1. Introduction
With easy access to the web, people now interact with brands and products in a whole new way. Whether with physical products or online services, people can share their opinions and reviews immediately on various platforms over the Internet. The world has transformed dramatically as a result of current advancements. Analyzing this large volume of consumer reviews will be helpful for consumers in making an informed decision about a product or service. In social network analyses, the sentiment analysis is an effective method for extracting user thoughts and determining a single user’s sentiments. Social media, with its rich sentiments, has developed into a valuable resource for businesses and governments to understand the opinions and sentiments of online users [
1]. For instance, users of Twitter and other social media platforms routinely send out a lot of quick text messages with emoticons to communicate their opinions about various subjects. A textual sentiment analysis (SA) is not just a theoretical approach; it has applications in a variety of fields, including finance [
2], education [
3], health [
4], and other areas.
Machine learning models have drawn a lot of attention recently. Traditional machine learning models almost universally use a two-step procedure. First, some manually created features from the papers are extracted. In a later stage, the features are sent to a classifier that performs predictions. The hand-crafted elements include the bag of words (BoW). Support vector machines (SVM), naive Bayes, gradient boosting trees, random forests, and the hidden Markov model (HMM) are some of the most used classification algorithms. There are various drawbacks to the two-step procedure. To achieve good performance relying on hand-crafted features, this necessitates time-consuming feature engineering and analysis phases. Furthermore, it is challenging to apply the strategy to new positions because it depends on domain expertise for feature creation.
Regarding mobile applications, the majority of apps can freely downloaded and a wide range of possibilities are accessible for a given sort of app, meaning sentiment analyses are made even more challenging. Users usually consult reviews or advice from other users before making decisions. App store owners can use the reviews to increase in the search ranks and catch fraud, while developers can use them to extract feedback (such as features, complaints, and privacy problems) [
5]. Manual analyses are quite challenging due to the rapidly increasing volume of reviews (including false and spam reviews). As a result, app reviews have been rated in various ways throughout the last few years, from general exploratory research to categorization, feature extraction, review filtering, and summarizing. Furthermore, evaluations frequently include user opinions, which can be viewed as additional useful meta-data.
To alleviate the restrictions caused by the usage of hand-crafted features, neural techniques have been investigated. These techniques do not require hand-crafted features since they use a machine learning model that converts text into a low-dimensional vector of features. An LSA (latent semantic analysis) was proposed by Dumais et al. [
6] in 1989 and was one of the earliest embedding models. An LSA is a trained linear model with 200,000 words and fewer than 1 million parameters. The first neural language model was put forth by Bengio et al. [
7] in 2001, and the model worked on a feed-forward neural network that had been trained using 14 million words. The reason they are rarely used is that these early embedding models outperform conventional models with hand-crafted variables. A range of NLP tasks quickly gained popularity for a collection of word2vec models [
8] that Google released in 2013, which were trained on 6 billion words. Using Google’s Transformer [
9], a fresh NN architecture, in 2018, embedding models were produced by OpenAI. For text-generating projects, their original model, GPT [
10], is now extensively used. The same year, Google created BERT [
7], a bidirectional Transformer-based system. BERT, which includes 340 million parameters and 3.3 billion words of training data, is currently the most advanced embedding model. It is possible for convolutional neural networks (CNN) [
8] to learn local responses from spatial or temporal data, but not sequential correlations. Short-term dependencies in a sequence of data can be handled by recurrent neural networks (RNNs) [
9], but long-term relationships are a problem for these networks.
To overcome the constraints of the existing systems in evaluating user sentiments for a certain service or product, a unique methodology based on deep learning utilizing XLNet has been developed. The existing sentiment categorization systems have two issues with handling missing context semantics in text:
- i.
The existing studies primarily use language symbol information in texts to classify sentiments. Only a few research have looked at sentiment data with punctuation marks in the dataset. The issue of text context semantics can be resolved with the aid of punctuation symbols that include sentimental information;
- ii.
The majority of the ongoing research is focused on the extraction of emotional characterizations and the modeling of textual material at the document level. On the other hand, studies rarely take into consideration doing other levels of text content, such as words or phrases. To overcome the lack of text context semantics in social media assessments, sentiment information can be efficiently collected from many levels via the extraction of sentiment features and by modeling texts from various levels.
Given the above issues in existing models for sentiment classification, a model named the manifold and multi-level sentiment modeling method (MFMLSC) is proposed. Therefore, the main contributions of this work are as follows:
- i.
Based on two dimensions, language symbols and emoticon symbols, the manifold sentiment classification method (MFSC) is proposed. In this approach, the problem of text context semantics missing in text reviews is tackled using the word, sentence, and document levels;
- ii.
The multi-dimensional sentiment classification method (MDSC) uses two symbol types, i.e., emoticons symbols and linguistic symbols. This approach is used to tackle the problem of missing context information from texts, which plays a significant role in obtaining hidden information from sentiments;
- iii.
Based on the effectiveness of these two models, the final model is proposed as the multi-fold and multi-level sentiment modeling method (MFMLSC)
- iv.
The proposed model is implemented on three different datasets of Google Pay, Phonpe, and Paytm mobile app reviews. Additionally, the proposed model is validated on the IMDB benchmark dataset.
The rest of the sections are organized as follows.
Section 2 discusses the related work.
Section 3 provides details and describes the workings of the proposed model. In
Section 4, various settings and evaluation parameters are discussed. In
Section 5, a summary and the conclusions are presented.
2. Related Work
This section provides a comprehensive review of the recent studies, along with recommended methodologies for addressing sentiment analysis challenges based on word embedding and deep learning (DL) techniques. Next, the state-of-the-art literature is addressed, with a focus on sentiment analyses in different areas.
Over the last two decades, the classification of user sentiments has attracted an increasing number of scholars and yielded a large number of research findings [
10]. The classical machine learning and deep learning methods for classifying emotions mostly depend on supervised learning. The challenge is that natural language processing relies on efficient word embedding. By thoroughly training the global word–word co-occurrence of statistical data from the corpus, Mikolov et al. [
11] and Pennington [
12] first revealed that word vectors are learned through an RNN. As seen in [
13], the final global vector (GloVe) has an intriguing linear substructure in the word vector space. Tang et al. [
14] offered three models that took into account the text’s emotional propensity and learned word embeddings with the sentiment. Word2Vec embedding was used in [
15] to perform a sentiment analysis on reviews received from the Indonesian website Traveloka. It is estimated that their model is 91.9% accurate. The authors of [
16] presented a monitoring system based on DL and ontology to aid the traveling process. Fuzzy ontologies and Word2vec embeddings were utilized to construct the suggested system’s feature extraction module; the BiLSTM model was then used to classify the input text. According to Facebook, TripAdvisor, and Twitter data, the proposed technique was tested and found to be 84% accurate in its predictions.
A multi-layer architecture for customer evaluation approaches (such as word embedding and compositional vector models) was proposed in [
17]. A back-propagation technique was used to train the network and provide weights for the various aspects of the design once it had been integrated into a neural network. GloVe-DCNN, a brand-new device featuring a variety of sentimental qualities, was introduced in [
18]. Word embedding, n-grams, and the polarity score properties of sentiment words were used to create a deep CNN. The authors of [
19,
20,
21] developed a document representation system using the fuzzy bag of words paradigm (FBoW). An enhanced FBoW model that replaces the initial hard planning module with the Word2vec approach using fuzzy mapping was developed by replacing the original module with the Word2vec embedding. To determine the degree of similarity between words and clusters in seven different real-world document datasets, the researchers used three different approaches.
