
ATICVis: A Visual Analytics System for Asymmetric Transformer Models Interpretation and Comparison


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We propose metrics to evaluate the captured information similarity between layers and attention heads. This helps users to identify layer and head combinations worth to compare and reduces the complexity when users compare models.
- A complete and convenient interactive visualization system is developed for experts to interpret and compare transformer-based models easily.
- Use cases are shown to demonstrate how the proposed system helps NLP experts understand their models and make decisions. In addition, user feedback is collected to discuss the pros and cons of our current system.
2. Related Works
2.1. Language Model
2.2. Model Interpretation
2.3. Model Comparison
3. Backgrounds
4. Goals and Requirements
4.1. Design Goals
4.2. Design Requirements
5. Visualization Design
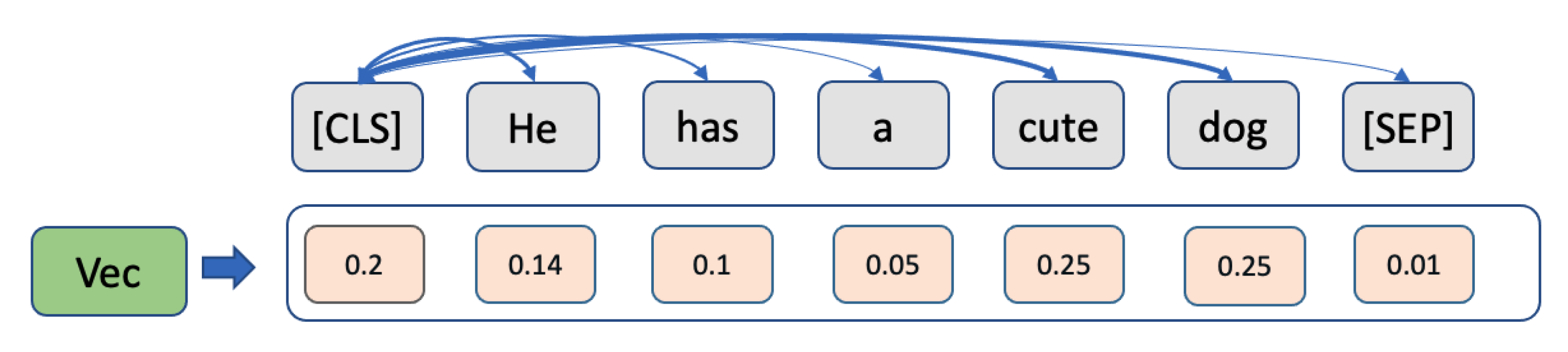
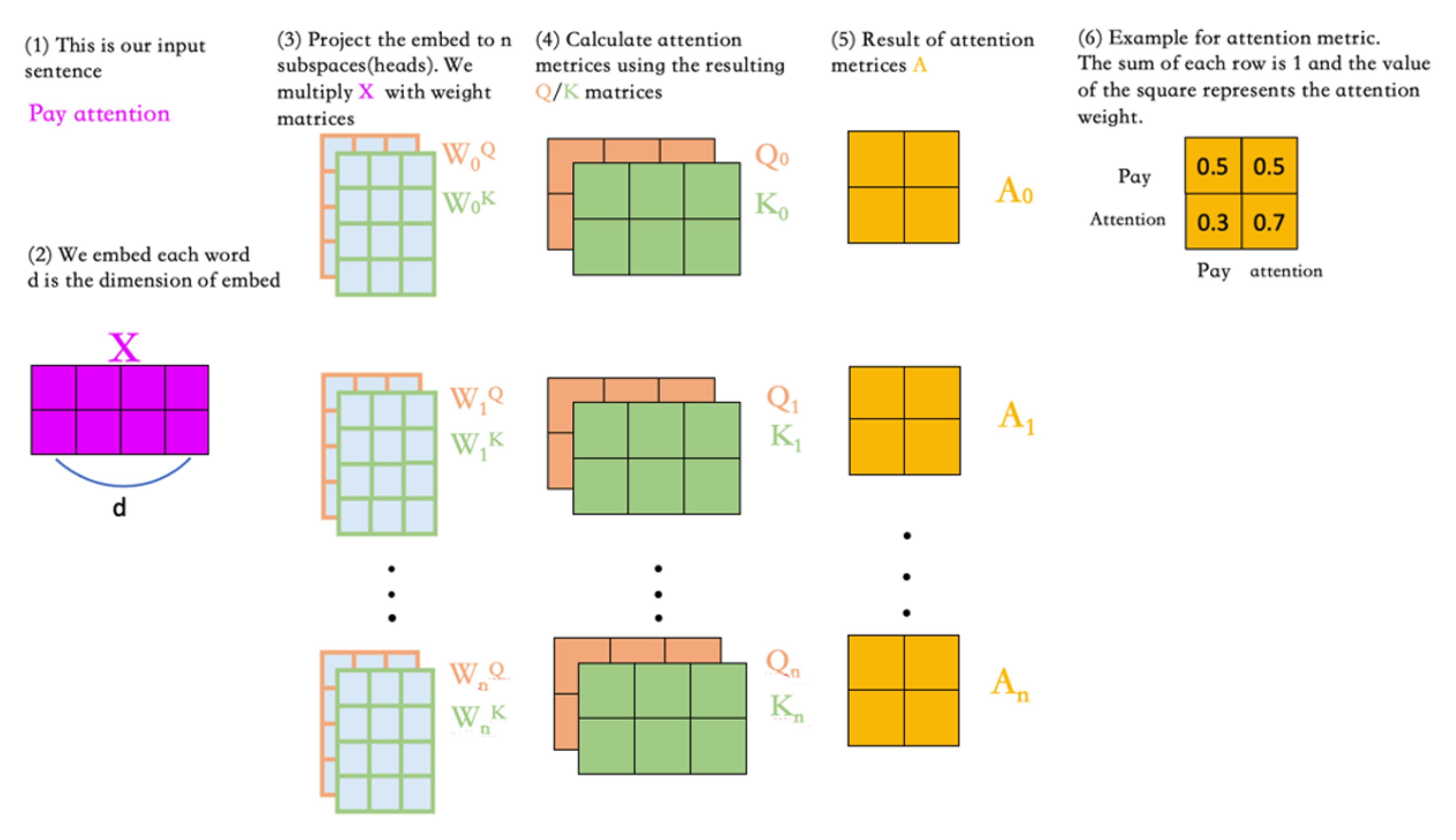
5.1. Layers and Heads Similarity Evaluation
