1. Introduction
The importance of automatic tweet or text classification has increased with the ongoing addition of text-based content to the internet. The rapid growth of social and digital media has resulted in an ever-increasing amount of data generated by various sources. The availability of such unorganized data provides an enormous potential for processing and extracting valuable information. One critical task is identifying individuals depending on their tweeting and grouping, a field of study that has gained increasing interest in recent years. Automated multi-labeled systems are now possible because of recent advances in deep-learning- and machine-learning-based approaches. Tweet or text classification is a necessary condition for the development of various emerging applications in diverse fields, such as linguistic (and dialect) recognition, user’s tweet classification, sentiment analysis, genre classification, spam filtering, and a few more [
1,
2,
3,
4]. There is a significant need for an automatic tweet or text categorization system for Arabic due to the abundance of Arabic data available on the web nowadays.
There are different criteria for classifying Arabic tweets, depending on the accessibility of data, resource limitations, and data quality. The Arabic language is considered one of the most widely used languages on social media, especially Twitter and Facebook. Most user and people attitudes are reflected on social media to express their opinions to different news, topics, and provided services that can be enhanced in future. Furthermore, the Arabic language on social media platforms contains long tweets with different morphological and polarity terms that are difficult to analyze.
As presented in [
5], the unsupervised sentiment analysis method is applied to improve the performance of analyzing sentiments using term weights from different datasets. In addition, the features are extracted for predicting the target or objective features. The authors of [
6] proposed different machine-learning models to classify text and provide a recommender system that can predict the orientation of sentiments. Despite this, they frequently fail to consider textual context or word order, so their classification accuracy needs to be improved by data sparsity. Furthermore, deep-learning-based techniques have been proven more efficient than conventional machine-learning approaches. They can extract important characteristics effectively without requiring extensive artificial feature extraction [
7]. The RNN and CNN have demonstrated varying capacities in displaying text. RNNs are good at modeling sequential data and effectively representing text by understanding contextual aspects and long-term relationships in phrases. They have been successfully employed in natural language-processing applications [
8]. Some known algorithms for text categorization combine CNN and RNN to maximize their potential [
9]. However, these algorithms treat every word in the phrase equally, making it impossible to tell which keywords are more important in the categorization process than the more prevalent ones. According to the attention-based technique, neural networks may give varying weights to words in a sentence based on their value for categorization, alleviating the previous difficulties. Attention-based RNN, CNN, and GRU can produce state-of-the-art results. However, these techniques are attributed to individual CNN, GRU, or RNN, and the significance of learning contextual information is insignificant in their implementation [
10]. The extent of BERT’s potential has yet to be explored, even though it has given reasonable results in NLP-related tasks surpassing most conventional approaches, such as word2vec, Cove, and Glove. Incorporating BERT does not help much because it is trained using a blend of a corpus in English and has no text categorization skills. When there is insufficient internal training data for fine-tuning, a task-awareness problem may be solved by using an external domain-related corpus.
To overcome the limitations of the aforementioned models, we proposed a model ARABERT4TWC for Arabic tweet classification. We attained performance compared to other well-known techniques, with three out of five datasets used. First, data sanitation is performed on the datasets to remove Arabic stop words and punctuation. As a part of data preprocessing, the model input is first tokenized with a word-piece tokenizer trained on a large Arabic corpus that contains 1.5-billion Arabic corpora and OSIAN, which are publicly available [
11,
12]. The word-piece tokenizer is based on a sub-word tokenization algorithm. Sub-word tokenization techniques are based on the idea that commonly employed phrases must be distinct from shorter sub-words. However, unique words should be deconstructed into meaningful sub-words when tokenizing them. Sub-word tokenization helps the model acquire meaningful, contextually independent representations while maintaining a suitable lexicon size.
The tokens obtained from the word-piece tokenizer are combined with segment and positional embedding. Second, an Arabic BERT for tweet classification is constructed by fine-tuning the pre-trained BERT case model provided by the Hugging Face Transformer Library that has been trained on larger unlabeled text corpora, including book corpora and Wikipedia [
13,
14,
15]. The fine-tuning is executed by initializing the weights of the pre-trained BERT model. All the 109-million parameters are fine-tuned with labeled data. A dense classification layer is added to the encoder to obtain an Arabic BERT, specifically used for Arabic tweet classification. The custom BERT model consists of 12 encoder layers with 12 self-attention heads, which are bi-directional, and 12 hidden layers. The final embedding layers obtained after merging with segment and positional embedding are passed through the encoder structure. Finally, the Softmax classification layer is used for classifying Arabic tweets. To validate our proposed model, the model’s performance in terms of accuracy is evaluated using five benchmark datasets with other well-known existing models for tweet classification. The contribution of the paper is explained as follows:
Propose an ARABERT4TWC model for classifying Arabic long tweets into different categories.
Propose a tokenization process algorithm for measuring the frequency of each pair of text in the vocabulary and then determining the most frequent terms.
Proposing an ARABERT4TWC algorithm that contains a token, segment, and positional embedding of terms, then applying an encoder/transformer.
Applying a fine-tuning of the ARABERT4TWC model ARABERT4TWC to achieve better performance on social media-related tasks.
Applying the proposed model to different datasets and the experimental results are compared with recent research methodologies, which explored high accuracy in the proposed model.
The remaining structure of the paper is as follows: The related work in text or tweet classification is reported in
Section 2. The proposed methodology Arabic BERT model for tweet classification (ARABERT4TWC) is presented in
Section 3, which explains the sanitation of data, the model architecture, the proposed algorithms, the self-attention layer, and the classification layer. The experiment setup, performance evaluation of our proposed model, and a comparison of the existing techniques are explained in
Section 4.
Section 5 summarizes the conclusion and future scope.
2. Related Works
Several research works addressed the problem of automated text classification, presenting various methodologies, and approaches. Deep-learning-based neural network models have significantly progressed in text categorization in recent years. In 2010, Sanad [
16] proposed several traditional learning supervised classifiers, such as KNN, SVM, Decision Tree classifier, and Nave Bayes for Arabic text classification. He examined the effect of data preprocessing on text classification. The CNN and BBC Arabic news databases, which are extensively shared but relatively smaller, were used. In 2007, Umer and Kiyal [
17] proposed a neural network-based approach for Arabic text classification, which outperformed the KNN, Decision Tree classifier, SVM, and NB methods in terms of accuracy with relatively smaller datasets. Learning vector quantization was used for categorizing or classifying the text content. In 2017, Gaussier, Mahdaouy, and Alaoui [
18] performed document and word embedding instead of data preprocessing and keyword counting. It was demonstrated that text embedding performed better than preprocessing strategies when they were learned with Doc2Vec, or when vectors that consisted of words were averaged. Word embedding was contrasted with established techniques that depend on data acquisition or keyword enumeration in various applications, such as tweet classification [
19].
