

Transpilers: A Systematic Mapping Review of Their Usage in Research and Industry

Abstract
:1. Introduction
1.1. Background
1.2. Transpiler Disambiguation
1.3. Objectives
- Identify the areas, approaches, or specific topics where transpilers have been used the most;
- Determine the use of transpilers in the construction of business applications and specifically regarding their use in front-end and back-end frameworks;
- Determine the use of transpilers in the framework of the approach to patterns and designs of software architecture.
1.4. Research Questions
- RQ1: What are the descriptive statistics of the publications among selected articles?
- RQ2: In which scenarios are transpilers most used?
- RQ3: In which kind of industry applications are transpilers commonly used?
- RQ4: Which programming languages and technologies are mainly related to transpilers?
- RQ5: Which are the usages of transpilers in the scope of the back-end of a transactional application?
1.5. Content Organization
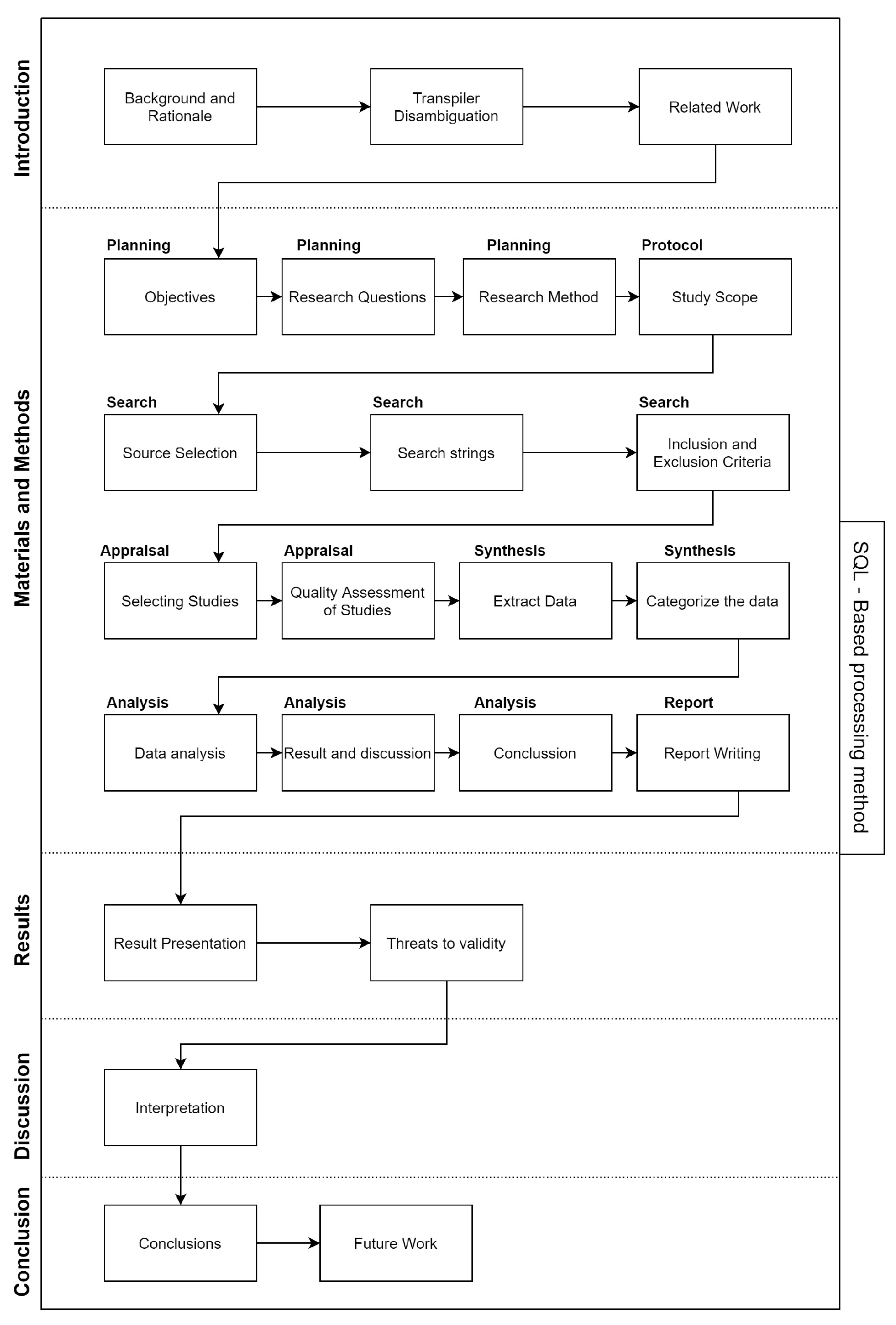
2. Methods and Execution
2.1. Related Work
- Scopus: 7 articles;
- IEEE Xplore: 1 article;
- ACM: 6 articles;
- SpringerLink: 17 articles.
- A Survey of Performance Tuning Techniques and Tools for Parallel Applications: [13]In this article, it is possible to see a survey related to tuning techniques for parallel applications. It is possible to see that one of the uses of transpilers is indeed in optimization for parallelization of source code. However, its objective has a specific approach to this topic, when the present article is focused on a mapping of the general scope of the use of transpilers.
- Evolution of Artificial Intelligence Programming Languages—a Systematic Literature Review: [14]In this article, the author proposes a literature review focused on the programming languages used for artificial intelligence (AI). Its objective has a different approach to the objective of the present study.
- Systematic mapping study of architectural trends in Latin America: [15]This article proposes a literature review focused on the uses of software architecture that have been proposed in Latin America. Although the use of transpilers is an element that is part of several software architecture proposals (Example: [16]), the present study has the objective of identifying the uses of transpilers, specifically, in any of their uses and without a defined geographical limitation.
- A systematic review on Transpiler usage for Transaction-Oriented Applications: [17]This article proposes a review of the specific literature for the use of transpilers in transaction-oriented applications. This article seeks to cover the use of transpilers in all its fields of use in recent years.
- Negative Perceptions About the Applicability of Source-to-Source Compilers in HPC: A Literature Review: [18]This article presents a study on the negative impacts of using a transpiler for HPC (high-performance computing). The focus of this article is specific to the stated objective, while the current article focuses on a wide coverage review of the use of transpilers in different topics.
- Using meta-heuristics and machine learning for software optimization of parallel computing systems: a systematic literature review: [19]This article presents a literature review focused on methods to optimize software in parallel computing systems. Although one of the techniques to optimize parallel computing is the use of transpilers, it does not focus on other uses of this technology.
2.2. Planning
Research Method
2.3. Protocol
Study Scope
2.4. Search
2.4.1. Source Selection
- Recognized or highly cited scientific databases or search systems
- Databases that are commonly used for computer science publications
- Consider a curated catalog of information, not a crawler-based search engine
- The capacity to include advanced search criteria to fit the scope of the current study
- The use of principal databases and also supplementary specialized databases
- Scopus (Principal)
- ACM Digital Library (Principal)
- Science Direct (Principal)
- IEEE Xplore (Supplementary)
2.4.2. Search Strings
2.4.3. Inclusion and Exclusion Criteria
2.5. Appraisal
2.5.1. Selecting Studies
2.5.2. Quality Assessments of Studies
2.6. Synthesis
2.6.1. Extract Data
2.6.2. Categorize the Data
3. Results
4. Industry Applications
- Haxe cross-compiler, which can transform Haxe language to several target languages (https://haxe.org/ (accessed on 11 January 2023))
- Typescript, which can transform the typescript language to javascript (https://www.typescriptlang.org/ (accessed on 11 January 2023))
- Dart is a client-optimized programming language which can compile for several platforms such as Android, iOS, Windows, and linux, and can also generate the code for Javascript. (https://dart.dev/overview (accessed on 11 January 2023))
- React Native is a cross-platform framework that uses the javascript language as a base, and can generate native code for several platforms such as Android, iOS, and the web. (https://reactnative.dev/ (accessed on 11 January 2023))
- Angular is a web front-end framework based on Typescript to build small to enterprise-level applications. (https://angular.io/ (accessed on 11 January 2023))
- The .Net framework proposes the common intermediate language (CIL), which is a human-readable code. When compatible programming language such as C#, Visual Basic .Net, F#, and others perform the compiling process, they really are performing a transpilation process to CIL. (https://dev.to/kcrnac/net-execution-process-explained-c-1b7a (accessed on 11 January 2023))
- Sharpkit is a tool to transform C# to Javascript (https://sharpkit.github.io/ (accessed on 11 January 2023))
- JSIL is a tool to transform CIL to Javascript (http://jsil.org/ (accessed on 11 January 2023))
- JSSweet is a tool that transpiles Java to Javascript (https://www.jsweet.org/ (accessed on 11 January 2023))
- Bck2Brwsr is a tool capable to transform Java Bytecode back to Javascript (http://wiki.apidesign.org/wiki/Bck2Brwsr (accessed on 11 January 2023))
- Cross-compilation for image preparation for Docker (https://www.docker.com/blog/faster-multi-platform-builds-dockerfile-cross-compilation-guide/ (accessed on 11 January 2023))
- Cross-compilation using the Go programming language (https://opensource.com/article/21/1/go-cross-compiling (accessed on 11 January 2023))
- FizzedWL is a tool to transform C# to Haxe (https://github.com/FizzerWL/Cs2hx (accessed on 11 January 2023))
- CoffeeScript is a language that transpile to javascript (https://coffeescript.org/ (accessed on 11 January 2023))
- SASS is a language that can transpile to CSS (https://sass-lang.com/ (accessed on 11 January 2023))
- The WORA definition (write-once run anywhere) proposed by Sun Microsystems (https://www.techtarget.com/whatis/definition/write-once-run-anywhere-WORA (accessed on 11 January 2023))
- Facebook AI Research’ Transcoder (https://arxiv.org/pdf/2006.03511.pdf (accessed on 11 January 2023))
5. The SQL-Based Processing Method
5.1. Search Execution
5.2. Download Search Result (BibTeX Format)
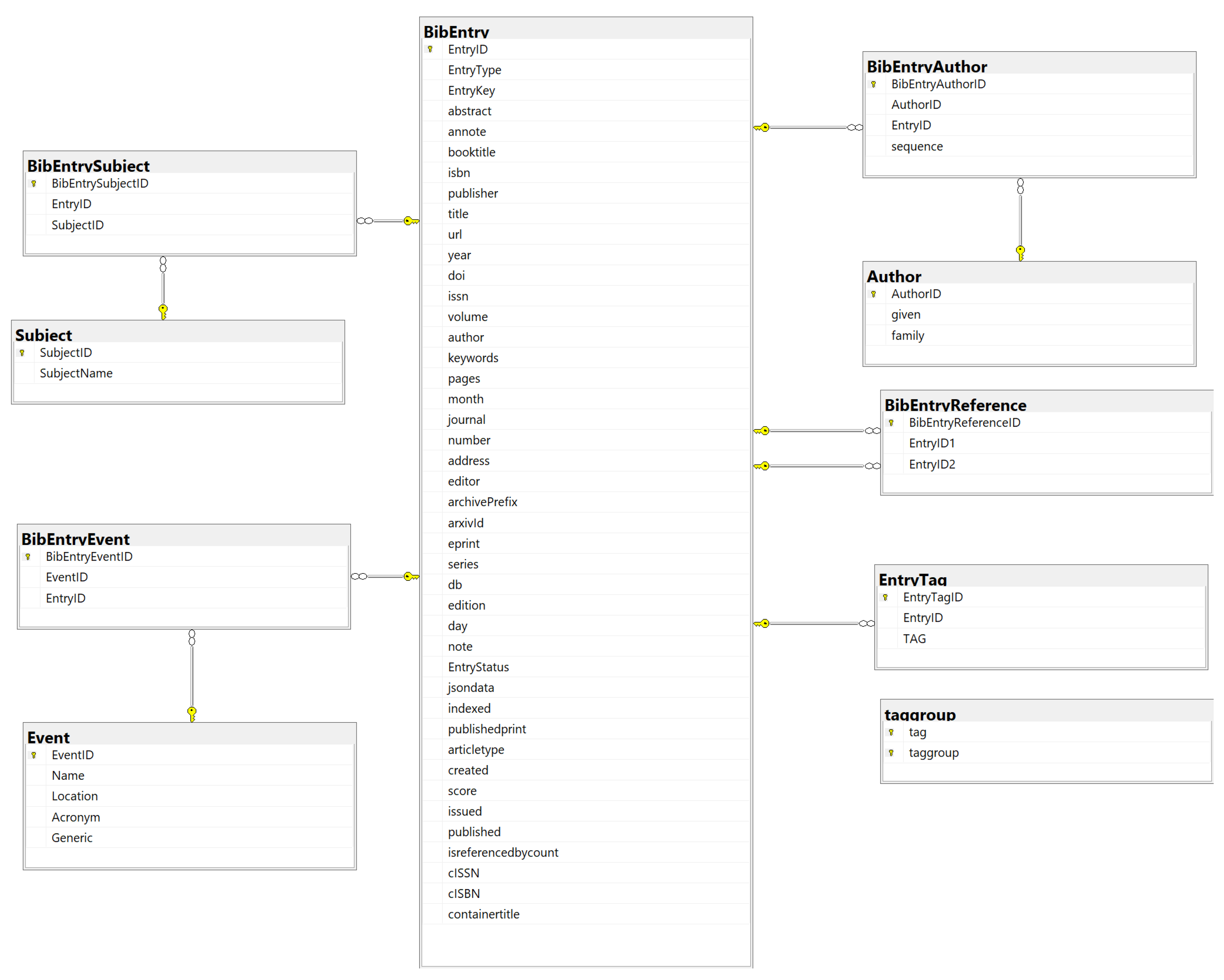
5.3. Load Data into a SQL Database
5.4. Data Enrichment
- 1.
