
Multi-Scale Aggregation Residual Channel Attention Fusion Network for Single Image Deraining

Abstract
:1. Introduction
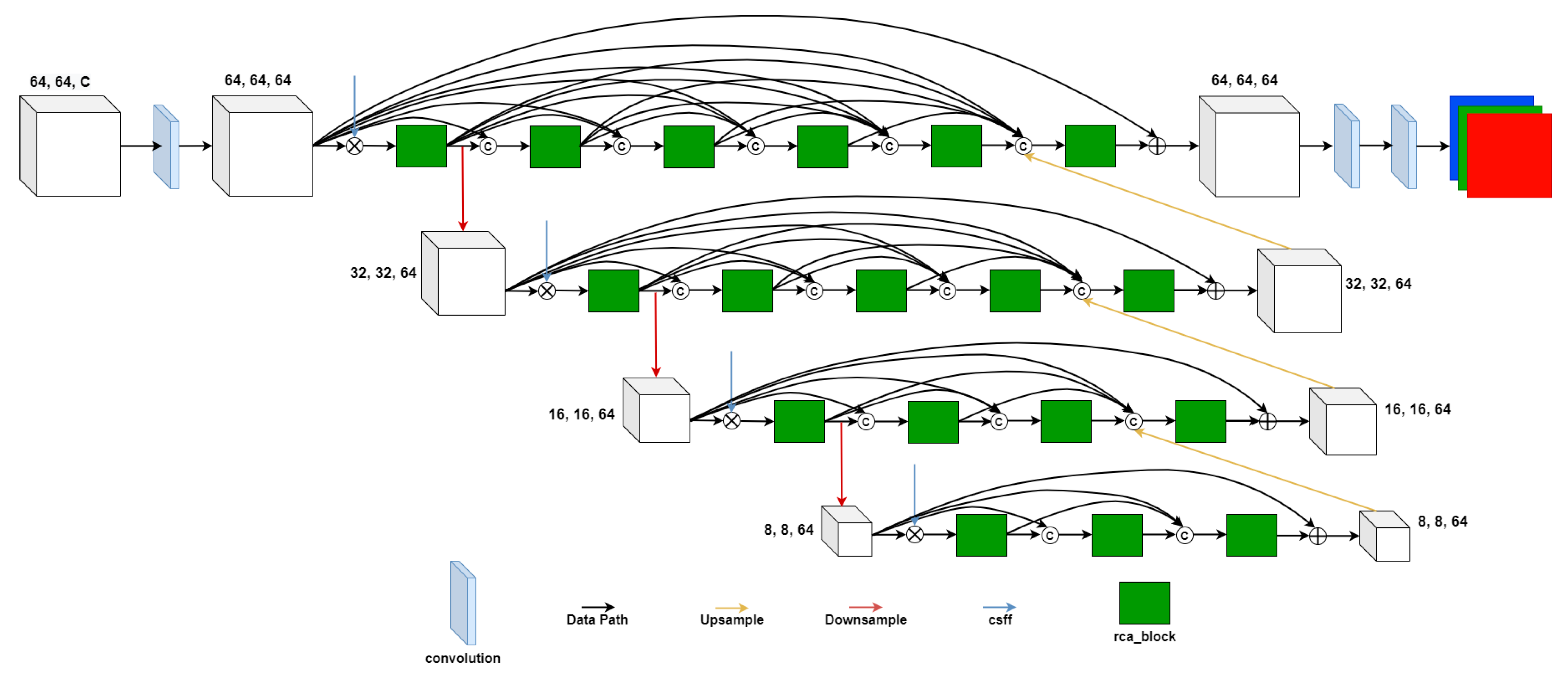
- A U-Net-based [17] encoder–decoder submodule called a CS block is proposed. Unlike a typical U-Net, the feature maps of the encoding steps are passed through a densely connected network [18] before being merged in the corresponding decoding steps. Three CS blocks are arranged consecutively in ascending order of dilation rate.
- To effectively utilize the feature maps of the CS block, a cross-stage feature fusion block (CSFF block) is proposed for providing information to subsequent CS blocks.
- A scale-blending operation is proposed and implemented in the model.
- To balance the tradeoff between pixel-level accuracy and structural accuracy, the model is trained using the mean square error (MSE) loss and structural similarity (SSIM) loss [19] functions.
