
Vehicle Trajectory Prediction Based on Graph Convolutional Networks in Connected Vehicle Environment

Abstract
:1. Introduction
- A new vehicle trajectory prediction framework, VTP-GCN, is proposed to model the spatial–temporal interaction behavior and output the future motion trajectories of vehicles based on GCN and fully convolutional layers, with the data from the comparative experiments showing that this method is effective in improving the accuracy of vehicle trajectory prediction.
- The concept of spatial interaction coefficient is proposed to mark the intensity of spatial interaction between two vehicles, with the results from the ablation test showing that the weighted adjacency matrix based on the spatial interaction coefficient can better model the spatial interaction behavior among vehicles and the corresponding model has a better prediction performance.
- A temporal graph construction method based on the self-attention mechanism is proposed to model the temporal interaction of vehicles at different historical moments, with the ablation test results showing that the relevant model is associated with smaller prediction errors than those associated with the reciprocal of the time interval.
2. Problem Description
3. The VTP-GCN Model
3.1. Graph Representation Based on Raw Vehicle Motion Data
- (1)
- Spatial Graph Representation Learning
- (2)
- Temporal Graph Representation Learning
3.2. Spatial-Temporal Interaction Feature Extraction
3.3. Vehicle Trajectory Prediction
4. Experimental Evaluation and Analysis
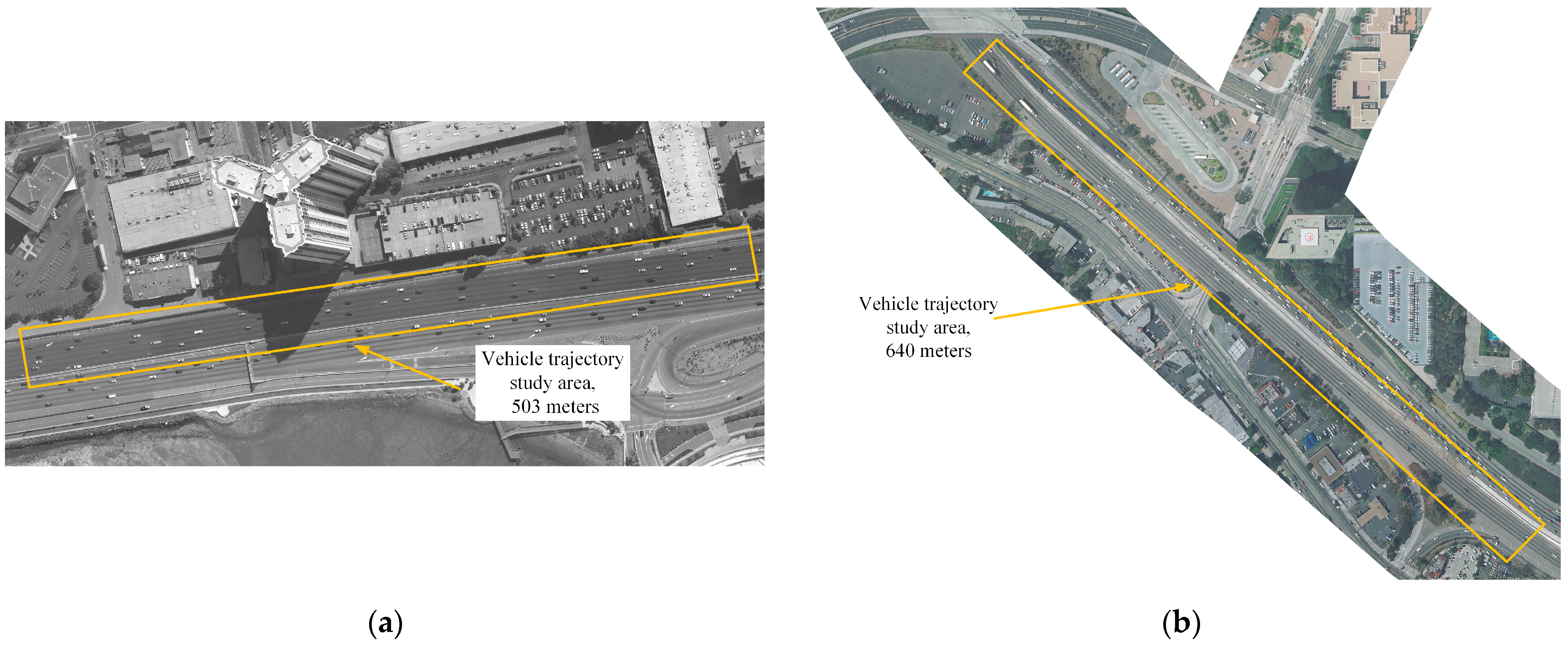
4.1. Evaluation Datasets and Mertics
4.2. Implementation Details
- (1)
- Spatial interaction range: we set the longitudinal spatial interaction range within ±100 m, which is similar to that in Ref [21].
