
Comparison of Artificial Neural Network and Regression Models for Filling Temporal Gaps of Meteorological Variables Time Series

Abstract
:1. Introduction
2. Materials and Methods
2.1. In Situ Meteorological Data
2.2. ERA-5 Land Reanalysis Data
2.2.1. Input Variables
2.2.2. Training and Validation Datasets
2.3. Models
2.3.1. Direct ERA5-Land Comparison
2.3.2. De-Biased ERA5-Land Data
2.3.3. Linear Regression Models
2.3.4. Gaussian Process Regression Models
2.3.5. Artificial Neural Network
2.4. Model Performance Estimation
2.5. Data Processing Overview
3. Results
3.1. Direct ERA5 Comparison
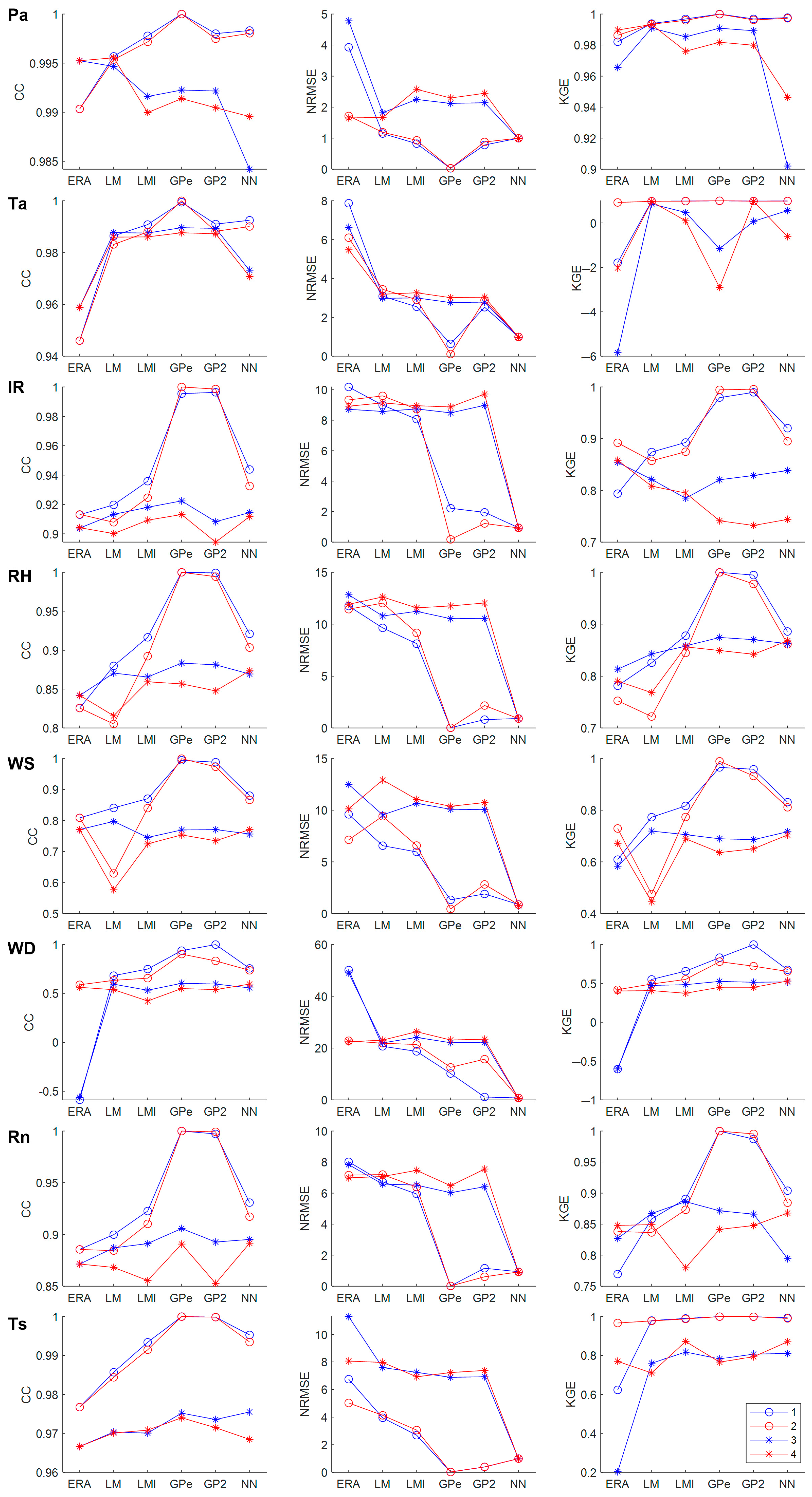
3.2. Model Performances
3.3. Computational Complexity
4. Discussion
4.1. Input Variables
4.2. The Model Comparison
5. Conclusions
Supplementary Materials
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- IPCC. Climate change 2021: The physical science basis. In Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Masson-Delmotte, V.P., Zhai, A., Pirani, S.L., Connors, C., Péan, S., Berger, N., Caud, Y., Chen, L., Goldfarb, M.I., Gomis, M., et al., Eds.; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Auer, C.; Kriegler, E.; Carlsen, H.; Kok, K.; Pedde, S.; Krey, V.; Müller, B. Climate change scenario services: From science to facilitating action. One Earth 2021, 4, 1074–1082. [Google Scholar] [CrossRef]
- Bhardwaj, E.; Khaiter, P.A. What data analytics can or cannot do for climate change studies: An inventory of interactive visual tools. Ecol. Inform. 2023, 73, 101918. [Google Scholar] [CrossRef]
- Kharyutkina, E.; Loginov, S.; Martynova, Y.V.; Sudakov, I. Time series analysis of atmospheric precipitation characteristics in Western Siberia for 1979–2018 across different datasets. Atmosphere 2022, 13, 189. [Google Scholar] [CrossRef]
- Hansen, J.; Sato, M.; Ruedy, R. Perception of climate change. Proc. Natl. Acad. Sci. USA 2012, 109, E2415–E2423. [Google Scholar] [CrossRef] [Green Version]
- Sillmann, J.; Donat, M.G.; Fyfe, J.C.; Zwiers, F.W. Observed and simulated temperature extremes during the recent warming hiatus. Environ. Res. Lett. 2014, 9, 64023–64029. [Google Scholar] [CrossRef]
- Kharyutkina, E.V.; Loginov, S.V.; Moraru, E.I.; Pustovalov, K.N.; Martynova, Y.V. Dynamics of extreme climatic characteristics and trends of dangerous meteorological phenomena over the territory of Western Siberia. Atmos. Ocean Opt. 2022, 35, 394–401. [Google Scholar] [CrossRef]
- Pastorello, G.; Trotta, C.; Canfora, E.; Chu, H.; Christianson, D.; Cheah, Y.W.; Poindexter, C.; Chen, J.; Elbashandy, A.; Humphrey, M.; et al. The FLUXNET2015 dataset and the ONEFlux processing pipeline for eddy covariance data. Sci. Data 2020, 7, 225. [Google Scholar] [CrossRef]
