1. Introduction
Mineral foam flotation is a beneficiation method used to obtain high-quality minerals. The traditional mining industry has been relying on manual observation of foam to monitor the flotation production conditions, which is subjective and inefficient. Therefore, the use of machine learning for foam flotation work classification is gradually becoming a research hotspot [
1]. Oktaba et al. [
2] first used an image algorithm to predict the copper content in the foam. Lu et al. [
3] proposed a flotation foam size distribution feature extraction approach. Li et al. [
4] proposed a floatation detection based on deep learning and a support vector machine. Sameer H. Morar et al. [
5] proposed a machine vision technique to measure the rate at which lamellae on the froth surface burst. Zhang et al. [
6] proposed a flotation dosing state recognition method based on multiscale CNN features and a ranks automatic encoder kernel extreme learning machine. In the above studies, although machine learning was used to process clear mineral foam images, problems such as insufficient clarity of foam images and poor foam boundaries were ignored. Infrared gray images are less susceptible to interference from complex conditions such as light and smoke but have disadvantages such as inconspicuous details and poor visibility. Visible images can capture a wealth of detailed information. Infrared and visible images present features that are inherent to almost all objects [
7]. If these two modality images are used directly, a large amount of redundant information will be generated, which is not conducive to the subsequent work. Due to the ubiquitous and complementary characteristics of infrared and visible images, their fusion technology has solved the above problems and has been widely used. Remote sensing [
8], object recognition [
7,
9], detection [
10], and surveillance [
11] are classical applications of infrared and visible image fusion. Therefore, in this paper, infrared and visible image fusion techniques are used to process foam images.
In the past few decades, multiscale transformation (MST) has achieved success in areas such as infrared and visible image fusion and is the most active area in image fusion [