- (2)
- Input embedding: we used 1 × 1 convolution to increase the number of channels to five, an approach which is beneficial to improve the learning ability of the network.
- (3)
- Residual connection: the residual connections were introduced in the interaction feature extraction module and the trajectory prediction module to avoid the problems of overfitting and gradient vanishing.
- (4)
- Training process: the VTP-GCN was trained on the NVIDIA GTX3080 GPU. The batch size and the learning rate were set to 128 and 0.01, respectively. We trained the prediction module for 250 epochs using a stochastic gradient descent (SGD) optimizer.
- (5)
- Model configuration: to obtain the best prediction accuracy, the number of GCN layers in the interaction feature extraction module and the number of CNN layers in the trajectory prediction module were set to different numbers, so as to select the best model configurations, i.e., two GCN layers and five CNN layers.
4.3. Quantitative Analysis
- (1)
- CV: this baseline uses a constant velocity Kalman filter to predict the trajectory of a single vehicle and does not consider the interaction between the predicted vehicle and the surrounding neighbor vehicles.
- (2)
- V-LSTM: this baseline learns the information hidden in the historical trajectory data based on an LSTM encoder–decoder, and then generates the trajectory distribution of the target vehicle. V-LSTM also does not consider the interdependencies among vehicles.
- (3)
- C-VGMM+VIM [27]: this baseline first estimates the maneuver intentions based on a hidden markov model (HMM), and then generates the future trajectory based on the variational gaussian mixture models.
- (4)
- MATF [28]: this baseline encodes the historical trajectory data of vehicles and the information of the driving scene into a multi-agent tensor, and then applies CNNs to extract spatial interactions, decode, and predict the trajectories of all vehicles based on LSTM.
