
Smartwatch In-Air Signature Time Sequence Three-Dimensional Static Restoration Classification Based on Multiple Convolutional Neural Networks

Abstract
:1. Introduction
2. Materials and Methods
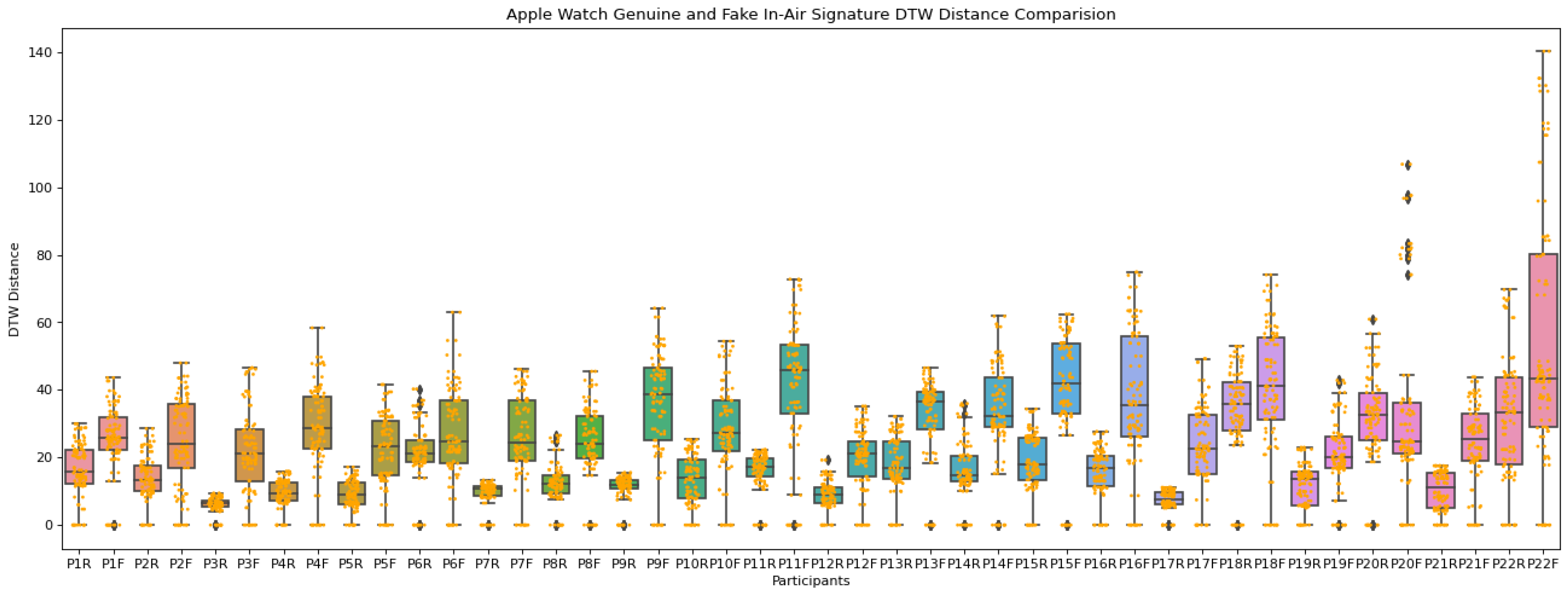
2.1. Data Acquisition
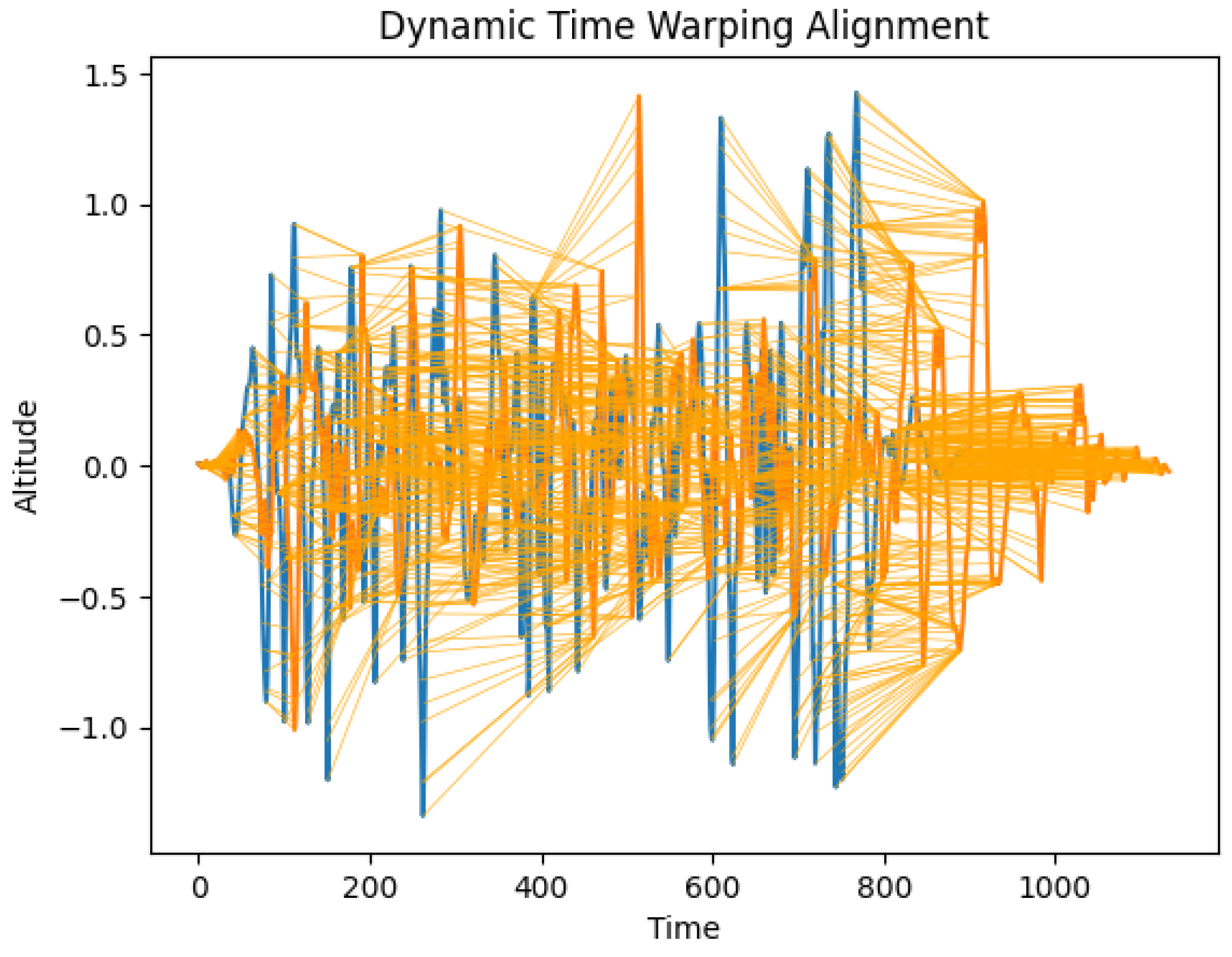
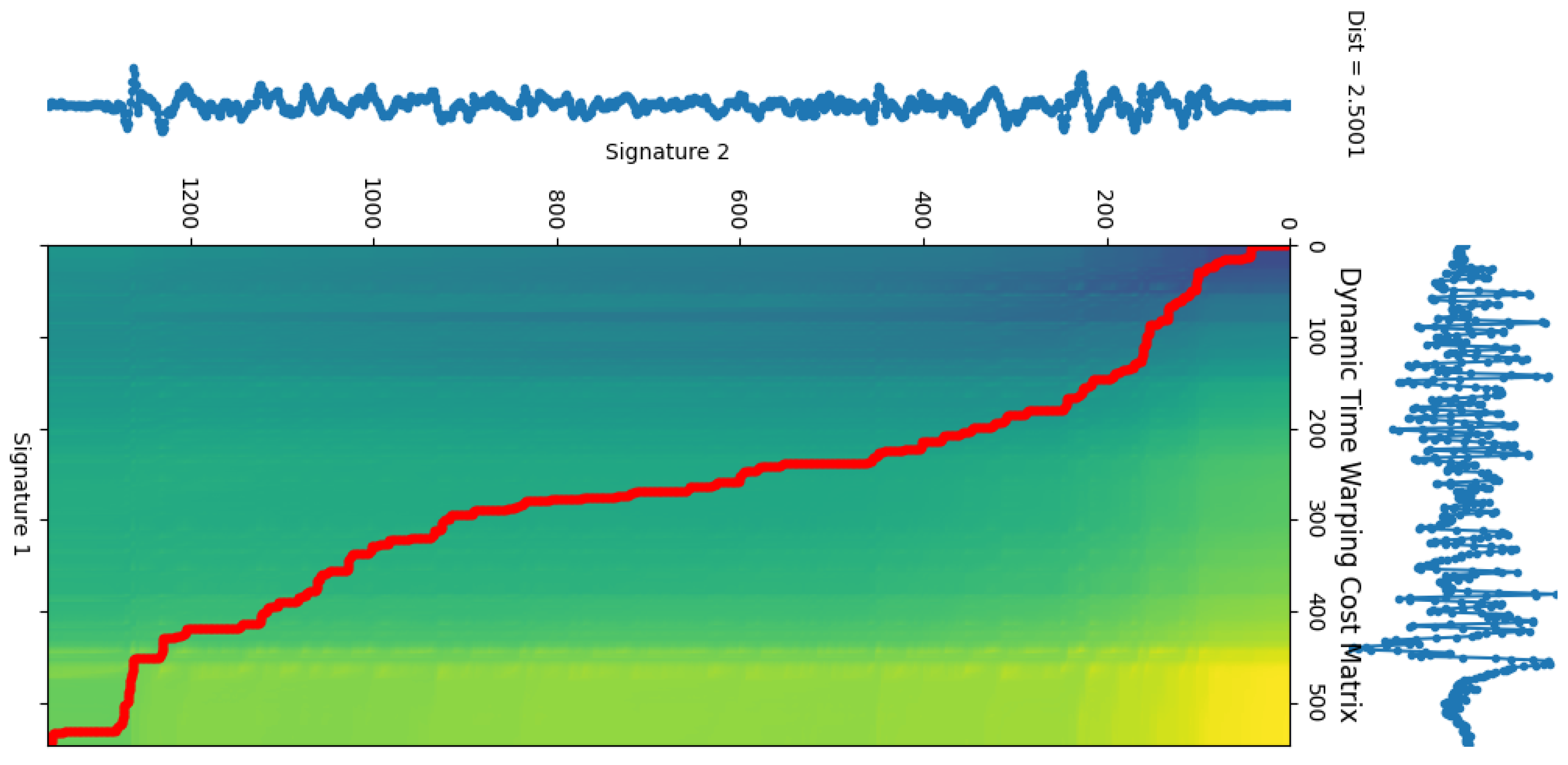
2.2. Data Analysis
| Algorithm 1 Dynamic time warping [35] |
|
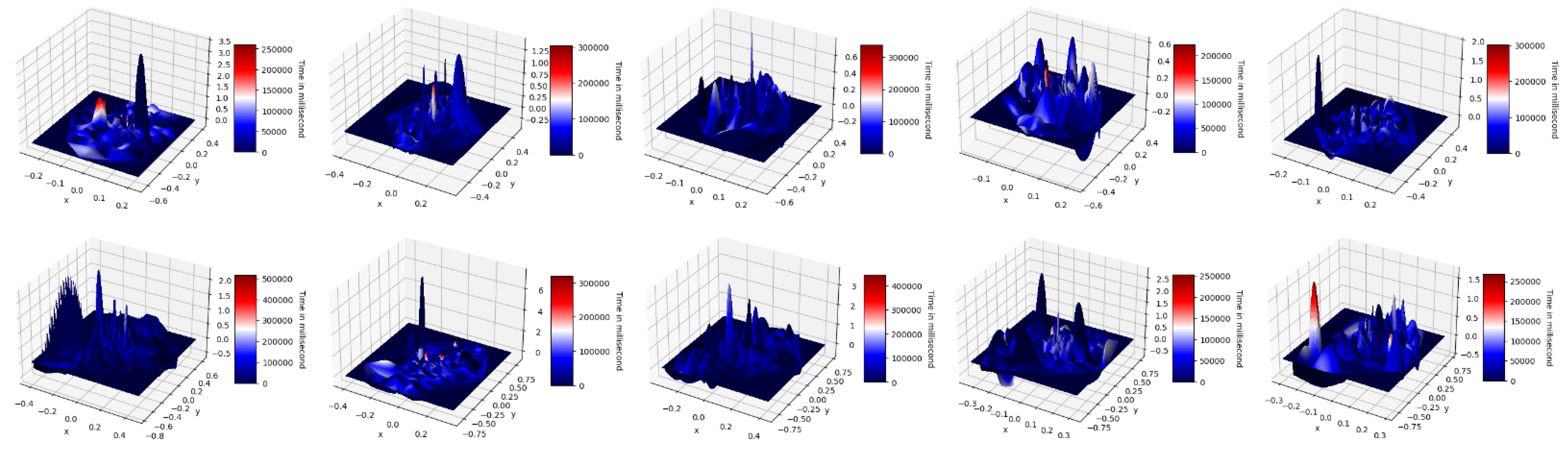
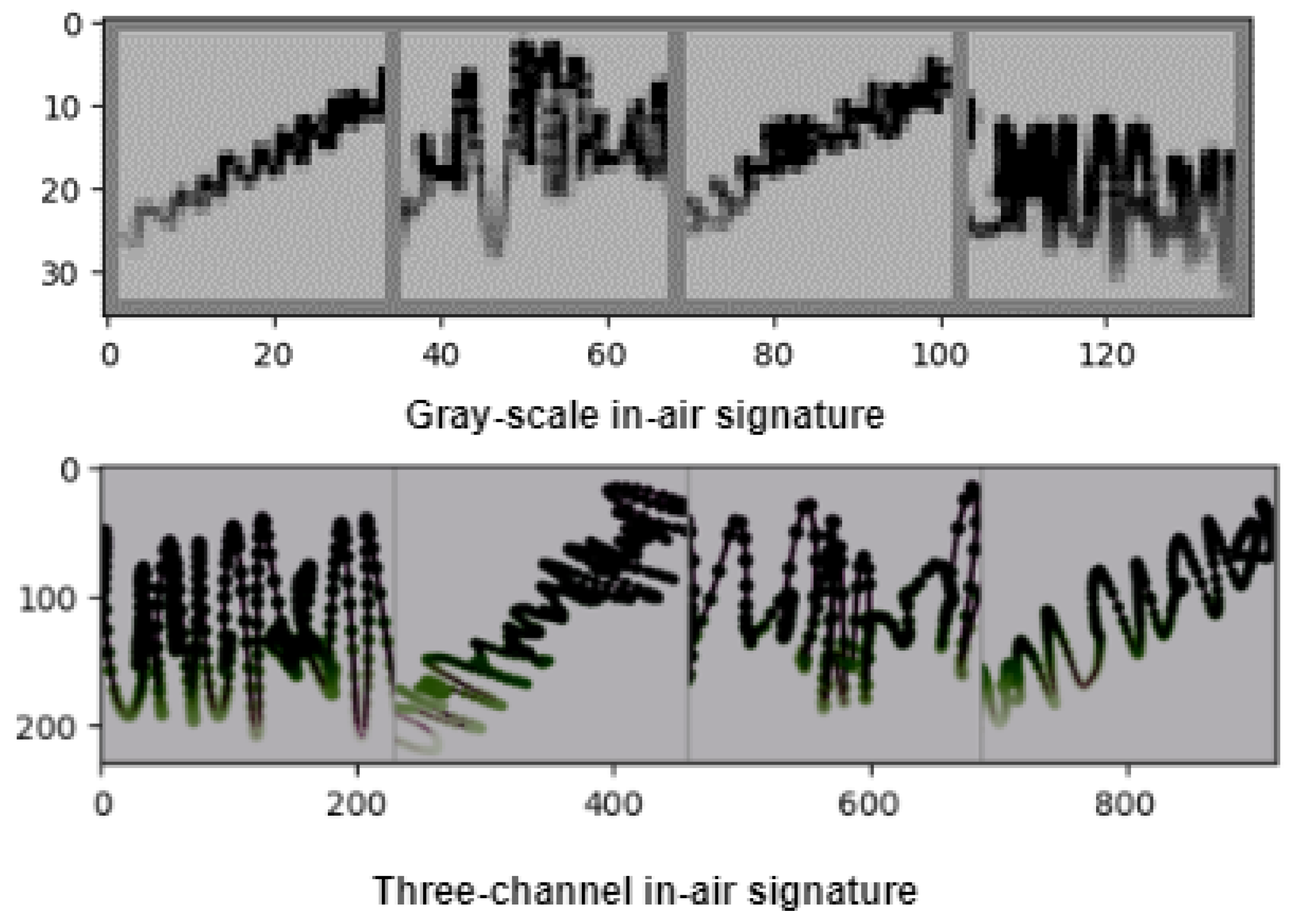
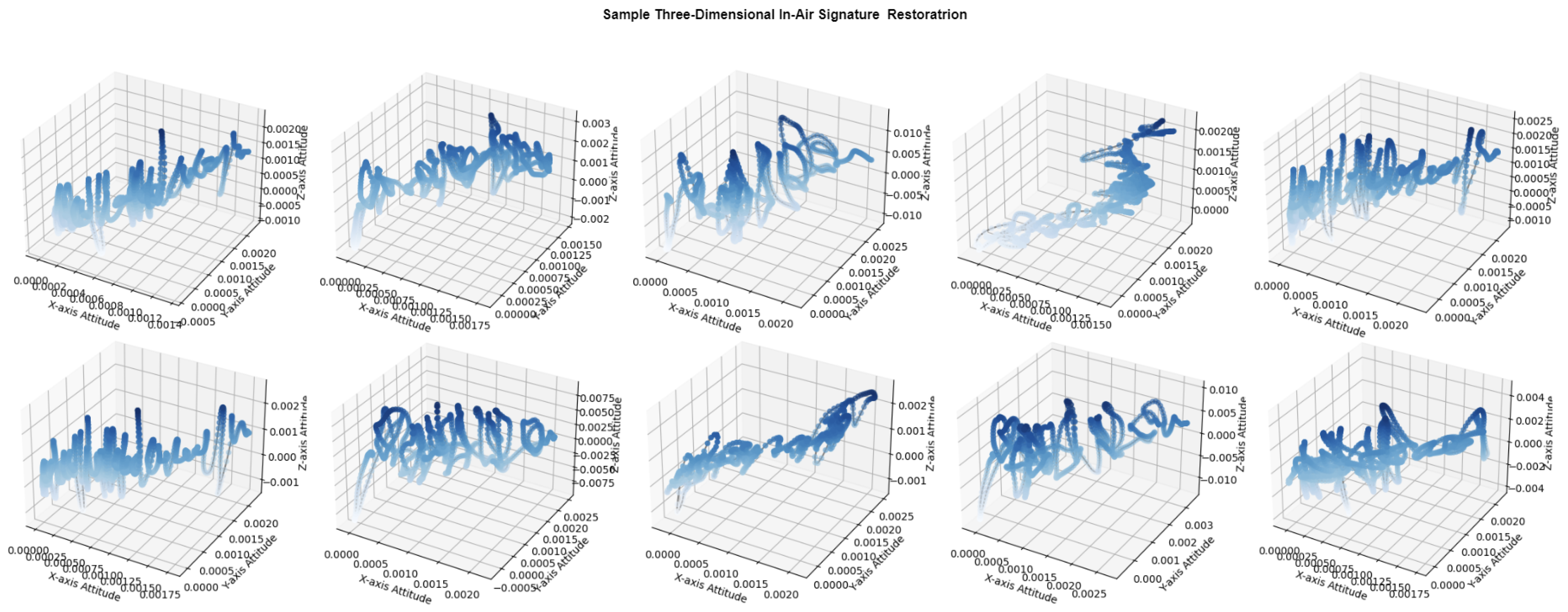
3. Proposal of Restoration of In-Air Signature
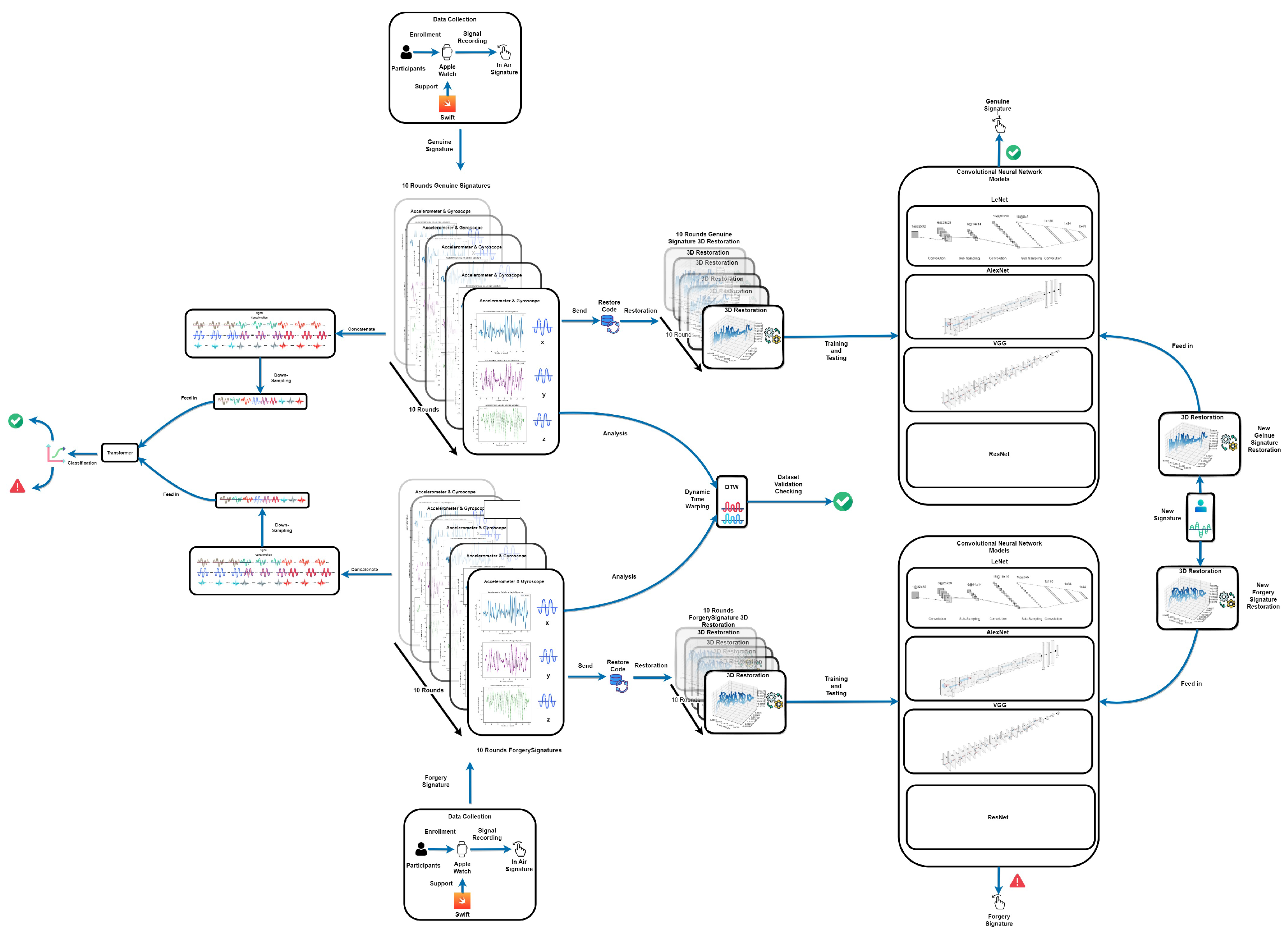
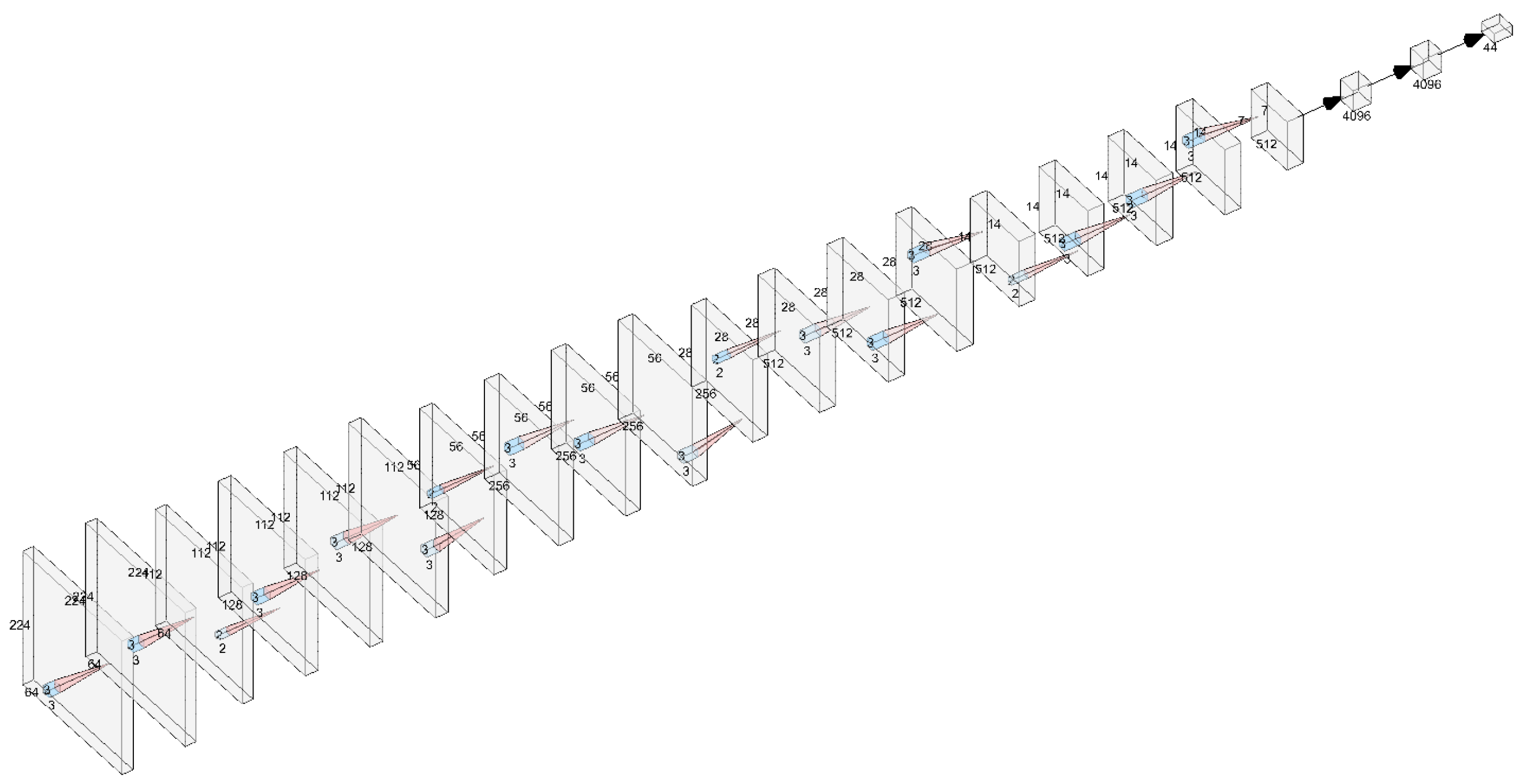
3.1. System Architecture
3.2. Methodology
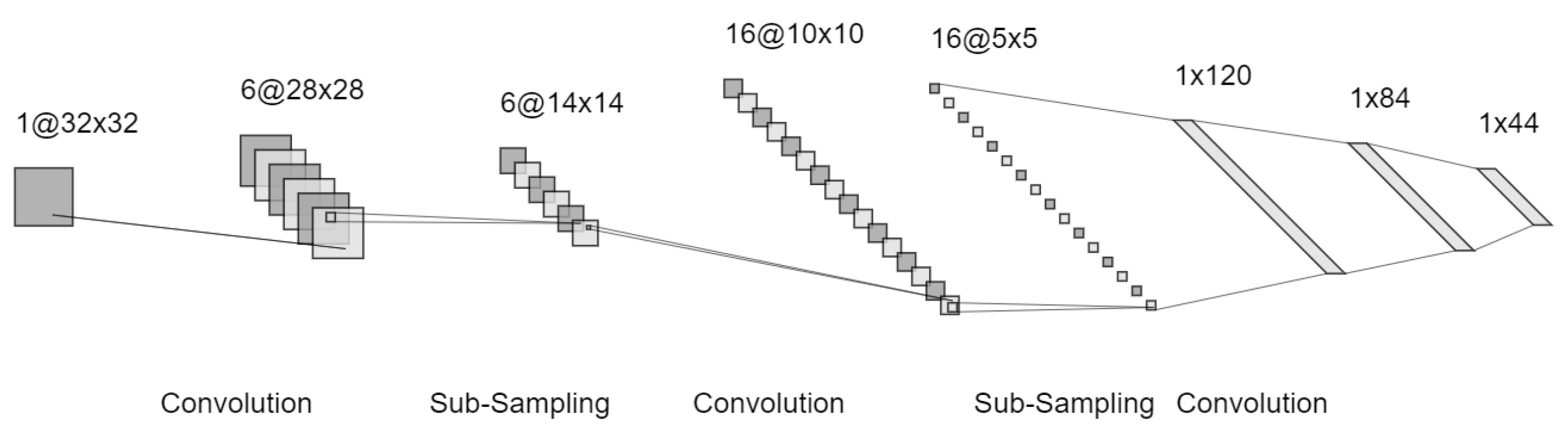
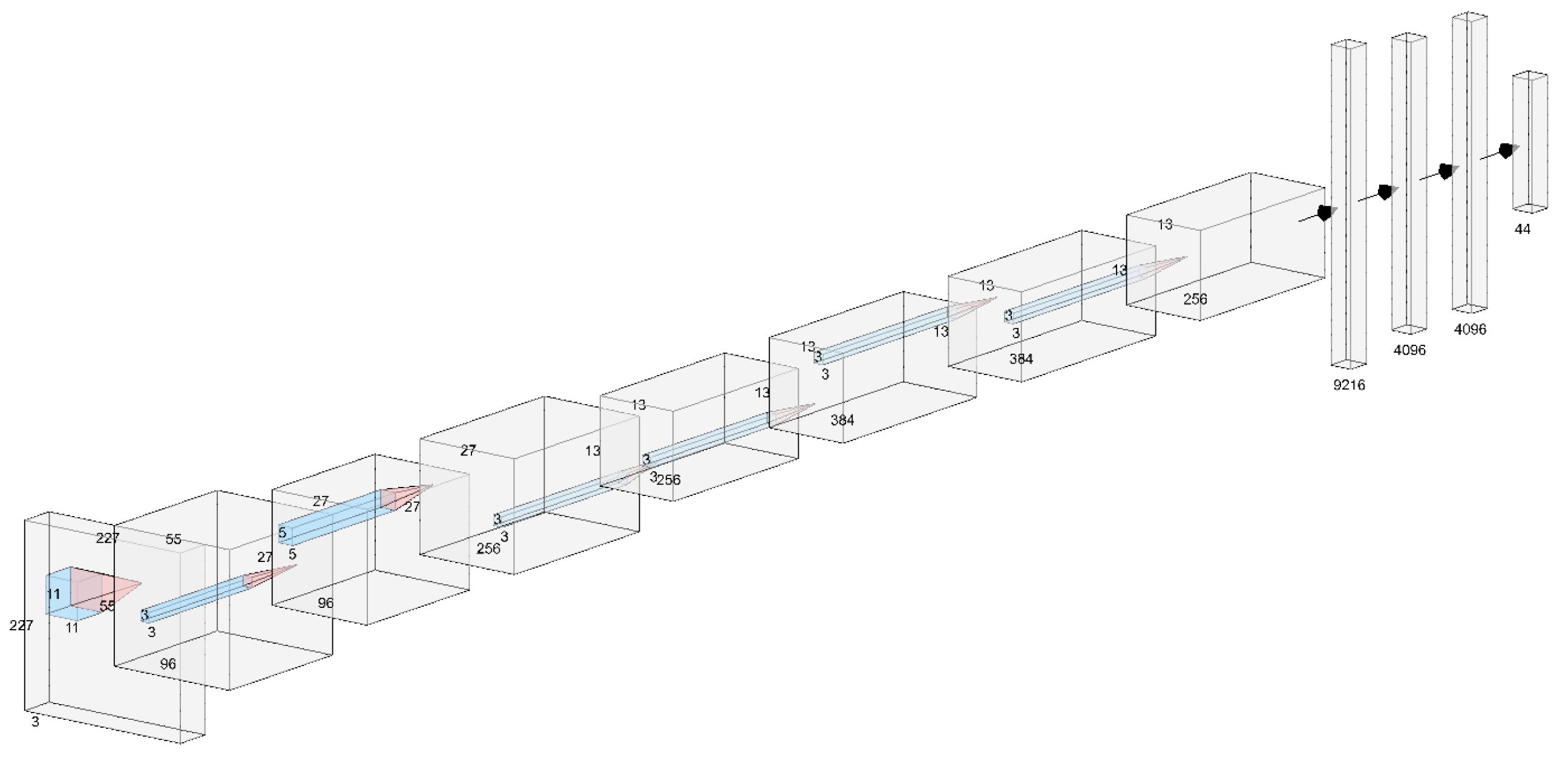
3.3. Comparative Study of CNN
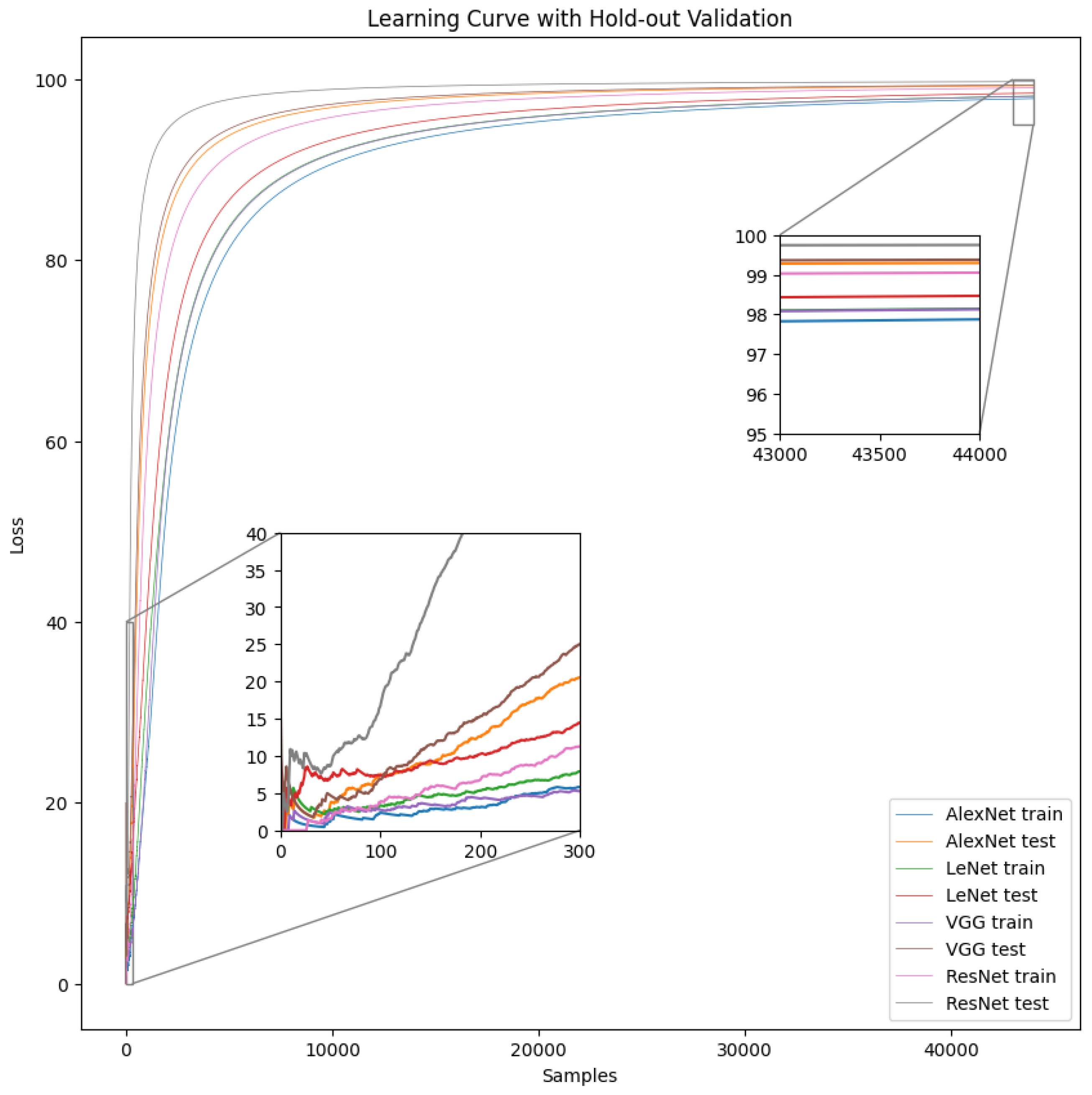
4. Results
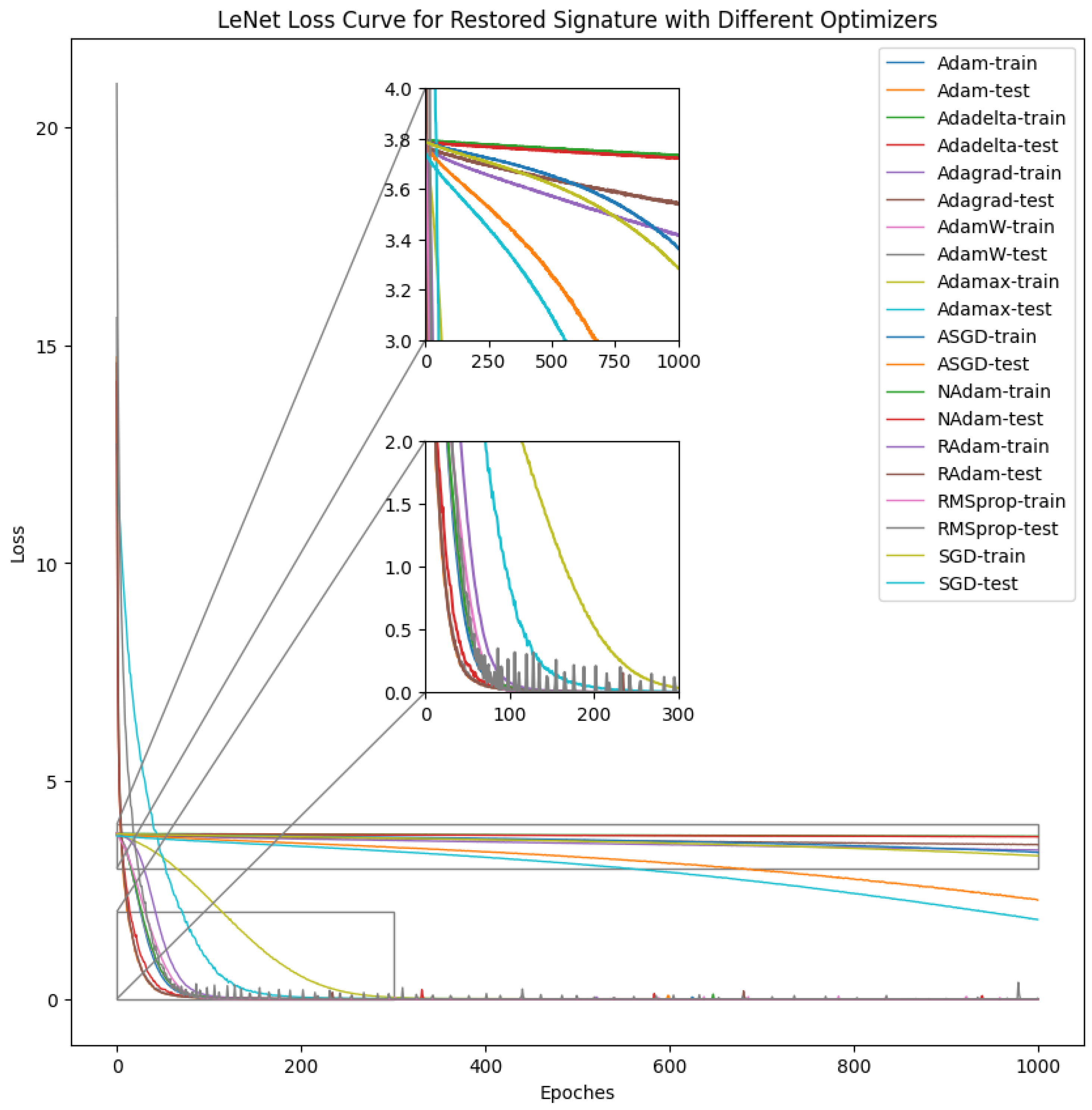
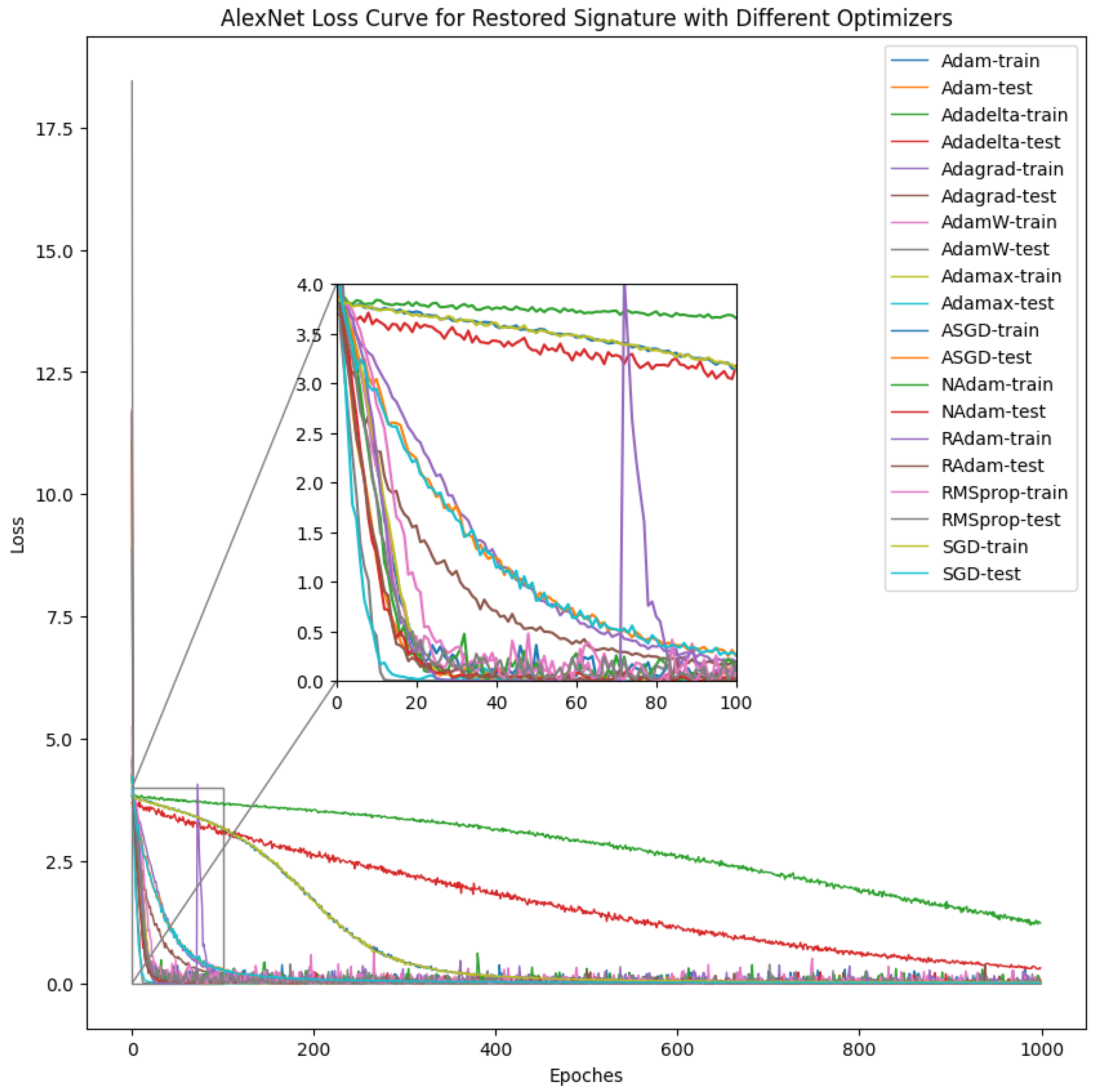
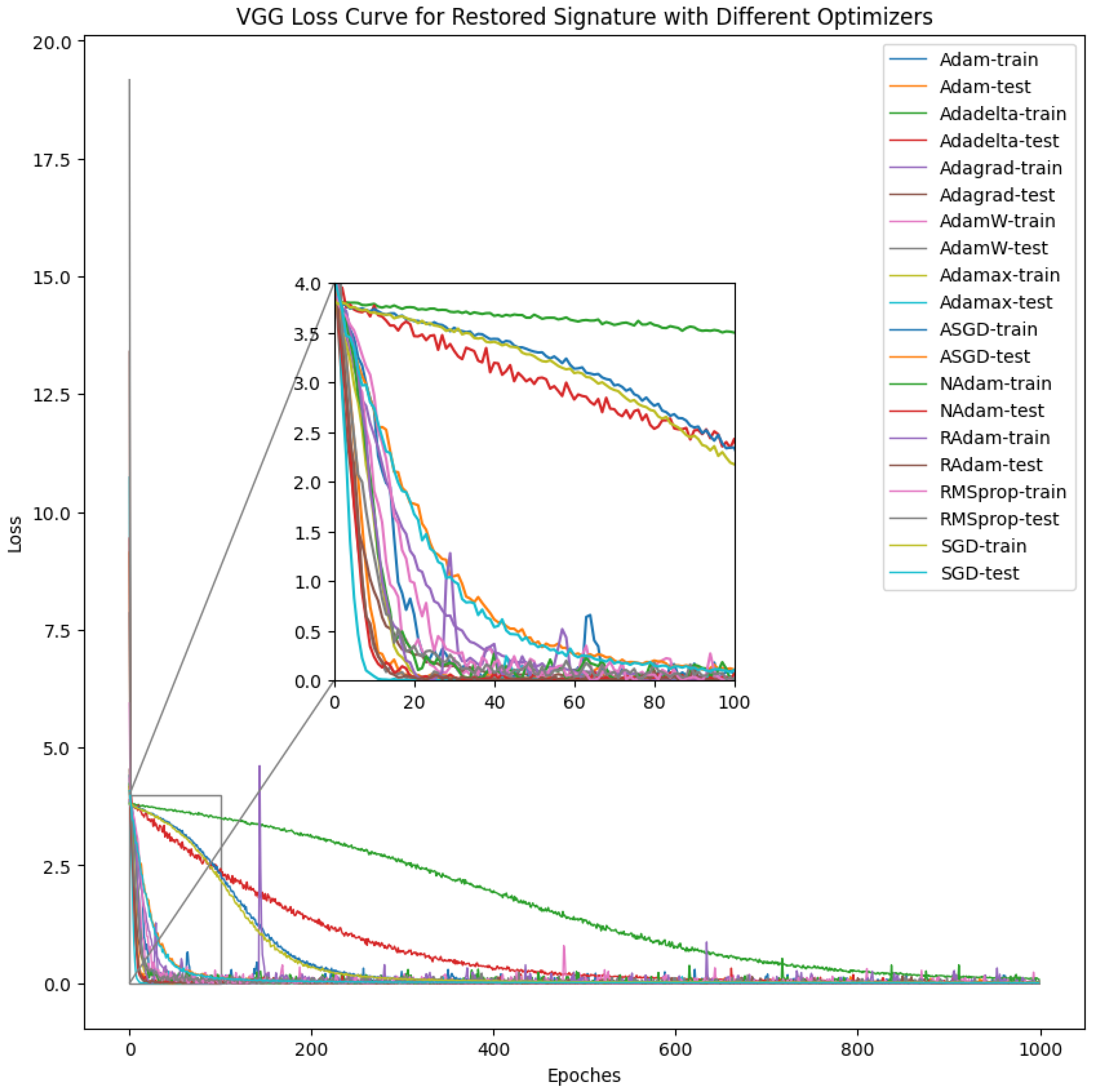
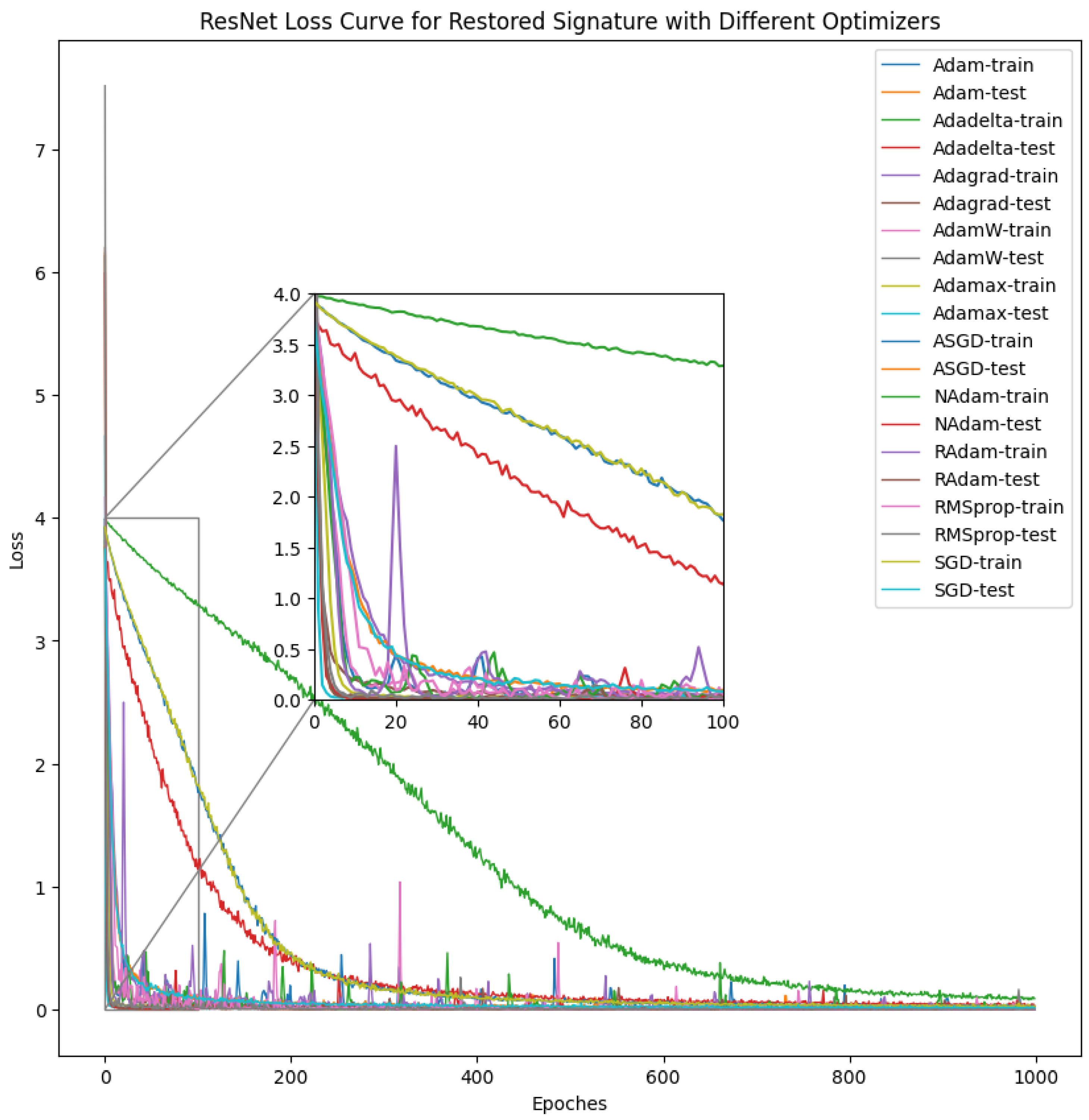
4.1. Convolutional Neural Network (CNN) Result
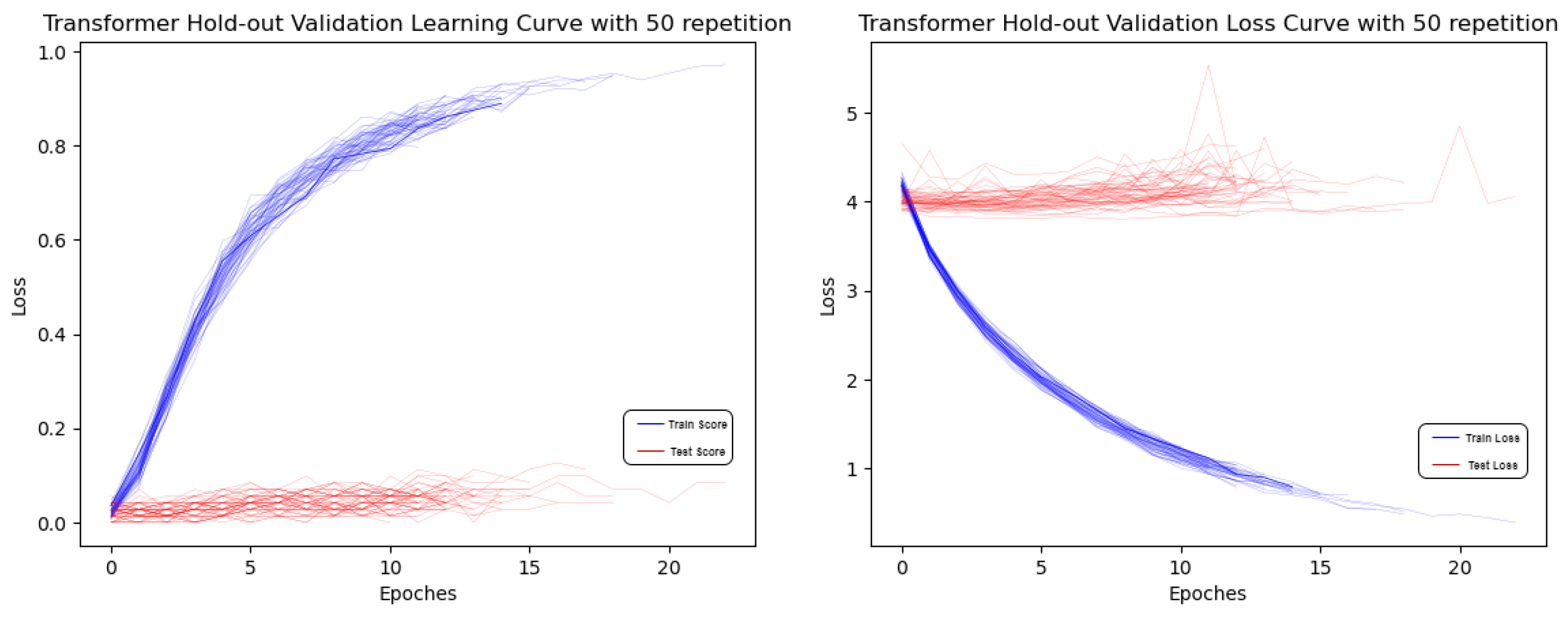
4.2. Transformer Result
5. Discussion
6. Future Research
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| DTW | dynamic time warping |
| MD-DTW | multidimensional dynamic time warping |
| BERT | pre-training of deep bidirectional transformers |
| EER | equal error rate |
| MHI | motion history image |
| EcoG | electrocorticography |
| ALS | amyotrophic lateral sclerosis |
