1. Introduction
Cooperative multi-agent planning involves coordinating the actions of multiple agents with a common objective and a willingness to work together towards a shared goal. While this type of planning can be less complex than non-cooperative planning, where agents may have conflicting goals or limited communication, it still requires careful coordination and consideration of the actions and capabilities of each agent. The number of possible combinations of actions that each agent can take can still grow exponentially with the number of agents. In addition, the environment in which the agents are operating may be dynamic and subject to change, requiring the plan to be flexible and adaptable.
All these challenges of cooperative multi-agent planning render the problem intractable for most interesting problems, such as warehouse commissioning. In a warehouse setting, there may be multiple agents with different capabilities and resources, working in a dynamic environment with constantly changing demands and constraints. Coordinating the actions of these agents to efficiently complete tasks can be a complex and computationally intensive task. Traditional optimization methods may not scale well to these types of problems, and even with advanced algorithms, finding an optimal solution may be impractical, due to the time and computational resources required. As a result, finding effective approaches to cooperative multi-agent planning in warehouse commissioning, and other similar problems, is an active area of research.
In this paper, we aimed to improve the scalability of cooperative multi-agent planning using online planning. Online planning involves making decisions and taking actions in real-time, as new information becomes available, rather than solving the problem in advance. This can be particularly useful in dynamic environments, where the problem may change rapidly, or in problems with large state spaces, where the computational cost of solving the problem in advance may be prohibitive. Monte Carlo Tree Search (MCTS) is one of the well-known online planning algorithms for complex problems. MCTS does not require a full model of the process. Instead, a black-box simulator, the definition of state, and action space is enough for MCTS.
The MCTS algorithm plans over the joint actions of agents. The joint action set is constructed as the Cartesian product of the actions of agents. The planning algorithm calculates a single joint action for the given state. Agents execute the assigned actions independently. Although this approach works well, it creates an exponential increase in the state and action space of the problem. To reduce this exponential increase, we propose using decoupled planning. When the MCTS algorithm is used as a planning algorithm, we call it decoupled MCTS. In decoupled MCTS, every agent plans independently, but the same joint reward of the simulation is used. This approach results in a linear increase in state and action space but suffers from local optimum results [
1]. In our experiments, we showed that this approach achieved reasonable performance, compared to the baseline methods such as MCTS over joint actions.
When decoupled MCTS uses deterministic action selection policy in cooperative problems, the action synchronization problem occurs. This is due to the propagation of the same reward value for each agent. Although decoupled MCTS is widely used in regard to general game-playing problems [
2,
3,
4,
5,
6,
7], they do not report such a problem, even for cooperative games. In cooperative problems, each decoupled agent chooses an individual action, then, these actions are combined and executed for the problem and, finally, a reward is taken. This reward updates all agents’ actions, but these updated actions constitute only one of the combinations of all agents’ actions. This combination has the same statistics. If a deterministic action selection policy is used, the actions of that combination are chosen together since they have the same statistics. To remedy this problem, we propose to use stochastic action selection policies where the action selection for each agent is a result of a stochastic process. We evaluated different stochastic action selection policies on different problems and showed that
-greedy had the best performance for most of the problems.
We also identified a miscoordination problem in decoupled MCTS planning. When the agents do not coordinate their selection of actions, their performance decreases depending on the problem. This is common, especially for problems having penalties for miscoordination. We propose a combination method on top of decoupled MCTS. After the decoupled MCTS, a centralized MCTS search tree is constructed using the individual action evaluations of decoupled MCTS. Since the construction of all possible joint actions is intractable, we generate a subset of joint actions. The joint actions are chosen based on the statistics of individual actions constituting the joint action. We showed that this method improves the performance of decoupled MCTS when the search is not shallow.
We compared our proposed method with the state-of-the-art decoupled planning method [
8] from the literature. We showed that our method outperformed it with a performance improvement of more than 10% in warehouse commissioning problems. We also report that our method is easy to generalize to all sets of multi-agent planning problems because it does not require a greedy algorithm to represent the other agents’ behaviors.
The contributions of the paper can be summarized as follows:
We present a unique problem in decoupled MCTS planning that occurs when deterministic action selection policies are used and propose to use stochastic action selection policies to solve it.
We present the coordination problem in decoupled MCTS and propose to combine the evaluation of individual actions to plan over joint actions.
We analyze different cooperative problems and show the limitations of decoupled MCTS when a combination strategy is used.
In
Section 2 we provide a short survey of the literature by summarizing the work done on the different aspects of multi-agent planning. We present the problem description in
Section 3. In
Section 4, we provide a brief background on Monte Carlo Tree Search. We present the proposed decoupled planning approach in
Section 5. In
Section 6, we show the results of the experiments in different settings. Finally, we provide the conclusions in
Section 7.
2. Related Work
There are two main issues in multi-agent planning; coordination and the
curse of dimensionality. The coordination problem arises when agents execute actions without the knowledge of other agents. In literature, there are three main approaches to handle the coordination problem; coordination-free, coordination-based, and explicit coordination [
9]. Coordination-free methods just ignore the problem and assume that the optimal joint action is unique. Coordination-based approaches use the coordination graph to decompose the value function over agents. The value function calculates an expected cumulative reward of the joint state. Explicit coordination mechanisms generally use a social convention or communication to determine a global ordering of agents and their actions [
10]. Our method used a coordination-free approach, where we assumed that the optimal joint action was unique.
The curse of dimensionality problem results from the Cartesian product of the action sets and state sets of agents. Goldman and Zilberstein categorized the cooperative decentralized planning problems in terms of model specializations, and communications [
11]. They showed that Decentralized Partially Observable Markov Decision Processes (Dec-POMDP) with independent observation and transition functions have NP-complete complexity and are a lot simpler than the original Dec-POMDP model (NExp-Complete [
12]). Even further specializations, such as having a single goal state and uniform cost, reduce the complexity to P-complete [
13]. They also showed that having direct communication between agents did not change the complexity class of decision processes. The decision–theoretic model of the problem targeted in this work was the Multi-agent Markov Decision Process (MMDP). The complexity of the MMDP is the same as MDP, except for the exponential increase in the action and state space. MMDP problems have the
curse of dimensionality due to the number of agents. Therefore, we attacked the
curse of dimensionality problem by representing every agent as an independent planner. However, representing every agent as an independent planner required a special mechanism to solve the coordination problem [
1,
14].
