
A Two-Step Framework to Recognize Emotion Using the Combinations of Adjacent Frequency Bands of EEG

Abstract
:1. Introduction
- (a)
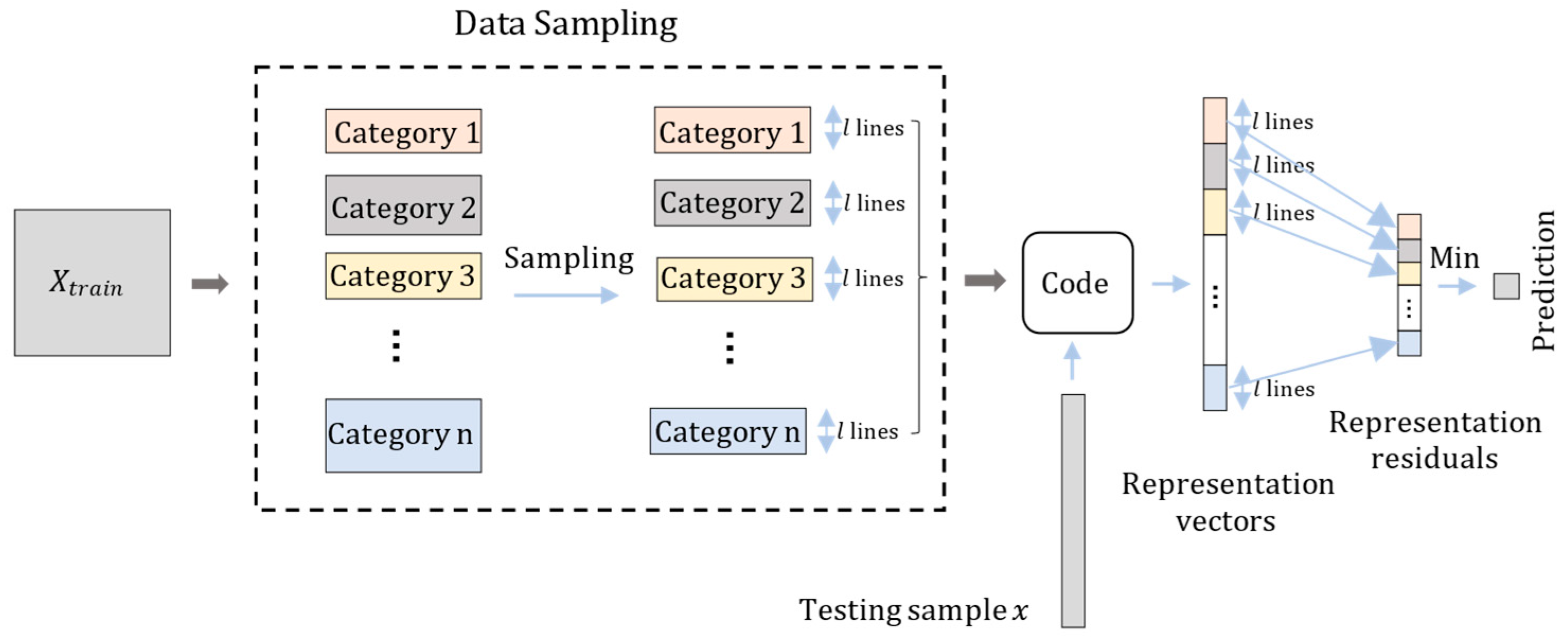
- The CRC_RLS method is optimized to retain the same dimension of the representation coefficient in each category;
- (b)
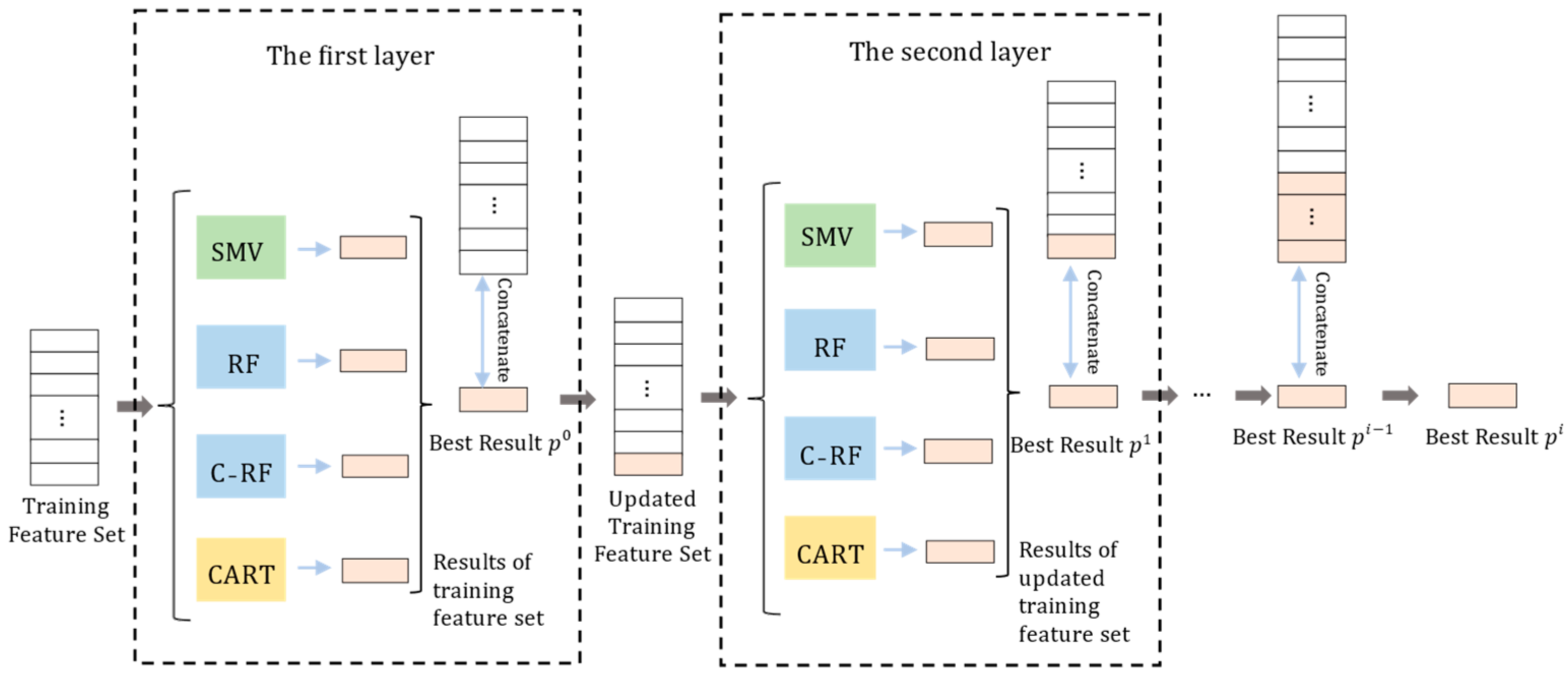
- The CGEL decision fusion method is designed to improve the prediction accuracy;
- (c)
- An EEG-based classification framework HCRC-CGEL is constructed to utilize the complementary information from different frequency bands;
- (d)
- The experiments on two databases demonstrate the performance of the framework.
