

Deep Clustering Efficient Learning Network for Motion Recognition Based on Self-Attention Mechanism

Abstract
:1. Introduction
- (1)
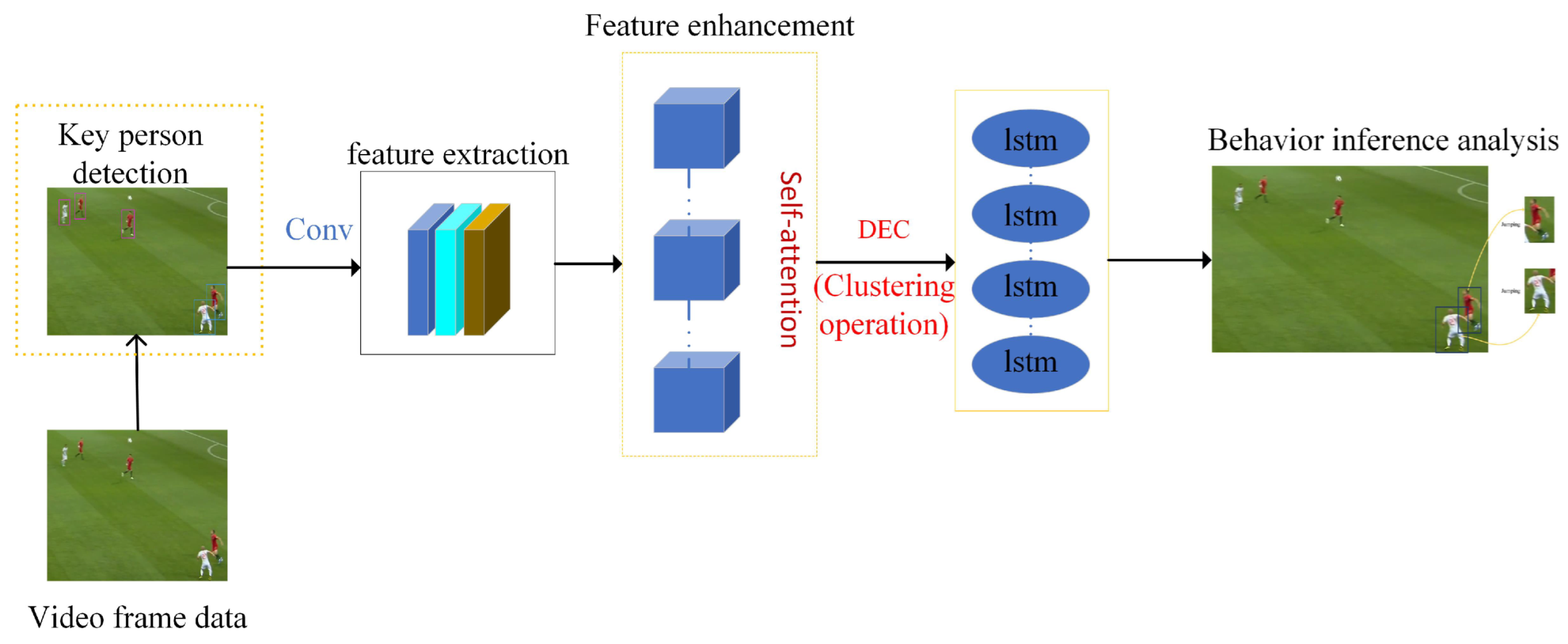
- Through the LSTM, this network can not only solve the problem of gradient disappearance and explosion in the recurrent neural network (RNN), but also capture the internal correlation between multiple people in the sports field for identification, etc.
- (2)
- On the basis of (1), the DEC is added to integrate the motion coding information in key frames to improve the judgment efficiency.
- (3)
- With the self-attention mechanism, it can not only analyze the whole process of the whole sports video macroscopically, but also focus on the specific attributes of the movement to capture more important details, extract the key posture features of athletes, and further enhance the features, effectively reducing the parameters of the self-attention mechanism in the calculation process, reducing the computational complexity while maintaining the ability to capture details, and improving the accuracy and efficiency of reasoning and judgment. Through verification on large video datasets of mainstream sports, we achieved high accuracy and improved the efficiency of detection and recognition.
