
A Semi-Supervised Learning Framework for Machining Feature Recognition on Small Labeled Sample



Abstract
:1. Introduction
2. Related Work
2.1. Rule-Based Approach
2.2. ANN-Based Approach
2.3. DNN-Based Approach
- We propose a semi-supervised learning framework to improve recognition on small samples. MsvNetLite and FeatureNetLite with semi-supervised learning surpassed their counterparts (MsvNet and FeatureNet) in machining feature classification, demonstrating the effectiveness of the proposed approaches.
- We use lightweight compressing techniques to reduce nearly 99% parameters and 98% computational complexity. Both MsvNetLite and FeatureNetLite achieved significant reductions in parameters and FLOPs compared to their counterparts, proving the efficiency of the proposed approaches in model scale and inference speed.
3. Methodology
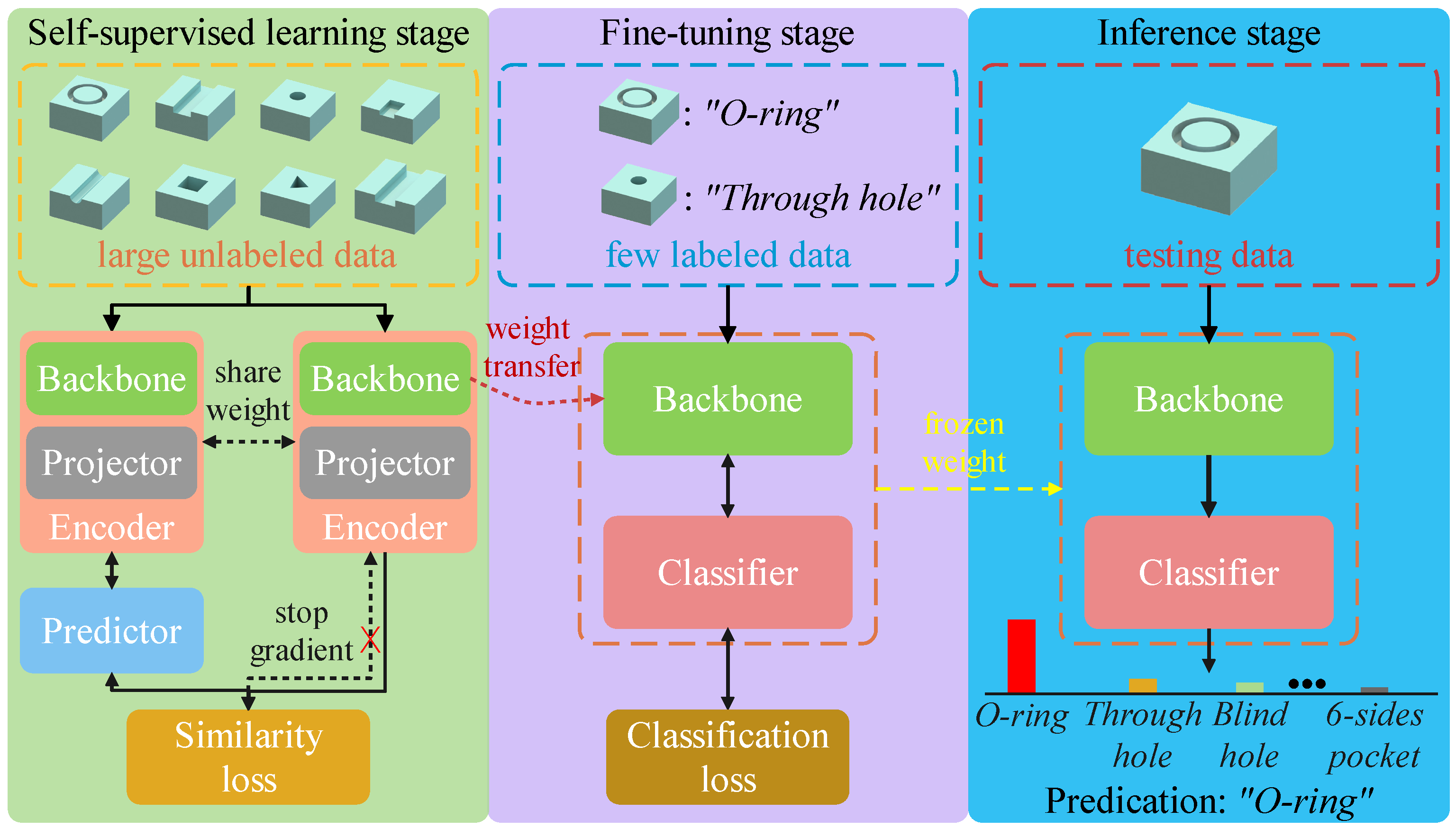