2. Related Work
3. Methods
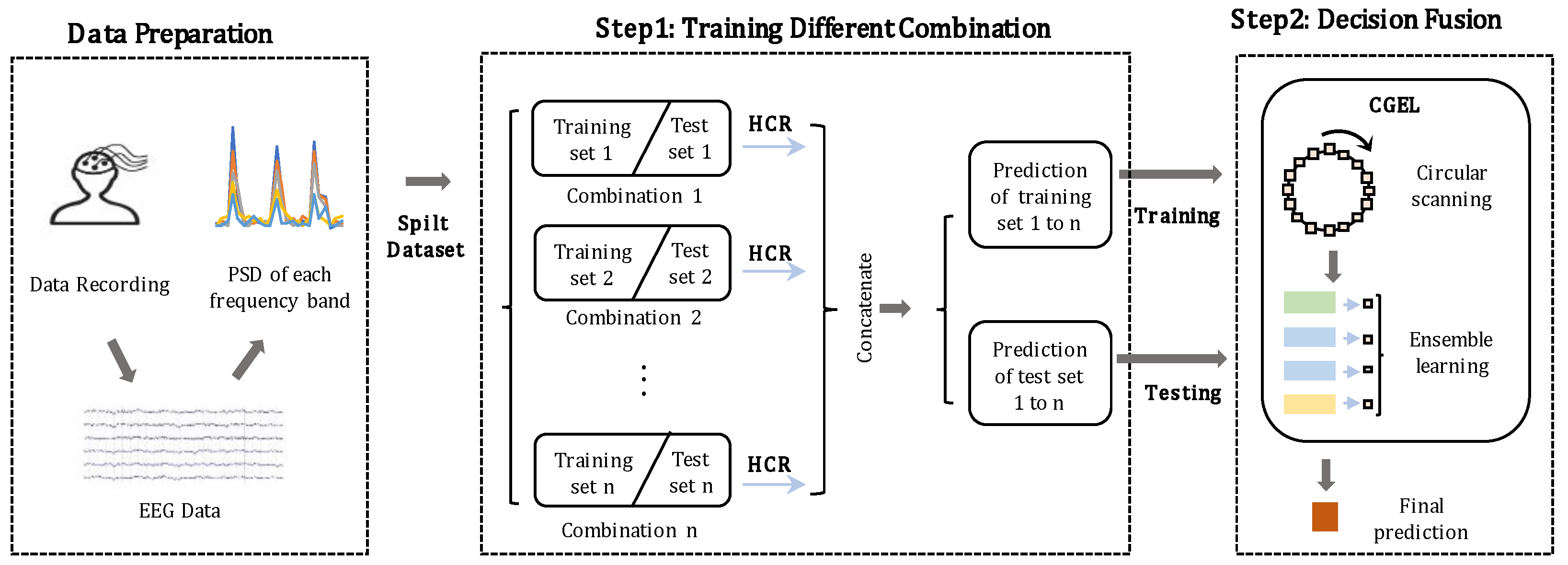
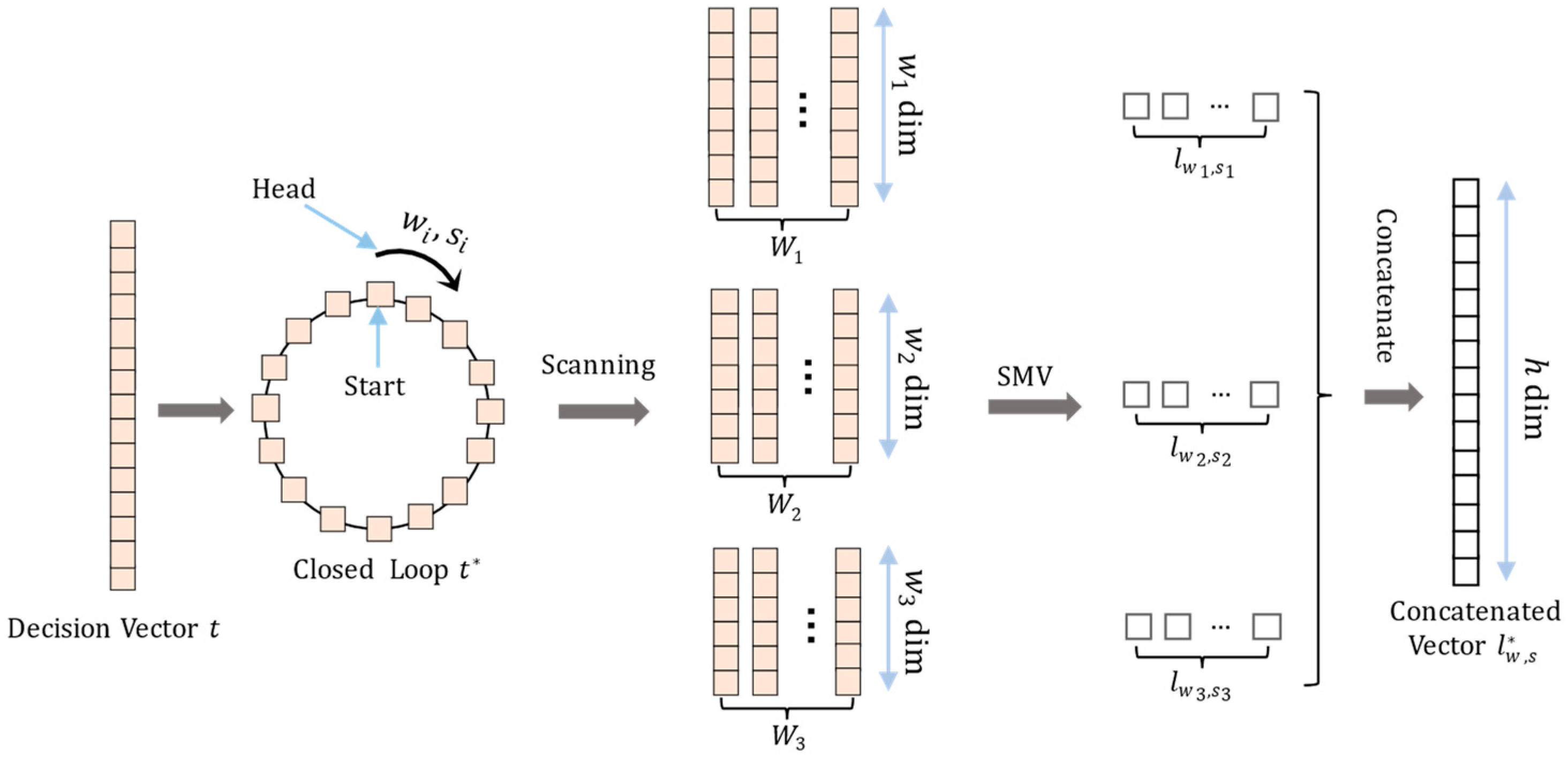
3.1. Combinations of All the Adjacent Frequency Bands
3.2. The HCRC Method
3.3. The CGEL Method
4. Materials and Experiments
4.1. Database Introduction and Preprocessing
4.2. Experimental Setting
4.3. Statistical Analysis
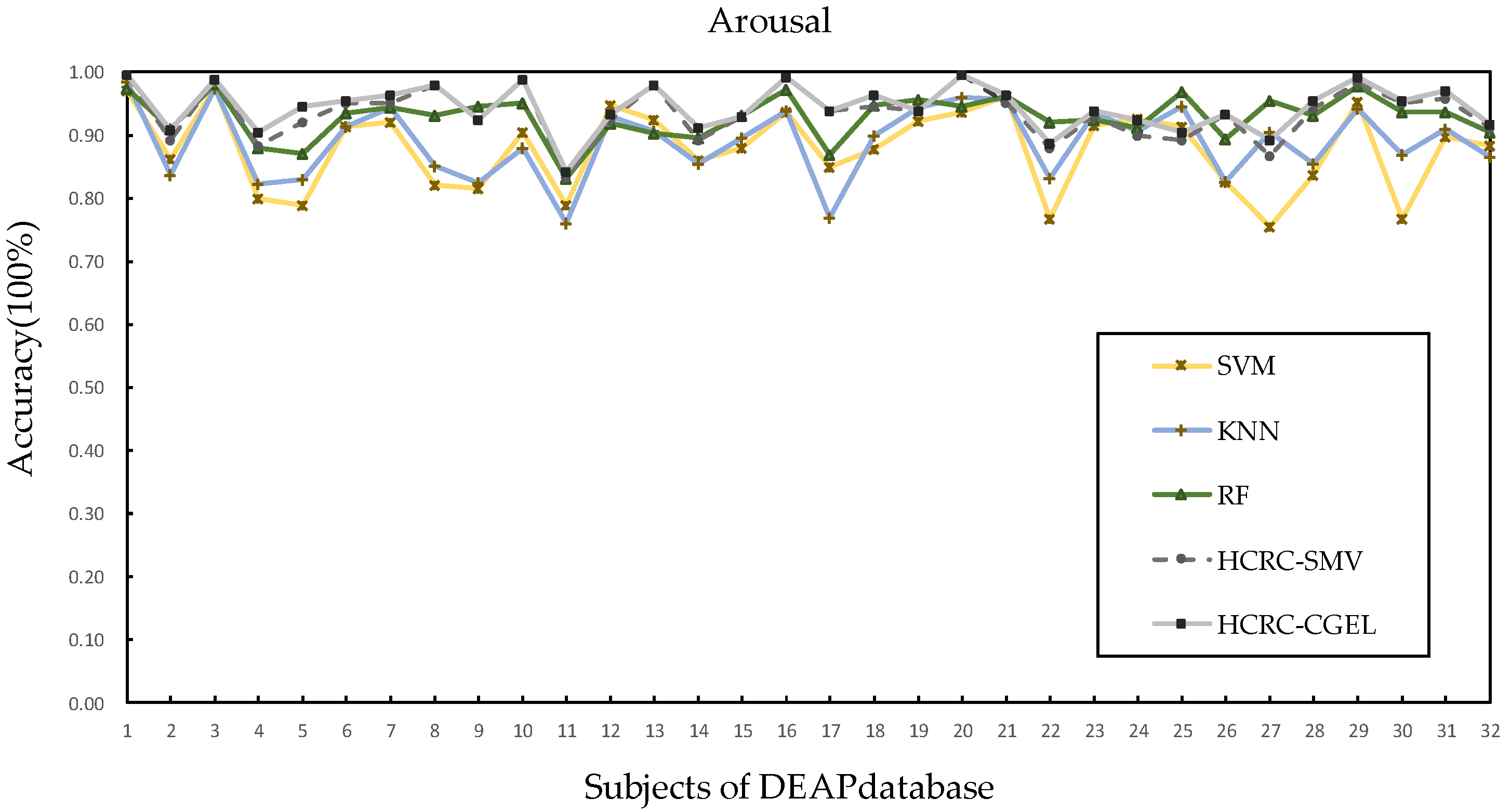
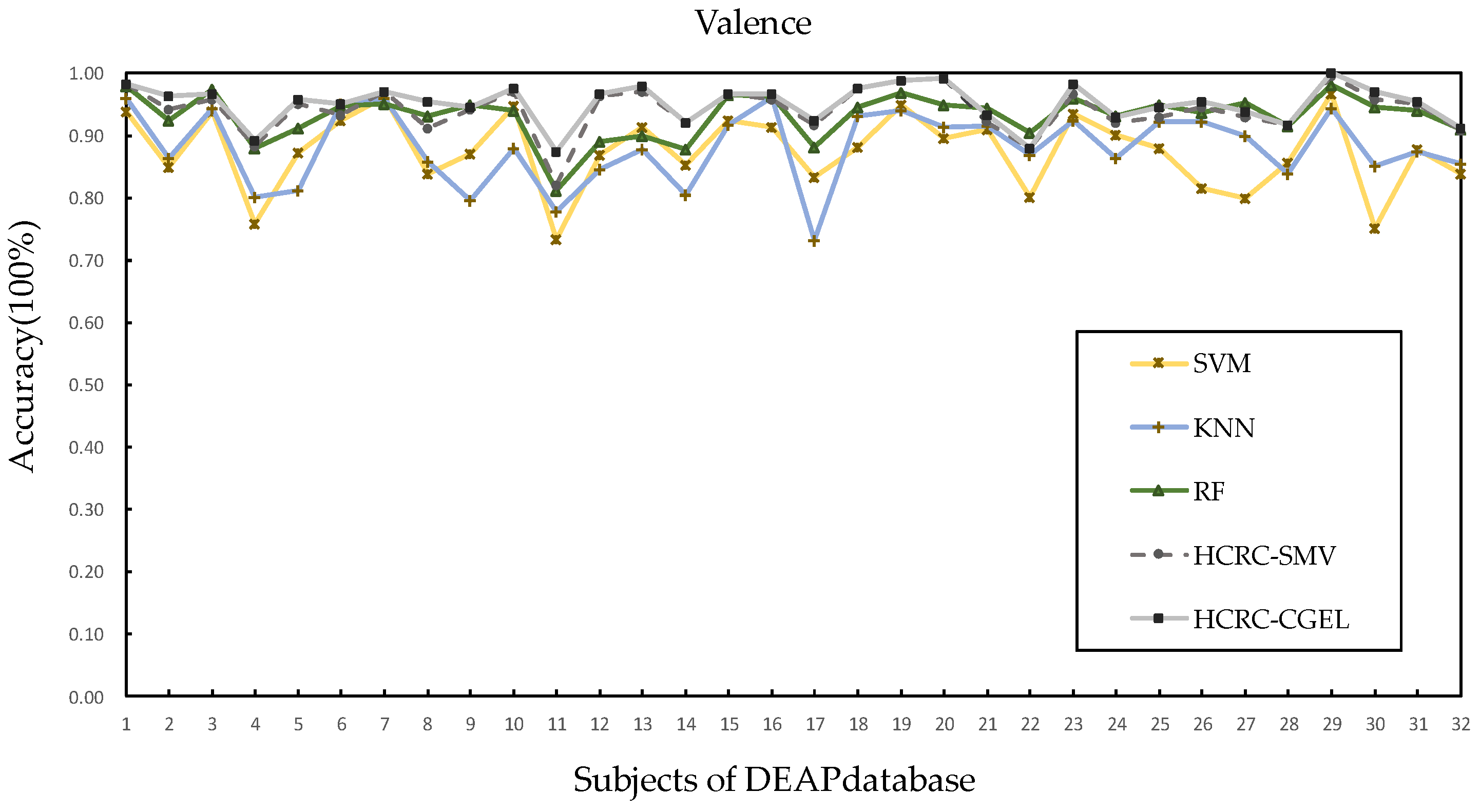
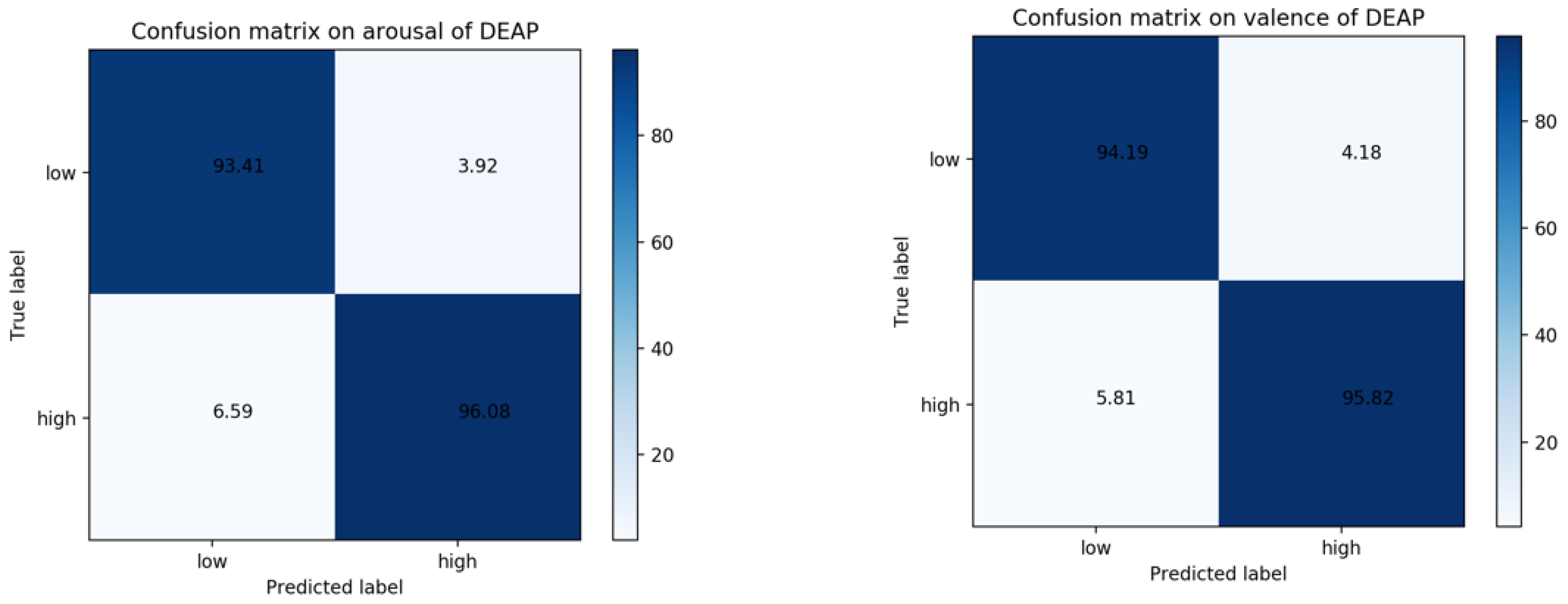
4.4. Performances on DEAP Database
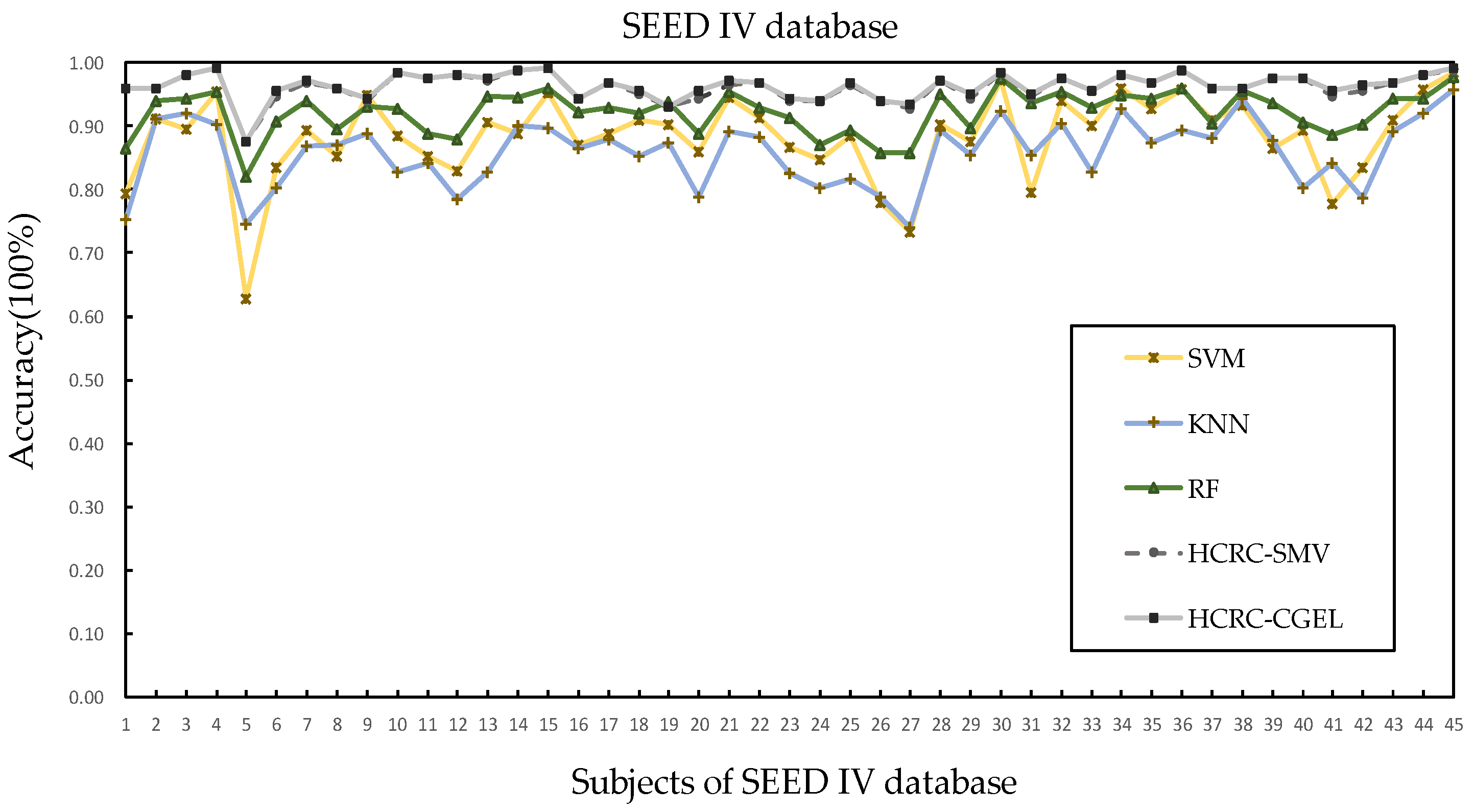
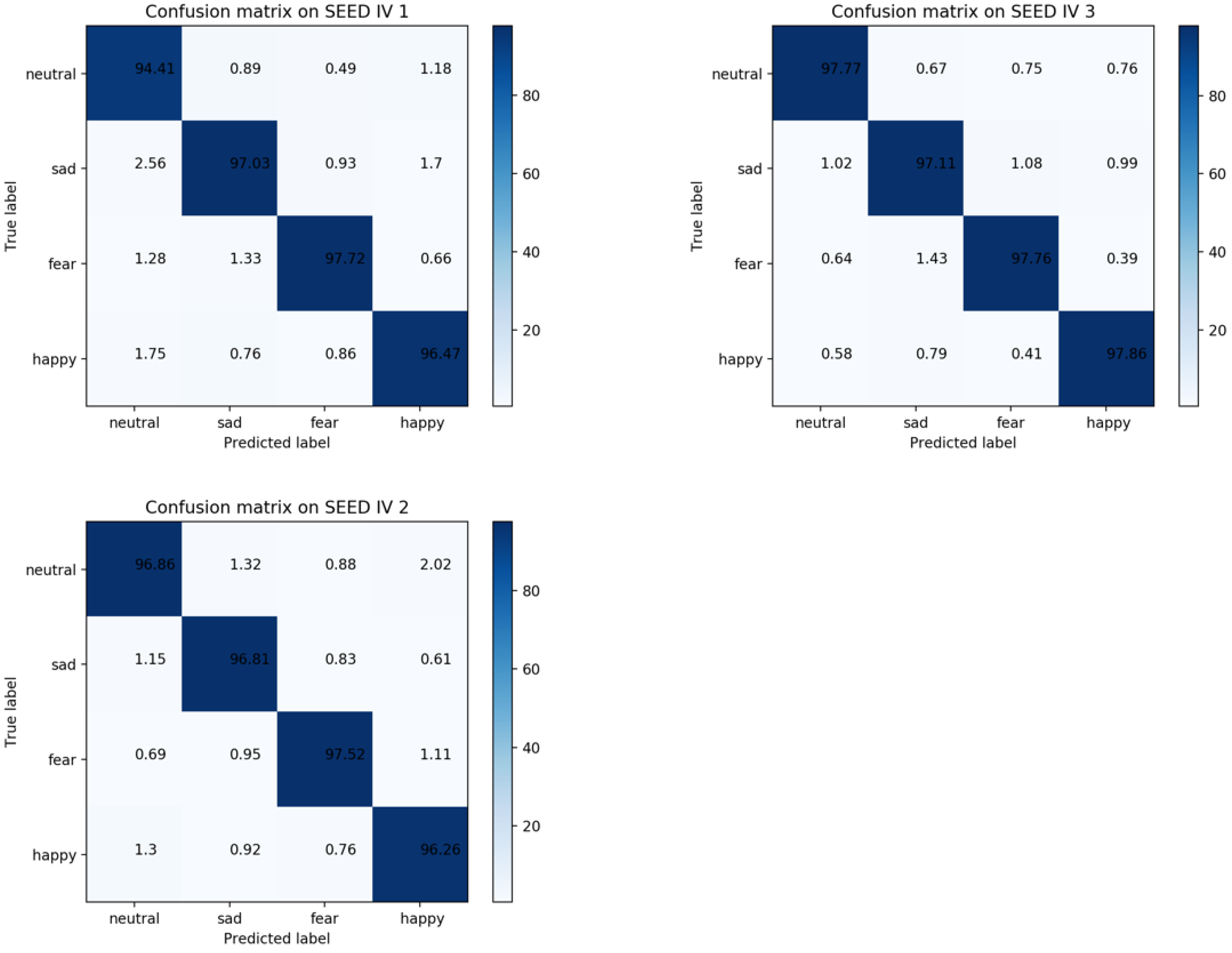
4.5. Performances on SEED IV Database
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Picard, R.W.; Vyzas, E.; Healey, J. Toward Machine Emotional Intelligence: Analysis of Affective Physiological State. IEEE Trans. Pattern Anal. 2001, 23, 1175–1191. [Google Scholar] [CrossRef]
- Feng, Z.; Yang, B.; Liu, H.; Lv, N.; Yang, X.; Yin, J.; Zhang, Y.; Zhao, X. An HCI Paradigm Fusing Flexible Object Selection and AOM-Based Animation. Inform. Sci. 2016, 369, 368–387. [Google Scholar] [CrossRef]
- Lopatovska, I.; Arapakis, I. Theories, Methods and Current Research on Emotions in Library and Information Science, Information Retrieval and Human-Computer Interaction. Inform. Process. Manag. 2011, 47, 575–592. [Google Scholar] [CrossRef]
- Li, C.; Tao, W.; Cheng, J.; Liu, Y.; Chen, X. Robust Multichannel EEG Compressed Sensing in the Presence of Mixed Noise. IEEE Sens. J. 2019, 19, 10574–10583. [Google Scholar]
- Recio, G.; Schacht, A.; Sommer, W. Recognizing Dynamic Facial Expressions of Emotion: Specificity and Intensity Effects in Event-Related Brain Potentials. Biol. Psychol. 2014, 96, 111–125. [Google Scholar] [PubMed]
