

MiniatureVQNet: A Light-Weight Deep Neural Network for Non-Intrusive Evaluation of VoIP Speech Quality

Abstract
:1. Introduction
2. Deep-Learning-Based Single-Ended Speech Quality Measures
2.1. Model Network Architecture
2.2. Training Datasets
3. Dataset
3.1. Noise–Network-Distorted Dataset
3.1.1. Effect of VoIP Network QoS on Speech Quality
3.1.2. Environmental Noise on Speech Quality
4. Proposed MiniatureVQNet Model
4.1. Network Architecture and Training
Model Optimization
5. Experimental Evaluation
5.1. General Performance
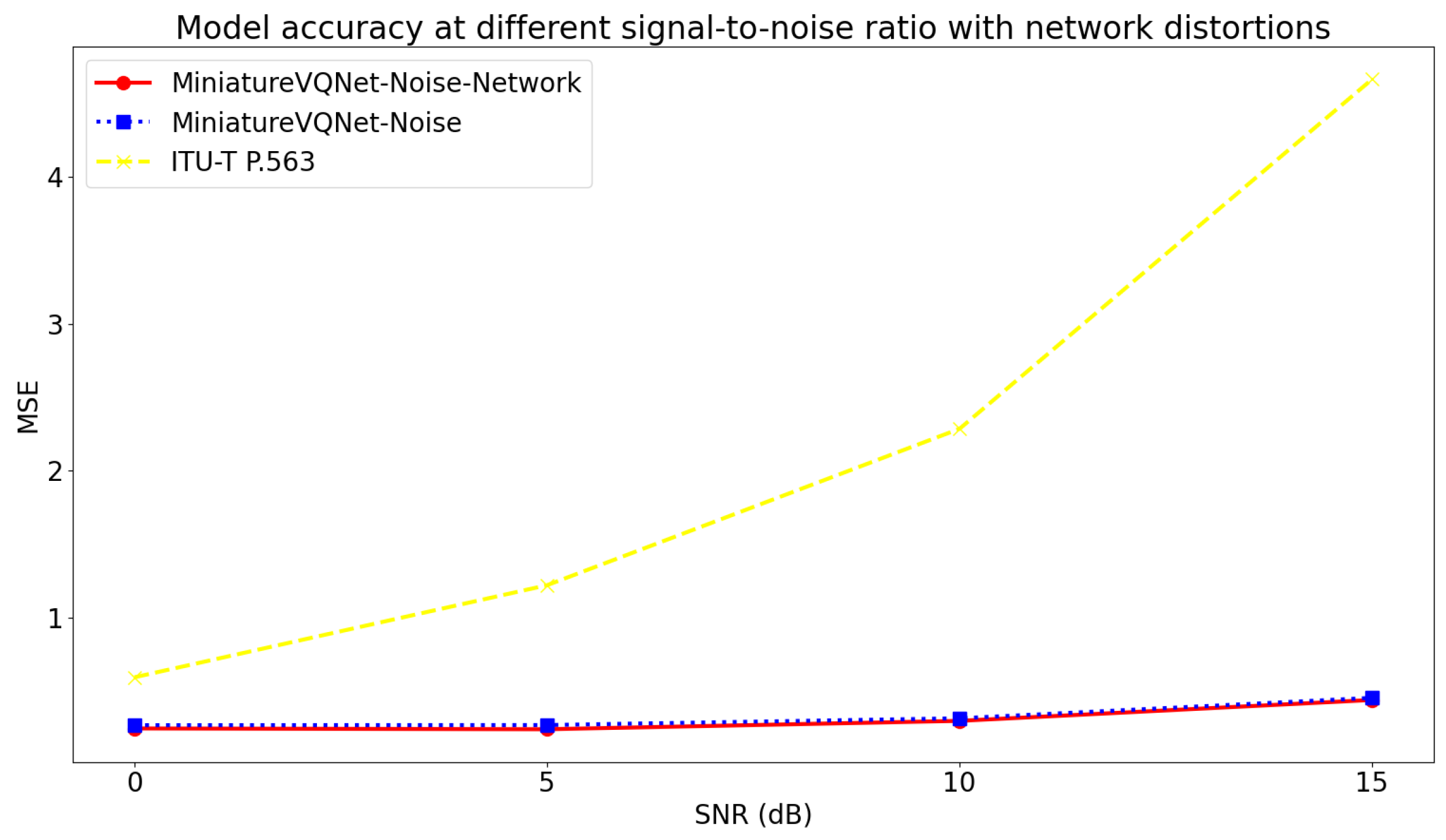
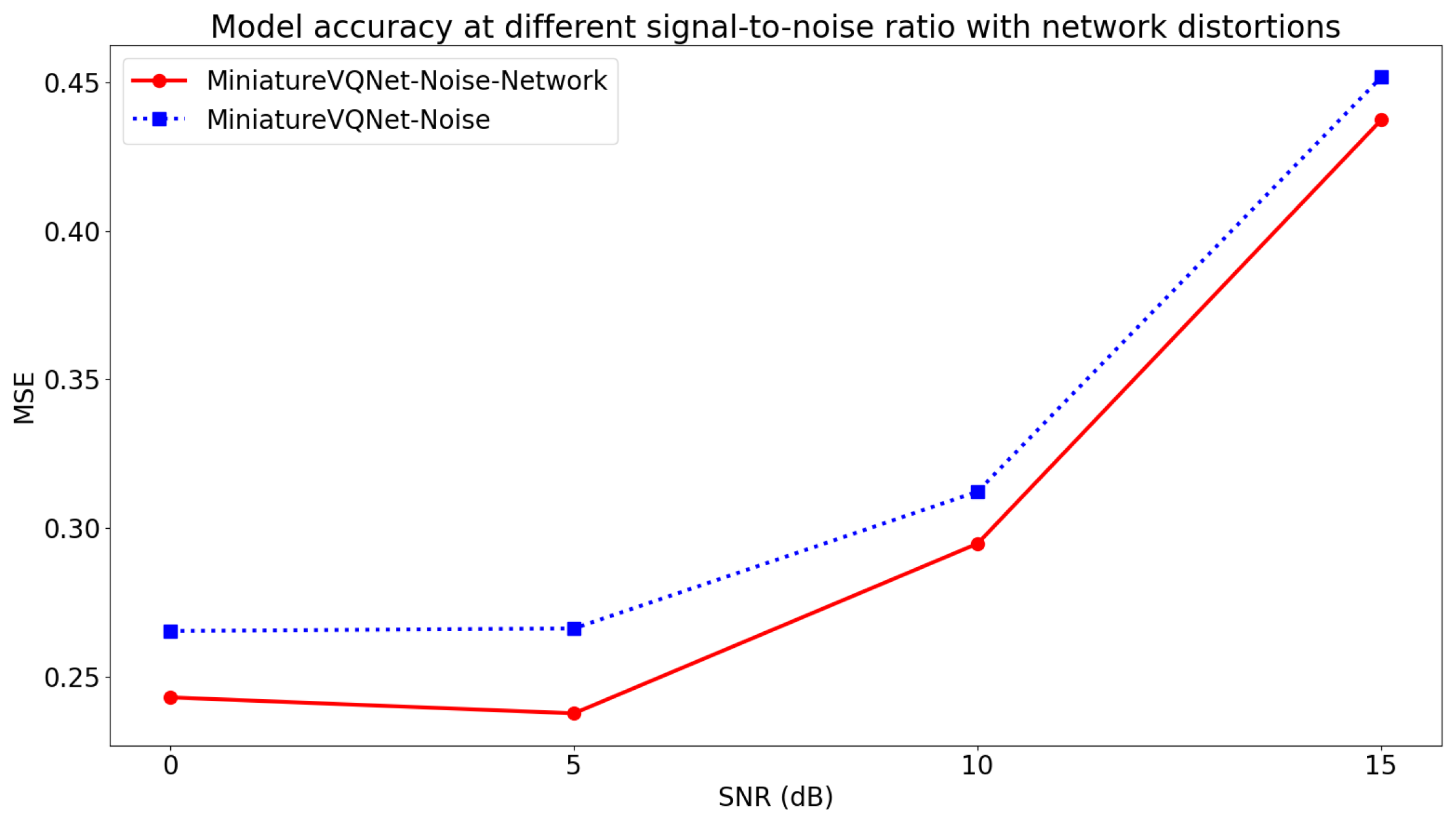
5.2. The Effect of Noise and Network Distortion on Prediction Accuracy
5.3. The Effect of Noise Type and Network Distortion on Prediction Accuracy
5.4. Effect of Jitter on Prediction Accuracy
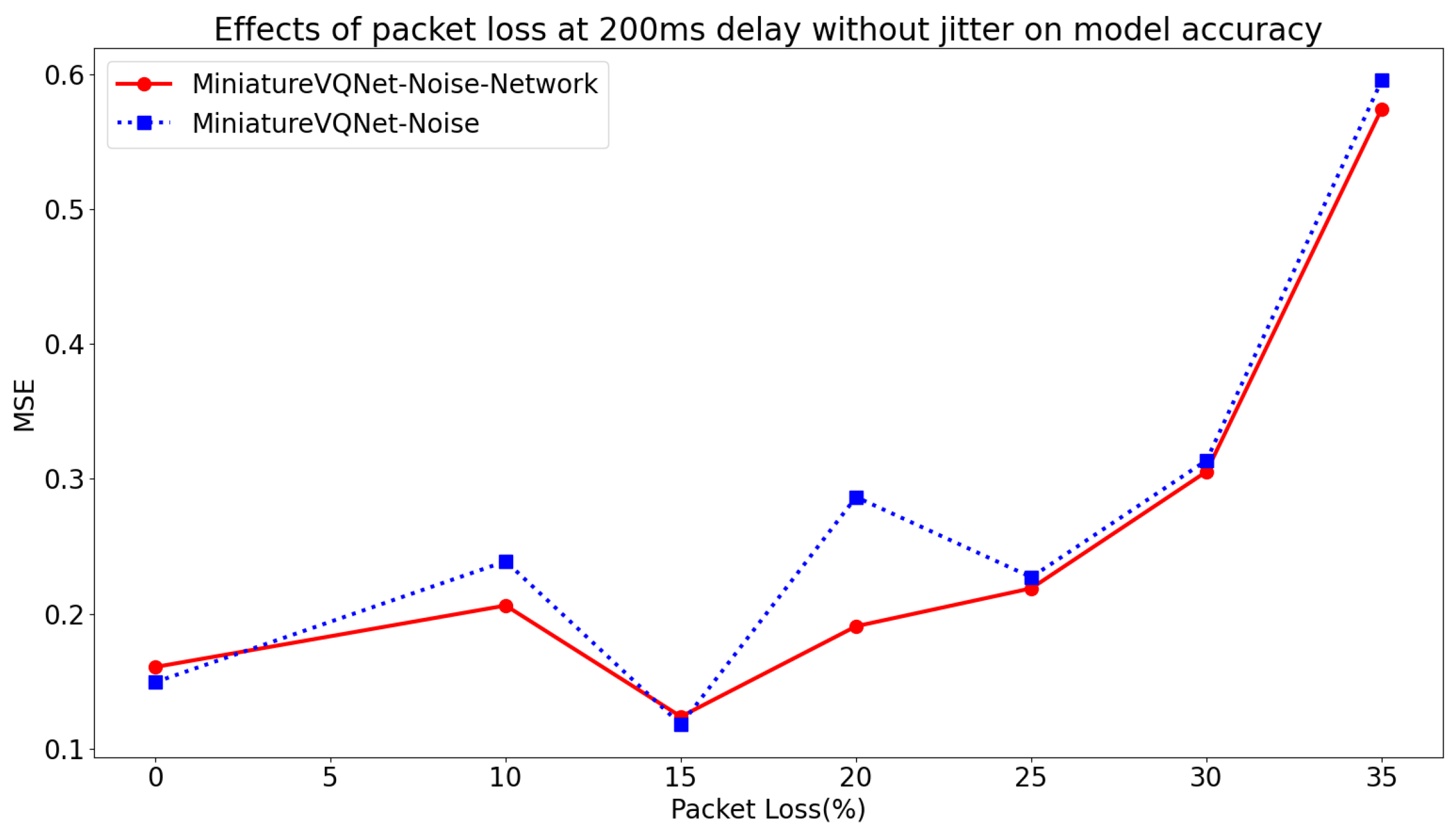
5.5. Effect of Packet Loss on Prediction Accuracy
5.6. Model Performance after Post-Training Optimization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Voiers, W. Interdependencies among measures of speech intelligility and speech “Quality”. In Proceedings of the ICASSP ’80. IEEE International Conference on Acoustics, Speech, and Signal Processing, Denver, CO, USA, 9–11 April 1980; Volume 5, pp. 703–705. [Google Scholar] [CrossRef]
- IEEE. IEEE Recommended Practice for Speech Quality Measurements. IEEE Trans. Audio Electroacoust. 1969, 17, 225–246. [Google Scholar] [CrossRef]
- International Telecommunication Union. Methods for Subjective Determination of Transmission Quality; ITU-T Recommendation P.800; International Telecommunication Union: Geneva, Switzerland, 1996. [Google Scholar]
- International Telecommunication Union. Subjective Test Methodology for Evaluating Speech Communication Systems That Include Noise Suppression Algorithm; ITU-T Recommendation P.835; International Telecommunication Union: Geneva, Switzerland, 2003. [Google Scholar]
- International Telecommunication Union. Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs; ITU-T Recommendation P.862; International Telecommunication Union: Geneva, Switzerland, 2001. [Google Scholar]