3.1. Semi-Supervised Machining Feature Recognition Framework
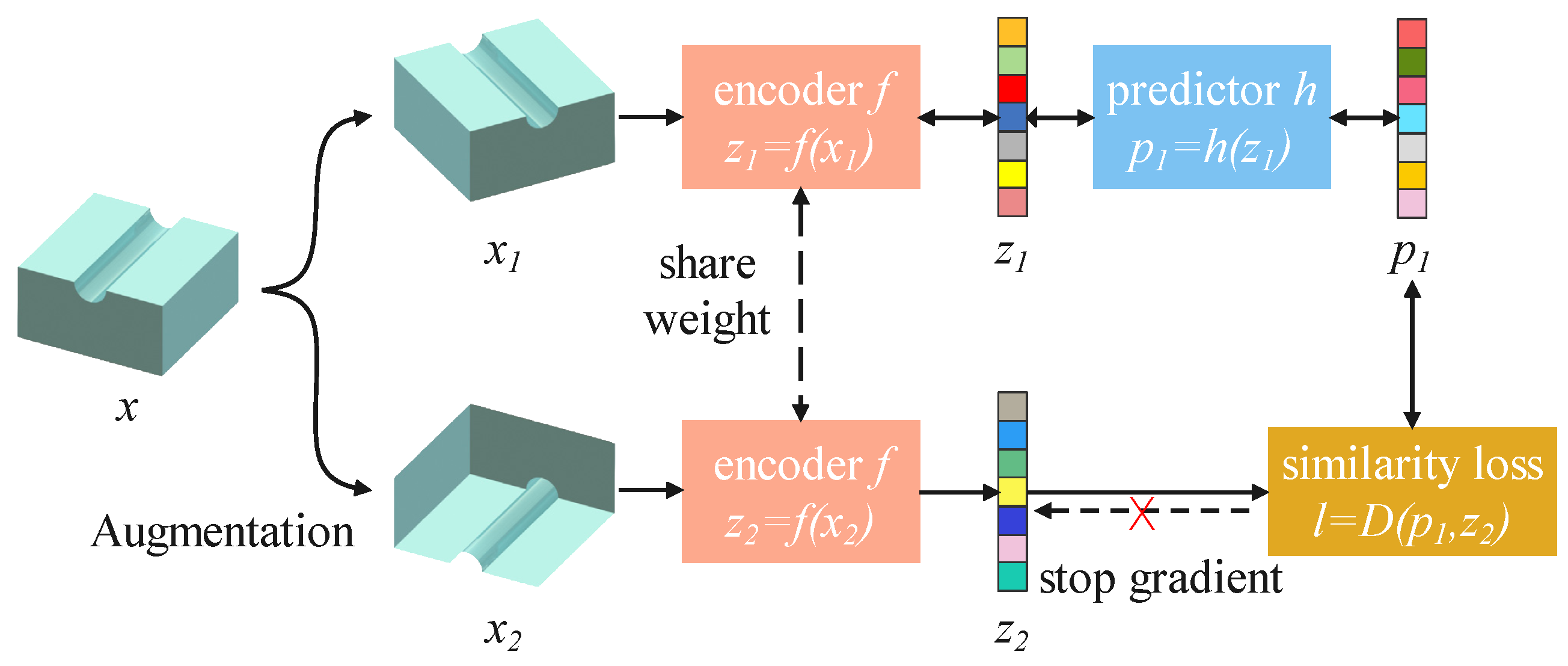
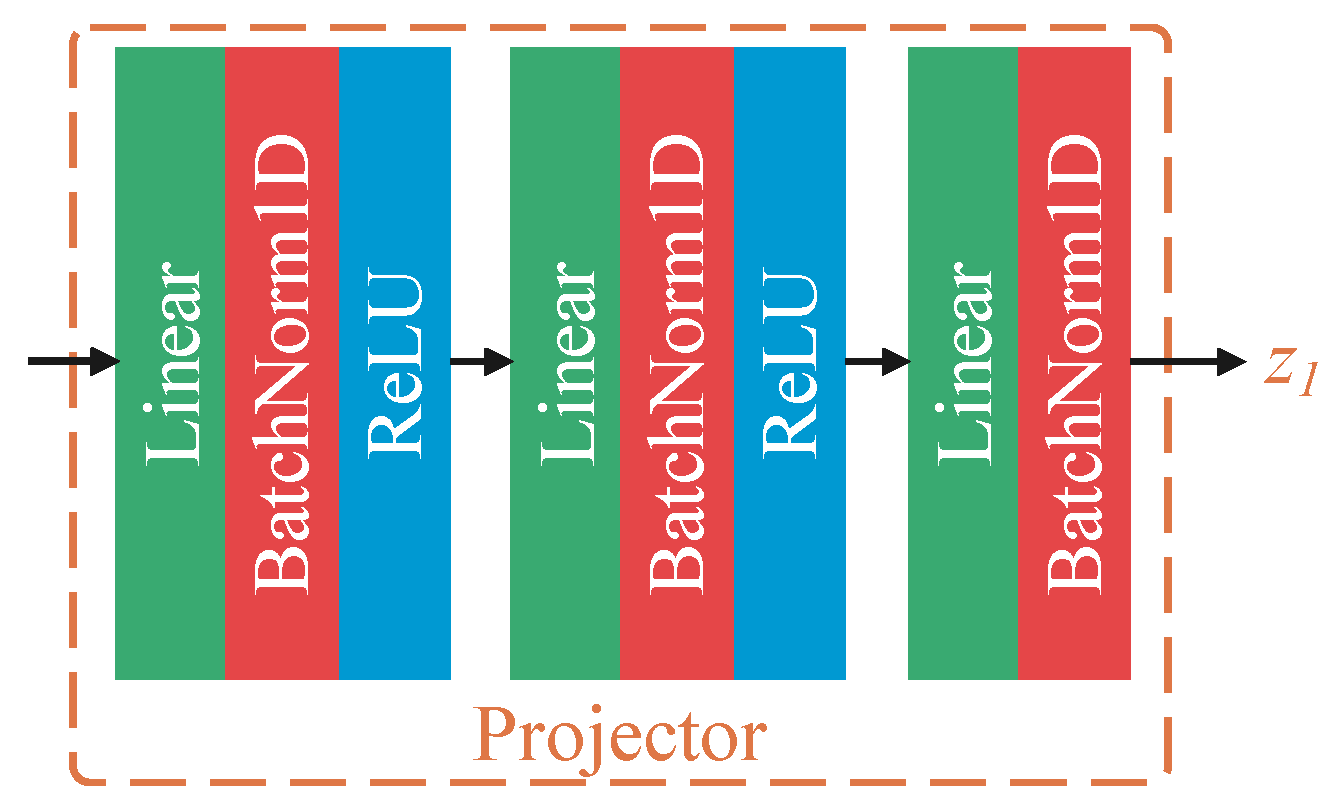
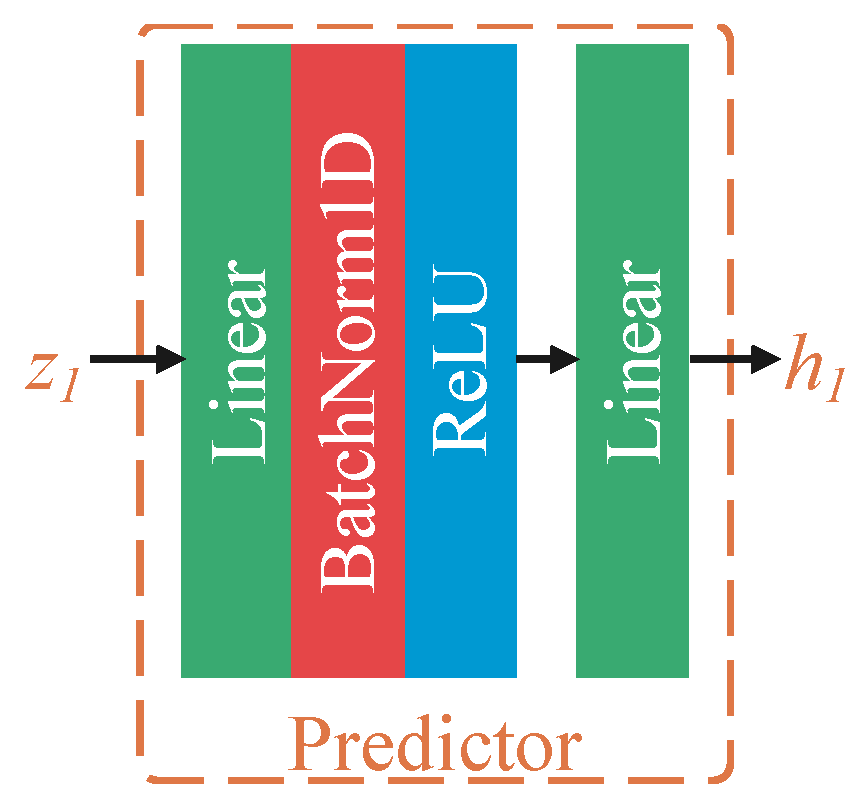
3.1.1. Self-Supervised Learning Stage
3.1.2. Fine-Tuning
3.1.3. Inference Stage
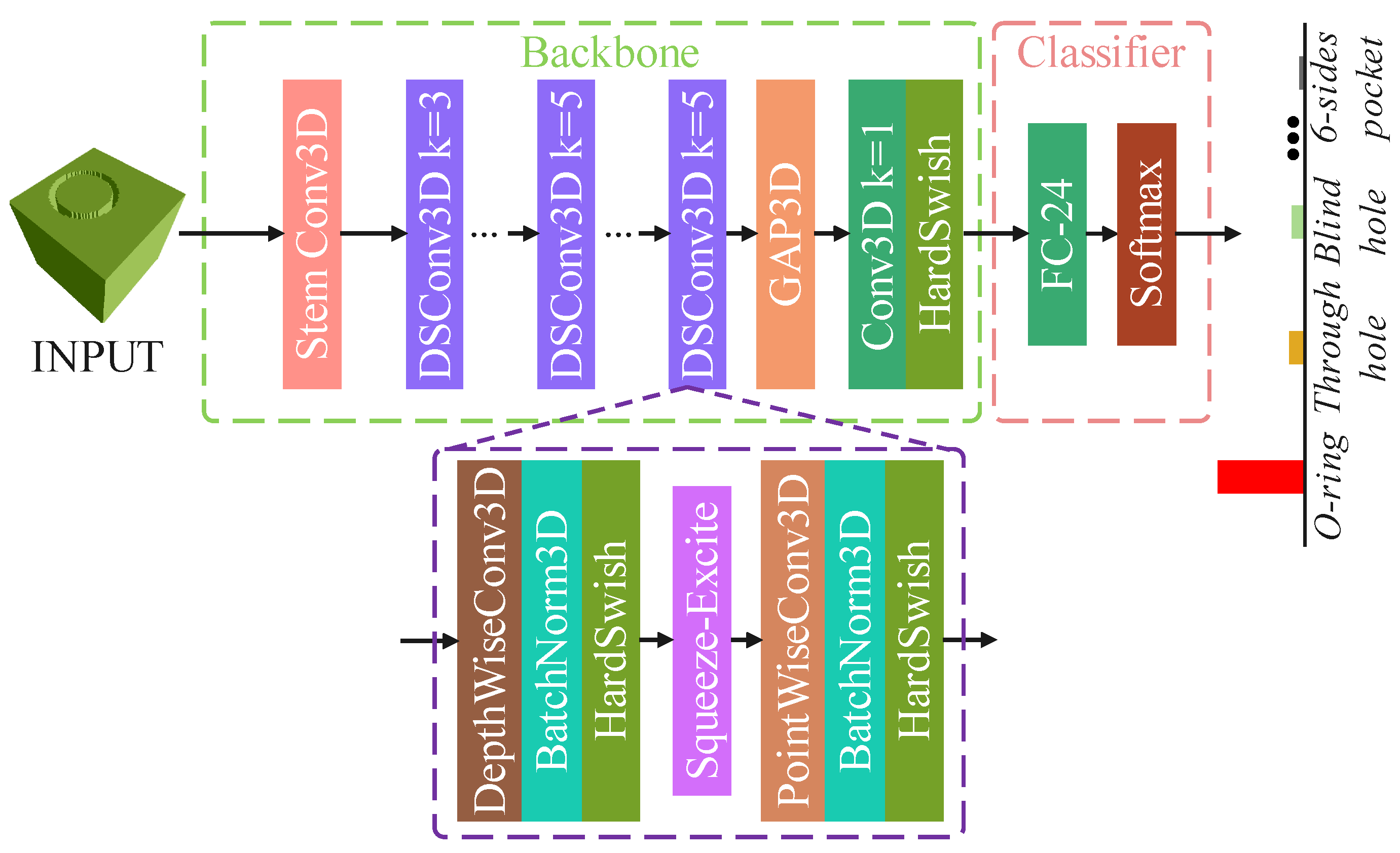
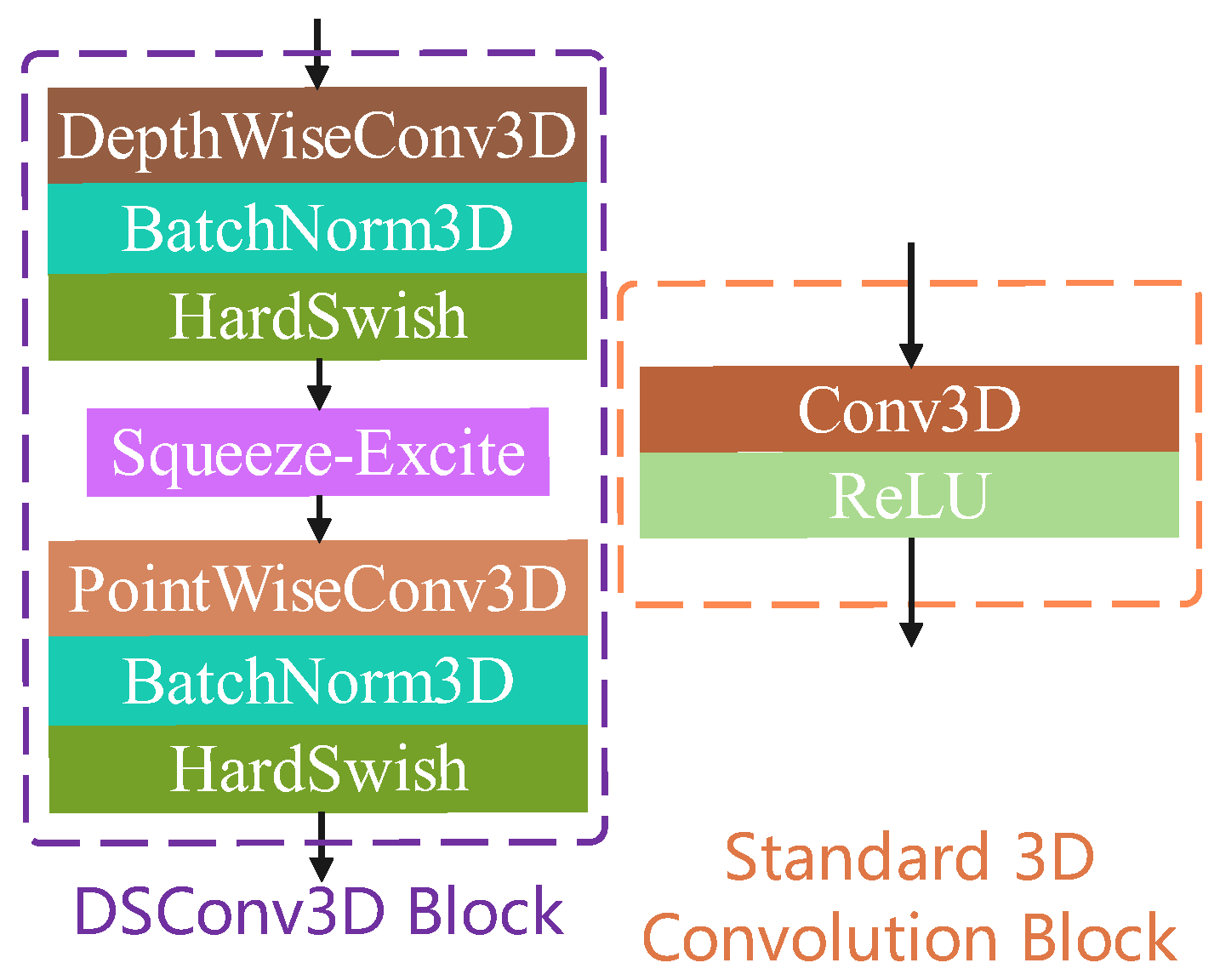
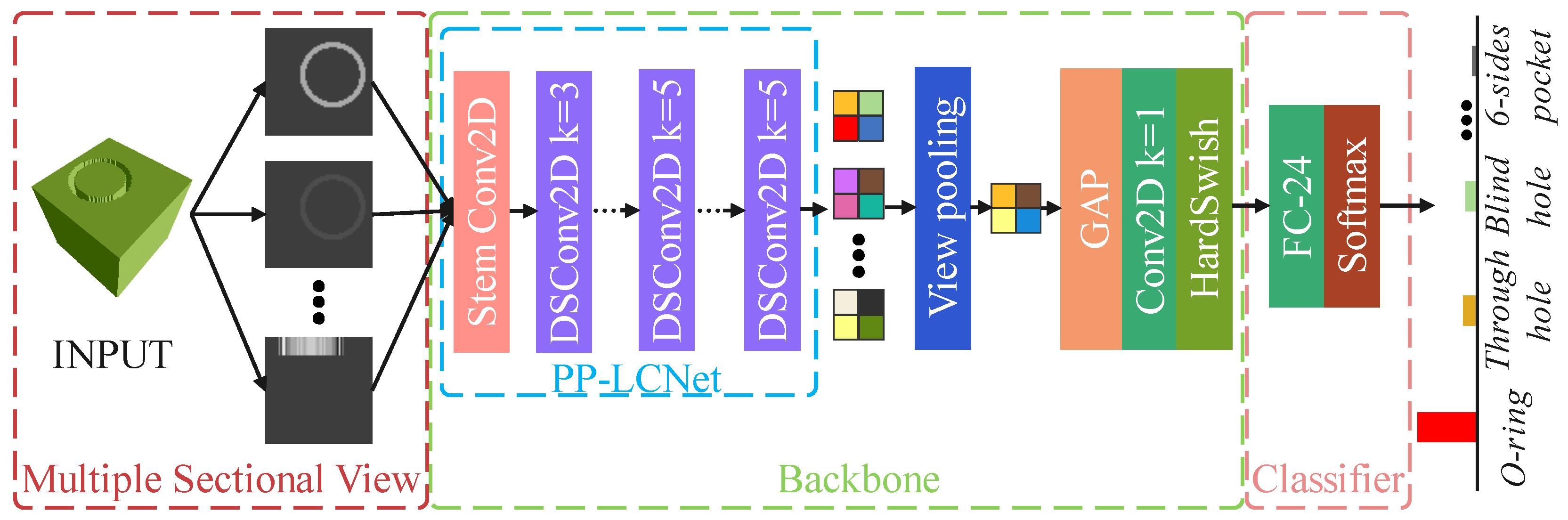
3.2. Lightweight CNN Models for Machining Feature Recognition
3.2.1. FeatureNetLite
3.2.2. MsvNetLite
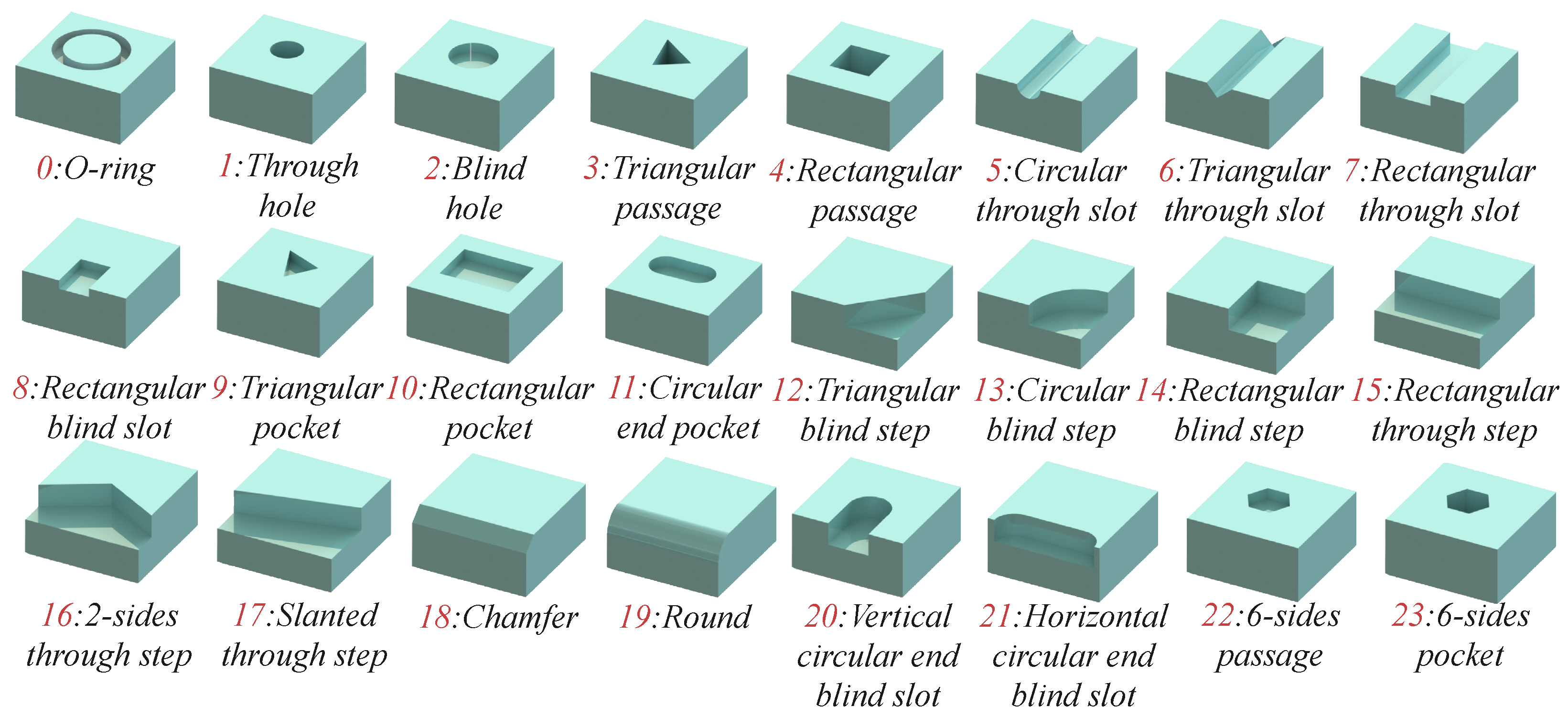
4. Experimental Results
4.1. Experimental Settings
4.2. Effectiveness of the Proposed Semi-Supervised Learning
- MsvNetLite, FeatureNetLite, FeatureNet, Baseline1, Baseline2, and VoxNet underwent 100 epoch training. The MsvNet was trained with 120 epochs. This is because Shi et al. adopted a two-stage training strategy, initially training the network 20 epochs on the single view of a voxel model.
