1. Introduction
Earthquakes are considered one of the most dangerous natural disasters, as they can occur without warning. The ratio of deaths caused by earthquakes is above half more than that of other natural disasters [
1]. According to the World Health Organization (WHO), earthquakes killed 750,000 people worldwide between 1998 and 2017 [
1]. During this period, more than 125 million people were affected by tremors, meaning that they were either injured or lost their houses and valuable properties. In 2020, Americans lost USD 4.4 billion, due to catastrophic earthquakes. Seismic activity prediction is the optimal technique for avoiding earthquake-related economic and human tragedies.
Machine learning (ML) approaches play a pivotal role in prediction and forecasting in various fields, including different disasters, such as floods, earthquakes, and landslides [
2,
3,
4,
5,
6,
7,
8]. Significant research has been conducted, using these techniques, to reduce the impact of the aforementioned disasters [
3,
6,
7,
9]. These studies have utilized a variety of machine learning approaches, including artificial neural network [
5], support vector machine [
9], random forest [
10], and convolutional neural network [
6]. In this work, we consider the seismic activity prediction problem as a binary classification problem, and present a deep neural network model for predicting the occurrence or otherwise of significant seismic activity.
Asim et al. [
11] used genetic programming and Ada-boost methods to classify seismic activities in the California region. The authors applied the mentioned methods on only one dataset, and reported accuracy of 78%. An artificial neural network was implemented by Oktarina et al. [
5] for earthquake prediction in the Indonesian region, and it calculated the mean square error. Jena et al. [
6] studied the Palu region in Indonesia, to identify earthquake-prone areas using cluster analysis techniques. The authors used silhouette clustering, pure locational clustering based on hierarchical clustering analysis, and convolutional neural networks. The approach to the selected region achieved 89% accuracy. Majhi et al. [
12] used a moth flame optimized functional link with an artificial neural network to predict seismic magnitude on earthquake catalog data, by considering the mean square error as a metric. Zhang et al. [
13] discussed the precursory pattern-based feature extraction method for earthquake prediction in China. The authors used an artificial neural network for earthquake prediction, and reported accuracy of 80%. A different approach was used by Aslam et al. [
14] in the northern areas of Pakistan, for the prediction of seismic activity. The authors implemented the support vector machine and hybrid neural network on the targeted area, to predict earthquake occurrence for a period of one month: the maximum accuracy of their models was 79% on one dataset. Al Banna et al. [
15] advocated the use of long short-term memory network structure for predicting earthquakes in the Bangladesh region: the authors used hyper-parameters optimization, as well as L1 and L2 regularization, to achieve maximum accuracy of 76%.
From the current literature, we identified that although machine learning models are used to predict earthquake occurrence to varying degree of success, the models mostly rely on data from one region, and there is no generalization in the proposed models. Generalization refers to the concept of the effectiveness (such as higher accuracy, low mean squared error) of a given machine learning model at learning from the given data, and effectively applying the learning to other datasets. The machine learning models proposed for earthquake prediction are not generalized, i.e., the proposed models performed well (to a certain degree) on the given datasets, but their performances on other datasets were either not evaluated or were found lacking: that is to say, the models could not be applied to other datasets/regions.
In this work, a novel methodology for prediction of earthquakes using feature engineering and a deep-learning-based technique is proposed. First, we collected the data for three regions: California, Chile, and Hindukush. The data collection was followed by data cleaning and pre-processing. New features were calculated based on the various seismic laws (such as the Gutenberg–Richter law). The features included the seismic rate of changes, foreshock frequencies, the release of seismic energy, the total time of recurrence, the maximum/minimum relevance, and redundancy. These features were extracted and used as input for our deep learning model. Afterwards, a deep-neural-network-based architecture was proposed, which was evaluated against standard benchmark algorithms, using accuracy, precision, recall, and F1-score.
Unlike previous works, we conducted Out of Sample testing, to validate the generality of the proposed technique. Out of Sample testing means that the model is trained on one dataset, but is evaluated on a different dataset. A better performance on an Out of Sample test reflects that the model is generalized, and can be used for datasets other than the one on which it was trained. The results showed that the proposed deep neural network was more accurate than the other machine learning approaches. This research will aid risk and uncertainty mitigation, for better decision-making regarding earthquake prediction, in various ways.