| MLP | multi-layer perceptron |
| SDG | stochastic gradient descent |
| Pi | Raspberry Pi |
| VR | virtual reality |
References
- Oğuz, A.; Ertuğrul, Ö.F. Human identification based on accelerometer sensors obtained by mobile phone data. Biomed. Signal Process. Control 2022, 77, 103847. [Google Scholar] [CrossRef]
- Ketabdar, H.; Moghadam, P.; Naderi, B.; Roshandel, M. Magnetic signatures in air for mobile devices. In Proceedings of the 14th International Conference on Human-Computer Interaction with Mobile Devices and Services Companion, San Francisco, CA, USA, 21–24 September 2012; pp. 185–188. [Google Scholar]
- Rehman, W.U.; Laghari, A.; Memon, Z.U. Exploiting smart phone accelerometer as a personal identification mechanism. Mehran Univ. Res. J. Eng. Technol. 2015, 34, 21–26. [Google Scholar]
- Li, G.; Sato, H. Sensing in-air signature motions using smartwatch: A high-precision approach of behavioral authentication. IEEE Access 2022, 10, 57865–57879. [Google Scholar] [CrossRef]
- Malik, J.; Elhayek, A.; Ahmed, S.; Shafait, F.; Malik, M.I.; Stricker, D. 3dairsig: A framework for enabling in-air signatures using a multi-modal depth sensor. Sensors 2018, 18, 3872. [Google Scholar] [CrossRef] [Green Version]
- Fang, Y.; Kang, W.; Wu, Q.; Tang, L. A novel video-based system for in-air signature verification. Comput. Electr. Eng. 2017, 57, 1–14. [Google Scholar] [CrossRef]
- Guerra-Segura, E.; Ortega-Pérez, A.; Travieso, C.M. In-air signature verification system using leap motion. Expert Syst. Appl. 2021, 165, 113797. [Google Scholar] [CrossRef]