2. Related Work
3. Method
3.1. Deep Embedded Clustering
3.2. Self-Attention Mechanism Fusion Depth Clustering Learning Network Model
3.2.1. Long Short Term Memory
3.2.2. Self-Attention Mechanism
3.3. Overall Pseudocode Architecture
| Algorithm 1: Display of Overall Algorithm Structure of Motion Recognition |
 |
4. Experiment
4.1. Experimental Platform and Setting
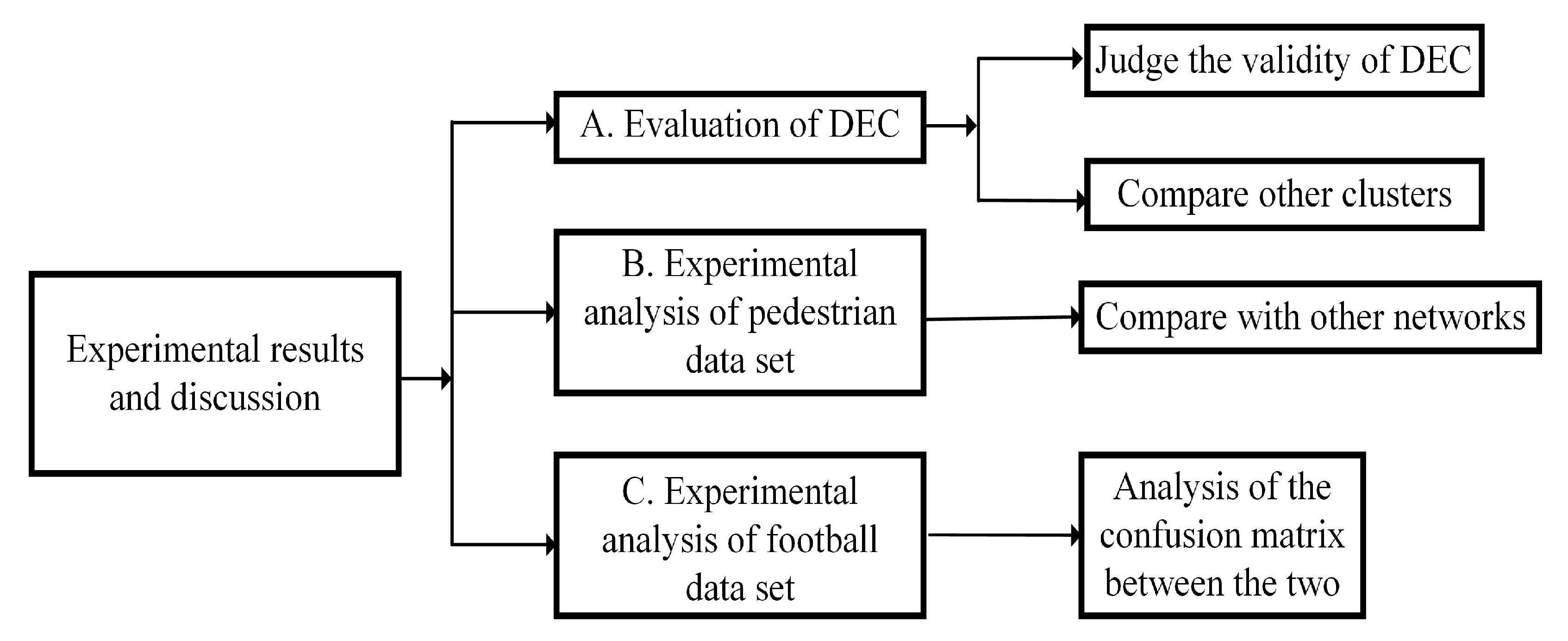
4.2. Experimental Results and Analysis
4.2.1. Deep Embedded Clustering Module
4.2.2. Network Model Performance Comparison Module
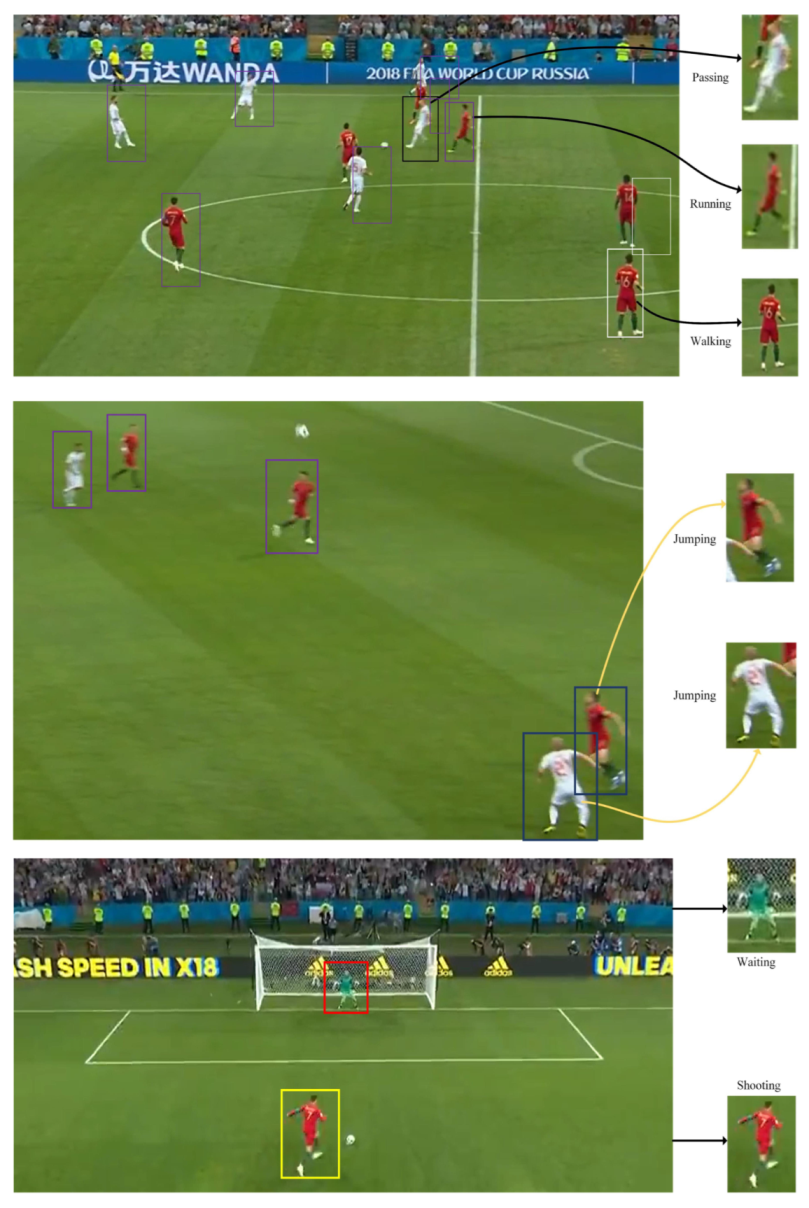
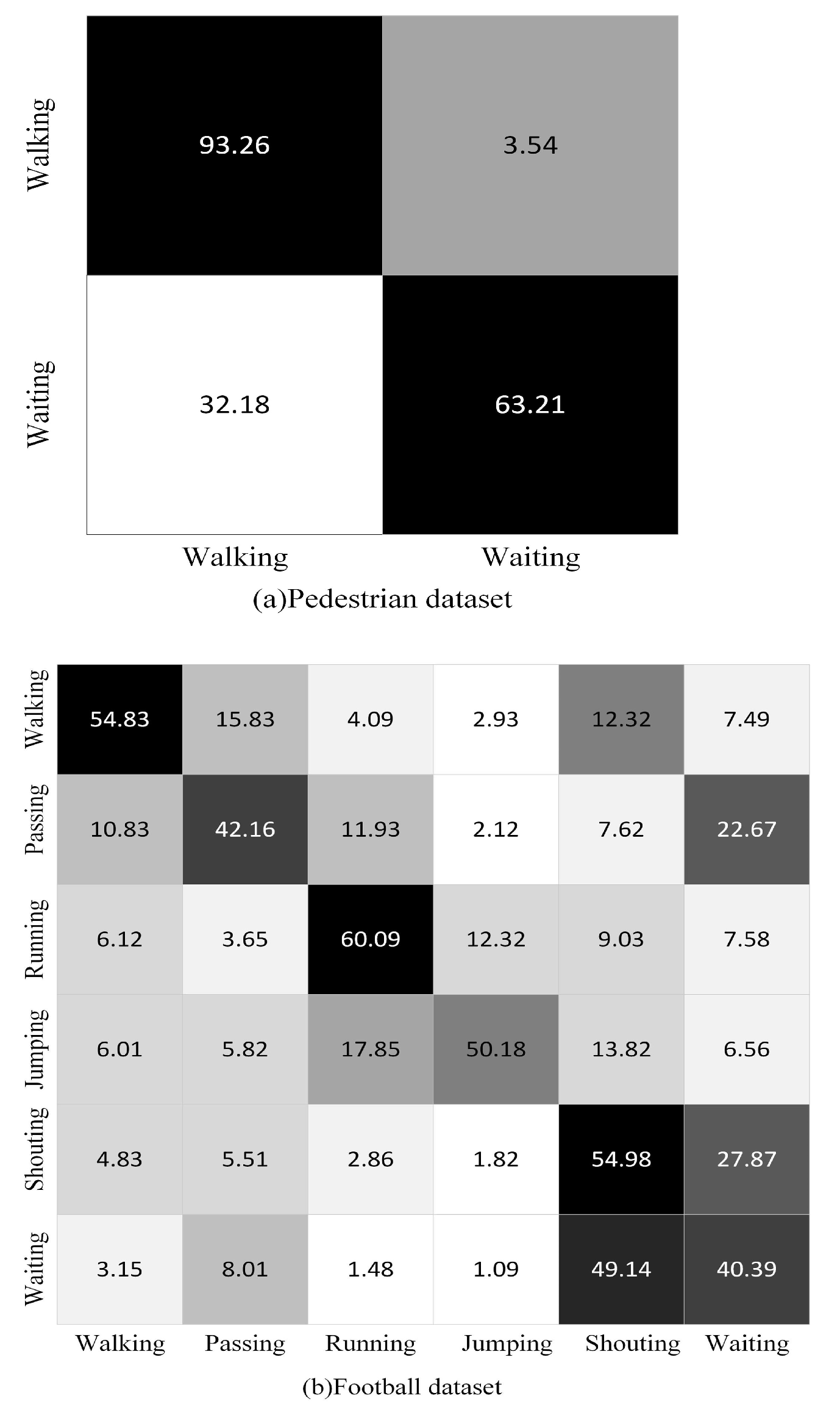
4.2.3. Results of Football Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fei, H.; Reardon, C.; Parker, L.E.; Hao, Z. Minimum uncertainty latent variable models for robot recognition of sequential human activities. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Li, X.; Chuah, M.C. Sbgar: Semantics based group activity recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2876–2885. [Google Scholar]
- Shu, X.; Zhang, L.; Sun, Y.; Tang, J. Host–parasite: Graph lstm-in-lstm for group activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 663–674. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Ni, B.; Yang, X. Recurrent modeling of interaction context for collective activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3048–3056. [Google Scholar]
- Yu, H.; Cheng, S.; Ni, B.; Wang, M.; Zhang, J.; Yang, X. Fine-grained video captioning for sports narrative. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6006–6015. [Google Scholar]
- Venugopalan, S.; Rohrbach, M.; Donahue, J.; Mooney, R.; Darrell, T.; Saenko, K. Sequence to sequence-video to text. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4534–4542. [Google Scholar]
- Kong, L.; Qin, J.; Huang, D.; Wang, Y.; Gool, L.V. Hierarchical attention and context modeling for group activity recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1328–1332. [Google Scholar]
- Bagautdinov, T.; Alahi, A.; Fleuret, F.; Fua, P.; Savarese, S. Social scene understanding: End-to-end multi-person action localization and collective activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4315–4324. [Google Scholar]