The rest of this paper is organized in the following manner:
Section 2 presents the proposed methodology, including the dataset, feature engineering, the proposed deep neural network architecture, the benchmark algorithms, and the evaluation metrics; the results are presented and discussed in
Section 3;
Section 4 concludes the work.
2. Methodology
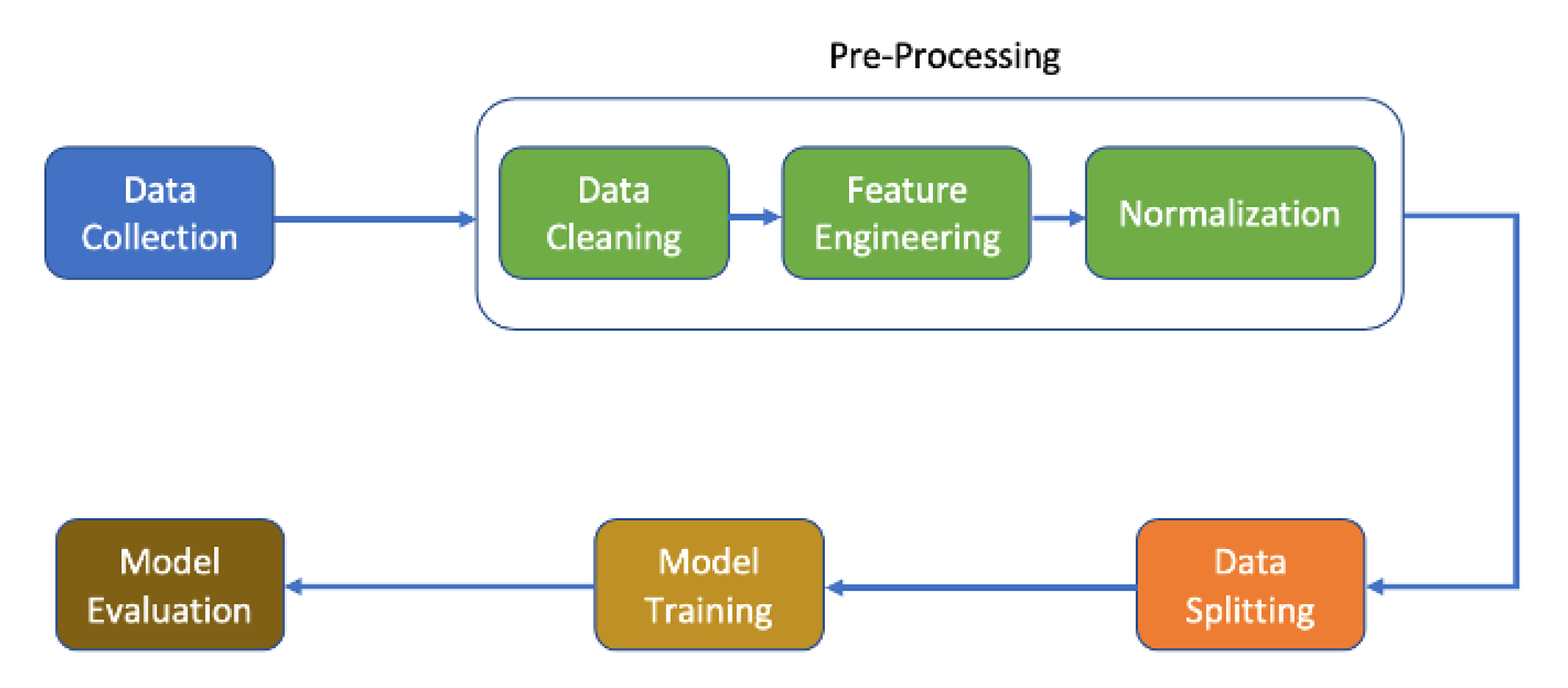
Figure 1 illustrates the workflow of the conducted research. As a first step, the data were collected from various sources, after which the pre-processing was performed. The pre-processing steps included data cleaning, feature engineering, and data normalization. Afterwards, the data were split into training and test sets, and model training was carried out on the training set. Once the training had been performed, and satisfactory results had been achieved on the training set, the model was evaluated on the test data based on the evaluation criterion. In the following, we explain the various phases in detail.
The steps of the proposed methodology are described as follows.
2.1. Data Collection
Earthquakes produces seismic waves, which are recorded in the form of seismograms. Seismograms represent ground motion at a specific location, as a function of time. A phase in seismic waves is the arrival pattern, which is observed in the seismogram: of particular interest are P-waves and S-waves [
16]. A seismogram also records the size of an earthquake at its source location (called the epicenter), which is generally referred to as magnitude. Magnitude is a logarithmic measure [
16].