- Ahrens, S.; Twanow, J.D.; Vidaurre, J.; Gedela, S.; Moore-Clingenpee, M.; Ostendorf, A.P. Electroencephalography Technologist Inter-Rater Agreement and Interpretation of Pediatric Critical Care Electroencephalography. Pediatr. Neurol. 2021, 115, 66–71. [Google Scholar] [CrossRef]
- Varsehi, H.; Firoozabadi, S. An EEG Channel Selection Method for Motor Imagery Based Brain–Computer Interface and Neurofeedback Using Granger Causality. Neural Netw. 2021, 133, 193–206. [Google Scholar] [CrossRef]
- Qureshi, S.A.; Dias, G.; Hasanuzzaman, M.; Saha, S. Improving Depression Level Estimation by Concurrently Learning Emotion Intensity. IEEE Comput. Intell. Mag. 2020, 15, 47–59. [Google Scholar] [CrossRef]
- Li, Q.; Liu, Y.Q.; Liu, Q.Y.; Zhang, Q.; Yan, F.; Ma, Y.M.; Zhang, X.Y. Multidimensional Feature in Emotion Recognition Based on Multi-Channel EEG Signals. Entropy 2022, 24, 1830. [Google Scholar] [CrossRef]
- Canolty, R.T.; Knight, R.T. The Functional Role of Cross-Frequency Coupling. Trends Cogn. Sci. 2010, 14, 506–515. [Google Scholar] [CrossRef]
- Wang, W. Brain Network Features Based on Theta-Gamma Cross-Frequency Coupling Connections in EEG for Emotion Recognition. Neurosci. Lett. 2021, 761, 136106. [Google Scholar] [CrossRef] [PubMed]
- Munck, J.C.; Goncalves, S.I.; Mammoliti, R.; Heethaar, R.M.; Da Silva, F.H.L. Interactions Between Different EEG Frequency Bands and Their Effect on Alpha-FMRI Correlations. Neuroimage 2009, 47, 69–76. [Google Scholar] [CrossRef] [PubMed]
- Alarcao, S.M.; Fonseca, M.J. Emotions Recognition Using EEG Signals: A Survey. IEEE Trans. Affect. Comput. 2017, 10, 374–393. [Google Scholar] [CrossRef]
- Ang, A.Q.; Yeong, Y.Q.; Wee, W. Emotion Classification from EEG Signals Using Time-Frequency-DWT Features and ANN. J. Comput. Commun. 2017, 5, 75–79. [Google Scholar] [CrossRef]