- DOI to BibTeX Converter (https://www.bibtex.com/c/doi-to-bibtex-converter (accessed on 22 December 2022))The objective is to obtain a different source of the article’s information and add it to the existing one. This is performed by using a query in the SQL database for obtaining the DOI column of all loaded data to a plain text file. Then those are loaded to the tool website and finally obtain a consolidated BibTeX file. The enrichment process is done by using a program that reads the generated BibTeX file, searching if the information obtained can be used to fill the blank fields.
- 2.
- CrossRef REST API (https://api.crossref.org/swagger-ui/index.html (accessed on 22 December 2022))Crossref is the official registration agency for managing the digital object identifier (DOI). They have published a Crossref Unified Resource API, in which it is possible to query articles’ metadata using REST protocol and JSON serialization (there are other formats available). They receive the DOI number as a parameter and return detailed information.For this, a program was written which iterates one by one all the articles registered in previous steps, so to obtain detailed information on each. The algorithm saves the information for the empty fields and for fields that seem to be more confident compared with previous ones.
- 3.
- Mendeley update reference toolMendeley is a references manager developed by Elsevier. This tool helps to manage citations and bibliographies, mainly for research works. Version Mendeley Desktop 1.13 (https://blog.mendeley.com/tag/new-release/ (accessed on 22 December 2022)) added the option called “Update Details”, which queries the Mendeley Catalog, searching the last information about an article. It is common to fill only the field DOI in the form and using this tool, Mendeley queries the other fields from Mendeley central library, bringing complementary information.For this case, it is generated a BibTeX file from the SQL database which contains only the DOI field filled. Then the file is loaded into Mendeley, and then the “Update Details” option is used to query the data for all the articles considered. Finally, it is needed to export information from Mendeley in BibTeX format. This file is read from a program that compares and fills the information to the empty fields.
5.5. Acceptance Criteria
- Articles without abstract;
- Articles without a DOI number;
- Articles which are duplicated between databases compared by DOI;
- Articles which are duplicated between databases compared by title;
- Articles which does not have complete information;
- Articles which are published in languages different from English.
5.6. Article Tagging
- 1.
- Base ListThis process consists of the author, based on a quick exploratory review, making a preliminary analysis of the specialties, sub-areas, and variants that are published in relation to the root topic, and identifying the possible keywords that would specifically segment them. A base list is created.
- 2.
- Refinement 1 A word cloud is made on the titles or abstracts of the articles, in which the connectors, articles, adverbs, or interjections that do not have the relevance of individual meaning are removed. The graph or the frequency table is analyzed to take the most recurring words. The found ones are added to the list.
- 3.
- Refinement 2 Collateral terms referring to techniques, methods, platforms, or technologies that may be slightly related to the root topic are identified. Those identified are added to the list.
- 4.
- Refinement 3 Articles from other research areas that use a substitute, complementary, or opposite ideas in relation to the root topic are identified. From them, the main terms that determine their variants are identified. Those terms are added to the list.
- 5.
- Refinement 4 The titles and quick review of the abstracts of the articles chosen for the study are reviewed, in search of terms that identify an application, case, or approach. The found terms are added to the list.
- 6.
- CleaningRepeated terms are removed. Terms that are based on very short acronyms, where a textual search could match with a substring within a word, are removed. The terms used in the main search strings of the study are incorporated.
- 7.
- Tag relationship A procedure is executed in the database through SQL queries, in which the list of identified terms is stored in a temporary table and compared with the texts collected from the articles that are part of the study. The information is searched both in the title and in the abstract, by means of a textual search of each term within the text. An article can have one or several related tags, which are recorded in the EntryTag relationship table.
5.7. Concept Identification
5.8. Reports Generation
- Distribution of articles by years;
- Distribution of articles by type of article;
- Distribution of articles by journal or conference of origin;
- Distribution of articles by scientific databases of origin;
- Identification of the articles most referred to by other articles;
- Identification of the most used journals on the subject;
- Identification of the most used conferences on the subject;
- Distribution of the most matching journal topics;
- List of classification terms;
- Comprehensive mapping chart.
5.9. Graphs Generation
- Pie chart, bar chart, or timeline for distribution of articles by years;
- Pie chart or bar chart for distribution by type of article;
- Pie chart or bar chart for distribution by type of publication (journal or conference);
- Pie chart or bar chart for distribution by scientific databases of origin;
- Timeline of posts on the topic with trend line;
- Tree-Map for visualization in areas of the publication journals;
- Pie chart or bar chart to represent the frequency of use of classification terms or classification groups;
- Correlation graph between variables and determination of correlation indicators.
5.10. Result Interpretation
6. Discussion
6.1. The Conclusion Process
6.2. Report-Writing Process
6.3. Discussion about Research Questions
- RQ1: What are the descriptive statistics of the publications among selected articles?As seen in the data analysis section, it has been possible to make a broad statistical description of the studies selected for this study. From this it is possible to highlight the following:
- –
- A total of 683 articles were selected, considered as the primary studies or the ones that met the search chains and applicable criteria.
- –
- The terms most found in the analysis, which refer to a particular research area, correspond to the following: performance, parallel, architecture, optimization, software, hardware, development, memory, GPU, and test.
- –
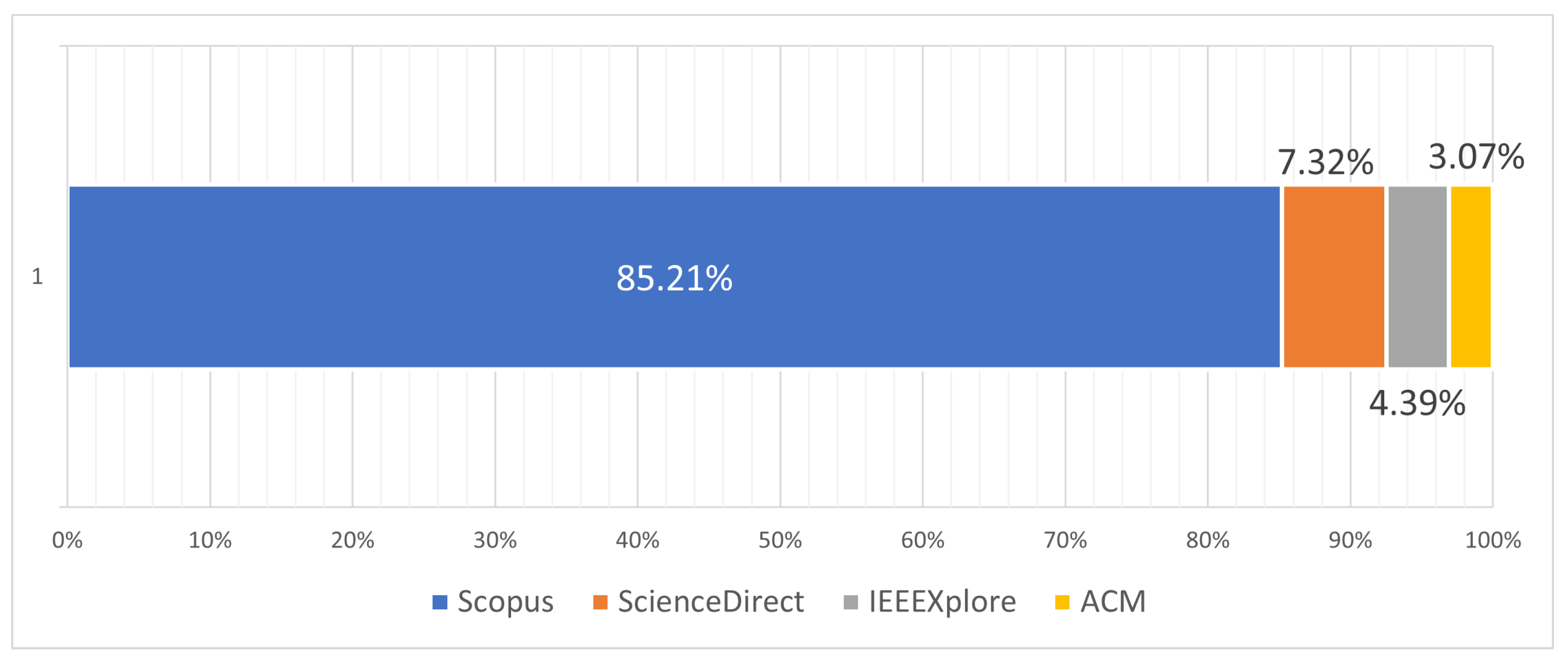
- As mentioned in Figure 5, most of the articles come from the Scopus database, after removing duplicates.