For the identification and condition analysis of traffic accidents, the authors of another study proposed a system based on using ontology with LDA (OLDA) and a BiLSTM network [
22]. OLDA was employed in the proposed system to extract data and label texts. As a result, classifiers such as FastText and BiLSTM are employed. This system was more accurate than the previous one. In another study, BiLSTMs were used to gather data on the long-term reliance on word and sentence locations [
23]. A CNN and BiLSTM were combined in the suggested hybrid strategy. LSTM outputs from sentence classification are applied to the multi-channel CNN to produce n-gram features. To find ADRs (adverse drug reactions) in electronic medical data, the authors of [
24] suggested using a deep learning approach (EHRs). The proposed approach used the joint AB-LSTM model and embeddings based on lemmas to locate ADRs. The proposed technique had an F-measure of 73.3% on the EHR dataset. The combined model, for example, outperformed previous models that used a stack of CNNs and LSTM deep learning models, as shown in [
25]. The dataset representation of Word2Vec is preferable to Word2Seq. Sentiment-based and dictionary-based representations of texts are some of the ways that texts are encoded. For extracting sentence features, the CNN model is paired with three attention methods. They concluded that the proposed CNN models were the most effective of all the models considered.
According to Hameed and Garcia-Zapirain [
26], the accuracy of the BiLSTM approach was 85.8% on the IMDB Movie Review and SST2 (Stanford Sentiment Treebank) datasets [
27]. The authors demonstrated that the BiLSTM method is both more efficient and suitable for sentiment analysis problems. Word2Vec, LSTM, RNN, and CNN methods were utilized by Xu and colleagues [
28] to extract emotions from Chinese hotel reviews. The model with the highest F-score, 92%, was the BiLSTM method.
Some researchers have proposed hybrid deep learning-based models to improve accuracy, such as the LSTM-CNN grid-search (GS) approach for Amazon and IMDB reviews [
29]. The authors utilized a grid-search technique and compared it to CNN, LSTM, CNN–LSTM, and other approaches. Their model outperformed several baseline models with an overall accuracy of 96%. In a similar study, the researchers [
30] used Amazon reviews to model topics before using a CNN to identify views. The authors stated that their proposed approach improved the accuracy by 6 to 20% in comparison with the established methods.
Further studies were conducted on the more efficient embedding approach, BERT, and its derivatives in enhancing the analysis of sentiments for user reviews. The authors of [
31] employed BERTCNN to improve a sentiment analysis for commodities reviews, with the results stating that the BERT-CNN (F1-score of 84.3%) outperforms the BERT (82%) and CNN (84.3%) (70.9%) approaches. Similarly, in [
32] the SenBERT-CNN (sentiment BERT-CNN) was proposed for analyzing the feedback for JD.com, a mobile phone supplier, by merging the BERT and CNN approaches to obtain deep characteristics of the dataset. When the LSTM, BERT, and CNN approaches were compared, the authors found that BERT-CNN worked the best, with a score or 95.7%. In [
33], on the other hand, a dataset from Drugs.com was used to develop neural network models for predicting reviews of drugs. On a scale from 0 to 9, patients’ levels of happiness were given scores between 0 and 9. The authors tested many neural network models, including the BERT-LSTM model, with the following methods: 10-class and 3-class compressed forms of the dataset. The results showed that the BERT-LSTM model was the best-suited for the 3-class setup, even though it took a very long time to train. Others examples include [
34], who used BERT to train different NN models on a dataset of movie reviews. The results showed that BERT was the most accurate, while [
35] used BERT to analyze Twitter sentiments by turning jargon into plain text for BERT training.
Additionally, in [
36], the authors suggested a deep learning model using BERT for ADE (adverse drug effect) retrieval and detection to find pharmacological side effects. As a classifier and retrieval tool, the proposed model utilized sentence structure feature embeddings and BERT. Furthermore, in [
37], the authors developed a method for extracting medical relations that relied on a pre-trained technique and a mechanism of fine-tuning rather than manual labeling. For feature extraction, the suggested method combined the BERT architecture with one-dimensional convolutional neural networks (1D-CNNs). The suggested method was tested on three datasets: the BioCreative V chemical relation corpus of illness, a classical Chinese literature dataset, and the i2b2 2012 temporal relation challenge dataset, and F1 score values of 0.7156, 0.8982, and 0.7085, respectively, were obtained. It was proposed by Ma et al. [
38] that an enhanced version of Sentic LSTM be used for a joint task that combined the target-dependent detection of aspects and targeted aspect-based polarity classification. In another study, Sentic LSTM was developed by Ma et al. for the explicit integration of explicit and implicit information. By refining pre-trained word vectors with scores of sentiment intensity provided by sentiment lexicons, Gu et al. [
39] presented a word vector refinement method that improved each word vector and performed better in the sentiment analysis. Hashida et al. [
40] created a hybrid paradigm of multi-channel decentralized representation for textual data.
Various pre-trained language models, such as ELMo [
41], BERT [
42], and GPT [
43], have recently demonstrated effective performance. Various Transformer-based language models such as BERT [
42], robustly optimized BERT pre-training approach (RoBERTa) [
44], and a lite BERT for self-supervised learning language representations (ALBERT) [
45], have recently obtained the highest performance in many NLP tasks. Transformer’s bidirectional encoder representation is known as BERT. Position embedding and word embedding are included in BERT’s inputs. BERT’s feature representation layers, unlike those of 1D-CNN and LSTM, rely on both left and right context information. A more advanced embedding technique, known as BERT, was also found to be useful in improving the sentiment analysis of reviews. Another study [
46] examined the sentiment analysis performance of the SVM, multi-nomial naive Bayes, LSTM, and BERT approaches. Stemming, tokenization, lemmatization, and punctuation removal were among the preprocessing techniques used. The dataset includes 1.6 million tweets classified as good or negative. The study determined that BERT’s performance was the best, with an accuracy rate of 85.4%. Two deep learning algorithms were created by the authors of [
47] for the analysis of sentiments in multi-lingual social media text. During Pakistan’s 2018 general election, Twitter was used to gather data. 80% of the dataset was used for training and 20% for testing. The XLM-RoBERTa and multi-lingual BERT (mBERT) from Transformer approaches were studied for their performance in this regard (XLM-R). The mBERT learning rate was set to 2 × 10
−5, and the XLM-R learning rate was set to 2 × 10
−6 during the hyperparameter tweaking. Furthermore, mBERT had a precision rate of 69%, while XLM-R had a precision rate of 71%, according to the results of the trial. Using a deep bidirectional long short-term memory (DBLSTM) approach, in [
48] the sentiments of Tamil tweets were analyzed. The dataset contains 1500 tweets categorized as either positive, negative, or neutral. The data were cleaned and pre-trained using the Word2Vec model before being represented using the DBLSTM word embedding approach. Furthermore, 80% of the dataset was utilized for training and 20% for testing. The DBLSTM approach was shown to be 86.2% accurate in the research. In a recent study [
49], the authors proposed an adversarial strategy for handling the domain shift problem. The adversarial meaning stems from the parallel structure designed between the loss function on training samples and that on test samples. Using a projector and classifier, they presented a theoretical analysis of several benchmark datasets. In [
50], the researchers performed a survey on an aspect-based sentiment analysis (ASBA). The authors showed a comparison of several techniques used in the ASBA.
In recent years, numerous studies have presented deep-learning-based sentiment assessments, each with its own set of characteristics and performance results. The traditional method for sentiment analyses is suitable for dealing with the categorization of small-scale texts. In the face of huge amounts of data, the analytical efficiency is low, and locating sentiment information is challenging. In recent years, deep learning approaches have demonstrated promising accuracy and efficiency in textual data sentiment classification. With the advent of Transformer-based pre-trained representations, the accuracy and efficacy have increased dramatically. Consequently, this study investigates and proposes a unique sentiment classification model based on the deep learning technique and XLNet’s autoregressive pre-trained model.
