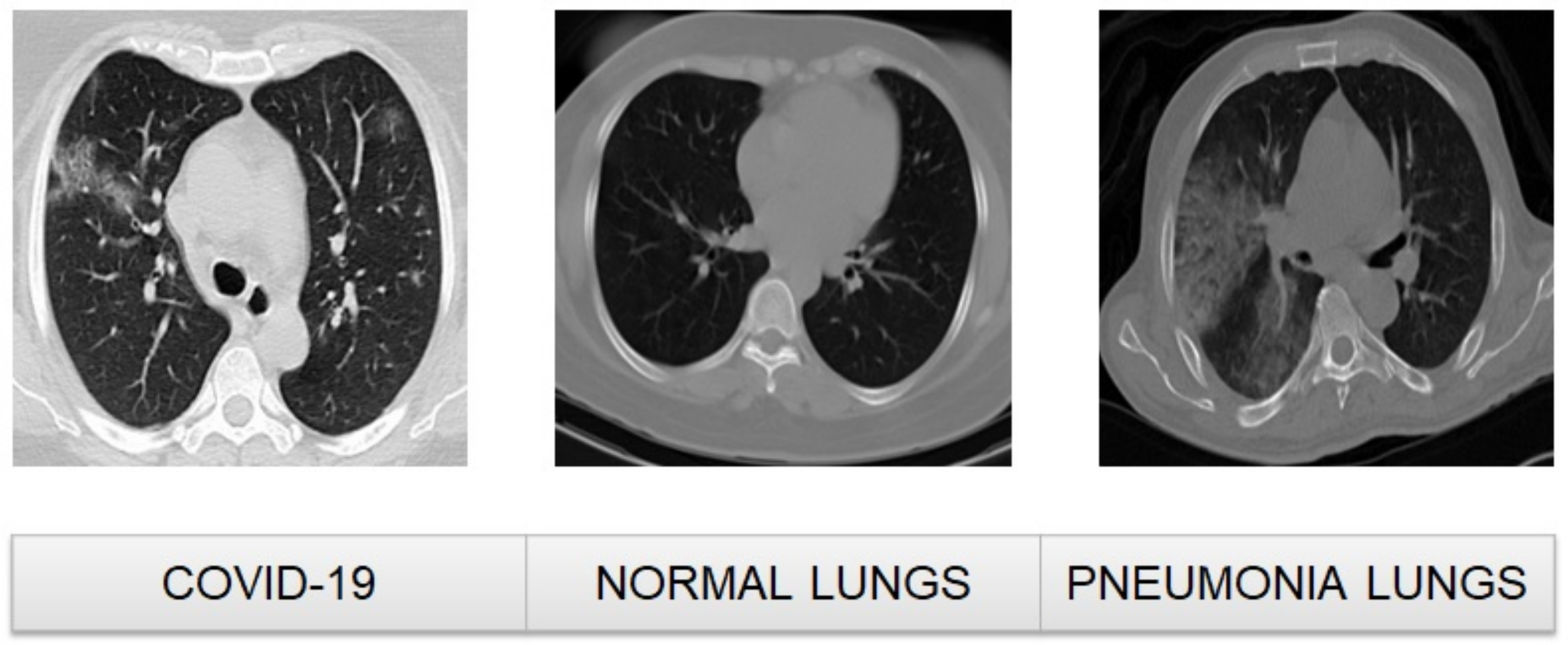
2.1. Dataset
2.2. Dataset Processing and Splitting
- 1.
