
MM-ConvBERT-LMS: Detecting Malicious Web Pages via Multi-Modal Learning and Pre-Trained Model

Abstract
:1. Introduction
2. Related Work
2.1. Detection Methods Based on Single-Modal Features
2.2. Detection Methods Based on Hybrid Features
2.3. Motivation
3. Method
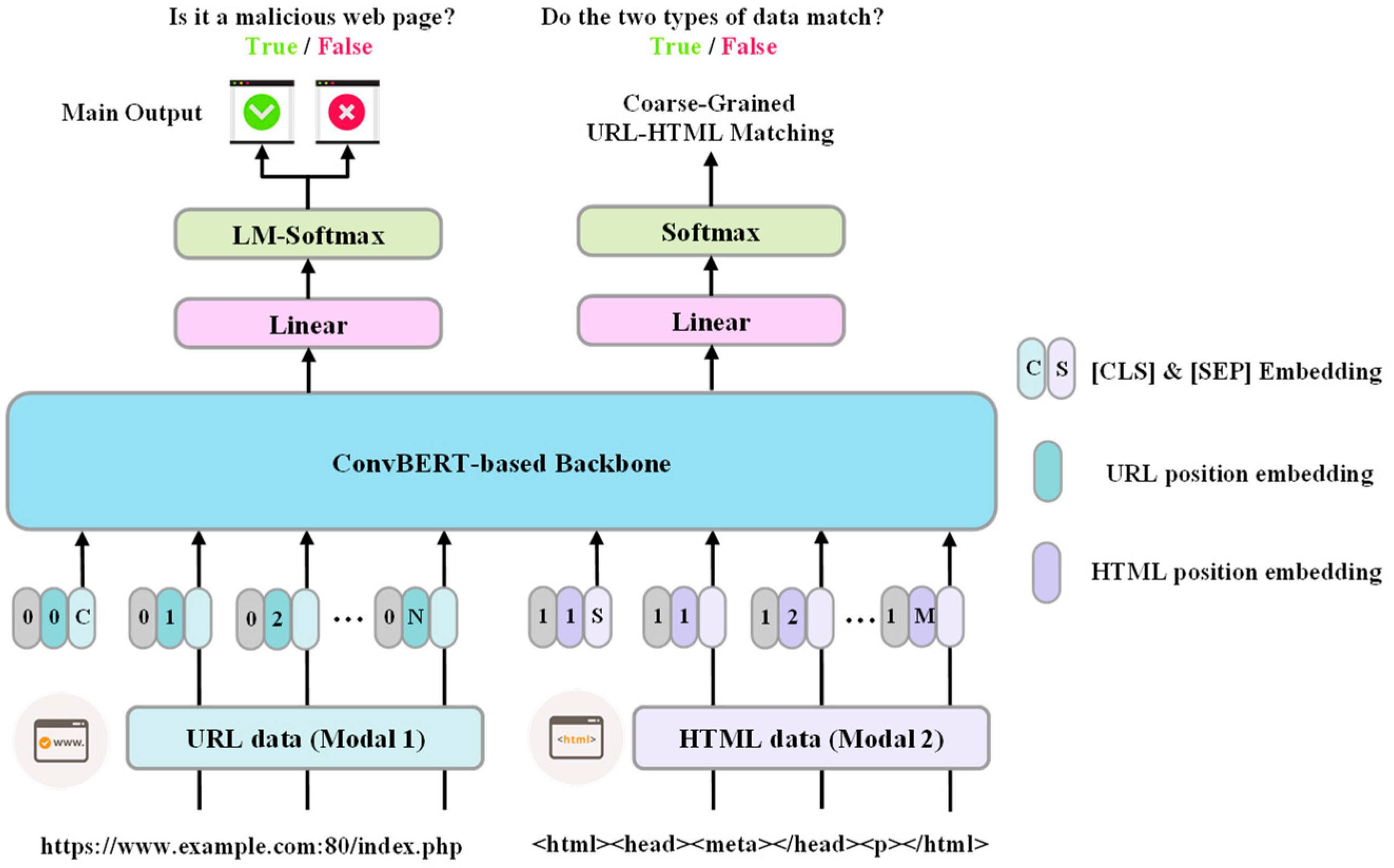
3.1. Overall Structure
3.2. Multi-Modal Input and Embedding
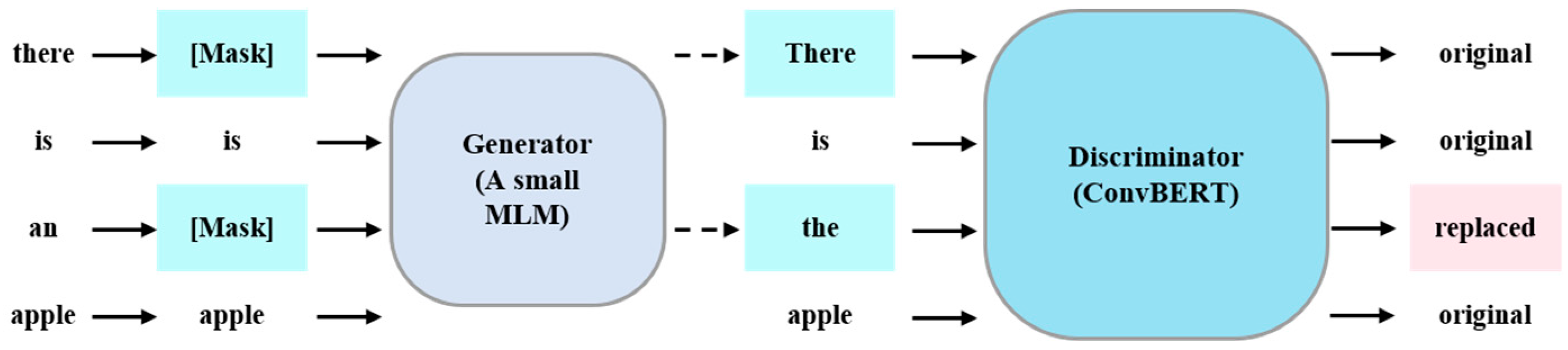
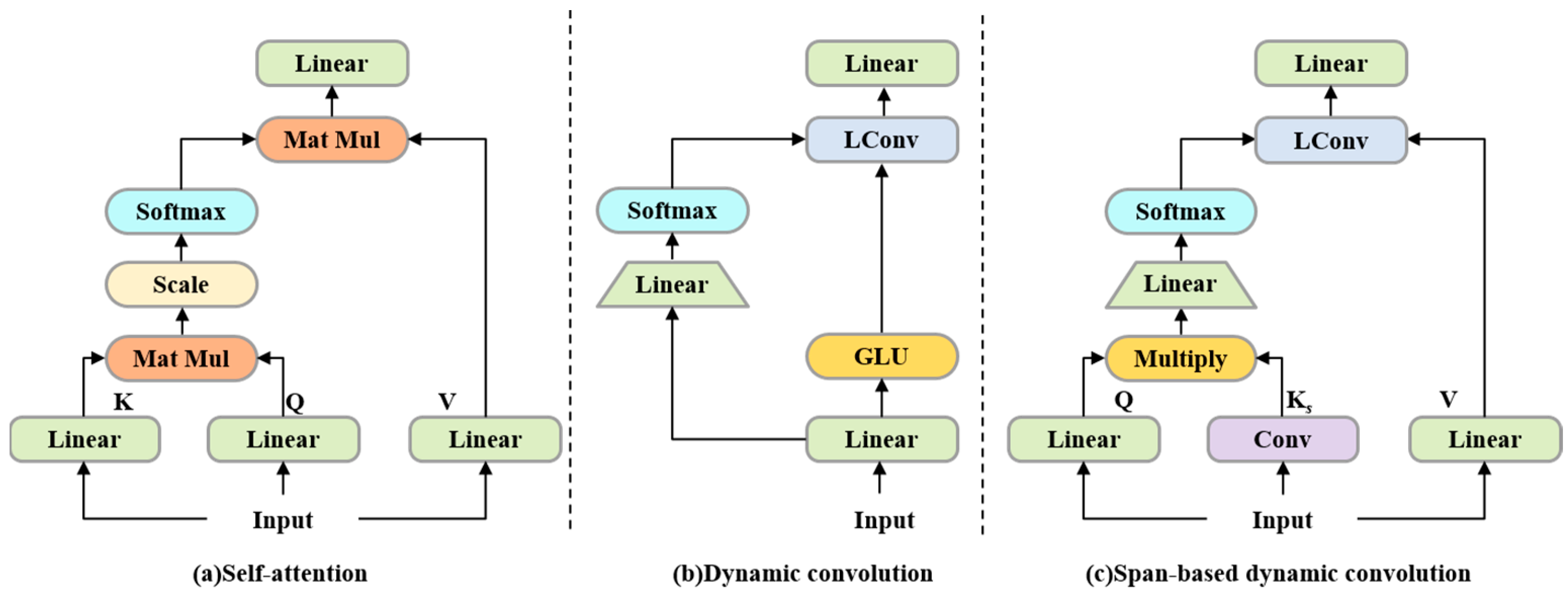