- Ramanathan, V.; Huang, J.; Abu-El-Haija, S.; Gorban, A.; Murphy, K.; Li, F.-F. Detecting events and key actors in multi-person videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3043–3053. [Google Scholar]
- Ibrahim, M.S.; Muralidharan, S.; Deng, Z.; Vahdat, A.; Mori, G. A hierarchical deep temporal model for group activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1971–1980. [Google Scholar]
- Gondal, I.; Murshed, M. Action recognition using spatio-temporal distance classifier correlation filter. In Proceedings of the 2011 International Conference on Digital Image Computing: Techniques and Applications, Noosa, QLD, Australia, 6–8 December 2011; pp. 474–479. [Google Scholar]
- Rodriguez, M.D.; Ahmed, J.; Shah, M. Action mach a spatio-temporal maximum average correlation height filter for action recognition. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhibin, Z.; Liping, S.; Xuan, C. Labeled box-particle cphd filter for multiple extended targets tracking. J. Syst. Eng. Electron. 2019, 30, 57–67. [Google Scholar]
- Araei, S.; Nadian-Ghomsheh, A. Spatio-temporal 3d action recognition with hierarchical self-attention mechanism. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021; pp. 1–5. [Google Scholar]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Tome, D.; Russell, C.; Agapito, L. Lifting from the deep: Convolutional 3d pose estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2500–2509. [Google Scholar]
- Shu, X.; Tang, J.; Qi, G.-J.; Liu, W.; Yang, J. Hierarchical long short-term concurrent memory for human interaction recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1110–1118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertasius, G.; Park, H.S.; Yu, S.X.; Shi, J. Am i a baller? basketball performance assessment from first-person videos. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2177–2185. [Google Scholar]
- Rossi, S.; Capasso, R.; Acampora, G.; Staffa, M. A multimodal deep learning network for group activity recognition. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–6. [Google Scholar]