- MsvNetLite and FeatureNetLite using semi-supervised learning were trained by an SGDM optimizer with weight decay. MsvNet, FeatureNet, Baseline1, Baseline2, and VoxNet were trained by an Adam optimizer [58] without weight decay.
- The mini-batch size was set to 64. The batch size is limited to the number of training data if the number of training data is less than the batch size.
- The initial learning values of MsvNetLite and FeatureNetLite using semi-supervised learning were set to for the backbone and 30.0 for the classifier, and a cosine learning rate decay scheduler was used. MsvNet, FeatureNet, Baseline1, Baseline2, and VoxNet were trained with an initial learning rate set to and no decay scheduler.
- According to [20], the following data augmentation strategies were also adopted in our experiments: Random Rotation, Random Scale, and Random PadCrop.
- For fair comparison with [20], the number of sectional views was set to 12 for multi-view approaches.
- FeatureNetLite using semi-supervised learning was trained 50 epochs in the self-supervised stage, and MsvNetLite using semi-supervised learning was trained 100 epochs in the self-supervised stage.
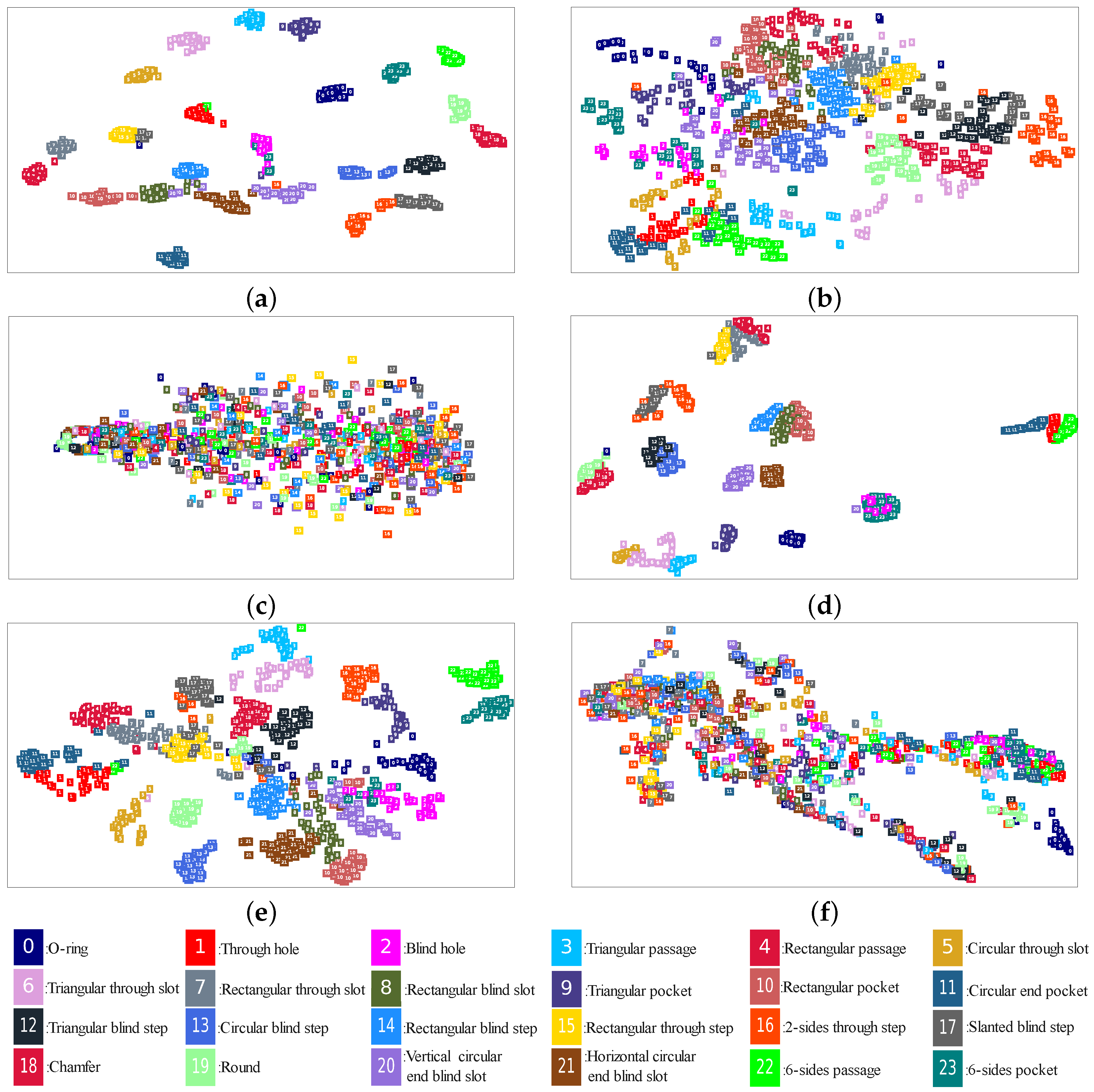
4.3. Visualization of the Visual Representation
4.4. Efficiency of the Proposed FeatureNetLite and MsvNetLite
4.5. Discussion about the Hyper-Parameters of the Proposed Semi-Supervised Learning
4.5.1. Different Numbers of Unlabeled Data in Self-Supervised Stage
4.5.2. Different Batch Size for Self-Supervised Learning
4.5.3. Different Training Epochs in Self-Supervised Stage
4.5.4. Different Data Augmentation Strategies in Self-Supervised Stage
4.5.5. Different Optimizers for Fine-Tuning
4.6. Critical Analysis and Discussion
5. Conclusions and Future Work
- Better self-supervised representation learning methods will be explored. In the future, we will improve the effectiveness of the self-supervised training stage to learn more stable pre-trained knowledge.
- We will continuously focus on the robustness of semi-supervised hyper-parameters. We will carry out a series of experiments with different hyper-parameters to understand how the hyper-parameters effect the training process.
- Our further research will consider the application of multiple, intersecting, and incomplete feature recognition. We will try to use the proposed approach to boost the performance of the current intersecting feature recognition method.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
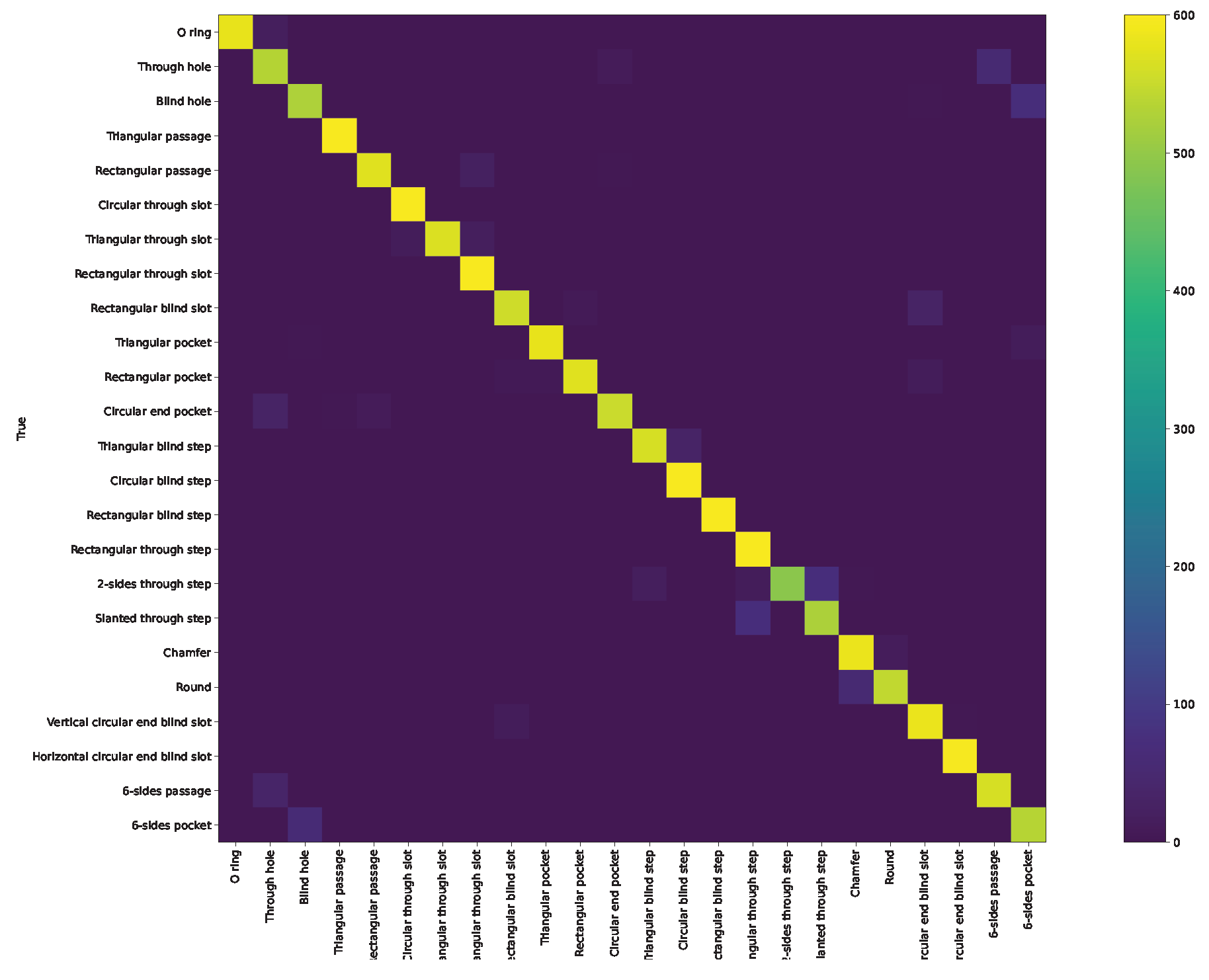
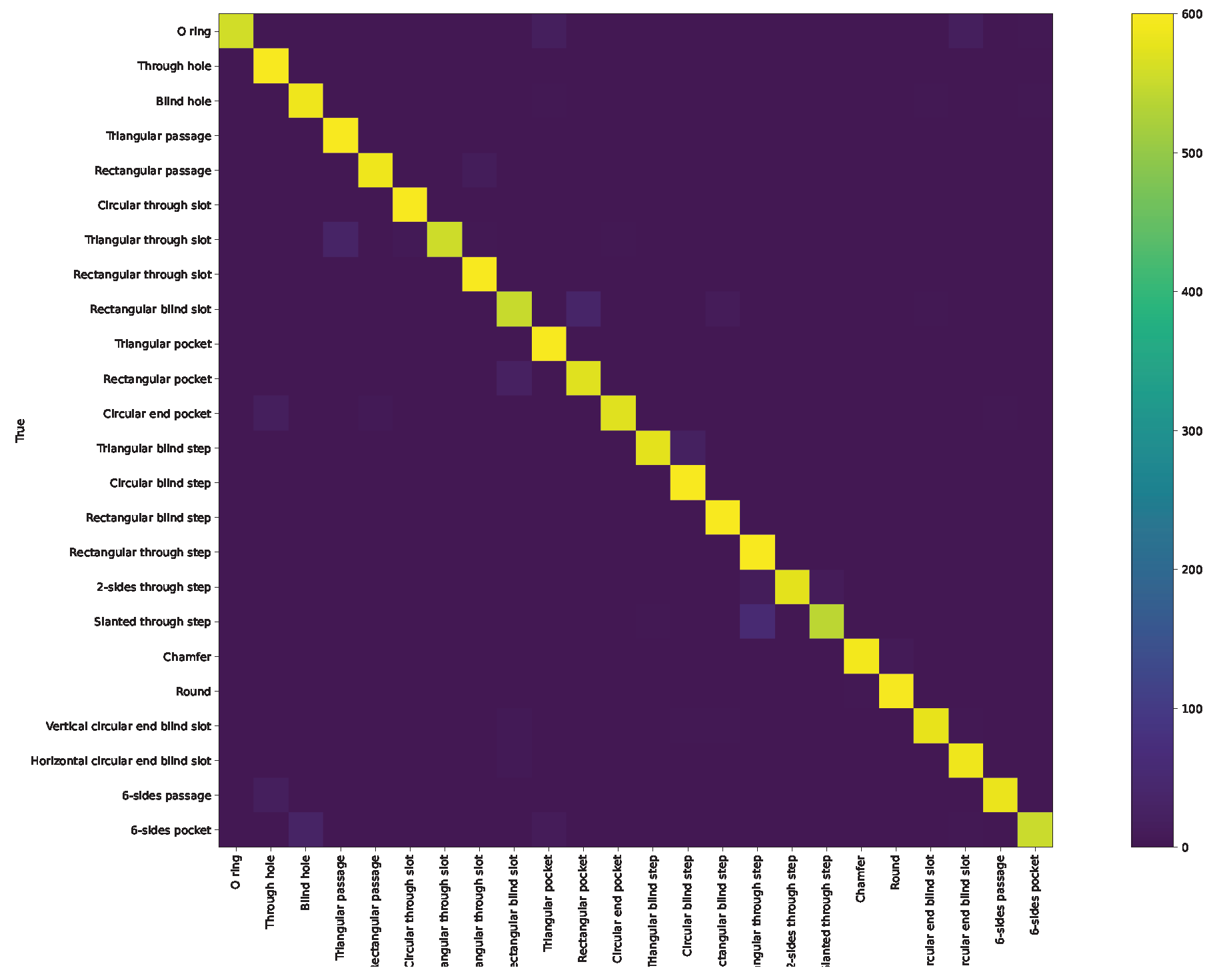
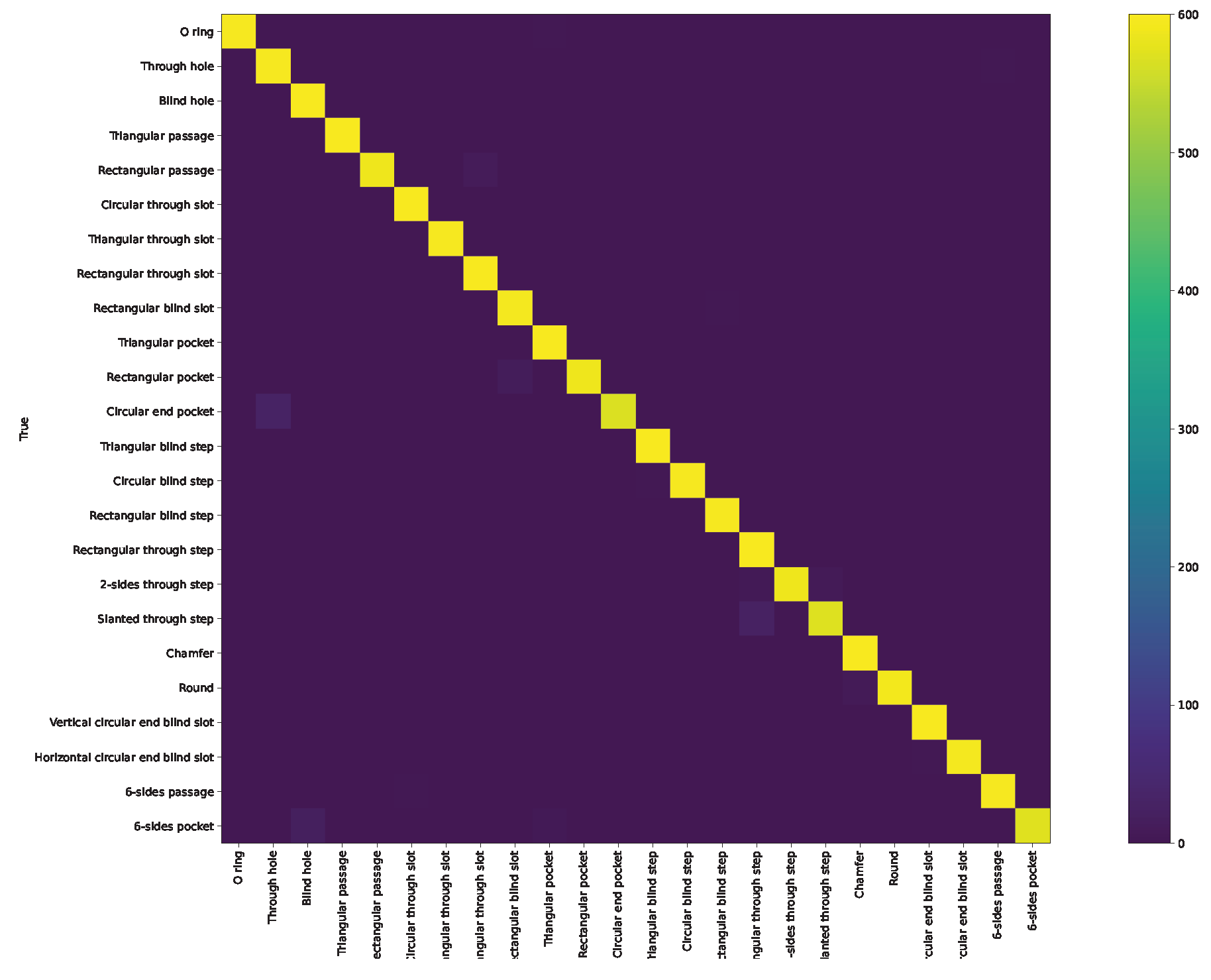
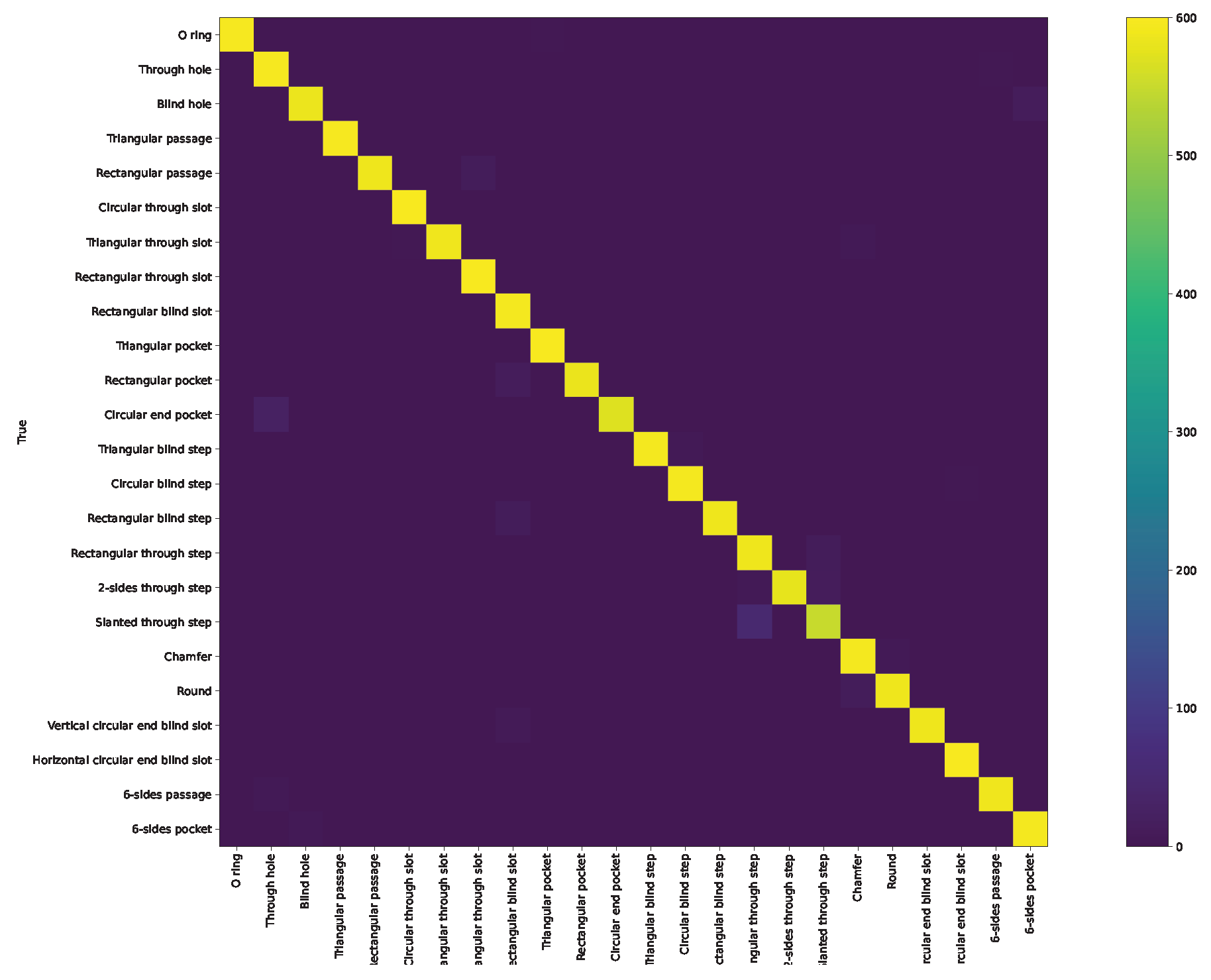
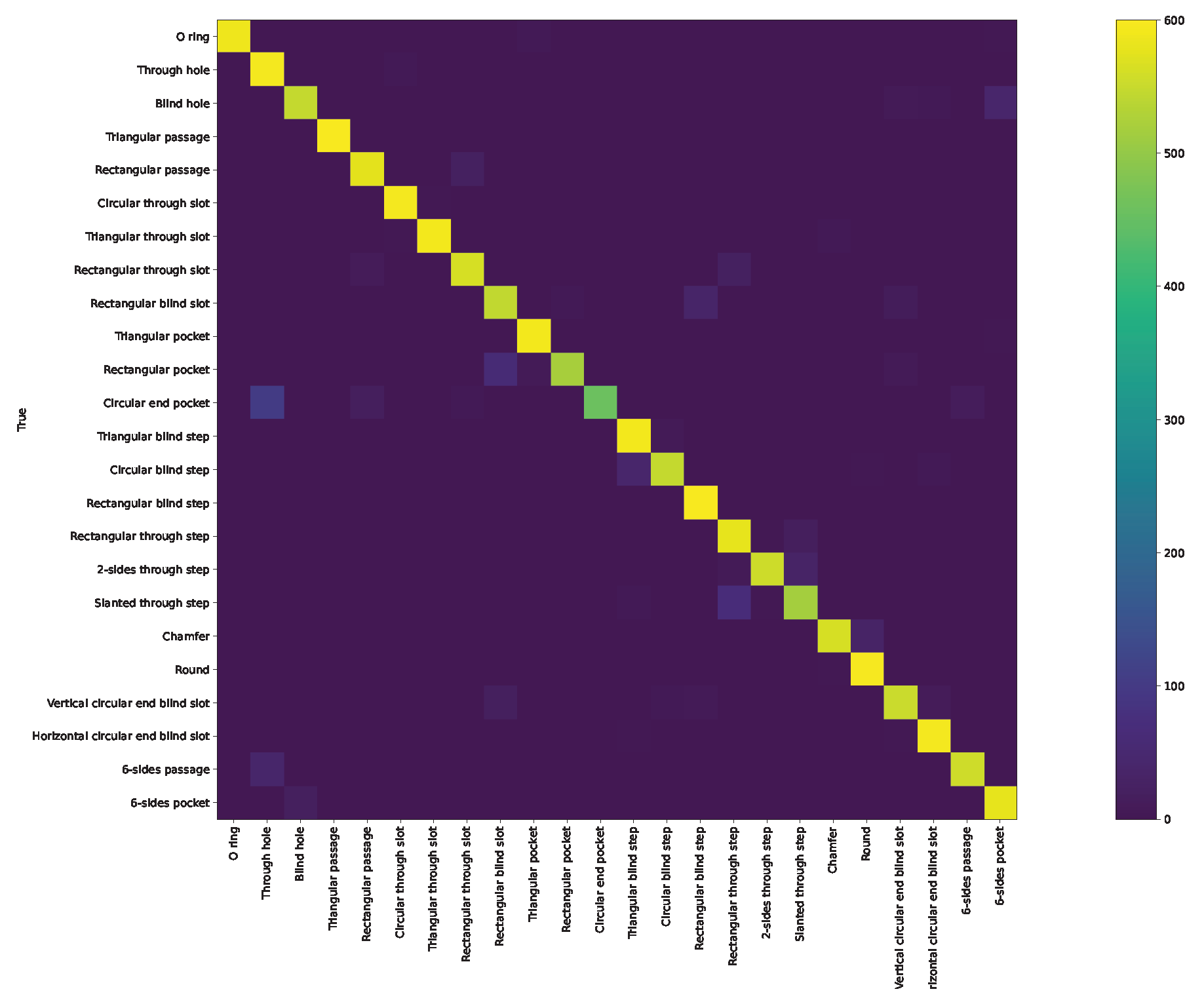
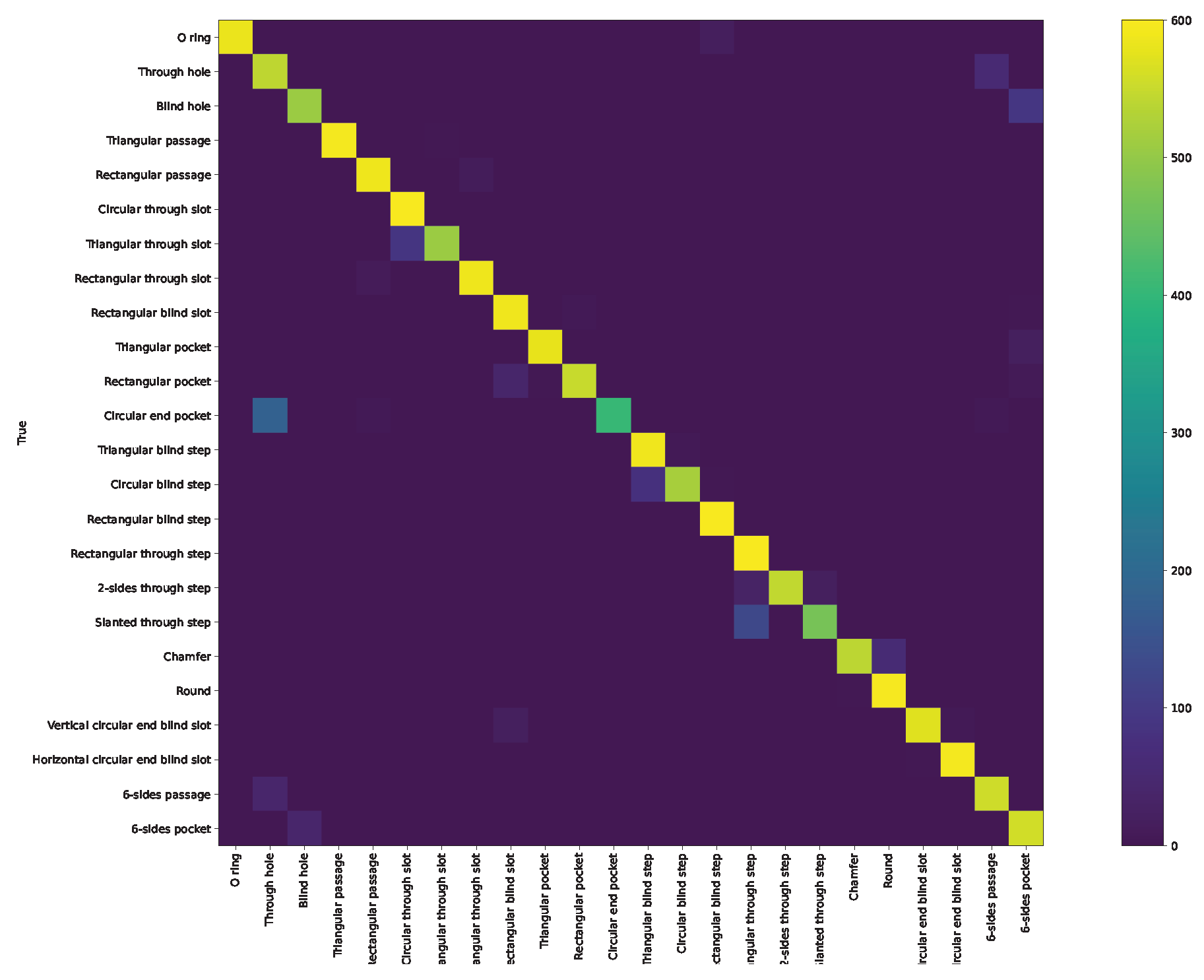
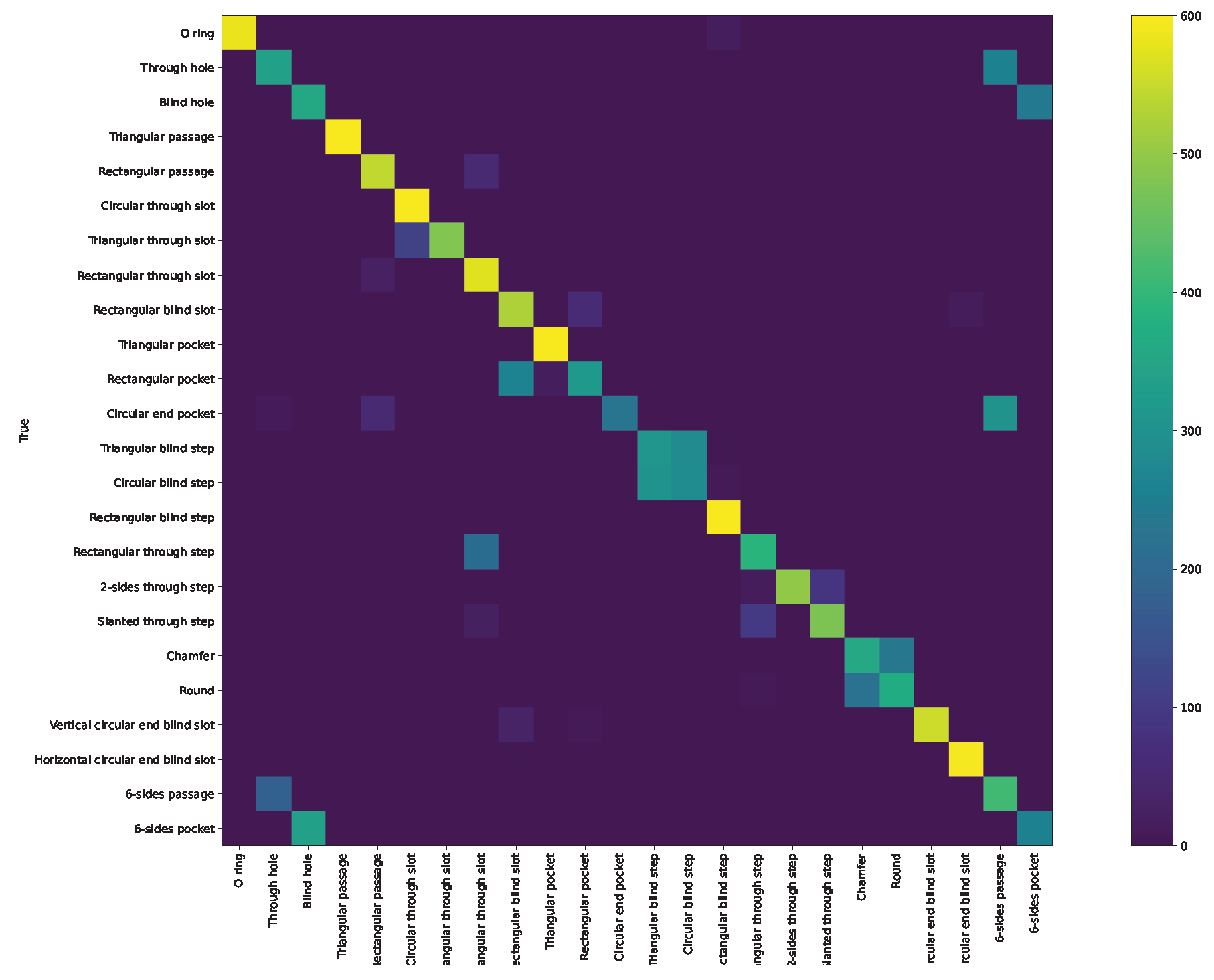
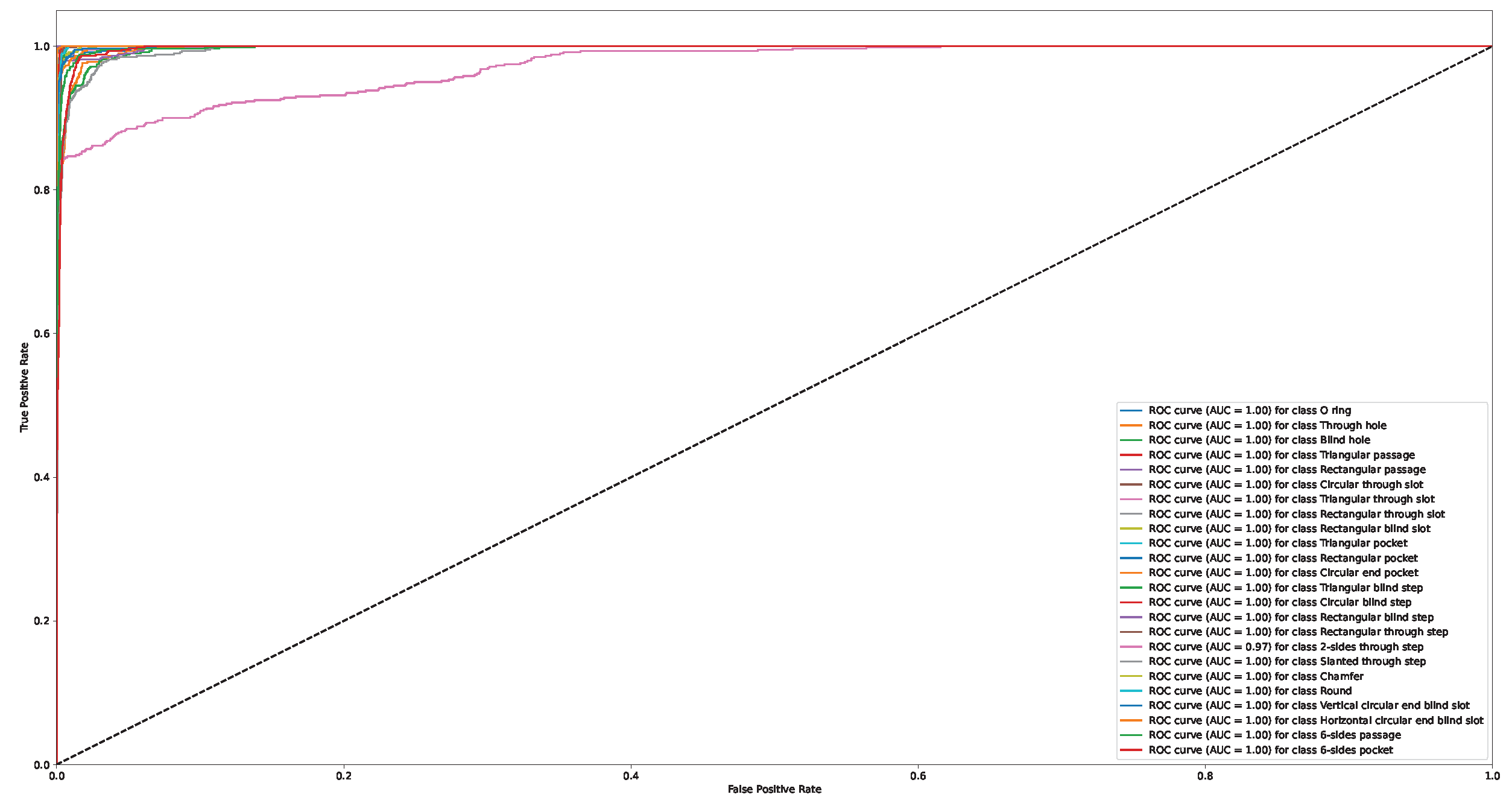
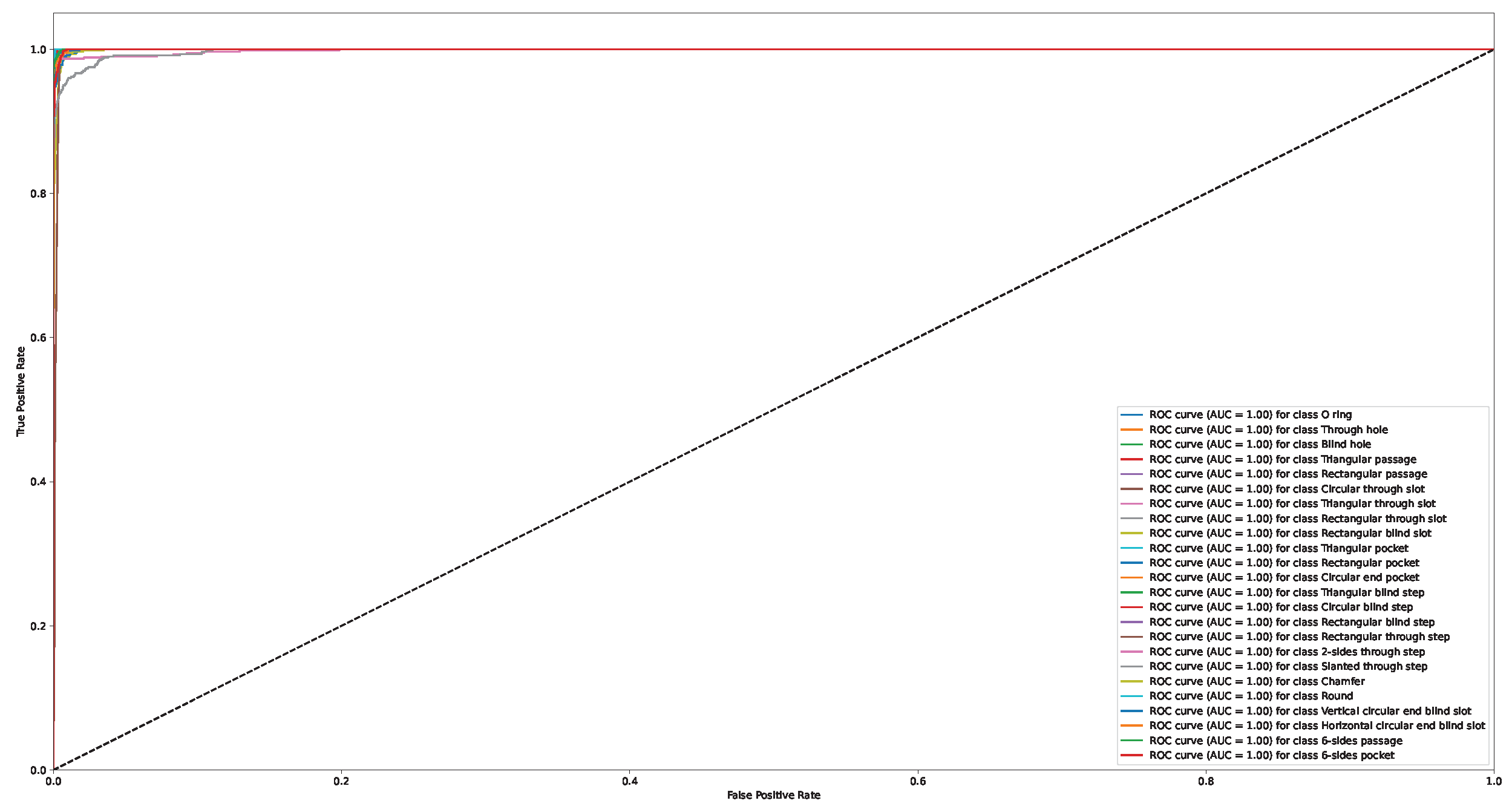
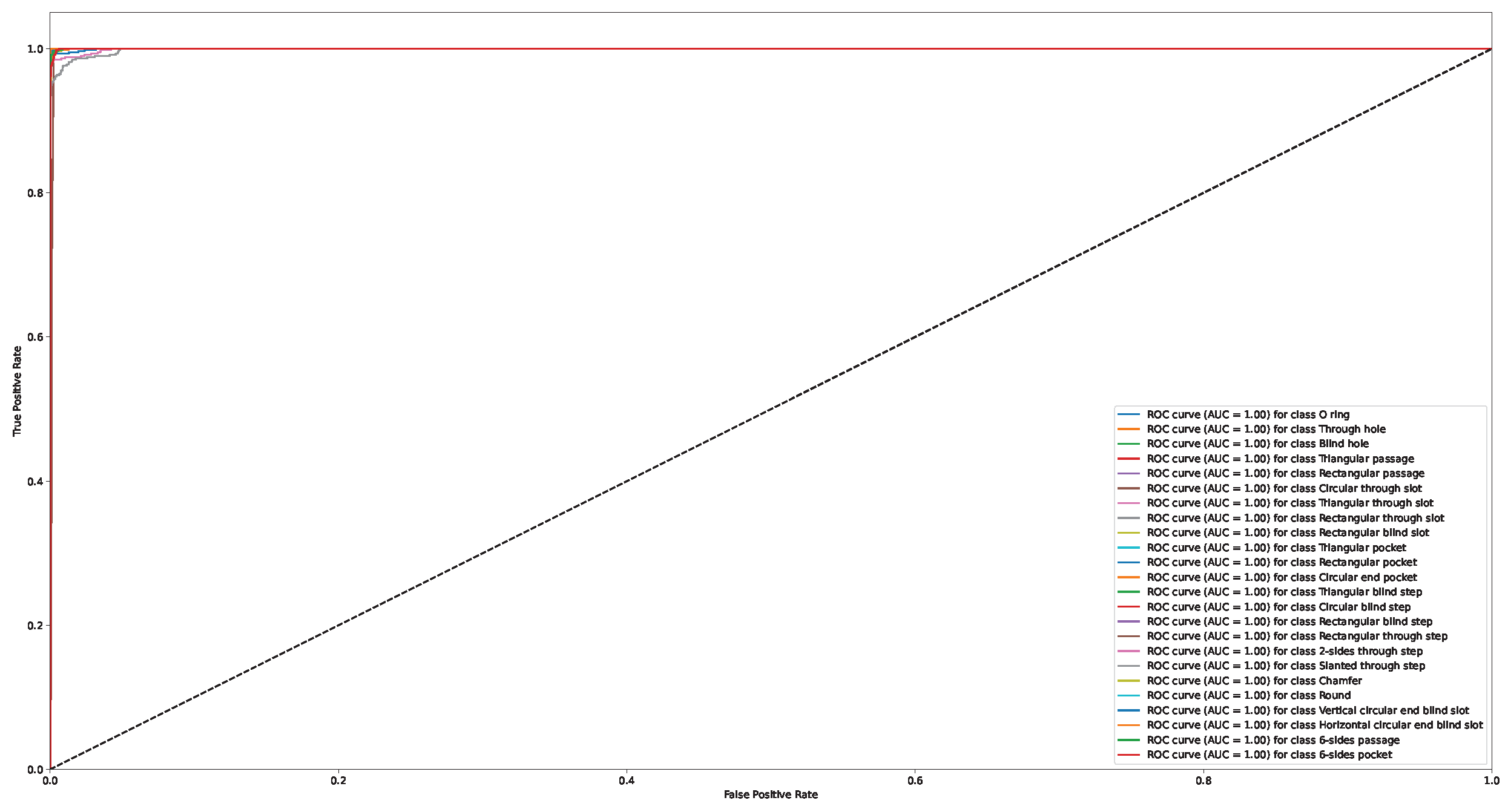
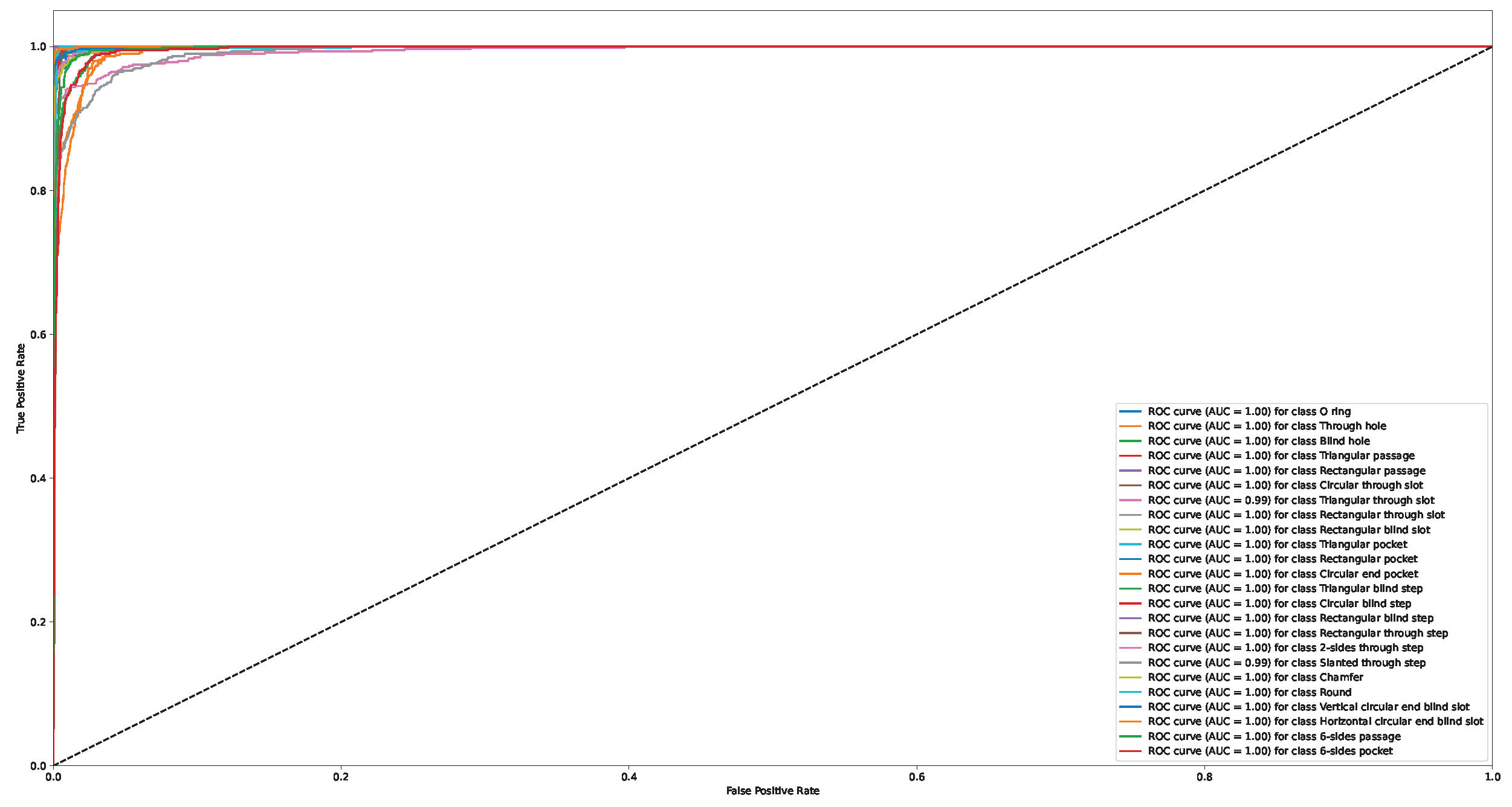
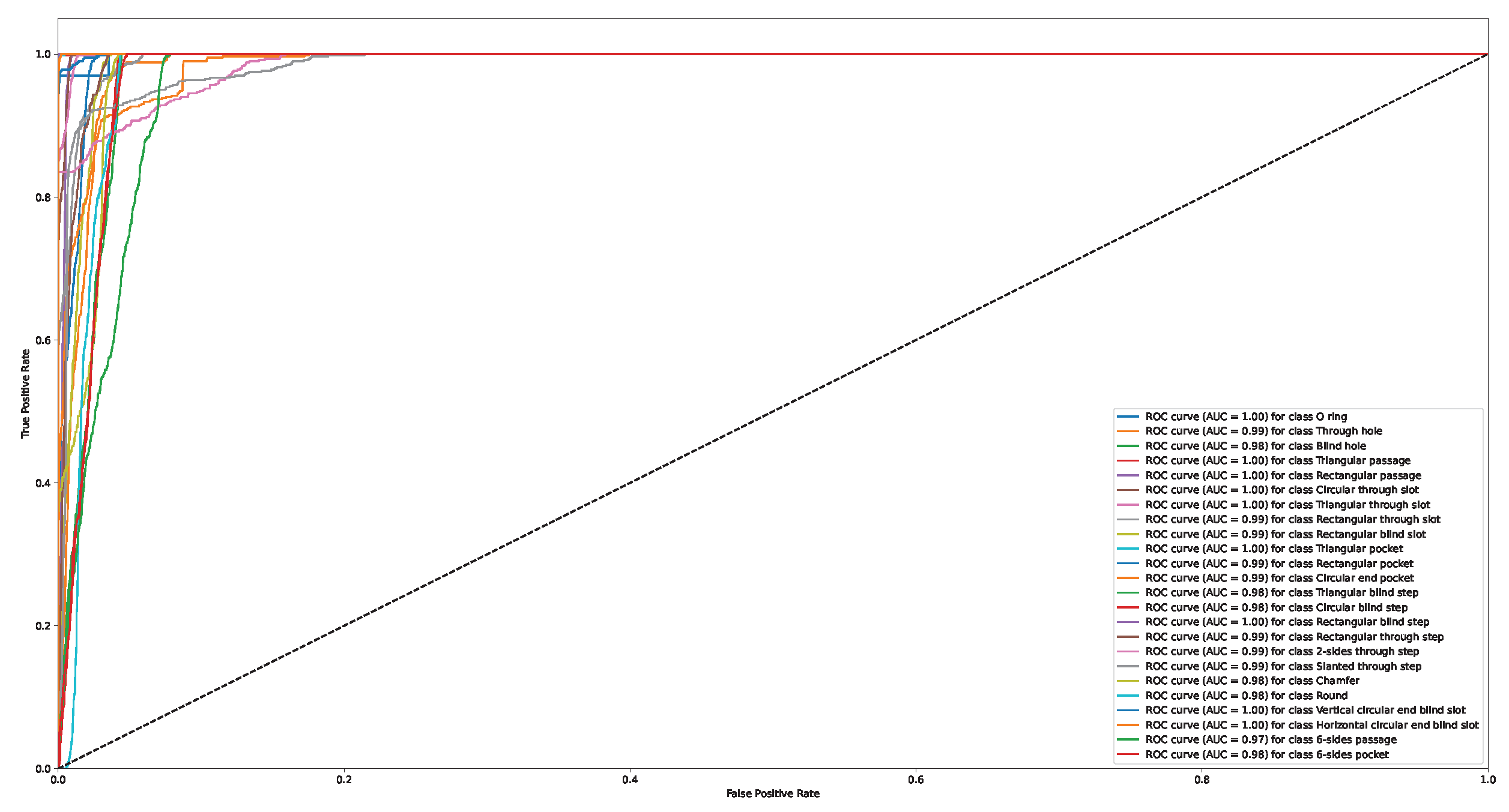
Appendix A. Confusion Matrix and ROC Curve for Different Approaches














References