- Alekseychik, P.; Mammarella, I.; Karpov, D.; Dengel, S.; Terentieva, I.; Sabrekov, A.; Glagolev, M.; Lapshina, E. Net ecosystem exchange and energy fluxes measured with the eddy covariance technique in a western Siberian bog. Atmos. Chem. Phys. 2017, 17, 9333–9345. [Google Scholar] [CrossRef] [Green Version]
- Dyukarev, E.; Zarov, E.; Alekseychik, P.; Nijp, J.; Filippova, N.; Mammarella, I.; Filippov, I.; Bleuten, W.; Khoroshavin, V.; Ganasevich, G.; et al. The multiscale monitoring of peatland ecosystem carbon cycling in the middle taiga zone of Western Siberia: The Mukhrino bog case study. Land 2021, 10, 824. [Google Scholar] [CrossRef]
- Szajdak, L.W.; Lapshina, E.D.; Gaca, W.; Styla, K.; Meysner, T.; Szczepanski, M.; Zarov, E.A. Physical, chemical and biochemical properties of Western Siberia Sphagnum and Carex peat soils. Environ. Dyn. Glob. Clim. Change 2016, 7, 13–25. [Google Scholar] [CrossRef] [Green Version]
- Bleuten, W.; Zarov, E.; Schmitz, O. A high-resolution transient 3-dimensional hydrological model of an extensive undisturbed bog complex in West Siberia. Mires Peat 2020, 26, 25. [Google Scholar] [CrossRef]
- Filippova, N.; Lapshina, E. Sampling event dataset on five-year observations of macrofungi fruit bodies in raised bogs, Western Siberia, Russia. Biodiv. Data J. 2019, 7, e35674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Coutinho, E.R.; da Silva, R.M.; Madeira, J.G.F.; Coutinho, P.R.d.O.d.S.; Boloy, R.A.M.; Delgado, A.R.S. Application of Artificial Neural Networks (ANNs) in the Gap Filling of Meteorological Time Series. Rev. Bras. Meteorol. 2018, 33, 317–328. [Google Scholar] [CrossRef]
- Gunawardena, N.; Pardyjak, E.; Durand, P.; Hedde, T.; Dupuy, F. Data Filling of Micrometeorological Variables in Complex Terrain for High-Resolution Nowcasting. Atmosphere 2022, 13, 408. [Google Scholar] [CrossRef]
- Boike, J.; Nitzbon, J.; Anders, K.; Grigoriev, M.; Bolshiyanov, D.; Langer, M.; Lange, S.; Bornemann, N.; Morgenstern, A.; Schreiber, P.; et al. A 16-year record (2002–2017) of permafrost, active-layer, and meteorological conditions at the Samoylov Island Arctic permafrost research site, Lena River delta, northern Siberia: An opportunity to validate remote-sensing data and land surface, snow, and permafrost models. Earth Syst. Sci. Data 2019, 11, 261–299. [Google Scholar] [CrossRef] [Green Version]
- Worrall, F.; Boothroyd, I.M.; Gardner, R.L.; Howden, N.J.K.; Burt, T.P.; Smith, R.; Mitchell, L.; Kohler, T.; Gregg, R. The impact of peatland restoration on local climate: Restoration of a cool humid island. J. Geophys. Res. Biogeosci. 2019, 124, 1696–1713. [Google Scholar] [CrossRef]