Lauer and Riedmiller presented a decentralized reinforcement learning algorithm for deterministic multi-agent domains [
15] where the coordination problem was solved using a special mechanism. The algorithm made use of the deterministic nature of the problem, such that agents could infer other agents’ actions using the next state and reward that was observable. However, every agent iteratively improved its policy and achieved coordination via updating its policy only in the case of improvement. That eliminated the accumulation of two or more actions having the same expected sum of rewards, and, therefore, policies chose one of the equilibrium points and solved the coordination problem. Peshkin et al. proposed another method for a decentralized policy search algorithm for cooperative multi-agent problems [
16]. They assumed that agents had local policies that mapped the local states of the agents to the actions. They showed that a decentralized policy search could learn local optimal policies using the gradient descent algorithm.
Gronauer et al. presented the challenges of multi-agent problems in the deep reinforcement learning domain [
17]. They listed non-stationarity and coordination under the distributed training of cooperative problems. However, these challenges are also valid for online planning methods, because they use the same mathematical formalism [
18]. The value-based reinforcement learning methods address these challenges by summarizing the effect of other agents [
19,
20]. Another line of research uses a coordination graph [
21] to decouple the agents and build a new formalism to describe the
influence of agents to each other [
22]. In addition to the multi-agent research, there are single-agent approaches that reduced the action complexity by converting the problem into a multi-agent one and achieved comparable performances [
23,
24].
There are methods based on Monte Carlo Tree Search (MCTS) that model agents independently in distributed planning. Best et al. presented a method for active robot perception, where each robot shares its search tree and the agent calculates a distribution over action sequences [
25]. Their formalism was limited, compared to ours, as the policies were represented as action sequences. Amini et al. presented a similar method for partially observable problems where the agents were modeled over joint action spaces [
26]. This made their method intractable, due to the exponential action space. Czechowski et al. presented a decoupled MCTS method that uses alternate maximization over independent search trees [
27]. Although their method was guaranteed to converge, the agent policies were modeled with a neural network that was computationally expensive to train.
Another line of work that uses decoupled planning comes from the general game-playing literature. Finnsson and et al. used decoupled UCT for general game playing and won the General Game Playing tournament twice [
2]. In game-playing, the planner models the opponent as another independent learner. Since agents get different rewards based on the state of the game, using deterministic action selection policies does not face the action synchronization problem. Decoupled planning was also applied to simultaneous move games where the agents take action without seeing the other agents’ actions [
4,
6,
7,
28]. They showed that different action selection policies had different performances for different games. Shafiei and et al. showed that UCB1-based decoupled planning was not guaranteed to converge to Nash-equilibrium [
3] when used for simultaneous move games. Since in our decoupled planning setting, agents took actions without seeing the other agents’ actions, our problem formulation was similar to simultaneous move games. This was also the main motivation of this paper to use decoupled planning for cooperative multi-agent problems. There are different applications of decoupled planning in different domains [
25,
26,
29], but they do not report on the action synchronization problem.
3. Problem Description
Cooperative multi-agent planning problems have different formulations. In this paper, we aimed to solve problems modeled as Multi-agent Markov Decision Process (MMDP). MMDPs are widely studied powerful representations for a class of problems where the next state only depends on the current state and the action of the agents.
Multi-Agent Markov Decision Process
Stochastic sequential decision-making problems can be modeled as Markov Decision Processes (MDPs). The MDP model defines the state space of the problem, available actions at every state, the probability of resulting states after executing an action, and the reward, given the current state, the next state, and the executed action. The solution to an MDP problem is called policy. Policies define state-action mapping. The optimal policy has the maximum expected cumulative reward given the MDP model. Calculating a policy for problems having huge state and action spaces is infeasible. The online planning approach solves this problem by only calculating the next most successful action. It evaluates only a subset of state and action spaces up to a limited time step by sampling actions from the given state.
To be able to plan for multiple agents, the action set is redefined as the Cartesian product of every agent’s action set, and this is called the joint action set. The main problem with multi-agent planning is the exponential increase in the space of actions and states, due to the number of agents. The MDP problem with many agents is called Multi-agent MDP (MMDP). In MMDP formalization, it is assumed that all agents can see the full state, and planning is done by a centralized entity.
The formal definition of MMDP is 5-tuple where:
D is the set of agents,
S is the finite set of states,
A is the finite set of joint actions (),
T is the transition function which assigns probabilities for transitioning from one state to another given a joint action, and
R is the immediate reward function.
The online planning approach presented in this paper can be used for MMDP problems. However, it does not need the full MMDP definition. It is enough to have the generative model of the problem with state and action definitions. This makes a huge difference, because, for most of real-world problems, it is easy to define a black-box generative model without knowing or calculating the transition probabilities. For all of the problems we used in the experiments, we had a generative model, including for the warehouse commissioning problem.
5. Method
5.1. Overview
We generalized the decoupled-UCT [
2] method to a cooperative multi-agent setting and called it decoupled-MCTS. Decoupled-UCT has been successfully used in the general game-playing domain, but has not been studied in cooperative problems. We showed the limitations of the direct application of decoupled-UCT to cooperative problems. Our method improved the performance of the decoupled-UCT and addressed the issues that arise in cooperative settings.