- –
- In Table 6 it is possible to see the articles that refer to transpilers, which have the largest number of references.
- –
- Figure 6 and the Equation (1) show that the trend of publications regarding transpilers has remained stable. Through a linear regression, it has been possible to see that the trend is slightly downward, which indicates that it is expected that there will be publications on the subject in a stable manner.
- –
- According to Figure 7, it has been possible to see that practically half of the selected articles have been published in scientific journals and the other half in scientific conferences.
- –
- In Table 8 it is possible to see the journals most used for publications related to transpilers.
- –
- In Table 9 it is possible to see the conferences most used for publications related to transpilers.
- –
- –
- In Table 13 it is possible to see the relationship of greater co-occurrence of terms in the same articles, allowing the determination of the most common research areas.
- –
- In Table 15, it is possible to see the programming languages most used in relation to transpilers.
- –
- Table 16 shows the most commonly used transpiler synonyms in scientific articles.
- RQ2: In which scenarios transpilers are most used?Referring to Table 14, the major research areas in relation to the use of transpilers can be evidenced. From this it has been possible to see that the scenarios where transpilers are mostly used are the following:
- –
- To improve performance in algorithms related to high-performance computing (HPC).
- –
- For preparation for parallel execution, mainly in relation to the transformation of sequential methods to algorithms prepared to take advantage of the GPU, CUDA cores, OpenMP, and others.
- –
- For the creation of automatic transformations between programming languages commonly used in the industry.
- –
- As preparation of methods to support different processor architectures.
- –
- As part of the internal procedures of a compiler and its execution platforms.
- –
- As an element to facilitate the processes of diagnosis and execution of software testing exercises.
- –
- To improve graphic processing procedures.
- –
- To generate compatibility with embedded systems so that the common code can be transferred to the specific languages of the specific circuits.
- –
- As part of the source code generation architecture.
- –
- As a constituent element in artificial intelligence methods.
- –
- As a base for the transformation of code for preparation of execution of the front-end of applications.
- –
- As part of the compatibility processes with the different mobile platforms.
- –
- As a method to transform sentences between parameterization languages, configuration or platform of network devices.
- –
- As a means to transfer, transform, or reuse mathematical models.
- –
- As a compatibility tool for the different platforms for the creation and execution of digital games.
- RQ3: In which kind of industry applications transpilers are commonly used?As it is possible to see in Section 4 of this document, the applications in the industry are very varied and of diverse uses. Among the most outstanding in recent times, the following are mainly included:
- –
- For the direct transformation from one language to another, as a code reuse tool or migration strategy for legacy platforms.
- –
- As a base language for the operation of a front-end framework, for compatibility with end-user and mobile platforms, for transformations from web language to native code of the platforms.
- –
- To generate language extensions, mainly as a superset of Javascript.
- –
- For source code refactoring processes.
- RQ4: Which programming languages and technologies are mainly related to transpilers?In Table 15 it is possible to see the programming languages that are mostly related to transpilers. In this context, it is possible to see that the relationship with the C family of languages stands out. Below are Java language and Javascript as the most-referred languages.
- RQ5: Which are the usages of transpilers in the scope of the back-end of a transactional application?The use of transpilers has been revised for the specific area of transactional applications. The front-end has had the greatest emphasis in this type of study, through the proposal of frameworks that transform web code into native mobile code or to have languages with greater capacities and expressiveness, and in the end, transform them into basic languages of execution. We could not find a framework that involves a transpiler in the back-end component.
- Regarding the proposed SQL-Based processing method, This method is a new approach to the qualitative processing of literature reviews. There are some tools that use similar conceptions of processing, for example, the Autocoding tool of Atlas.ti (https://atlasti.com/research-hub/auto-coding-and-smart-coding-in-atlas-ti-web (accessed on 22 December 2022)). The difference is that the proposed one uses commonly accessible tools for researchers and its capability of making ad hoc queries to deep inside the retrieved information.
6.4. Threats to Validity
6.4.1. Internal Validity
- The SQL-based processing method proposed is a new way to process literature reviews using a qualitative approach. The conception of this method allows for finding research areas based on tags found in the text. This raises the problem that a term can be used in different contexts and ways. The validity of this method is based on the fact that, although it is not precise, the greater the appearance of certain terms in the articles, the better it will allow for finding tendencies and similarities and be certain of those that are mostly repeated, which provides a possible identification of a common theme and dialectic between researchers in the area. The idea is that by statistical tendency and the law of large numbers, it is possible to infer certain research areas that have multiple terms in common. The level of detail is sacrificed in exchange for achieving a broad-spectrum mapping, which, when having to review a large number of articles, is useful to later move on to a detailed review if needed.
- The selection of the scientific databases could not involve any important one that had information of focus in the computer sciences.
- Although the corresponding mitigation was carried out through a sequential and strict exercise, there could be possible differences and biases incorporated at the time of the creation of the search strings and their execution in the scientific databases.
- Although the corresponding mitigation was made through data processing techniques, there could be differences and biases regarding the selection of classification terms. Others might have been missing that the method used might not have been considered, but that may have been important.
6.4.2. External Validity
7. Conclusions
7.1. Study Conclusions
7.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hirzel, M.; Klaeren, H. Code Coverage for Any Kind of Test in Any Kind of Transcompiled Cross-platform Applications. In Proceedings of the 2nd International Workshop on User Interface Test Automation, Saarbrucken, Germany, 21 July 2016; ACM: New York, NY, USA, 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Chaber, P.; Lawrynczuk, M. Effectiveness of PID and DMC control algorithms automatic code generation for microcontrollers: Application to a thermal process. In Proceedings of the 2016 3rd Conference on Control and Fault-Tolerant Systems (SysTol), Barcelona, Spain, 7–9 September 2016; pp. 618–623. [Google Scholar] [CrossRef]
- Intel. MCS-86 Assembly Language Converter Operating Instructions for ISIS-II Users. Technical Report. 1978. Available online: http://www.bitsavers.org/pdf/intel/ISIS_II/9800642A_MCS-86_Assembly_Language_Converter_Operating_Instructions_for_ISIS-II_Users_Mar79.pdf (accessed on 5 January 2023).
- Research, D. XLT86 8080 to 8086 Assembly Language Translator, User’s Guide. Technical Report. 1981. Available online: http://www.s100computers.com/Software%20Folder/Assembler%20Collection/Digital%20Research%20XLT86%20Manual.pdf (accessed on 5 January 2023).
- Baxter, I.; Pidgeon, C.; Mehlich, M. DMS/spl reg/: Program transformations for practical scalable software evolution. In Proceedings of the 26th International Conference on Software Engineering, Edinburgh, UK, 28 May 2004; pp. 625–634. [Google Scholar] [CrossRef]
- Marcelino, M.; Leitão, A.M. Transpiling Python to Julia using PyJL. In Proceedings of the The 15th European Lisp Symposium (ELS’22), Porto, Portugal, 21–22 March 2022. [Google Scholar] [CrossRef]
- Ling, M.; Yu, Y.; Wu, H.; Wang, Y.; Cordy, J.R.; Hassan, A.E. In Rust We Trust—A Transpiler from Unsafe C to Safer Rust. In Proceedings of the 44th ACM/IEEE International Conference on Software Engineering: Companion, ICSE-Companion 2022, Pittsburgh, PA, USA, 22–27 May 2022; pp. 354–355. [Google Scholar] [CrossRef]
- Leopoldseder, D.; Stadler, L.; Wimmer, C.; Mössenböck, H. Java-to-JavaScript Translation via Structured Control Flow Reconstruction of Compiler IR. In Proceedings of the 11th Symposium on Dynamic Languages, Pittsburgh, PA, USA, 27 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 91–103. [Google Scholar] [CrossRef]
- Wang, C.K.; Chen, P.S. Automatic scoping of task clauses for the OpenMP tasking model. J. Supercomput. 2015, 71, 808–823. [Google Scholar] [CrossRef]
- Kim, D.; Hong, J.E.; Yoon, I.; Lee, S.H. Code refactoring techniques for reducing energy consumption in embedded computing environment. Cluster Comput. 2016, 21, 1079–1095. [Google Scholar] [CrossRef]
- Bierman, G.; Abadi, M.; Torgersen, M. Understanding TypeScript. In Proceedings of the ECOOP 2014—Object-Oriented Programming; Jones, R., Ed.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 257–281. [Google Scholar]
- Grant, M.J.; Booth, A. A typology of reviews: An analysis of 14 review types and associated methodologies. Health Inf. Libr. J. 2009, 26, 91–108. [Google Scholar] [CrossRef]