3. Proposed Model
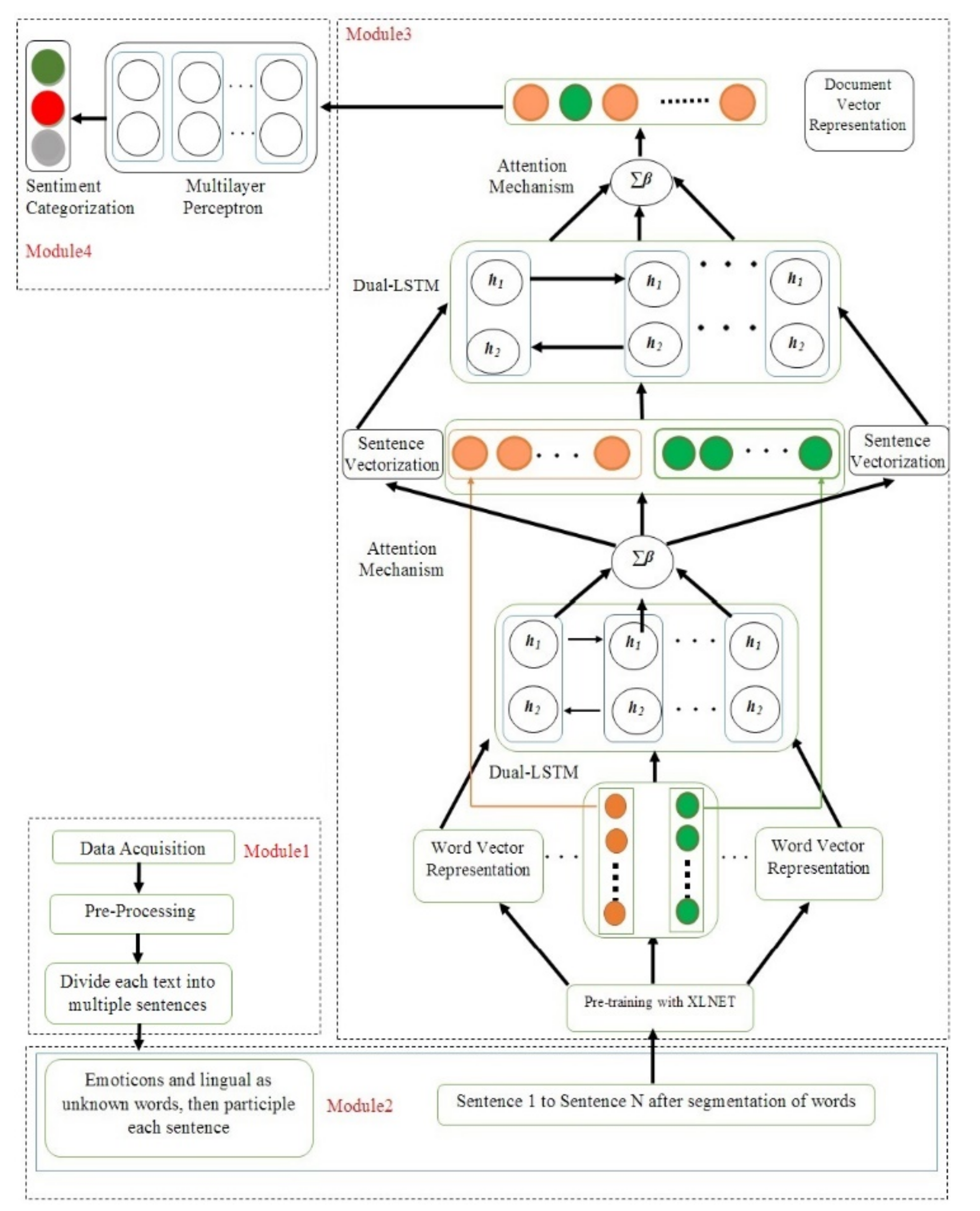
The proposed model primarily consists of two major components. Manifold emotion modeling is a technique that incorporates three different components: words, sentences, and documents. The second method makes use of language and punctuation marks to model multi-dimensional sentiments in two dimensions. Each word in the dataset is broken up into its unique phrase by using emoticons as separators. Through the practice of regarding emoticons and linguistic markings as unrecognized words, every sentence is segmented utilizing the word segmentation methodology that is currently in use. A technique for modeling the emotions associated with textual material is presented with three levels: word, phrase, and document. A multi-dimensional technique for classifying sentiment is given for modeling the text content using two dimensions: language-based symbols and emoji symbols at the word and sentence level.
The multi-fold with multi-level modeling results are inputs into the multi-level perception network using the pre-trained autoregressive word representation model XLNet to produce the final sentiment classification results (
Figure 1). The algorithm of the proposed model is shown as Algorithm 1.
| Algorithm 1: Multi-Fold Dimensional Modeling Method for Sentiment Classification |
- 1:
input: IDocument - 2:
output: IDocumentDVector - 3:
initialization of the XLNet and Dual-LSTM models - 4:
IDocumentSVector = [] - 5:
for each sentence in IDocument: - 6:
for each W_word, emoji in sentence: - 7:
WVector = BERT(W_word) - 8:
L_languageWVector = XLNet (L_language) - 9:
P_emoticonsWVector = XLNet (P_emoticons) - 10:
sentence WVector = [WVector, emoticon WVector] - 11:
SVector = Attention(Dual-LSTM(S WVector)) - 12:
L_languageSVector = L_languageWVector - 13:
sentence SVector = [SVector, L_languageSVector] - 14:
IDocumentSVector += sentence SVector - 15:
IDocumentDVector = Attention(Dual-LSTM(IDocumentSVector))
|
The proposed model is divided into four modules. The module-wise discussions of the proposed model are presented below.
3.1. Pre-Processing
The goal of the pre-processing phase is to remove all extraneous words from the corpus.
The following are the major stages of the pre-processing phase:
- i.
Using the WordPiece tokenization paradigm, each word in the social input text is tokenized and can be broken into several sub-words;
- ii.
The Natural Language Toolkit (NLTK) removes stop words (is, the, a, etc.);
- iii.
Slang is converted to more formal forms;
- iv.
By eliminating texts that include indentations or by employing a widely unused set of suffixes and indentations, such as “-ing” or “pre-,” one can restore extracted words to the word stem format using a rule-based stemmer technique;
- v.
Lemmatization removes inflection endings and returns words to the dictionary format. The proposed approach utilizes the NLTK suffix-dropping algorithm for stemming and lemmatization to improve the lexical context and analysis;
- vi.
Uppercase characters are converted to lowercase characters and repeated characters to their generic form;
- vii.
Spelling corrections are made using the Levenshtein distance and by selecting misspelled keywords.
Punctuation marks are used to divide cleaned and pre-processed texts into sentences. Punctuation is a collection of symbols that control and clarify the contents of various texts. Punctuation serves to clarify the meanings of texts by connecting or separating words, phrases, and clauses. As a result, punctuation is used to transform words into sentences.
XLNet
XLNet is a novel NLP pretraining approach that produces cutting-edge outcomes on several NLP tasks. Autoregressive (AR) language modeling and autoencoding (AE) are two pretraining aims for pretraining neural networks used in transfer learning NLP that have been proven effective. While avoiding the limitations of the two types of language pretraining objectives (AR and AE), XLNet incorporates concepts from both.
3.2. Multi-Fold Sentiment Modeling Method (MFSC)
The majority of the current research focuses on document-level text content modeling and sentiment feature extraction, with minimal attention paid to the interaction and correlation among sentences in the document. Between successive sentences in the text, there are evident progressive (forward) and adversative (reverse) linkages, as well as clear correlation and reciprocal influences between terms. As a result, the technique is suggested here for multi-fold sentiment modeling. The extraction of sentiment features and modeling content of text at several levels, such as words, phrases, and documents, helps address the lack of context semantics in dataset texts.
The multi-fold sentiment modeling method has three stages, the (i) word, (ii) sentence, and (iii) document levels. In the first fold of words, the input is the outcome of the segmentation `of sentences. The outcome of this process is the representation of the word vector for the given sentences. In the second fold, i.e., the sentence level, the input for the model is the representation of vectorized words of the given set of sentences, and the outcome is the representation of vectorized sentences from the set of sentences. The multi-dimensional sentiment model is described in detail in the next section. The vectorized collection of several sentences is provided as the input in the document fold, and the result is the vectorized document.