- Koronatova, N.G.; Mironycheva-Tokareva, N.P.; Solomin, Y.R. Thermal regime of peat deposits of palsas and hollows of peat plateaus in Western Siberia. Earth’s Cryosph. 2018, 22, 16–25. [Google Scholar] [CrossRef]
- Kiselev, M.V.; Dyukarev, E.A.; Voropay, N.N. Seasonally frozen layer of peatlands in the southern taiga zone of Western Siberia. Earth’s Cryosph. 2019, 23, 3–15. [Google Scholar] [CrossRef]
- Sabino, M.; de Souza, A.P. Gap-filling meteorological data series using the GapMET software in the state of Mato Grosso, Brazil. Brazil J. Agric. Environ. Eng. 2023, 27, 149–156. [Google Scholar] [CrossRef]
- Voropay, N.N.; Ryazanova, A.A.; Dyukarev, E.A. High-resolution bias corrected precipitation data over the South Siberia, Russia. Atmos. Res. 2021, 254, 105528. [Google Scholar] [CrossRef]
- Teutschbein, C.; Seibert, J. Bias correction of regional climate model simulations for hydrological climate-change impact studies: Review and evaluation of different methods. J. Hydrol. 2012, 456–457, 12–29. [Google Scholar] [CrossRef]
- Gyawali, B.; Ahmed, M.; Murgulet, D.; Wiese, D.N. Filling temporal gaps within and between GRACE and GRACE-FO terrestrial water storage records: An innovative approach. Remote Sens. 2022, 14, 1565. [Google Scholar] [CrossRef]
- Jehanzaib, M.; Ajmal, M.; Achite, M.; Kim, T.-W. Comprehensive review: Advancements in rainfall-runoff modelling for flood mitigation. Climate 2022, 10, 147. [Google Scholar] [CrossRef]
- Sun, T.; Huang, X.; Liang, C.; Liu, R.; Huang, X. Prediction and analysis of dew point indirect evaporative cooler performance by artificial neural network method. Energies 2022, 15, 4673. [Google Scholar] [CrossRef]
- Khan, M.S.; Jeon, S.B.; Jeong, M.-H. Gap-filling eddy covariance latent heat flux: Inter-comparison of four machine learning model predictions and uncertainties in forest ecosystem. Remote Sens. 2021, 13, 4976. [Google Scholar] [CrossRef]
- Hanoon, M.S.; Ahmed, A.N.; Zaini, N.; Razzaq, A.; Kumar, P.; Sherif, M.; Sefelnasr, A.; El-Shafie, A. Developing machine learning algorithms for meteorological temperature and humidity forecasting at Terengganu state in Malaysia. Sci. Rep. 2021, 11, 18935. [Google Scholar] [CrossRef] [PubMed]
- Su, H.; Jiang, J.; Wang, A.; Zhuang, W.; Yan, X.-H. Subsurface temperature reconstruction for the global ocean from 1993 to 2020 using satellite observations and deep learning. Remote Sens. 2022, 14, 3198. [Google Scholar] [CrossRef]
- Ridwan, W.M.; Sapitang, M.; Aziz, A.; Kushiar, K.F.; Ahmed, A.N.; El-Shafie, A. Rainfall forecasting model using machine learning methods: Case study Terengganu, Malaysia. Ain Shams Eng. J. 2021, 12, 1651–1663. [Google Scholar] [CrossRef]