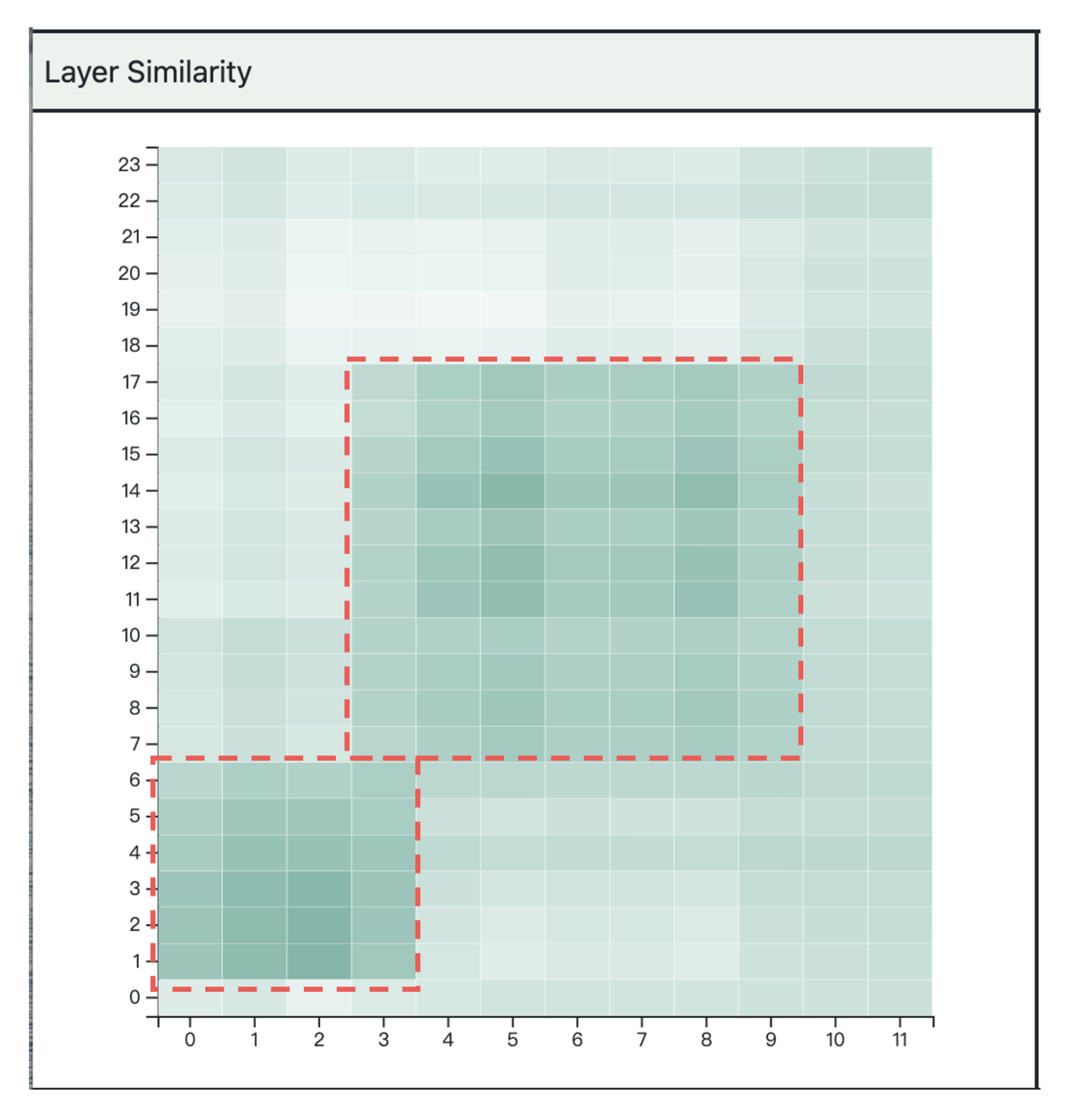
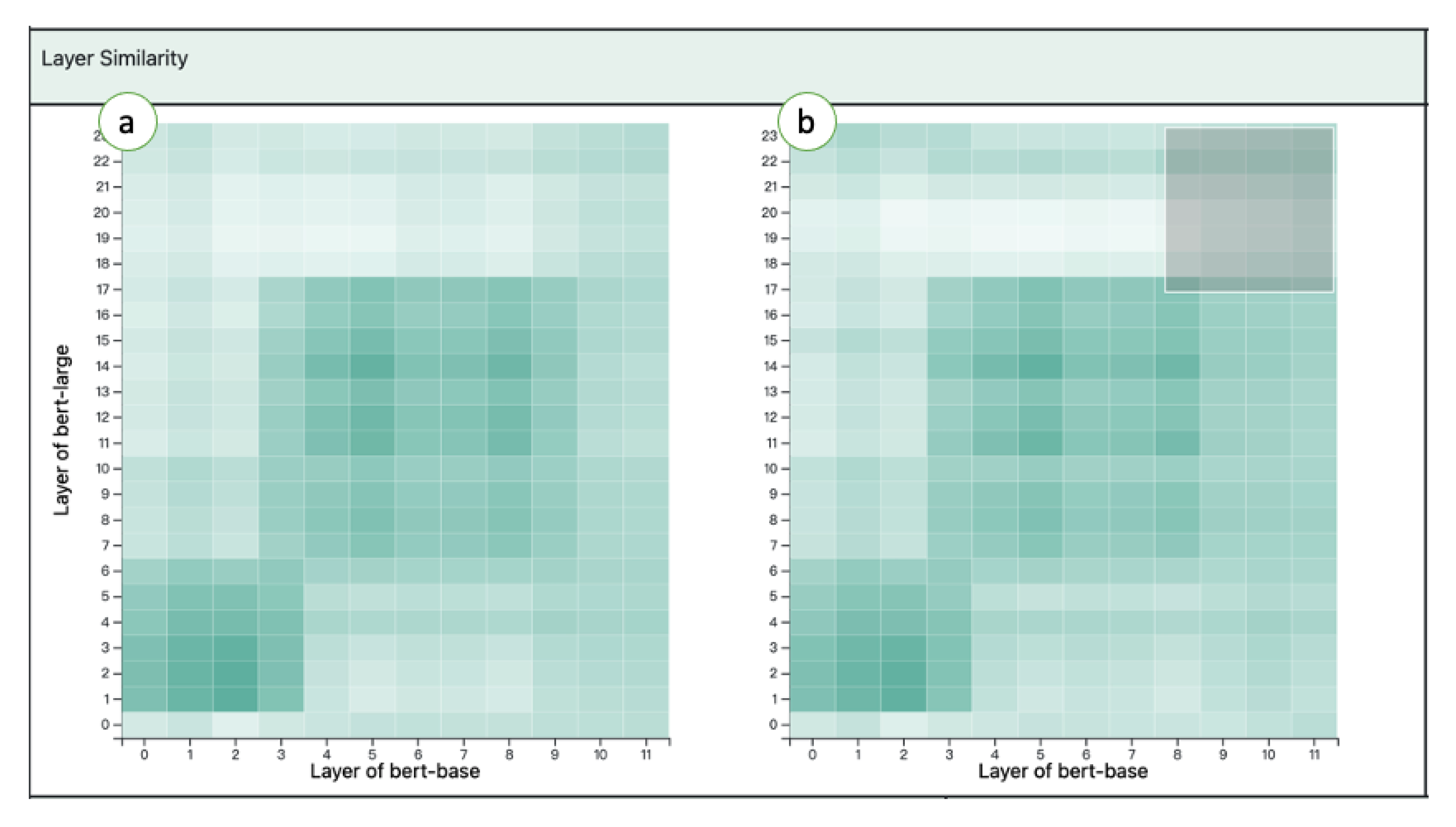
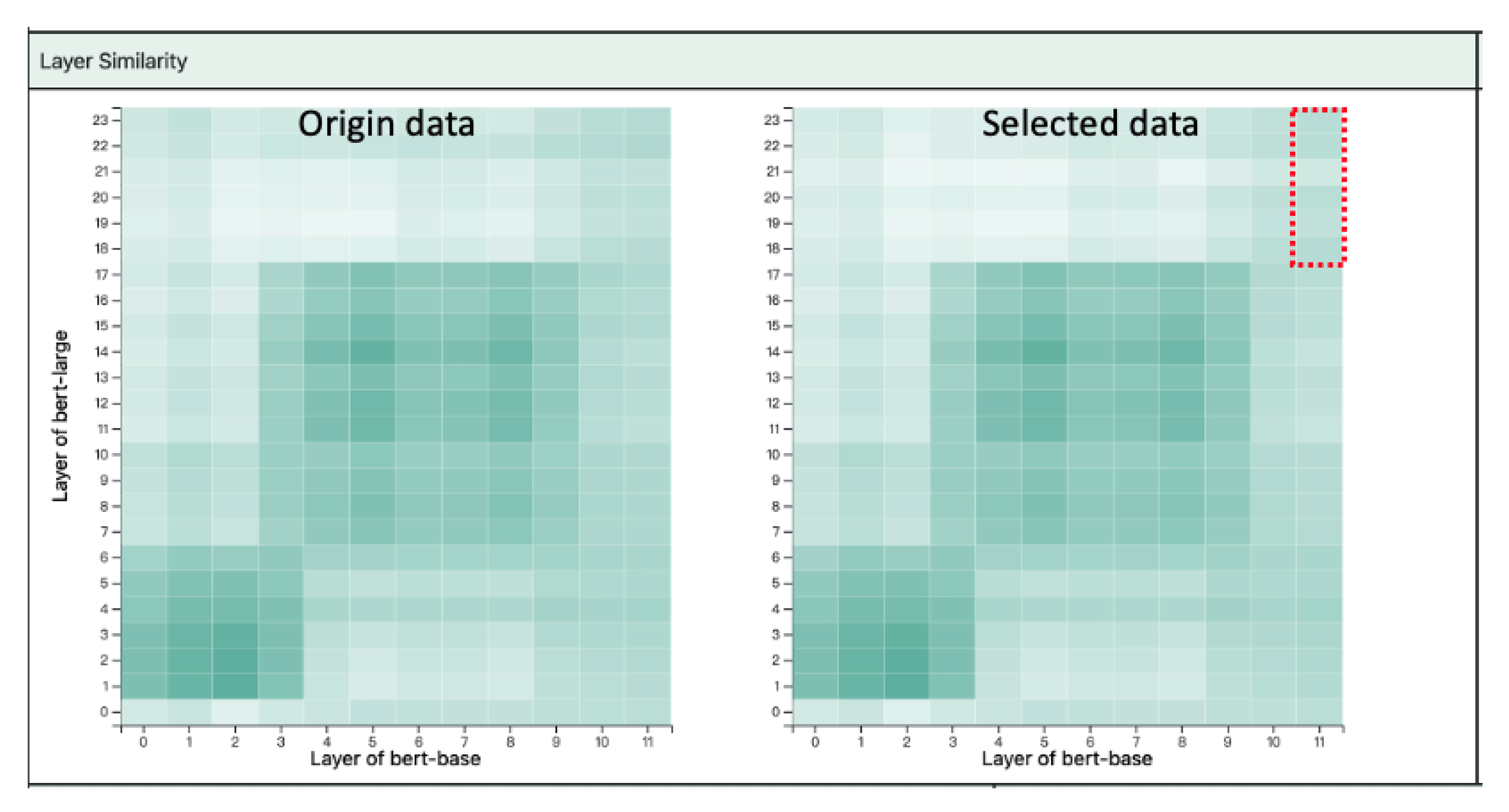
5.2. Layer Similarity Graph
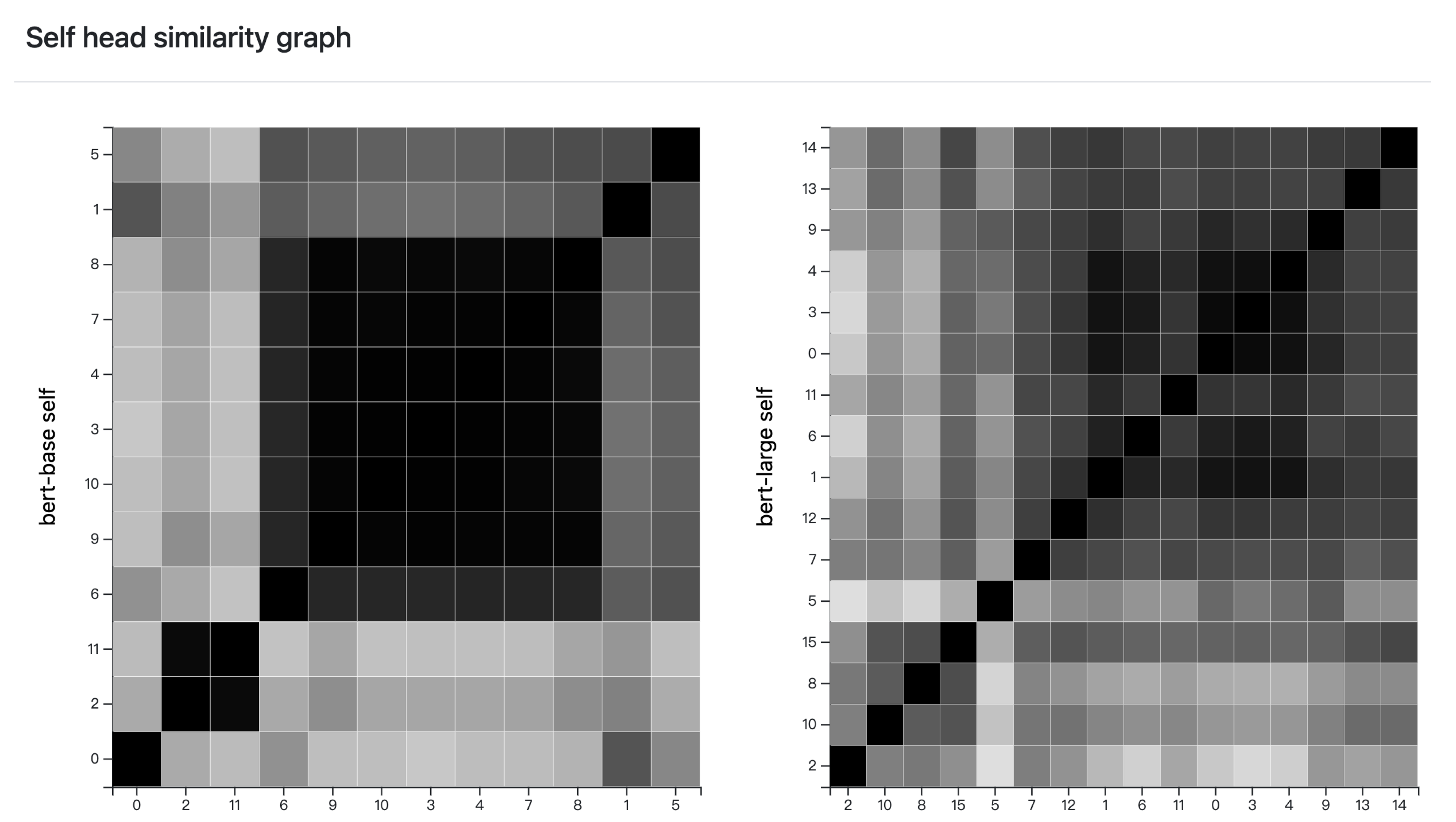
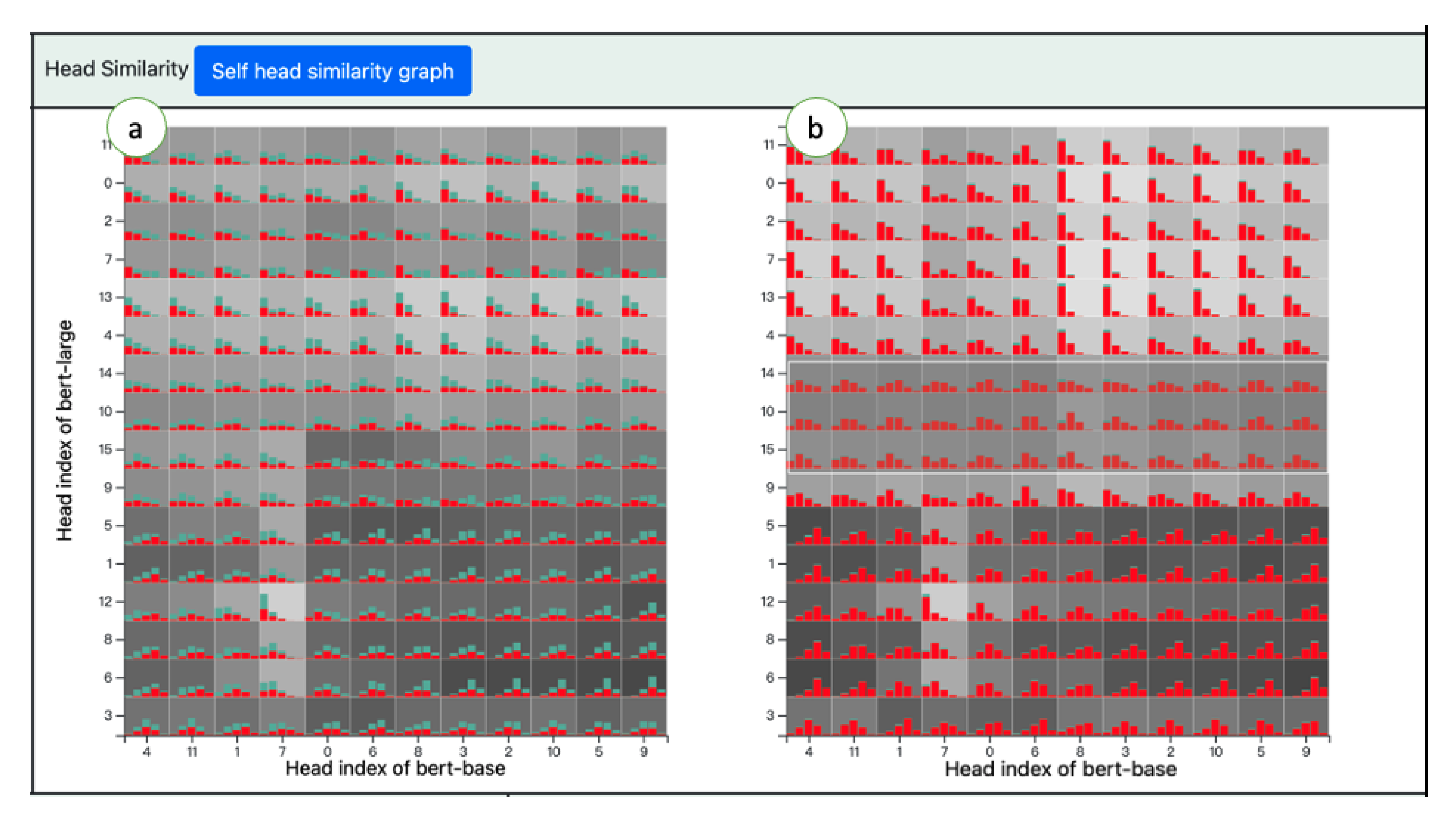
5.3. Head Similarity Graph
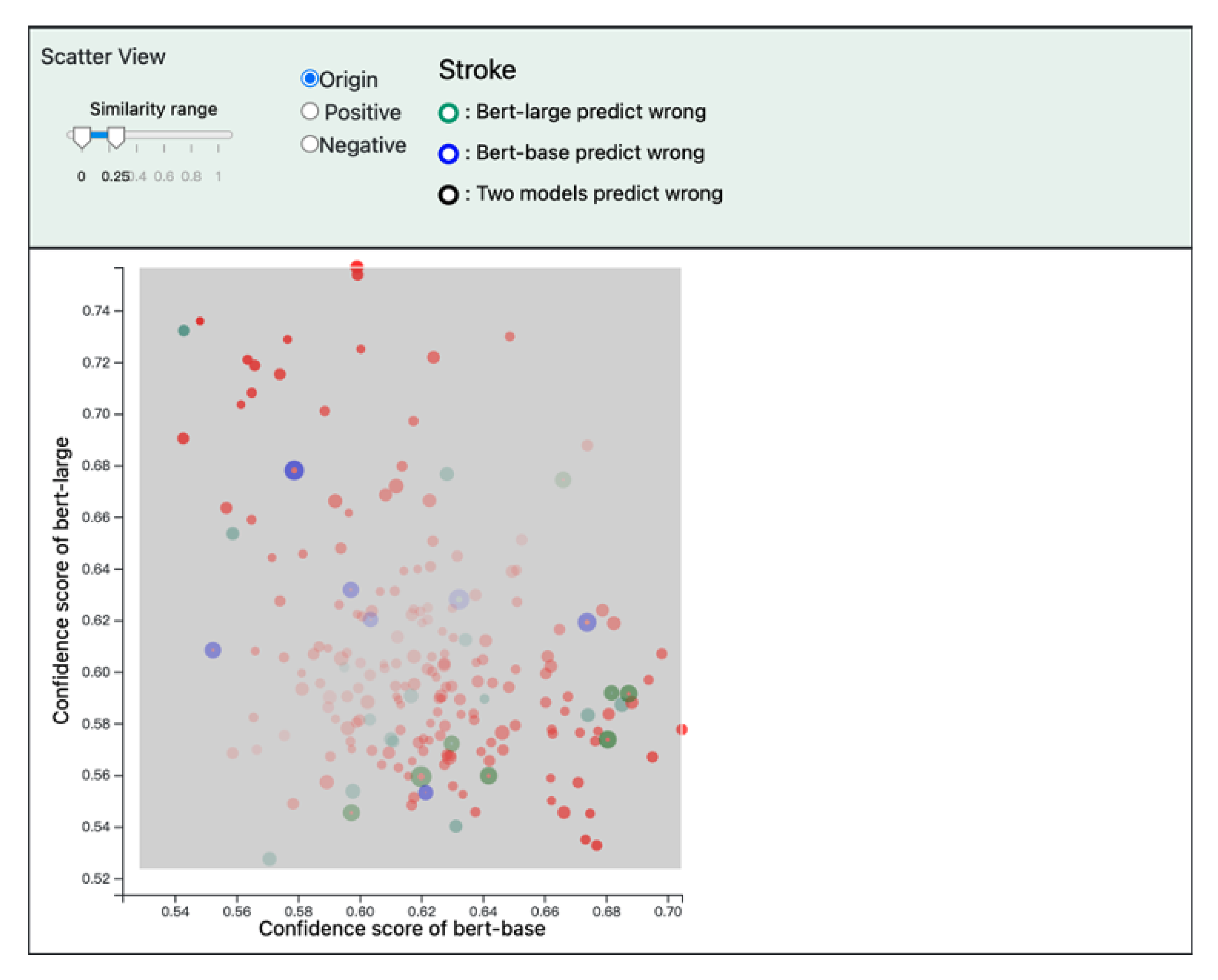
5.4. Scatter View
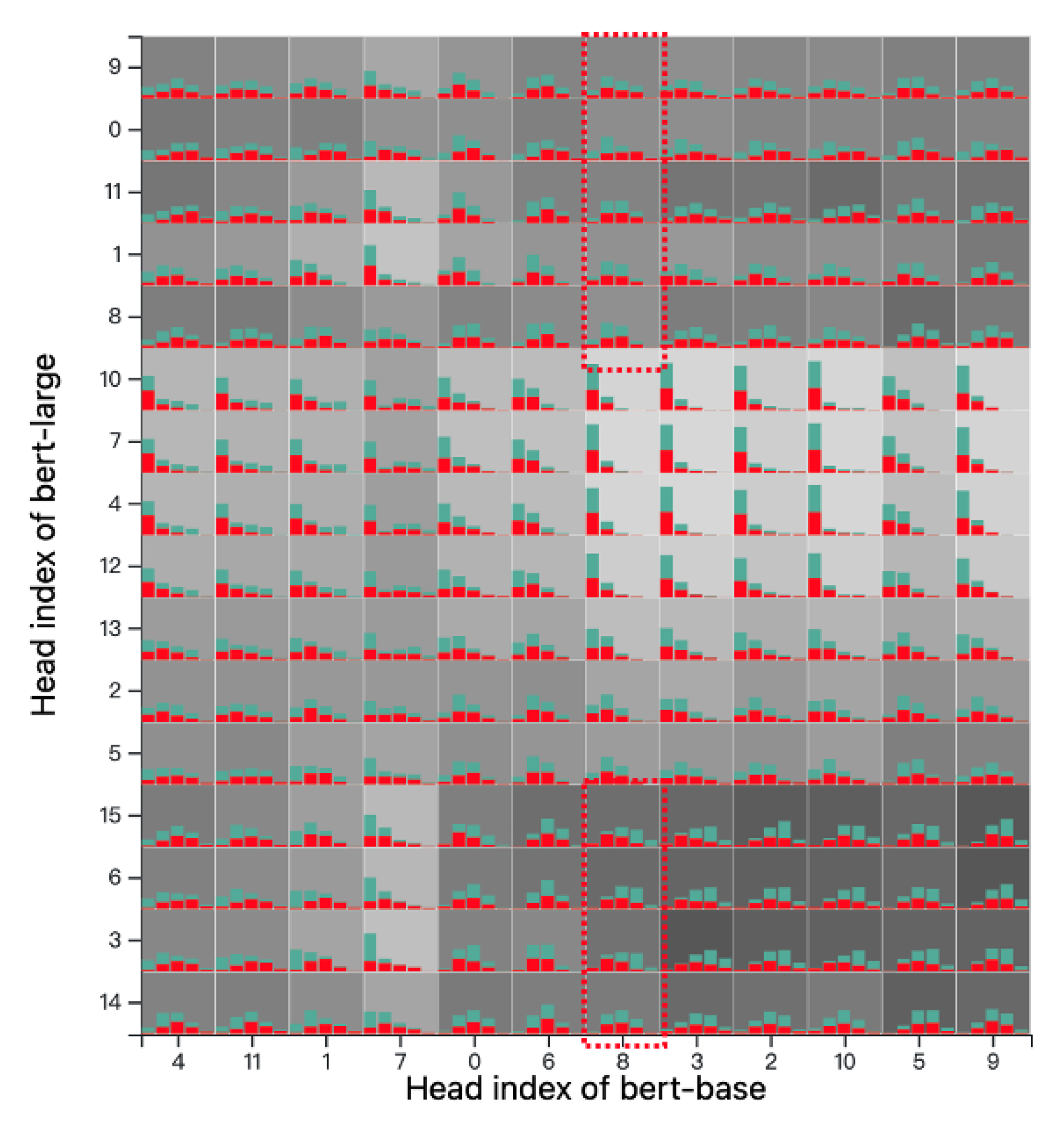
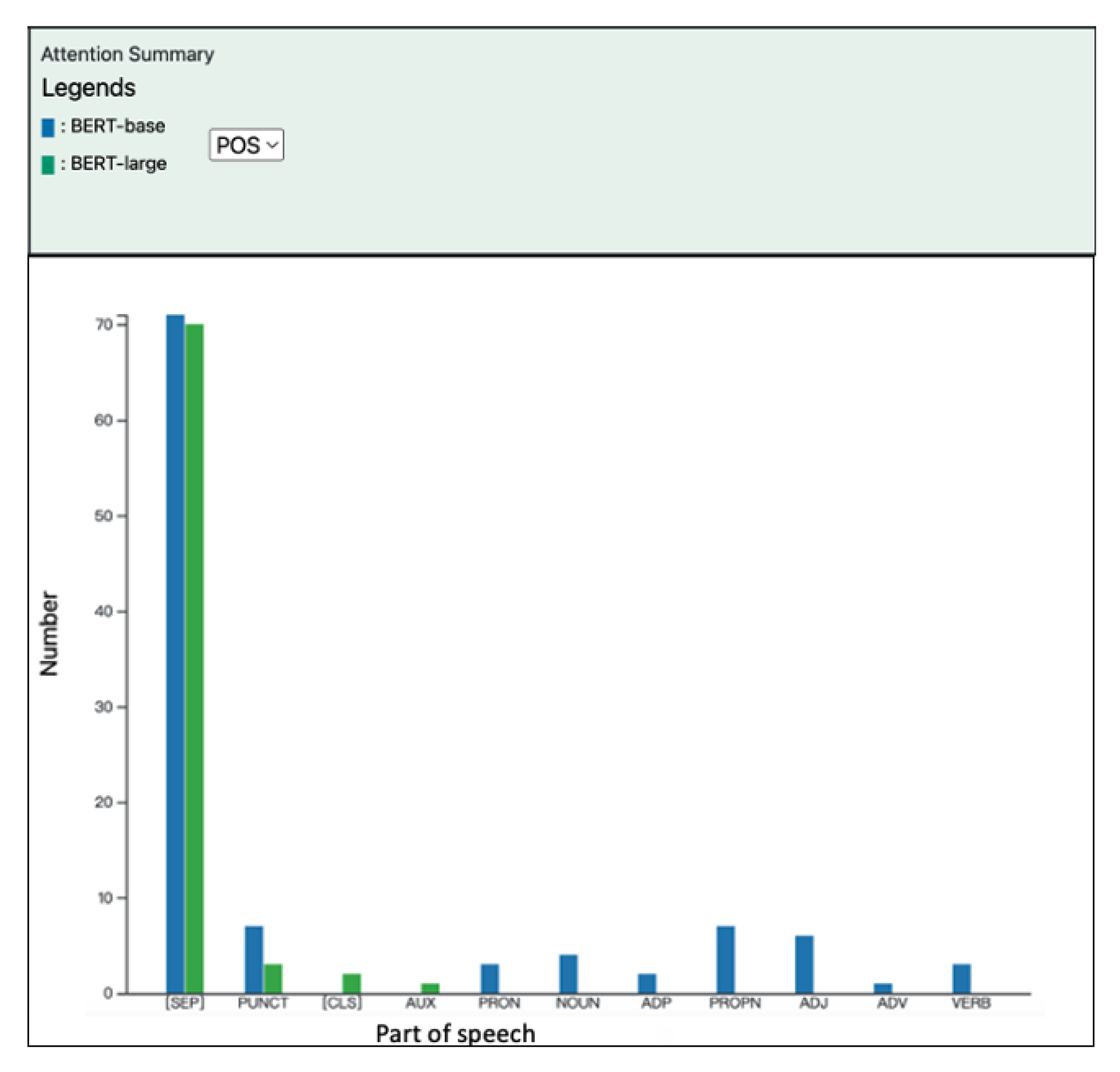
5.5. Attention View and Attention Summary
5.6. System Implementation
6. Use Cases
6.1. Use Case 1: Exploring and Comparing Behaviors of a Large and a Small Models (Video S1)
6.2. Use Case 2: Comparison of Parameterized Linguistic Information (Video S2)
7. Conclusions and Future Works
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; p. 32. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Ming, Y.; Cao, S.; Zhang, R.; Li, Z.; Chen, Y.; Song, Y.; Qu, H. Understanding hidden memories of recurrent neural networks. In Proceedings of the 2017 IEEE Conference on Visual Analytics Science and Technology (VAST), Phoenix, AZ, USA, 3–6 October 2017; pp. 13–24. [Google Scholar]