- Tang, Y.; Wang, Z.; Li, P.; Lu, J.; Yang, M.; Zhou, J. Mining semantics-preserving attention for group activity recognition. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1283–1291. [Google Scholar]
- Homayounfar, N.; Fidler, S.; Urtasun, R. Sports field localization via deep structured models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2017; pp. 5212–5220. [Google Scholar]
- Chen, Z.; Huang, J.; Ahn, H.; Ning, X. Costly features classification using monte carlo tree search. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Zhang, Y.-H.; Wen, C.; Zhang, M.; Xie, K.; He, J.-B. Fast 3d visualization of massive geological data based on clustering index fusion. IEEE Access 2022, 10, 28821–28831. [Google Scholar] [CrossRef]
- Peng, H.; Zhou, S.; Weitze, S.; Li, J.; Islam, S.; Geng, T.; Li, A.; Zhang, W.; Song, M.; Xie, M.; et al. Binary complex neural network acceleration on fpga. In Proceedings of the 2021 IEEE 32nd International Conference on Application-specific Systems, Architectures and Processors (ASAP), Virtual Conference, 7–9 July 2021; pp. 85–92. [Google Scholar]
- He, F.; Ye, Q. A bearing fault diagnosis method based on wavelet packet transform and convolutional neural network optimized by simulated annealing algorithm. Sensors 2022, 22, 1410. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Natarajan, V.; Shah, M.; Jiang, Y.; Chen, X.; Batra, D.; Parikh, D.; Rohrbach, M. Towards vqa models that can read. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8317–8326. [Google Scholar]
- Wang, X.; Wang, C.; Liu, B.; Zhou, X.; Zhang, L.; Zheng, J.; Bai, X. Multi-view stereo in the deep learning era: A comprehensive review. Displays 2021, 70, 102102. [Google Scholar] [CrossRef]
- Singh, A.; Pang, G.; Toh, M.; Huang, J.; Galuba, W.; Hassner, T. Textocr: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8802–8812. [Google Scholar]
- Zeng, G.; Zhang, Y.; Zhou, Y.; Yang, X. Beyond ocr+ vqa: Involving ocr into the flow for robust and accurate textvqa. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; pp. 376–385. [Google Scholar]