- Essam, Y.; Ahmed, A.N.; Ramli, R.; Chau, K.W.; Ibrahim, M.S.I.; Sherif, M.; Sefelnasr, A.; El-Shafie, A. Investigating photovoltaic solar power output forecasting using machine learning algorithms. Eng. Appl. Comput. Fluid Mech. 2022, 16, 2002–2034. [Google Scholar] [CrossRef]
- Ruppert, J.; Mauder, M.; Thomas, C.; Luers, J. Innovative gap-filling strategy for annual sums of CO2 net ecosystem exchange. Agric. For. Meteorol. 2006, 138, 5–18. [Google Scholar] [CrossRef]
- Jiang, Y.; Tang, R.; Li, Z.L. A physical full-factorial scheme for gap-filling of eddy covariance measurements of daytime evapotranspiration. Agric. For. Meteorol. 2022, 323, 109087. [Google Scholar] [CrossRef]
- Falge, E.; Baldocchi, D.; Olson, R.; Anthoni, P.; Aubinet, M.; Bernhofer, C.; Burba, G.; Ceulemans, R.; Clement, R.; Dolman, H.; et al. Gap filling strategies for long term energy flux data sets. Agric. For. Meteorol. 2001, 107, 71–77. [Google Scholar] [CrossRef] [Green Version]
- Irvin, J.; Zhou, S.; McNicol, G.; Lu, F.; Liu, V.; Fluet-Chouinard, E.; Ouyang, Z.; Knox, S.H.; Lucas-Moffat, A.; Trotta, C.; et al. Gap-filling eddy covariance methane fluxes: Comparison of machine learning model predictions and uncertainties at FLUXNET-CH4 wetlands. Agric. For. Meteorol. 2021, 308–309, 108528. [Google Scholar] [CrossRef]
- Vuichard, N.; Papale, D. Filling the gaps in meteorological continuous data measured at FLUXNET sites with ERA-Interim reanalysis. Earth Syst. Sci. Data 2015, 7, 157–171. [Google Scholar] [CrossRef] [Green Version]
- Berg, P.; Donnelly, C.; Gustafsson, D. Near-real-time adjusted reanalysis forcing data for hydrology. Hydr. Earth Syst. Sci. 2018, 22, 989–1000. [Google Scholar] [CrossRef] [Green Version]
- Maraun, D.; Widmann, M. Statistical Downscaling and Bias Correction for Climate Research; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar] [CrossRef] [Green Version]
- Sunyer, M.A.; Hundecha, Y.; Lawrence, D.; Madsen, H.; Willems, P.; Martinkova, M.; Vormoor, K.; Bürger, G.; Hanel, M.; Kriaučiūnienė, J.; et al. Inter-comparison of statistical downscaling methods for projection of extreme precipitation in Europe. Hydrol. Earth Syst. Sci. 2015, 19, 1827–1847. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Yang, K.; Shao, C.; Zhou, X.; Zhao, L.; Chen, Y.; Wu, H. A downscaling approach for constructing high-resolution precipitation dataset over the Tibetan Plateau from ERA5 reanalysis. Atmos. Res. 2021, 256, 105678. [Google Scholar] [CrossRef]
- Iseri, Y.; Diaz, A.J.; Trinh, T.; Kavvas, M.L.; Ishida, K.; Anderson, M.L.; Ohara, N.; Snider, E.D. Dynamical downscaling of global reanalysis data for high-resolution spatial modeling of snow accumulation/melting at the central/southern Sierra Nevada watersheds. J. Hydrol. 2021, 598, 126445. [Google Scholar] [CrossRef]
