
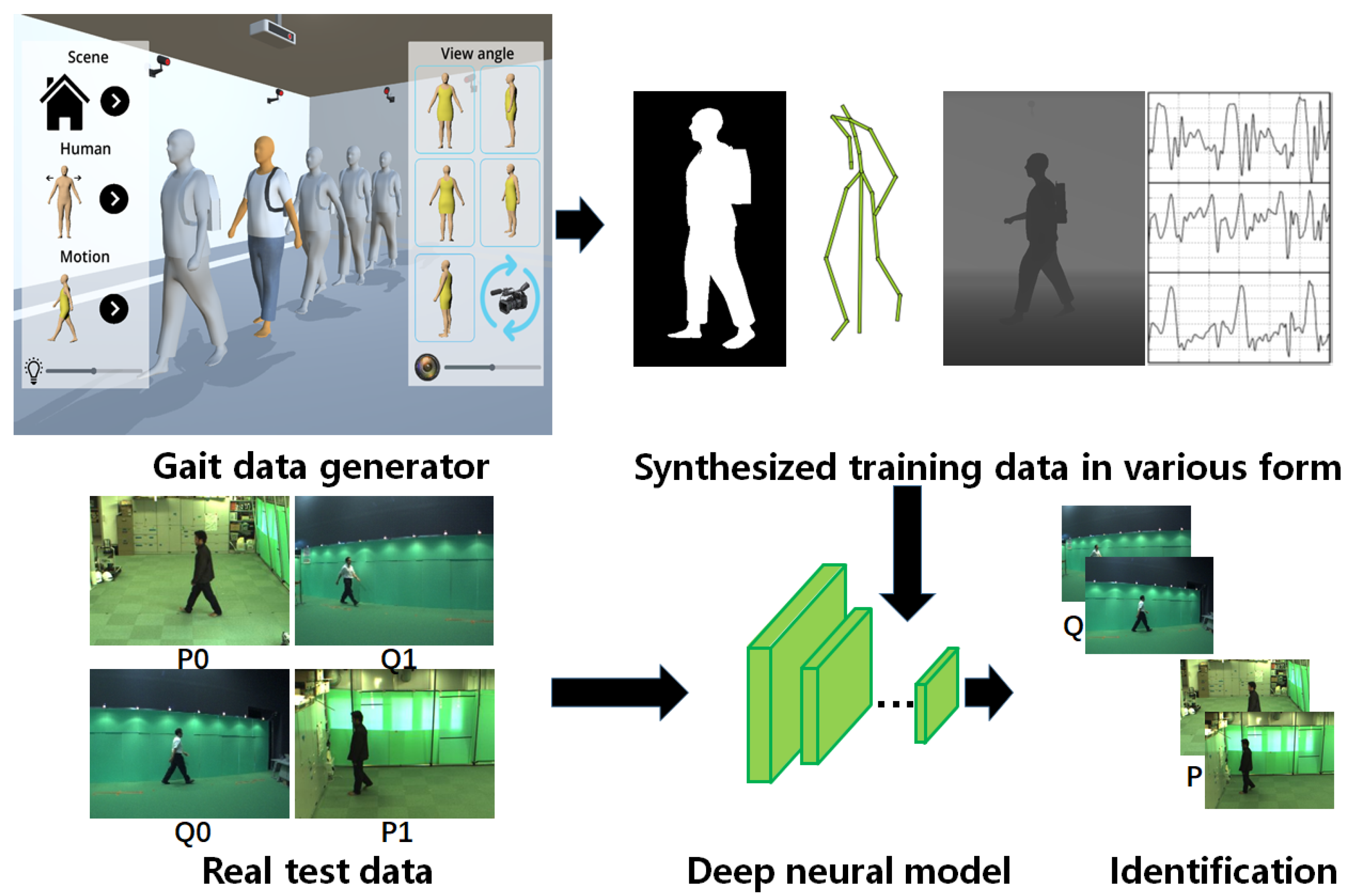
Synthesizing 3D Gait Data with Personalized Walking Style and Appearance

Abstract
:1. Introduction
- We propose a complete framework to explore gait data generation for the purpose of synthesizing unlimited, realistic, and diverse motion data. These data could serve as the training database for learning-based methods in gait recognition, etc.
- We develop a semantic motion style exploration method that controls the motion style via a deep neural network and interpolates motion sequences of different lengths.
- We introduce an appearance parameterization model capable of generating virtual characters with different weight, height, girth, clothing, etc.