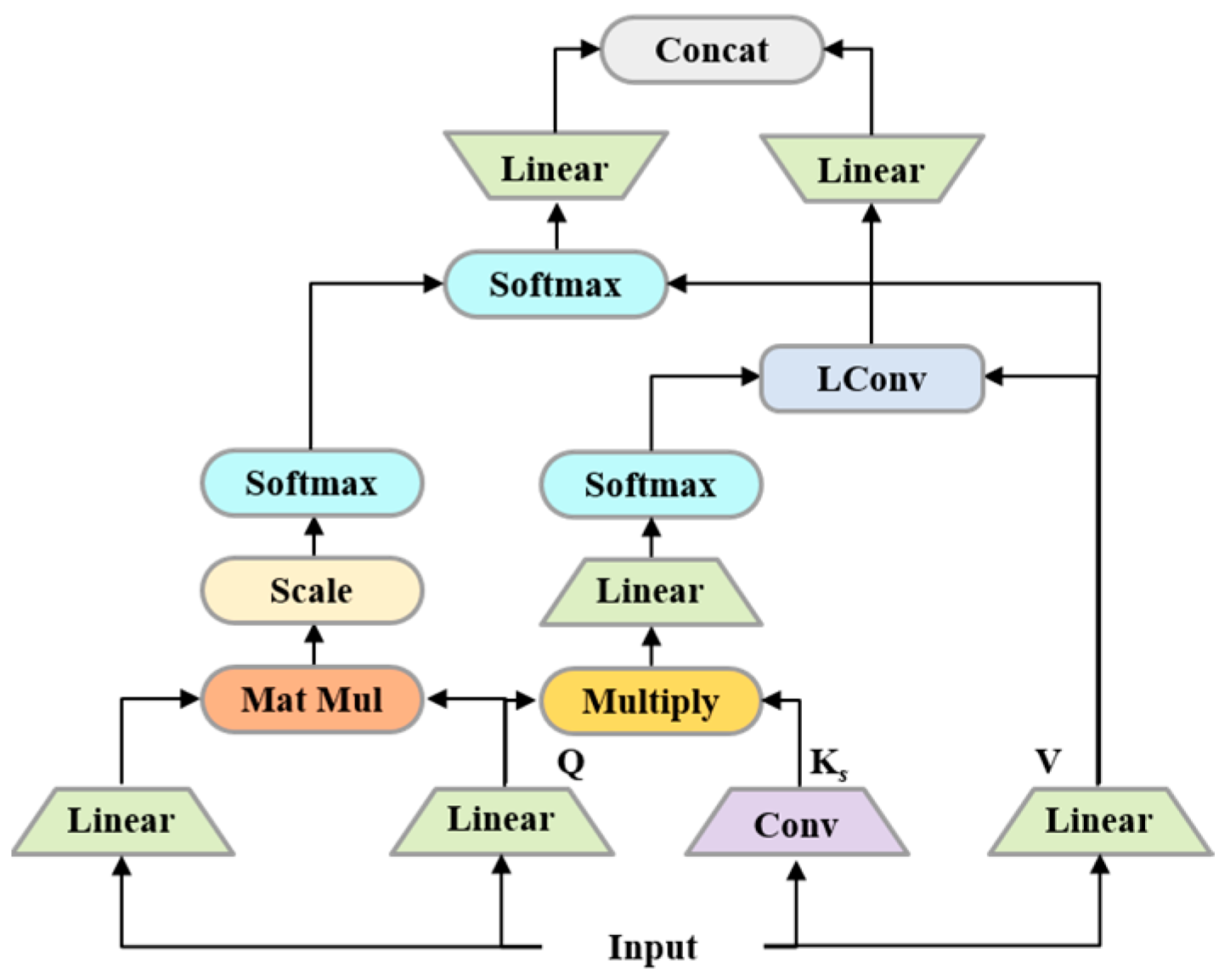
3.3. ConvBERT-Based Backbone Network
3.4. Multi-Task Optimization Objective
4. Experiment and Analysis
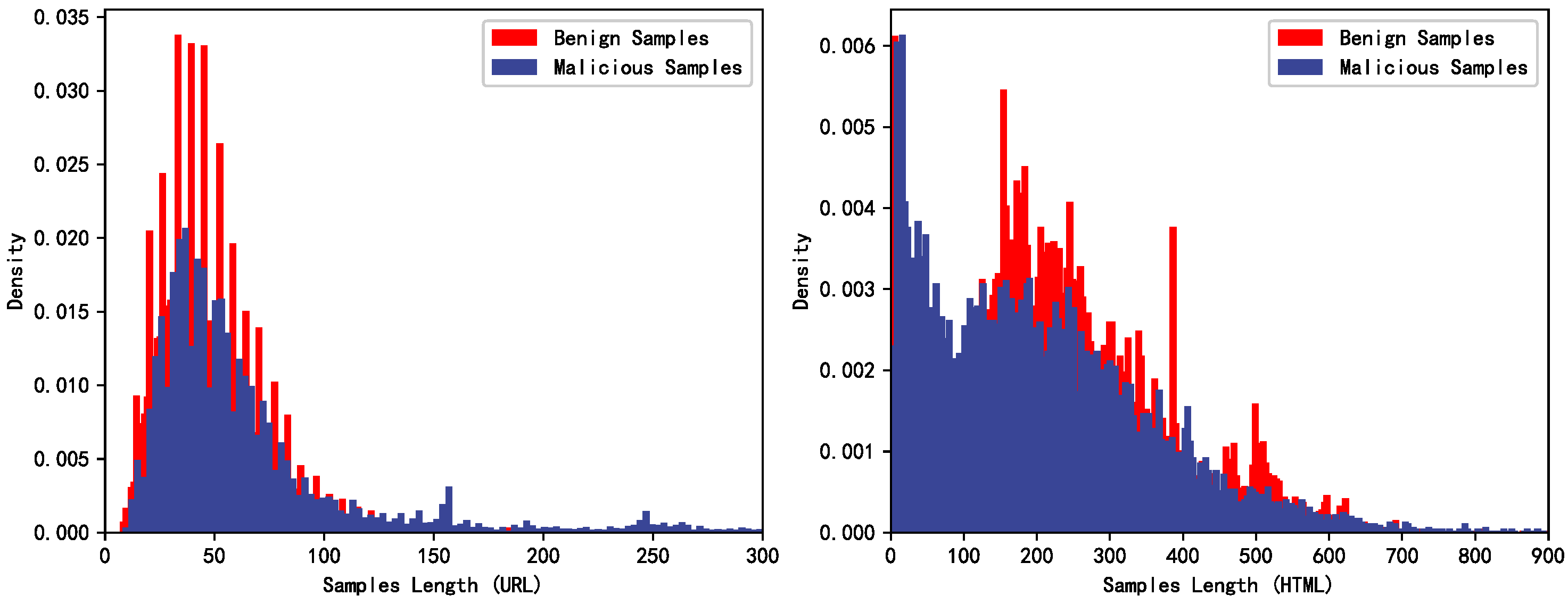
4.1. Experimental Datasets and Metrics
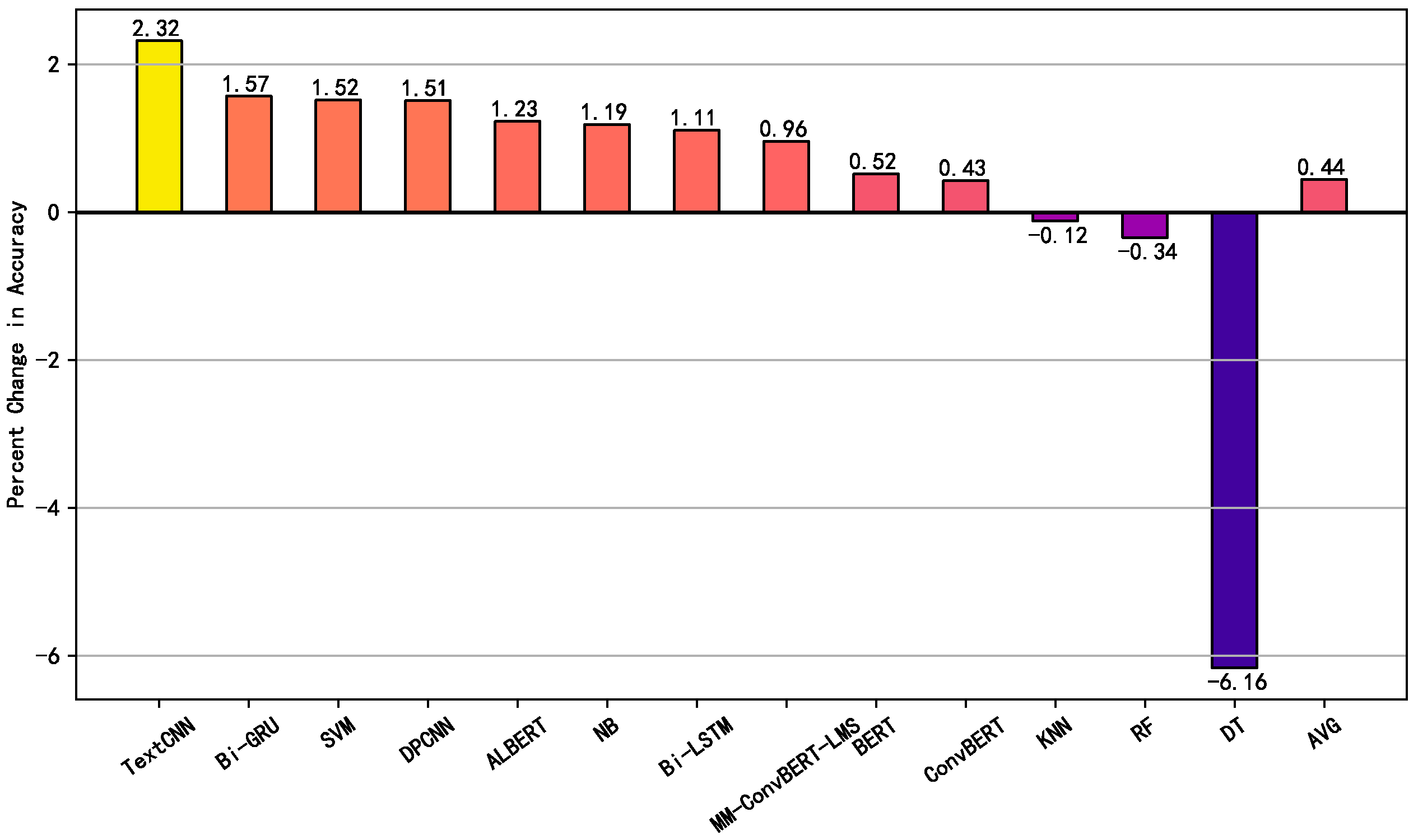