- Shi, Y.; Zhang, Y.; Xia, K.; Harik, R. A critical review of feature recognition techniques. Comput.-Aided Des. Appl. 2020, 17, 861–899. [Google Scholar] [CrossRef]
- Babic, B.; Nesic, N.; Miljkovic, Z. A review of automated feature recognition with rule-based pattern recognition. Comput. Ind. 2008, 59, 321–337. [Google Scholar] [CrossRef]
- Vandenbrande, J.H.; Requicha, A.A. Spatial reasoning for the automatic recognition of machinable features in solid models. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1269–1285. [Google Scholar] [CrossRef]
- Nau, D.S.; Gupta, S.K.; Kramer, T.R.; Regli, W.C.; Zhang, G. Development of machining alternatives, based on MRSEVs. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, San Diego, CA, USA, 8–12 August 1993; Volume 97645, pp. 47–57. [Google Scholar] [CrossRef]
- Joshi, S.; Chang, T. Graph-based heuristics for recognition of machined features from a 3D solid model. Comput.-Aided Des. 1988, 20, 58–66. [Google Scholar] [CrossRef]
- Marefat, M.; Kashyap, R.L. Geometric reasoning for recognition of three-dimensional object features. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 949–965. [Google Scholar] [CrossRef]
- Li, Y.; Ding, Y.; Mou, W.; Guo, H. Feature recognition technology for aircraft structural parts based on a holistic attribute adjacency graph. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2010, 224, 271–278. [Google Scholar] [CrossRef]
- Kim, Y.S. Volumetric feature recognition using convex decomposition. In Manufacturing Research and Technology; Elsevier: Amsterdam, The Netherlands, 1994; Volume 20, pp. 39–63. [Google Scholar] [CrossRef]
- Sakurai, H. Volume decomposition and feature recognition: Part 1—polyhedral objects. Comput.-Aided Des. 1995, 27, 833–843. [Google Scholar] [CrossRef]
- Sakurai, H.; Dave, P. Volume decomposition and feature recognition, Part II: Curved objects. Comput.-Aided Des. 1996, 28, 519–537. [Google Scholar] [CrossRef]
- Gao, S.; Shah, J. Automatic recognition of interacting machining features based on minimal condition subgraph. Comput.-Aided Des. 1998, 30, 727–739. [Google Scholar] [CrossRef]
- Zhang, C.; Chan, K.; Chen, Y. A hybrid method for recognizing feature interactions. Integr. Manuf. Syst. 1998, 9, 120–128. [Google Scholar] [CrossRef]
- Henderson, M.R.; Anderson, D.C. Computer recognition and extraction of form features: A CAD/CAM link. Comput. Ind. 1984, 5, 329–339. [Google Scholar] [CrossRef]
- Zhang, Z.; Jaiswal, P.; Rai, R. FeatureNet: Machining feature recognition based on 3D Convolution Neural Network. Comput.-Aided Des. 2018, 101, 12–22. [Google Scholar] [CrossRef]
- Ning, F.; Shi, Y.; Cai, M.; Xu, W.; Zhang, X. Manufacturing cost estimation based on the machining process and deep-learning method. J. Manuf. Syst. 2020, 56, 11–22. [Google Scholar] [CrossRef]
- Prabhakar, S.; Henderson, M.R. Automatic form-feature recognition using neural-network-based techniques on boundary representations of solid models. Comput.-Aided Des. 1992, 24, 381–393. [Google Scholar] [CrossRef]