2. Related Work
2.1. Gait Recognition
2.2. Gait Data Collection
2.3. Identity Aware Data Synthesis
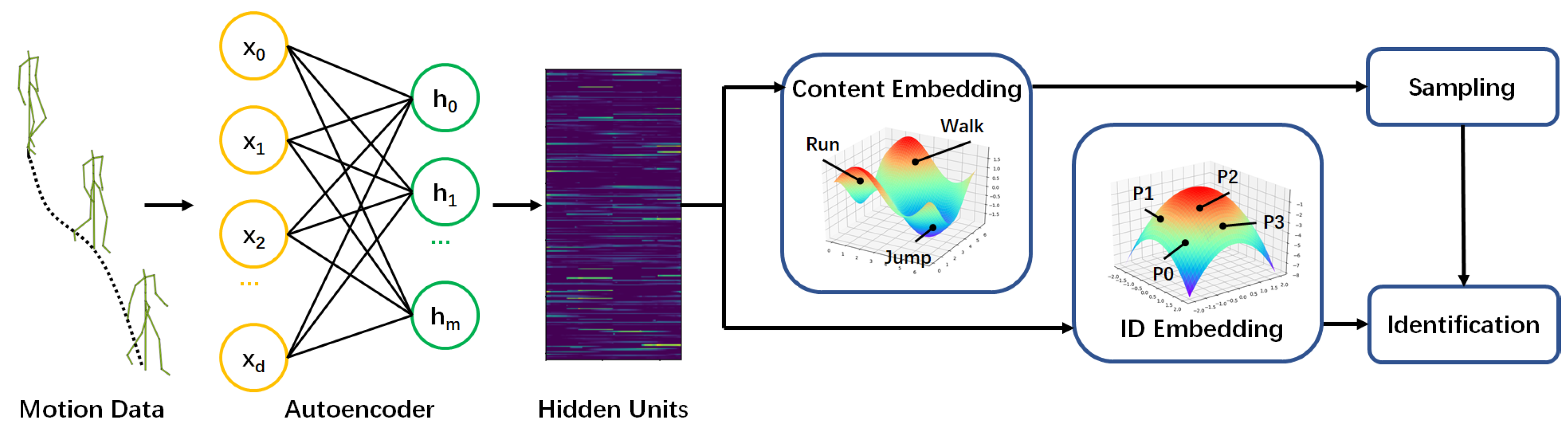
3. Diverse and Personalized Walking Motion Synthesis
- Given synthesized motion data, we should be able to determine whether it is a gait motion or not.