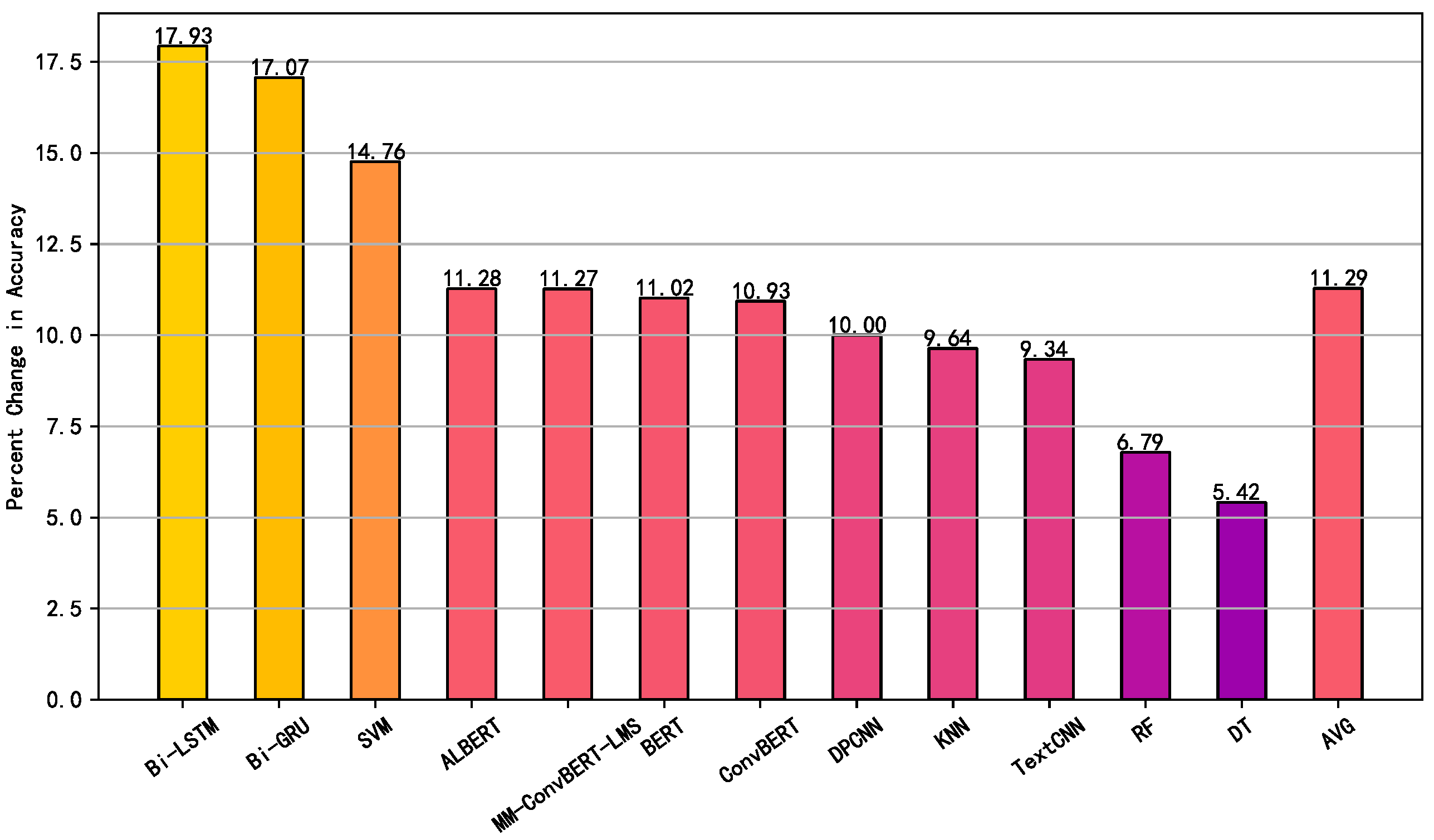
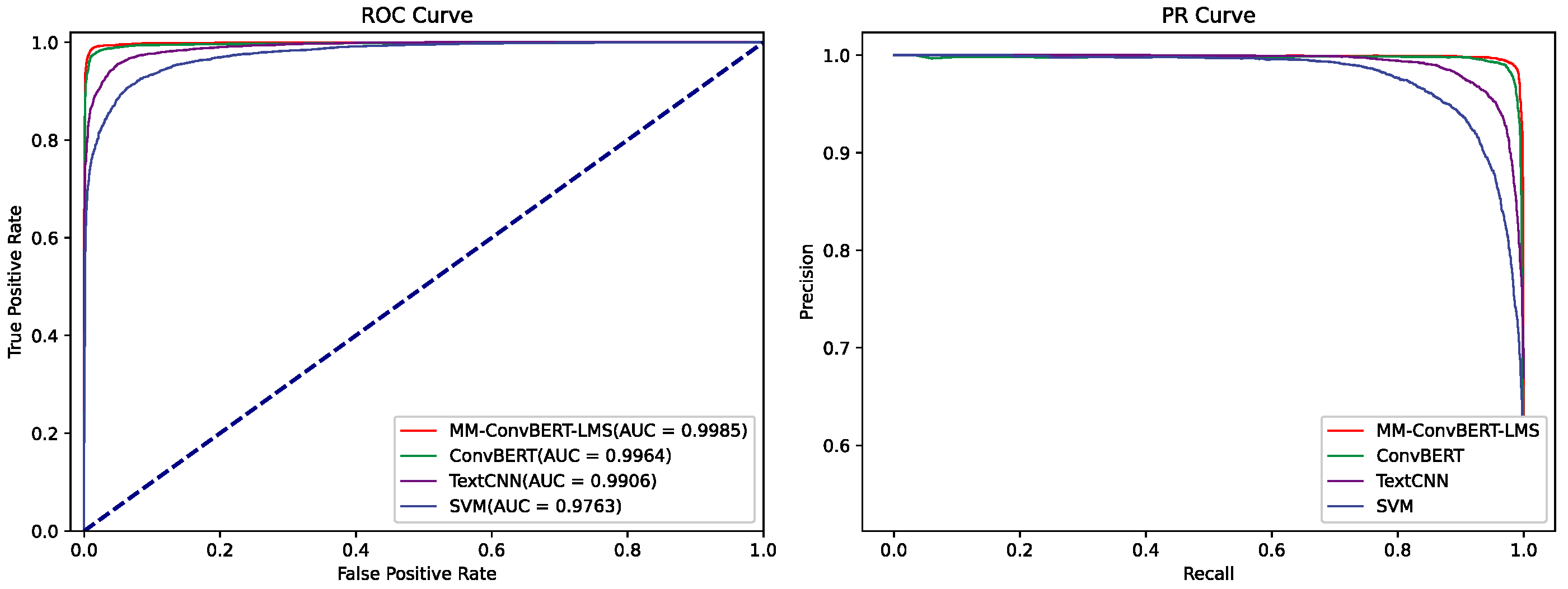
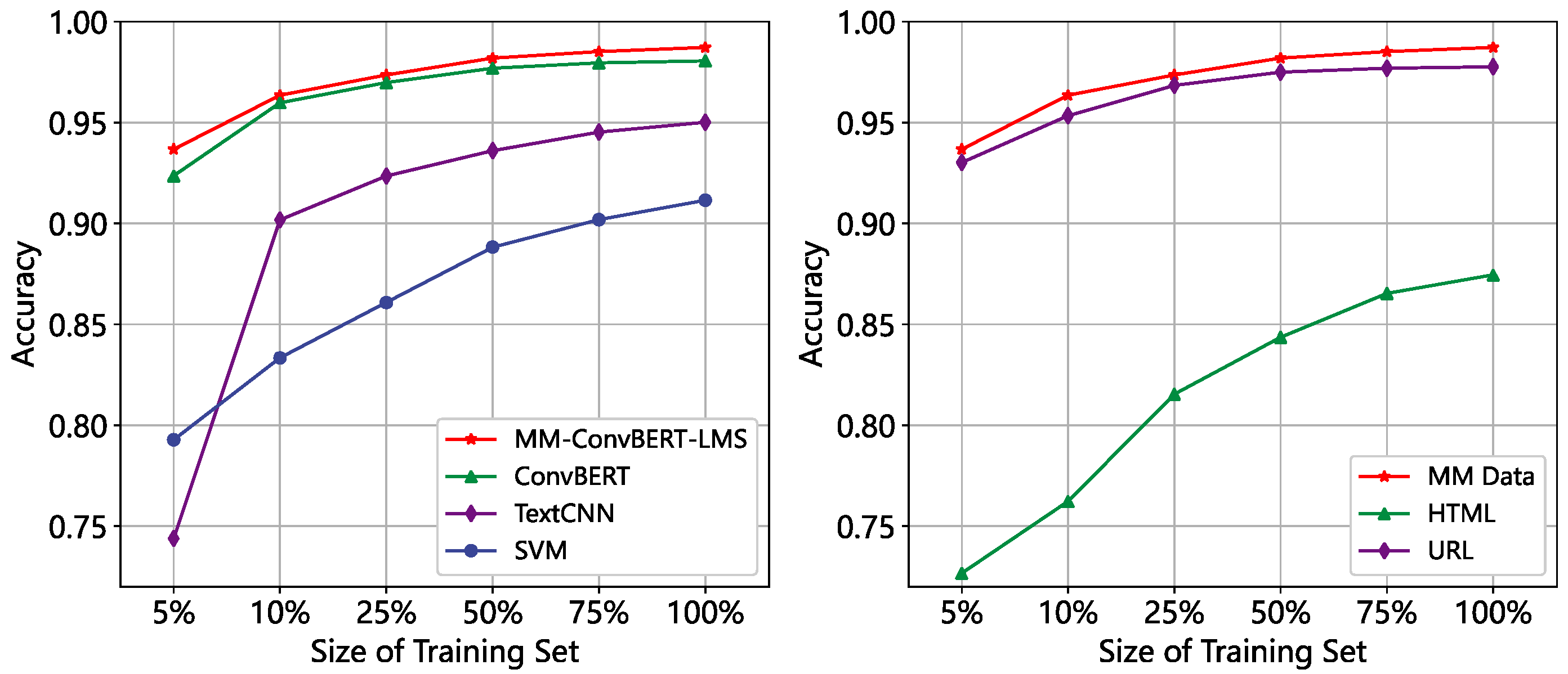
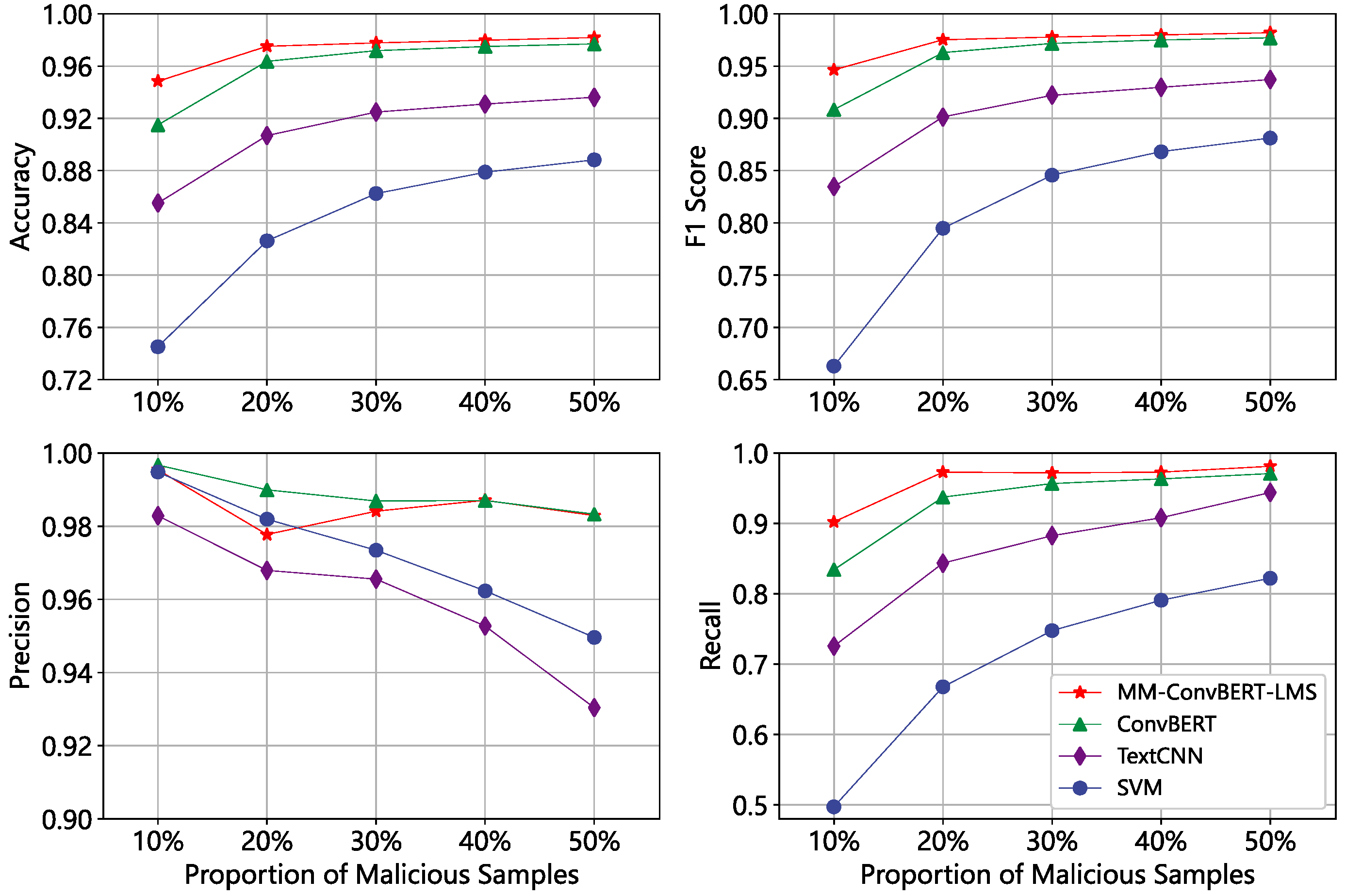
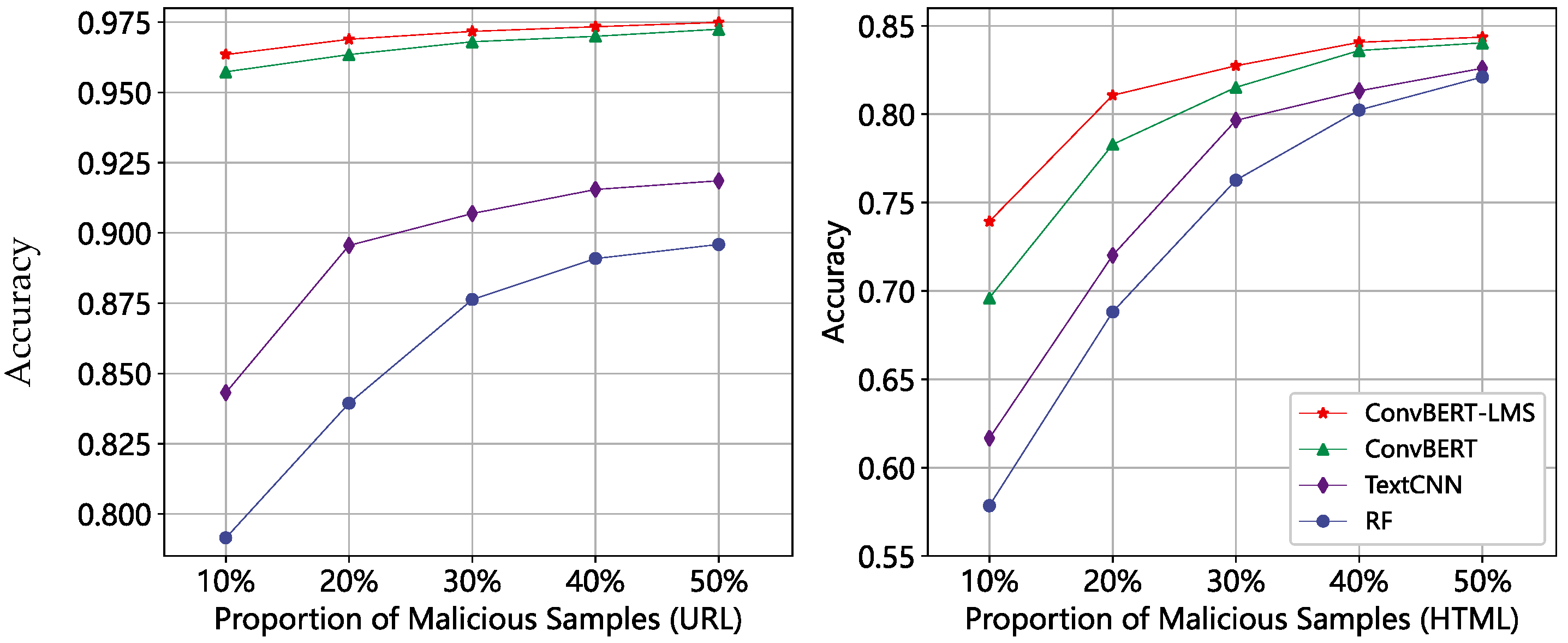