The development of deep-learning-based algorithms to handle various challenges has increased significantly over the previous four years. This is because it outperforms traditional learning algorithms based on performance. In 2019, Vincent and Ogier explained the significance of applying deep learning to solve content analysis constraints. The deep-learning algorithm based on convolutional neural networks could extract deep characteristics or features from texts or tweets, producing better results in text classification [
20]. Text categorization was improved in 2014 when Kim created the first CNN (Convolutional Neural Network) architecture with a simple yet effective topology [
21]. Using unlabeled data, Jhonson and R developed a new semi-supervised CNN architecture for text classification that first learns text region embedding and then labels them [
22]. In 2018, the authors observed that by enhancing CNN’s depth, sentences with a long-term correlation could be learned effectively when the text sequence is character-based instead of word-based encoding [
23].
RNNs have been used in the machine translation, question-answering, and speech recognition fields to find long-term correlations in sequential data. In recent studies, it has been indicated that it may also be used in categorizing text [
9,
10]. As presented in [
8], the authors proposed a recurrent convolutional neural network (RCNN) that utilized a periodic or recurrent structure to capture contextual data and CNN for feature extraction. As shown in [
24], the authors proposed a deep-learning-based model that uses a condition-based random classifier and recurrent structures, such as bi-directional and simple LSTM (Long Short-Term Memory). The two models were adapted to the Arabic hotel reviews dataset, in which the first approach was carried out with character-based and word-based encoding to extract the text’s most highly expressed phrases. Context-aware Gated Recurrent Units (C-GRU), which used an additional layer to retrieve the context data from tweets, were proposed by the authors in 2018 [
25].
As presented in [
26], an activation function is proposed to enhance the performance on the training dataset by optimizing the neural network. The authors aimed to provide different solutions related to training of data where one of the solutions applied activated gradient for eliminating the gradient problem. Furthermore, the authors provided different theorems to vanish the problem of a saddle point. The proposed model is implemented and compared with different ResNet models that achieved a high performance with the activated gradient. As shown in [