- Mustafa, D. A Survey of Performance Tuning Techniques and Tools for Parallel Applications. IEEE Access 2022, 10, 15036–15055. [Google Scholar] [CrossRef]
- Adetiba, E.; Adeyemi-Kayode, T.M.; Akinrinmade, A.A.; Moninuola, F.S.; Akintade, O.O.; Badejo, J.A.; Obiyemi, O.O.; Thakur, S.; Abayomi, A. Evolution of Artificial Intelligence Programming Languages—A Systematic Literature Review. J. Comput. Sci. 2021, 17, 1157–1171. [Google Scholar] [CrossRef]
- Alomoto, D.; Carrera, A.; Navas, G. Systematic mapping study of architectural trends in Latin America. Commun. Comput. Inf. Sci. 2019, 895, 312–326. [Google Scholar] [CrossRef]
- Bastidas, A.F.; Pérez, M. Transpiler-based architecture for multi-platform web applications. In Proceedings of the 2017 IEEE Second Ecuador Technical Chapters Meeting (ETCM), Salinas, Ecuador, 16–20 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Bastidas, F.A.; Perez, M. A systematic review on Transpiler usage for Transaction-Oriented Applications. In Proceedings of the 3rd IEEE Ecuador Technical Chapters Meeting, Cuenca, Ecuador, 15–19 October 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Milewicz, R.; Pirkelbauer, P.; Soundararajan, P.; Ahmed, H.; Skjellum, T. Negative Perceptions About the Applicability of Source-to-Source Compilers in HPC: A Literature Review. In Proceedings of the High Performance Computing; Jagode, H., Anzt, H., Ltaief, H., Luszczek, P., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 233–246. [Google Scholar]
- Memeti, S.; Pllana, S.; Binotto, A.; Kołodziej, J.; Brandic, I. Using meta-heuristics and machine learning for software optimization of parallel computing systems: A systematic literature review. Computing 2019, 101, 893–936. [Google Scholar] [CrossRef] [Green Version]
- Son, L.; Pritam, N.; Khari, M.; Kumar, R.; Phuong, P.; Thong, P. Empirical Study of Software Defect Prediction: A Systematic Mapping. Symmetry 2019, 11, 212. [Google Scholar] [CrossRef] [Green Version]
- Khari, M.; Kumar, P. An extensive evaluation of search-based software testing: A review. Soft Comput. 2017, 23, 1933–1946. [Google Scholar] [CrossRef]
- Dalal, R.; Khari, M.; Anzola, J.P.; Garcia-Diaz, V. Proliferation of Opportunistic Routing: A Systematic Review. IEEE Access 2022, 10, 5855–5883. [Google Scholar] [CrossRef]
- Sugandh, U.; Khari, M.; Nigam, S. How Blockchain Technology Can Transfigure the Indian Agriculture Sector: A Review. In Handbook of Green Computing and Blockchain Technologies; CRC Press: Boca Raton, FL, USA, 2022; pp. 69–88. [Google Scholar]
- Mengist, W.; Soromessa, T.; Legese, G. Method for conducting systematic literature review and meta-analysis for environmental science research. MethodsX 2020, 7, 100777. [Google Scholar] [CrossRef] [PubMed]
- Petticrew, M.; Roberts, H. Systematic Reviews in the Social Sciences: A Practical Guide; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Gusenbauer, M.; Haddaway, N. Which Academic Search Systems are Suitable for Systematic Reviews or Meta-Analyses? Evaluating Retrieval Qualities of Google Scholar, PubMed and 26 other Resources [OPEN ACCESS]. Res. Synth. Methods 2020, 11, 181–217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, X.; Yu, C.H.; Zhang, P.; Chen, Y.; Wang, Y.; Hu, H.; Liang, Y.; Cong, J. Automated Systolic Array Architecture Synthesis for High Throughput CNN Inference on FPGAs. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017. [Google Scholar] [CrossRef]
- Verdoolaege, S.; Juega, J.C.; Cohen, A.; Gómez, J.I.; Tenllado, C.; Catthoor, F. Polyhedral parallel code generation for CUDA. ACM Trans. Archit. Code Optim. 2013, 9, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Filieri, R.; McLeay, F.; Tsui, B.; Lin, Z. Consumer perceptions of information helpfulness and determinants of purchase intention in online consumer reviews of services. Inf. Manag. 2018, 55, 956–970. [Google Scholar] [CrossRef]
- Bouajjani, A.; Derevenetc, E.; Meyer, R. Checking and Enforcing Robustness against TSO. In Programming Languages and Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 533–553. [Google Scholar] [CrossRef] [Green Version]
- Vitousek, M.M.; Kent, A.M.; Siek, J.G.; Baker, J. Design and evaluation of gradual typing for python. In Proceedings of the 10th ACM Symposium on Dynamic languages–DLS’14, Portland, ON, USA, 20–24 October 2014. [Google Scholar] [CrossRef]
- Winterstein, F.; Bayliss, S.; Constantinides, G.A. High-level synthesis of dynamic data structures: A case study using Vivado HLS. In Proceedings of the 2013 International Conference on Field-Programmable Technology (FPT), Kyoto, Japan, 9–11 December 2013. [Google Scholar] [CrossRef] [Green Version]
- Membarth, R.; Reiche, O.; Hannig, F.; Teich, J.; Korner, M.; Eckert, W. HIPAcc: A Domain-Specific Language and Compiler for Image Processing. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 210–224. [Google Scholar] [CrossRef]
- Garousi, V.; Küçük, B. Smells in software test code: A survey of knowledge in industry and academia. J. Syst. Softw. 2018, 138, 52–81. [Google Scholar] [CrossRef]
- Mortazavi-Naeini, M.; Kuczera, G.; Kiem, A.S.; Cui, L.; Henley, B.; Berghout, B.; Turner, E. Robust optimization to secure urban bulk water supply against extreme drought and uncertain climate change. Environ. Model. Softw. 2015, 69, 437–451. [Google Scholar] [CrossRef]
- Magni, A.; Dubach, C.; O’Boyle, M.F.P. A large-scale cross-architecture evaluation of thread-coarsening. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Denver CO, USA, 17–21 November 2013. [Google Scholar] [CrossRef]
- Chen, G.; Wu, B.; Li, D.; Shen, X. PORPLE: An Extensible Optimizer for Portable Data Placement on GPU. In Proceedings of the 2014 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014. [Google Scholar] [CrossRef]
- Kofler, K.; Grasso, I.; Cosenza, B.; Fahringer, T. An automatic input-sensitive approach for heterogeneous task partitioning. In Proceedings of the 27th International ACM Conference on International Conference on Supercomputing, Eugene, ON, USA, 10–14 June 2013. [Google Scholar] [CrossRef] [Green Version]
- Baykasoğlu, A.; Akpinar, Ş. Weighted Superposition Attraction (WSA): A swarm intelligence algorithm for optimization problems – Part 1: Unconstrained optimization. Appl. Soft Comput. 2017, 56, 520–540. [Google Scholar] [CrossRef]
- Darulova, E.; Kuncak, V. Towards a Compiler for Reals. ACM Trans. Program. Lang. Syst. 2017, 39, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Bloomfield, R.A.; Polo-Wood, F.; Mandel, J.C.; Mandl, K.D. Opening the Duke electronic health record to apps: Implementing SMART on FHIR. Int. J. Med Informatics 2017, 99, 1–10. [Google Scholar] [CrossRef]
- Cardoso, J.M.P.; Coutinho, J.G.F.; Carvalho, T.; Diniz, P.C.; Petrov, Z.; Luk, W.; Gonçalves, F. Performance-driven instrumentation and mapping strategies using the LARA aspect-oriented programming approach. Softw. Pract. Exp. 2014, 46, 251–287. [Google Scholar] [CrossRef]
- Bae, H.; Mustafa, D.; Lee, J.W.; Aurangzeb.; Lin, H.; Dave, C.; Eigenmann, R.; Midkiff, S.P. The Cetus Source-to-Source Compiler Infrastructure: Overview and Evaluation. Int. J. Parallel Program. 2012, 41, 753–767. [Google Scholar] [CrossRef]
- Bispo, J.; Cardoso, J.M. Clava: C/C++ source-to-source compilation using LARA. SoftwareX 2020, 12, 100565. [Google Scholar] [CrossRef]
- Puder, A.; Antebi, O. Cross-Compiling Android Applications to iOS and Windows Phone 7. Mob. Networks Appl. 2012, 18, 3–21. [Google Scholar] [CrossRef]
- Palkowski, M.; Bielecki, W. A Practical Approach to Tiling Zuker’s RNA Folding Using the Transitive Closure of Loop Dependence Graphs. In Information Systems Architecture and Technology: Proceedings of 38th International Conference on Information Systems Architecture and Technology—ISAT 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 200–209. [Google Scholar] [CrossRef]
- Palkowski, M.; Bielecki, W. TRACO Parallelizing Compiler. In Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2015; pp. 409–421. [Google Scholar] [CrossRef]
- Pinto, P.; Carvalho, T.; Bispo, J.; Cardoso, J.M.P. LARA as a language-independent aspect-oriented programming approach. In Proceedings of the Symposium on Applied Computing, Marrakech, Morocco, 3–7 April 2017. [Google Scholar] [CrossRef] [Green Version]
- Morvan, A.; Derrien, S.; Quinton, P. Polyhedral Bubble Insertion: A Method to Improve Nested Loop Pipelining for High-Level Synthesis. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2013, 32, 339–352. [Google Scholar] [CrossRef]
- Harel, R.; Mosseri, I.; Levin, H.; Alon, L.O.; Rusanovsky, M.; Oren, G. Source-to-Source Parallelization Compilers for Scientific Shared-Memory Multi-core and Accelerated Multiprocessing: Analysis, Pitfalls, Enhancement and Potential. Int. J. Parallel Program. 2019, 48, 1–31. [Google Scholar] [CrossRef]
- Balogh, G.; Mudalige, G.; Reguly, I.; Antao, S.; Bertolli, C. OP2-Clang: A Source-to-Source Translator Using Clang/LLVM LibTooling. In Proceedings of the 2018 IEEE/ACM 5th Workshop on the LLVM Compiler Infrastructure in HPC (LLVM-HPC), Dallas, TX, USA, 12 November 2018. [Google Scholar] [CrossRef] [Green Version]
- Belwal, M.; Sudarshan, T.S.B. Source-to-source translation: Impact on the performance of high level synthesis. In Proceedings of the 2017 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 5–6 May 2017. [Google Scholar] [CrossRef]
- Wang, Z.; Plyakhin, Y.; Sun, C.; Zhang, Z.; Jiang, Z.; Huang, A.; Wang, H. A source-to-source CUDA to SYCL code migration tool: Intel® DPC++ Compatibility Tool. In Proceedings of the International Workshop on OpenCL, Kingdom, UK, 10–12 May 2022. [Google Scholar] [CrossRef]
- Marangoni, M.; Wischgoll, T. Paper: Togpu: Automatic Source Transformation from C++ to CUDA using Clang/LLVM. Electron. Imaging 2016, 28, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Kalms, L.; Hebbeler, T.; Göhringer, D. Automatic OpenCL Code Generation from LLVM-IR using Polyhedral Optimization. In Proceedings of the Proceedings of the 9th Workshop and 7th Workshop on Parallel Programming and RunTime Management Techniques for Manycore Architectures and Design Tools and Architectures for Multicore Embedded Computing Platforms—PARMA-DITAM’18, Manchester, UK, 23 January 2018. [Google Scholar] [CrossRef]