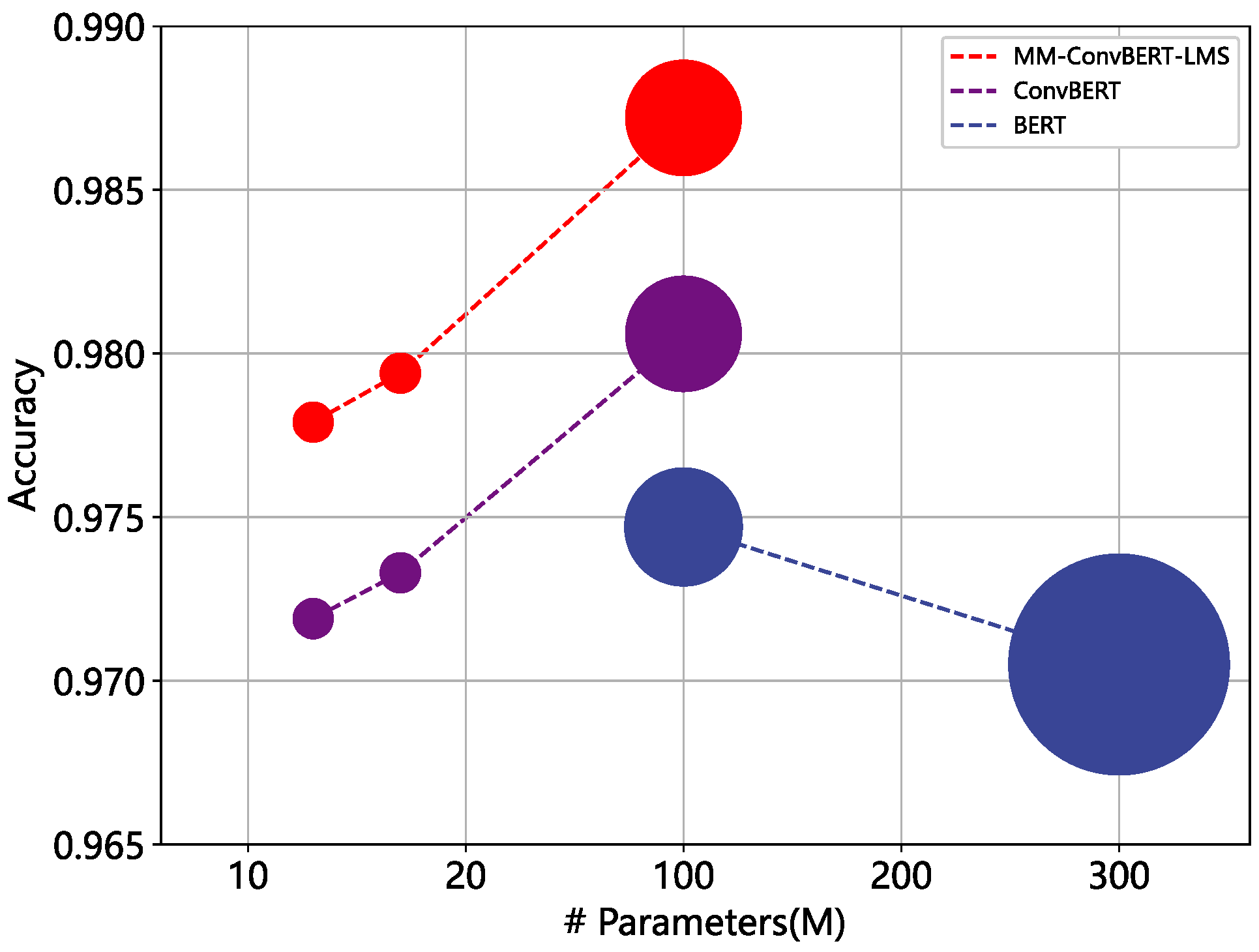
4.2. Comparative Experiment
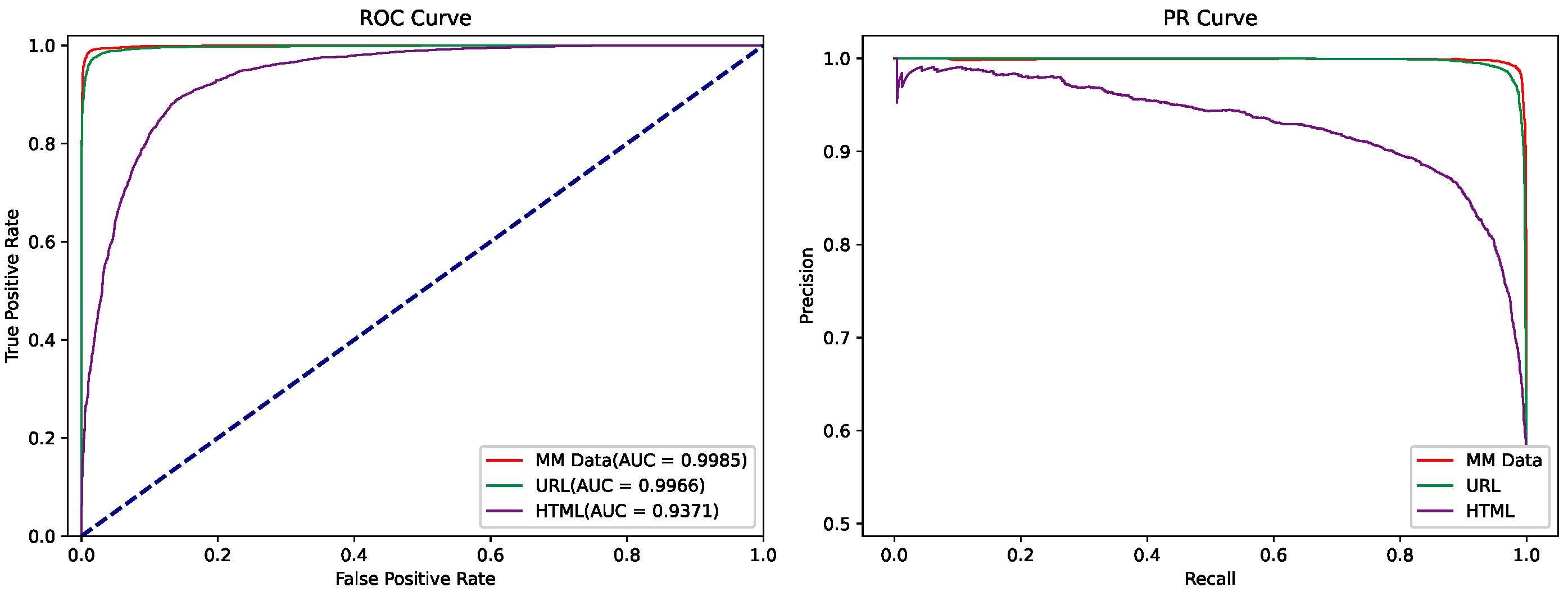
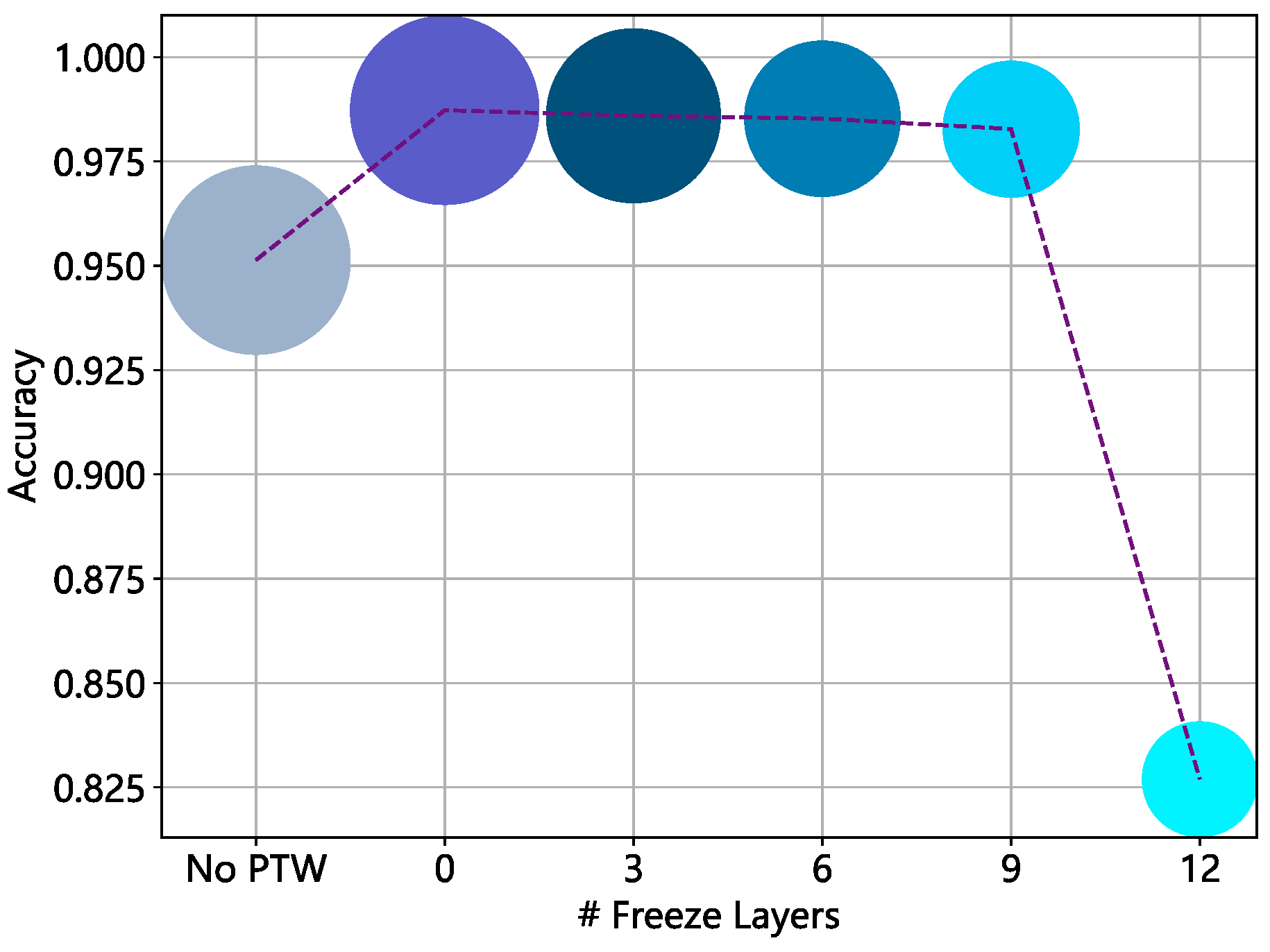
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Tutorial and critical analysis of phishing websites methods. Comput. Sci. Rev. 2015, 17, 1–24. [Google Scholar] [CrossRef] [Green Version]
- 2021 China Cybersecurity Report. Available online: http://it.rising.com.cn/dongtai/19858.html (accessed on 23 December 2022).