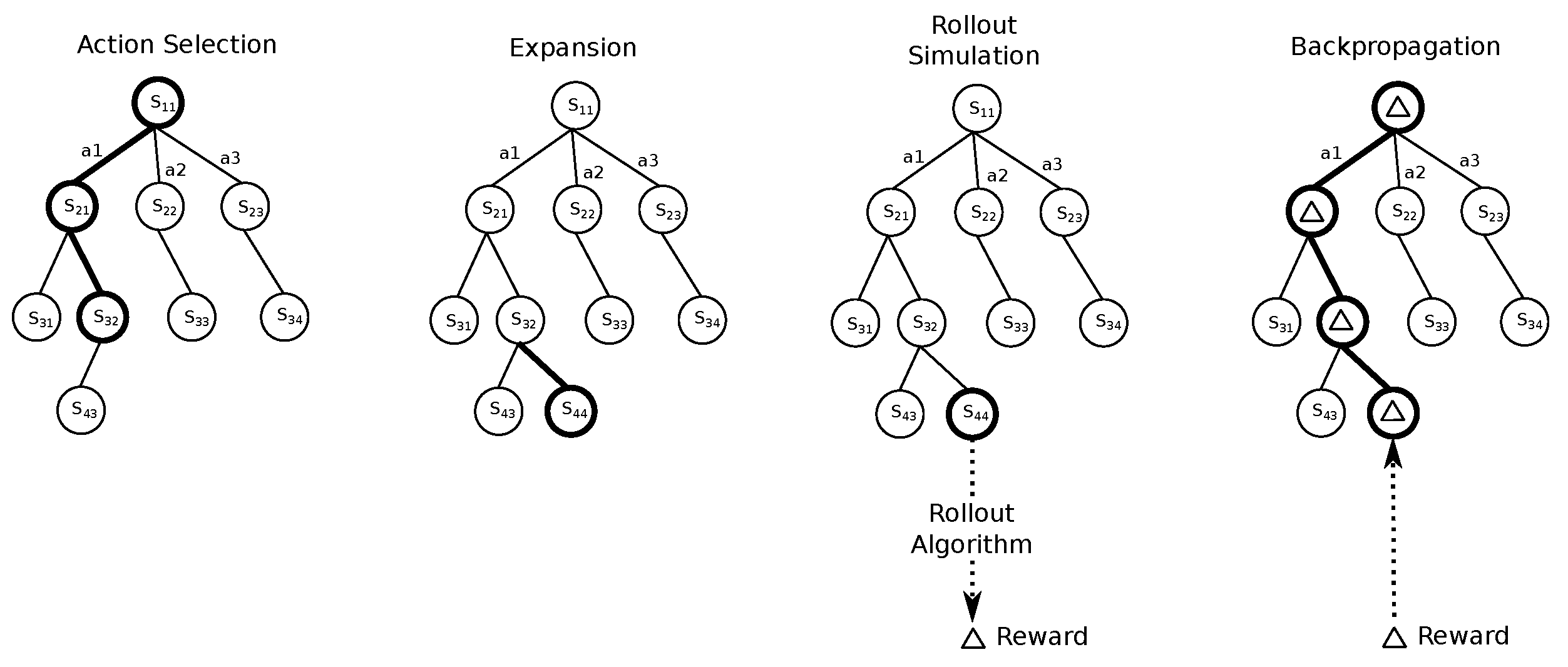
Monte Carlo Tree Search (MCTS) is an online planning method that evaluates the available actions starting from the current state using Monte Carlo simulations. When MCTS is used for Multi-agent Markov Decision Process (MMDP) problems, the search evaluates the cross-product of the sets of actions available to each agent. This is one of the main limitations of MCTS when applied to MMDP. Decoupled-MCTS aims to solve this by evaluating each agents’ set of actions separately. As seen in
Figure 2, in decoupled-MCTS, nodes have a set of actions for each agent, in contrast to MCTS, where nodes have a set of joint actions composed of cross-product of all agents’ actions. In the back-propagation step, all individual actions of agents that are selected at that simulation are updated with the same reward.
5.2. Decoupled-MCTS
In multi-agent planning, the complexity of the problem increases exponentially in terms of the number of agents. Decoupled-MCTS tackles this problem by planning for each agent separately. In the planning phase, each agent becomes the part of the environment from the perspective of the planner agent. All agents are both planner and also part of the environment. They collectively plan using the same simulation runs. In the beginning, each agent would be a noise to other agents, but as the agent converges to a behavior, each agent has a chance to adapt to other agents.
Each agent runs a single agent MCTS planning. In the general game-playing domain, this approach works well when the deterministic action selection algorithm is used [
2]. All agents get different rewards given the state for these problems. One common example would be zero-sum games, where at each state the sum of the agents’ rewards is 0. Although decoupled-MCTS is not the only method, it works well as it reduces the exponential complexity.
Cooperative multi-agent problem is a subset of the general game-playing problem. The main difference is that all agents share the same reward and aim to optimize the same performance. This difference has a big effect on the performance of decoupled-MCTS when deterministic action selection policy is used. Due to this limitation, we used stochastic action selection policies, which solve the action synchronization problem where statistics of first combinations of actions are fixed at the beginning (see
Section 5.2.1).
There are two possible representations for decoupled-MCTS: (1) single search tree and (2) separate search tree. Single search tree differs from single agent MCTS with the representation of actions. At each state node, we have the list of actions available to each agent with their respective statistics and next nodes, as seen in
Figure 2. At each action selection, the method selects an action for each agent separately using the statistics, but it expands and moves on the same tree as if it was a single agent MCTS. Separate search tree differs from single search tree by maintaining different search trees for each agent. We have a single agent MCTS search tree for each agent, but action selection and back-propagation is driven by the simulation shared by all agents, as seen in
Figure 3. The main advantage of separate search tree is distributed planning where each search tree can be distributed to different computation resource and exchange simulation data as required. Separate search trees also maintain different agent states relevant for Dec-MDP problems that is not in the scope of this paper. However, in this paper, we used the single search tree because we were able to fit search trees in memory and gain efficiency when we combined it to create a search tree over joint action space (see
Section 5).
At each planning step, decoupled-MCTS obtains the initial state and constructs a search tree starting from that state. The search tree construction is driven by the simulations and each simulation adds a new node. Nodes contain states, lists of actions and next nodes reachable from each action. Nodes also contain different statistics of the actions to use in an action selection algorithm. The main difference between MCTS and decoupled-MCTS is the representation of actions in search nodes. A decoupled-MCTS node has a list of actions for each agent with the relevant statistics. As a result of this change, decoupled-MCTS runs its selection and back-propagation steps for each agent on their action lists.
