

Body Shape-Aware Object-Level Outfit Completion for Full-Body Portrait Images

Abstract
:1. Introduction
2. Related Works
3. Methodology
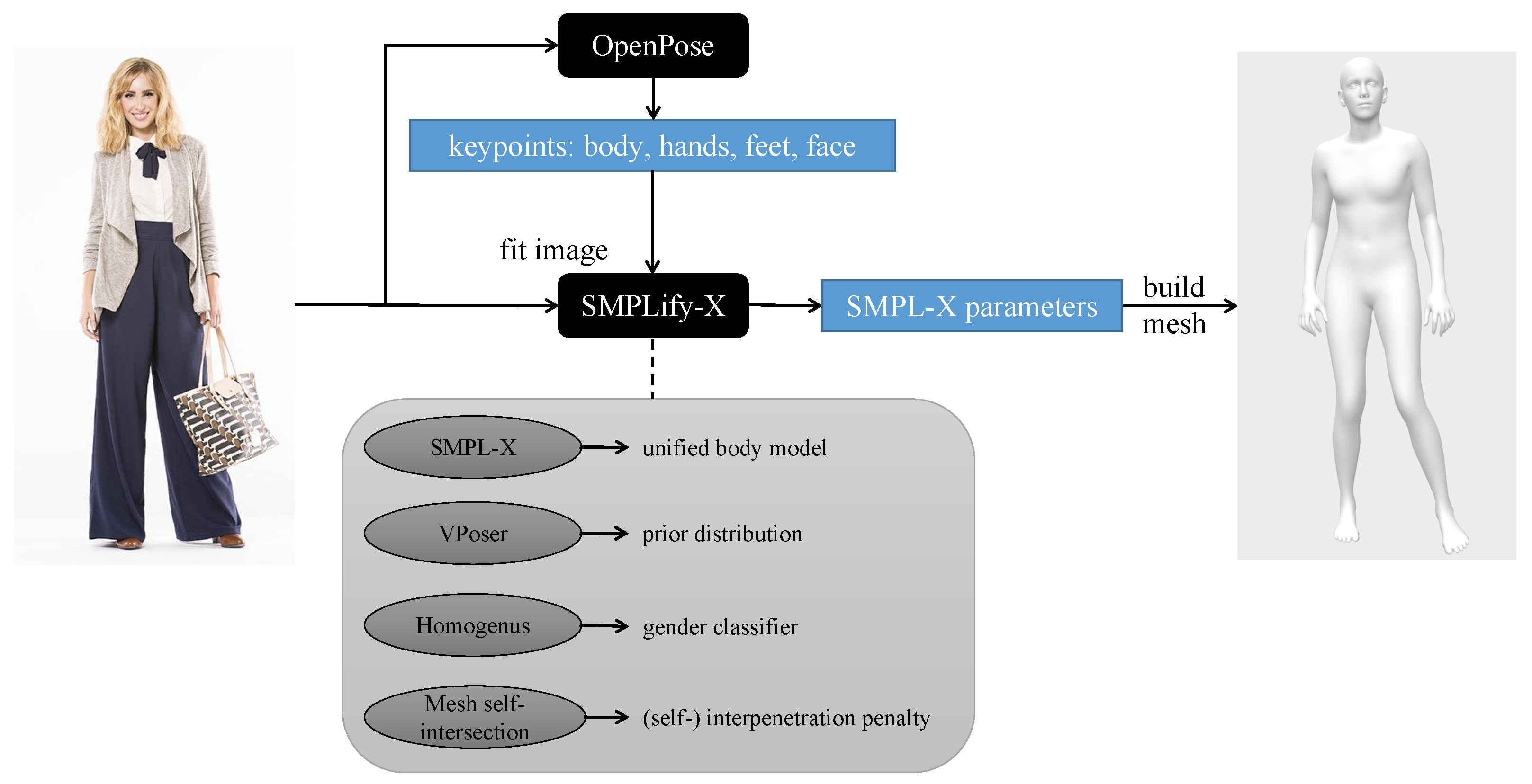
3.1. Data Processing
3.2. Image-Level Distance
3.3. Region-Level Distance
3.4. Object-Level Distance
3.5. Body-Shape Compatibility
3.6. Category Matching
3.7. Objective Function
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Comparison Models
- CF [6]: It learns embedding vectors for scenes and items without using visual features, and uses MF to compute the scene–item compatibility.