- International Telecommunication Union. Perceptual Objective Listening Quality Assessment: An Advanced Objective Perceptual Method for End-to-End Listening Speech Quality Evaluation of Fixed, Mobile, and IP-Based Networks and Speech Codecs Covering Narrowband, Wideband, and Super-Wideband; ITU-T Recommendation P.863; International Telecommunication Union: Geneva, Switzerland, 2011. [Google Scholar]
- Huber, R.; Kollmeier, B. PEMO-Q-A new method for objective audio quality assessment using a model of auditory perception. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1902–1911. [Google Scholar] [CrossRef]
- Thiede, T.; Treurniet, W.C.; Bitto, R.; Schmidmer, C.; Sporer, T.; Beerends, J.G.; Colomes, C. PEAQ-The ITU standard for objective measurement of perceived audio quality. J. Audio Eng. Soc. 2000, 48, 3–29. [Google Scholar]
- International Telecommunication Union. Single-Ended Method for Objective Speech Quality Assessment in Narrow-Band Telephony Applications; ITU-T Recommendation P.563; International Telecommunication Union: Geneva, Switzerland, 2004. [Google Scholar]
- Sharma, D.; Wang, Y.; Naylor, P.A.; Brookes, M. A data-driven non-intrusive measure of speech quality and intelligibility. Speech Commun. 2016, 80, 84–94. [Google Scholar] [CrossRef]
- Gamper, H.; Reddy, C.K.A.; Cutler, R.; Tashev, I.J.; Gehrke, J. Intrusive and Non-Intrusive Perceptual Speech Quality Assessment Using a Convolutional Neural Network. In Proceedings of the 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), IEEE, New Paltz, NY, USA, 20–23 October 2019. [Google Scholar]
- Cauchi, B.; Siedenburg, K.; Santos, J.F.; Falk, T.H.; Doclo, S.; Goetze, S. Non-Intrusive Speech Quality Prediction Using Modulation Energies and LSTM-Network. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1151–1163. [Google Scholar] [CrossRef]