Decoupled-MCTS modifies the action selection and back-propagation steps of the MCTS algorithm. The Algorithm 1 presents the main planner that returns the selected set of actions for the given state. The root node is created at the beginning of the algorithm. At each simulation; a new node is added to the tree with
EXPAND algorithm, the simulation is run to termination with
ROLLOUT algorithm and when the simulation is terminated,
BACK-PROPAGATE algorithm updates the statistics of the actions selected during the expansion using the accumulated reward. Finally, the actions of agents having the maximum expected reward are returned.
| Algorithm 1 Decoupled Monte Carlo Tree Search |
Require: is the current state Ensure: is the list of actions function PLAN() for do end for for do end for return end function
|
The Algorithm 2 shows the expansion of the search tree until a leaf node is reached. The main difference of this algorithm from MCTS is that we select an action (
) for each agent using the statistics of the actions. The algorithm moves to the next node or leaf node by running the selected actions on the simulation. When a leaf node is reached a new node is created and connected to the leaf node. When the simulation is terminated, the back-propagation starts. The Algorithm 3 shows how the reward is back-propagated to the nodes that are visited during the current simulation. It starts from the leaf node and updates the statistics of the selected actions with rewards collected after that node. The same reward updates the selected actions of the agents at each node.
| Algorithm 2 EXPAND algorithm that traverses the search tree using the statistics of the nodes |
Require: is a node of search tree Ensure: is the leaf node reached by expanding the tree function EXPAND() while do for do end for end while return end function
|
| Algorithm 3 BACK-PROPAGATE algorithm that updates the value of the nodes traversed during the simulation |
Require: is the leaf node where back propagation starts Require: is reward collected as a result of rollout function BACKP-ROPAGATE() while do end while end function
|
5.2.1. Action Synchronization Problem
In decoupled-MCTS, if the action selection policy is deterministic, the initial selection of actions generates a limited number of possible combinations to be evaluated by the simulations. As the number of agents and the number of actions increase, the difference becomes larger. This is a huge limitation that hinders the performance of deterministic policies. We showed that the stochastic action selection policies outperformed the deterministic ones due to this problem.
We used a matrix game, the climbing reward structure of which is shown in