- As mentioned before, we need to balance between inter-subject and intra-subject differences carefully.
3.1. Content Embedding
3.2. ID Embedding
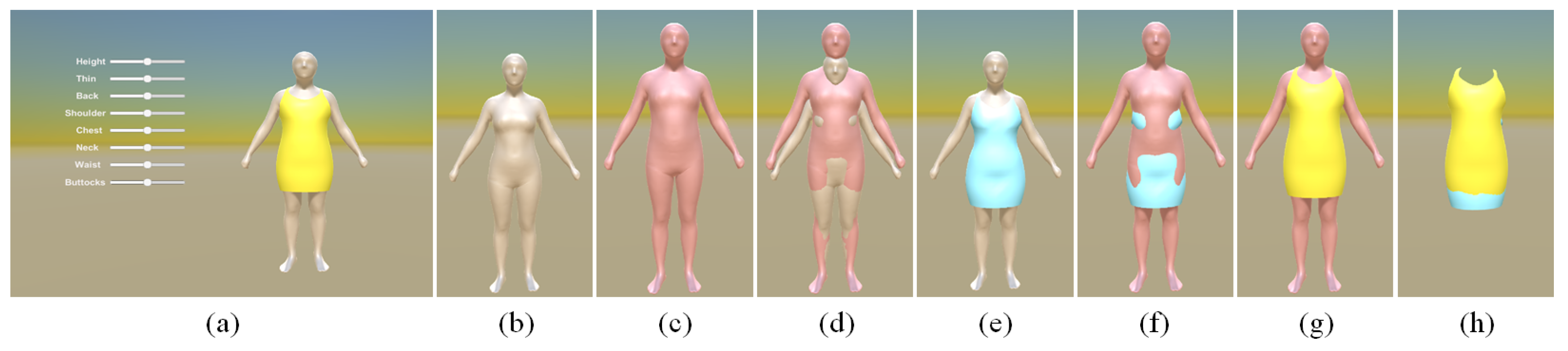
4. Consistent Subject Appearance Variation
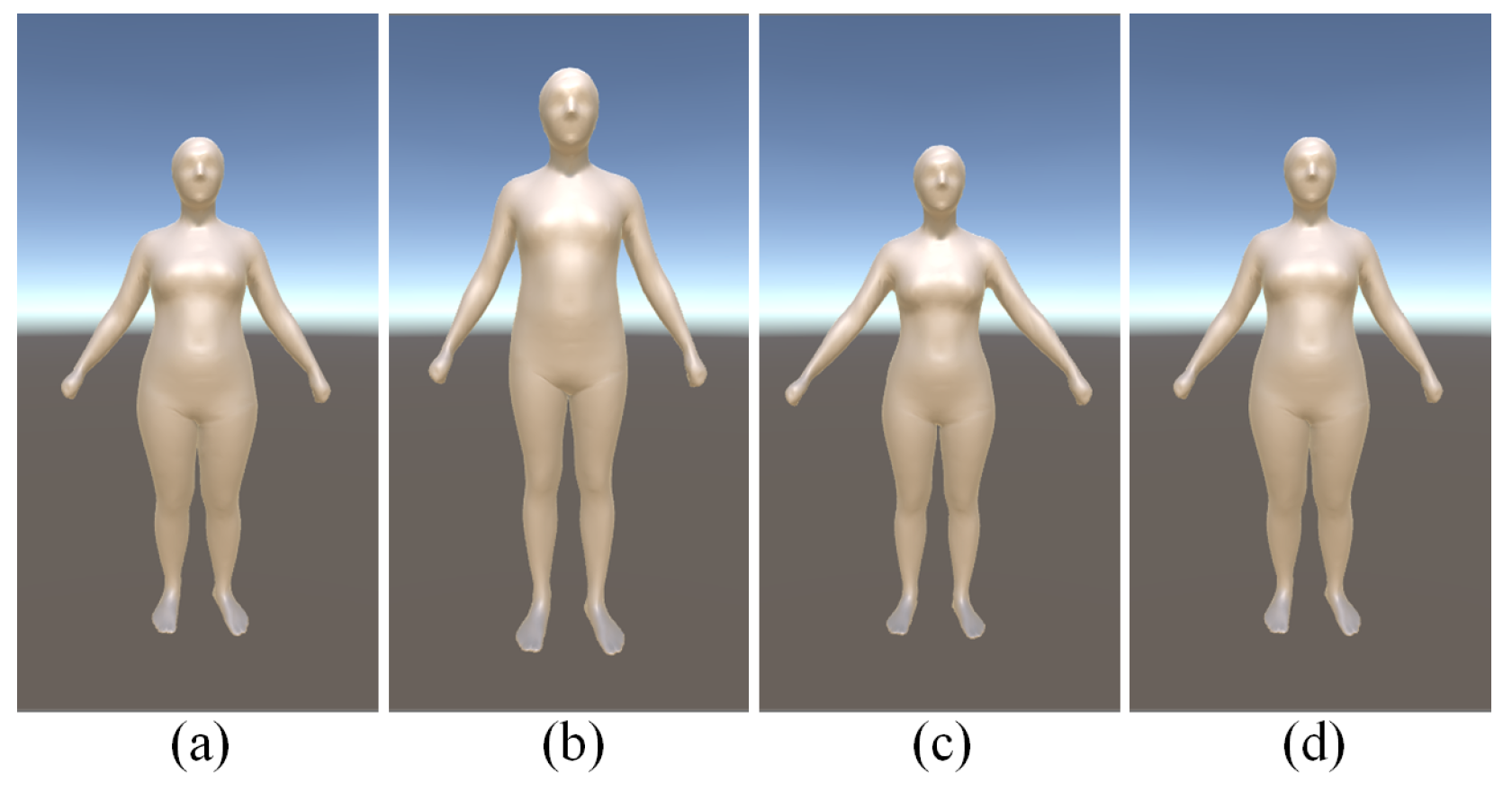
4.1. Parametric Body Adjustment
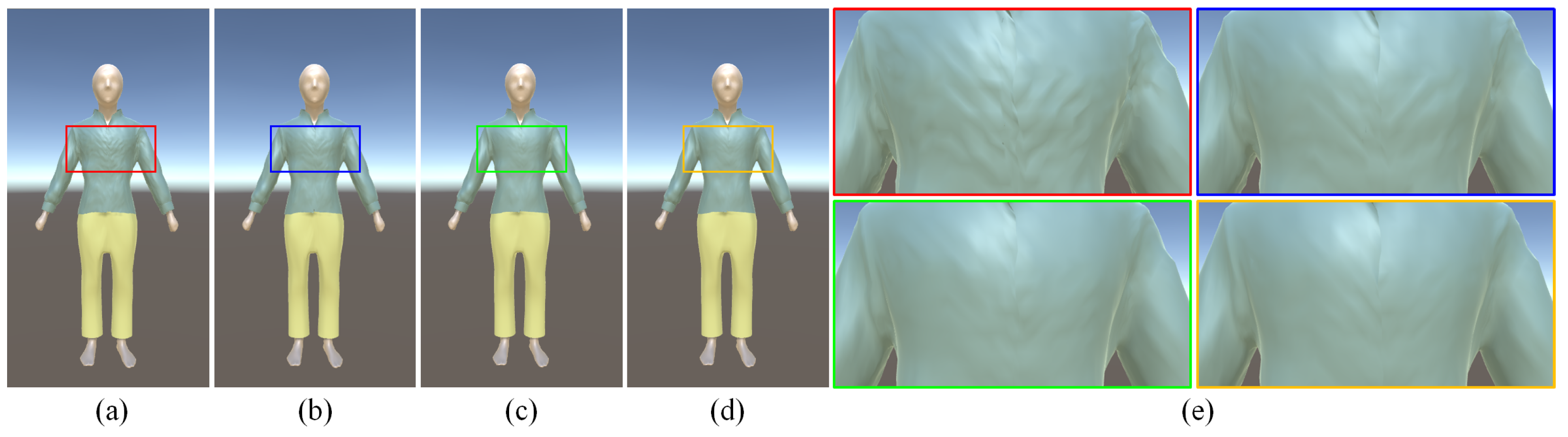
4.2. Clothing Adaptation