- Behera, S.K.; Dash, A.K.; Dogra, D.P.; Roy, P.P. Air signature recognition using deep convolutional neural network-based sequential model. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3525–3530. [Google Scholar]
- Wang, H.; Lymberopoulos, D.; Liu, J. Sensor-based user authentication. In Wireless Sensor Networks; Abdelzaher, T., Pereira, N., Tovar, E., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 168–185. [Google Scholar]
- Laghari, A.; Waheed-ur-Rehman; Memon, Z.A. Biometric authentication technique using smartphone sensor. In Proceedings of the 2016 13th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 12–16 January 2016; pp. 381–384. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. Parallel Distrib. Process. 1986, 1, 318–363. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Kiernan, M.C.; Vucic, S.; Cheah, B.C.; Turner, M.R.; Eisen, A.; Hardiman, O.; Burrell, J.R.; Zoing, M.C. Amyotrophic lateral sclerosis. Lancet 2011, 377, 942–955. [Google Scholar] [CrossRef] [Green Version]
- Xie, Z.; Schwartz, O.; Prasad, A. Decoding of finger trajectory from ecog using deep learning. J. Neural Eng. 2017, 15, 11. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Pfurtscheller, G.; Müller, G.R.; Pfurtscheller, J.; Gerner, H.J.; Rupp, R. ‘Thought’—Control of functional electrical stimulation to restore hand grasp in a patient with tetraplegia. Neurosci. Lett. 2003, 351, 33–36. [Google Scholar] [CrossRef]