- Sepúlveda, A.; Castillo, L.; Palma, C.; Rodriguez-Fernandez, M. Emotion Recognition from ECG Signals Using Wavelet Scattering and Machine Learning. Appl. Sci. 2021, 11, 4945. [Google Scholar] [CrossRef]
- Sun, L.; Jin, B.; Yang, H.; Tong, J.; Liu, C.; Xiong, H. Unsupervised EEG Feature Extraction Based on Echo State Network. Inform. Sci. 2018, 475, 1–17. [Google Scholar] [CrossRef]
- Zhuang, N.; Zeng, Y.; Tong, L.; Zhang, C.; Zhang, H. Emotion Recognition from EEG Signals Using Multidimensional Information in EMD Domain. BioMed Res. Int. 2017, 2017, 8317357. [Google Scholar] [CrossRef]
- Gupta, V.; Chopda, M.D.; Pachori, R.B. Cross-subject Emotion Recognition Using Flexible Analytic Wavelet Transform from EEG Signals. IEEE Sens. J. 2019, 19, 2266–2274. [Google Scholar] [CrossRef]
- Hu, J.; Wang, C.; Jia, Q.; Bu, Q.; Sutcliffe, R.; Feng, J. ScalingNet: Extracting Features from Raw EEG Data for Emotion Recognition. Neurocomputing 2021, 463, 177–184. [Google Scholar] [CrossRef]
- Li, Q.; Liu, Y.Q.; Shang, Y.J.; Zhang, Q.; Yan, F. Deep Sparse Autoencoder and Recursive Neural Network for EEG Emotion Recognition. Entropy 2022, 24, 1187. [Google Scholar] [CrossRef]
- Hu, Z.F.; Chen, L.; Luo, Y.; Zhou, J.F. EEG-Based Emotion Recognition Using Convolutional Recurrent Neural Network with Multi-Head Self-Attention. Appl. Sci. 2022, 12, 11255. [Google Scholar] [CrossRef]
- Li, Y.J.; Huang, J.J.; Zhou, H.Y.; Zhong, N. Human Emotion Recognition with Electroencephalographic Multidimensional Features by Hybrid Deep Neural Networks. Appl. Sci. 2017, 7, 1060. [Google Scholar] [CrossRef]