- ImageNet Features: The features extracted by ResNet-50 are directly used as scene/item embeddings, and distance is adopted to compute the scene–item compatibility.
- IBR [11]: Image-Based Recommendation (IBR) projects scenes and items into style space and computes the Mahalanobis distance between visual vectors.
- DVBPR [30]: Deep Visual-Aware Bayesian Personalized Ranking (DVBPR) trains CNN with BPR, where CNN is learned to extract visual features, and BPR is an extension of CF with pair-wise learning.
- ViBE [5]: It computes the squared distance between the item and the body embeddings, where the visual features and text information of items are used as item embeddings, and the body information extracted by SMPL together with the subject’s information are used as body embeddings. Since the text and the subject’s information are not available in our datasets, we only use the visual features and SMPL parameters.
- CTL [2]: It considers the global image-level and local region-level visual distances to obtain the scene–item compatibility.
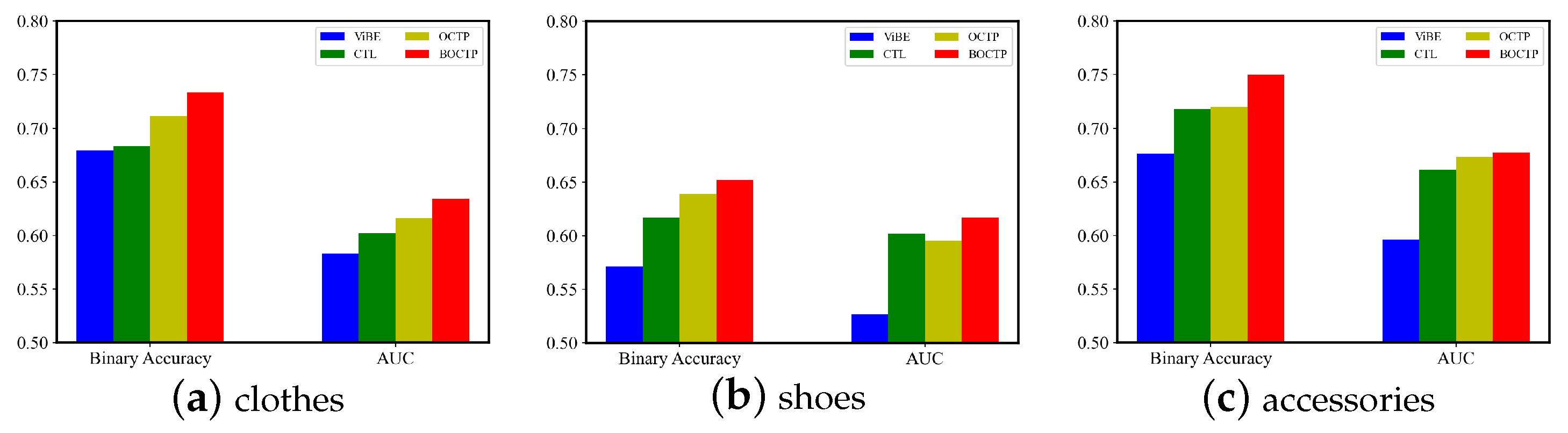
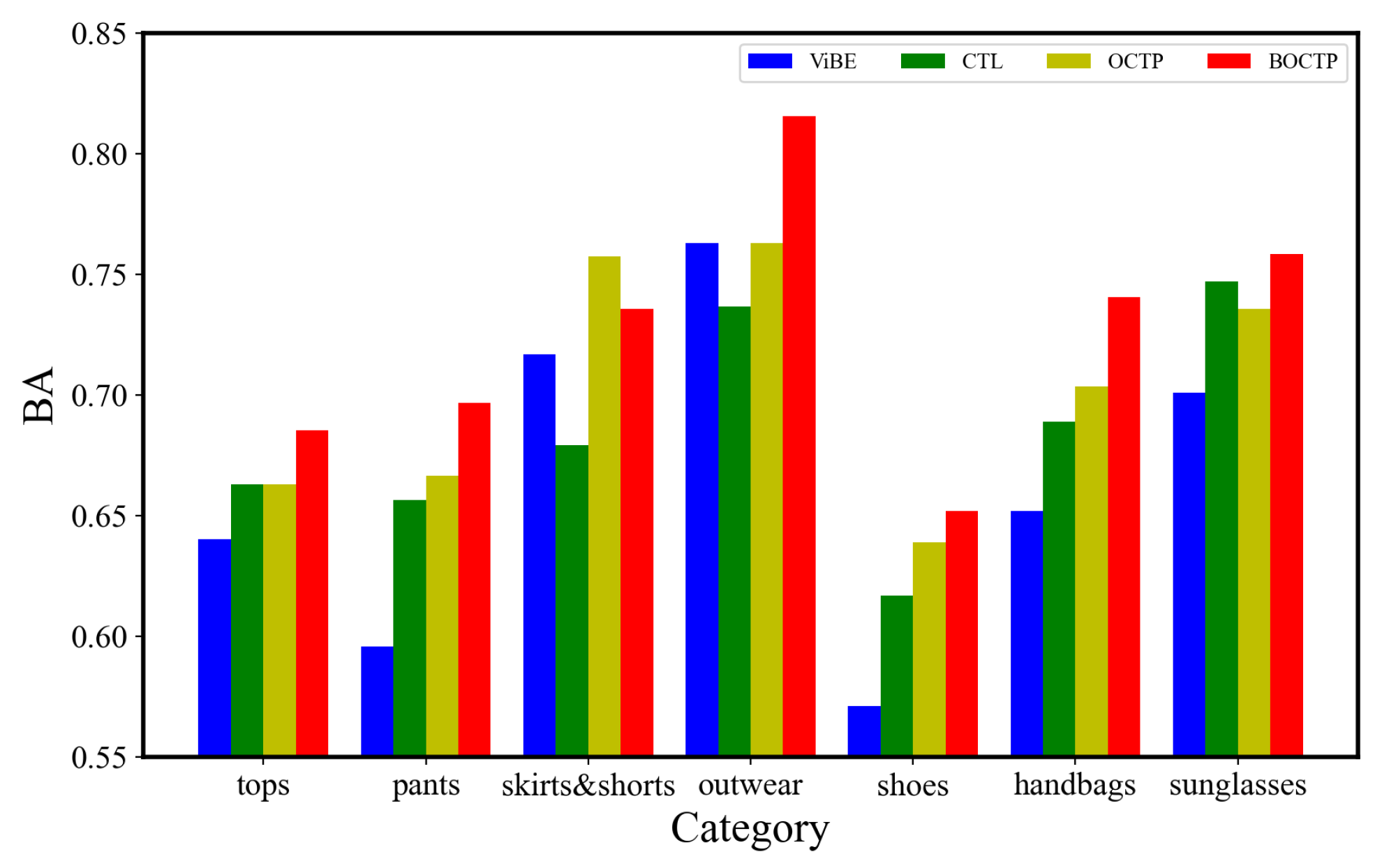
4.5. Non-Label-Given Completion
- HR and NDCG. Figure 7 shows the results of HR and NDCG on `all’ datasets. In contrast to AUC, which evaluates the overall ranking performance, HR and NDCG are to evaluate the top-ranked performance. The results are consistent with AUC, where BOCTP can outperform all the baselines. Figure 8 shows HR and NDCG on `clothes’ datasets, where BOCTP can outperform all the baselines in most cases, which are consistent with the results on `all’ datasets. Meanwhile, we can observe that BOCTP can better show its advantage over STL-Fashion, which is much larger than Street2Shop.