Numerous techniques of data acquisition, analysis and filtering in time, frequency, and scale domains exist in the literature [
17,
18]. In this study, however, we did not use the raw seismograms data: instead, we selected the already-available digital data for three of the most active zones in the globe, for earthquake occurrences. The original seismic activities data were downloaded, from the information provided in the respective articles [
9,
19,
20]. The downloaded data contained the
magnitude data. As these three datasets had been used in the existing literature [
9,
19,
20], we also selected the same, for a meaningful comparison. Due to space constraint, the process of data collection from the various sources cannot be explained here, and the reader is referred to the respective sources, which are available at [
9,
19,
20].
Table 1 provides an overview of each dataset.
2.2. Pre-Processing
After obtaining the data from various sources, the data cleaning and feature engineering steps were performed as follows.
2.2.1. Data Cleaning
After obtaining the raw data from the original sources (please refer to [
9,
19,
20]), the data cleaning step was performed. In the data cleaning, the dataset was reviewed for missing values and invalid values. Once it had been ascertained that there were no missing/invalid values, the data were reviewed for cut-off magnitude. The threshold for cut-off magnitude is dependent on the density of the instrumentation in a particular region [
9]. As discussed in Asim et al. [
9], the cut-off magnitude is
for the California region,
for Chile, and
for Hindukush. Weimer and Wyess [
21] have discussed various methodologies for determining the cut-off magnitude; however, in line with the existing literature, we used the Gutenberg–Richter law [
9]. The determination of the magnitude of completeness was independent of the Gutenberg–Richter law.
2.2.2. Feature Engineering
The process of extracting new attributes, characteristics, and properties from data is called feature engineering. The main goal of feature engineering is to design/create new features that can be used to improve the performance of the model. The features are engineered based on seismic activities indicators. The features are considered from the available literature. The detailed description about various engineered features is given as follows.
Gutenberg–Richter Law
The Gutenberg–Richter law describes the relationship between the magnitude and the number of earthquakes in a particular region [
22]. The Gutenberg–Richter law states that earthquake magnitudes are distributed exponentially as:
Note that N represents the number of earthquakes of magnitudes of at least m, such that , is the threshold magnitude of completeness, b is referred to as the scaling parameter, and a is a constant.
Two different methods—least square regression analysis (
) and maximum likelihood (
)—were used to calculate the values of
a and
b. We used both sets of techniques to identify the values of
a and
b, and we used these values as our features for the machine learning models. The values of
a and
b were calculated using least square regression, and the maximum likelihood criterion was calculated using Equations (
2)–(
5) [
23].
Mean of Earthquake Magnitude
The mean of the earthquake magnitude was the mean value of
n events, as shown in Equation (
6). Prior to any large-scale earthquake, the seismic magnitude is usually rising.
Standard Deviation of b’s Value
The standard deviation of
b’s value (
) was established by Shi and Bolt [
24], and is calculated as shown in Equation (
7):
Recurrence Time
The time between two magnitudes of earthquakes equal to or greater than
(
being the value of fixed magnitude) is called the total recurrence time, and is calculated using Equation (
8) [
9]; it is also called the probabilistic recurrence time (
).
Note that T is the length of total time under consideration.
Seismic Rate of Change
In a region, the increase and decrease seismic behavior for two different time intervals is called the Seismic Rate of Change. We calculated the decrease in seismic behavior, using Equation (
9) [
25]:
where
n is the number of events, the duration of time is
t, and the observed events are
.
To calculate the increase in seismic behavior, we used Equation (
10) [
26]:
where
and
are the seismic rates for two difference intervals,
and
represent the standard deviation, and
and
represent the seismic events observed in the two intervals.
Rate of Square Root of Seismic Energy Released
The rate of the square root of seismic energy released over time
T was calculated as shown in Equation (
11):
In cases where the release of seismic energy is not possible for a prolonged duration, the abrupt accumulated energy release may result in major seismic activity [
27].
Elapsed Time for Last n Seismic Activities
The
n number of seismic events to have occurred before
, as represented in Equation (
12) in days, is elapsed time:
Maximum Earthquake Magnitude in the Last 7 Days
This feature is considered an important parameter of seismic events: it means the maximum magnitude recorded in the last 7 days. The mathematical representation is given in Equation (
13):
Note that is the magnitude of the earthquake observed on day t.