- Zhu, H.; Lin, N.; Leung, H.; Leung, R.; Theodoidis, S. Target Classification from SAR Imagery Based on the Pixel Grayscale Decline by Graph Convolutional Neural Network. IEEE Sens. Lett. 2020, 4, 1–4. [Google Scholar] [CrossRef]
- Phan, A.V.; Nguyen, M.L.; Nguyen, Y.L.H.; Bui, L.T. DGCNN: A Convolutional Neural Network over Large-Scale Labeled Graphs. Neural Netw. 2018, 108, 533–543. [Google Scholar] [CrossRef]
- Aditi, S.; Pradeep, T.; Harshit, B.; Divya, A.; Arpit, B. A LSTM based deep learning network for recognizing emotions using wireless brainwave driven system. Expert Syst. Appl. 2021, 173, 114516. [Google Scholar]
- Zuo, X.; Zhang, C.; Hämäläinen, T.; Gao, H.B.; Fu, Y.; Cong, F.Y. Cross-Subject Emotion Recognition Using Fused Entropy Features of EEG. Entropy 2022, 29, 1281. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, M.; Feng, X. Sparse Representation or Collaborative Representation: Which Helps Face Recognition? In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 471–478. [Google Scholar]
- Jiang, Y.; Li, W.; Hossain, M.S.; Chen, M.; Alelaiwi, A.; Al-Hammadi, M. A Snapshot Research and Implementation of Multimodal Information Fusion for Data-Driven Emotion Recognition. Inform. Fusion 2019, 53, 209–221. [Google Scholar] [CrossRef]
- Nemati, S.; Rohani, R.; Basiri, M.E.; Abdar, M.; Yen, N.Y.; Makarenkov, V. A Hybrid Latent Space Data Fusion Method for Multimodal Emotion Recognition. IEEE Access 2019, 7, 172948–172964. [Google Scholar] [CrossRef]
- Shen, F.; Peng, Y.; Kong, W.; Dai, G. Multi-scale Frequency Bands Ensemble Learning for EEG-Based Emotion Recognition. Sensors 2021, 21, 1262. [Google Scholar] [CrossRef]
- Zhou, Z.; Feng, J. Deep forest. Nati. Sci. Rev. 2019, 6, 74–86. [Google Scholar] [CrossRef]