Figure 4 for illustrative purposes. There are two agents and each agent has three actions. In decoupled-MCTS, each agent has a table to keep the statistics of each action. Since the matrix game is a single-step planning problem, a table is used instead of a search tree. Note that the action selection is random until all actions are selected at least once. Let us assume that agent 1 chooses
,
, and
actions and agent 2 chooses
,
, and
for the first three simulations, respectively. In other words,
,
, and
action combinations are selected in the first three simulations. According to these selections, the action values are updated as follows:
,
,
,
,
, and
. Since each action has some statistics, the next actions are selected based on them. However, a problem arises due to the shared reward. The first selected combinations are synchronized such that their statistics are updated together. For example, when we use UCB1 deterministic action selection policy, agent 1 selects
and agent 2 selects
since they have the highest UCB1 values. After these actions are selected for some time, the UCB1 explores other actions; agent 1 chooses
and agent 2 chooses
since they have the second highest values. Finally, agent 1 explores
and agent 2 explores
. As is seen from the action selection pattern, the action combinations that are considered by decoupled-MCTS only consist of the first combinations that are created randomly. Therefore, for that problem, the algorithm only considers three joint action combinations (
,
, and
) out of nine possible combinations.
The action synchronization can affect performance in a limited way, depending on the reward structure of the problem. If some combinations of actions result in the same reward, the UCB1 (or any deterministic action selection policy) can randomize the action selection for actions having the same statistics. It can arise directly from the regularities in the reward structure (similar to the attainable matrix game in
Figure 4) or from a specific exploration term that equalizes the UCB1 values of the actions at some stage. In the experiments section, we show that the effect of regularities and exploration term on the performance was limited, and deterministic action selection policies performed worse, compared to stochastic action selection policies.
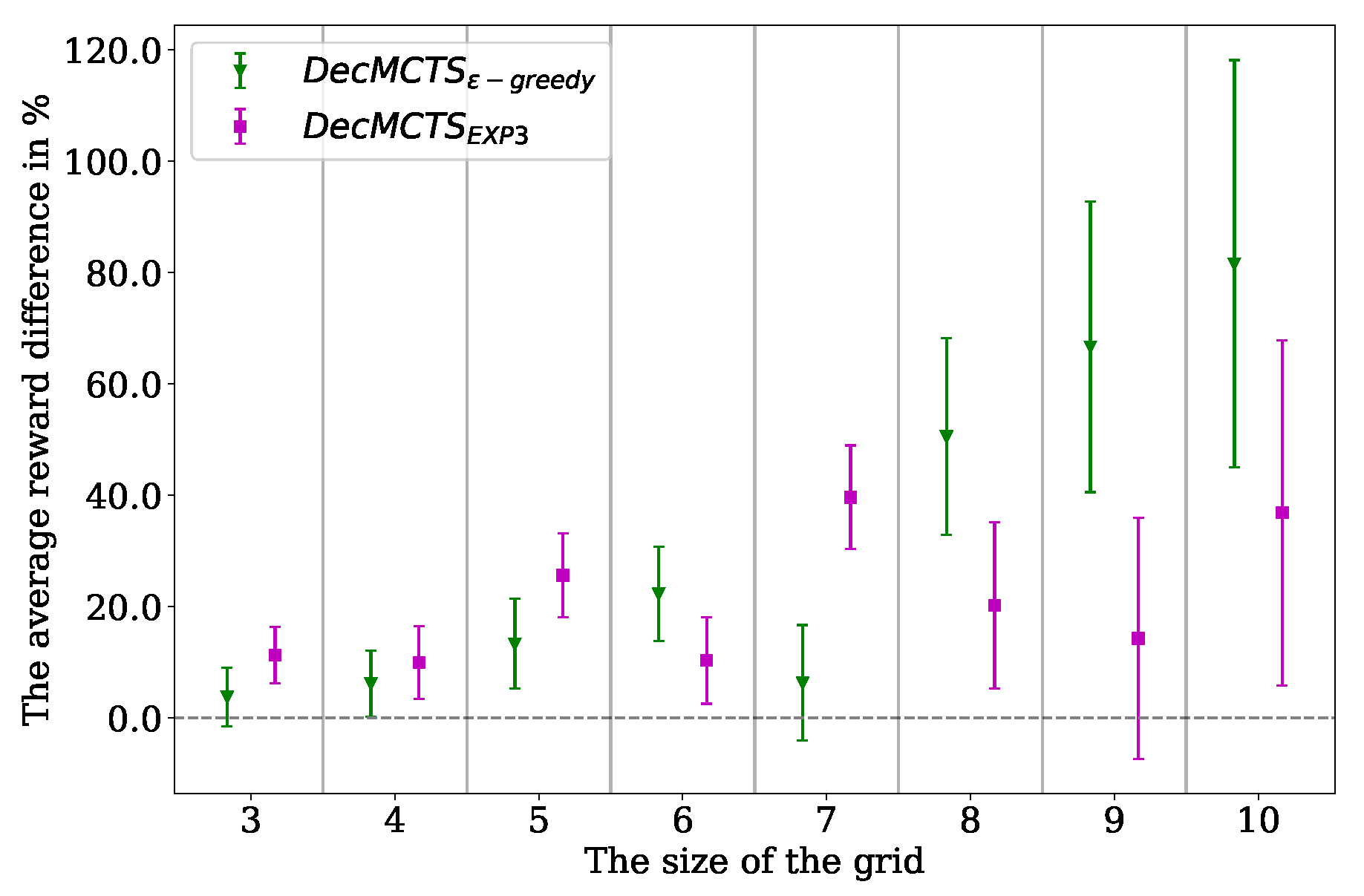
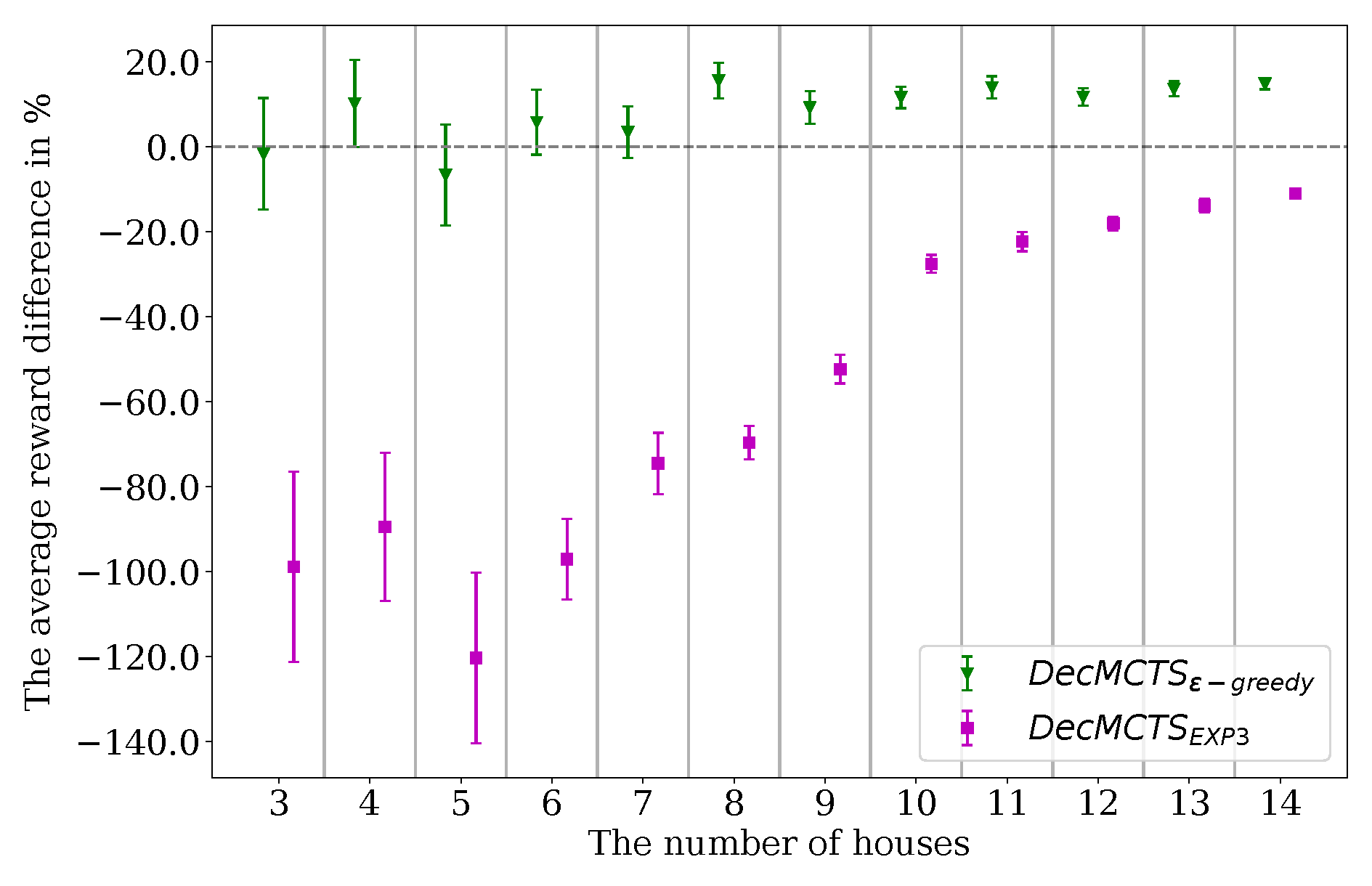
We evaluated two well-known stochastic selection policies: -greedy and EXP3 in the experiments. Although -greedy is simple and lacks good analytical regret boundaries, it performed better than EXP3 in most of the experiments. We observed that the weight iteration step of EXP3 grew boundlessly and equalized all weights at a very high value in our experiments. We normalized and set a maximum weight value to address this issue, but EXP3 was still behind of -greedy. We also found it harder to optimize the exploration parameter of EXP3 compared to -greedy.