- Catellier, A.A.; Voran, S.D. Wawenets: A No-Reference Convolutional Waveform-Based Approach to Estimating Narrowband and Wideband Speech Quality. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2020; Volume 2020, pp. 331–335. [Google Scholar] [CrossRef]
- Falk, T.H.; Chan, W.Y. Single-ended speech quality measurement using machine learning methods. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1935–1947. [Google Scholar] [CrossRef]
- Ooster, J.; Huber, R.; Meyer, B.T. Prediction of perceived speech quality using deep machine listening. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Hyderabad, India, 2–6 September 2018; Volume 2018, pp. 976–980. [Google Scholar] [CrossRef]
- Fu, S.W.; Tsao, Y.; Hwang, H.T.; Wang, H.M. Quality-Net: An end-to-end non-intrusive speech quality assessment model based on BLSTM. arXiv 2018, arXiv:1808.05344. [Google Scholar]
- Mittag, G.; Möller, S. Non-intrusive Speech Quality Assessment for Super-wideband Speech Communication Networks. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2019; Volume 2019, pp. 7125–7129. [Google Scholar] [CrossRef]
- Manocha, P.; Xu, B.; Kumar, A. NORESQA: A Framework for Speech Quality Assessment using Non-Matching References. Adv. Neural Inf. Process. Syst. 2021, 27, 22363–22378. [Google Scholar]
- ITU-T. The E-Model: A Computational Model for Use in Transmission Planning; Recommendation ITU-T G.107; ITU-T: Geneva, Switzerland, 2015. [Google Scholar]
- Sun, L.; Ifeachor, E. Perceived speech quality prediction for voice over IP-based networks. In Proceedings of the 2002 IEEE International Conference on Communications, New York, NY, USA, 28 April–2 May 2002; Volume 4, pp. 2573–2577. [Google Scholar] [CrossRef]
- Sun, L.; Ifeachor, E. Voice quality prediction models and their application in VoIP networks. IEEE Trans. Multimed. 2006, 8, 809–820. [Google Scholar] [CrossRef]
- Rodriguez, D.Z.; Rosa, R.L.; Almeida, F.L.; Mittag, G.; Moller, S. Speech Quality Assessment in Wireless Communications with MIMO Systems Using a Parametric Model. IEEE Access 2019, 7, 35719–35730. [Google Scholar] [CrossRef]