- Ding, L.; Matthews, J. A contemporary study into the application of neural network techniques employed to automate CAD/CAM integration for die manufacture. Comput. Ind. Eng. 2009, 57, 1457–1471. [Google Scholar] [CrossRef] [Green Version]
- Shi, P.; Qi, Q.; Qin, Y.; Scott, P.J.; Jiang, X. Highly interacting machining feature recognition via small sample learning. Robot. Comput.-Integr. Manuf. 2022, 73, 102260. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S.; Zhang, Y.; Liang, J.; Wang, Z. Machining feature recognition based on a novel multi-task deep learning network. Robot. Comput.-Integr. Manuf. 2022, 77, 102369. [Google Scholar] [CrossRef]
- Shi, P.; Qi, Q.; Qin, Y.; Scott, P.J.; Jiang, X. A novel learning-based feature recognition method using multiple sectional view representation. J. Intell. Manuf. 2020, 31, 1291–1309. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar] [CrossRef]
- Zhang, X.; Nassehi, A.; Newman, S.T. Feature recognition from CNC part programs for milling operations. Int. J. Adv. Manuf. Technol. 2014, 70, 397–412. [Google Scholar] [CrossRef]
- Xu, T.; Li, J.; Chen, Z. Automatic machining feature recognition based on MBD and process semantics. Comput. Ind. 2022, 142, 103736. [Google Scholar] [CrossRef]
- Ferreira, J.; Hinduja, S. Convex hull-based feature-recognition method for 2.5D components. Comput.-Aided Des. 1990, 22, 41–49. [Google Scholar] [CrossRef]
- Kim, Y.S.; Wang, E.; Rho, H.M. Geometry-based machining precedence reasoning for feature-based process planning. Int. J. Prod. Res. 2001, 39, 2077–2103. [Google Scholar] [CrossRef]
- Woo, Y.; Sakurai, H. Recognition of maximal features by volume decomposition. Comput.-Aided Des. 2002, 34, 195–207. [Google Scholar] [CrossRef]
- Woo, Y. Fast cell-based decomposition and applications to solid modeling. Comput.-Aided Des. 2003, 35, 969–977. [Google Scholar] [CrossRef]
- Han, J.; Requicha, A.A. Integration of feature based design and feature recognition. Comput.-Aided Des. 1997, 29, 393–403. [Google Scholar] [CrossRef]
- Rahmani, K.; Arezoo, B. Boundary analysis and geometric completion for recognition of interacting machining features. Comput.-Aided Des. 2006, 38, 845–856. [Google Scholar] [CrossRef]
- Verma, A.K.; Rajotia, S. A hybrid machining Feature Recognition system. Int. J. Manuf. Res. 2009, 4, 343–361. [Google Scholar] [CrossRef]
- Yao, X.; Wang, D.; Yu, T.; Luan, C.; Fu, J. A machining feature recognition approach based on hierarchical neural network for multi-feature point cloud models. J. Intell. Manuf. 2022, 1–12. [Google Scholar] [CrossRef]
- Shi, P.; Qi, Q.; Qin, Y.; Scott, P.J.; Jiang, X. Intersecting Machining Feature Localization and Recognition via Single Shot Multibox Detector. IEEE Trans. Ind. Inform. 2021, 17, 3292–3302. [Google Scholar] [CrossRef]
- Wang, J.; Liu, S. Hopfield neural network-based automatic recognition for 3-D features. In Proceedings of the 1993 International Conference on Neural Networks (IJCNN-93-Nagoya, Japan), Nagoya, Japan, 25–29 October 1993; Volume 3, pp. 2121–2124. [Google Scholar] [CrossRef]