The specifics at the document level are listed below.
- i.
Based on the grammatical rules and conjunctions between sentences, two types of relations are obtained: forward relations and reverse relations;
- ii.
The attention-based network is provided with prior knowledge of the following two types of relationships between sentences. Sentences with a reverse connection should have opposing sentiment polarities as much as is feasible. Sentences with forwarding relationships should have uniform sentiment polarity as much as is feasible. An attention-based system at the sentence level that is based on relationship constraints between sentences is provided here. This mechanism takes into account the two different sorts of linkages that exist between sentences. In the research, the attention-based method utilizes the attention formula at the phrase level;
- iii.
The vectorized text of every phrase is provided as the input for the dual-LSTM network based on the limitations of the attention-based mechanism, and the vectorized view of the given document is collected.
An output for sentiment categorization is generated by a multi-layer perception network using the representation of a vectorized document that has been obtained. Equation (1) provides a definition of the sentiment classification function that is based on multi-fold and multi-dimensional sentiment modeling:
Here, the total number of texts is represented by M, which represents the model of the sentiment classification; is the representation of the vector of the jth text is the sentimental orientation of the jth text; and is the factor of attention for the word level; is the factor of attention for the sentence level; is the factor of similarity of sentiment text j and sentiment phrase k; is the similarity factor of sentence j and sentence k; , , and ∂3 represent the various hyperparameters.
3.3. Multi-Dimensional Sentiment Classification Method (MDSC)
The primary actions involved in multi-dimensional sentiment modeling at the level of individual words are discussed below:
- (1)
Since emoji and linguistic data provide information about sentiments, the dataset that contains emoji and linguistic symbols is used as the input to the language model, i.e., pre-training XLNet;
- (2)
Emojis and linguistic symbols are processed in the same way as sentiment words when a pre-trained model is used to model information available on social networks. This leads to the creation of the linguistic symbol word vector as well as the emoticons symbol word vector. This combination produces a multi-dimensional representation of the text’s emotions.
The following are the primary steps in the multi-dimensional sentiment modeling at the sentence level:
- i.
The attention network provides prior knowledge of sentimental words. An approach based on word-level attention on the dictionary of sentiment restriction is provided, with the attention coefficients of sentiment-related words being as similar as possible. The attention formula is based on the attention formula at the word level;
- ii.
Vectorized words of language symbols and emoji symbols are given as inputs to a dual-LSTM network integrated with attention; the output is received as the vector of sentences of language symbols;
- iii.
The vectorized words of the emoji symbols are taken as outputs as the vectors of sentences of the emoji symbols directly;
- iv.
Combining the obtained sentence vectors of language symbols with emoticon symbols yields the sentence vectors.
The detailed mechanism of sub-modules is discussed below.
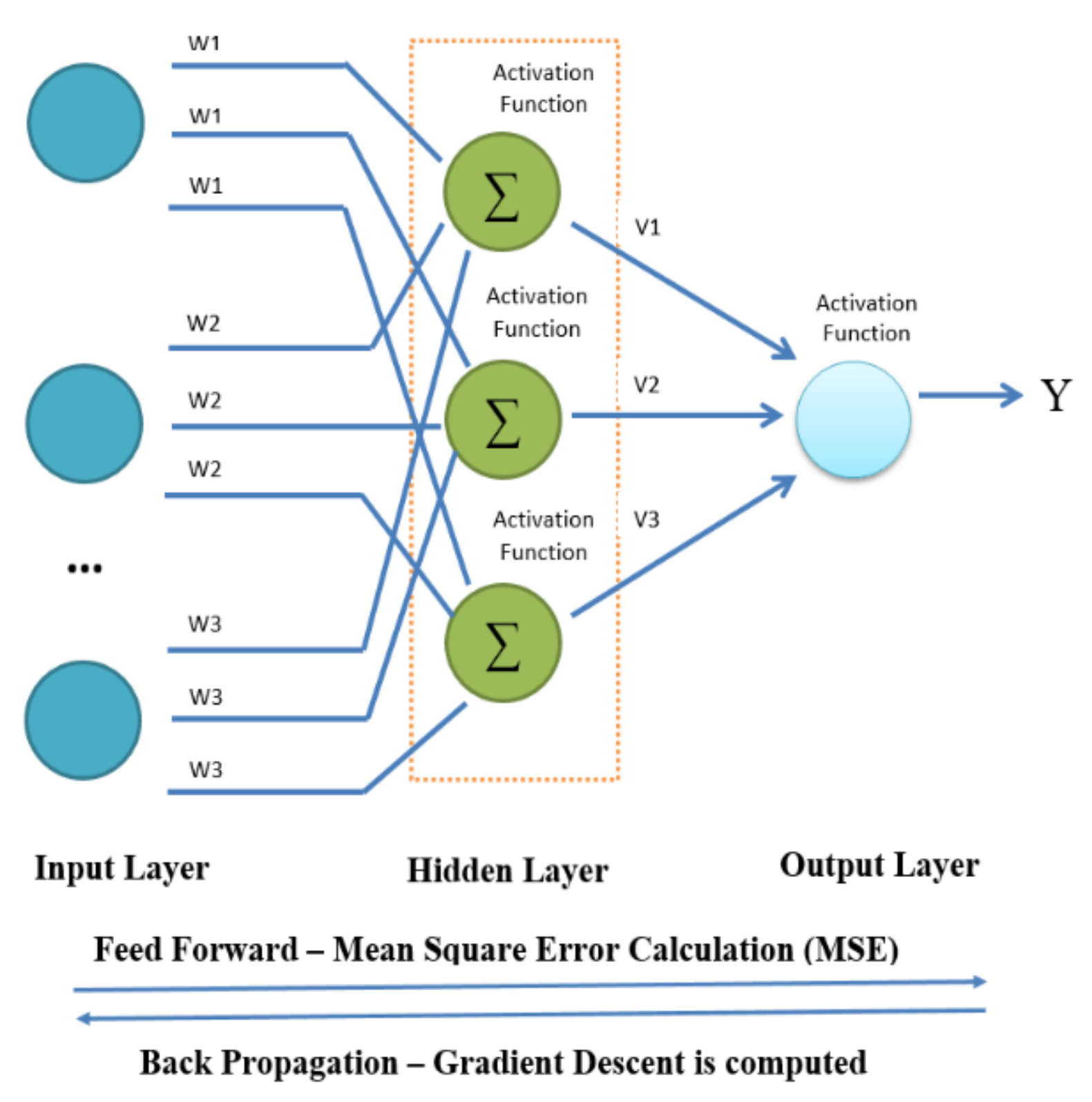
3.4. Sentiment Classification Using Multi-Layer Perceptron
The document vector representation is fed into a multi-level perceptron. The following parameter settings shown in
Table 1 are used in obtaining optimized performance during sentiment classification. These parameters are obtained by performing several experiments with different parameters.