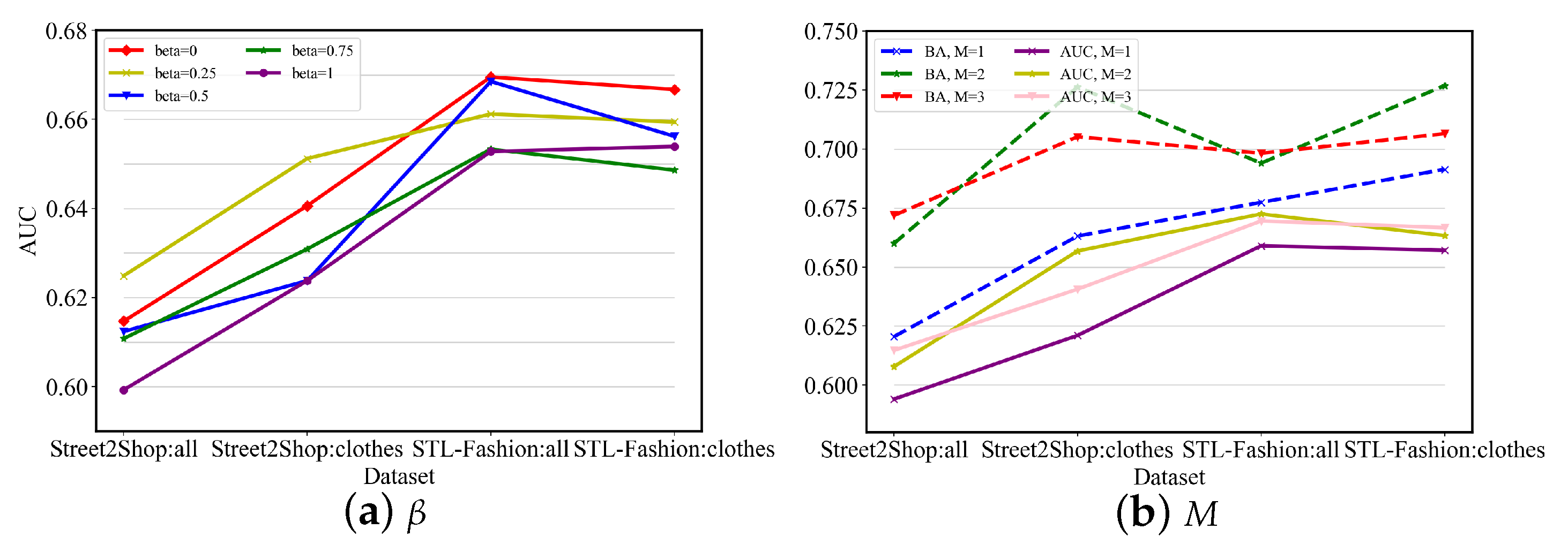
- Hyperparameters. Figure 9a shows the influence of . We found that will influence the results, but the changes in , and cannot improve the results. For a non-label-given task, a smaller can achieve a higher AUC. The goal of region-level distance is to use an attention mechanism to focus on the regions where the human subject appears, which is close to extracting the objects from the scene. The information learned by region-level and object-level distances is overlapped and sometimes conflicted. Hence, for training efficiency, we can simply keep object-level distance since it is more accurate and independent of the quality of the learned attention weights. Figure 9b shows the influence of changing the number M of objects. We do not perform experiments for since such data are scarce in Street2Shop and STL-Fashion datasets. We can observe that, for , or 3 can achieve the highest accuracy.