- (5)
- CS-LSTM: this baseline uses convolutional social pooling as an improvement to social pooling layers to robustly learn spatial interdependencies in vehicle motion.
- (6)
- GRIP: this baseline uses GCNs to model the spatial–temporal interactions among vehicles and generate the trajectories of all vehicles based on an LSTM encoder–decoder.
4.4. Ablation Study
- (1)
- Spatial Graph with Different Weighted Adjacency Matrices
- (2)
- Temporal Graph with Different Weighted Adjacency Matrices
- (3)
- Effectiveness of Feature Extraction Modules
4.5. Qualitative Analysis
5. Conclusions
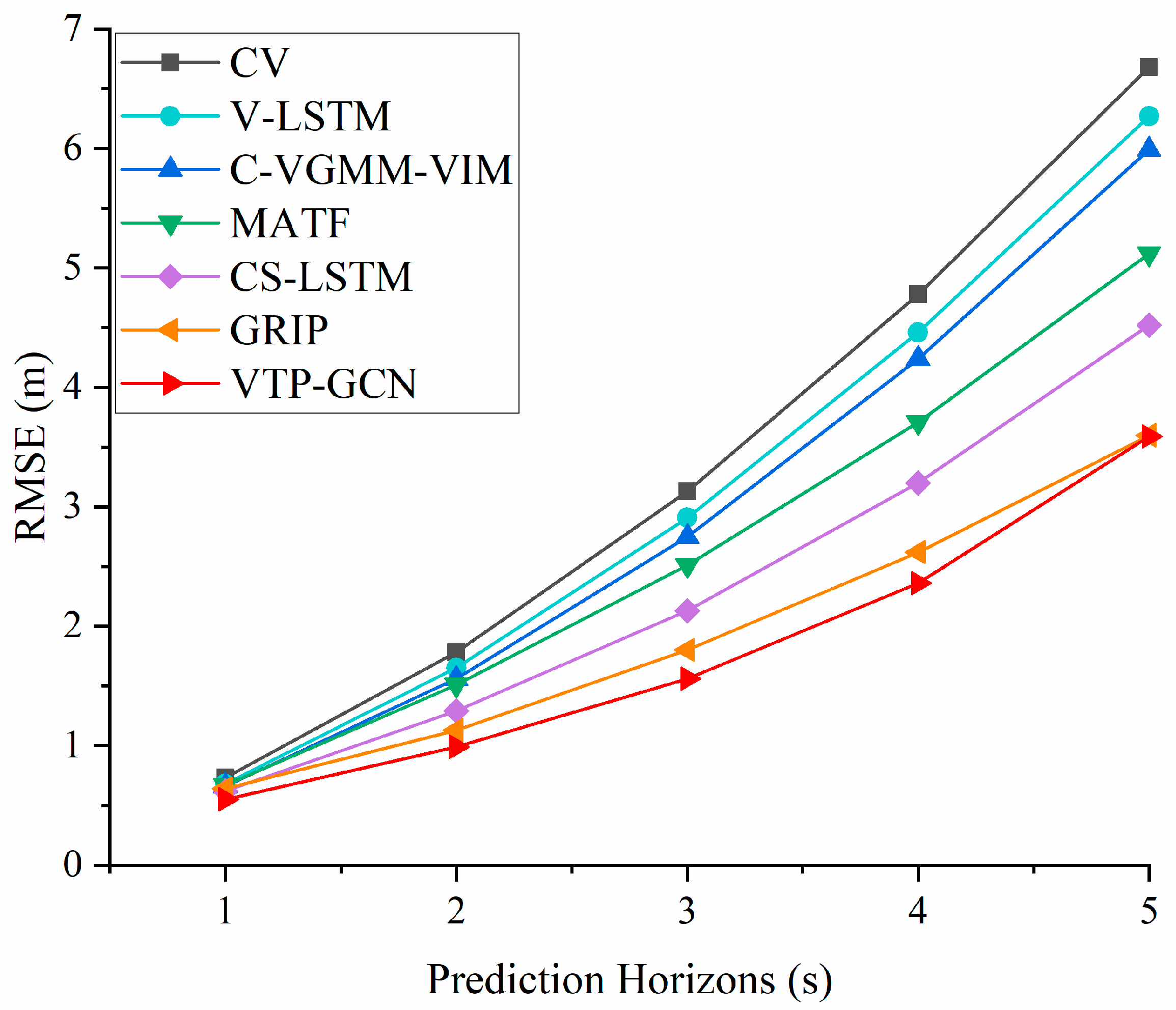
- The comparative experiment data show that, compared with the baseline models, the vehicle trajectory prediction model VTP-GCN based on graph convolutional neural networks proposed in this manuscript is associated with smaller prediction errors. Specifically, compared with GRIP, the average RMSE value of VTP-GCN is lower by 8%, effectively improving the prediction effectiveness of the future motion trajectories of all vehicles in the driving scene.
- We model the spatial–temporal interactions among vehicles based on the SIC and the self-attention mechanism. The ablation experiment results of spatial interactions show that the prediction errors of the spatial interaction modeling method based on the traditional reciprocal Euclidean distance are larger, and its average RMSE value increases by 5% compared with the method based on the SIC. The results of the temporal interaction ablation experiment show that the trajectory prediction errors of the temporal interaction modeling method based on the reciprocal of the time interval are larger, and its average RMSE value increases by 12% compared with the method proposed in this study.