27], a deep-learning structure comprises BERT–Base and a final emotional and sentimental analysis classification layer. By considering two datasets of tweets, they attained an accuracy of 92 and 90% for emotion and sentimental analysis, respectively, from which it was possible to conclude that Bert’s language modeling power contributes significantly to achieving a good tweet classification. Small datasets were used, and the Bert model could not classify long tweets due to a lower number of attention layers. Since then, new language processing models, including BERT, Roberta, AL–BERT, and T5, increased performance by experimenting with alternative pre-training approaches, updated model topologies, and bigger training corpora. In 2021, Antoun et al. developed an ARABERT model for various downstream tasks like Named Entity Recognition (NER) and Sentiment Analysis (SA). They achieved a 92% accuracy for the various downstream tasks [
28]. As proposed in [
29], the authors performed a self-training of the Arabic dataset that contains different dialects that cause low performance when a new dataset is added. The authors of [
30] provided a sequence-to-sequence model that performs a text normalization of the Arabic dialect. The paper proposed an encoder/decoder model where the encoder accepts the input text, builds the features, and then collects the features to generate the final output. As explained in [
31], the Naïve Bayes model is applied to the spark dataset to collect tokens, and then the polarity terms are counted to measure the accuracy. The authors of [
32] applied different-machine learning models to extract user reviews from Saudi institutions to improve the prediction that can help make accurate decisions for providing services. As presented in [
33], the authors collected Arabic tweets that can explain and express the depression statements in the tweets. The novelty of the proposed model is that the authors applied many symptoms to classify the depression classes and then detect whether the applied sentiment contains depression terms or not. As shown in [
34], the authors collected different Arabic tweets about the COVID–19 pandemic to detect the user reactions and feelings based on their polarity. In addition, the proposed model tried to predict the spread of the pandemic based on user reviews.
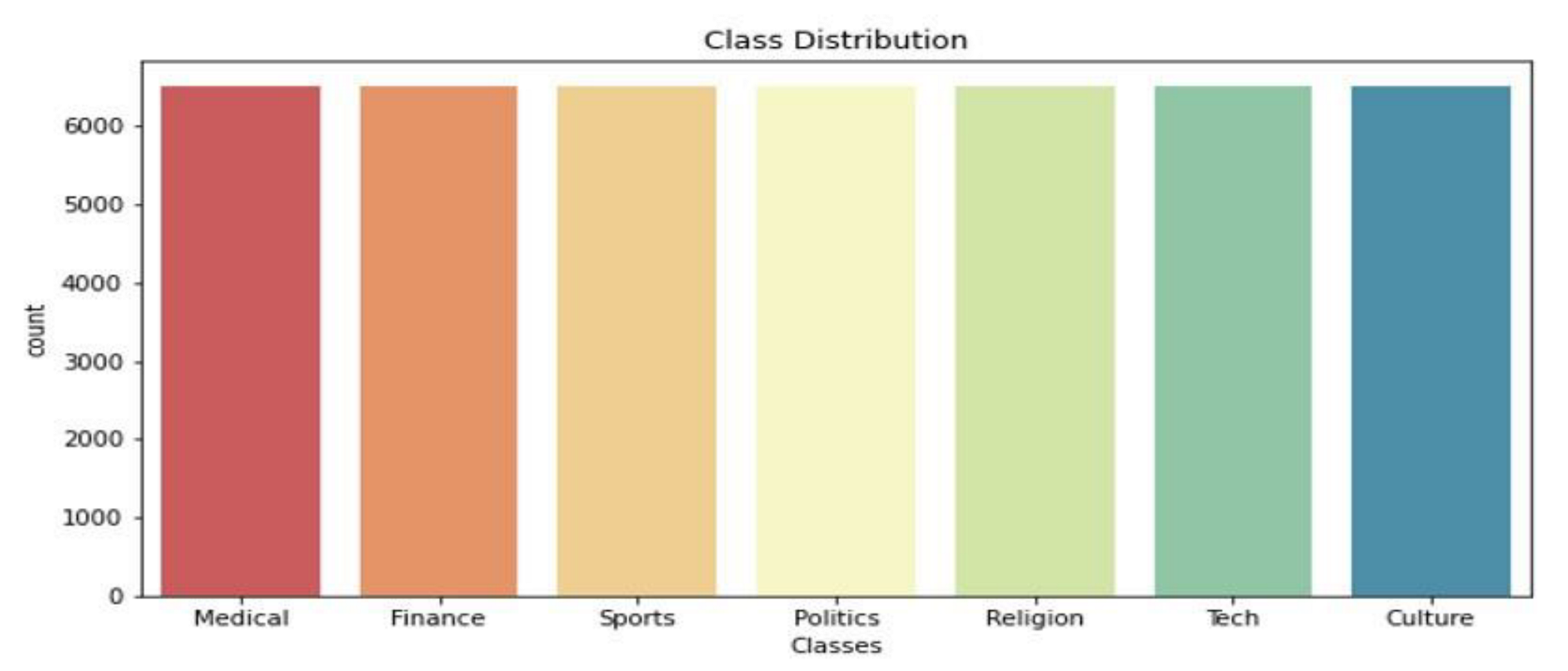
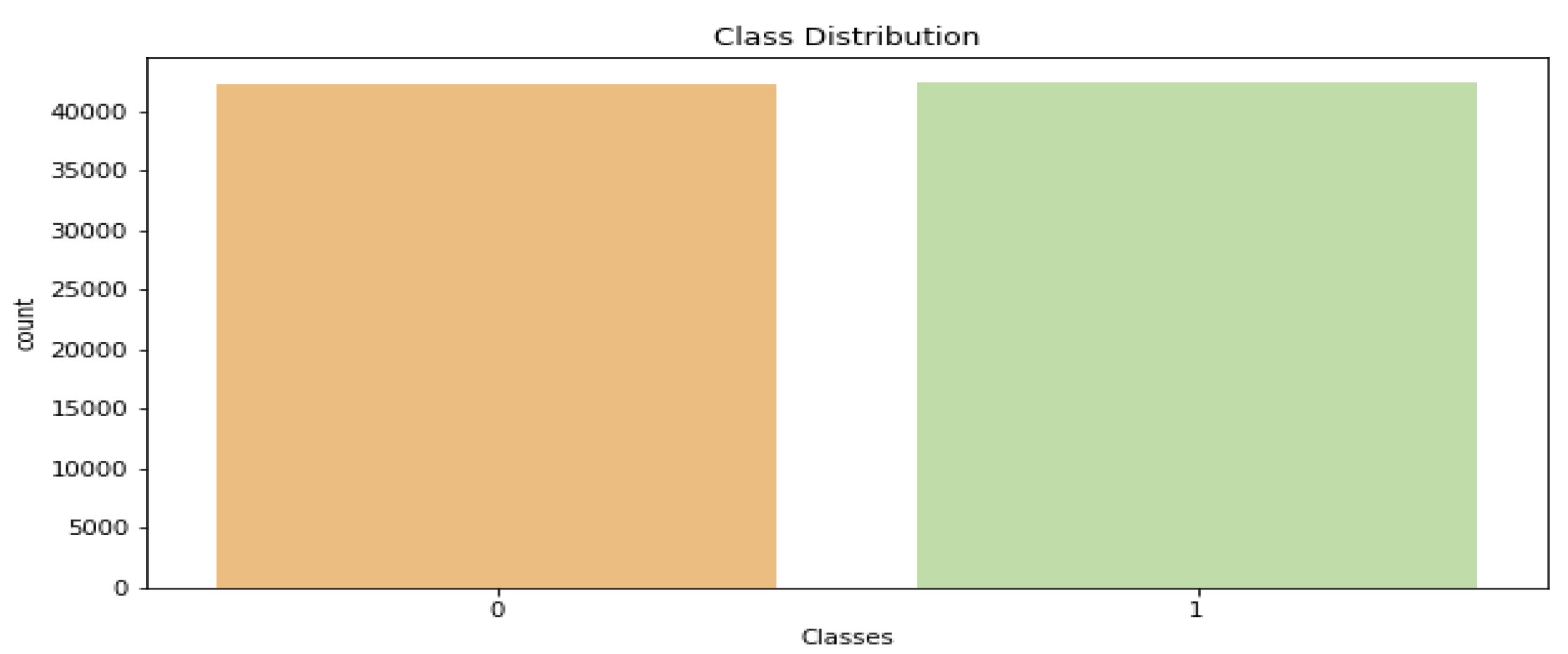
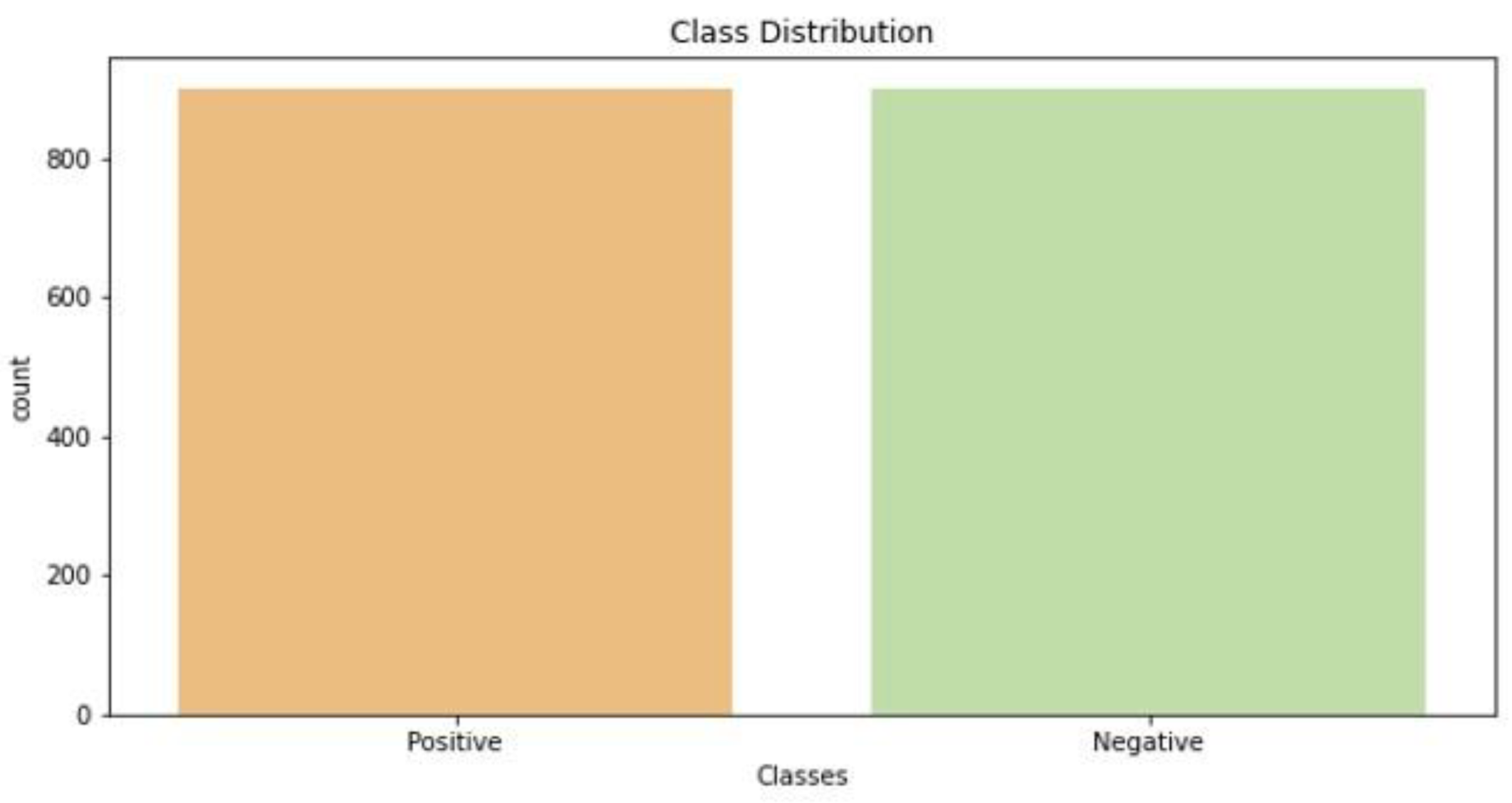
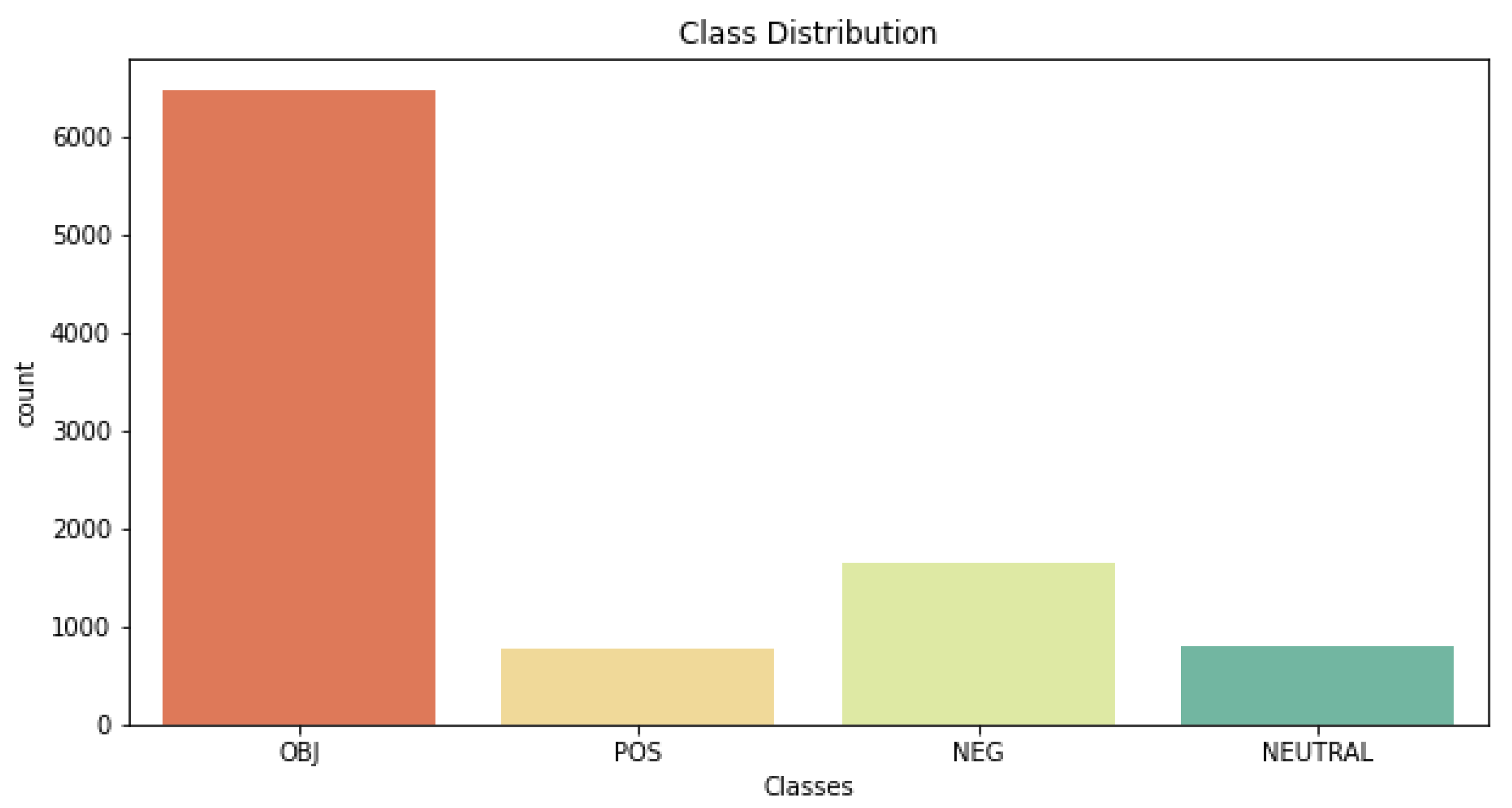
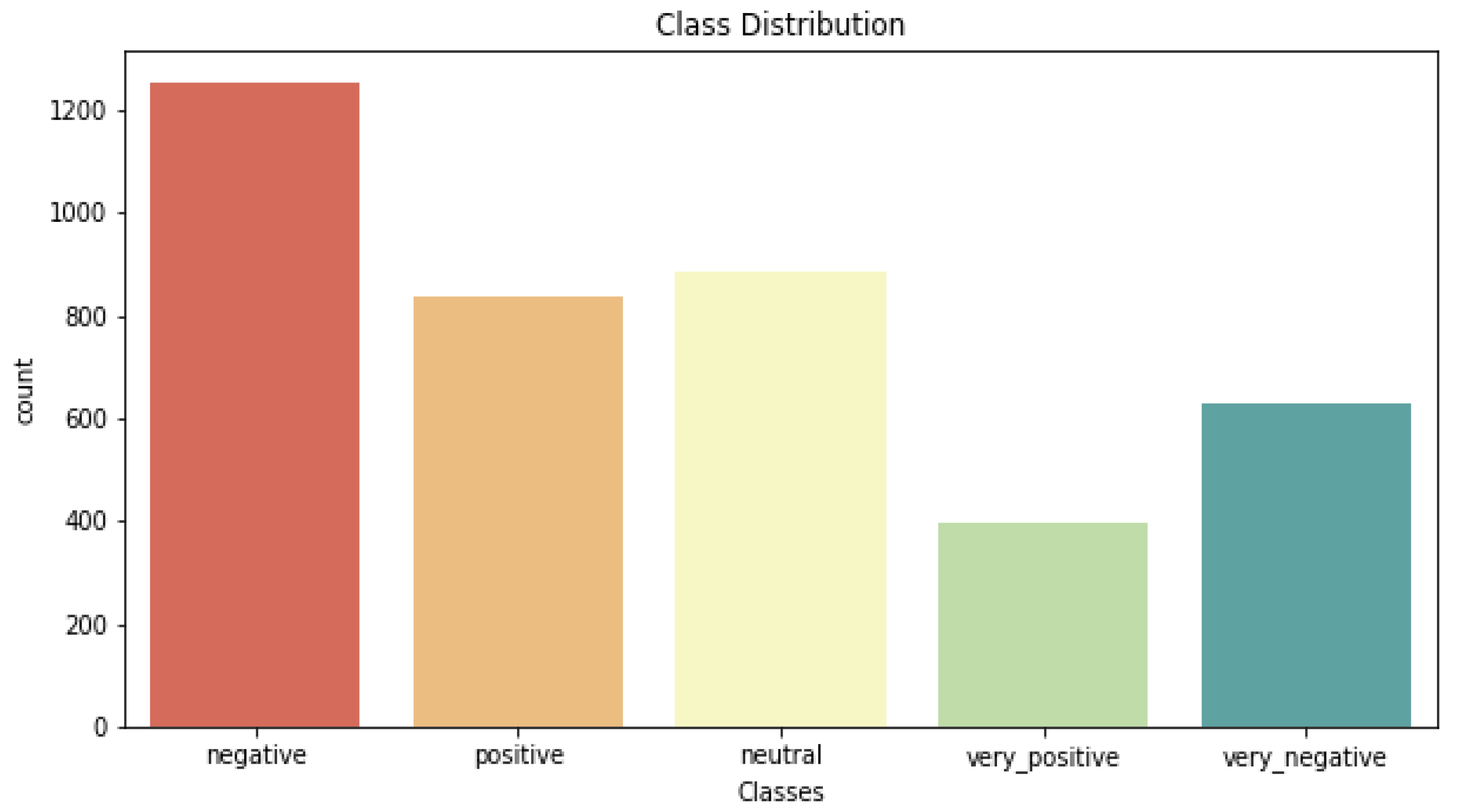
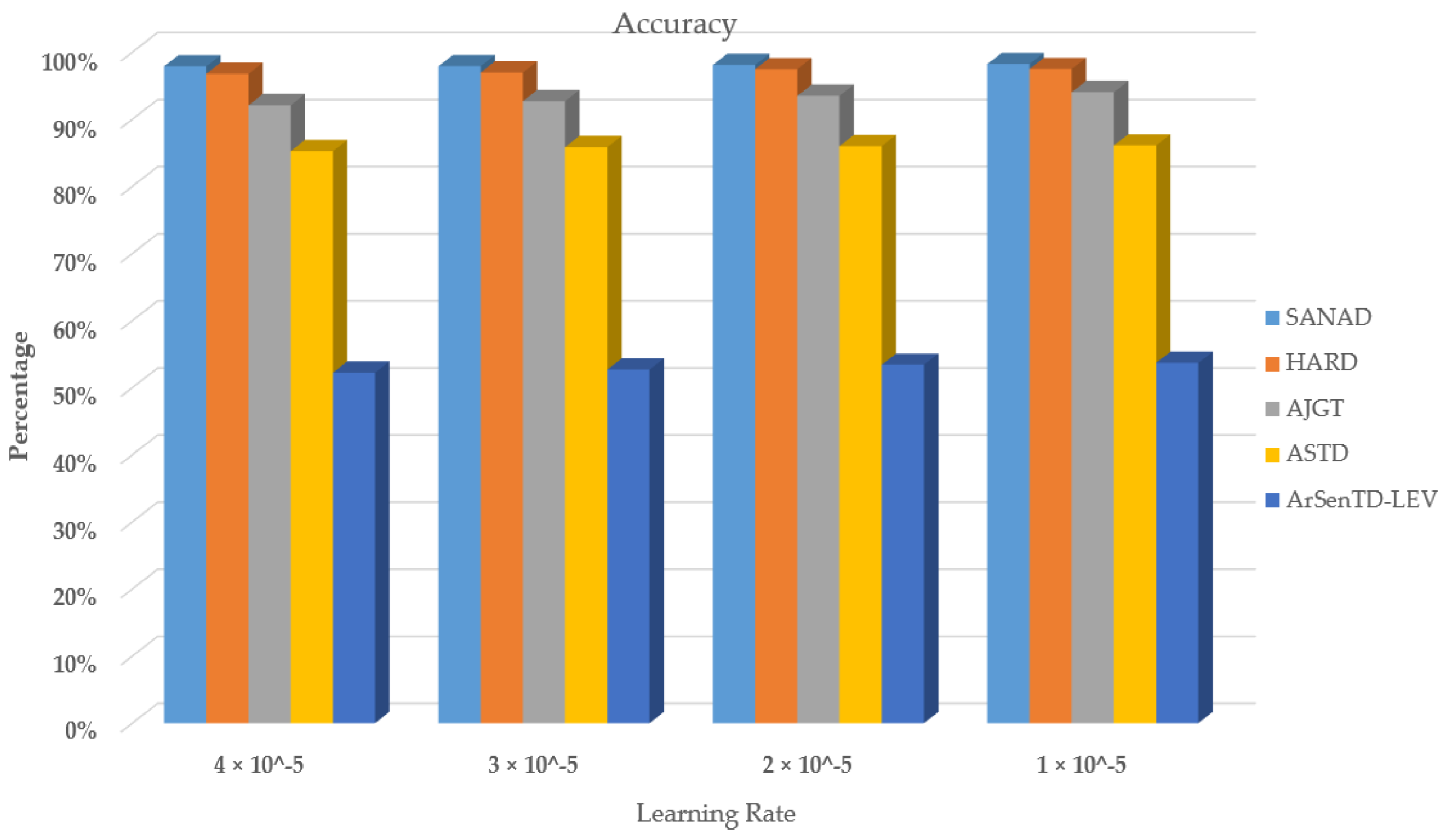
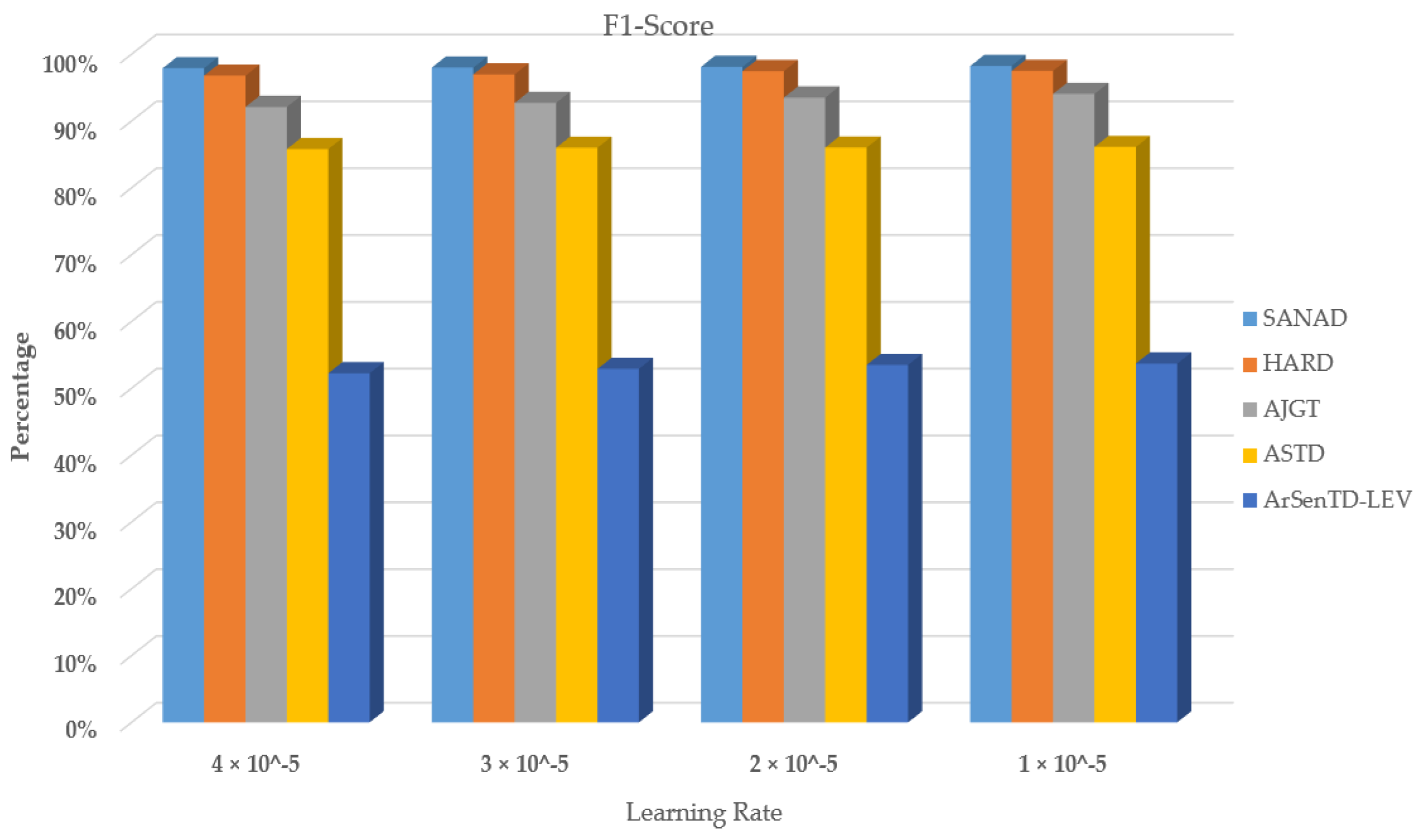