4]. Generally, MST-based fusion methods include three basic steps. Firstly, the source image is decomposed to obtain low and high-frequency information. Secondly, the low-frequency and high-frequency information is fused according to the corresponding fusion rules. Finally, the fused high and low-frequency bands are used to perform the corresponding inverse transform to obtain the final fused image. The commonly used MST methods in image fusion include Laplace Pyramid (LP) [
12], Wavelet Transform [
13], Contourlet Transform [
14], Non-subsampled Contourlet Transform (NSCT) [
15], and Non-subsampled Shearlet Transform (NSST) [
16], among which NSST has a great advantage of no direction number limitation and avoiding the Pseudo-Gibbs effect. In addition to the image transform selection, the high and low-frequency coefficient fusion strategy is also a key issue. The high frequency is usually chosen to fuse the maximum absolute value and the simple rule of sampling the weighted average of the low frequency to obtain the fusion coefficients [
12]. Since most of the image energy is in the low-frequency sub-bands, the average fusion will reduce the contrast and lose the energy information of the source image. In this paper, the pulse-coupled neural network algorithm (PCNN) is used for high-frequency fusion, and the PCNN is a biological neural network derived from the cortical model of Echorn et al. [
17], which has features such as global coupling and pulse synchronization and is well suited as a tool for image fusion. Specifically, PCNN is usually used to extract the activity level of the decomposition coefficients of the MST. In most cases, the parameters of PCNNs are empirically or manually entered, which largely limits the performance of the algorithm [
18], and parametric adaptive PCNN (PAPCNN) [
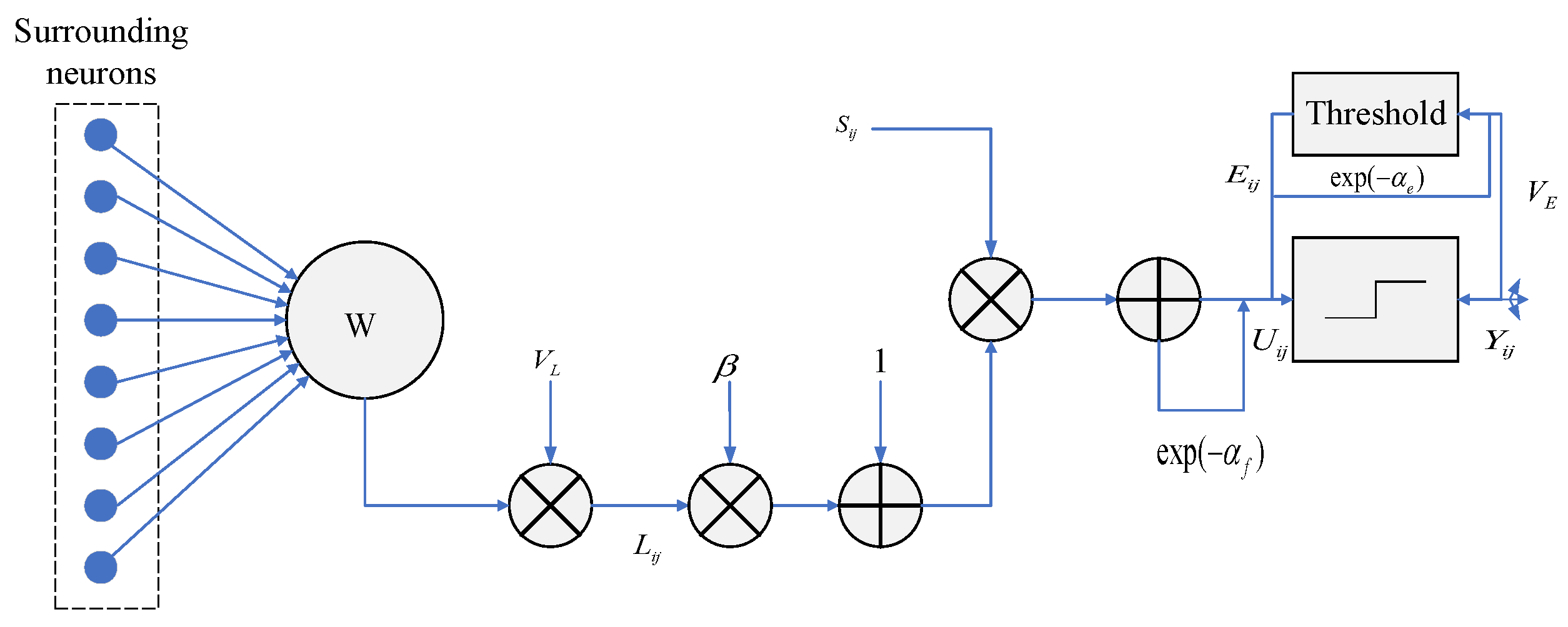
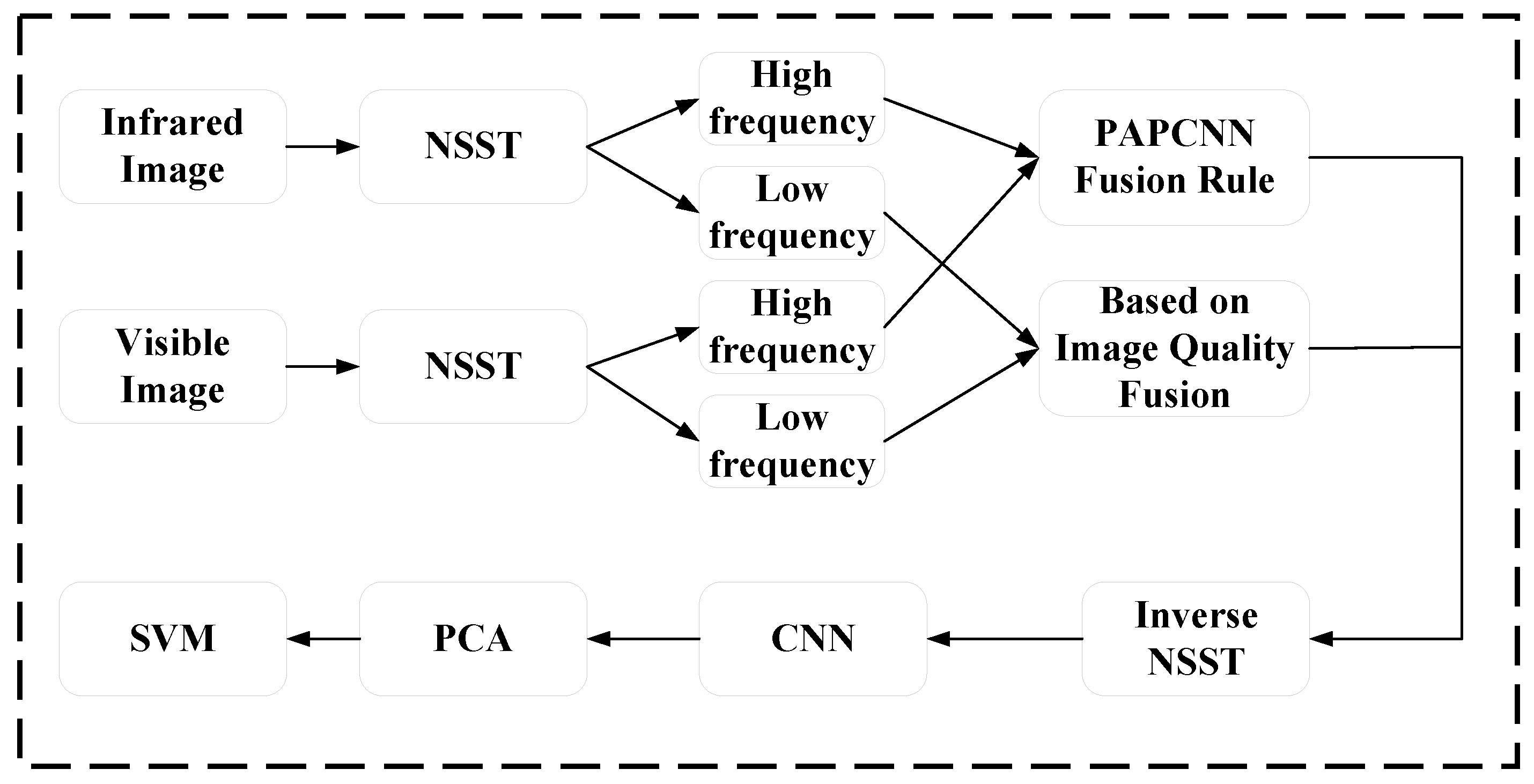
19] is introduced into the field of foam image fusion to overcome the difficulty of setting free parameters. For low-frequency fusion, this paper proposes a new low-frequency fusion strategy based on image quality detection, which obtains the fusion weights of low frequency by detecting the image quality of low-frequency sub-bands and adjusts the fusion weight according to the different image quality of different low-frequency sub-bands, which not only retains the background information contained in low frequency but also retains a small amount of detailed information.