- Lo, P.S.; Wu, J.L.; Deng, S.T.; Wang, K.C. CNERVis: A visual diagnosis tool for Chinese named entity recognition. J. Vis. 2022, 25, 653–669. [Google Scholar] [CrossRef]
- Wang, X.; He, J.; Jin, Z.; Yang, M.; Wang, Y.; Qu, H. M2Lens: Visualizing and explaining multimodal models for sentiment analysis. IEEE Trans. Vis. Comput. Graph. 2021, 28, 802–812. [Google Scholar] [CrossRef]
- DeRose, J.F.; Wang, J.; Berger, M. Attention flows: Analyzing and comparing attention mechanisms in language models. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1160–1170. [Google Scholar] [CrossRef]
- Zhou, J.; Huang, W.; Chen, F. A Radial Visualisation for Model Comparison and Feature Identification. In Proceedings of the 2020 IEEE Pacific Visualization Symposium (PacificVis), Tianjin, China, 3–5 June 2020; pp. 226–230. [Google Scholar]
- Li, Y.; Fujiwara, T.; Choi, Y.K.; Kim, K.K.; Ma, K.L. A visual analytics system for multi-model comparison on clinical data predictions. Vis. Inform. 2020, 4, 122–131. [Google Scholar] [CrossRef]
- Yu, W.; Yang, K.; Bai, Y.; Yao, H.; Rui, Y. Visualizing and comparing convolutional neural networks. arXiv 2014, arXiv:1412.6631. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 6–9 July 2008; pp. 160–167. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; pp. 1532–1543. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech, Chiba, Japan, 26–30 September 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Hoang, M.; Bihorac, O.A.; Rouces, J. Aspect-based sentiment analysis using bert. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku, Finland, 30 September–2 October 2019; pp. 187–196. [Google Scholar]
- Liu, Z.; Jiang, F.; Hu, Y.; Shi, C.; Fung, P. NER-BERT: A pre-trained model for low-resource entity tagging. arXiv 2021, arXiv:2112.00405. [Google Scholar]
- Mitzalis, F.; Caglayan, O.; Madhyastha, P.; Specia, L. BERTGEN: Multi-task Generation through BERT. arXiv 2021, arXiv:2106.03484. [Google Scholar]
- Endert, A.; Ribarsky, W.; Turkay, C.; Wong, B.W.; Nabney, I.; Blanco, I.D.; Rossi, F. The state of the art in integrating machine learning into visual analytics. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2017; Volume 36, pp. 458–486. [Google Scholar]