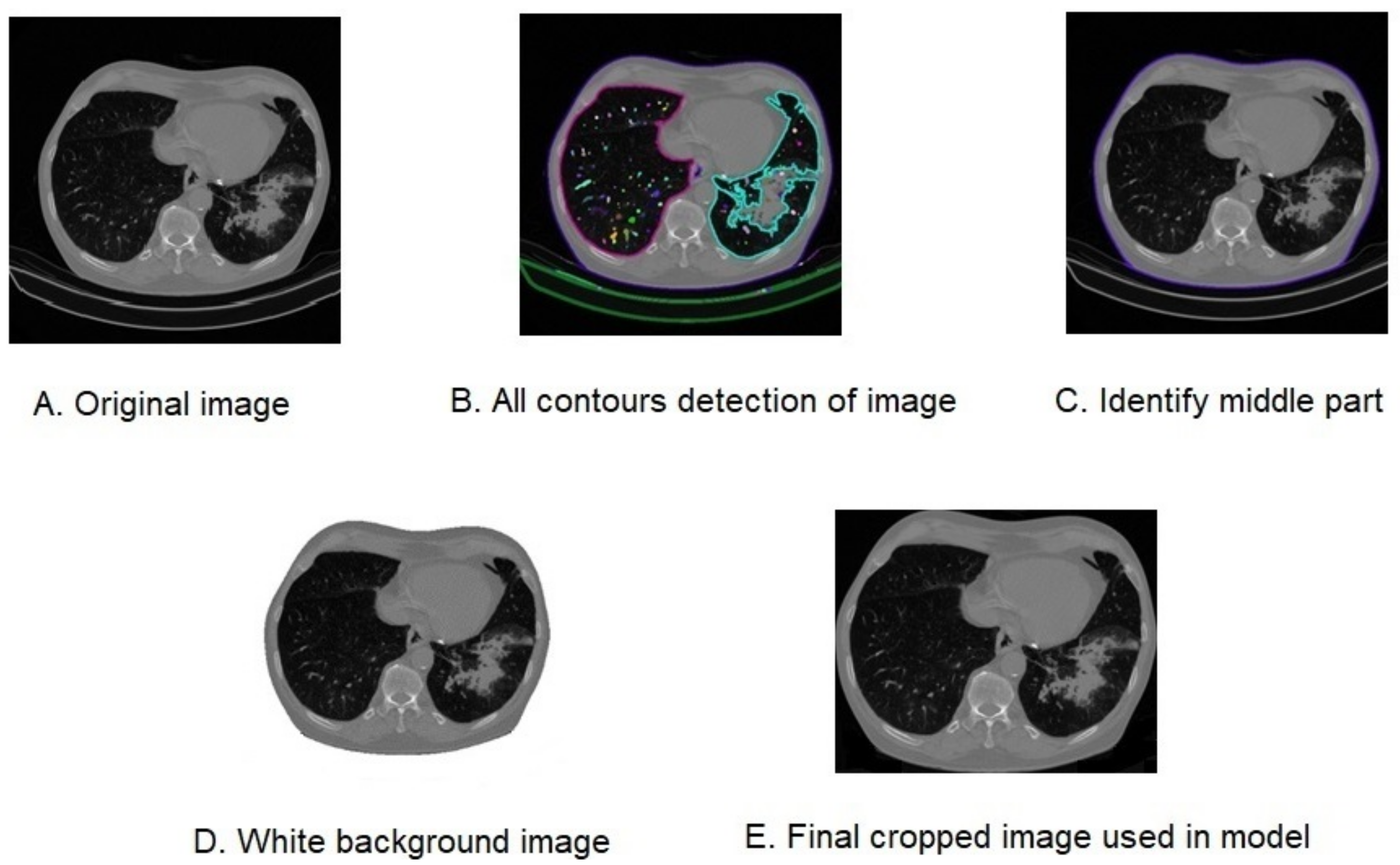
- The first step in this process was to resize the images to a standard size and convert them to grayscale. This helps to simplify the processing steps that followed and ensured that all images were of the same size and color format, as demonstrated in Figure 2A.
- 2.
- Next, binary thresholding was applied to the images, which involved converting them to black and white and highlighting key areas of the images of importance for the contouring algorithm. This step simplified the detection and isolation of relevant features in the images.
- 3.
- The OpenCV library’s findContours function was then used to detect all the contours present in the images, as shown in Figure 2B. This allowed for the identification of the different shapes and patterns present in the images, which is an important step in many image processing tasks.
- 4.
- The boundary contour was determined using the outer lung region as a reference, as illustrated in Figure 2C. This contour was used to crop the original images, which were already resized to a standard size of 256 × 256 pixels, as can be seen in Figure 2D with a white background and in Figure 2E with a black background.
- 5.
- TFinally, the images were normalized and converted to a uniform depth of 8-bit, which ensured that the pixel values were consistent across all images. This step is important for ensuring that the data are well-prepared for the training of machine learning models, which often require data to be in a specific format.