Table 1 summarizes the learning method used and the demerits of the existing methods applied in tweet or text classification systems. The major disadvantages of the existing methods are that neither the conventional methods nor the models, such as recurrent networks or convolutional networks, can provide more significance to keywords that are significant in text categorization. Contextual awareness between words plays a key role in a tweet or text classification. Another significant disadvantage of the existing methods is that they are tested on small Arabic text corpora, and accuracy is also impacted due to outliers in data.
3. Proposed Methodology
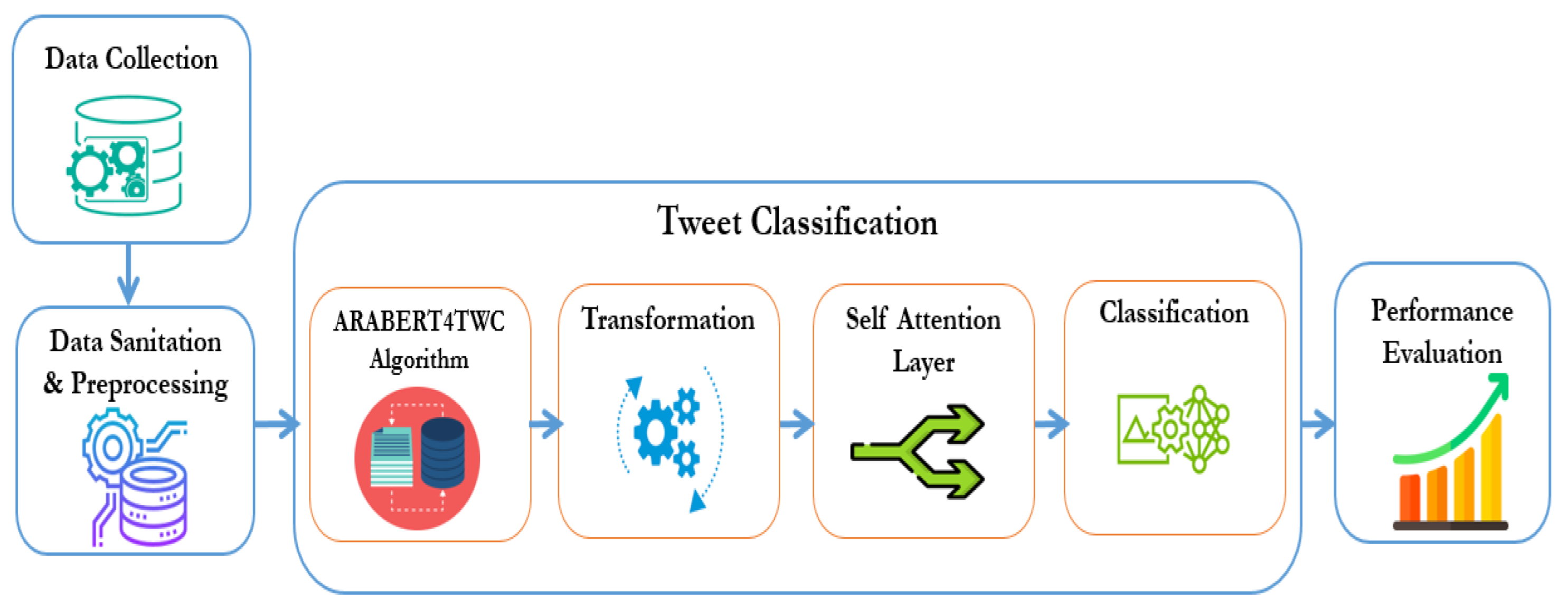
The proposed methodology and the architecture of the Arabic BERT model for tweet classification (ARABERT4TWC) are discussed in detail. The proposed methodology can be divided into four parts, as depicted in
Figure 1. The first benchmark datasets are collected from different sources [
35]. Second, data sanitation and preprocessing are performed on all the datasets collected. The sequence of tweet inputs is preprocessed before classification in batches using the word, segment, and positional embedding and converted to input vectors. Third, the input vectors obtained are passed through the custom-built Arabic BERT model (ARABERT4TWC). In the last step, we input this output into a linear network with two dense layers and a sigmoid activation function.