2. Related Work
2.1. Video Deraining Methods
2.2. Single Image Deraining Methods
3. Multi-Scale Aggregation Residual Channel Attention Fusion Network
3.1. Architecture of Model
3.1.1. Coding Structure Block
3.1.2. Residual Channel Attention Block
3.1.3. Cross Stage Feature Fusion Block
3.1.4. Scale Blend Block
3.2. Loss Function
4. Experiment Results and Analysis
4.1. Datasets
4.2. Training Details
4.3. Quantitative Analysis
4.4. Qualitative Analysis
4.5. Ablation Study
4.5.1. Effectiveness of Sub-Modules
4.5.2. Effectiveness of Dilation Rate
5. Conclusions
6. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, Z.; Bebis, G.; Miller, R. On-road vehicle detection using Gabor filters and support vector machines. In Proceedings of the International Conference on Digital Signal Processing, Santorini, Greece, 1–3 July 2002; pp. 1019–1022. [Google Scholar]
- Janai, J.; Guney, F.; Behl, A.; Geiger, A. Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art. Found. Trends Comput. Graph. Vis. 2020, 12, 1–308. [Google Scholar] [CrossRef]
- Kang, L.W.; Lin, C.W.; Fu, Y.H. Automatic single-image-based rain streaks removal via image decomposition. IEEE Trans. Image Process. 2011, 21, 1742–1755. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, S.; Chen, C.; Zeng, B. A hierarchical approach for rain or rain or snow removing in a single color image. IEEE Trans. Image Process. 2017, 26, 3936–3950. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Rain streak removal using layer priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2736–2744. [Google Scholar]
- Yu, L.; Yong, X.; Hui, J. Removing rain from a single image via discriminative sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3397–3405. [Google Scholar]
- Li, X.; Wu, J.; Lin, Z.; Liu, H.; Zha, H. Recurrent Squeeze-and-Excitation Context Aggregation Net for Single Image Deraining. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 254–269. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20–25 June 2019; pp. 3937–3946. [Google Scholar]
- Fu, X.; Liang, B.; Huang, Y.; Ding, X.; Paisley, J. Lightweight pyramid networks for image deraining. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1794–1807. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-Scale Progressive Fusion Network for Single Image Deraining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8346–8355. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-Stage Progressive Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14816–14826. [Google Scholar]
- Wang, H.; Yue, Z.; Xie, Q.; Zhao, Q.; Zheng, Y.; Meng, D. From rain generation to rain. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14791–14801. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Wang, Z.; Wang, X.; Jiang, J.; Lin, C. Rain-Free and Residue Hand-in-Hand: A Progressive Coupled Network for Real-Time Image Deraining. IEEE Trans. Image Process. 2021, 30, 7404–7418. [Google Scholar] [CrossRef] [PubMed]
- Yin, H.; Deng, H. RAiA-Net: A Multi-Stage Network with Refined Attention in Attention Module for Single Image Deraining. IEEE Signal Process. Lett. 2022, 29, 747–751. [Google Scholar] [CrossRef]
- Korus, P.; Huang, J. Multi-scale analysis strategies in PRNU-based tampering localization. IEEE Trans. Inf. Forensics Secur. 2017, 12, 809–824. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the IEEE Winter Conference, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Zhou, W.; Alan Conrad, B.; Hamid Rahim, S.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Garg, K.; Nayar, S.K. Detection and removal of rain from videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 528–535. [Google Scholar]
- Zhang, X.; Li, H.; Qi, Y.; Leow, W.K.; Ng, T.K. Rain removal in video by combining temporal and chromatic properties. In Proceedings of the IEEE International Conference on Multimedia and Expo, Hilton Toronto, ON, Canada, 9–12 July 2006; pp. 461–464. [Google Scholar]
- Chen, Y.L.; Hsu, C.T. A generalized low-rank appearance model for spatio-temporally correlated rain streaks. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1968–1975. [Google Scholar]
- Kim, J.H.; Sim, J.Y.; Kim, C.S. Video deraining and desnowing using temporal correlation and low-rank matrix completion. IEEE Trans. Image Process. 2015, 24, 2658–2670. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Xie, Q.; Zhao, Q.; Wei, W.; Gu, S.; Tao, J.; Meng, D. Video rain streak removal by Multiscale Convolutional sparse coding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6644–6653. [Google Scholar]