Using the above parameters in
Table 1, the multi-layer perceptron (as shown in
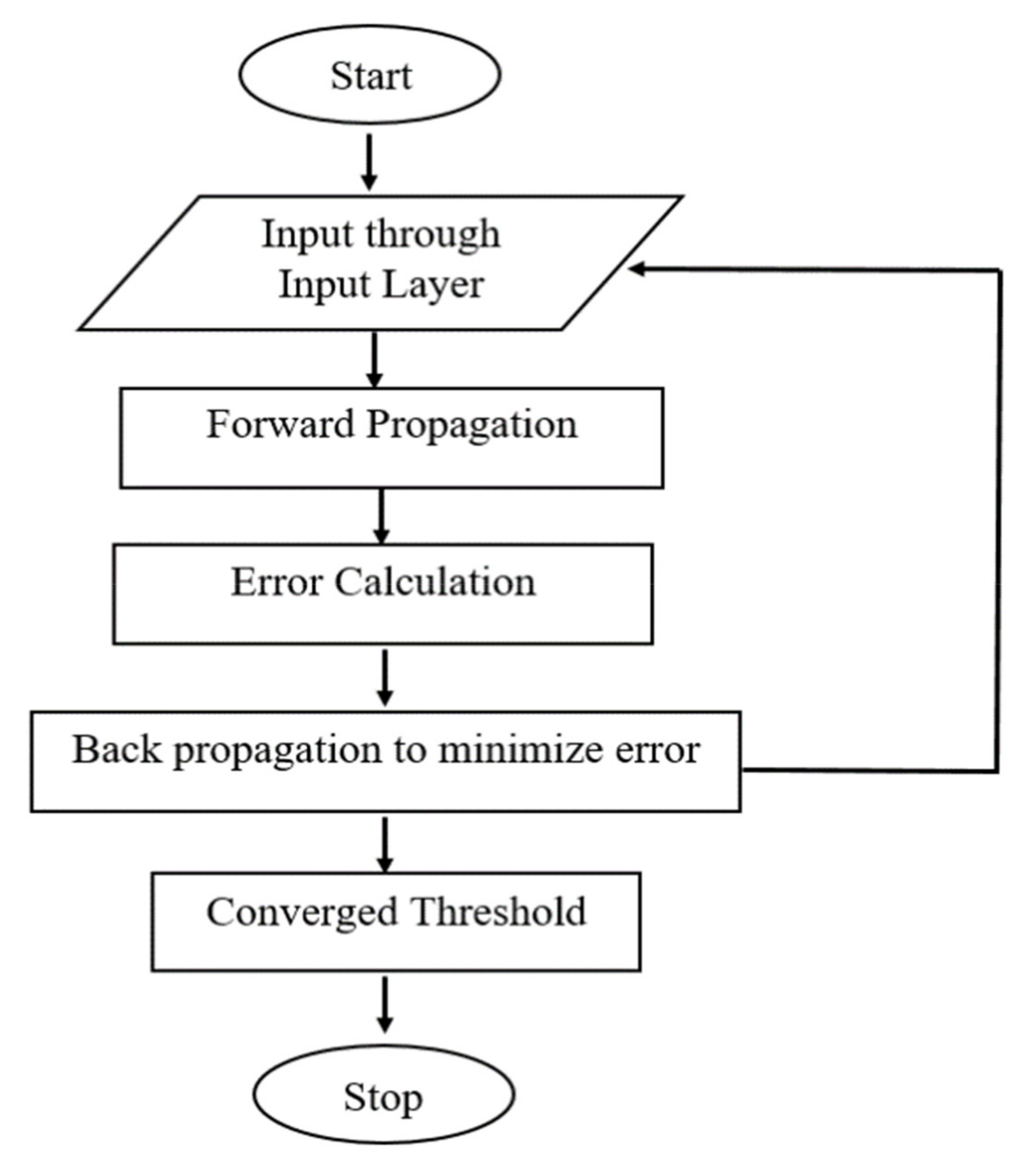
Figure 2) goes through the learning process and the output class labels are obtained using the below process, the MLP learning Procedure, as shown in
Figure 3.
- i.
Using forward propagation, the data from the input layers are transmitted to the output layer;
- ii.
The error is calculated based on the received output (the difference between the predicted outcome and the achieved outcome);
- iii.
The error is back-propagated and its derivatives are obtained concerning all weights in the network, then the model is updated.
These three steps are repeated over multiple epochs to learn the ideal weights. Finally, the output is achieved through a threshold function to obtain the predicted class labels.
The error, i.e., the mean square error, is calculated using the following equation:
Here, is the gradient of the current iteration, is the bias, is the error in each iteration, the weight vector is represented by , represents the learning rate, and the gradient of the previous iteration is denoted by
This process continues until each input–output pair’s gradient has converged, which means the freshly computed gradient has not changed more than the set convergence threshold since the previous iteration. Here, the network updates are performed incrementally.
4. Results and Discussion
4.1. Data Acquisition
Using the Google Play Scraper package with Python APIs, the dataset for three popular UPI mobile payment apps were collected. The three payment apps were GooglePay, PhonePe, and Paytm. Google Play Scraper offers Python APIs for crawling the Google Play Store without external dependencies. The details of the dataset obtained are as shown in
Table 2. Here, we considered only positive and negative reviews, while neutral reviews were not considered.
In this process, the equations are numbered consecutively, with equation numbers shown in parentheses flush with the right margin of the column, as in (1). First, use the equation editor to create the equation. Then, select the “Equation” markup style. Press the tab key and write the equation number in parentheses. To make your equations more compact, you may use the solidus (/),exp function, or appropriate exponents. Use parentheses to avoid ambiguities in denominators. Punctuate equations when they are part of a sentence, as in:
4.2. Data Augmentation
A balanced dataset facilitates the establishment of unambiguous decision limits for every class and enables models for the classification of data more precisely in any classification task. Any unbalanced dataset can be converted to a balanced one using data augmentation techniques, guaranteeing that the dataset is consistent across labels. The algorithm is named SMOTE [
51], and is a commonly used data augmentation approach that may be used for any dataset without any influence on predictions based on a particular label. SMOTE samples the class with a minority with the help of a k-nearest neighbours classifier; it selects samples close to the feature space and generates synthesized data points. In this study, we use SMOTE to balance the dataset in terms of the labels and performs an evaluation.
4.3. Performance Measurement
To assess how well the suggested model works, an accuracy matrix is computed. For positive sentiment classification, true positive and false positive variables are identified. For negative sentiment classification, the true negative and true positive variables are defined as shown in
Table 3.
Using the parameters in
Table 3, the following equation is defined to assess the accuracy of the proposed model:
4.4. Performance Evaluation
For a clear view of and simplicity in the graphical representations, the models are termed hereafter as shown in
Table 4.
A hyperparameter is a value for a parameter that is used to influence the learning process. Different hyperparameters are tuned for optimized performance accuracy. Comprehensive experiments are performed using several hyperparameters, such as the embedding type, activation function, and dropout.
The deep learning methods CNN and BiLSTM with different word embedding methods, i.e., Word2Vec and BERT, are tested on different hyperparameters. The proposed model is also tuned with several hyperparameters. The hyperparameter tuning process is performed with different embedding combinations on 200, 300, and 400 words and with learning rates ranging from 0.01 to 0.10. The observations of these experiments are shown in
Table 5 and
Table 6.
The above
Table 5 provides the performance accuracy rates of different models with an embedding size of 200 with dropout from 0.01 to 0.10. All models M01, M02, M03, M04, M05, M06, M07, M08, and M09 are tested using this combination. It can be observed that the proposed model achieves the highest classification accuracy rate of 96.62% using a dropout rate of 0.10 for dataset 1.
For dataset 2, the highest accuracy can be observed for the dropout of 0.04 with 95.95% accuracy. At the same time, 96.36% accuracy is obtained for dataset 3 at a dropout rate of 0.04. The accuracy rates of the other models vary depending on the different dropout values. Overall, the proposed model shows the highest performance in terms of classification accuracy as compared to the other eight models.
Table 6 shows the classification accuracy performance for the embedding size of 300 and with dropout rates ranging from 0.01 to 0.10. As per the observations for the above figure, it is clear that none of the models shows consistent performance. For example, model M01 shows an accuracy rate of 67.36% for dataset 1, but for dataset 2 the accuracy decreases to 64.32%, and again the model achieves a higher accuracy rate of 68.62% for dataset 3, with a dropout rate of 0.01. Model M02 achieves its highest accuracy rate of 77.46% for dataset 2 with a dropout rate of 0.09, whereas the lowest accuracy rate of 67.33% is achieved with a dropout rate of 0.04. The observations from the experiments with an embedding size of 300 and dropout rate of 0.03 indicate that this combination with other hyperparameters has shown consistent performance for all models.
Table 7 shows the accuracy performance for the embedding size of 400 and with dropout rates ranging from 0.01 to 0.10. The observations show that except for the proposed model, none of the models show consistency.