- Hu, Z.; Yan, H.; Yan, T.; Geng, H.; Liu, G. Evaluating QoE in VoIP networks with QoS mapping and machine learning algorithms. Neurocomputing 2020, 386, 63–83. [Google Scholar] [CrossRef]
- Wuttidittachotti, P.; Daengsi, T. Subjective MOS model and simplified E-model enhancement for Skype associated with packet loss effects: A case using conversation-like tests with Thai users. Multimed. Tools Appl. 2017, 76, 16163–16187. [Google Scholar] [CrossRef]
- Jelassi, S.; Rubino, G. A perception-oriented Markov model of loss incidents observed over VoIP networks. Comput. Commun. 2018, 128, 80–94. [Google Scholar] [CrossRef]
- Uhl, T. QoS by VoIP under Use Different Audio Codecs. In Proceedings of the 2018 Joint Conference—Acoustics, Acoustics 2018, Ustka, Poland, 11–14 September 2018; pp. 311–314. [Google Scholar] [CrossRef]
- Mittag, G.; Cutler, R.; Hosseinkashi, Y.; Revow, M.; Srinivasan, S.; Chande, N.; Aichner, R. DNN No-Reference PSTN Speech Quality Prediction. arXiv 2020, arXiv:2007.14598. [Google Scholar] [CrossRef]
- Valentini-Botinhao, C. Noisy Speech Database for Training Speech Enhancement Algorithms and TTS Models; Centre for Speech Technology Research (CSTR), School of Informatics, University of Edinburgh: Edinburgh, UK, 2017. [Google Scholar] [CrossRef]
- Mittag, G.; Naderi, B.; Chehadi, A.; Möller, S. NISQA: A deep CNN-self-attention model for multidimensional speech quality prediction with crowdsourced datasets. arXiv 2021, arXiv:2104.09494. [Google Scholar]
- Kumalija, E.J.; Nakamoto, Y. Performance Evaluation of Automatic Speech Recognition Systems on Integrated Noise-Network Distorted Speech. Front. Signal Process. 2022, 2, 999457. [Google Scholar] [CrossRef]
- da Silva, A.P.C.; Varela, M.; de Souza e Silva, E.; Leão, R.M.; Rubino, G. Quality assessment of interactive voice applications. Comput. Netw. 2008, 52, 1179–1192. [Google Scholar] [CrossRef]