- Lankalapalli, K.; Chatterjee, S.; Chang, T. Feature recognition using ART2: A self-organizing neural network. J. Intell. Manuf. 1997, 8, 203–214. [Google Scholar] [CrossRef]
- Öztürk, N.; Öztürk, F. Hybrid neural network and genetic algorithm based machining feature recognition. J. Intell. Manuf. 2004, 15, 287–298. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, S.; Huang, R.; Huang, B.; Yang, L.; Liang, J. A deep learning-based approach for machining process route generation. Int. J. Adv. Manuf. Technol. 2021, 115, 3493–3511. [Google Scholar] [CrossRef]
- Ning, F.; Shi, Y.; Cai, M.; Xu, W. Various realization methods of machine-part classification based on deep learning. J. Intell. Manuf. 2020, 31, 2019–2032. [Google Scholar] [CrossRef]
- Peddireddy, D.; Fu, X.; Shankar, A.; Wang, H.; Joung, B.G.; Aggarwal, V.; Sutherland, J.W.; Jun, M.B.G. Identifying manufacturability and machining processes using deep 3D convolutional networks. J. Manuf. Process. 2021, 64, 1336–1348. [Google Scholar] [CrossRef]
- Mohammadi, N.; Nategh, M.J. Development of a deep learning machining feature recognition network for recognition of four pilot machining features. Int. J. Adv. Manuf. Technol. 2022, 121, 7451–7462. [Google Scholar] [CrossRef]
- Ning, F.; Shi, Y.; Cai, M.; Xu, W. Part machining feature recognition based on a deep learning method. J. Intell. Manuf. 2021, 34, 809–821. [Google Scholar] [CrossRef]
- Fu, X.; Peddireddy, D.; Aggarwal, V.; Jun, M.B.G. Improved Dexel Representation: A 3D CNN Geometry Descriptor for Manufacturing CAD. IEEE Trans. Ind. Inform. 2021, 9, 5882–5892. [Google Scholar] [CrossRef]
- Cao, W.; Robinson, T.; Hua, Y.; Boussuge, F.; Colligan, A.R.; Pan, W. Graph representation of 3d cad models for machining feature recognition with deep learning. In Proceedings of the International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Boston, MA, USA, 17–19 August 2020; Volume 84003, p. V11AT11A003. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap Your Own Latent—A New Approach to Self-Supervised Learning. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Event, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 21271–21284. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; Volume 139, pp. 12310–12320. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Cui, C.; Gao, T.; Wei, S.; Du, Y.; Guo, R.; Dong, S.; Lu, B.; Zhou, Y.; Lv, X.; Liu, Q.; et al. PP-LCNet: A Lightweight CPU Convolutional Neural Network. arXiv 2021, arXiv:2109.15099. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ye, R.; Liu, F.; Zhang, L. 3D depthwise convolution: Reducing model parameters in 3D vision tasks. In Proceedings of the Canadian Conference on Artificial Intelligence, Kingston, ON, Canada, 28–31 May 2019; pp. 186–199. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view Convolutional Neural Networks for 3D Shape Recognition. arXiv 2015, arXiv:1505.00880. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, Canada, 8–14 December 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
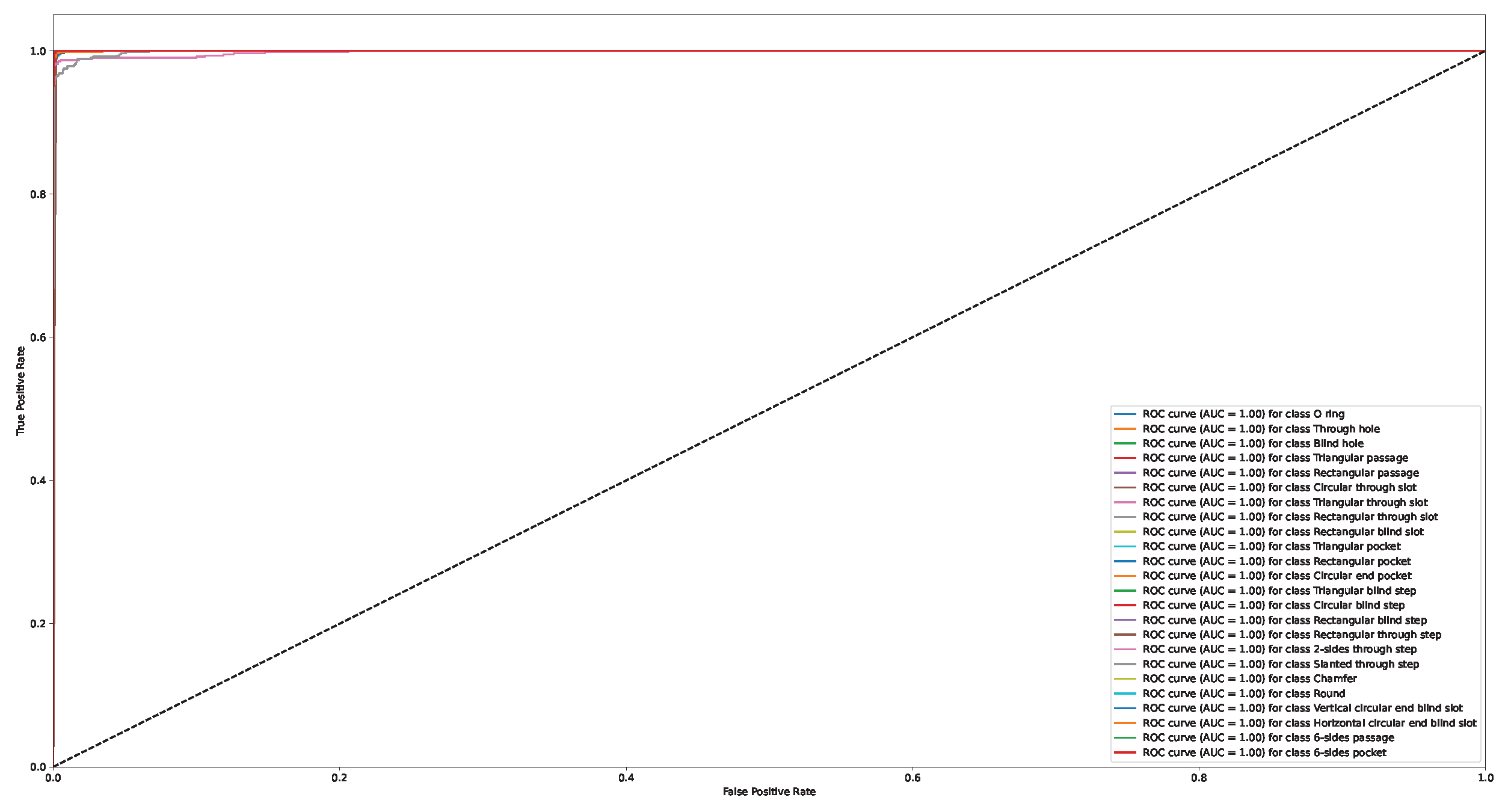{kind=link}