- Guerra-Casanova, J.; Sánchez-Ávila, C.; de Santos-Sierra, A.; Bailador, G. A robustness verification system for mobile phone authentication based on gestures using linear discriminant analysis. In Proceedings of the 2011 Third World Congress on Nature and Biologically Inspired Computing, Salamanca, Spain, 19–21 October 2011; pp. 157–162. [Google Scholar]
- Guerra-Casanova, J.; Ávila, C.S.; Bailador, G.; de-Santos-Sierra, A. Time series distances measures to analyze in-air signatures to authenticate users on mobile phones. In Proceedings of the 2011 Carnahan Conference on Security Technology, Barcelona, Spain, 18–21 October 2011; pp. 1–7. [Google Scholar]
- Khoh, W.H.; Pang, Y.H.; Teoh, A.B. In-air hand gesture signature recognition system based on 3-dimensional imagery. Multimed. Tools Appl. 2019, 78, 6913–6937. [Google Scholar] [CrossRef]
- Wang, S.; Yuan, J.; Wen, J. Adaptive phone orientation method for continuous authentication based on mobile motion sensors. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1623–1627. [Google Scholar]
- Buriro, A.; Crispo, B.; Delfrari, F.; Wrona, K. Hold and sign: A novel behavioral biometrics for smartphone user authentication. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; pp. 276–285. [Google Scholar]
- Primo, A.; Phoha, V.V.; Kumar, R.; Serwadda, A. Context-aware active authentication using smartphone accelerometer measurements. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 98–105. [Google Scholar]