- Li, G.; Wang, J.; Shen, H.W.; Chen, K.; Shan, G.; Lu, Z. Cnnpruner: Pruning convolutional neural networks with visual analytics. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1364–1373. [Google Scholar] [CrossRef]
- Liu, S.; Wang, X.; Liu, M.; Zhu, J. Towards better analysis of machine learning models: A visual analytics perspective. Vis. Inform. 2017, 1, 48–56. [Google Scholar] [CrossRef]
- Liu, M.; Shi, J.; Li, Z.; Li, C.; Zhu, J.; Liu, S. Towards better analysis of deep convolutional neural networks. IEEE Trans. Vis. Comput. Graph. 2016, 23, 91–100. [Google Scholar] [CrossRef] [Green Version]
- Strobelt, H.; Gehrmann, S.; Behrisch, M.; Perer, A.; Pfister, H.; Rush, A.M. S Equation (2)s eq-v is: A visual debugging tool for sequence-to-sequence models. IEEE Trans. Vis. Comput. Graph. 2018, 25, 353–363. [Google Scholar] [CrossRef] [Green Version]
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. arXiv 2019, arXiv:1905.05950. [Google Scholar]
- Hao, Y.; Dong, L.; Wei, F.; Xu, K. Visualizing and understanding the effectiveness of BERT. arXiv 2019, arXiv:1908.05620. [Google Scholar]
- Hoover, B.; Strobelt, H.; Gehrmann, S. exbert: A visual analysis tool to explore learned representations in transformers models. arXiv 2019, arXiv:1910.05276. [Google Scholar]
- Park, C.; Na, I.; Jo, Y.; Shin, S.; Yoo, J.; Kwon, B.C.; Zhao, J.; Noh, H.; Lee, Y.; Choo, J. Sanvis: Visual analytics for understanding self-attention networks. In Proceedings of the 2019 IEEE Visualization Conference (VIS), Vancouver, BC, Canada, 20–25 October 2019; pp. 146–150. [Google Scholar]
- Wexler, J.; Pushkarna, M.; Bolukbasi, T.; Wattenberg, M.; Viégas, F.; Wilson, J. The what-if tool: Interactive probing of machine learning models. IEEE Trans. Vis. Comput. Graph. 2019, 26, 56–65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for Large-Scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Piringer, H.; Berger, W.; Krasser, J. Hypermoval: Interactive visual validation of regression models for real-time simulation. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2010; Volume 29, pp. 983–992. [Google Scholar]