5.2.2. Coordination Problem
When using centralized planning with joint actions, the selected joint action ensures the coordination of the actions. However, in the case of decoupled planning, where each agent evaluates its own actions, there is no mechanism to ensure the coordination of actions. Considering the problem, having the attainable reward structure given in
Figure 4, the expected values of actions
and
are the same for agent 1, and, similarly, the expected values of actions
and
are the same for agent 2 under uniform action selection. However, if their selection of actions is not coordinated, they may get the reward of 0, due to the selection of
or
action combinations.
Considering the problem having the penalty reward structure shown in
Figure 4, the uncoordinated selection may be penalized. In these cases, the explorations on the action space make these actions unfavorable since their expected values are very low, due to the high penalty values.
This coordination problem is studied in [
1] in the independent reinforcement learning domain. Decoupled-MCTS handles each action selection at each node as an independent multi-armed bandit problem. Therefore, the results derived for game matrices in [
1] are valid for the action selection in decoupled-MCTS. They show that an exploration strategy with a gradually increasing exploitation converges to an equilibrium. However, the independent learners approach suffers from miscoordination in high penalty cases [
38]. In this paper, we propose an improvement on decoupled-MCTS to address the coordination problem in
Section 5.3. The method solved the miscoordination by creating a single search tree over a subset of joint actions. The statistics collected in decoupled-MCTS were used for the pruning of joint actions.
5.3. Combined Decoupled Monte Carlo Tree Search
In decoupled-MCTS, we have a coordination problem where agents take actions without knowing which actions were taken by their teammates. Although we have this information, we do not keep or use it in the planning stage because we want to reduce the complexity of the planning. To solve this problem, we propose an improvement over the decoupled-MCTS method. We used decoupled planning to reduce the number of actions available at each node. Once, we completed the decoupled planning, we had good estimations of individual actions of agents. We used this information to construct a search tree over joint actions, but we did not construct all joint actions that would be intractable. We chose joint actions based on the value calculated in decoupled-MCTS planning. Then, we ran another planning stage on this combined search tree using UCT, but we did not add any new nodes to the tree. We were walking on the tree and updating the values of the nodes using rewards collected from new simulation runs. In this way, we improved the performance of overall planning by fine-tuning the joint action evaluations which we might have missed during decoupled planning.