- Liu, J.; Yang, W.; Yang, S.; Guo, Z. Erase of fill? Deep joint recurrent rain removal and reconstruction in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3233–3242. [Google Scholar]
- Yue, Z.; Xie, J.; Zhao, Q.; Meng, D. Semi-Supervised Video Deraining with Dynamical Rain Generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 642–652. [Google Scholar]
- Huang, D.A.; Kang, L.W.; Wang, Y.C.; Lin, C.W. Self-learning based image decomposition with applications to single image denoising. IEEE Transaction. Multimed. 2014, 16, 83–93. [Google Scholar] [CrossRef]
- Zhu, L.; Fu, C.W.; Lischinski, D.; Heng, P.A. Joint bi-layer optimization for single-image rain streak removal Deep-learning. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2526–2534. [Google Scholar]
- Eigen, D.; Krishnan, D.; Fergus, R. Restoring an image taken through a window covered with dirt or rain. In Proceedings of the International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 633–640. [Google Scholar]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J. Clearing the skies: A deep network architecture for single-image rain removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J. Removing rain from single images via a deep detail network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3855–3863. [Google Scholar]
- Hu, X.; Fu, C.W.; Zhu, L.; Heng, P.A. Depth-attentional features for single-image rain removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20–25 June 2019; pp. 8022–8031. [Google Scholar]
- Wang, T.; Yang, X.; Xu, K.; Chen, S.; Zhang, Q.; Lau, R.W. Spatial attentive single-image deraining with a high quality real rain dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20–25 June 2019; pp. 12262–12271. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3943–3956. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. HINet: Half Instance Normalization Network for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Nashville, TN, USA, 19–25 June 2021; pp. 182–192. [Google Scholar]
- Wang, Q.; Sun, G.; Dong, J.; Zhang, Y. PFDN: Pyramid Feature Decoupling Network for Single Image Deraining. IEEE Trans. Image Process. 2022, 31, 7091–7101. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–13. [Google Scholar]
- Maas, A.L.; Hannum, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1–6. [Google Scholar]
- Hu, J.L.; Albanie, S.; Sun, G.; Vedaldi, A. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–9. [Google Scholar]
- Huynh, Q.T.; Ghanbari, M. Scope of validity of psnr in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Rain14000 [31] | Rain1800 [41] | Rain100h [41] | Rain100l [41] | Rain800 [41] | Rain12 [41] |
|---|---|---|---|---|---|---|
| Train samples | 11,200 | 1800 | 0 | 0 | 700 | 12 |
| Test samples | - | 0 | 100 | 100 | - | 0 |
| Test rename | - | - | Rain100h | Rain100l | - | - |
| Methods | Rain100H | Rain100L | ||
|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |
| RESCAN [7] | 28.86 | 0.8646 | 33.12 | 0.9534 |
| PReNet [8] | 26.83 | 0.8582 | 32.53 | 0.9501 |
| LPNet [9] | 23.77 | 0.8226 | 25.63 | 0.8983 |
| MSPFN [10] | 28.23 | 0.8496. | 32.13 | 0.9263 |
| MPRNet [11] | 30.41 | 0.8895 | 36.40 | 0.9646 |
| VRGNet [12] | 30.06 | 0.8855 | 36.87 | 0.9743 |
| PCNet [13] | 28.28 | 0.8699 | 34.19 | 0.9526 |
| RAiANet [14] | 30.42 | 0.8941 | 36.79 | 0.9673 |
| MARCAFNet (our) | 32.62 | 0.9046 | 37.47 | 0.9766 |
| Model | M1 | M2 | M3 | M4 |
|---|---|---|---|---|
| CSFF | ✗ | ✗ | ✓ | ✓ |
| SB | ✗ | ✓ | ✗ | ✓ |
| PSNR | 27.87 | 33.65 | 27.94 | 35.04 |
| SSIM | 0.8118 | 0.9403 | 0.8131 | 0.9406 |
| Dilation Rate | 1,1,1 | 2,2,2 | 3,3,3 | 1,2,3 |
| PSNR | 33.99 | 34.46 | 32.70 | 35.04 |
| SSIM | 0.9403 | 0.9329 | 0.9259 | 0.9406 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.-G.; Wu, C.-S. Multi-Scale Aggregation Residual Channel Attention Fusion Network for Single Image Deraining. Appl. Sci. 2023, 13, 2709. https://doi.org/10.3390/app13042709
Wang J-G, Wu C-S. Multi-Scale Aggregation Residual Channel Attention Fusion Network for Single Image Deraining. Applied Sciences. 2023; 13(4):2709. https://doi.org/10.3390/app13042709
Chicago/Turabian StyleWang, Jyun-Guo, and Cheng-Shiuan Wu. 2023. "Multi-Scale Aggregation Residual Channel Attention Fusion Network for Single Image Deraining" Applied Sciences 13, no. 4: 2709. https://doi.org/10.3390/app13042709