- Murugesan, S.; Malik, S.; Du, F.; Koh, E.; Lai, T.M. Deepcompare: Visual and interactive comparison of deep learning model performance. IEEE Comput. Graph. Appl. 2019, 39, 47–59. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, L.; Zheng, Y.; Yeh, C.C.M.; Jain, S.; Zhang, W. Learning-From-Disagreement: A Model Comparison and Visual Analytics Framework. IEEE Trans. Vis. Comput. Graph. 2022. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Rocktäschel, T.; Grefenstette, E.; Hermann, K.M.; Kočiskỳ, T.; Blunsom, P. Reasoning about entailment with neural attention. arXiv 2015, arXiv:1509.06664. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning PMLR, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Johnson, S.C. Hierarchical clustering schemes. Psychometrika 1967, 32, 241–254. [Google Scholar] [CrossRef]
- Yang, S.; Pan, C.; Hurst, G.B.; Dice, L.; Davison, B.H.; Brown, S.D. Elucidation of Zymomonas mobilis physiology and stress responses by quantitative proteomics and transcriptomics. Front. Microbiol. 2014, 5, 246. [Google Scholar] [CrossRef] [Green Version]
- Vig, J. BertViz: A tool for visualizing multihead self-attention in the BERT model. In Proceedings of the ICLR Workshop: Debugging Machine Learning Models, New Orleans, LA, USA, 6 May 2019. [Google Scholar]


























Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.-L.; Chang, P.-C.; Wang, C.; Wang, K.-C. ATICVis: A Visual Analytics System for Asymmetric Transformer Models Interpretation and Comparison. Appl. Sci. 2023, 13, 1595. https://doi.org/10.3390/app13031595
Wu J-L, Chang P-C, Wang C, Wang K-C. ATICVis: A Visual Analytics System for Asymmetric Transformer Models Interpretation and Comparison. Applied Sciences. 2023; 13(3):1595. https://doi.org/10.3390/app13031595
Chicago/Turabian StyleWu, Jian-Lin, Pei-Chen Chang, Chao Wang, and Ko-Chih Wang. 2023. "ATICVis: A Visual Analytics System for Asymmetric Transformer Models Interpretation and Comparison" Applied Sciences 13, no. 3: 1595. https://doi.org/10.3390/app13031595