In
Figure 5, we show how the decoupled-MCTS search tree was used to construct one new search tree having joint actions. In this simple example, we assumed that nodes were created by running five simulations (
sum shows the sum of the collected reward and
n shows the number of visits). There were two agents with actions:
,
, and
,
. If we chose actions based on the current decoupled evaluations, agent 1 would choose
and agent 2 would choose
.
The method uses the statistics from decoupled-MCTS to decide how actions are going to be selected for combining. We sorted individual actions by their selected statistics and chose them to be part of a joint action one by one randomly. This reduced the complexity such that we did not need to construct all possible joint actions. If we used the average cumulative reward as a statistic, in
Figure 5, we chose
and
as the first candidate. Then, to generate the next joint action, we replaced
with
and kept the
as it is. For that example, we randomly chose Agent 2 to update. After the joint actions were selected we calculated their statistics by summing the cumulative rewards of individual actions and dividing that by the total visits to individual actions. The joint action
,
has
and
,
had
as the cumulative reward. This ensured that the evaluations of individual actions were used to estimate the cumulative reward of the joint action. We set the visit count to 1. In this way, we could incorporate the statistics of individual actions to preset the initial action selection. However, because we set the visit count to 1, we gave very small weight to our initial evaluation.
We limited the number of selected joint actions by the sum of the agents’ actions to keep the total number the same as the decoupled one. For example, if one agent had 4 different actions and another agent had 3 different actions, we chose 7 different joint actions from 12 available joint actions. For the example in
Figure 5, we chose two joint actions instead of four for illustrative purposes.
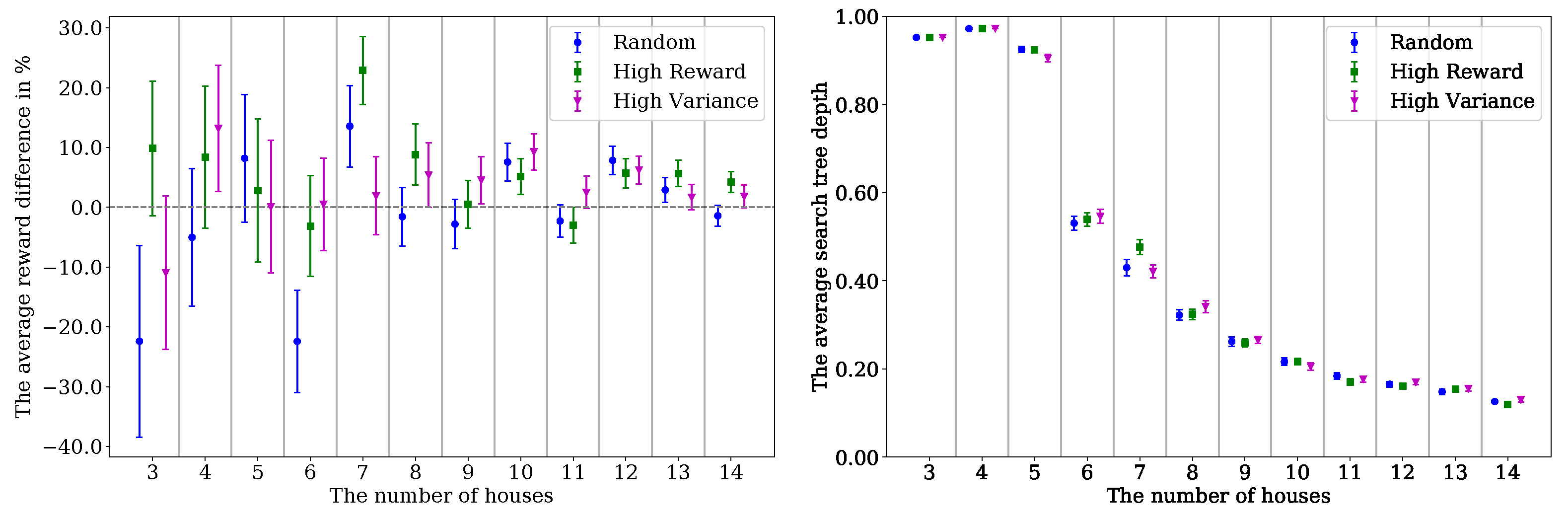
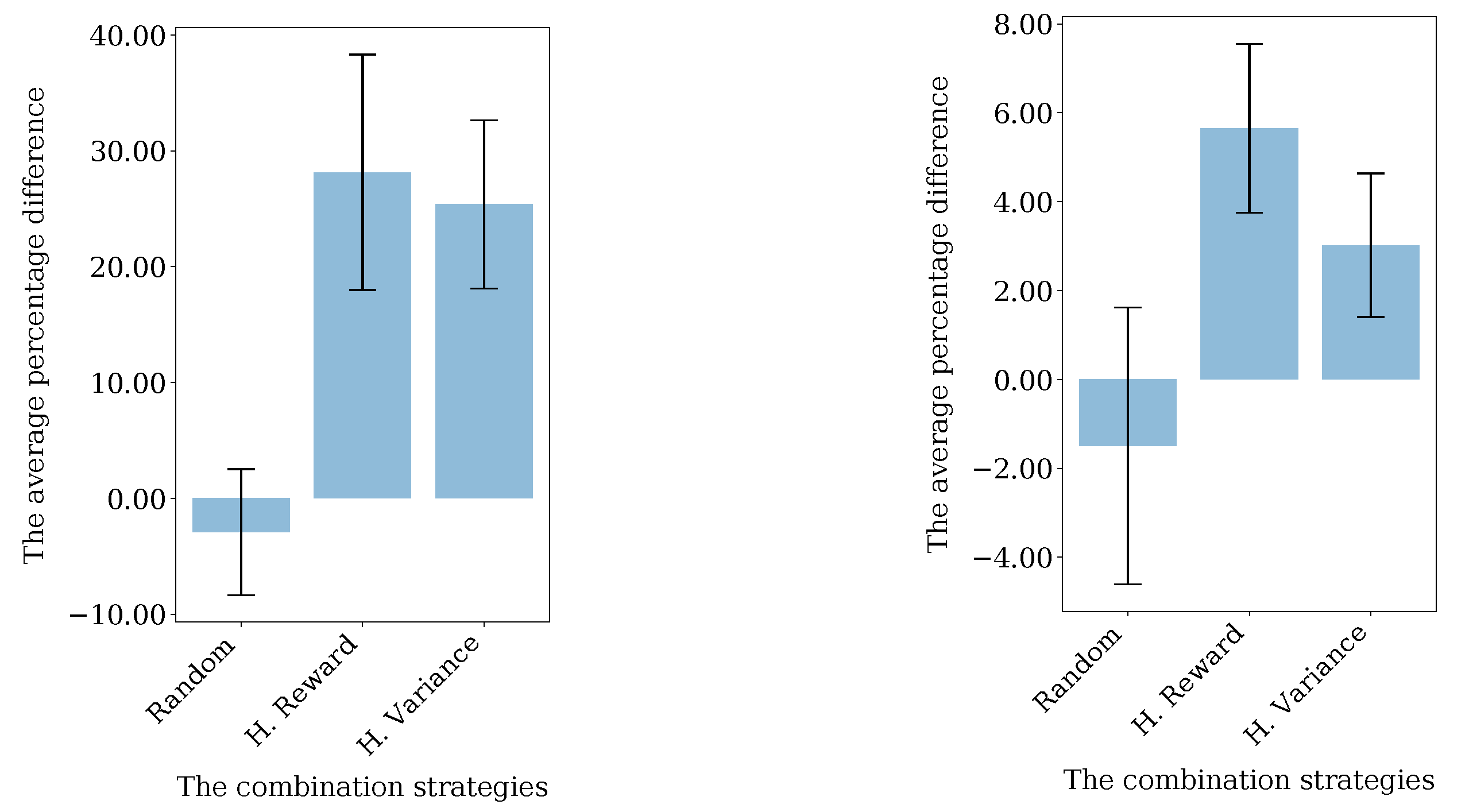
Action Combination Strategies
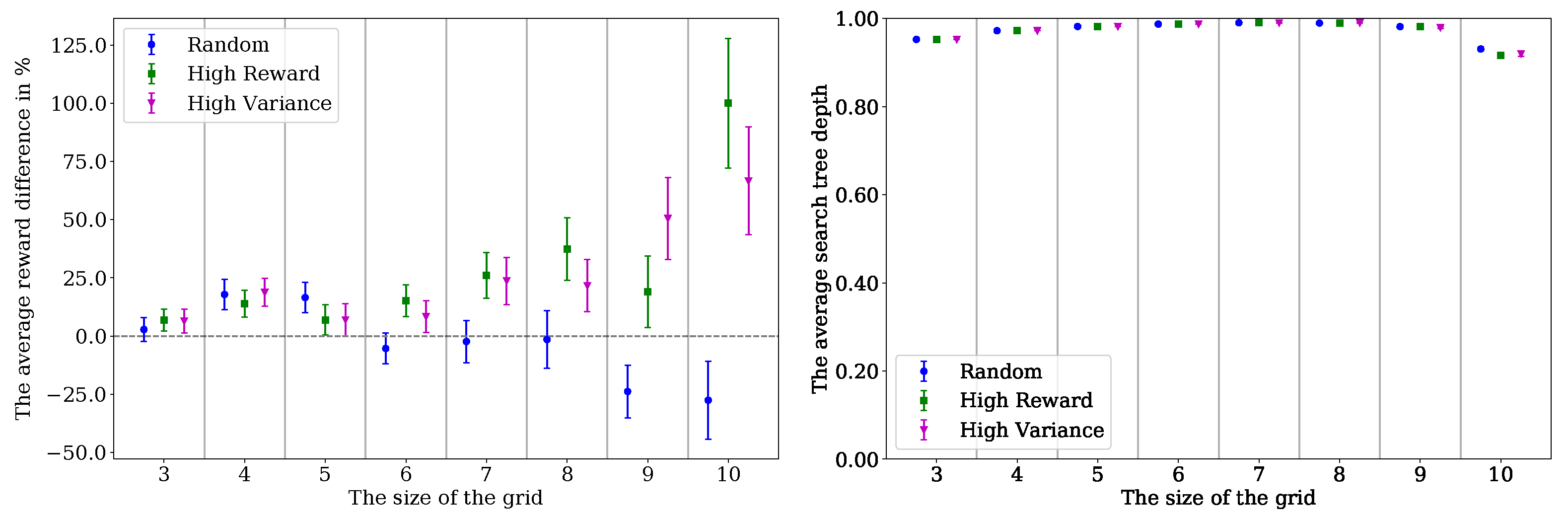