- Prakash, P.; Kumar, M.; Kompella, R.R.; Gupta, M. Phishnet: Predictive Blacklisting to Detect Phishing Attacks. In Proceedings of the 2010 IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010. [Google Scholar] [CrossRef]
- Chou, N. Client-side defense against web-based identity theft. In Proceedings of the 11th Annual Network and Distributed System Security Symposium (NDSS’04), San Diego, CA, USA, 24–27 February 2004. [Google Scholar]
- Nicomette, V.; Kaâniche, M.; Alata, E.; Herrb, M. Set-up and deployment of a high-interaction honeypot: Experiment and lessons learned. J. Comput. Virol. 2010, 7, 143–157. [Google Scholar] [CrossRef] [Green Version]
- Atrees, M.; Ahmad, A.; Alghanim, F. Enhancing Detection of Malicious URLs Using Boosting and Lexical Features. Intell. Autom. Soft Comput. 2022, 31, 1405–1422. [Google Scholar] [CrossRef]
- Wang, Z.; Ren, X.; Li, S.; Wang, B.; Zhang, J.; Yang, T. A Malicious URL Detection Model Based on Convolutional Neural Network. Secur. Commun. Netw. 2021, 2021, 5518528. [Google Scholar] [CrossRef]
- Yuan, J.; Liu, Y.; Yu, L. A Novel Approach for Malicious URL Detection Based on the Joint Model. Secur. Commun. Netw. 2021, 2021, 4917016. [Google Scholar] [CrossRef]
- Luo, C.; Su, S.; Sun, Y.; Tan, Q.; Han, M.; Tian, Z. A Convolution-Based System for Malicious URLs Detection. Comput. Mater. Contin. 2020, 62, 399–411. [Google Scholar] [CrossRef]
- Yan, X.; Xu, Y.; Cui, B.; Zhang, S.; Guo, T.; Li, C. Learning URL Embedding for Malicious Website Detection. IEEE Trans. Ind. Informatics 2020, 16, 6673–6681. [Google Scholar] [CrossRef]
- Khan, N.; Abdullah, J.; Khan, A.S. Defending Malicious Script Attacks Using Machine Learning Classifiers. Wirel. Commun. Mob. Comput. 2017, 2017, 5360472. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Cai, W.-D.; Wei, P.-C. A deep learning approach for detecting malicious JavaScript code. Secur. Commun. Netw. 2016, 9, 1520–1534. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Li, T.; Zhang, L.; Li, B.; Liu, X. JSContana: Malicious JavaScript detection using adaptable context analysis and key feature extraction. Comput. Secur. 2021, 104, 102218. [Google Scholar] [CrossRef]
- Alex, S.; Rajkumar, T.D. Spider bird swarm algorithm with deep belief network for malicious JavaScript detection. Comput. Secur. 2021, 107, 102301. [Google Scholar] [CrossRef]
- Fang, Y.; Huang, C.; Liu, L.; Xue, M. Research on Malicious JavaScript Detection Technology Based on LSTM. IEEE Access 2018, 6, 59118–59125. [Google Scholar] [CrossRef]
- Fang, Y.; Huang, C.; Su, Y.; Qiu, Y. Detecting malicious JavaScript code based on semantic analysis. Comput. Secur. 2020, 93, 101764. [Google Scholar] [CrossRef]
- Fang, Y.; Huang, C.; Zeng, M.; Zhao, Z.; Huang, C. JStrong: Malicious JavaScript detection based on code semantic representation and graph neural network. Comput. Secur. 2022, 118, 102715. [Google Scholar] [CrossRef]
- Phung, N.M.; Mimura, M. Detection of malicious javascript on an imbalanced dataset. Internet Things 2021, 13, 100357. [Google Scholar] [CrossRef]
- Hou, Y.-T.; Chang, Y.; Chen, T.; Laih, C.-S.; Chen, C.-M. Malicious web content detection by machine learning. Expert Syst. Appl. 2010, 37, 55–60. [Google Scholar] [CrossRef]
- Altay, B.; Dokeroglu, T.; Cosar, A. Context-sensitive and keyword density-based supervised machine learning techniques for malicious webpage detection. Soft Comput. 2018, 23, 4177–4191. [Google Scholar] [CrossRef]
- Kazemian, H.; Ahmed, S. Comparisons of machine learning techniques for detecting malicious webpages. Expert Syst. Appl. 2014, 42, 1166–1177. [Google Scholar] [CrossRef]
- Wang, R.; Zhu, Y.; Tan, J.; Zhou, B. Detection of malicious web pages based on hybrid analysis. J. Inf. Secur. Appl. 2017, 35, 68–74. [Google Scholar] [CrossRef]
- Deng, W.; Peng, Y.; Yang, F.; Song, J. Feature optimization and hybrid classification for malicious web page detection. Concurr. Comput. Pr. Exp. 2020, 34, e5859. [Google Scholar] [CrossRef]
- Amrutkar, C.; Kim, Y.S.; Traynor, P. Detecting Mobile Malicious Webpages in Real Time. IEEE Trans. Mob. Comput. 2016, 16, 2184–2197. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 13–23. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Wang, Y.; Shen, Y.; Liu, Z.; Liang, P.P.; Zadeh, A.; Morency, L.-P. Words Can Shift: Dynamically Adjusting Word Representations Using Nonverbal Behaviors. Proc. Conf. AAAI Artif. Intell. 2019, 33, 7216–7223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Qian, S.; Fang, Q.; Xu, C. Multi-Modal Meta Multi-Task Learning for Social Media Rumor Detection. IEEE Trans. Multimed. 2021, 24, 1449–1459. [Google Scholar] [CrossRef]
- Jiang, Z.H.; Yu, W.; Zhou, D.; Chen, Y.; Feng, J.; Yan, S. ConvBERT: Improving BERT with span-based dynamic convolution. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Virtual, 6–12 December 2020; pp. 12837–12848. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 5999–6009. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805, 2018. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555, 2020. [Google Scholar]
- Kobayashi, T. Large Margin In Softmax Cross-Entropy Loss. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019; p. 139. [Google Scholar]
- Saxe, J.; Sanders, H. Malware Data Science: Attack Detection and Attribution; No Starch Press: San Francisco, CA, USA, 2018; ISBN 978-159-327-859-5. [Google Scholar]
- Faizan, A. Using Machine Learning to Detect Malicious URLs. Available online: https://github.com/faizann24/Using-machine-learning-to-detect-malicious-URLs (accessed on 6 September 2022).
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942, 2019. [Google Scholar]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [Green Version]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Models | Prior Knowledge | Features | Feature Engineering | Multimodal Matching | Analysis |
|---|---|---|---|---|---|---|
| Atrees [6] | AdaBoost | ✗ | URL | ✓ | ✗ | Methods based on a single feature and statistical machine learning: 1. They perform well on small-scale datasets and are able to respond quickly to meet real-time requirements. 2. They require feature engineering, which can lead to additional data preprocessing costs and information loss. 3. Due to their relatively small number of model parameters, these models can quickly reach convergence on large-scale datasets, thereby entering a plain stage in a shorter time frame. 4. They mainly learn statistical features, which may be less effective in mining high-level semantic features. |
| Khan [11] | KNN et al. | ✗ | JS | ✓ | ✗ | |
| Hou [19] | Decision Tree | ✗ | HTML | ✓ | ✗ | |
| Wang [7] | Dynamic Conv. | ✗ | URL | ✗ | ✗ | Deep learning models based on a single feature and supervised learning: 1. It is proved that the representation ability of the deep learning models is stronger than the statistical machine learning models in malicious web page detection tasks. 2. Complex feature engineering is often not required. 3. Models’ performance may be limited in small data set scenarios due to a lack of prior knowledge. 4. The single-modal and multi-view work represented by the research [7] is enlightening for the method based on multimodal learning. |