4.6. Label-Given Completion
4.7. Visualization
4.8. Training Epoch
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hadi Kiapour, M.; Han, X.; Lazebnik, S.; Berg, A.C.; Berg, T.L. Where to buy it: Matching street clothing photos in online shops. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3343–3351. [Google Scholar]
- Kang, W.C.; Kim, E.; Leskovec, J.; Rosenberg, C.; McAuley, J. Complete the look: Scene-based complementary product recommendation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 10532–10541. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference On Uncertainty in Artificial Intelligence, Montreal, QB, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Song, X.; Han, X.; Li, Y.; Chen, J.; Xu, X.S.; Nie, L. GP-BPR: Personalized Compatibility Modeling for Clothing Matching. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 320–328. [Google Scholar]
- Hsiao, W.L.; Grauman, K. ViBE: Dressing for Diverse Body Shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11059–11069. [Google Scholar]
- Schafer, J.B.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative filtering recommender systems. In The Adaptive Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 291–324. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Deng, Z.H.; Huang, L.; Wang, C.D.; Lai, J.H.; Philip, S.Y. Deepcf: A unified framework of representation learning and matching function learning in recommender system. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; Volume 33, pp. 61–68. [Google Scholar]
- Chen, J.; Wang, C.; Zhou, S.; Shi, Q.; Chen, J.; Feng, Y.; Chen, C. Fast Adaptively Weighted Matrix Factorization for Recommendation with Implicit Feedback. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 3470–3477. [Google Scholar]
- Wang, J.; Mei, H.; Li, K.; Zhang, X.; Chen, X. Collaborative Filtering Model of Graph Neural Network Based on Random Walk. Appl. Sci. 2023, 13, 1786. [Google Scholar] [CrossRef]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- He, R.; Packer, C.; McAuley, J. Learning compatibility across categories for heterogeneous item recommendation. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 937–942. [Google Scholar]
- Lin, Y.; Ren, P.; Chen, Z.; Ren, Z.; Ma, J.; de Rijke, M. Improving outfit recommendation with co-supervision of fashion generation. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1095–1105. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances In Neural Information Processing Systems, Montreal, QB, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Liu, K.; Chen, Y.; Tang, J.; Huang, H.; Liu, L. Self-Attentive Subset Learning over a Set-Based Preference in Recommendation. Appl. Sci. 2023, 13, 1683. [Google Scholar] [CrossRef]
- Zuo, Y.; Liu, S.; Zhou, Y.; Liu, H. TRAL: A Tag-Aware Recommendation Algorithm Based on Attention Learning. Appl. Sci. 2023, 13, 814. [Google Scholar] [CrossRef]
- Han, X.; Wu, Z.; Jiang, Y.G.; Davis, L.S. Learning fashion compatibility with bidirectional lstms. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1078–1086. [Google Scholar]
- Singhal, A.; Chopra, A.; Ayush, K.; Govind, U.P.; Krishnamurthy, B. Towards a Unified Framework for Visual Compatibility Prediction. In Proceedings of the The IEEE Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 3607–3616. [Google Scholar]
- Kuang, Z.; Gao, Y.; Li, G.; Luo, P.; Chen, Y.; Lin, L.; Zhang, W. Fashion retrieval via graph reasoning networks on a similarity pyramid. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3066–3075. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. 2015, 34, 1–16. [Google Scholar] [CrossRef]