- Xia, H.; Tang, J.; Qiao, J.; Zhang, J.; Yu, W. DF Classification Algorithm for Constructing a Small Sample Size of Data-Oriented DF Regression Model. Neural Comput. Appl. 2022, 34, 2785–2810. [Google Scholar] [CrossRef]
- Benasich, A.A.; Gou, Z.; Choudhury, N. Early Cognitive and Language Skills are Linked to Resting Frontal Gamma Power Across the First 3 Years. Behav. Brain Res. 2008, 195, 215–222. [Google Scholar]
- Zivan, M.; Bar, S.; Jing, X. Screen-exposure and Altered Brain Activation Related to Attention in Preschool Children: An EEG Study. Trends Neurosci. Edu. 2019, 17, 100117. [Google Scholar] [CrossRef] [PubMed]
- Sun, G.; Hu, J.; Wu, G. A Novel Frequency Band Selection Method for Common Spatial Pattern in Motor Imagery Based Brain Computer Interface. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–6. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Liu, F.; Ting, K.; Yu, Y.; Zhou, Z. Spectrum of Variable-Random Trees. J. Artif. Intell. Res. 2008, 32, 355–384. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees. Biometric 1984, 40, 874. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. DEAP: A Database for Emotion Analysis Using Physiological Signals. IEEE T. Affect. Comput. 2011, 3, 18–31. [Google Scholar] [CrossRef]
- Zheng, W.; Liu, W.; Lu, Y.; Lu, B.; Cichocki, A. Emotionmeter: A Multimodal Framework for Recognizing Human Emotions. IEEE T. Cybern. 2018, 49, 1110–1122. [Google Scholar] [CrossRef]
- Shi, L.; Jiao, Y.; Lu, B. Differential Entropy Feature for EEG-Based Vigilance Estimation. In Proceedings of the 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 6627–6630. [Google Scholar]
- Zheng, X.; Yu, X.; Yin, Y.; Li, T.; Yan, X. Three-dimensional Feature Maps and Convolutional Neural Network-Based Emotion Recognition. Int. J. Intell. Syst. 2021, 36, 6312–6336. [Google Scholar] [CrossRef]