4.3. Skeleton Update
5. Experimental Results
5.1. Implementation Details
5.2. Visual Demonstration of Factor Variations
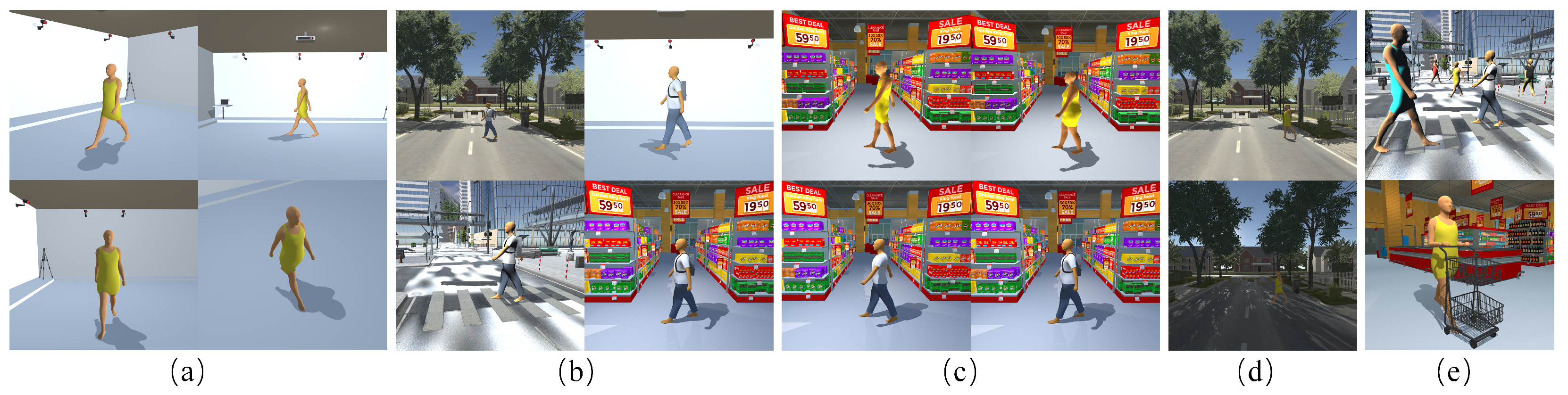
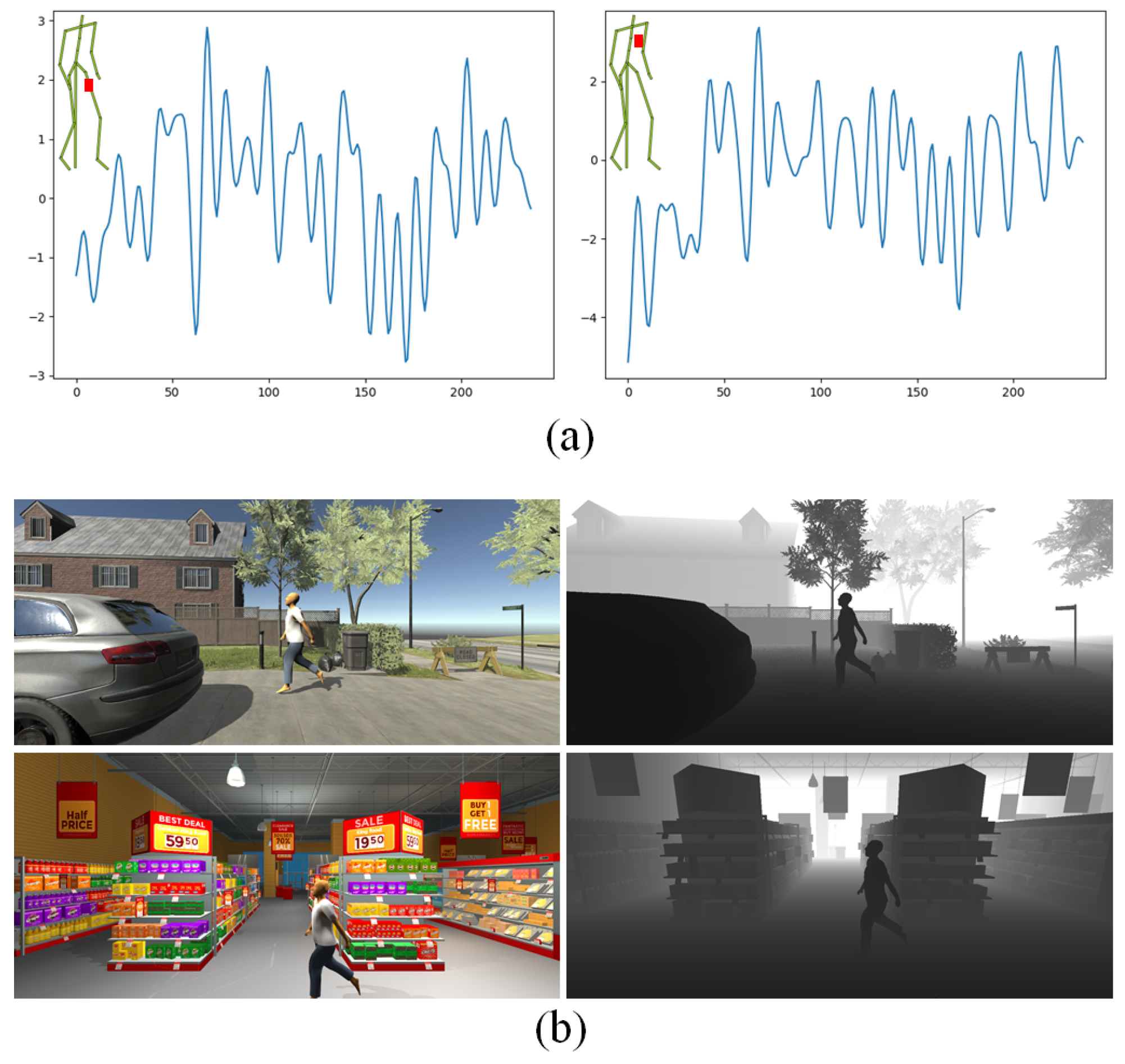
- View variation. As mentioned before, our paradigm can easily generate gait data under various camera positions (see Figure 4a).