- Saleem, M.; Kovari, B. Survey of signature verification databases. In Proceedings of the MultiScience—XXXIII microCAD International Multidisciplinary Scientific Conference, Miskolc, Hungary, 23–24 May 2019. [Google Scholar]
- Bailador, G.; Sanchez-Avila, C.; Guerra-Casanova, J.; de Santos Sierra, A. Analysis of pattern recognition techniques for in-air signature biometrics. Pattern Recognit. 2011, 44, 2468–2478. [Google Scholar] [CrossRef] [Green Version]
- Yeo, K.; Yin, O.S.; Han, P.Y.; Kwee, W.K. Real time mobile application of in-air signature with fast dynamic time warping (fastdtw). In Proceedings of the 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–21 October 2015; pp. 315–320. [Google Scholar]
- Muscillo, R.; Conforto, S.; Schmid, M.; Caselli, P.; D’Alessio, T. Classification of motor activities through derivative dynamic time warping applied on accelerometer data. In Proceedings of the Conference proceedings: Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007; Volume 2007, pp. 4930–4933. [Google Scholar]
- Mantena, G.; Achanta, S.; Prahallad, K. Query-by-example spoken term detection using frequency domain linear prediction and nonsegmental dynamic time warping. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 946–955. [Google Scholar] [CrossRef]
- Furlanello, C.; Merler, S.; Jurman, G. Combining feature selection and dtw for time-varying functional genomics. IEEE Trans. Signal Process. 2006, 54, 2436–2443. [Google Scholar] [CrossRef]