- The ablation experiment data on the effectiveness of the feature extraction module show that the absence of any interaction module will lead to an increase in vehicle trajectory prediction errors. It is worth noting that the absence of SGCN causes the model average prediction error to increase by 6%, while the absence of TGCN causes the model average prediction error to increase by 4%. Therefore, we speculate that spatial interaction modeling is of greater importance than temporal interaction modeling for vehicle trajectory prediction.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, K.; Chang, X.Y.; Li, J.W.; Qing, X.; Bolin, G.; Jian, P. Cloud control system for intelligent and connected vehicles and its application. Automot. Eng. 2020, 42, 1595–1605. [Google Scholar]
- Huang, Y.; Du, J.; Yang, Z.; Zhou, Z.; Zhang, L.; Chen, H. A Survey on Trajectory-Prediction Methods for Autonomous Driving. IEEE Trans. Intell. Veh. 2022, 7, 652–674. [Google Scholar] [CrossRef]
- Ammoun, S.; Nashashibi, F. Real Time Trajectory Prediction for Collision Risk Estimation between Vehicles. In Proceedings of the IEEE 5th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 27–29 August 2009; pp. 417–422. [Google Scholar]
- Jin, B.; Jiu, B.; Su, T.; Liu, H.; Liu, G. Switched Kalman filter-interacting multiple model algorithm based on optimal autoregressive model for manoeuvring target tracking. IET Radar Sonar Navig. 2015, 9, 199–209. [Google Scholar] [CrossRef]
- Guo, Y.; Kalidindi, V.V.; Arief, M.; Wang, W.; Zhu, J.; Peng, H.; Zhao, D. Modeling Multi-Vehicle Interaction Scenarios using Gaussian Random Field. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3974–3980. [Google Scholar]
- Deng, Q.; Soffker, D. Improved Driving Behaviors Prediction Based on Fuzzy Logic-Hidden Markov Model (FL-HMM). In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 2003–2008. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Perez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Deep Inverse Reinforcement Learning for Behavior Prediction in Autonomous Driving: Accurate Forecasts of Vehicle Motion. IEEE Signal Process. Mag. 2020, 38, 87–96. [Google Scholar] [CrossRef]
- Das, K.; Kumar, R.; Krishna, A. Analyzing electric vehicle battery health performance using supervised machine learning. Renew. Sustain. Energy Rev. 2024, 189, 113967. [Google Scholar] [CrossRef]
- Das, K.; Kumar, R.; Krishna, A. Supervised learning and data intensive methods for the prediction of capacity fade of lithium-ion batteries under diverse operating and environmental conditions. Water Energy Int. 2023, 66, 53–59. [Google Scholar]
- Kumar, R.; Pachauri, R.K.; Badoni, P.; Bharadwaj, D.; Mittal, U.; Bisht, A. Investigation on parallel hybrid electric bicycle along with issuer management system for mountainous region. J. Clean. Prod. 2022, 362, 132430. [Google Scholar] [CrossRef]
- Das, K.; Kumar, R. Assessment of Electric Two-Wheeler Ecosystem Using Novel Pareto Optimality and TOPSIS Methods for an Ideal Design Solution. World Electr. Veh. J. 2023, 14, 215. [Google Scholar] [CrossRef]
- Zyner, A.; Worrall, S.; Nebot, E. A recurrent neural network solution for predicting driver intention at unsignalized intersections. IEEE Robot. Autom. Lett. 2018, 3, 1759–1764. [Google Scholar] [CrossRef]
- Xin, L.; Wang, P.; Chan, C.-Y.; Chen, J.; Li, S.E.; Cheng, B. Intention-Aware Long Horizon Trajectory Prediction of Surrounding Vehicles using Dual LSTM Networks. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 1441–1446. [Google Scholar]
- Deo, N.; Trivedi, M.M. Convolutional Social Pooling for Vehicle Trajectory Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1468–1476. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Marchetti, F.; Becattini, F.; Seidenari, L.; Del Bimbo, A. Multiple Trajectory Prediction of Moving Agents with Memory Augmented Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 45, 6688–6702. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 1st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Zhao, X.; Chen, Y.; Guo, J.; Zhao, D. A spatial-temporal attention model for human trajectory prediction. IEEE/CAA J. Autom. Sin. 2020, 7, 965–974. [Google Scholar] [CrossRef]
- Kim, H.; Kim, D.; Kim, G.; Cho, J.; Huh, K. Multi-Head Attention Based Probabilistic Vehicle Trajectory Prediction. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1720–1725. [Google Scholar]
- Sheng, Z.; Xu, Y.; Xue, S.; Li, D. Graph-based spatial-temporal convolutional network for vehicle trajectory prediction in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17654–17665. [Google Scholar] [CrossRef]
- Li, X.; Ying, X.; Chuah, M.C. GRIP: Graph-Based Interaction-Aware Trajectory Prediction. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3960–3966. [Google Scholar]
- Su, Y.; Du, J.; Li, Y.; Li, X.; Liang, R.; Hua, Z.; Zhou, J. Trajectory Forecasting Based on Prior-Aware Directed Graph Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16773–16785. [Google Scholar] [CrossRef]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14424–14432. [Google Scholar]
- Shi, L.; Wang, L.; Long, C.; Zhou, S.; Zhou, M.; Niu, Z.; Hua, G. SGCN: Sparse Graph Convolution Network for Pedestrian Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8994–9003. [Google Scholar]
- Traffic Analysis Tools: Next Generation Simulation-FHWA Operations. Available online: https://ops.fhwa.dot.gov/trafficanalysistools/ngsim.htm (accessed on 24 November 2020).