- Scene variations. Our gait generator also supports the changes in the scenes, from simple lab environment to a complex real street scenario (see Figure 4b).
- Lighting variation. We can also simulate different lighting conditions. This is particularly common for surveillance cameras on the street (see Figure 4d).
- Motion variations. Unlimited motion data of walking, running, and jumping can be synthesized from the PCA motion space.
5.3. Gait Style Analysis
- The use of absolute coordinates consistently outperforms the relative coordinates across most scenarios. The exceptions are only 5 out of 36 cases, in which the relative coordinates show minor advantages over the absolute ones. The superiority of absolute coordinates shows that the joint trajectories in the global world better reflect the motion content and personal style. We believe the movement of root joints is significant for differentiating walking and running as well as different subjects (people walk or run at different preferred speeds).
- The use of -norm performs best in maximizing the distance in both content and ID embedding. This is shown in the maximal value of . This shows that such a distance metric follows the L2 principle. The potential reason for causing the under-performance of the Mahalanobis distance is a relatively small dataset.
- is optimal for both the content and ID embedding, as shown in the bold numbers. This confirms the usefulness of our auto-encoder in extracting the latent features for both the motion content and personal style.
5.4. Subject Shape Variation
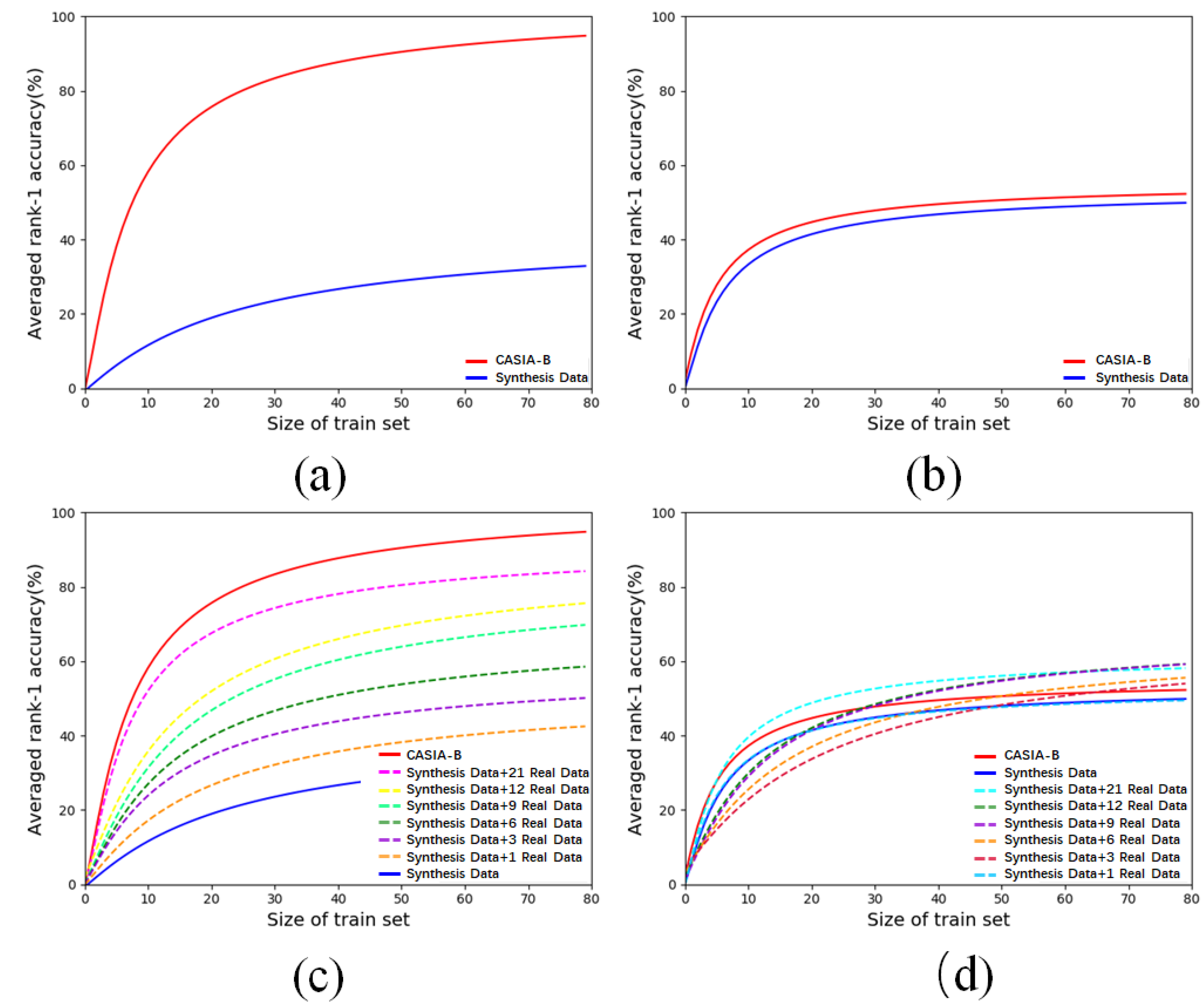
5.5. The Real-to-Virtual Gap and Closing
5.6. Applications
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, L.; Tan, T.; Ning, H.; Hu, W. Silhouette analysis-based gait recognition for human identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1505–1518. [Google Scholar] [CrossRef]
- Connor, P.; Ross, A. Biometric recognition by gait: A survey of modalities and features. Comput. Vis. Image Underst. 2018, 167, 1–27. [Google Scholar] [CrossRef]
- Feng, Y.; Li, Y.; Luo, J. Learning effective Gait features using LSTM. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 325–330. [Google Scholar]
- Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; Tan, T. A comprehensive study on cross-view gait based human identification with deep CNNs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 209–226. [Google Scholar] [CrossRef]
- Chao, H.; He, Y.; Zhang, J.; Feng, J. GaitSet: Regarding gait as a set for cross-view gait recognition. In Proceedings of the AAAI Conference on Artifical Inteligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8126–8133. [Google Scholar]
- Iwama, H.; Okumura, M.; Makihara, Y.; Yagi, Y. The OU-ISIR gait database: Comprising the large population dataset and performance evaluation of gait recognition. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1511–1521. [Google Scholar] [CrossRef]
- Gaidon, A.; Wang, Q.; Cabon, Y.; Vig, E. Virtual worlds as proxy for multi-object tracking analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4340–4349. [Google Scholar]
- Martinez-Gonzalez, P.; Oprea, S.; Garcia-Garcia, A.; Jover-Alvarez, A.; Orts-Escolano, S.; Garcia-Rodriguez, J. Unrealrox: An extremely photorealistic virtual reality environment for robotics simulations and synthetic data generation. Virtual Real. 2020, 24, 271–288. [Google Scholar] [CrossRef]