| Algorithm 1: Data preparation Algorithm |
| Input: Image dataset of 512 × 512 from Kaggle collected by Maftouni, et al. 2021 [16] |
| Output: 256 × 256 cropped images split in patient aware manner |
 |
2.3. Existing Model Recreation
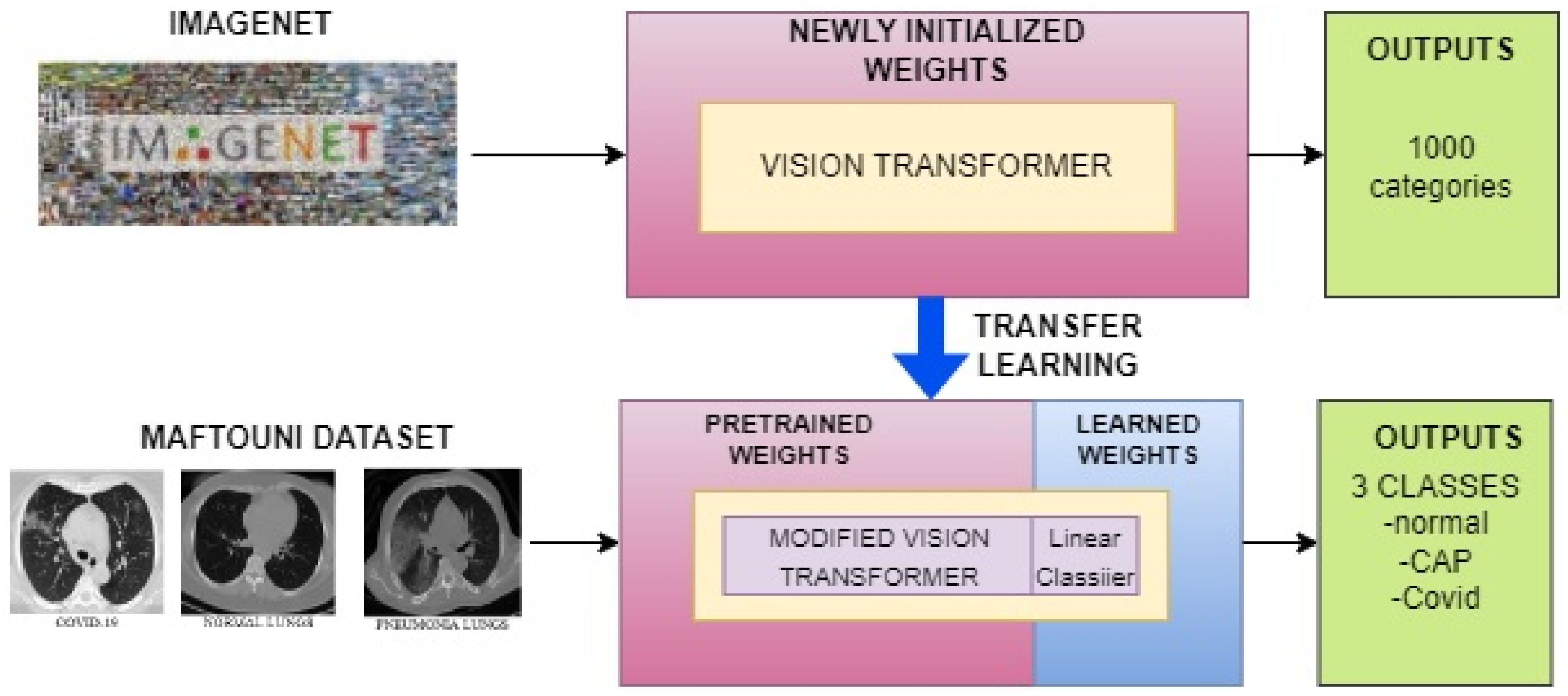
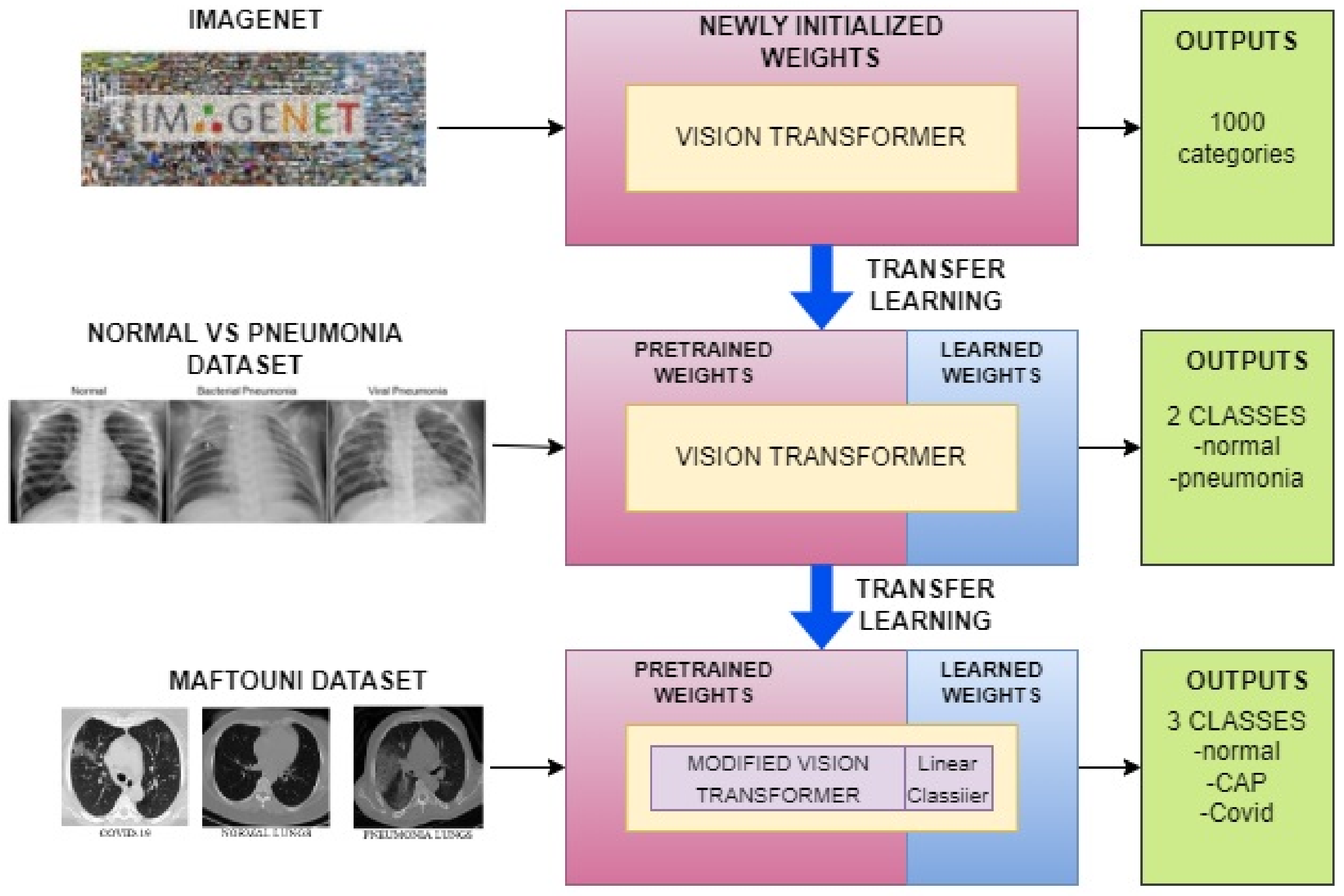
2.4. Vision Transformer with a Custom Linear Classifier
2.4.1. One-Step Transfer Learning Approach
2.4.2. Two-Step Transfer Learning Approach
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lotfi, M.; Hamblin, M.R.; Rezaei, N. COVID-19: Transmission, prevention, and potential therapeutic opportunities. Clin. Chim. Acta 2020, 508, 254–266. [Google Scholar] [CrossRef]
- Rubino, S.; Kelvin, N.; Bermejo-Martin, J.F.; Kelvin, D. As COVID-19 cases, deaths and fatality rates surge in Italy, underlying causes require investigation. J. Infect. Dev. Ctries. 2020, 14, 265–267. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwee, T.C.; Kwee, R.M. Chest CT in COVID-19: What the radiologist needs to know. RadioGraphics 2020, 40, 1848–1865. [Google Scholar] [CrossRef] [PubMed]
- Hani, C.; Trieu, N.H.; Saab, I.; Dangeard, S.; Bennani, S.; Chassagnon, G.; Revel, M.-P. COVID-19 pneumonia: A review of typical CT findings and differential diagnosis. Diagn. Interv. Imaging 2020, 101, 263–268. [Google Scholar] [CrossRef] [PubMed]
- Parasher, A. COVID-19: Current Understanding of Its Pathophysiology, Clinical Presentation and Treatment. Available online: https://pmj.bmj.com/content/97/1147/312.citation-tools (accessed on 3 December 2022).