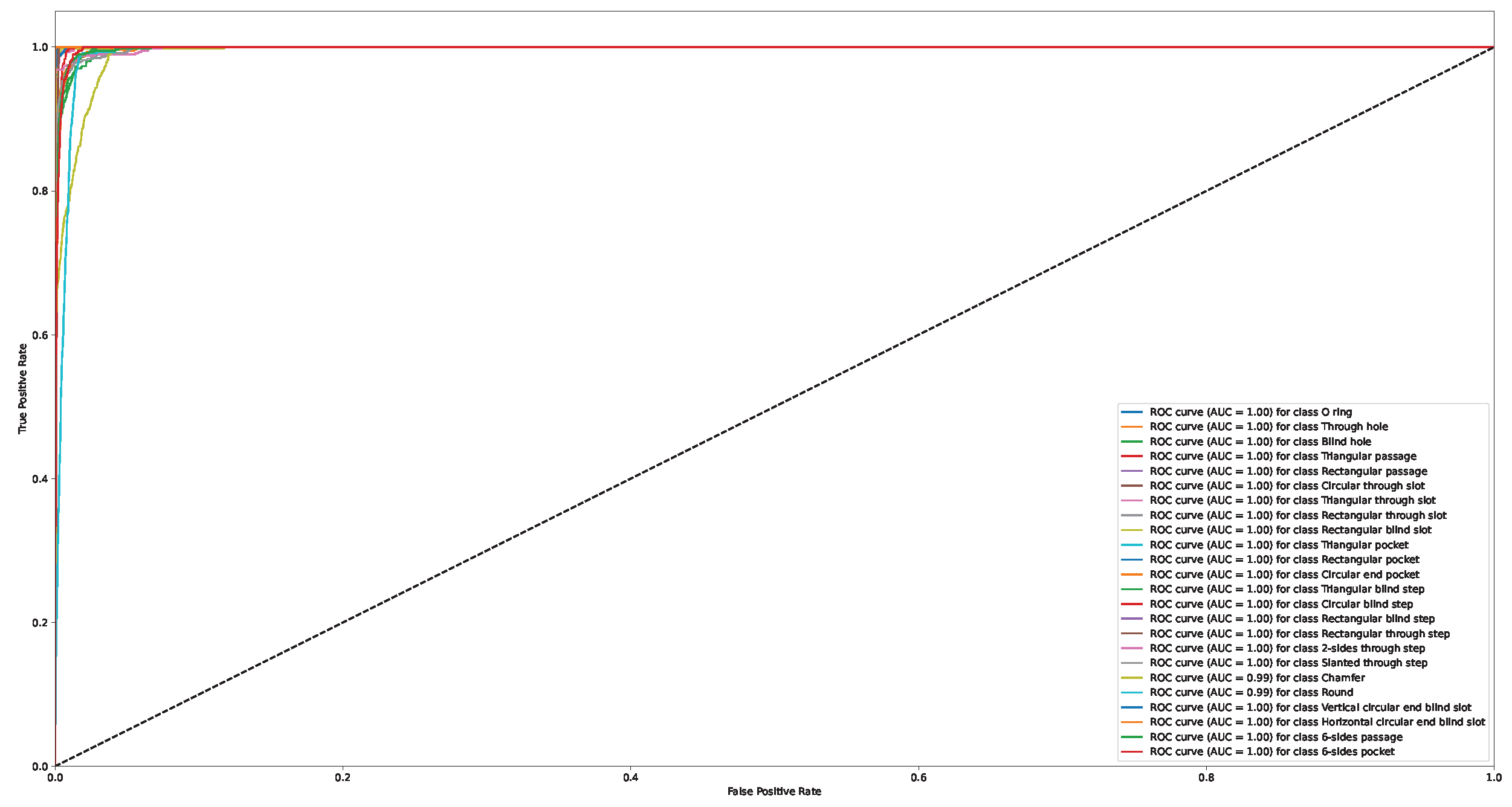{kind=link}
{kind=link}
{kind=link}
| Operator | SE | Stride | Input () | Output () |
|---|---|---|---|---|
| Stem Conv3D, k = 3 | - | 2 | ||
| DSConv3D, k = 3 | - | 1 | ||
| DSConv3D, k = 3 | - | 2 | ||
| DSConv3D, k = 3 | - | 1 | ||
| DSConv3D, k = 3 | - | 2 | ||
| DSConv3D, k = 3 | - | 1 | ||
| DSConv3D, k = 3 | - | 2 | ||
| 5× DSConv3D, k = 5 | - | 1 | ||
| DSConv3D, k = 5 | ✓ | 2 | ||
| DSConv3D, k = 5 | ✓ | 1 | ||
| GAP3D | - | - | ||
| Conv3D, k = 1 | - | 1 | ||
| Flatten | - | - | 1280 | |
| Linear | - | - | 1280 | 24 |
| Operator | SE | Stride | Input () | Output () |
|---|---|---|---|---|
| Stem Conv2D, k = 3 | - | 2 | ||
| DSConv2D, k = 3 | - | 1 | ||
| DSConv2D, k = 3 | - | 2 | ||
| DSConv2D, k = 3 | - | 1 | ||
| DSConv2D, k = 3 | - | 2 | ||
| DSConv2D, k = 3 | - | 1 | ||
| DSConv2D, k = 3 | - | 2 | ||
| 5× DSConv2D, k = 5 | - | 1 | ||
| DSConv2D, k = 5 | ✓ | 2 | ||
| DSConv2D, k = 5 | ✓ | 1 | ||
| View pooling | - | - | ||
| GAP2D | - | - | ||
| Conv2D, k = 1 | - | 1 | ||
| Flatten | - | - | 1280 | |
| Linear | - | - | 1280 | 24 |
| Approach | Data Format | Training Strategy | Number of Training Data per Class | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PT | DA | Semi-Sup. | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | ||
| [20] | Multi-view | 13.42 | 17.85 | 22.88 | 35.44 | 52.93 | 67.15 | 87.65 | 94.47 | |||
| ✓ | 28.88 | 48.52 | 60.51 | 73.03 | 84.88 | 92.38 | 96.12 | 98.03 | ||||
| ✓ | 16.77 | 26.72 | 47.72 | 65.60 | 82.33 | 92.67 | 96.64 | 98.65 | ||||
| ✓ | ✓ | 50.34 | 73.17 | 86.65 | 92.71 | 94.51 | 97.23 | 98.54 | 99.01 | |||
| MsvNetLite (ours) | 6.03 | 7.58 | 9.67 | 15.12 | 26.33 | 48.74 | 68.56 | 85.52 | ||||
| ✓ | 25.81 | 35.10 | 47.52 | 67.58 | 82.32 | 94.69 | 95.88 | 98.31 | ||||
| ✓ | 13.99 | 18.22 | 34.16 | 56.97 | 71.38 | 86.36 | 94.06 | 95.70 | ||||
| ✓ | ✓ | 45.23 | 57.00 | 81.03 | 89.24 | 94.70 | 97.07 | 98.41 | 98.76 | |||
| ✓ | ✓ | 69.81 | 76.04 | 87.74 | 93.95 | 97.15 | 97.56 | 98.03 | 98.84 | |||
| [14] | Voxel | 12.70 | 14.42 | 15.78 | 18.87 | 27.90 | 30.58 | 43.31 | 52.28 | |||
| ✓ | 16.67 | 18.68 | 24.08 | 42.42 | 59.24 | 75.02 | 90.73 | 94.26 | ||||
| FeatureNetLite (ours) | 4.17 | 5.63 | 9.08 | 12.35 | 15.23 | 22.63 | 38.79 | 69.17 | ||||
| ✓ | 8.78 | 16.05 | 23.85 | 44.53 | 67.92 | 83.07 | 90.60 | 94.65 | ||||
| ✓ | ✓ | 36.52 | 56.40 | 61.00 | 74.42 | 86.53 | 91.83 | 92.12 | 97.10 | |||
| [38] | 11.17 | 11.76 | 17.59 | 21.38 | 25.74 | 32.60 | 41.65 | 55.36 | ||||
| ✓ | 15.47 | 20.31 | 28.62 | 45.73 | 60.98 | 76.88 | 86.79 | 94.34 | ||||
| [40] | 8.05 | 10.86 | 14.69 | 20.81 | 27.28 | 31.18 | 38.35 | 54.16 | ||||
| ✓ | 14.97 | 19.42 | 20.32 | 35.67 | 57.90 | 67.47 | 83.78 | 93.38 | ||||
| [59] | 10.22 | 13.44 | 16.97 | 17.70 | 22.32 | 29.56 | 38.60 | 48.90 | ||||
| ✓ | 15.22 | 18.97 | 24.84 | 31.24 | 45.83 | 61.25 | 69.70 | 77.74 | ||||
| Network | Optimal Accuracy (%) ↑ | Parameters | FLOPs | Latency (ms) @ GPU ↓ | Latency (ms) @ CPU ↓ |
|---|---|---|---|---|---|
| [20] | 99.01 | 128.86 M | 7.46 G | 8.83 | 127.89 |
| MsvNetLite (ours) | 98.84 | 1.70 M | 0.16 G | 6.96 | 19.27 |