3.1. Data Sanitation and Preprocessing
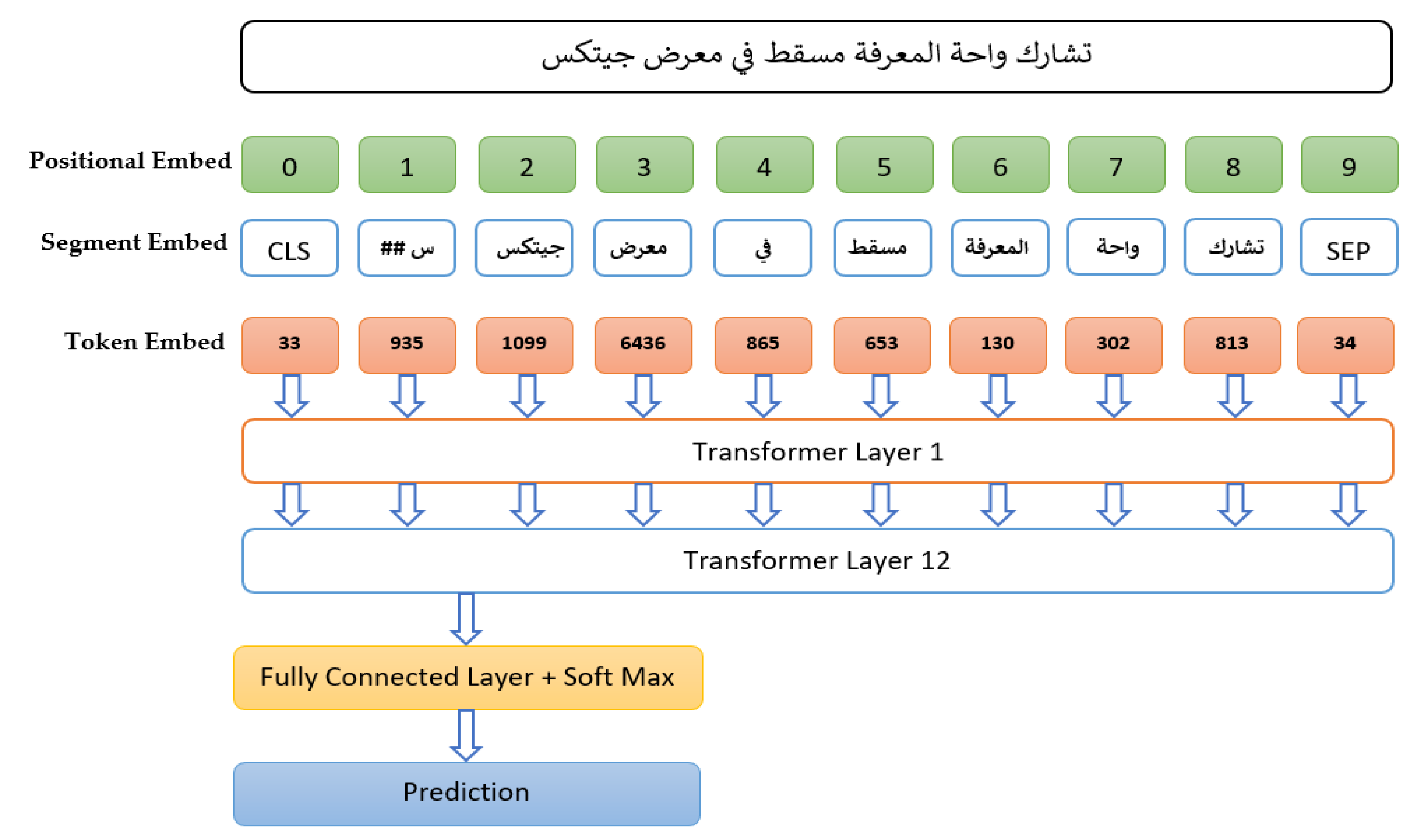
The data sanitation process removes Arabic stop words, punctuation, and extra spaces from the text corpus. Text normalization is not performed as it might alter the meaning of some words, such as “ball”. After performing data sanitation on the text corpus, the data preprocessing step is carried out to convert the input text sequence to the embedding vectors, which are obtained after merging the sub-word tokenization, segment embedding, and positional embedding into the input sequence. Special tokens [CLS] are added at the beginning of the input sequence, and the [SEP] token is used to separate a long sentence into a meaningful sentence. The input sequences are tokenized with a word-piece tokenizer. The word-piece tokenizer is based on the sub-word tokenization algorithm. Sub-word tokenization techniques are based on the idea that commonly employed phrases must be distinct from shorter sub-words. However, unique words should be deconstructed into meaningful sub-words when tokenizing them. After tokenization and using a word-piece tokenizer, the input sequences are represented numerically using token embedding. The BERT model discriminates between various phrases in a single input segment. Using this embedding vector, the values of each word in a sentence are the same, but the values vary when the phrase is changed. The positional embedding vectors are used to calculate the location of each word or the distances between distinct phrases in the sequences.