- McCormac, J.; Handa, A.; Leutenegger, S.; Davison, A.J. Scenenet rgb-d: 5m photorealistic images of synthetic indoor trajectories with ground truth. arXiv 2016, arXiv:1612.05079. [Google Scholar]
- Ariyanto, G.; Nixon, M.S. Model-based 3D gait biometrics. In Proceedings of the International Joint Conference on Biometrics, Washington, DC, USA, 11–13 October 2011; pp. 1–7. [Google Scholar]
- He, Y.; Zhang, J.; Shan, H.; Wang, L. Multi-task GANs for view-specific feature learning in gait recognition. IEEE Trans. Inf. Forensics Secur. 2018, 14, 102–113. [Google Scholar] [CrossRef]
- Sivapalan, S.; Chen, D.; Denman, S.; Sridharan, S.; Fookes, C. Histogram of weighted local directions for gait recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 125–130. [Google Scholar]
- Muramatsu, D.; Shiraishi, A.; Makihara, Y.; Uddin, M.Z.; Yagi, Y. Gait-based person recognition using arbitrary view transformation model. IEEE Trans. Image Process. 2015, 24, 140–154. [Google Scholar] [CrossRef]
- Makihara, Y.; Suzuki, A.; Muramatsu, D.; Li, X.; Yagi, Y. Joint intensity and spatial metric learning for robust gait recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5705–5715. [Google Scholar]
- Zhang, K.; Luo, W.; Ma, L.; Liu, W.; Li, H. Learning joint gait representation via quintuplet loss minimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4700–4709. [Google Scholar]
- Zhang, Z.; Tran, L.; Yin, X.; Atoum, Y.; Liu, X.; Wan, J.; Wang, N. Gait recognition via disentangled representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4710–4719. [Google Scholar]
- Sarkar, S.; Phillips, P.J.; Liu, Z.; Vega, I.R.; Grother, P.; Bowyer, K.W. The humanID gait challenge problem: Data sets, performance, and analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 162–177. [Google Scholar] [CrossRef]
- Yu, S.; Tan, D.; Tan, T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In Proceedings of the International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; pp. 441–444. [Google Scholar]
- Matovski, D.S.; Nixon, M.S.; Mahmoodi, S.; Carter, J.N. The effect of time on the performance of gait biometrics. In Proceedings of the IEEE International Conference on Biometrics: Theory, Applications and Systems, Tampa, FL, USA, 23–26 September 2010; pp. 1–6. [Google Scholar]
- Xu, C.; Makihara, Y.; Ogi, G.; Li, X.; Yagi, Y.; Lu, J. The OU-ISIR gait database comprising the large population dataset with age and performance evaluation of age estimation. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 1–14. [Google Scholar] [CrossRef]
- Pavlakos, G.; Choutas, V.; Ghorbani, N.; Bolkart, T.; Osman, A.A.A.; Tzionas, D.; Black, M.J. Expressive Body Capture: 3D Hands, Face, and Body from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10975–10985. [Google Scholar]
- Han, J.; Bhanu, B. Individual recognition using gait energy image. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; H?usser, P.; Hazirbas, C.; Golkov, V.; van der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Handa, A.; Patraucean, V.; Badrinarayanan, V.; Stent, S.; Cipolla, R. Understanding real world indoor scenes with synthetic data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4077–4085. [Google Scholar]
- Sakaridis, C.; Dai, D.; Gool, L.V. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef]
- Huang, S.; Ramanan, D. Expecting the unexpected: Training detectors for unusual pedestrians with adversarial imposters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2243–2252. [Google Scholar]