| [14] | 94.26 | 33.94 M | 12.51 G | 13.36 | 137.88 |
| FeatureNetLite (ours) | 97.10 | 1.91 M | 0.14 G | 6.90 | 55.97 |
| [38] | 94.34 | 33.75 M | 6.40 G | 7.60 | 71.28 |
| [40] | 93.38 | 32.75 M | 10.70 G | 15.43 | 178.72 |
| [59] | 77.74 | 11.27 M | 0.73 G | 1.74 | 20.31 |
| Number of Unlabeled Data per Class in Self-Supervised Stage | Number of Labeled Data per Class for Fine-Tuning | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | |
| 3600 | 51.78 | 64.22 | 77.60 | 86.17 | 92.12 | 94.92 | 97.04 | 98.28 |
| 6000 | 69.81 | 76.04 | 87.74 | 93.95 | 97.15 | 97.56 | 98.03 | 98.84 |
| Batch Size in Self-Supervised Stage | Number of Labeled Data per Class for Fine-Tuning | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | |
| 16 | 64.08 | 74.76 | 83.90 | 92.25 | 95.26 | 96.82 | 98.12 | 98.63 |
| 32 | 69.81 | 76.04 | 87.74 | 93.95 | 97.15 | 97.56 | 98.03 | 98.84 |
| 64 | 31.40 | 48.95 | 59.18 | 75.28 | 84.63 | 92.28 | 94.69 | 97.14 |
| 128 | 25.26 | 44.21 | 45.28 | 70.67 | 72.79 | 83.88 | 90.46 | 95.60 |
| 256 | 53.67 | 68.99 | 83.33 | 92.81 | 95.40 | 96.83 | 97.94 | 98.56 |
| Training Epoch in Self-Supervised Stage | Number of Labeled Data per Class for Fine-Tuning | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | |
| 50 | 53.44 | 63.78 | 66.02 | 74.24 | 83.83 | 93.81 | 97.28 | 97.62 |
| 100 | 69.81 | 76.04 | 87.74 | 93.95 | 97.15 | 97.56 | 98.03 | 98.84 |
| 200 | 76.33 | 86.94 | 87.30 | 92.52 | 94.54 | 96.65 | 97.25 | 98.38 |
| Data Augmentation Strategies in Self-Supervised Learning Stage | Number of Labeled Data per Class for Fine-Tuning | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rotation | Scale | PadCrop | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| ✓ | 22.28 | 31.33 | 43.66 | 52.26 | 73.06 | 74.35 | 84.31 | 96.18 | ||
| ✓ | ✓ | 34.41 | 43.51 | 61.55 | 71.58 | 84.44 | 91.99 | 94.84 | 96.94 | |
| ✓ | ✓ | ✓ | 69.81 | 76.04 | 87.74 | 93.95 | 97.15 | 97.56 | 98.03 | 98.84 |
| Optimizer for Fine-Tuning | Number of Labeled Data per Class for Fine-Tuning | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | |
| Adam | 15.39 | 21.62 | 13.21 | 24.08 | 26.42 | 81.99 | 94.93 | 96.15 |
| SGDM () | 69.81 | 76.04 | 87.74 | 93.95 | 97.15 | 97.56 | 98.03 | 98.84 |
| SGD | 66.98 | 73.85 | 82.08 | 83.70 | 93.83 | 96.24 | 97.99 | 98.53 |
| RMSProp | 7.71 | 7.17 | 9.19 | 8.17 | 10.24 | 44.97 | 80.12 | 89.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Lei, R.; Huang, P.; Peng, Y. A Semi-Supervised Learning Framework for Machining Feature Recognition on Small Labeled Sample. Appl. Sci. 2023, 13, 3181. https://doi.org/10.3390/app13053181
Wu H, Lei R, Huang P, Peng Y. A Semi-Supervised Learning Framework for Machining Feature Recognition on Small Labeled Sample. Applied Sciences. 2023; 13(5):3181. https://doi.org/10.3390/app13053181
Chicago/Turabian StyleWu, Hongjin, Ruoshan Lei, Pei Huang, and Yibing Peng. 2023. "A Semi-Supervised Learning Framework for Machining Feature Recognition on Small Labeled Sample" Applied Sciences 13, no. 5: 3181. https://doi.org/10.3390/app13053181