- Deo, N.; Rangesh, A.; Trivedi, M.M. How Would Surround Vehicles Move? A Unified Framework for Maneuver Classification and Motion Prediction. IEEE Trans. Intell. Veh. 2018, 3, 129–140. [Google Scholar] [CrossRef]
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y.N. Multi-Agent Tensor Fusion for Contextual Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12118–12126. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction Horizon (s) | CV * | V-LSTM * | C-VGMM-VIM * | MATF * | CS-LSTM * | GRIP * | VTP-GCN (∆GRIP) |
|---|---|---|---|---|---|---|---|
| 1 | 0.73 | 0.68 | 0.66 | 0.67 | 0.62 | 0.64 | 0.55 (↓14%) |
| 2 | 1.78 | 1.65 | 1.56 | 1.51 | 1.29 | 1.13 | 0.99 (↓12%) |
| 3 | 3.13 | 2.91 | 2.75 | 2.51 | 2.13 | 1.80 | 1.56 (↓13%) |
| 4 | 4.78 | 4.46 | 4.24 | 3.71 | 3.20 | 2.62 | 2.36 (↓9%) |
| 5 | 6.68 | 6.27 | 5.99 | 5.12 | 4.52 | 3.60 | 3.59 (↓0%) |
| Average | 3.42 | 3.30 | 3.04 | 2.70 | 2.35 | 1.96 | 1.81 (↓8%) |
| Prediction Horizon (s) | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 0.63(+0.08) | 1.08(+0.09) | 1.65(+0.09) | 2.43(+0.07) | 3.73(+0.04) | |
| 0.55 | 0.99 | 1.56 | 2.36 | 3.59 |
| Prediction Horizon (s) | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Reciprocal of time interval | 0.72(+0.17) | 1.23(+0.24) | 1.79(+0.23) | 2.57(+0.21) | 3.80(+0.21) |
| Self-attention | 0.55 | 0.99 | 1.56 | 2.36 | 3.59 |
| Prediction Horizon (s) | W/O SGCN | W/O TGCN | VTP-GCN |
|---|---|---|---|
| 1 | 0.62(+0.07) | 0.67(+0.12) | 0.55 |
| 2 | 1.05(+0.06) | 1.16(+0.17) | 0.99 |
| 3 | 1.63(+0.07) | 1.69(+0.13) | 1.56 |
| 4 | 2.48(+0.12) | 2.40(+0.04) | 2.36 |
| 5 | 3.82(+0.23) | 3.49(−0.10) | 3.59 |
| Average | 1.92(↑6%) | 1.88(↑4%) | 1.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Sun, D.; Guo, B. Vehicle Trajectory Prediction Based on Graph Convolutional Networks in Connected Vehicle Environment. Appl. Sci. 2023, 13, 13192. https://doi.org/10.3390/app132413192
Shi J, Sun D, Guo B. Vehicle Trajectory Prediction Based on Graph Convolutional Networks in Connected Vehicle Environment. Applied Sciences. 2023; 13(24):13192. https://doi.org/10.3390/app132413192
Chicago/Turabian StyleShi, Jian, Dongxian Sun, and Baicang Guo. 2023. "Vehicle Trajectory Prediction Based on Graph Convolutional Networks in Connected Vehicle Environment" Applied Sciences 13, no. 24: 13192. https://doi.org/10.3390/app132413192