| Luo [9] | Composite NN | ✗ | URL | ✓ | ✗ | |
| Alex [14] | DBN | ✗ | JS | ✓ | ✗ | |
| Yuan [8] | IndRNN + CapsNet | Word2Vec | URL | ✗ | ✗ | Deep learning models based on a single feature and mixed-supervised learning: 1. Pre-training with unsupervised learning can effectively leverage prior knowledge to improve the performance of these models on downstream tasks. 2. Static word embeddings generated by most methods struggle to handle polysemy. 3. JSContana [13] is inspired by the ELMo [25] model and employs a Bi-LSTM to transform word2vec into dynamic word embedding. However, the use of an LSTM-based backbone limits parallel computing, which negatively impacts training efficiency. 4. Most methods lack an attention mechanism that can assist the models in extracting more relevant features while filtering out noise. |
| Yan [10] | URL embed | ✗ | URL | ✗ | ✗ | |
| Wang [12] | SAE + LR | Layer-wise Pre-training | JS | ✓ | ✗ | |
| JSContana [13] | TextCNN | Word2Vec | JS | ✓ | ✗ | |
| Fang [15] | LSTM | Word2Vec | JS | ✓ | ✗ | |
| Fang [16] | Att-LSTM | fastText | JS | ✓ | ✗ | |
| JStrong [17] | GNN | Word2Vec | JS | ✓ | ✗ | |
| Doc2Vec [18] | SVM | Doc2Vec | JS | ✓ | ✗ | |
| Altay [20] | SVM et al. | ✗ | HTML | ✓ | ✗ | Statistical machine learning models based on mixed features: 1. It has been demonstrated that the integration of these hybrid features can significantly improve detection performance. 2. These approaches primarily concentrate on feature extraction. However, the complexity of the data can escalate the difficulty and cost of feature engineering, potentially leading to the curse of dimensionality. 3. Statistical machine learning models face inherent challenges in capturing correlations between different features, especially in the context of hybrid features. Furthermore, these models often lack auxiliary optimization objectives to facilitate the mining of information across modalities. |
| Kazemian [21] | SVM et al. | ✗ | Page Link, Screenshot, URL, Keywords | ✓ | ✗ | |
| Wang [22] | Decision Tree | ✗ | URL, HTML, JS | ✓ | ✗ | |
| Deng [23] | Rotation Forest | ✗ | Content, JS, URL | ✓ | ✗ | |
| kAYO [24] | SVM et al. | ✗ | URL, HTML, JS, Statistical features | ✓ | ✗ | |
| Ours | ConvBERT | Dynamic Embed. | URL + HTML | ✗ | ✓ | A method based on multimodal learning and pre-trained model: 1. This method accepts the raw URL string and HTML tag sequence directly as input and does not require any feature engineering. 2. To learn dynamic text embeddings using pre-training based on prior knowledge, ConvBERT was chosen as the backbone. 3. The model incorporates modal matching as an auxiliary task to enable cross-modal information learning. 4. The Transformer-based architecture is more suitable for parallel computing than sequential models such as LSTM. 5. The self-attention mechanism is used to better focus on meaningful features. |
| Device & Software | Information |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2690 v4 |
| RAM | 12 GB |
| External Storage | 512 GB SSD |
| Operating System | Ubuntu 18.04.3 LTS |
| Python Version | 3.8.8 (AMD64) |
| Machine Learning Library | Pytorch 1.11.0 |
| Methods | Models | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Machine Learning | NB | 88.72 | 97.52 | 79.64 | 87.68 |
| SVM | 89.63 | 95.27 | 83.57 | 89.04 | |
| KNN | 84.11 | 92.28 | 74.72 | 82.58 | |
| DT | 89.41 | 93.51 | 84.88 | 88.99 | |
| RF | 91.37 | 94.62 | 87.88 | 91.12 | |
| Deep Learning | Bi-LSTM | 92.49 | 94.97 | 89.86 | 92.34 |
| Bi-GRU | 92.18 | 93.50 | 90.79 | 92.13 | |
| TextCNN | 92.70 | 94.93 | 90.34 | 92.58 | |
| DPCNN | 92.38 | 94.10 | 90.56 | 92.30 | |
| ALBERT | 95.70 | 95.84 | 95.62 | 95.73 | |
| BERT | 96.95 | 97.08 | 96.87 | 96.97 | |
| ConvBERT | 97.63 | 97.66 | 97.64 | 97.65 | |
| ConvBERT-LMS(ours) | 97.76 | 97.93 | 97.62 | 97.77 |
| Methods | Models | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Machine Learning | SVM | 76.39 | 77.56 | 74.80 | 76.15 |
| KNN | 74.35 | 77.49 | 69.21 | 73.12 | |
| DT | 77.83 | 79.10 | 76.13 | 77.59 | |
| RF | 84.24 | 82.61 | 87.06 | 84.78 | |
| Deep Learning | Bi-LSTM | 75.67 | 75.94 | 75.71 | 75.83 |
| Bi-GRU | 76.68 | 79.67 | 72.14 | 75.72 | |
| TextCNN | 85.68 | 83.78 | 88.77 | 86.20 | |
| DPCNN | 83.89 | 85.64 | 81.75 | 83.65 | |
| ALBERT | 85.65 | 86.25 | 85.10 | 85.67 | |
| BERT | 86.45 | 86.81 | 86.21 | 86.51 | |
| ConvBERT | 87.13 | 87.02 | 87.52 | 87.27 | |
| ConvBERT-LMS(ours) | 87.45 | 86.71 | 88.69 | 87.69 |
| Methods | Models | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| Machine Learning | NB | 89.91 | 97.21 | 82.34 | 89.16 |
| SVM | 91.15 | 95.55 | 86.47 | 90.78 | |
| KNN | 83.99 | 91.03 | 75.69 | 82.66 | |
| DT | 83.25 | 84.40 | 81.90 | 83.13 | |
| RF | 91.03 | 92.23 | 89.76 | 90.98 | |
| Deep Learning | Bi-LSTM | 93.60 | 96.73 | 90.36 | 93.43 |
| Bi-GRU | 93.75 | 96.37 | 91.03 | 93.62 | |
| TextCNN | 95.02 | 96.38 | 93.63 | 94.99 | |
| DPCNN | 93.89 | 94.73 | 93.06 | 93.88 | |
| ALBERT * | 96.93 | 97.06 | 96.85 | 96.95 | |
| BERT | 97.47 | 97.65 | 97.32 | 97.49 | |
| ConvBERT | 98.06 | 98.29 | 97.86 | 98.07 | |
| MM-ConvBERT-LMS(ours) | 98.72 | 98.90 | 98.55 | 98.73 |
| Models | Version | Layers | Heads | Hidden Size | Parameters (M) |
|---|---|---|---|---|---|
| ConvBERT | Small | 12 | 4 | 128 | 13 |
| Medium-Small | 12 | 8 | 384 | 17 | |
| Base | 12 | 12 | 768 | 106 | |
| BERT | Base | 12 | 12 | 768 | 109 |
| Large | 24 | 16 | 1024 | 335 |
| Modules | Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| MM-ConvBERT-LMS | 98.72 | 98.90 | 98.55 | 98.73 | |
| The input modules | MM-ConvBERT-LMS w/o HTML | 96.42 (2.30 ↓) | 94.19 (4.71 ↓) | 99.01 (0.46 ↑) | 96.54 (2.19 ↓) |
| MM-ConvBERT-LMS w/o URL | 86.20 (12.52 ↓) | 86.81 (12.09 ↓) | 85.63 (12.92 ↓) | 86.22 (12.51 ↓) | |
| MM-ConvBERT-LMS w/o MTE | 98.41 (0.31 ↓) | 98.68 (0.22 ↓) | 98.15 (0.40 ↓) | 98.42 (0.31 ↓) | |
| MM-ConvBERT-LMS w/o MTE & HTML | 97.07 (1.65 ↓) | 96.06 (2.84 ↓) | 98.21 (0.34 ↓) | 97.13 (1.60 ↓) | |
| MM-ConvBERT-LMS w/o MTE & URL | 82.50 (16.22 ↓) | 82.46 (16.44 ↓) | 82.92 (15.63 ↓) | 82.69 (16.04 ↓) | |
| The output modules | MM-ConvBERT-LMS w/o modal-matching | 98.26 (0.46 ↓) | 98.43 (0.47 ↓) | 98.12 (0.43 ↓) | 98.27 (0.46 ↓) |
| MM-ConvBERT-LMS w/o LMS | 98.61 (0.11 ↓) | 98.42 (0.48 ↓) | 98.83 (0.28 ↑) | 98.62 (0.11 ↓) | |
| Main structure | Two-stream MM-ConvBERT-LMS | 98.63 (0.09 ↓) | 98.90 (0) | 98.37 (0.18 ↓) | 98.64 (0.09 ↓) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, X.; Jin, B.; Wang, J.; Yang, Y.; Suo, Q.; Wu, Y. MM-ConvBERT-LMS: Detecting Malicious Web Pages via Multi-Modal Learning and Pre-Trained Model. Appl. Sci. 2023, 13, 3327. https://doi.org/10.3390/app13053327
Tong X, Jin B, Wang J, Yang Y, Suo Q, Wu Y. MM-ConvBERT-LMS: Detecting Malicious Web Pages via Multi-Modal Learning and Pre-Trained Model. Applied Sciences. 2023; 13(5):3327. https://doi.org/10.3390/app13053327
Chicago/Turabian StyleTong, Xin, Bo Jin, Jingya Wang, Ying Yang, Qiwei Suo, and Yong Wu. 2023. "MM-ConvBERT-LMS: Detecting Malicious Web Pages via Multi-Modal Learning and Pre-Trained Model" Applied Sciences 13, no. 5: 3327. https://doi.org/10.3390/app13053327