Earthquake Magnitude Deficit
The earthquake magnitude deficit is defined as the difference between the maximum observed magnitude and the maximum possible magnitude defined by
from the Gutenberg–Richter relationship, and is formulated as shown in Equation (
14). Note that
and
are the parameters of the Gutenberg–Richter relationship, and
represents
2.2.3. Normalization
Data normalization for machine learning models is an essential part of the pre-processing. Normalization is transforming the numeric values to a common scale without wrenching differences from the range of values. The calculated features were normalized using the MinMaxScaler from the scikit-learn library.
Pre-processing is a mandatory step, which is known to have a significant impact on the performance and generalizability of machine learning models [
28]: these steps are, as such, required, and cannot be ignored.
2.3. Data Splitting
In machine learning, data splitting is normally utilized for splitting the dataset into training and test sets. Using the “Train/Test split” from the scikit-learn, the datasets were divided into two parts, with 75% of the data being used for training, while the remaining 25% was used for testing.
2.4. The Proposed Deep Neural Network Architecture
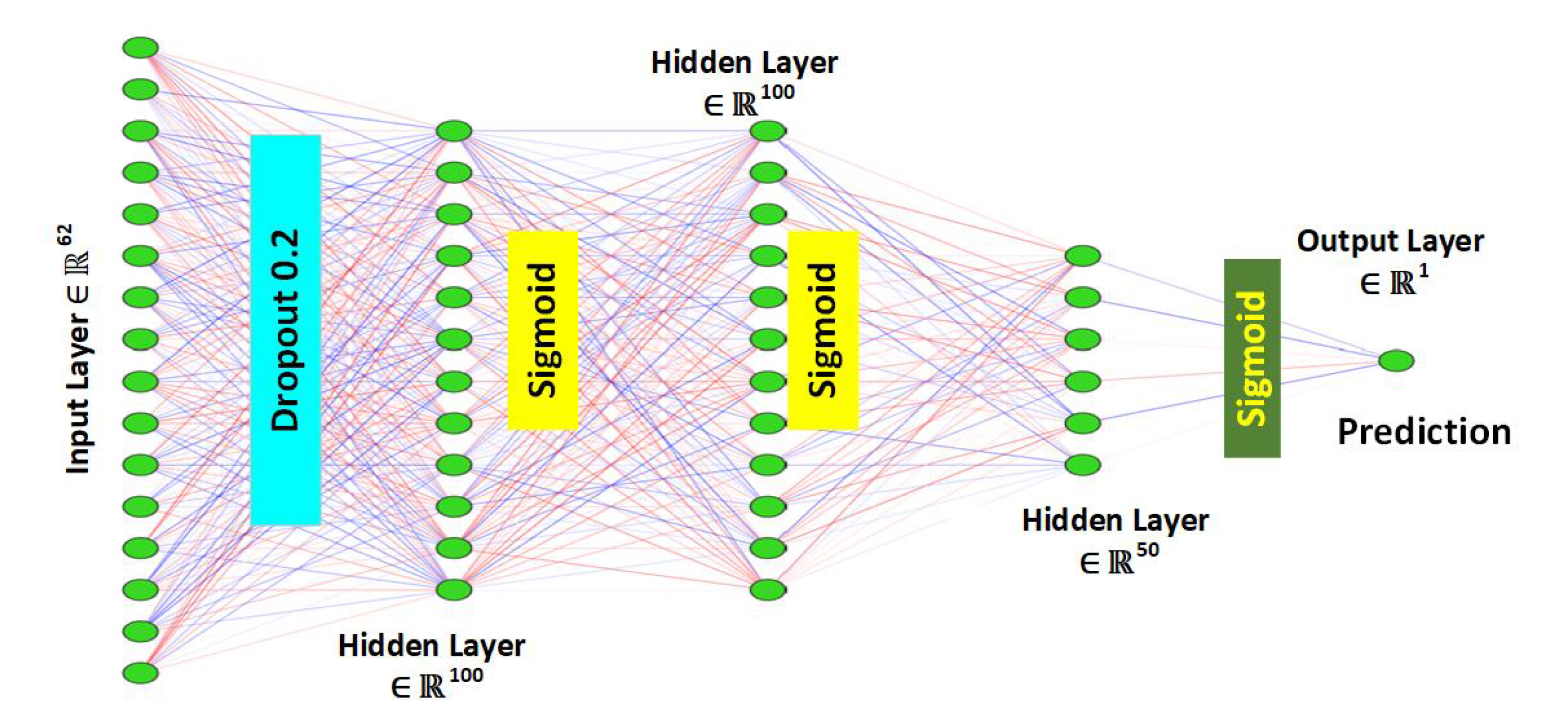
2.4.1. Layers in the Model
A sequential deep neural network (DNN) model was proposed in this work. The model contained one input layer, three hidden layers, and one output layer for earthquake prediction. The input layer contained 62 neurons, which represented the no. of features. The three hidden layers contained 100, 100, and 50 neurons, respectively, while the output layer comprised a single neuron. The number of layers, and the number of neurons in each hidden layer, were initially selected randomly, and the final values were the ones which provided the optimum results. The sigmoid function was used for all layers except the input layer. The model was implemented in Python 3.7, using Jupyter Notebook as an IDE.