There is a strong correlation between foam features and flotation conditions, and a condition recognition model can be established through various features of foam images. Liu et al. [
20] proposed to introduce a gray correlation matrix to extract foam textures and to use a self-organizing neural network to identify the foam condition; Patel et al. [
21] proposed a support vector machine regression (SVR) based algorithm that can better predict the quality of iron ore images. Guyon [
22] proposed an SVM-RFE model, which eliminates features one by one in a recursive manner to reduce the data dimensionality. From the above references, it can be seen that there are large errors, redundant information, and poor relations in some features. Deep learning solves the above problems. Additionally, dynamic data distribution [
4,
23], disease detection [
24], and image recognition [
25] are typical applications of CNN and deep learning. Convolutional neural networks can extract effective features from images and perform deep learning to avoid complex feature extraction. The steps are convolution, pooling and other operations [
25], extraction of features with discriminatory, feeding into classifiers for target recognition for training, and using the trained classifiers to complete the operation of identity recognition considering unknown targets [
26,
27].
Based on the above research, this paper proposes a mineral foam flotation classification model based on multi-modality image fusion in visible and infrared gray. Firstly, the source image is scale decomposed using NSST. Secondly, the fusion of high-frequency sub-bands uses PAPCNN, and the fusion of low-frequency sub-bands is based on an image quality detection fusion method. Thirdly, NSST inversion reconstructs the new fused image. Finally, the image features are extracted using CNN, and after dimensionality reduction by PCA, the mineral foam images are classified using SVM.