When we collected statistics for individual actions, we used this data to select joint actions. The statistics of the actions could be used in many ways. We proposed two strategies for the combination of joint actions: (1) using the reward, and (2) using the variance of reward. The strategy of using actions with high expected rewards aimed to reevaluate the best actions to reduce the effect of miscalculation. This would reduce the uncertainty introduced due to miscoordination. However, it would not fix the problem of actions severely penalized due to miscoordination. The strategy of using actions with high reward variance addressed that problem. If an action was affected by miscoordination, we expected its variance to be higher than others. When we constructed a joint action from actions with high variance, we gave a new chance to these actions to be evaluated without the uncertainty introduced by other agents. In
Section 6.2, we evaluate these strategies with different problems.
7. Conclusions
We propose a new decoupled planning algorithm (decoupled-MCTS) for cooperative multi-agent planning problems. The proposed method improves the scalability of Monte Carlo Tree Search by decoupling the agents in online planning. Decoupled-MCTS generalizes the decoupled-UCT algorithm to cooperative multi-agent planning. Although decoupled-UCT is used in cooperative problems, it is used without a reference to its limitations.
We present the action synchronization problem in decoupled-MCTS approaches for cooperative problems. When the action selection policy of MCTS is deterministic, a limited number of action combinations are evaluated. We address this issue by proposing stochastic action selection policies. We showed that -greedy action selection policy has the best performance for different problems, such as matrix games and MMDP problems.
We present miscoordination as another limitation of decoupled-MCTS. It is best illustrated when there is a penalty if the agents do not coordinate their actions. We propose a combination approach to address the coordination problem. We analyzed and showed when our combination method was most useful. The combined method improved the decoupled-MCTS significantly when the search tree was not shallow.
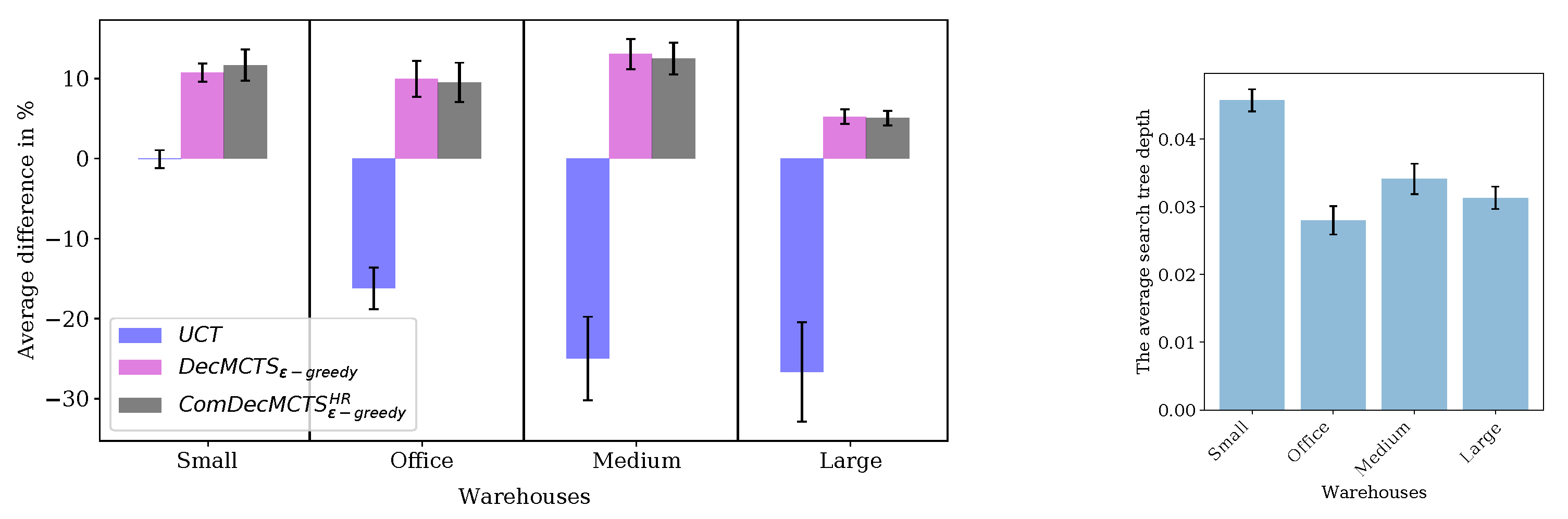
We compared our method with another decoupled task allocation method in the warehouse commissioning problem. Our method performed over 10% percent better than the existing method. Our method does not need a greedy rollout algorithm to represent the behaviors of other agents. This increases the applicability of our method.
In this study, we focused on the performance comparison of different stochastic selection policies in different types of problems and reported significant improvements. However, we showed an empirical evaluation of decoupled-MCTS and its combined version. In the future, we aim to further investigate the selection policies in terms of Nash-equilibrium.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}