- Slany, W. Pocket code. In Proceedings of the Companion Publication of the 2014 ACM SIGPLAN Conference on Systems, Programming, and Applications: Software for Humanity—SPLASH’14, Portland, ON, USA, 20–24 October 2014. [Google Scholar] [CrossRef]
- Awile, O.; Kumbhar, P.; Cornu, N.; Dura-Bernal, S.; King, J.G.; Lupton, O.; Magkanaris, I.; McDougal, R.A.; Newton, A.J.H.; Pereira, F.; et al. Modernizing the NEURON Simulator for Sustainability, Portability, and Performance. Front. Neuroinformatics 2022, 16, 884046. [Google Scholar] [CrossRef]
- Kim, H.; Hong, S.; Park, J.; Han, H. Static code transformations for thread-dense memory accesses in GPU computing. Concurr. Comput. Pract. Exp. 2019, 32, e5512. [Google Scholar] [CrossRef]
- Qiao, B.; Reiche, O.; Hannig, F.; Teich, J. Automatic Kernel Fusion for Image Processing DSLs. In Proceedings of the 21st International Workshop on Software and Compilers for Embedded Systems, Sankt Goar, Germany, 28–30 May 2018. [Google Scholar] [CrossRef]
- Ivanenko, P.A.; Doroshenko, A.Y.; Zhereb, K.A. TuningGenie: Auto-Tuning Framework Based on Rewriting Rules. In Information and Communication Technologies in Education, Research, and Industrial Applications; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 139–158. [Google Scholar] [CrossRef]
- Kong, M. On the Impact of Affine Loop Transformations in Qubit Allocation. ACM Trans. Quantum Comput. 2021, 2, 1–40. [Google Scholar] [CrossRef]
- Rivera, J.; Franchetti, F.; Puschel, M. An Interval Compiler for Sound Floating-Point Computations. In Proceedings of the 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Seoul, Republic of Korea, 27 February–3 March 2021. [Google Scholar] [CrossRef]
- Christmann, D.; Braun, T.; Gotzhein, R. SDL Real-Time Tasks – Concept, Implementation, and Evaluation. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 239–257. [Google Scholar] [CrossRef]
- Rocha, R.C.O.; Góes, L.F.W.; Pereira, F.M.Q. An Algebraic Framework for Parallelizing Recurrence in Functional Programming. In Programming Languages; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 140–155. [Google Scholar] [CrossRef]
- Duenha, L.; Guedes, M.; Almeida, H.; Boy, M.; Azevedo, R. MPSoCBench: A toolset for MPSoC system level evaluation. In Proceedings of the 2014 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS XIV), Agios Konstantinos, Greece, 14–17 July 2014. [Google Scholar] [CrossRef]
- Seitz, K.A.; Foley, T.; Porumbescu, S.D.; Owens, J.D. Supporting Unified Shader Specialization by Co-opting C++ Features. Proc. ACM Comput. Graph. Interact. Tech. 2022, 5, 1–17. [Google Scholar] [CrossRef]
- Majeti, D.; Sarkar, V. Heterogeneous Habanero-C (H2C): A Portable Programming Model for Heterogeneous Processors. In Proceedings of the 2015 IEEE International Parallel and Distributed Processing Symposium Workshop, Hyderabad, India, 25–29 May 2015. [Google Scholar] [CrossRef]
- Nunnari, F.; Heloir, A. Write-Once, Transpile-Everywhere: Re-using Motion Controllers of Virtual Humans Across Multiple Game Engines. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 435–446. [Google Scholar] [CrossRef]
- Ramos, P.P.; Leitão, A.M. Reaching Python from Racket. In Proceedings of the ILC 2014 on 8th International Lisp Conference, Montreal, QC, Canada, 14–17 August 2014. [Google Scholar] [CrossRef]
- Schneider, L.; Schultes, D. Evaluating swift-to-kotlin and kotlin-to-swift transpilers. In Proceedings of the 9th IEEE/ACM International Conference on Mobile Software Engineering and Systems. ACM, Pittsburgh, PA, USA, 17–24 May 2022. [Google Scholar] [CrossRef]
- Zaytsev, Y.V.; Morrison, A. CyNEST: A maintainable Cython-based interface for the NEST simulator. Front. Neuroinformatics 2014, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meyer, R.; Wolff, S. Pointer life cycle types for lock-free data structures with memory reclamation. Proc. ACM Program. Lang. 2019, 4, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Bispo, J.; Reis, L.; Cardoso, J.M.P. C and OpenCL generation from MATLAB. In Proceedings of the 30th Annual ACM Symposium on Applied Computing, Salamanca, Spain, 13–17 April 2015. [Google Scholar] [CrossRef] [Green Version]
- Lindner, A.; Guanciale, R.; Metere, R. TrABin: Trustworthy analyses of binaries. Sci. Comput. Program. 2019, 174, 72–89. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Fei, X.; Li, Z.; Zhang, Y. Polyhedral-Based Compilation Framework for In-Memory Neural Network Accelerators. ACM J. Emerg. Technol. Comput. Syst. 2021, 18, 1–23. [Google Scholar] [CrossRef]
- Che, S.; Meng, J.; Skadron, K. Dymaxion++: A Directive-Based API to Optimize Data Layout and Memory Mapping for Heterogeneous Systems. In Proceedings of the 2014 IEEE International Parallel Distributed Processing Symposium Workshops, Phoenix, AZ, USA, 19–23 May 2014. [Google Scholar] [CrossRef] [Green Version]
- Corchuelo, R.; Toro, M. A scheduler for SCADA-based multi-source fusion systems. Inf. Fusion 2020, 63, 41–55. [Google Scholar] [CrossRef]
- Nannicini, G.; Bishop, L.S.; Günlük, O.; Jurcevic, P. Optimal Qubit Assignment and Routing via Integer Programming. ACM Trans. Quantum Comput. 2022, 4, 1–31. [Google Scholar] [CrossRef]
- Arabnejad, H.; Bispo, J.; Barbosa, J.G.; Cardoso, J.M. An OpenMP Based Parallelization Compiler for C Applications. In Proceedings of the 2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustainable Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/SustainCom) (ISPA/IUCC/BDCloud/SocialCom/SustainCom), Melbourne, VIC, Australia, 11–13 December 2018. [Google Scholar] [CrossRef] [Green Version]
- Klein, T.; Bruckner, S.; Gröller, M.E.; Hadwiger, M.; Rautek, P. Towards Interactive Visual Exploration of Parallel Programs using a Domain-Specific Language. In Proceedings of the 4th International Workshop on OpenCL, Vienna, Austria, 19–21 April 2016. [Google Scholar] [CrossRef] [Green Version]
- Wahib, M.; Maruyama, N. Automated GPU Kernel Transformations in Large-Scale Production Stencil Applications. In Proceedings of the 24th International Symposium on High-Performance Parallel and Distributed Computing, Portland, ON, USA, 15–19 June 2015. [Google Scholar] [CrossRef]
- Shirako, J.; Hayashi, A.; Paul, S.R.; Tumanov, A.; Sarkar, V. Automatic Parallelization of Python Programs for Distributed Heterogeneous Computing. In Euro-Par 2022: Parallel Processing; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 350–366. [Google Scholar] [CrossRef]
- Khandan, H. Introducing A-Cell for Scalable and Portable SIMD Programming. In Proceedings of the 2014 IEEE 8th International Symposium on Embedded Multicore/Manycore SoCs, Aizu-Wakamatsu, Japan, 23–25 September 2014. [Google Scholar] [CrossRef]
- Chaber, P.; Ławryńczuk, M. Automatic Code Generation of MIMO Model Predictive Control Algorithms using Transcompiler. In Advances in Intelligent Systems and Computing; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 315–324. [Google Scholar] [CrossRef]
- Xu, S.; Gregg, D. Exploiting Hyper-Loop Parallelism in Vectorization to Improve Memory Performance on CUDA GPGPU. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015. [Google Scholar] [CrossRef]
- Ahmed, W.; Khan, M.; Khan, A.A.; Mehmood, R.; Algarni, A.; Albeshri, A.; Katib, I. A Framework for Faster Porting of Scientific Applications Between Heterogeneous Clouds. In Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 27–43. [Google Scholar] [CrossRef]
- Khan, M.; Priyanka, N.; Ahmed, W.; Radhika, N.; Pavithra, M.; Parimala, K. Understanding source-to-source transformations for frequent porting of applications on changing cloud architectures. In Proceedings of the 2014 International Conference on Parallel, Distributed and Grid Computing, Solan, India, 11–13 December 2014. [Google Scholar] [CrossRef]
- Hoshino, T.; Maruyama, N.; Matsuoka, S. A Directive-Based Data Layout Abstraction for Performance Portability of OpenACC Applications. In Proceedings of the 2016 IEEE 18th International Conference on High Performance Computing and Communications & IEEE 14th International Conference on Smart City & IEEE 2nd International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Sydney, NSW, Australia, 12–14 December 2016. [Google Scholar] [CrossRef]
- Flynn, P.; Yi, X.; Yan, Y. Exploring source-to-source compiler transformation of OpenMP SIMD constructs for Intel AVX and Arm SVE vector architectures. In Proceedings of the Thirteenth International Workshop on Programming Models and Applications for Multicores and Manycores, Seoul, Republic of Korea, 2–6 April 2022. [Google Scholar] [CrossRef]
- Yang, Z.; Bodeveix, J.P.; Filali, M. Towards a simple and safe Objective Caml compiling framework for the synchronous language SIGNAL. Front. Comput. Sci. 2019, 13, 715–734. [Google Scholar] [CrossRef] [Green Version]
- Ferry, C.; Yuki, T.; Derrien, S.; Rajopadhye, S. Increasing FPGA Accelerators Memory Bandwidth with a Burst-Friendly Memory Layout. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022, 1. [Google Scholar] [CrossRef]
- Géczi, Z.; Iványi, P. Automatic translation of assembly shellcodes to printable byte codes. Pollack Period. 2018, 13, 3–20. [Google Scholar] [CrossRef]
- Sathre, P.; Helal, A.E.; Feng, W.-C. A Composable Workflow for Productive Heterogeneous Computing on FPGAs via Whole-Program Analysis and Transformation. In Proceedings of the 2018 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 3–5 December 2018. [Google Scholar] [CrossRef]
- Liu, A.; Bernstein, G.L.; Chlipala, A.; Ragan-Kelley, J. Verified tensor-program optimization via high-level scheduling rewrites. Proc. ACM Program. Lang. 2022, 6, 1–28. [Google Scholar] [CrossRef]
- Kokkinis, A.; Ferikoglou, A.; Danopoulos, D.; Masouros, D.; Siozios, K. Leveraging HW Approximation for Exploiting Performance-Energy Trade-offs Within the Edge-Cloud Computing Continuum. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 406–415. [Google Scholar] [CrossRef]