- Zhu, H.; Zuo, X.; Wang, S.; Cao, X.; Yang, R. Detailed human shape estimation from a single image by hierarchical mesh deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4491–4500. [Google Scholar]
- Kolotouros, N.; Pavlakos, G.; Black, M.J.; Daniilidis, K. Learning to reconstruct 3D human pose and shape via model-fitting in the loop. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2252–2261. [Google Scholar]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.; Tzionas, D.; Black, M.J. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10975–10985. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision And Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zheng, S.; Yang, F.; Kiapour, M.H.; Piramuthu, R. Modanet: A large-scale street fashion dataset with polygon annotations. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1670–1678. [Google Scholar]
- Ge, Y.; Zhang, R.; Wang, X.; Tang, X.; Luo, P. Deepfashion2: A versatile benchmark for detection, pose estimation, segmentation and re-identification of clothing images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5337–5345. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Kang, W.C.; Fang, C.; Wang, Z.; McAuley, J. Visually-aware fashion recommendation and design with generative image models. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 207–216. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Images | Categories |
|---|---|---|
| ModaNet | 55 K | bag, belt, headwear, sunglasses, scarf&tie, top, pants, shorts, skirt, outer, dress, boots, footwear |
| DeepFashion2 | 491 K | short sleeve top, long sleeve top, short sleeve outwear, long sleeve outwear, vest, sling, shorts, trousers, skirt, short sleeve dress, long sleeve dress, vest dress, sling dress |
| Dataset | #Pairs | Categories |
|---|---|---|
| Street2Shop | 2533 | footwear, dresses, tops, skirts, pants, leggings, outerwear, bags, hats, belts, eyewear |
| STL-Fashion | 9619 | shoes, shirts&tops, shorts, skirts, pants, coats&jackets, handbags&wallets&cases, sunglasses, necklaces, earrings |
| Method | Street2Shop | ||||
|---|---|---|---|---|---|
| All | Clothes | ||||
| BA | AUC | BA | AUC | ||
| a | CF | 0.4861 | 0.4876 | 0.4421 | 0.4543 |
| b | ImageNet Features | 0.5019 | 0.5020 | 0.4842 | 0.4620 |
| c | IBR | 0.5256 | 0.5207 | 0.5578 | 0.5402 |
| d | DVBPR | 0.5533 | 0.5284 | 0.5684 | 0.5473 |
| e | ViBE | 0.6007 | 0.5613 | 0.6526 | 0.5526 |
| f | CTL | 0.6284 | 0.5944 | 0.6631 | 0.6082 |
| g | OCTP (ours) | 0.6442 | 0.6078 | 0.6842 | 0.6096 |
| h | BOCTP (ours) | 0.6719 | 0.6147 | 0.7263 | 0.6568 |
| imp | h vs f | 6.92% | 3.41% | 9.53% | 7.99% |
| Method | STL-Fashion | ||||
|---|---|---|---|---|---|
| All | Clothes | ||||
| BA | AUC | BA | AUC | ||
| a | CF | 0.5192 | 0.5055 | 0.4609 | 0.4563 |
| b | ImageNet Features | 0.5078 | 0.5114 | 0.5354 | 0.5172 |
| c | IBR | 0.5723 | 0.5477 | 0.5638 | 0.5410 |
| d | DVBPR | 0.5015 | 0.5010 | 0.5496 | 0.5133 |
| e | ViBE | 0.6116 | 0.5613 | 0.6315 | 0.5609 |
| f | CTL | 0.6357 | 0.6223 | 0.6418 | 0.5993 |
| g | OCTP (ours) | 0.6940 | 0.6630 | 0.6843 | 0.6552 |
| h | BOCTP (ours) | 0.6982 | 0.6725 | 0.7269 | 0.6667 |
| imp | h vs f | 9.83% | 8.06% | 13.25% | 11.24% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chong, X.; Leung, H. Body Shape-Aware Object-Level Outfit Completion for Full-Body Portrait Images. Appl. Sci. 2023, 13, 3214. https://doi.org/10.3390/app13053214
Chong X, Leung H. Body Shape-Aware Object-Level Outfit Completion for Full-Body Portrait Images. Applied Sciences. 2023; 13(5):3214. https://doi.org/10.3390/app13053214
Chicago/Turabian StyleChong, Xiaoya, and Howard Leung. 2023. "Body Shape-Aware Object-Level Outfit Completion for Full-Body Portrait Images" Applied Sciences 13, no. 5: 3214. https://doi.org/10.3390/app13053214