- Giorgi, F.; Jones, C.; Asrar, G.R. Addressing climate information needs at the regionallevel: The CORDEX framework. WMO Bull. 2009, 58, 175–183. [Google Scholar]
- Almendra-Martín, L.; Martínez-Fernández, J.; Piles, M.; González-Zamora, Á. Comparison of gap-filling techniques applied to the CCI soil moisture database in Southern Europe. Remote Sens. Environ. 2021, 258, 112377. [Google Scholar] [CrossRef]
- Farhani, N.; Carreau, J.; Kassouk, Z.; Mougenot, B.; Le Page, M.; Lili-Chabaane, Z.; Zitouna-Chebbi, R.; Boulet, G. Regional sub-daily stochastic weather generator based on reanalyses for surface water stress estimation in central Tunisia. Environ. Model. Softw. 2022, 155, hal-02554676. [Google Scholar] [CrossRef]
- Lucas-Moffat, A.M.; Schrader, F.; Herbst, M.; Brümmer, C. Multiple gap-filling for eddy covariance datasets. Agric. For. Meteorol. 2022, 325, 109114. [Google Scholar] [CrossRef]
- Foltýnov’, L.; Fischer, M.; McGloin, R.P. Recommendations for gap-filling eddy covariance latent heat flux measurements using marginal distribution sampling. Theor. Appl. Climatol. 2020, 139, 677–688. [Google Scholar] [CrossRef]
- Jääskeläinen, E.; Manninen, T.; Hakkarainen, J.; Tamminen, J. Filling gaps of black-sky surface albedo of the Arctic sea ice using gradient boosting and brightness temperature data. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102701. [Google Scholar] [CrossRef]
- Peng, Z.; Ding, Y.; Qu, Y.; Wang, M.; Li, X. Generating a Long-Term Spatiotemporally Continuous Melt Pond Fraction Dataset for Arctic Sea Ice Using an Artificial Neural Network and a Statistical-Based Temporal Filter. Remote Sens. 2022, 14, 4538. [Google Scholar] [CrossRef]
- Philippopoulos, K.; Deligiorgi, D. Application of artificial neural networks for the spatial estimation of wind speed in a coastal region with complex topography. Renew. Energy 2012, 38, 75–82. [Google Scholar] [CrossRef]
- Dyukarev, E.; Filippova, N.; Karpov, D.; Shnyrev, N.; Zarov, E.; Filippov, I.; Voropay, N.; Avilov, V.; Artamonov, A.; Lapshina, E. Hydrometeorological dataset of West Siberian boreal peatland: A 10-year record from the Mukhrino field station. Earth Syst. Sci. Data 2021, 13, 2595–2605. [Google Scholar] [CrossRef]
- Dyukarev, E.; Filippova, N.; Karpov, D.; Shnyrev, N.; Zarov, E.; Filippov, I.; Voropay, N.; Avilov, V.; Artamonov, A.; Lapshina, E. Hydrometeorological Dataset of West Siberian Boreal Peatland: A 10-Year Records from the Mukhrino Field Station. Dataset. Version 2020/12. [CrossRef]
- Hennermann, K. ERA5 Data Documentation. ECMWF. 2019. Available online: https://confluence.ecmwf.int/display/CKB/ERA5%3A+data+documentation (accessed on 21 September 2022).