- Saeed, G.A.; Gaba, W.; Shah, A.; Al Helali, A.A.; Raidullah, E.; Al Ali, A.B.; Elghazali, M.; Ahmed, D.Y.; Al Kaabi, S.G.; Almazrouei, S. Correlation between chest CT severity scores and the clinical parameters of adult patients with COVID-19 pneumonia. Radiol. Res. Pract. 2021, 2021, 6697677. [Google Scholar] [CrossRef] [PubMed]
- Mogami, R.; Lopes, A.J.; Araújo Filho, R.C.; de Almeida, F.C.S.; Messeder, A.M.D.C.; Koifman, A.C.B.; Guimarães, A.B.; Monteiro, A. Chest Computed Tomography in COVID-19 Pneumonia: A Retrospective Study of 155 Patients at a University Hospital in Rio de Janeiro, Brazil. Available online: https://pubmed.ncbi.nlm.nih.gov/33583973/ (accessed on 2 December 2022).
- Zhang, B.; Zhang, J.; Chen, H.; Chen, L.; Chen, Q.; Li, M.; Chen, Z.; You, J.; Yang, K.; Zhang, S. Novel coronavirus disease 2019 (COVID-19): Relationship between chest CT scores and laboratory parameters. Eur. J. Nucl. Med. Mol. Imaging 2020, 47, 2083–2089. [Google Scholar] [CrossRef] [PubMed]
- Liao, J.; Chen, Y.; Huang, C.Q.; He, G.; Du, J.C.; Chen, Q.L. Clinical differences in chest CT characteristics between the progression and remission stages of patients with Covid-19 pneumonia. Int. J. Clin. Pract. 2020, 75, e13760. [Google Scholar] [CrossRef] [PubMed]
- Fusco, R.; Grassi, R.; Granata, V.; Setola, S.V.; Grassi, F.; Cozzi, D.; Pecori, B.; Izzo, F.; Petrillo, A. Artificial Intelligence and COVID-19 using chest CT scan and chest X-ray images: Machine learning and deep learning approaches for diagnosis and treatment. J. Pers. Med. 2021, 11, 993. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Xingming, Z.; Tao, G.; Dan, T.; Li, J.; Chen, X.; Li, Y.; Zhou, Z.; Zhang, X.; Zhou, J.; et al. Classification of covid-19 by compressed chest CT image through deep learning on a large patients cohort. Interdiscip. Sci. Comput. Life Sci. 2021, 13, 73–82. [Google Scholar] [CrossRef] [PubMed]
- El Naqa, I.; Murphy, M.J. What Is Machine Learning? In Machine Learning in Radiation Oncology; El Naqa, I., Li, R., Murphy, M., Eds.; Springer: Cham, Switzerland, 2015. [Google Scholar] [CrossRef]
- Gunraj, H.; Sabri, A.; Koff, D.; Wong, A. Covid-net CT-2: Enhanced Deep Neural Networks for detection of COVID-19 from chest CT images through bigger, more diverse learning. Front. Med. 2022, 8, 3126. [Google Scholar] [CrossRef] [PubMed]
- Kogilavani, S.V.; Prabhu, J.; Sandhiya, R.; Kumar, M.S.; Subramaniam, U.S.; Karthick, A.; Muhibbullah, M.; Imam, S.B. COVID-19 detection based on lung CT scan using Deep Learning Techniques. Comput. Math. Methods Med. 2022, 2022, 7672196. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Jiang, W.; Qiu, X. Deep learning for COVID-19 detection based on CT Images. Sci. Rep. 2021, 11, 14353. [Google Scholar] [CrossRef] [PubMed]
- Maftouni, M.; Law, A.C.C.; Shen, B.; Kong, Z.; Zhou, Y.; Yazdi, N.A. A Robust Ensemble-Deep Learning Model for COVID-19 Diagnosis based on an Integrated CT Scan Images Database. In IIE Annual Conference; Institute of Industrial and Systems Engineers: Peachtree Corners, GA, USA, 2021; pp. 632–637. [Google Scholar]
- Farooq, M.; Hafeez, A. Covid-ResNet: A Deep Learning Framework for Screening of COVID-19 from Radiographs. Available online: https://arxiv.org/abs/2003.14395 (accessed on 2 December 2022).