2.4.2. Addressing Over-Fitting
Over-fitting is a common problem in machine learning, and happens when a model does not generalize effectively from observed to unseen data [
29]. In order to avoid over-fitting from the data, the dropout
was used after the first layer of the model.
2.4.3. Activation Function
The sigmoid function was used as activation and output function in the proposed model. The sigmoid function—also called the logistic function—is mathematically represented as follows:
Furthermore, a binary cross-entropy (BCE) [
30] as loss function, and “Adam” as an optimizer, were used in the model. The mathematical representation of the BCE is as follows:
Note that is the actual output for the ith input/record, and is the predicted probability for the ith input/record.
2.4.4. Weight Initializing
For the better learning of the model, implementation of a weight initializing scheme, “uniform distribution of a fixed bound”, and one hundred epochs in the proposed model were used. The graphical representation of the model is shown in
Figure 2.
2.5. Benchmark Algorithms
To compare the performance of our proposed model, we selected logistic regression, support vector machine, and random forest as our benchmark algorithms.
2.5.1. Logistic Regression
Logistic regression is a machine learning technique used to predict positive class based on prior observation. Logistic regression is used for binary and multi-label classification. Mathematically, logistic regression is defined as follows [
31]:
where
is the set of parameters. Logistic regression, using the sigmoid function to transform the output to probability values, aims to minimize the cost function, to attain an optimal probability.
2.5.2. Support Vector Machine
Support vector machine (SVM) is a robust method of supervised learning, used for classification and regression problems [
32]. SVM helps in finding the hyper-plane in N-dimensional space, with less computation. The following is the mathematical representation of SVM:
such that:
2.5.3. Random Forest
An ensemble learning technique, random forest is the collection of various decision trees. Random forest is a flexible and easy-to-use algorithm or classifier among machine learning approaches, and is mostly used for classification and prediction purposes [
33].
2.6. Evaluation Metrics
The proposed model and the benchmark algorithms were evaluated using the standard evaluation metrics for classification problems: accuracy; precision; recall; and F1-score [
34]. The terms accuracy, precision, recall and F1-score were based on a confusion matrix, which was calculated on the basis of the actual and predicted values. The confusion matrix is shown in
Table 2. The terms accuracy, recall, precision, and F1-scores are defined in
Table 3.