- Soni, M.H.; Patil, H.A. Novel deep autoencoder features for non-intrusive speech quality assessment. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2315–2319. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep Speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Gysel, P.; Pimentel, J.; Motamedi, M.; Ghiasi, S. Ristretto: A Framework for Empirical Study of Resource-Efficient Inference in Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5784–5789. [Google Scholar] [CrossRef] [PubMed]
- Alkhawaldeh, R.S.; Khawaldeh, S.; Pervaiz, U.; Alawida, M.; Alkhawaldeh, H. NIML: Non-intrusive machine learning-based speech quality prediction on VoIP networks. IET Commun. 2019, 13, 2609–2616. [Google Scholar] [CrossRef]
- Valin, J.M.; Vos, K.; Terriberry, T. Definition of the Opus Audio Codec; IETF RFC 6716: Milford, MA, USA, 2012. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distortion | Parameter | Values |
|---|---|---|
| Network | Packet loss (%) | 0, 10, 15, 20, 25, 30, 35 |
| Delay (ms) | 0, 100, 200, 300, 500 | |
| Jitter (% delay) | 0, 10, 20, 30, 40 | |
| Codec | G722 | |
| Noise | Noise type | Babble, car, exhibition hall, restaurant, street, airport, train station, train |
| SNR (dB) | 0, 5, 10, 15 |
| Model | Correlation | MSE |
|---|---|---|
| MiniatureVQNet–Noise–Network | 0.691 | 0.194 |
| Float16 MiniatureVQNet–Noise–Network | 0.690 | 0.194 |
| Full-Integer MiniatureVQNet–Noise–Network | 0.670 | 0.254 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumalija, E.J.; Nakamoto, Y. MiniatureVQNet: A Light-Weight Deep Neural Network for Non-Intrusive Evaluation of VoIP Speech Quality. Appl. Sci. 2023, 13, 2455. https://doi.org/10.3390/app13042455
Kumalija EJ, Nakamoto Y. MiniatureVQNet: A Light-Weight Deep Neural Network for Non-Intrusive Evaluation of VoIP Speech Quality. Applied Sciences. 2023; 13(4):2455. https://doi.org/10.3390/app13042455
Chicago/Turabian StyleKumalija, Elhard James, and Yukikazu Nakamoto. 2023. "MiniatureVQNet: A Light-Weight Deep Neural Network for Non-Intrusive Evaluation of VoIP Speech Quality" Applied Sciences 13, no. 4: 2455. https://doi.org/10.3390/app13042455