- Varol, G.; Romero, J.; Martin, X.; Mahmood, N.; Black, M.J.; Laptev, I.; Schmid, C. Learning from synthetic humans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 109–117. [Google Scholar]
- Roberto de Souza, C.; Gaidon, A.; Cabon, Y.; Manuel Lopez, A. Procedural generation of videos to train deep action recognition networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4757–4767. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Tobin, J.; Zaremba, W.; Abbeel, P. Domain randomization and generative models for robotic grasping. arXiv 2017, arXiv:1710.06425. [Google Scholar]
- Kortylewski, A.; Schneider, A.; Gerig, T.; Egger, B.; Morel-Forster, A.; Vetter, T. Training deep face recognition systems with synthetic data. arXiv 2018, arXiv:1802.05891. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2180–2188. [Google Scholar]
- Tran, L.; Yin, X.; Liu, X. Disentangled representation learning gan for pose-invariant face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1415–1424. [Google Scholar]
- Shen, Y.; Luo, P.; Yan, J.; Wang, X.; Tang, X. FaceID-GAN: Learning a symmetry three-player GAN for identity-preserving face synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 821–830. [Google Scholar]
- Shen, Y.; Zhou, B.; Luo, P.; Tang, X. FaceFeat-GAN: A two-stage approach for identity-preserving face synthesis. arXiv 2018, arXiv:1812.01288. [Google Scholar]
- Bao, J.; Chen, D.; Wen, F.; Li, H.; Hua, G. Towards open-set identity preserving face synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6713–6722. [Google Scholar]
- Nitzan, Y.; Bermano, A.; Li, Y.; Cohen-Or, D. Face identity disentanglement via latent space mapping. ACM Trans. Graph. 2020, 39, 1–14. [Google Scholar] [CrossRef]
- Li, S.; Xiao, T.; Li, H.; Yang, W.; Wang, X. Identity-aware textual-visual matching with latent co-attention. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1890–1899. [Google Scholar]
- Zhou, Y.; Han, X.; Shechtman, E.; Echevarria, J.; Kalogerakis, E.; Li, D. MakeItTalk: Speaker-aware talking head animation. ACM Trans. Graph. 2020, 39, 1–15. [Google Scholar] [CrossRef]
- Yoon, Y.; Cha, B.; Lee, J.H.; Jang, M.; Lee, J.; Kim, J.; Lee, G. Speech gesture generation from the trimodal context of text, audio, and speaker identity. ACM Trans. Graph. 2020, 39, 1–16. [Google Scholar] [CrossRef]
- CMU. Carnegie-Mellon Mocap Database. Available online: http://mocap.cs.cmu.edu/ (accessed on 1 September 2022).
- Xia, S.; Wang, C.; Chai, J.; Hodgins, J. Realtime style transfer for unlabeled heterogeneous human motion. ACM Trans. Graph. 2015, 34, 1–10. [Google Scholar] [CrossRef]
- Müller, M.; Röder, T.; Clausen, M.; Eberhardt, B.; Krüger, B.; Weber, A. Documentation Mocap Database HDM05; Report No. CG-2007-2; Universitat Bonn: Bonn, Germany, 2007. [Google Scholar]
- Holden, D.; Saito, J.; Komura, T. A deep learning framework for character motion synthesis and editing. ACM Trans. Graph. 2016, 35, 1–11. [Google Scholar] [CrossRef]
- de Vazelhes, W.; Carey, C.; Tang, Y.; Vauquier, N.; Bellet, A. Metric-learn: Metric learning algorithms in Python. arXiv 2019, arXiv:1908.04710. [Google Scholar]
- Pishchulin, L.; Wuhrer, S.; Helten, T.; Theobalt, C.; Schiele, B. Building statistical shape spaces for 3D human modeling. Pattern Recognit. 2017, 67, 276–286. [Google Scholar] [CrossRef]
- Chu, C.H.; Tsai, Y.T.; Wang, C.C.L.; Kwok, T.H. Exemplar-based statistical model for semantic parametric design of human body. Comput. Ind. 2010, 61, 541–549. [Google Scholar] [CrossRef]