4. Conclusions
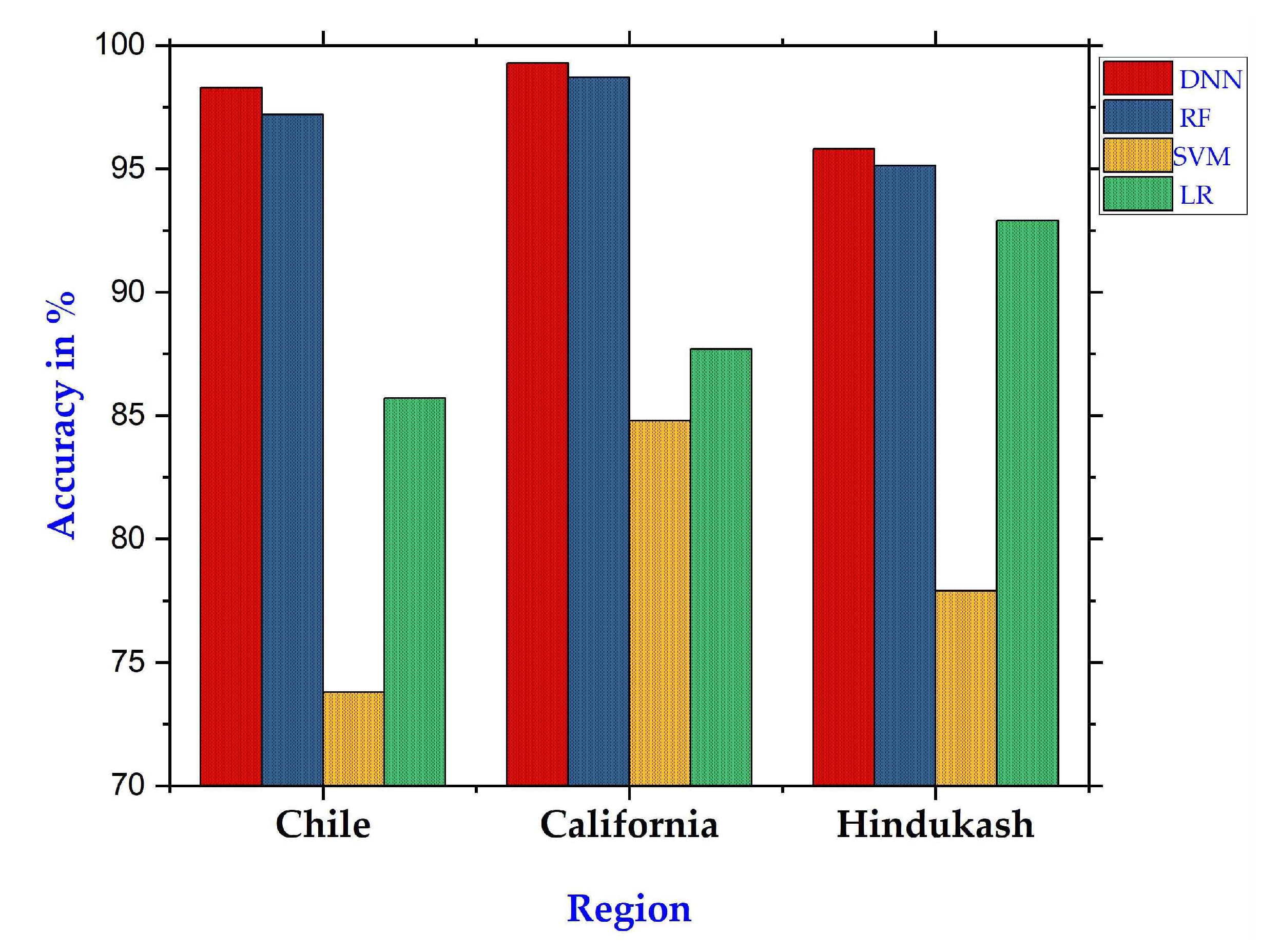
In this research, a trans-disciplinary investigation was carried out, for seismic prediction via machine learning technique. Several machine learning algorithms—including deep neural networks, random forest, support vector machine, and linear regressions—were applied to three distinct datasets: Chile, Southern California, and Hindukush. The algorithms were evaluated on the mentioned datasets, using in-sample and out-of-sample techniques. Our proposed deep neural network approach outperformed the benchmark techniques on all the datasets. On average, the accuracy of the proposed model was 10% better than the benchmark algorithms, while in terms of precision, recall, and F1-score, the performance improvement was 20%, 29%, and 36%, respectively. The same performance order was observed using out-of-sample testing.
Although our model outperformed the existing works, and achieved significantly better performance, it is important to mention that we focused on seismic activity prediction only (classification problem), and did not consider the problem of predicting exact magnitude (regression problem). Furthermore, we did not collect our own data: instead, we used the currently available and already peer-reviewed data. Like all machine learning works, the current work was heavily dependent on the underlying data. Although we have shown that our proposed model was able to achieve better performance than the current techniques, the model may require further testing on other datasets, to strengthen its case. Finally, like all machine learning techniques, our proposed model also suffers from the inherit risk of interpretability.
The proposed technique enriches the body of literature, by proposing a deep-learning-based generalizable architecture for seismic activity prediction. The study should be of interest to trans-disciplinary researchers and practitioners in the domain of seismology. This work could be extended further, by identifying the important features that affected the seismic outcome. Another interesting direction would be to design explainable AI-based techniques.


 ,
, 



{kind=link}
{kind=link}
{kind=link}