As presented in Algorithm 1, the tokenization algorithm is based on filling the vocabulary with the input text characters. Even if the vocabulary is less than the ideal vocabulary , the frequency of each pair of text is calculated, and then the most frequent pair of text is determined. A new unused pair of text is added to expand the vocabulary. The input text characters are divided into word segments then the process is repeated again for each text entry until the entire text document is finished.
| Algorithm 1: Tokenization Process |
|
Let
|
|
Let
|
|
Let
|
|
Let
|
| Step 1: | |
| Step 2: | |
| |
Count
|
| |
Find
|
| | Substitute |
| | Add to |
| Step 3: | Divide such that |
| Step 4: | Repeat Step two & Step three |
| Step 5: | Apply |
| Step 6: | Train |
3.2. Model Architecture
We constructed an Arabic BERT model for text classification from a pre-trained BERT model by fine-tuning the 109-million parameters with the labeled data. The network architecture of the constructed Arabic BERT model (AR-ABERT4TWC) is shown in
Figure 1. As presented in Algorithm 2, the input vector, which is a combination of token embedding, segment embedding, and positional embedding, has a shape of (
n, 768) where
n is the size of the input sequence length, and the model can take an input sequence up to 512 sizes. The custom BERT model consists of 12 encoder layers with 12 self-attention heads, which are bi-directional in nature, and 12 hidden layers. Each self-attention head in the encoders computes the key, value, and query for each input token in a sequence, which is then utilized to produce a weighted representation of the sequence. All the outputs obtained from self-attention heads in similar layers are merged and routed through a fully linked layer. Every layer is preceded by layer normalization and is linked with a skip connection. The final output is taken through the [CLS] token vector, and it is passed through the linear layer and finally through the
layer for classification. The final output of the classification model is to merge the output of the normalization process in both linear layer and
classification layer.
| Algorithm 2: ARABERT4TWC |
| 1 | Let |
| 2 | Let |
| 3 |
Let
|
| 4 | Input: BERT =
|
| 5 |
Let
|
| 6 |
Let
|
| 7 | Calculate |
| 8 | |
| 9 | |
| 10 | |
| 11 | Input: |
| 12 | Apply Encoder/Transformer Layers |
| 13 | SET ,
|
| 14 | |
| 15 | SET
|
| 16 | SET
|
| 17 | Merge Output |
| 18 | SET Output = Merge |
| 19 | Apply Layer Normalization for Every Layer |
| 20 | Link Layer Normalization with Skip Connection |
| 21 | |
| 22 | Pass Final Output through Linear Layer |
| 23 | Pass Final Output through Layer |
| 24 | |
3.3. Transformer-Based Model
In order to perform NLP tasks like language translation and text synthesis, this paper uses a neural network architecture for the proposed transformer-based model [
28]. The transformer model may consider the importance of different input components while making predictions as it is based on self-attention. In contrast to previous RNN models, which process input sequentially, the transformer model processes all input parts in parallel, allowing for faster training and inference. Each encoder and decoder in the transformer model has multiple layers of feed-forward and self-attentional neural networks. The input sequence is sent into the encoder, which creates hidden states. The decoder uses these hidden states to create the output sequence.
A key component of the transformer model is based on the mechanism of multi-head self-attention, which enables the model to attend to various input portions at various places. It is a crucial feature of the transformer model. This mechanism is implemented by computing multiple sets of key, value, and query vectors for each input token and then using them to compute a weighted sum of the input. Additionally, the transformer model includes skip connections and layer normalization, which help stabilize the training and improve the model ability to generate to new data. Overall, transformer-based models are considered successful in NLP tasks and have become the de facto standard in this field. They have been used in many recent models, such as BERT, GPT–2, and T5. Furthermore, the Hugging Face Transformer library’s BERT model was adjusted tuned for the classification task. The BERT model uses the pre-trained weights as a starting point, which can reduce the amount of labeled data required for fine-tuning and improve the model’s performance on the specific task. BERT uses a transformer architecture with multiple layers of self-attention and feed-forward neural networks. The BERT’s bidirectional nature, which takes into account the context before and after each token in the input sequence, is one of its key characteristics. BERT can comprehend a word’s meaning in the context of the complete phrase instead of only the context of the words that came before it. The pre-training of the BERT model was performed on a large corpus of text data. A masked language model for estimating the proportion of input tokens that are randomly masked is the goal of the pre-training. This helps the model to understand the relationships between words and their meanings.
3.4. Self-Attention Layer
In a self-attention layer, each word or token in a sequence is assigned a specified weight or importance score based on its significance to the other words in the sequence. These weights are then utilized to calculate a weighted sum of the input sequence, which is then used as the output of the layer. The impact of selecting only the important words instead of all the words depends on the dataset being applied and used. The majority of the information may be concentrated in only a few key words, so selecting only those important words may be sufficient to achieve high accuracy. In other cases, there may be important information distributed across multiple words, so selecting only a subset of words may lead to a loss of accuracy.
For each word in the phrase, self-attention enables it to see the words around it, allowing it to choose which words are most important to the present word’s meaning. Self-attention refers to the sentence’s tendency to focus on itself while deciding how to describe each of its tokens. To comprehend a single word’s meaning, one must know in what context that word is used, and that word is taken care of by the self-attention layer. The weights, which are matrices derived during model training, are multiplied by the input to produce the key, value, and query vectors for each input. Equation (1) represents how the input vectors are transformed when passed through the linear layers to get the key, value, and query vectors.
Figure 2 shows the process for obtaining the key, value, and query vectors. The Y represents the input, each row of the Y matrix is the embedding vectors, and WK, WQ, and WV are the weight matrices of key, query, and value.
The calculation of attention weights as
-normalized dot products for each pair of words is shown in Equation (1), where
is the attention weight,
is the query vector,
is the key vector, and
is the value vector.
3.5. Classification Layer
On top of the BERT, the encoder is a basic classifier, which does the classification. Let represent the range of all learnable BERT4TC parameters. The classification layer uses the vector to calculate likelihood distributions.
Let
be the likelihood distribution over the categorical labels
where
considered the target labels. The likelihood distribution is given as follows:
Let
be the ground truth of an input vector or sequence
. As the expected outcome, we choose the predicted label, which has a higher likelihood distribution as a result. The loss
is calculated by given formula:
We specify the size of the training batches with the batch size parameter. To prevent over fitting, the dropout regularization approach is employed, and the value is constantly maintained at 0.3. For our model ARABERT4TWC, we have used an Adam optimizer with default parameters = 0.9 and = 0.999.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}