- Li, M.; Hsu, W.; Xie, X.; Cong, J.; Gao, W. Sacnn: Self-attention convolutional neural network for low-dose ct denoising with self-supervised perceptual loss network. IEEE Trans. Med. Imaging 2020, 39, 2289–2301. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Sun, G.; Jia, X.; Wu, L.; Zhang, A.; Ren, J.; Fu, H.; Yao, Y. Spectral–spatial self-attention networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Cheng, Z.; Yan, C.; Wu, F.; Wang, J. Drug-target interaction prediction using multi-head self-attention and graph attention network. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 19, 2208–2218. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Zhang, M.; Xie, K.; Zhang, Y.-H.; Wen, C.; He, J.-B. Fine segmentation on faces with masks based on a multistep iterative segmentation algorithm. IEEE Access 2022, 10, 75742–75753. [Google Scholar] [CrossRef]
- Ning, X.; Xu, S.; Nan, F.; Zeng, Q.; Wang, C.; Cai, W.; Li, W.; Jiang, Y. Face editing based on facial recognition features. IEEE Trans. Cogn. Dev. Syst. 2022. [Google Scholar] [CrossRef]
- Zou, Z.; Careem, M.; Dutta, A.; Thawdar, N. Joint spatio-temporal precoding for practical non-stationary wireless channels. IEEE Trans. Commun. 2023. [Google Scholar] [CrossRef]
- Zhang, Y.; Mu, L.; Shen, G.; Yu, Y.; Han, C. Fault diagnosis strategy of cnc machine tools based on cascading failure. J. Intell. Manuf. 2019, 30, 2193–2202. [Google Scholar] [CrossRef]
- Shen, G.; Zeng, W.; Han, C.; Liu, P.; Zhang, Y. Determination of the average maintenance time of cnc machine tools based on type ii failure correlation. Eksploat. I Niezawodn. 2017, 19, 604–614. [Google Scholar] [CrossRef]
- Shen, G.; Han, C.; Chen, B.; Dong, L.; Cao, P. Fault analysis of machine tools based on grey relational analysis and main factor analysis. J. Physics Conf. Ser. 2018, 1069, 012112. [Google Scholar] [CrossRef]
- Chu, X.; Lei, J.; Liu, X.; Wang, Z. Kmeans algorithm clustering for massive ais data based on the spark platform. In Proceedings of the 2020 5th International Conference on Control, Robotics and Cybernetics (CRC), Wuhan, China, 16–18 October 2020; pp. 36–39. [Google Scholar]