- Hersbach, H.; de Rosnay, P.; Bell, B.; Schepers, D.; Simmons, A.; Soci, C.; Abdalla, S.; Alonso-Balmaseda, M.; Balsamo, G.; Bechtold, P.; et al. Operational Global Reanalysis: Progress, Future Directions and Synergies with NWP; ERA Rep. Ser. 27; ECMWF: Reading, UK, 2018. [Google Scholar] [CrossRef]
- Beck, H.E.; Pan, M.; Roy, T.; Weedon, G.P.; Pappenberger, F.; van Dijk, A.I.J.M.; Huffman, G.J.; Adler, R.F.; Wood, E.F. Daily evaluation of 26 precipitation datasets using Stage-IV gauge-radar data for the CONUS. Hydr. Earth Syst. Sci. 2019, 23, 207–224. [Google Scholar] [CrossRef] [Green Version]
- Muñoz-Sabater, J. ERA5-Land hourly data from 1981 to present. Copernicus Climate Change Service (C3S) Climate Data Store (CDS). [CrossRef]
- Pustovalov, K.; Kharyutkina, E.; Korolkov, V.A.; Nagorskiy, P.M. Variations in resources of solar and wind energy in the Russian sector of the Arctic. Atmos. Ocean. Opt. 2020, 33, 282–288. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal component analysis. In Springer Series in Statistics; Springer: New York, NY, USA, 2002; p. 488. [Google Scholar] [CrossRef]
- The MathWorks, Inc. Regression Learner Math Toolbox; MathWorks, Inc.: Natick, MA, USA, 2019; Available online: https://www.mathworks.com/help/stats/regressionlearner-app.html (accessed on 10 January 2023).
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Available online: https://gaussianprocess.org/gpml/ (accessed on 10 January 2023).
- Osborne, M.A.; Roberts, S.J.; Rogers, A.; Ramchurn, S.D.; Jennings, N.R. Towards Real-Time Information Processing of Sensor Network Data Using Computationally Efficient Multi-output Gaussian Processes. In Proceedings of the 2008 International Conference on Information Processing in Sensor Networks (IPSN 2008), St. Louis, MO, USA, 22–24 April 2008. [Google Scholar]
- Öztopal, A. Artificial neural network approach to spatial estimation of wind velocity data. Energy Convers. Manag. 2006, 47, 395–406. [Google Scholar] [CrossRef]
- Kling, H.; Fuchs, M.; Paulin, M. Runoff conditions in the upper Danube basin under an ensemble of climate change scenarios. J. Hydrol. 2012, 424–425, 264–277. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Variable | Unit | n | Min | Max |
|---|---|---|---|---|---|
| Pa | Surface air pressure | hPa | 52,982 | 965 | 1062 |
| Ta | Air temperature at 2 m | °C | 48,496 | −40.1 | 34.9 |
| IR | Incoming photosynthetically active radiation | µmol/m2/s | 47,916 | 0 | 1521 |
| RH | Relative air humidity | kPa | 48,547 | 15.6 | 100 |
| WS | Wind speed at 10 m | m/s | 39,031 | 0 | 15.8 |
| WD | Wind direction at 10 m | deg | 42,186 | 0 | 360 |
| Rn | Net radiation | W/m2 | 48,549 | −166 | 669 |
| Ts | Soil temperature at 5 cm | °C | 46,241 | −2.6 | 33.0 |
| N | Variable, Unit | N | Variable, Unit |
|---|---|---|---|
| 1 | 2 m temperature, °C (Ta) | 25 | ST level 1, °C (Ts) |
| 2 | 2 m dewpoint temperature, °C | 26 | ST level 2, °C |