- Müller, M. Information Retrieval for Music and Motion; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Schaller, M.; Gonnet, P.; Draper, P.W.; Chalk, A.B.; Bower, R.G.; Willis, J.; Hausammann, L. SWIFT: SPH with Inter-Dependent Fine-Grained Tasking; Astrophysics Source Code Library: Online, 2018; ascl:1805.020. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Diederik, K.; Jimmy, B. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef] [Green Version]
- McMahan, B. Follow-the-regularized-leader and mirror descent: Equivalence theorems and l1 regularization. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 525–533. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–4. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, Atlanta, GA, USA, 17–19 June 2013; Dasgupta, S., McAllester, D., Eds.; PMLR: Cambridge, MA, USA, 2013; Volume 28, pp. 1139–1147. [Google Scholar]
- Fukushima, K. Cognitron: A self-organizing multilayered neural network. Biol. Cybern. 1975, 20, 121–136. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. 2015. Available online: https://arxiv.org/abs/1506.01186 (accessed on 10 February 2023).
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A systematic review on imbalanced data challenges in machine learning: Applications and solutions. ACM Comput. Surv. (CSUR) 2019, 52, 79. [Google Scholar] [CrossRef] [Green Version]
- Chollet, François and others; Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 10 February 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Cambridge, MA, USA, 2019; pp. 8024–8035. Available online: http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf (accessed on 10 February 2023).