- Sreejith, V.; George, T. Detection of COVID-19 from chest X-rays using resnet-50. J. Phys. Conf. Ser. 2021, 1937, 012002. [Google Scholar] [CrossRef]
- Diallo, P.A.; Ju, Y. Accurate detection of COVID-19 using K-efficientnet deep learning image classifier and K-COVID chest X-Ray Images Dataset. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020. [Google Scholar] [CrossRef]
- Chowdhury, N.K.; Kabir, M.A.; Rahman, M.M.; Rezoana, N. ECOVNet: A highly effective ensemble based deep learning model for detecting COVID-19. PeerJ Comput. Sci. 2021, 7, e551. [Google Scholar] [CrossRef] [PubMed]
- Mishra, N.K.; Singh, P.; Joshi, S.D. Automated detection of COVID-19 from CT scan using Convolutional Neural Network. Biocybern. Biomed. Eng. 2021, 41, 572–588. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. Available online: https://arxiv.org/abs/1608.06993 (accessed on 1 December 2022).
- Zhang, Y.-D.; Satapathy, S.C.; Zhang, X.; Wang, S.-H. COVID-19 diagnosis via DenseNet and optimization of transfer learning setting. Cogn. Comput. 2021. [Google Scholar] [CrossRef] [PubMed]
- Chouat, I.; Echtioui, A.; Khemakhem, R.; Zouch, W.; Ghorbel, M.; Hamida, A.B. COVID-19 detection in CT and CXR images using Deep Learning Models. Biogerontology 2022, 23, 65–84. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. Available online: https://arxiv.org/abs/2102.04306v1 (accessed on 3 December 2022).
- Sagar, A. Vitbis: Vision Transformer for Biomedical Image Segmentation. Available online: https://arxiv.org/abs/2201.05920 (accessed on 3 December 2022).
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention Gated Networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. Available online: https://arxiv.org/abs/2010.11929v1 (accessed on 2 December 2022).
- Boesch, G. Vision Transformers (VIT) in Image Recognition—2022 Guide. Available online: https://viso.ai/deep-learning/vision-transformer-vit/ (accessed on 3 December 2022).
- Lutins, E. Ensemble Methods in Machine Learning: What are They and Why Use Them? Available online: https://towardsdatascience.com/ensemble-methods-in-machine-learning-what-are-they-and-why-use-them-68ec3f9fef5f (accessed on 2 December 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | F1-Score | Mean(Acc) |
|---|---|---|---|---|
| VGG-19 | 0.8001 ± 0.0097 | 0.7684 ± 0.0094 | 0.7439 ± 0.0188 | 0.7660 ± 0.0111 |
| DenseNet-121 | 0.8777 ± 0.0071 | 0.9409 ± 0.0098 | 0.9093 ± 0.0110 | 0.9228 ± 0.0035 |
| Maftouni Ensemble Model with FC | 0.8984 ± 0.0071 | 0.9830 ± 0.0071 | 0.9386 ± 0.0082 | 0.9508 ± 0.0012 |
| Maftouni Ensemble Model with FC+SVM | 0.9078 ± 0.0110 | 0.9789 ± 0.0103 | 0.9420 ± 0.0097 | 0.9529 ± 0.0043 |
| Vision Transformer with 1 step Classifier Model | 0.9698 ± 0.0054 | 0.9666 ± 0.0075 | 0.9618 ± 0.0119 | 0.9693 ± 0.0037 |
| Vision Transformer with 2-step Classifier Model | 0.9766 ± 0.0081 | 0.9761 ± 0.0037 | 0.9767 ± 0.0075 | 0.9736 ± 0.0051 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Umejiaku, A.P.; Dhakal, P.; Sheng, V.S. Detecting COVID-19 Effectively with Transformers and CNN-Based Deep Learning Mechanisms. Appl. Sci. 2023, 13, 4050. https://doi.org/10.3390/app13064050
Umejiaku AP, Dhakal P, Sheng VS. Detecting COVID-19 Effectively with Transformers and CNN-Based Deep Learning Mechanisms. Applied Sciences. 2023; 13(6):4050. https://doi.org/10.3390/app13064050
Chicago/Turabian StyleUmejiaku, Afamefuna Promise, Prastab Dhakal, and Victor S. Sheng. 2023. "Detecting COVID-19 Effectively with Transformers and CNN-Based Deep Learning Mechanisms" Applied Sciences 13, no. 6: 4050. https://doi.org/10.3390/app13064050