- Yin, Y.; Zheng, X.; Hu, B.; Zhang, Y.; Cui, X. EEG Emotion Recognition Using Fusion Model of Graph Convolutional Neural Networks and LSTM. Appl. Soft Comput. 2021, 100, 106954. [Google Scholar] [CrossRef]
- Zheng, F.; Hu, B.; Zhang, S.; Li, Y.; Zheng, X. EEG Emotion Recognition Based on Hierarchy Graph Convolution Network. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; pp. 1628–1632. [Google Scholar]
- Deng, X.; Zhu, J.; Yang, S. SFE-Net: EEG-based Emotion Recognition with Symmetrical Spatial Feature Extraction. In Proceedings of the 29th ACM International Conference on Multimedia, Nice, France, 21–25 October 2021; pp. 2391–2400. [Google Scholar]
- Jia, J.; Zhang, B.; Lv, H.; Xu, Z.; Hu, S.; Li, H. CR-GCN: Channel-relationships-based Graph Convolutional Network for EEG Emotion Recognition. Brain Sci. 2022, 12, 987. [Google Scholar] [CrossRef] [PubMed]
- Qiu, J.; Liu, W.; Lu, B. Multi-view Emotion Recognition Using Deep Canonical Correlation Analysis. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 18–22 November 2018; pp. 221–231. [Google Scholar]
- Qiu, J.; Li, X.; Hu, K. Correlated Attention Networks for Multimodal Emotion Recognition. In Proceedings of the International Conference on Bioinformatics and Biomedicine (BIBM), IEEE, Madrid, Spain, 3–6 December 2018; pp. 2656–2660. [Google Scholar]
- Qing, C.; Qiao, R.; Xu, X.; Cheng, Y. Interpretable Emotion Recognition Using EEG Signals. IEEE Access 2019, 7, 94160–94170. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Data Content | Data Shape | Data Description |
|---|---|---|---|
| DEAP | Raw data | 40 × 32 × (128 × 63) | Video × channel × (sample rate × time) |
| Preprocessed data | × 128 | sample number × (channel × band) | |