- Cui, K.; Zhan, Z.; Pan, C. Applying radam method to improve treatment of convolutional neural network on banknote identification. In Proceedings of the 2020 International Conference on Computer Engineering and Application (ICCEA), Guangzhou, China, 18–20 March 2020; pp. 468–476. [Google Scholar]
- Ariff, N.A.M.; Ismail, A.R. Study of adam and adamax optimizers on alexnet architecture for voice biometric authentication system. In Proceedings of the 2023 17th International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Republic of Korea, 3–5 January 2023; pp. 1–4. [Google Scholar]
- Lorencin, I. Urinary bladder cancer diagnosis using customized vgg-16 architectures. Sarcoma 2022, 10, 11. [Google Scholar]
- Yang, J.; Bagavathiannan, M.; Wang, Y.; Chen, Y.; Yu, J. A comparative evaluation of convolutional neural networks, training image sizes, and deep learning optimizers for weed detection in alfalfa. Weed Technol. 2022, 36, 512–522. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep transformer models for time series forecasting: The influenza prevalence case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Wichard, J.D. Classification of Ford Motor Data. Computer Science. 2008. Available online: https://www.semanticscholar.org/paper/Classification-of-Ford-Motor-Data-Wichard/7a7b1674a126db6836337cf9164c0522465f76fc#related-papers (accessed on 10 February 2023).