Table 8 above shows the average performance accuracy of each model for the three datasets. The average accuracy is measured on dropout rates ranging from 0.01 to 0.10 for an embedding size of 200. Model M01 exhibits the lowest accuracy rate of 61.45% for the 0.01 dropout rate and the highest average accuracy rate of 71.38% for the 0.10 dropout rate. Model M02 has the lowest average accuracy rate of 61.65% for the dropout rate of 0.06 and the highest average accuracy rate of 73.17% for the dropout rate of 0.04. For models M03, M04, M05, and M06, the lowest observed performance results are 60.96% for a dropout rate of 0.09, 69.08% for a 0.08 dropout rate, 80.98% for a dropout rate of 0.10, and 81.90% for a dropout rate of 0.01, respectively. The highest accuracy rates achieved for these models are 75.11% for M03 using a dropout rate of 0.10, 85.05% for M04 on a dropout rate of 0.10, and 86.24% for M05 using a dropout rate of 0.09, while for M06, the highest average accuracy can be observed for a dropout rate of 0.10, with 88.63%. The highest average performance rate for model M07 can be observed for a dropout rate of 0.09%, with an accuracy rate of 92.89%, whereas the lowest average accuracy rate of 84.60% can be observed with a floor dropout rate of 0.01%. The performance of the proposed model is the highest among all models, with the lowest average accuracy rate of 91.53% for a dropout rate of 0.02, whereas the highest accuracy rate of 96.21% can be observed for a dropout rate of 0.04. In
Table 8, the observations clearly show that the proposed model performs much better and is more consistent for all dropout rates as compared to the other eight models.
Table 9 shows the comparative observations of all models with dropout rates of 0.01 to 0.10 for an embedding size of 300. Again, the observations show that none of the models achieve better performance than the proposed model. For an embedding size of 300, all the models show much better performance as compared to the embedding size of 200. Model M01 shows the lowest average accuracy rate of 66.77%, which is 5.32% more than that of the embedding size of 200. The highest performance rate for model M01 is 78.17% for a dropout rate of 0.1, which is again much better than the performance of model M01, which is just 71.38% for the embedding size of 200. Model M02 has the lowest average accuracy rate of 66.34% for the dropout rate of 0.04. The highest performance accuracy rate for M02 of 77.19% can be observed for the dropout rate of 0.09. For the dropout rate of 0.01, an exceptional case can be identified for model M05, which shown better performance than model M09, with an average accuracy rate of 93.82%, while the proposed model shows a 92.65% average accuracy rate. The overall observations in
Table 9 show that except for model M09, none of the models are consistent, but the proposed model M09 shows clear and consistent performance, with the highest average accuracy rate of 97.3% for the dropout rate of 0.03 and embedding size of 300.
For the embedding size of 400 and using different dropout rates ranging from 0.01 to 0.10, the average classification accuracy results are shown in
Table 10. As far as the performance is considered, the same trend can also be observed here, showing that the proposed model M09 outperforms the other models but these embedding and dropout combinations do not achieve the highest and most consistent performance for all models as well as the proposed model. The proposed model shows better performance than the other models, but these hyperparameter combinations do not achieve the best performance.
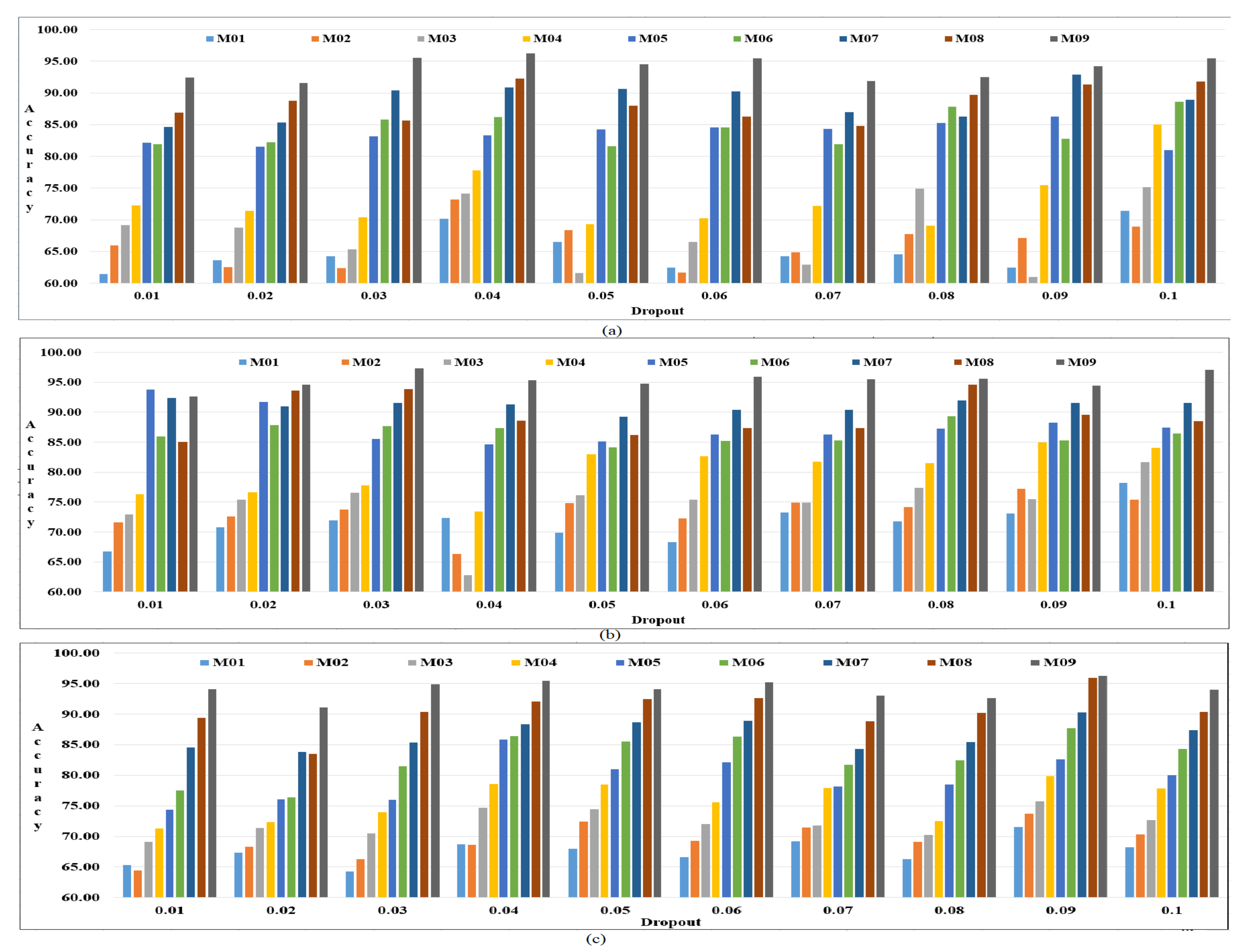
Figure 4a–c depict the average performance accuracy results for all of the models for the three datasets.
Figure 4a shows the average performance accuracy results for an embedding size of 200 and with dropout rates ranging from 0.01 to 0.10.
Figure 4b shows the average performance accuracy results for an embedding size of 300 and with the dropout rates ranging from 0.01–0.10.
Figure 4c shows the average performance accuracy results for an embedding size of 400 and with the dropout rates ranging from 0.01 to 0.10. The experimental findings for the three datasets demonstrate that the proposed model shows effective and efficient performance over the other models, and except for very few combinations of hyperparameters, the models do not show consistent performance results.
Out of all the models under consideration, and particularly as compared models M01 and M02, when Word2Vec is applied with CNN and BiLSTM, respectively, the response of the model is very poor. If BERT is used in place of Word2Vec then some improvement can be observed in inaccuracy, which shows the effectiveness of the BERT model in text classification. The BERT model shows its supremacy over the Word2Vec model, with improvements of 5% to 10% for sentiment classification. Models M05, M06, M07, and M08 also show improvements, but the proposed model shows the highest and most consistent performance for all datasets for the embedding size of 300 and dropout rate of 0.03. Since this combination showed consistent performance for other models, the embedding size 300 and dropout rate of 0.03 were implemented on all datasets for all models to conduct further experiments, as shown in
Table 11.