- Yang, P.; Clapworthy, G.; Dong, F.; Codreanu, V.; Williams, D.; Liu, B.; Roerdink, J.B.; Deng, Z. GSWO: A programming model for GPU-enabled parallelization of sliding window operations in image processing. Signal Process. Image Commun. 2016, 47, 332–345. [Google Scholar] [CrossRef] [Green Version]
- Saied, M.; Gustedt, J.; Muller, G. Automatic Code Generation for Iterative Multi-dimensional Stencil Computations. In Proceedings of the 2016 IEEE 23rd International Conference on High Performance Computing (HiPC), Hyderabad, India, 19–22 December 2016. [Google Scholar] [CrossRef] [Green Version]
- Bodei, C.; Degano, P.; Focardi, R.; Galletta, L.; Tempesta, M. Transcompiling Firewalls. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 303–324. [Google Scholar] [CrossRef] [Green Version]
- Gent, K.; Hsiao, M.S. Functional Test Generation at the RTL Using Swarm Intelligence and Bounded Model Checking. In Proceedings of the 2013 22nd Asian Test Symposium, Yilan, Taiwan, 18–21 November 2013. [Google Scholar] [CrossRef]
- Knodtel, J.; Schwabe, W.; Lieske, T.; Reichenbach, M.; Fey, D. A Novel Methodology for Evaluating the Energy Consumption of IP Blocks in System-Level Designs. In Proceedings of the 2018 28th International Symposium on Power and Timing Modeling, Optimization and Simulation (PATMOS), Platja d’Aro, Spain, 2–4 July 2018. [Google Scholar] [CrossRef]
- Burgholzer, L.; Wille, R. Advanced Equivalence Checking for Quantum Circuits. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021, 40, 1810–1824. [Google Scholar] [CrossRef]
- Parameshwaran, I.; Budianto, E.; Shinde, S.; Dang, H.; Sadhu, A.; Saxena, P. DexterJS: Robust testing platform for DOM-based XSS vulnerabilities. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, Bergamo, Italy, 30 August–4 September 2015. [Google Scholar] [CrossRef]
- Franke, M.; Thoben, K.D. Interoperable Test Cases to Mediate between Supply Chain’s Test Processes. Information 2022, 13, 498. [Google Scholar] [CrossRef]
- Marco, H.; Ripoll, I.; de Andrés, D.; Ruiz, J.C. Security through Emulation-Based Processor Diversification. In Emerging Trends in ICT Security; Elsevier: Amsterdam, The Netherlands, 2014; pp. 335–357. [Google Scholar] [CrossRef]
- Wilson, E.; Singh, S.; Mueller, F. Just-in-time Quantum Circuit Transpilation Reduces Noise. In Proceedings of the 2020 IEEE International Conference on Quantum Computing and Engineering (QCE), Denver, CO, USA, 12–16 October 2020. [Google Scholar] [CrossRef]
- Rivera, V.; Lee, J.; Mazzara, M. Mapping Event-B Machines into Eiffel Programming Language. In Advances in Intelligent Systems and Computing; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 255–264. [Google Scholar] [CrossRef]
- Fischer, M.; Riedel, O.; Lechler, A. Arithmetic Coding for Floating-Points and Elementary Mathematical Functions. In Proceedings of the 2021 5th International Conference on System Reliability and Safety (ICSRS), Palermo, Italy, 24–26 November 2021. [Google Scholar] [CrossRef]
- Chung, S.; Wang, J. Tightly Coupled Machine Learning Coprocessor Architecture With Analog In-Memory Computing for Instruction-Level Acceleration. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 544–561. [Google Scholar] [CrossRef]
- Vassiliev, A.V. Scalable OpenCL FPGA Computing Evolution. In Proceedings of the 5th International Workshop on OpenCL, Toronto, ON, Canada, 16–18 May 2017. [Google Scholar] [CrossRef]
- Viganò, D.; Perna, R.; Rea, N.; Pons, J.A. Spectral features in isolated neutron stars induced by inhomogeneous surface temperatures. Mon. Not. R. Astron. Soc. 2014, 443, 31–40. [Google Scholar] [CrossRef] [Green Version]
- Poya, R.; Gil, A.J.; Ortigosa, R. A high performance data parallel tensor contraction framework: Application to coupled electro-mechanics. Comput. Phys. Commun. 2017, 216, 35–52. [Google Scholar] [CrossRef] [Green Version]
- Palkowski, M.; Bielecki, W. Parallel Tiled Cache and Energy Efficient Code for Zuker’s RNA Folding. In Parallel Processing and Applied Mathematics; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 25–34. [Google Scholar] [CrossRef]
- Sapuan, F.; Saw, M.; Cheah, E. General-Purpose Computation on GPUs in the Browser Using gpu.js. Comput. Sci. Eng. 2018, 20, 33–42. [Google Scholar] [CrossRef]
- Reiser, M.; Bläser, L. Accelerate JavaScript applications by cross-compiling to WebAssembly. In Proceedings of the 9th ACM SIGPLAN International Workshop on Virtual Machines and Intermediate Languages. ACM, Vancouver, BC, Canada, 24 October 2017. [Google Scholar] [CrossRef]
- Patoliya, J.J.; Patel, S.B.; Desai, M.M.; Patel, K.K. Embedded Linux Based Smart Secure IoT Intruder Alarm System Implemented on BeagleBone Black. In Soft Computing and Its Engineering Applications; Springer: Singapore, 2021; pp. 343–355. [Google Scholar] [CrossRef]
- Bernardes, T.F.; Miyake, M.Y. Cross-platform Mobile Development Approaches: A Systematic Review. IEEE Lat. Am. Trans. 2016, 14, 1892–1898. [Google Scholar] [CrossRef]
- Vendramini, V.J.; Goldman, A.; Mounié, G. Improving mobile app development using transpilers with maintainable outputs. In Proceedings of the XXXIV Brazilian Symposium on Software Engineering, ACM, Natal, Brazil, 21–23 October 2020. [Google Scholar] [CrossRef]
- Verghese, A.; Byron, D.; Amann, A.; Popovici, E. Max-Cut Problem Implementation and Analysis on a Quantum Computer. In Proceedings of the 2022 33rd Irish Signals and Systems Conference (ISSC), Cork, Ireland, 9–10 June 2022. [Google Scholar] [CrossRef]
- Natarajan, S.; Broman, D. Timed C: An Extension to the C Programming Language for Real-Time Systems. In Proceedings of the 2018 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Porto, Portugal, 11–13 April 2018. [Google Scholar] [CrossRef]
- Almudever, C.G.; Lao, L.; Wille, R.; Guerreschi, G.G. Realizing Quantum Algorithms on Real Quantum Computing Devices. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020. [Google Scholar] [CrossRef]
- Hamidy, G.M.; Philippaerts, P.; Joosen, W. SecSharp: Towards Efficient Trusted Execution in Managed Languages (Work in Progress). In Proceedings of the 19th International Conference on Managed Programming Languages and Runtimes, Brussels, Belgium, 14–15 September 2022. [Google Scholar] [CrossRef]
- Scheuner, J.; Leitner, P. Transpiling Applications into Optimized Serverless Orchestrations. In Proceedings of the 2019 IEEE 4th International Workshops on Foundations and Applications of Self* Systems (FAS*W), Umea, Sweden, 16–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Liu, G.P. A novel NCS simulation and experimental platform. In Proceedings of the 2016 UKACC 11th International Conference on Control (CONTROL), Belfast, UK, 31 August–2 September 2016. [Google Scholar] [CrossRef]
- Liu, J.; Bello, L.; Zhou, H. Relaxed Peephole Optimization: A Novel Compiler Optimization for Quantum Circuits. In Proceedings of the 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Seoul, Republic of Korea, 27 February–3 March 2021. [Google Scholar] [CrossRef]
- Fadillah, M.H.A.Z.; Idrus, B.; Hasan, M.K.; Mohd, S.M. Impact of various IBM Quantum architectures with different properties on Grover’s algorithm. In Proceedings of the 2021 International Conference on Electrical Engineering and Informatics (ICEEI), Kuala Terengganu, Malaysia, 12–13 October 2021. [Google Scholar] [CrossRef]
- Duenha, L.; Madalozzo, G.; Santiago, T.; Moraes, F.; Azevedo, R. MPSoCBench: A benchmark for high-level evaluation of multiprocessor system-on-chip tools and methodologies. J. Parallel Distrib. Comput. 2016, 95, 138–157. [Google Scholar] [CrossRef]
- de Holanda, J.A.M.; Cardoso, J.M.P.; Marques, E. A pipelined multi-softcore approach for the HOG algorithm. In Proceedings of the 2016 Conference on Design and Architectures for Signal and Image Processing (DASIP), Rennes, France, 12–14 October 2016. [Google Scholar] [CrossRef]
- Moussawi, A.H.E.; Derrien, S. Superword level parallelism aware word length optimization. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017. [Google Scholar] [CrossRef] [Green Version]
- Younis, E.; Iancu, C. Quantum Circuit Optimization and Transpilation via Parameterized Circuit Instantiation. In Proceedings of the 2022 IEEE International Conference on Quantum Computing and Engineering (QCE), Broomfield, CO, USA, 18–23 September 2022. [Google Scholar] [CrossRef]
- Banerjee, A.; Liang, X.; Tohid, R. Locality-aware Qubit Routing for the Grid Architecture. In Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Lyon, France, 30 May–3 June 2022. [Google Scholar] [CrossRef]
- Schnappinger, M.; Streit, J. Efficient Platform Migration of a Mainframe Legacy System Using Custom Transpilation. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), Luxembourg, 27 September–1 October 2021. [Google Scholar] [CrossRef]
- Alhawi, O.M.; Rocha, H.; Gadelha, M.R.; Cordeiro, L.C.; Batista, E. Verification and refutation of C programs based on k-induction and invariant inference. Int. J. Softw. Tools Technol. Transf. 2020, 23, 115–135. [Google Scholar] [CrossRef]
- Saki, A.A.; Suresh, A.; Topaloglu, R.O.; Ghosh, S. Split Compilation for Security of Quantum Circuits. In Proceedings of the 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021. [Google Scholar] [CrossRef]
- Nunnari, F.; Heloir, A. Yet another low-level agent handler. Comput. Animat. Virtual Worlds 2019, 30, e1891. [Google Scholar] [CrossRef]
- Chaber, P.; Lawrynczuk, M. AutoMATiC: Code Generation of Model Predictive Control Algorithms for Microcontrollers. IEEE Trans. Ind. Informatics 2020, 16, 4547–4556. [Google Scholar] [CrossRef]
- Cordasco, G.; D’Auria, M.; Negro, A.; Scarano, V.; Spagnuolo, C. FLY: A Domain-Specific Language for Scientific Computing on FaaS. In Euro-Par 2019: Parallel Processing Workshops; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 531–544. [Google Scholar] [CrossRef]