4. Conclusions and Future Directions
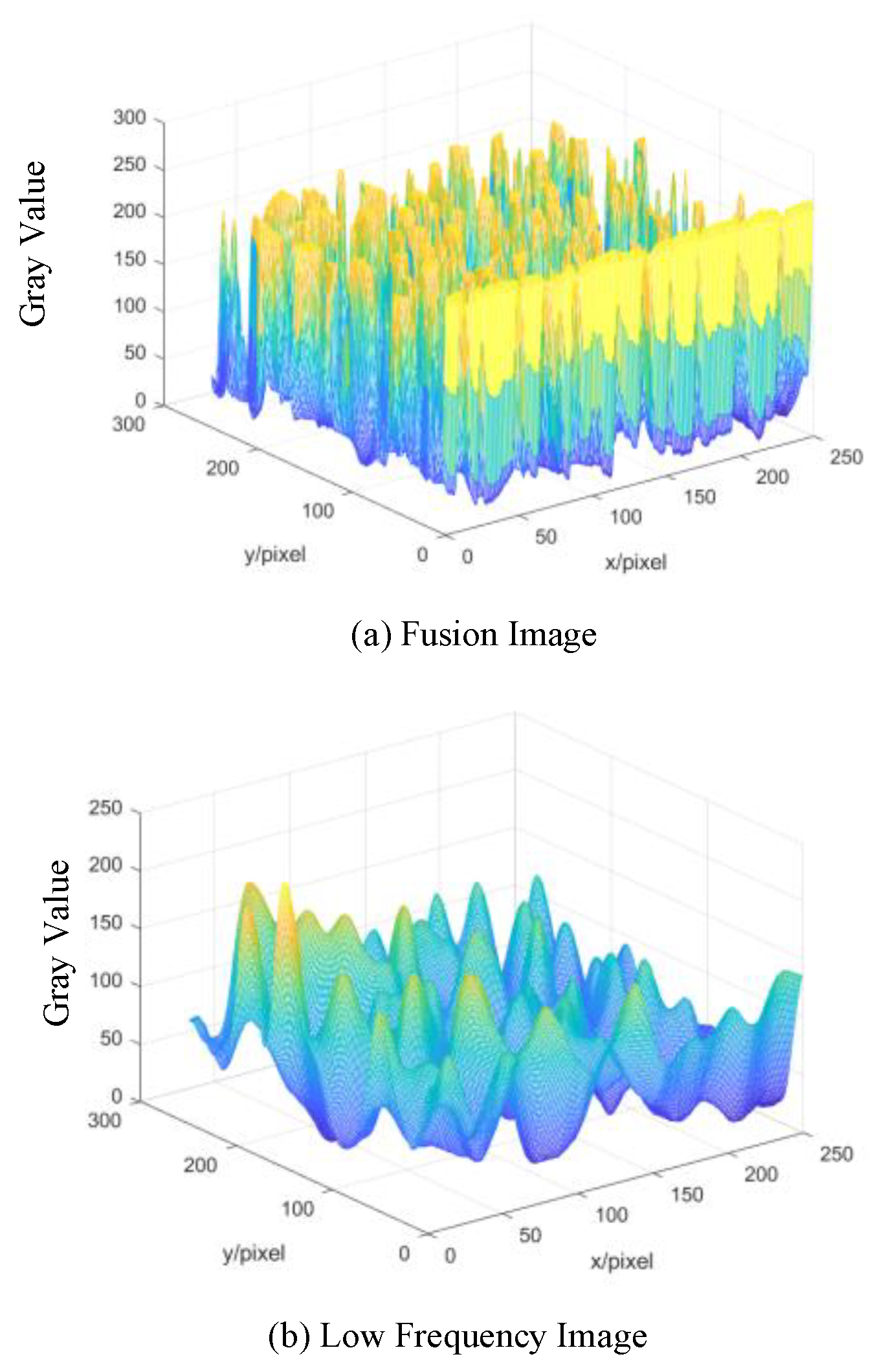
In this paper, a new foam image fusion method is proposed. The fused mineral foam image contains rich texture detail features and highlights the mineral foam outline, which is beneficial to mineral foam flotation feature extraction and conditions classification.