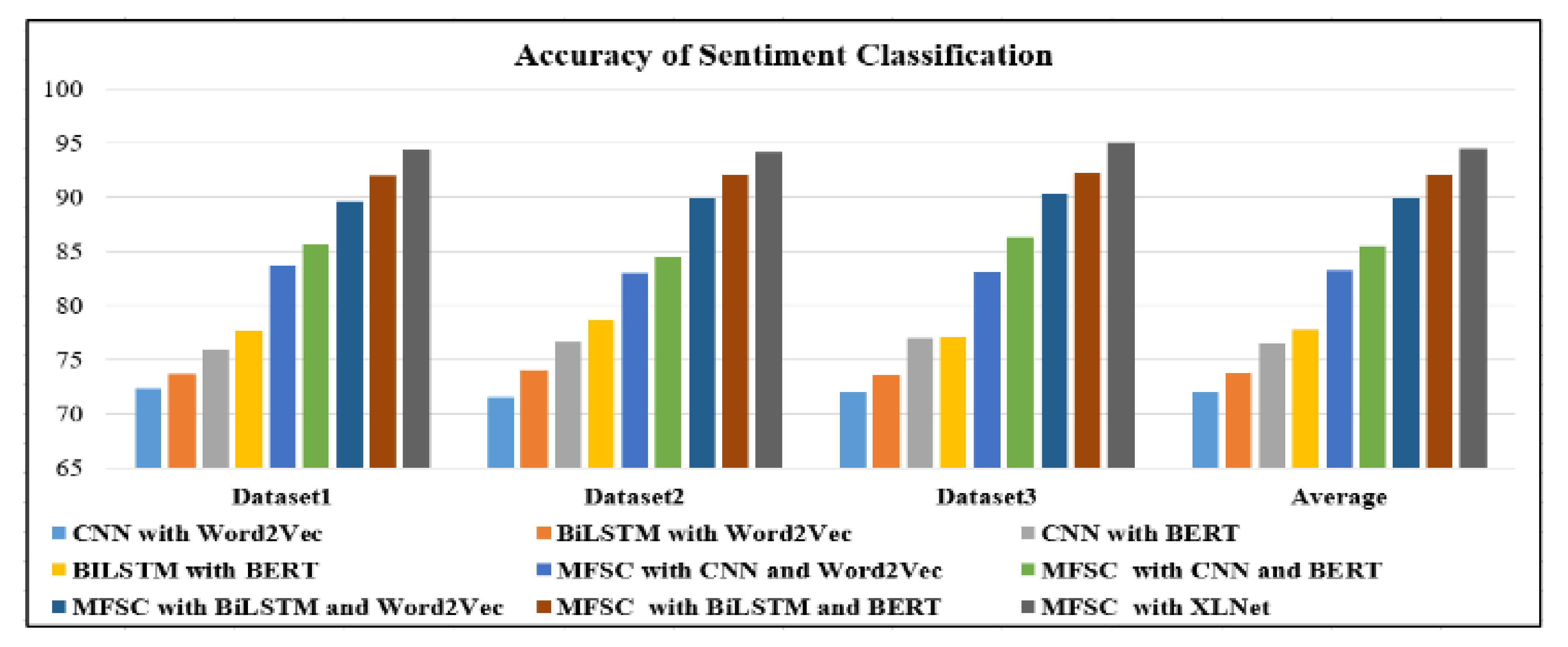
4.5. Evaluation of Multi-Fold Model of Sentiment Classification (MFSC)
To investigate the performance of a sentiment classification approach that relies solely on multi-dimensional sentiment modeling, the performance of the proposed multi-fold sentiment modeling method with XLNet (MFSC) shown in
Table 12 and
Figure 5 is compared with a CNN with Word2Vec, BiLSTM with Word2Vec, CNN with BERT, and BILSTM with BERT. The methods are discussed below.
CNN with Word2Vec: Firstly, Word2Vec is used to initialize the vectorized word, following which CNN is applied to extract the features of the sentiments from the dataset, and finally a fully connected network is used for sentiment classification of the social media text.
BiLSTM with Word2Vec: In this instance, Word2Vec is applied to achieve the word vectors, then BiLSTM is implemented for extraction of the sentiment characteristics of a given dataset, and finally a fully connected network is used for implement sentiment classification of the dataset.
CNN with BERT: The initialization of the word vector is accomplished with the help of BERT, then the CNN is applied for extraction of the sentiment features of the dataset, and finally a fully connected network is used for sentiment classification of the dataset.
BILSTM with BERT: Here, BERT is utilized to initialize the vector of words, followed by the BiLSTM technique being used for extraction of the sentiment features of the dataset, then in the last phase a fully connected network is used to implement sentiment classification of a dataset.
MFSM with CNN and Word2Vec: The Word2Vec, CNN, and MFSM approaches are used to classify sentiments. To begin, emoji-based symbols are treated as language symbols in a social media text. Next, Word2Vec is implemented to for the initialization of the word vector, and the CNN extracts sentiment characteristics from the dataset. Finally, the sentiment categorization approach is accomplished through a completely connected network.
MFSM with CNN and BERT: the BERT, CNN, and MFSM approaches are used to create a sentiment classification system. To begin, both language symbols and emoticon symbols are handled in datasets in the same manner as language symbols. Next, BERT is used for the initialization of the word vector, and the CNN is implemented to extract the emotional components of the dataset. Finally, the sentiment categorization approach is accomplished through a completely connected network.
MFSM with BiLSTM and Word2Vec: The Word2Vec, BiLSTM, and MFSM-based sentiment categorization approaches are used. To begin, all symbols in a dataset, including language symbols and emoticon symbols, are regarded as language symbols. The vector of the word is then initialized using Word2Vec, and the BiLSTM model extracts features of sentiments from the dataset. Finally, the sentiment categorization approach is accomplished through a completely connected network.
MFSM with BiLSTM and BERT: This is a sentiment categorization approach based on the BERT, BiLSTM, and MFSM models. To begin, in the dataset, language symbols and emoticon symbols are both treated as language symbols. The BiLSTM model collects sentiment characteristics from the dataset after initializing the word vector with BERT. Finally, a completely connected network is used to achieve sentiment categorization.