- Qiao, B.; Ozkan, M.A.; Teich, J.; Hannig, F. The Best of Both Worlds: Combining CUDA Graph with an Image Processing DSL. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020. [Google Scholar] [CrossRef]
- Essertel, G.M.; Tahboub, R.Y.; Rompf, T. On-stack replacement for program generators and source-to-source compilers. In Proceedings of the 20th ACM SIGPLAN International Conference on Generative Programming: Concepts and Experiences, Chicago, IL, USA, 17–18 October 2021. [Google Scholar] [CrossRef]
- Falch, T.L.; Elster, A.C. ImageCL: Language and source-to-source compiler for performance portability, load balancing, and scalability prediction on heterogeneous systems. Concurr. Comput. Pract. Exp. 2017, 30, e4384. [Google Scholar] [CrossRef] [Green Version]
- Scholz, B.; Vorobyov, K.; Krishnan, P.; Westmann, T. A Datalog Source-to-Source Translator for Static Program Analysis: An Experience Report. In Proceedings of the 2015 24th Australasian Software Engineering Conference, Adelaide, SA, Australia, 28 September–1 October 2015. [Google Scholar] [CrossRef]
- Shi, J.; Lai, K.K.; Hu, P.; Chen, G. Understanding and predicting individual retweeting behavior: Receiver perspectives. Appl. Soft Comput. 2017, 60, 844–857. [Google Scholar] [CrossRef]
- Scott, G.G.; Wiencierz, S.; Hand, C.J. The volume and source of cyberabuse influences victim blame and perceptions of attractiveness. Comput. Hum. Behav. 2019, 92, 119–127. [Google Scholar] [CrossRef] [Green Version]
- Süslü, S.; Csallner, C. SPEjs: A symbolic partial evaluator for JavaScript. In Proceedings of the 1st International Workshop on Advances in Mobile App Analysis, Montpellier, France, 4 September 2018. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Description |
|---|---|
| Procotol | For defining the study scope |
| Search | For defining the search strategy |
| Appraisal | For selecting the studies and to make quality assessment |
| Synthesis | For extracting and categorizing data |
| Analysis | For data analysis, results formulation, and discussion |
| Report | For defining conclusions and writing the report |
| Element | Definition | Synonyms |
|---|---|---|
| Population | Software architects, software developers, and software and computer science researchers | Computer science area |
| Intervention | Transpilers usage |
|
| Comparison | n/a | n/a |
| Outcome | Scenarios of transpiler usages in scientific articles | n/a |
| Context | All recent studies | The period of the last 10 years |
| Search Engine | Search String | Additional Filter |
|---|---|---|
| Scopus | TITLE-ABS-KEY ( transpiler OR transcompiler OR “cross compiler” OR “cross-compiler” OR “source to source” OR “S2S compiler” OR “source-to-source” OR transpilation OR transcompilation OR “cross compilation” OR “S2S compilation” ) AND ( LIMIT-TO ( PUBYEAR, 2022 ) OR LIMIT-TO ( PUBYEAR, 2021 ) OR LIMIT-TO ( PUBYEAR, 2020 ) OR LIMIT-TO ( PUBYEAR, 2019 ) OR LIMIT-TO ( PUBYEAR, 2018 ) OR LIMIT-TO ( PUBYEAR, 2017 ) OR LIMIT-TO ( PUBYEAR, 2016 ) OR LIMIT-TO ( PUBYEAR, 2015 ) OR LIMIT-TO ( PUBYEAR, 2014 ) OR LIMIT-TO ( PUBYEAR, 2013 ) ) AND ( LIMIT-TO ( SUBJAREA, “COMP” ) ) |
|
| IEEE Xplore | (“All Metadata”:transpiler) OR (“All Metadata”:transcompiler) OR (“All Metadata”:“cross compiler”) OR (“All Metadata”:“cross-compiler”) OR (“All Metadata”:“source to source”) OR (“All Metadata”:“source-to-source”) OR (“All Metadata”:“S2S compiler”) OR (“All Metadata”:“transpilation”) OR (“All Metadata”:transcompilation) OR (“All Metadata”:“cross compilation”) OR (”All Metadata”:“S2S compilation”) |
|
| ACM | Title:(transpiler OR transcompiler OR “cross compiler” OR “cross-compiler” OR “source to source” OR “S2S compiler” OR “source-to-source” OR transpilation OR transcompilation OR “cross compilation” OR “S2S compilation”) OR Abstract:(transpiler OR transcompiler OR “cross compiler” OR “cross-compiler” OR “source to source” OR “S2S compiler” OR “source-to-source” OR transpilation OR transcompilation OR “cross compilation” OR “S2S compilation”) OR Keywords:(transpiler OR transcompiler OR “cross compiler” OR “cross-compiler” OR “source to source” OR “S2S compiler” OR “source-to-source” OR transpilation OR transcompilation OR “cross compilation” OR “S2S compilation”) |
|
| Science Direct | “transpiler” OR “transcompiler” OR “cross compiler” OR “cross-compiler” OR “source to source” OR “S2S compiler” OR “source-to-source” OR “transpilation” OR “transcompilation” |
|
| Criteria Type | Description | Definition |
|---|---|---|
| Period | Articles can be selected based on the time of the article publication date. |
|
| Language | Articles can be excluded based on language. |
|
| Type of Literature | Articles can be excluded if they are considered grey literature |
|
| Document Type | Articles can be excluded by their document type |
|
| Impact Source | Articles can be excluded by impact factor or quartile of the source. | No criteria will be applied |
| Accessibility | Articles can be excluded if they cannot be directly accessible or cannot obtain full-text version |
|
| Relevance to research questions | Articles can be excluded if they cover topics not relevant to answer research questions. |
|
| Duplicated articles | Articles can be excluded if they are repeated between scientific databases. |
|
| Word | Length | Matches |
|---|---|---|
| performance | 11 | 541 |
| source-to-source | 16 | 471 |
| compiler | 8 | 450 |
| programming | 11 | 399 |
| parallel | 8 | 307 |
| software | 8 | 278 |
| memory | 6 | 271 |
| framework | 9 | 258 |
| transformation | 14 | 254 |
| hardware | 8 | 234 |
| optimization | 12 | 215 |
| development | 11 | 214 |
| gpu | 3 | 162 |
| algorithm | 9 | 156 |
| quantum | 7 | 138 |
| opencl | 6 | 134 |
| openmp | 6 | 133 |
| compilers | 9 | 123 |
| hls | 3 | 118 |
| architecture | 12 | 115 |
| gpus | 4 | 108 |
| javascript | 10 | 107 |
| kernels | 7 | 104 |
| simulation | 10 | 97 |
| fpga | 4 | 94 |
| kernel | 6 | 91 |
| semantics | 9 | 91 |
| cuda | 4 | 82 |
| learning | 8 | 82 |
| accelerators | 12 | 80 |
| benchmarks | 10 | 78 |
| mobile | 6 | 78 |
| power | 5 | 76 |
| network | 7 | 71 |
| space | 5 | 67 |
| benchmark | 9 | 66 |
| java | 4 | 66 |
| web | 3 | 66 |
| fpgas | 5 | 63 |
| graph | 5 | 62 |
| hpc | 3 | 62 |
| openacc | 7 | 61 |
| python | 6 | 61 |
| cloud | 5 | 59 |
| matlab | 6 | 59 |
| intel | 5 | 58 |
| polyhedral | 10 | 55 |
| low-level | 9 | 54 |
| portability | 11 | 54 |
| accelerator | 11 | 52 |
| translator | 10 | 51 |
| Article | # References |
|---|---|
| Automated Systolic Array Architecture Synthesis for High Throughput CNN Inference on FPGAs [27] | 210 |
| Polyhedral parallel code generation for CUDA [28] | 203 |
| Consumer perceptions of information helpfulness and determinants of purchase intention in online consumer reviews of services [29] | 166 |
| Checking and Enforcing Robustness against TSO [30] | 75 |
| Design and evaluation of gradual typing for python [31] | 67 |
| High-level synthesis of dynamic data structures: A case study using Vivado HLS [32] | 66 |
| HIPA: A Domain-Specific Language and Compiler for Image Processing [33] | 65 |
| Smells in software test code: A survey of knowledge in industry and academia [34] | 64 |
| Robust optimization to secure urban bulk water supply against extreme drought and uncertain climate change [35] | 64 |
| A large-scale cross-architecture evaluation of thread-coarsening [36] | 59 |
| PORPLE: An Extensible Optimizer for Portable Data Placement on GPU [37] | 58 |
| An automatic input-sensitive approach for heterogeneous task partitioning [38] | 56 |
| Weighted Superposition Attraction (WSA): A swarm intelligence algorithm for optimization problems—Part 1: Unconstrained optimization [39] | 50 |
| Towards a Compiler for Reals [40] | 50 |
| Opening the Duke electronic health record to apps: Implementing SMART on FHIR [41] | 49 |
| Article | # References |
|---|---|
| Performance-driven instrumentation and mapping strategies using the LARA aspect-oriented programming approach [42] | 10 |
| HIPA: A Domain-Specific Language and Compiler for Image Processing [33] | 8 |
| The Cetus Source-to-Source Compiler Infrastructure: Overview and Evaluation [43] | 5 |
| Clava: C/C source-to-source compilation using LARA [44] | 5 |
| Cross-Compiling Android Applications to iOS and Windows Phone 7 [45] | 4 |
| Parallel tiled Nussinov RNA folding loop nest generated using both dependence graph transitive closure and loop skewing [46] | 4 |
| TRACO Parallelizing Compiler [47] | 3 |
| LARA as a language-independent aspect-oriented programming approach [48] | 3 |
| Polyhedral Bubble Insertion: A Method to Improve Nested Loop Pipelining for High-Level Synthesis [49] | 3 |
| Source-to-Source Parallelization Compilers for Scientific Shared-Memory Multi-core and Accelerated Multiprocessing: Analysis, Pitfalls, Enhancement, and Potential [50] | 3 |
| Journal | Article Number | Quartile |
|---|---|---|
| Proceedings of the ACM on Programming Languages (https://dl.acm.org/journal/pacmpl (accessed on 10 January 2023)) | 9 | Q1 |
| The Journal of Supercomputing (https://www.springer.com/journal/11227 (accessed on 10 January 2023)) | 9 | Q2 |
| Advances in Intelligent Systems and Computing (https://www.springer.com/series/11156 (accessed on 10 January 2023)) | 9 | Q4 |
| Communications in Computer and Information Science (https://www.springer.com/series/7899 (accessed on 10 January 2023)) | 9 | Q4 |
| ACM Transactions on Architecture and Code Optimization (https://dl.acm.org/journal/taco (accessed on 10 January 2023)) | 8 | Q3 |
| International Journal of Parallel Programming (http://www.springer.com/computer+science/theoretical+computer+science/foundations+of+computations/journal/10766 (accessed on 10 January 2023)) | 8 | Q3 |
| IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (https://ieeexplore.ieee.org/xpl/RecentIssue.jsp?punumber=43 (accessed on 10 January 2023)) | 7 | Q2 |
| Parallel Computing (https://www.journals.elsevier.com/parallel-computing (accessed on 10 January 2023)) | 7 | Q3 |
| Concurrency and Computation: Practice and Experience (https://onlinelibrary.wiley.com/journal/15320634 (accessed on 10 January 2023)) | 6 | Q3 |