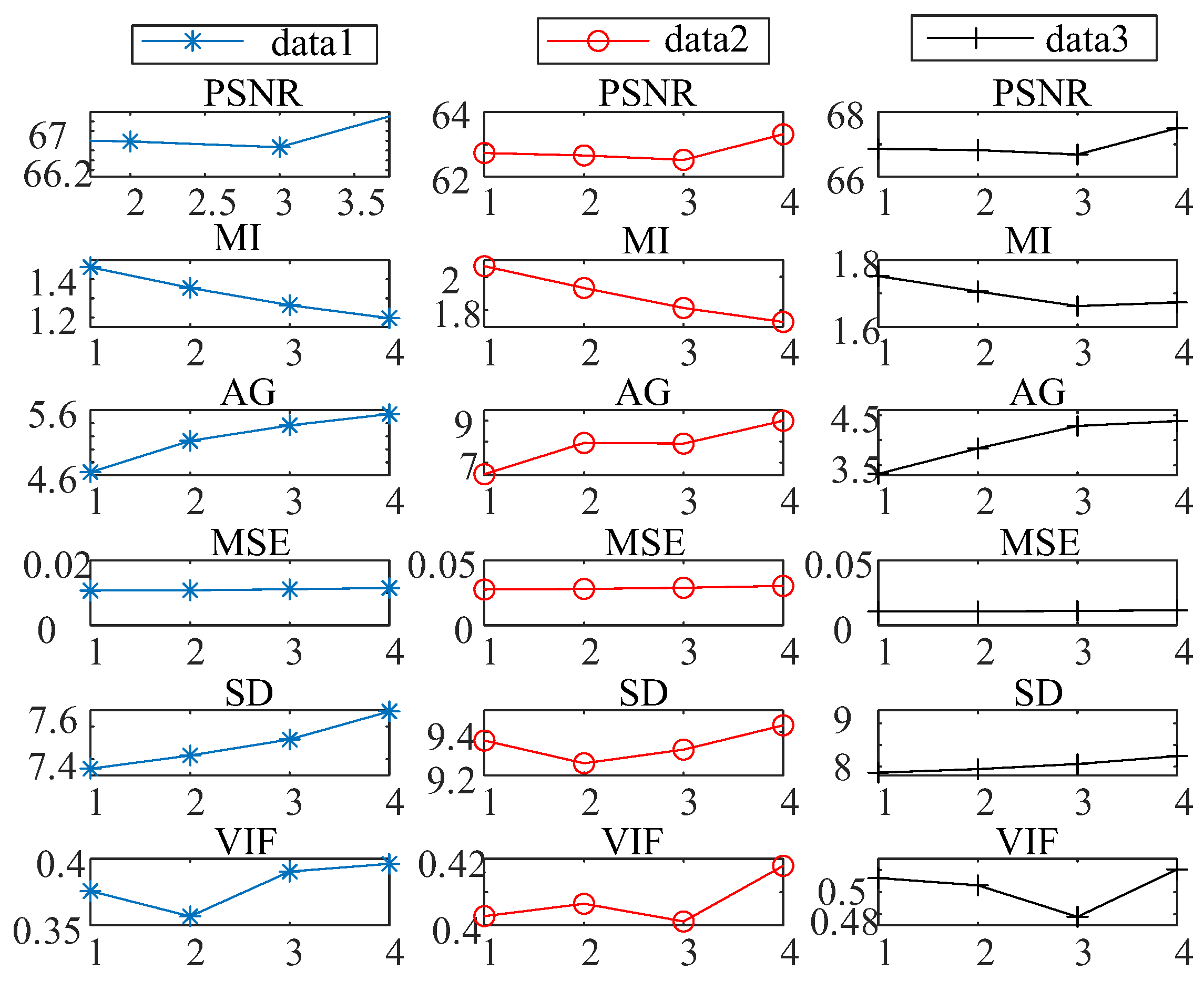
The CNN-PCA-SVM model based on Multi-modal foam image fusion was successfully proposed, which can classify three foam conditions. After effective design, training, testing, and verification, the classification accuracy is 92.3% considering the blind dataset.
This shows that the image fusion model proposed in this paper is suitable for feature extraction of mineral foam images, which can be used for cross-domain image fusion. The classification model is applicable to the classification of mineral foam quality, and this trained classification model can be used for cross-domain data distribution.
The future work will feed the model with a large amount of data to reduce misclassification, increase the robustness of the model in a highly noisy environment through model augmentation [
41], and build a real-time detection error classification system.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}