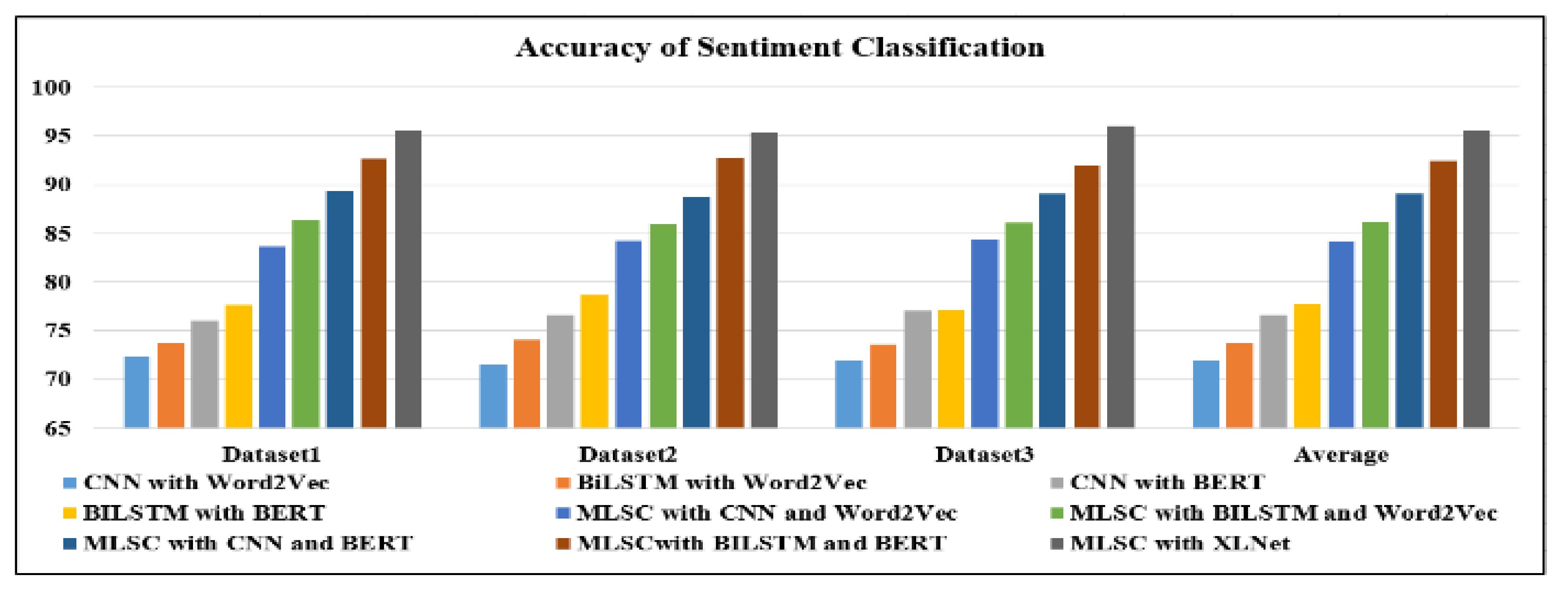
4.6. Evaluation of Multi-Level Model of Sentiment Classification (MLSC)
In the second phase of the performance evaluation of the proposed model, the evaluation is conducted only with the multi-dimension model of sentiment classification (MLSC). The MDSC model with XLNet is compared with the CNN with Word2Vec, BiLSTM with Word2Vec, CNN with BERT, and BILSTM with BERT approaches, as shown in
Table 13 and
Figure 6. In addition to these models, the MDSC model is also implemented with the abovementioned techniques.
MLSC with CNN and Word2Vec: The classification of sentiments is accomplished with the assistance of the Word2Vec, CNN, and MLSM models. Initially, the vectorized word is populated with the help of Word2Vec, and then with a CNN-based attention mechanism, the emotional characteristics of the dataset are retrieved from different levels of words, sentences, and phrases. Lastly, the completely linked network is used to implement the sentiment classification.
MLSC with BILSTM and Word2Vec: This is a Word2Vec, BiLSTM, and MDSC-based sentiment categorization algorithm. Here, Word2Vec is used to initialize the word vector, and then BiLSTM is used to extract sentiment features of the dataset from different levels of words and sentences using an attention mechanism. Finally, the completely linked network is used for sentiment classification in the given dataset.
MLSC with CNN and BERT: This is a BERT, CNN, and MDSC-based sentiment classification approach. The word vector’s initialization is achieved using BERT, and then the CNN is utilized to extract the sentiment features of the dataset from different levels, as discussed using an attention mechanism. Finally, the completely linked network is used for the sentiment classification of the dataset.
MLSC with BILSTM and BERT: This is a BERT, BiLSTM, and MDSC-based sentiment classification approach. BERT is used to initialize the word vector, and then BiLSTM is utilized to extract the sentiment features of the dataset from the given levels using an attention mechanism. In the final phase, using a fully interconnected computer network, the dataset classification process is carried out
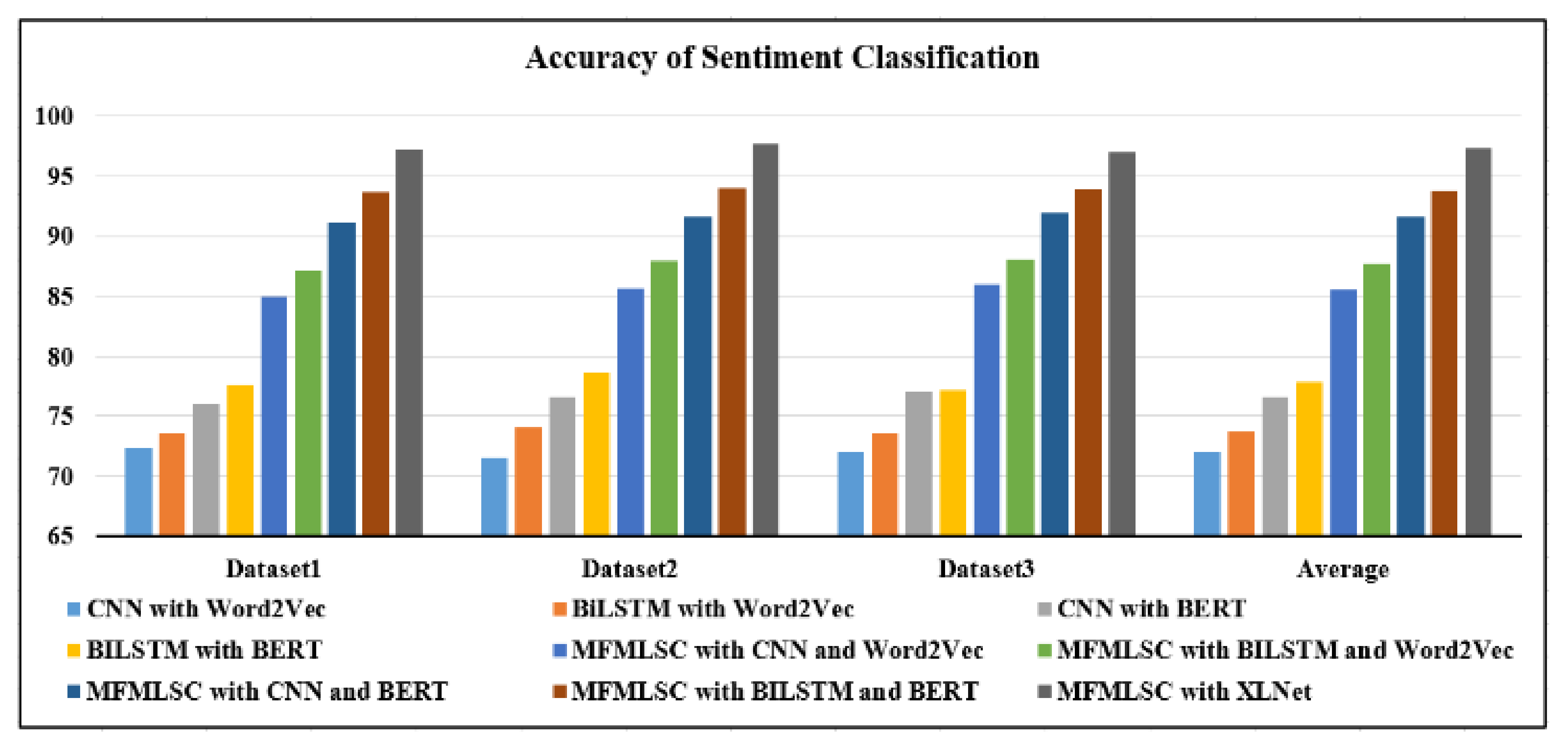
4.7. Assessment of Multi-Fold and Multi-Level Modeling of Sentiment Method (MFMLSC)
To assess our method’s overall performance, the performance results in terms of the multi-fold and multi-level classification for the sentiment method are compared with the methods discussed in the previous section.
As shown in
Figure 7 and
Table 14, the proposed model achieves the maximum performance as compared to the other deep learning models that use combinations of different deep learning and word embedding models. For the embedding size of 300 and dropout rate of 0.03, the proposed MFMLSC shows the highest accuracy rates during sentiment classification, with scores of 97.23%, 97.65%, and 97.01% for datset 1, dataset 2, and datset 3, respectively. The proposed model outperforms the other models, with an average accuracy rate of 97.30%.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}