| Journal of Parallel and Distributed Computing (https://www.sciencedirect.com/journal/journal-of-parallel-and-distributed-computing (accessed on 10 January 2023)) | 5 | Q1 |
| Acronym | Conference Name | Article Number |
|---|---|---|
| CGO | IEEE/ACM International Symposium on Code Generation and Optimization (CGO) | 10 |
| PLDI | ACM SIGPLAN International Conference on Programming Language Design and Implementation | 10 |
| SPLASH | SPLASH: Conference on Systems, Programming, and Applications: Software for Humanity | 9 |
| SC | SC: The International Conference for High Performance Computing, Networking, Storage and Analysis | 7 |
| PPoPP | PPoPP: ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming | 7 |
| IPDPSW | IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW) | 7 |
| ICS | ACM international conference | 7 |
| ICSE | ICSE: International Conference on Software Engineering | 6 |
| FCCM | International Symposium on Field-Programmable Custom Computing Machines (FCCM) | 6 |
| FedCSIS | Conference on Computer Science and Intelligence Systems | 5 |
| Author | # Articles |
|---|---|
| Marek Palkowski | 9 |
| Alejandro Acosta | 6 |
| João Bispo | 6 |
| Aurelien Bloch | 5 |
| Pedro Pinto | 4 |
| Junyi Liu | 4 |
| Bo Qiao | 4 |
| Patryk Chaber | 4 |
| Arno Puder | 4 |
| Cedric Nugteren | 3 |
| Author | # Articles |
|---|---|
| Joao Manuel Paiva Cardoso | 21 |
| João Bispo | 16 |
| Marek Palkowski | 12 |
| Wlodzimierz Bielecki | 11 |
| George A. Constantinides | 9 |
| Frank Hannig | 9 |
| Jurgen Teich | 9 |
| Steven Derrien | 8 |
| Alejandro Acosta | 8 |
| Pedro Pinto | 7 |
| Article Title | Matches | Tags |
|---|---|---|
| OP2-Clang: A Source-to-Source Translator Using Clang/LLVM LibTooling [51] | 28 | performance, HPC, optimization, OpenMP, hardware, GPU, CLang, Parallel, Translation, C language, translator, embedded, Fortran, CPU, Domain Specific, architecture, processor, portability, source-to-source, transformation, translate, memory, Intel, LLVM, C++, DSL, refactor, CUDA |
| Source-to-source translation: Impact on the performance of high level synthesis [52] | 23 | statistic, performance, Translation, hardware, source-to-source, memory, architecture, High performance computing, High Level Synthesis, CUDA, Verilog, OpenMP, software, Intel, High-level languages, optimization, HDL, hls, C-code, Microsoft, CPU, C++, FPGA |
| A source-to-source CUDA to SYCL code migration tool: Intel DPC++ Compatibility Tool [53] | 17 | accelerator, CPU, software, hardware, C++, LLVM, source-to-source, architecture, Intel, CLang, performance, Parallel, GPU, FPGA, CUDA, multiple platforms, development |
| Paper: Togpu: Automatic Source Transformation from C++ to CUDA using Clang/LLVM [54] | 17 | transformation, software, C++, Translation, open source, translate, CUDA, GPU, development, LLVM, optimization, CLang, workflow, Parallel, opencl, performance, source to source |
| Automatic OpenCL Code Generation from LLVM-IR using Polyhedral Optimization [55] | 17 | code generation, CPU, polyhedral, LLVM, CUDA, C-code, C++, kernel, CLang, architecture, transformation, opencl, optimization, FPGA, source-to-source, Parallel, GPU |
| Transpiler-based architecture for multi-platform web applications [16] | 17 | translate, GitHub, Java, architecture, transpilation, programming language, Haxe, cloud, test, performance, css, web, software, transpiler, PHP, HTML, javascript |
| Pocket code [56] | 16 | Windows Phone, Parallel, C++, Windows, Java, open source, HTML, programming language, development, test, Mobile, javascript, smartphone, Android, cross-compilation, lego |
| Modernizing the NEURON Simulator for Sustainability, Portability, and Performance [57] | 16 | C language, architecture, Simulation, source-to-source, development, software, GPU, portability, performance, hardware, React, biological, cloud, just-in-time compilation, memory, workflow |
| Translating CUDA to OpenCL for Hardware Generation using Neural Machine Translation [58] | 16 | source-to-source, Translation, C language, DSL, opencl, kernel, hls, High-level languages, hardware, CUDA, FPGA, GPU, software, C++, translate, Neural |
| Automatic Kernel Fusion for Image Processing DSLs [59] | 15 | performance, optimization, source-to-source, memory, software, kernel, open source, portability, GPU, Parallel, DSL, graphic, hardware, accelerator, C language |
| Tags Combination | Number |
|---|---|
| (performance) (Parallel), | 127 |
| (transformation) (performance), | 105 |
| (performance) (optimization), | 97 |
| (performance) (architecture), | 95 |
| (performance) (hardware), | 87 |
| (performance) (GPU), | 83 |
| (performance) (memory), | 79 |
| (transformation) (Parallel), | 79 |
| (transformation) (optimization), | 75 |
| (Parallel) (architecture), | 72 |
| (Parallel) (GPU), | 68 |
| (Parallel) (optimization), | 64 |
| (software) (performance), | 63 |
| (Parallel) (memory), | 62 |
| (hardware) (architecture), | 59 |
| (software) (hardware), | 58 |
| (performance) (development), | 57 |
| (transformation) (software), | 57 |
| (transformation) (memory), | 52 |
| (software) (development), | 50 |
| Concept | Tags | # Articles | # References | Examples |
|---|---|---|---|---|
| transpiler | cross compilation, cross compiler, cross-compilation, cross-compiler, hls, source to source, source-to-source, source-to-source compilation, source-to-source compiler, transcompilation, transcompiler, transformation, transpilation, transpiler | 563 | 3262 | [51,60,61] |
| performance | High performance computing, HPC, performance, supercomputing | 310 | 2345 | [53,62,63] |
| parallel | CUDA, GPU, kernel, opencl, OpenMP, optimization, Parallel, XcalableMP | 348 | 2212 | [64,65,66] |
| development | architecture, development, Eclipse, GitHub, lifecycle, open source, portability, software | 351 | 1965 | [67,68,69] |
| programming language | .js, .Net, C language, C++, C-code, CLang, F#, Fortran, Haxe, High-level languages, Java, javascript, low-code, markup, matlab, Objective C, Ocaml, PHP, programming language, Python, Rust, semantics | 308 | 1667 | [70,71,72] |
| hardware | CISC, CPU, electronic, hardware, HDL, Intel, microcontroller, peripheral, Verilog | 235 | 1472 | [73,74,75] |
| compiler | GCC compiler, just-in-time compilation, LLVM, low-level, memory, polyhedral | 179 | 1427 | [47,76,77] |
| testing | bug, diagnostic, portability, static analysis, test | 174 | 1201 | [78,79,80] |
| graphics | 3D model, CAD application, GPU, graphic, OpenGL | 128 | 1091 | [81,82,83] |
| embedded systems | arduino, cyber physical, cyber-physical, embedded, FPGA, Internet of things, microcontroller, raspberry, real-time, realtime, remote devices | 145 | 1046 | [52,84,85] |
| processor | ARM, CISC, CPU, Intel, multi-thread, multicore, multithread, processor, RISC, Xeon | 214 | 1030 | [52,86,87] |
| language | English, semantics, speak, speech, translate, Translation, translator | 193 | 998 | [88,89,90] |
| other | accelerator, computer science, convert, High Level Synthesis, quantum | 135 | 777 | [59,91,92] |
| operating system | kernel, linux, virtual reality, Windows | 97 | 683 | [93,94,95] |
| code generation | code generation, Domain Specific, DSL, model driven, refactor | 75 | 662 | [96,97,98] |
| architecture | microservices, multi-thread, multiple platforms, Simulation | 78 | 532 | [99,100,101] |
| security | attack, IKEv2, malware, safety, security, surveillance, vulnerability | 56 | 451 | [102,103,104] |
| research | empirical, literature, mapping, systematic | 84 | 438 | [76,105,106] |
| AI | artificial intelligence, classification algorithm, human-robot, Machine Learning, ML Module, ML Program, Natural Language, Neural | 39 | 426 | [107,108,109] |
| math | Arithmetic, mathematical, probabilistic, statistic | 43 | 347 | [52,110,111] |
| front-end | .js, Angular, css, Flutter, HTML, javascript, React, sass, Typescript, web | 72 | 321 | [112,113,114] |
| mobile | Android, Mobile, smartphone, Windows Phone | 40 | 273 | [115,116,117] |
| networking | 5G, connectivity, Internet, IPV6, Protocol, satellite, Virtual Machine, wi-fi, Wireless | 53 | 188 | [118,119,120] |
| cloud | Amazon Web Services, AWS, Azure, cloud | 32 | 123 | [121,122,123] |
| brand | Alibaba, Amazon Web Services, AWS, Azure, google, IBM, Microsoft, Oracle | 30 | 111 | [52,124,125] |
| energy | power consumption | 15 | 83 | [126,127,128] |
| quantum | quantum | 20 | 55 | [105,129,130] |
| vertical | biological, Economy, medical | 13 | 38 | [57,131,132] |
| games | game, lego | 9 | 36 | [56,133,134] |
| industry | cyber physical, cyber-physical, RFID, SCADA, workflow | 14 | 28 | [135,136,137] |
| database | Oracle, polystore, RDBMS, SQL | 8 | 27 | [138,139,140] |
| social network | facebook, twitter | 3 | 24 | [141,142,143] |
| Programming Language | # Articles |
|---|---|
| C++ / C | 135 |
| Java | 63 |
| javascript | 41 |
| Rust | 22 |
| Python | 21 |
| Fortran | 20 |
| matlab | 18 |
| High-level languages | 6 |
| Haxe | 2 |
| Ocaml | 2 |
| Term | # Articles |
|---|---|
| source-to-source | 386 |
| transformation | 231 |
| transpiler | 37 |
| hls | 36 |
| cross-compilation | 32 |
| source to source | 30 |
| transpilation | 24 |
| cross-compiler | 23 |
| transcompiler | 11 |
| cross compiler | 7 |
| cross compilation | 6 |
| transcompilation | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bastidas Fuertes, A.; Pérez, M.; Meza Hormaza, J. Transpilers: A Systematic Mapping Review of Their Usage in Research and Industry. Appl. Sci. 2023, 13, 3667. https://doi.org/10.3390/app13063667
Bastidas Fuertes A, Pérez M, Meza Hormaza J. Transpilers: A Systematic Mapping Review of Their Usage in Research and Industry. Applied Sciences. 2023; 13(6):3667. https://doi.org/10.3390/app13063667
Chicago/Turabian StyleBastidas Fuertes, Andrés, María Pérez, and Jaime Meza Hormaza. 2023. "Transpilers: A Systematic Mapping Review of Their Usage in Research and Industry" Applied Sciences 13, no. 6: 3667. https://doi.org/10.3390/app13063667