- Wei, R.; Garcia, C.; El-Sayed, A.; Peterson, V.; Mahmood, A. Variations in variational autoencoders-a comparative evaluation. IEEE Access 2020, 8, 153651–153670. [Google Scholar] [CrossRef]
- Zhu, Q.; Tang, X.; Liu, Z. Revised dbscan clustering algorithm based on dual grid. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 3461–3466. [Google Scholar]
- Huang, M.; Liu, Y.; Peng, Z.; Liu, C.; Lin, D.; Zhu, S.; Yuan, N.; Ding, K.; Jin, L. Swintextspotter: Scene text spotting via better synergy between text detection and text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4593–4603. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | MNIST | |||
|---|---|---|---|---|
| KMeans [40] | AE [41] | DBSCAN [42] | DEC | |
| ACC | 0.52 | 0.78 | 0.69 | 0.95 |
| NMI | 0.53 | 0.77 | 0.82 | 0.92 |
| ARI | 0.34 | 0.69 | 0.71 | 0.93 |
| Method | Accuracy% | Recall% |
|---|---|---|
| X. Li et al. [2] | 91.1 | 91.2 |
| X. Shu et al. [3] | 91.6 | 91.5 |
| M. Wang et al. [4] | 92.2 | 92.3 |
| H. Yu et al. [5] | 93.4 | 93.4 |
| S. Venugopalan et al. [6] | 93.6 | 93.7 |
| S. Araei et al. [13] | 90.8 | 90.8 |
| X. Shu et al. [16] | 95.3 | 95.4 |
| G. Bertasius et al. [17] | 95.6 | 95.8 |
| ours | 96.1 | 96.1 |
| Method | Accuracy% | Recall% |
|---|---|---|
| X. Li et al. [2] | 91.2 | 91.2 |
| X. Shu et al. [3] | 91.7 | 91.5 |
| M. Wang et al. [4] | 92.3 | 92.3 |
| H. Yu et al. [5] | 93.4 | 93.2 |
| S. Venugopalan et al. [6] | 93.5 | 93.6 |
| S. Araei et al. [13] | 90.8 | 90.9 |
| X. Shu et al. [16] | 94.3 | 94.4 |
| G. Bertasius et al. [17] | 96.6 | 96.8 |
| ours | 97.5 | 97.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ru, T.; Zhu, Z. Deep Clustering Efficient Learning Network for Motion Recognition Based on Self-Attention Mechanism. Appl. Sci. 2023, 13, 2996. https://doi.org/10.3390/app13052996
Ru T, Zhu Z. Deep Clustering Efficient Learning Network for Motion Recognition Based on Self-Attention Mechanism. Applied Sciences. 2023; 13(5):2996. https://doi.org/10.3390/app13052996
Chicago/Turabian StyleRu, Tielin, and Ziheng Zhu. 2023. "Deep Clustering Efficient Learning Network for Motion Recognition Based on Self-Attention Mechanism" Applied Sciences 13, no. 5: 2996. https://doi.org/10.3390/app13052996