| 3 | 10 m U wind component, m/s | 27 | ST level 3, °C |
| 4 | 10 m V wind component, m/s | 28 | ST level 4, °C |
| 5 | EV, mwe/s | 29 | Sub-surface runoff, m/s |
| 6 | EV from bare soil, mwe/s | 30 | Surface latent heat flux, W/m2 |
| 7 | EV from open water surfaces, mwe/s | 31 | Surface net solar radiation, W/m2 |
| 8 | EV from the top of canopy, mwe/s | 32 | Surface net thermal radiation, W/m2 |
| 9 | EV from vegetation transpiration, mwe/s | 33 | Surface pressure, hPa (Pa) |
| 10 | Forecast albedo | 34 | Surface runoff, m/s |
| 11 | LAI, high vegetation, m2/m2 | 35 | Surface sensible heat flux, W/m2 |
| 12 | LAI, low vegetation, m2/m2 | 36 | Surface solar radiation downwards, W/m2 (IR) |
| 13 | Potential EV, mwe/s | 37 | Surface thermal radiation downwards, W/m2 |
| 14 | Runoff, m/s | 38 | Temperature of snow layer, °C |
| 15 | Skin reservoir content, mwe | 39 | Total precipitation, mm/h |
| 16 | Skin temperature, °C | 40 | VSW layer 1, % |
| 17 | Snow albedo | 41 | VSW layer 2, % |
| 18 | Snow cover, % | 42 | VSW layer 3, % |
| 19 | Snow density, kg/m3 | 43 | VSW layer 4, % |
| 20 | Snow depth, m | 44 | Relative air humidity, % (RH) |
| 21 | Snow depth water equivalent, mwe | 45 | Wind speed at 10 m, m/s (WS) |
| 22 | Snow evaporation, mwe/s | 46 | Wind direction at 10 m, deg (WD) |
| 23 | Snowfall, mwe/s | 47 | Net radiation, W/m2 (Rn) |
| 24 | Snowmelt, mwe/s |
| Model | Dataset | CC | NRME | KGE | Rank CC | Rank NRMSE | Rank KGE | MER |
|---|---|---|---|---|---|---|---|---|
| ERA | ERA | 0.89 | 10.01 | 0.70 | 35 | 0 | 0 | 12 |
| dbERA | ERA | 0.89 | 8.49 | 0.78 | 35 | 65 | 61 | 54 |
| LM | ERA | 0.90 | 8.08 | 0.83 | 66 | 83 | 100 | 83 |
| LMI | ERA | 0.90 | 7.99 | 0.80 | 77 | 87 | 77 | 80 |
| GPRexp | ERA | 0.91 | 7.68 | 0.80 | 100 | 100 | 77 | 92 |
| GPR2 | ERA | 0.90 | 7.95 | 0.82 | 66 | 88 | 89 | 81 |
| NN | ERA | 0.90 | 7.75 | 0.80 | 77 | 97 | 78 | 84 |
| LM | PCA | 0.88 | 8.55 | 0.79 | 26 | 63 | 67 | 52 |
| LMI | PCA | 0.88 | 8.21 | 0.79 | 27 | 77 | 67 | 57 |
| GPRexp | PCA | 0.90 | 8.05 | 0.75 | 70 | 84 | 41 | 65 |
| GPR2 | PCA | 0.87 | 8.64 | 0.82 | 0 | 59 | 89 | 49 |
| NN | PCA | 0.90 | 8.36 | 0.81 | 69 | 71 | 80 | 74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dyukarev, E. Comparison of Artificial Neural Network and Regression Models for Filling Temporal Gaps of Meteorological Variables Time Series. Appl. Sci. 2023, 13, 2646. https://doi.org/10.3390/app13042646
Dyukarev E. Comparison of Artificial Neural Network and Regression Models for Filling Temporal Gaps of Meteorological Variables Time Series. Applied Sciences. 2023; 13(4):2646. https://doi.org/10.3390/app13042646
Chicago/Turabian StyleDyukarev, Egor. 2023. "Comparison of Artificial Neural Network and Regression Models for Filling Temporal Gaps of Meteorological Variables Time Series" Applied Sciences 13, no. 4: 2646. https://doi.org/10.3390/app13042646