- Sorkine, O.; Alexa, M. As-rigid-as-possible surface modeling. In Proceedings of the Eurographics Symposium on Geometry Processing, Barcelona, Spain, 4–6 July 2007; pp. 109–116. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Gadaleta, M.; Rossi, M. IDNet: Smartphone-based gait recognition with convolutional neural networks. Pattern Recognit. 2018, 74, 25–37. [Google Scholar] [CrossRef]
- Chattopadhyay, P.; Sural, S.; Mukherjee, J. Frontal gait recognition from incomplete sequences using RGB-D camera. IEEE Trans. Inf. Forensics Secur. 2014, 9, 1843–1856. [Google Scholar] [CrossRef]
- Hattori, H.; Boddeti, V.N.; Kitani, K.; Kanade, T. Learning scene-specific pedestrian detectors without real data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3819–3827. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Vector | Metric | Content Embedding Distances | ID Embedding Distances | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Walk | Run | W–R | P1 | P2 | P1–P2 | ||||||||
| Dist | Std | Dist | Std | Dist | Dist | Std | Dist | Std | Dist | ||||
| 53.22 | 12.25 | 24.41 | 15.16 | 95.25 | 1.27 | 13.79 | 13.98 | 11.53 | 11.17 | 62.67 | 2.48 | ||
| 21.88 | 6.61 | 8.17 | 4.84 | 25.89 | 0.86 | 6.82 | 7.23 | 5.36 | 5.07 | 47.12 | 3.87 | ||
| 2.77 | 0.92 | 1.93 | 1.22 | 3.24 | 0.81 | 1.12 | 0.92 | 1.61 | 1.06 | 2.91 | 1.07 | ||
| 73.67 | 26.63 | 38.10 | 18.32 | 100.12 | 1.00 | 40.22 | 26.11 | 34.95 | 17.20 | 79.77 | 1.30 | ||
| 43.50 | 18.78 | 24.41 | 12.62 | 60.23 | 0.89 | 34.20 | 21.90 | 29.70 | 16.57 | 51.06 | 0.80 | ||
| 1.98 | 0.57 | 0.96 | 0.50 | 3.20 | 1.09 | 0.89 | 0.55 | 0.78 | 0.35 | 2.43 | 1.46 | ||
| 48.11 | 10.83 | 23.26 | 14.38 | 71.18 | 1.00 | 10.71 | 10.64 | 6.64 | 8.52 | 49.76 | 2.87 | ||
| 17.30 | 4.82 | 6.73 | 4.06 | 42.67 | 1.78 | 5.27 | 5.56 | 3.08 | 3.86 | 36.27 | 4.34 | ||
| 3.26 | 1.04 | 2.78 | 1.79 | 3.24 | 0.54 | 1.10 | 0.91 | 0.90 | 1.03 | 2.93 | 1.47 | ||
| 64.90 | 16.94 | 31.67 | 12.84 | 71.86 | 0.74 | 33.93 | 16.91 | 29.39 | 11.19 | 65.28 | 1.03 | ||
| 28.79 | 8.79 | 15.40 | 7.07 | 42.08 | 0.95 | 22.37 | 11.10 | 18.21 | 7.27 | 37.49 | 0.92 | ||
| 2.89 | 0.71 | 1.52 | 0.61 | 3.24 | 0.73 | 1.38 | 0.59 | 1.15 | 0.38 | 2.70 | 1.07 | ||
| 575.62 | 178.39 | 621.93 | 361.30 | 1423.82 | 1.19 | 112.60 | 98.07 | 42.51 | 32.51 | 719.86 | 4.64 | ||
| 250.40 | 74.48 | 242.08 | 147.29 | 953.01 | 1.94 | 71.18 | 61.89 | 27.94 | 21.78 | 494.09 | 4.98 | ||
| 2.16 | 0.74 | 3.17 | 1.96 | 3.23 | 0.61 | 0.82 | 0.91 | 0.33 | 0.33 | 2.90 | 2.52 | ||
| 2215.04 | 1167.85 | 1352.18 | 704.60 | 1954.28 | 0.55 | 1603.36 | 1019.97 | 1081.91 | 535.17 | 1008.38 | 0.38 | ||
| 1302.38 | 676.76 | 830.79 | 421.47 | 1312.16 | 0.62 | 1276.79 | 786.57 | 833.78 | 404.82 | 823.57 | 0.39 | ||
| 2.10 | 0.95 | 1.14 | 0.62 | 3.09 | 0.95 | 1.22 | 0.65 | 0.91 | 0.42 | 0.70 | 0.33 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Y.; Zhang, G.; Huang, S.; Wang, Z.; Cheng, X.; Lin, J. Synthesizing 3D Gait Data with Personalized Walking Style and Appearance. Appl. Sci. 2023, 13, 2084. https://doi.org/10.3390/app13042084
Cheng Y, Zhang G, Huang S, Wang Z, Cheng X, Lin J. Synthesizing 3D Gait Data with Personalized Walking Style and Appearance. Applied Sciences. 2023; 13(4):2084. https://doi.org/10.3390/app13042084
Chicago/Turabian StyleCheng, Yao, Guichao Zhang, Sifei Huang, Zexi Wang, Xuan Cheng, and Juncong Lin. 2023. "Synthesizing 3D Gait Data with Personalized Walking Style and Appearance" Applied Sciences 13, no. 4: 2084. https://doi.org/10.3390/app13042084