- Wu, S.; Xiao, X.; Ding, Q.; Zhao, P.; Wei, Y.; Huang, J. Adversarial sparse transformer for time series forecasting. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Cambridge, MA, USA, 2020; Volume 33, pp. 17105–17115. [Google Scholar]
- Cai, L.; Janowicz, K.; Mai, G.; Yan, B.; Zhu, R. Traffic transformer: Capturing the continuity and periodicity of time series for traffic forecasting. Trans. GIS 2020, 24, 736–755. [Google Scholar] [CrossRef]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12104–12113. [Google Scholar]
- Sasipriyaa, N.; Natesan, P.; Mohana, R.; Gothai, E.; Venu, K.; Mohanapriya, S. Design and simulation of handwritten detection via generative adversarial networks and convolutional neural network. Mater. Today Proc. 2021, 47, 6097–6100. Available online: https://www.sciencedirect.com/science/article/pii/S2214785321036002 (accessed on 10 February 2023). [CrossRef]
- Ghosh, S.; Ghosh, S.; Kumar, P.; Scheme, E.; Roy, P.P. A novel spatio-temporal siamese network for 3d signature recognition. Pattern Recognit. Lett. 2021, 144, 13–20. [Google Scholar] [CrossRef]
- Upton, E.; Halfacree, G. Raspberry Pi User Guide; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Schuemie, M.J.; Straaten, P.V.D.; Krijn, M.; Van Der Mast, C.A. Research on presence in virtual reality: A survey. Cyberpsychol. Behav. 2001, 4, 183–201. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
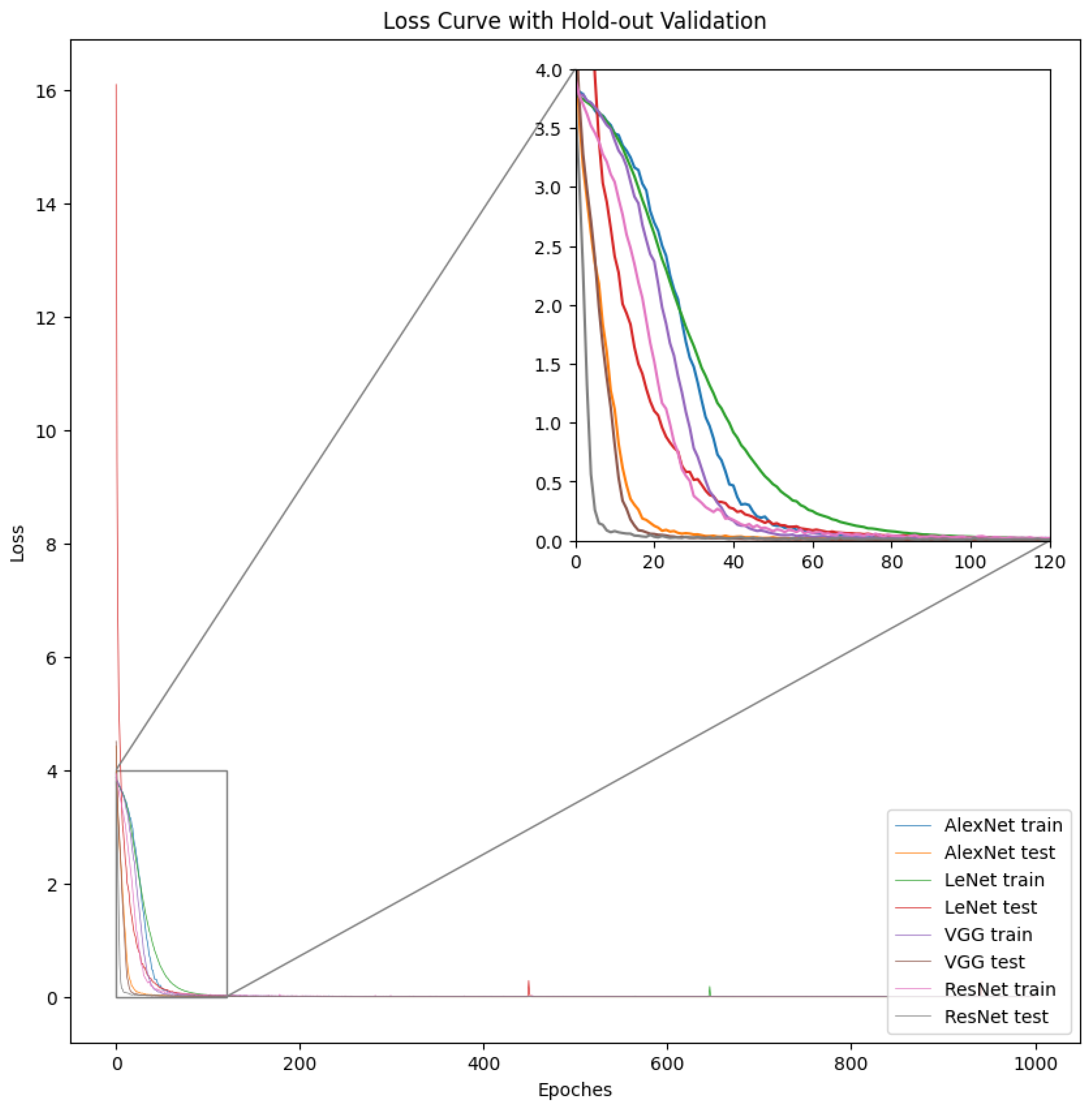{kind=link}
| Computer Configurations | |
|---|---|
| Item | Property |
| Processor | 12th Gen Intel(R) Core(TM) i7-12700KF 3.61 GHz |
| Installed RAM | 32.0 GB (31.8 GB usable) |
| System type | 64-bit operating system, x64-based processor |
| GPU | NVIDIA GeForce RTX 3080 |
| Apple Watch Series 6 Configuration | |
|---|---|
| Properties | Specifications |
| Chip | S6 SiP with 64-bit dual-core processor |
| W3 (Apple wireless chip) | |
| U1 chip (Ultra Wideband) | |
| Connectivity | LTE and UMTS |
| GPS + Cellular models | |
| Wi-Fi 802.11b/g/n 2.4 GHz and 5 GHz | |
| Sensor | Accelerometer (up to 32 g-forces with fall detection) |
| Gyroscope | |
| Smartwatch Data Format | ||||||||
|---|---|---|---|---|---|---|---|---|
| WatchGyroX | WatchGyroY | WatchGyroZ | WatchAccX | WatchAccY | WatchAccZ | WatchAttX | WatchAttY | WatchAttZ |
| 0.02570195 | −0.03224608 | −0.0120639 | −0.01228451 | −0.00830266 | 0.00186165 | 0.21137402 | 0.21104763 | −0.75536253 |
| 0.02712557 | −0.03940424 | −0.0088675 | −0.00624303 | −0.00330171 | 0.00035724 | 0.2120575 | 0.21096044 | −0.75540958 |
| 0.03478016 | −0.0445323 | −0.0054437 | −0.00450777 | 0.00784102 | −0.00614287 | 0.21283413 | 0.21098173 | −0.75545861 |
| 0.05405451 | −0.04379743 | −0.01255126 | −0.00808688 | 0.01724837 | −0.0044408 | 0.21344206 | 0.21110055 | −0.75555888 |
| … | … | … | … | … | … | … | … | … |
| Model Performance with Respect to Learning Rate | |||||
|---|---|---|---|---|---|
| Cross-Entropy & SDG | Learning Rate | ||||
| Model | Criteria | ||||
| LeNet | Train Loss | ||||
| Train Score (%) | 98.5995 | 98.0359 | 87.6746 | 24.3396 | |
| Test Loss | |||||
| Test Score (%) | 99.4086 | 99.0645 | 98.8136 | 46.2164 | |
| AlexNet | Train Loss | Inf | |||
| Train Score (%) | 2.2718 | 84.3845 | 98.1127 | 97.8732 | |
| Test Loss | Inf | ||||
| Test Score (%) | 2.2727 | 81.7914 | 97.6605 | 99.2946 | |
| VGG | Train Loss | Inf | |||
| Train Score (%) | 2.2727 | 87.4872 | 98.7905 | 98.1264 | |
| Test Loss | Inf | ||||
| Test Score (%) | 2.2727 | 93.5286 | 98.1041 | 99.3759 | |
| ResNet | Train Loss | ||||
| Train Score (%) | 84.8318 | 96.0959 | 99.4000 | 98.9268 | |
| Test Loss | |||||
| Test Score (%) | 83.6241 | 98.9127 | 99.4386 | 99.7723 | |
| Transformer (Baseline) | Train Loss | ||||
| Train Score (%) | 0.0356 | 0.9609 | 0.5872 | 0.1103 | |
| Test Loss | |||||
| Test Score (%) | 0.0000 | 0.0282 | 0.0704 | 0.0423 | |
| Model Performance with Respect to Optimizers | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| & Cross-Entropy | Optimizers | ||||||||||
| Model | Criteria | Adadelta | Adagrad | Adam | AdamW | Adamax | ASGD/Ftrl | NAdam | RAdam | RMSprop | SGD |
| LeNet | Train Loss | ||||||||||
| Train Score (%) | 5.0468 | 28.7778 | 98.1396 | 97.9845 | 93.0550 | 12.0159 | 98.0236 | 97.0636 | 97.9309 | 24.3396 | |
| Test Loss | |||||||||||
| Test Score (%) | 3.8445 | 12.1927 | 98.4664 | 98.4068 | 92.9855 | 34.8241 | 98.1705 | 98.4814 | 96.4250 | 46.2164 | |
| AlexNet | Train Loss | ||||||||||
| Train Score (%) | 55.5791 | 98.0123 | 97.7586 | 97.7295 | 98.8518 | 89.1786 | 97.8955 | 97.4246 | 97.4186 | 97.8732 | |
| Test Loss | |||||||||||
| Test Score (%) | 70.4927 | 98.2100 | 98.5827 | 98.7150 | 99.4232 | 97.4268 | 98.5796 | 98.5955 | 98.1386 | 99.2946 | |
| VGG | Train Loss | ||||||||||
| Train Score (%) | 81.4840 | 98.8759 | 97.8546 | 98.1414 | 99.0646 | 94.1918 | 98.2309 | 97.9536 | 97.8327 | 98.1264 | |
| Test Loss | |||||||||||
| Test Score (%) | 88.2750 | 99.4282 | 99.0191 | 99.1255 | 99.5205 | 98.3523 | 99.1636 | 99.1818 | 98.4050 | 99.3759 | |
| ResNet | Train Loss | ||||||||||
| Train Score (%) | 85.6623 | 99.6332 | 99.1150 | 99.0900 | 99.7636 | 97.6668 | 99.1091 | 98.9477 | 99.0100 | 98.9268 | |
| Test Loss | |||||||||||
| Test Score (%) | 96.3550 | 99.8514 | 99.6814 | 99.6777 | 99.8427 | 99.5318 | 99.6905 | 99.6505 | 99.6600 | 99.7723 | |
| Transformer (Baseline) | Train Loss | ||||||||||
| Train Score (%) | 0.0463 | 0.9288 | 0.0356 | 0.0249 | 0.8683 | 0.7331 | 0.6228 | 0.7758 | 0.5089 | 0.9609 | |
| Test Loss | |||||||||||
| Test Score (%) | 0.0000 | 0.08451 | 0.0000 | 0.0000 | 0.1268 | 0.1127 | 0.0704 | 0.0563 | 0.0704 | 0.0282 | |
| Final Configuration for Each Model | |||||
|---|---|---|---|---|---|
| LeNet | AlexNet | VGG | ResNet | Transformer (Baseline) | |
| Learning Rate | |||||
| Optimizer | SGD | Adamax | Adamax | Adagrad | Adamax |
| Test Score (%) | 99.4086 | 99.4232 | 99.5205 | 99.8514 | 0.1268 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Sato, H. Smartwatch In-Air Signature Time Sequence Three-Dimensional Static Restoration Classification Based on Multiple Convolutional Neural Networks. Appl. Sci. 2023, 13, 3958. https://doi.org/10.3390/app13063958
Guo Y, Sato H. Smartwatch In-Air Signature Time Sequence Three-Dimensional Static Restoration Classification Based on Multiple Convolutional Neural Networks. Applied Sciences. 2023; 13(6):3958. https://doi.org/10.3390/app13063958
Chicago/Turabian StyleGuo, Yuheng, and Hiroyuki Sato. 2023. "Smartwatch In-Air Signature Time Sequence Three-Dimensional Static Restoration Classification Based on Multiple Convolutional Neural Networks" Applied Sciences 13, no. 6: 3958. https://doi.org/10.3390/app13063958