| Preprocessed labels | × 2 | sample number × (A, V) | |
| Number of dataset | 32 | trial | |
| SEED IV | Raw data | ) | video × channel × (sample rate × time) |
| Preprocessed data | × 310 | sample number × (channel × band) | |
| Preprocessed labels | × 4 | sample number × (H, S, F and N) | |
| Number of dataset | 45 | trial |
| Dataset | RF | KNN | SVM | HCRC-SMV | HCRC-CGEL |
|---|---|---|---|---|---|
| DEAP(A) | 92.86 | 88.94 | 87.81 | 93.88 | 94.93 |
| DEAP(V) | 93.14 | 88.13 | 87.48 | 94.26 | 95.09 |
| Method | Arousal (%) | Valence (%) |
|---|---|---|
| 3DCNER (Zheng et al.) [42] | 84.53 | 83.83 |
| ERDL (Yin et al.) [43] | 85.27 | 84.81 |
| ERHGCN (Zheng et al.) [44] | 88.79 | 90.56 |
| SFE-Net (Deng et al.) [45] | 91.94 | 92.49 |
| CR-GCN (Jia et al.) [46] | 93.46 | 94.78 |
| Our Approach (HCRC-SMV) | 93.88 | 94.26 |
| Our Approach (HCRC-CGEL) | 94.93 | 95.09 |
| Dataset | RF | KNN | SVM | HCRC-SMV | HCRC-CGEL |
|---|---|---|---|---|---|
| SEED IV 1 | 91.64 | 84.94 | 86.84 | 96.25 | 96.36 |
| SEED IV 2 | 91.31 | 84.53 | 87.67 | 96.80 | 96.97 |
| SEED IV 3 | 93.51 | 87.89 | 90.28 | 97.52 | 97.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Zhang, L. A Two-Step Framework to Recognize Emotion Using the Combinations of Adjacent Frequency Bands of EEG. Appl. Sci. 2023, 13, 1954. https://doi.org/10.3390/app13031954
Zhang Z, Zhang L. A Two-Step Framework to Recognize Emotion Using the Combinations of Adjacent Frequency Bands of EEG. Applied Sciences. 2023; 13(3):1954. https://doi.org/10.3390/app13031954
Chicago/Turabian StyleZhang, Zhipeng, and Liyi Zhang. 2023. "A Two-Step Framework to Recognize Emotion Using the Combinations of Adjacent Frequency Bands of EEG" Applied Sciences 13, no. 3: 1954. https://doi.org/10.3390/app13031954